Prefácio: Em cenários de negócios, a equipe de segurança de uma empresa geralmente usa códigos de verificação como um método para reduzir o risco de danos aos negócios, de modo a reduzir a possibilidade de eventos de risco, como credenciamento, registro falso, furto fraudulento, roubo de informações e lã.
Hoje, vamos explorar a importância dos códigos de verificação no controle de riscos de negócios por meio da aplicação prática de códigos de verificação no evento especial do 10º aniversário da GeeExpert.
No evento de 10 anos de outubro, simulamos atividades de marketing de comércio eletrônico para criar um evento real de um cenário de negócios sendo atacado por uma máquina. Neste evento, o robô participou de um total de 1.183.900 sorteios de cartas e recebeu um total de 7.811 assinaturas iQiyi mensais por meio de trapaça de máquina. Se esse investimento for convertido em atividades operacionais de grande escala, os negócios da empresa podem causar uma perda de 234.300 yuans.
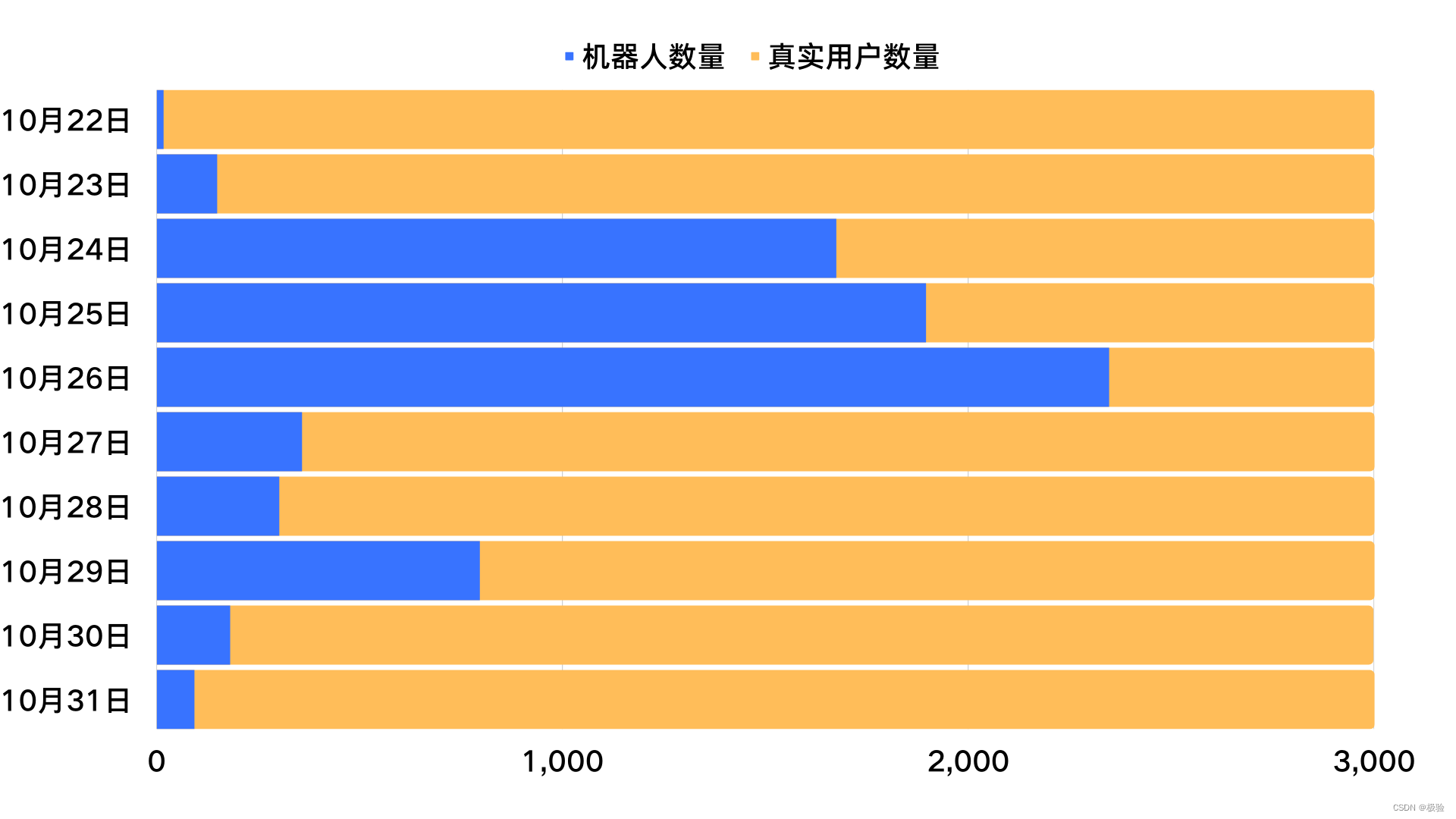
Usuários de máquinas x humanos aceitando prêmios
Tomando 27 de outubro como a linha divisória para implantar o código de verificação na cena de recebimento de recompensa, dividimos toda a atividade no primeiro estágio e no segundo estágio. No primeiro estágio sem o código de verificação, o robô retirou 6.081 recompensas com sucesso; mas na segunda etapa, o código de verificação desempenhou o papel de interceptar contas anormais, identificou com sucesso contas de risco e implementou estratégias de controle de risco. Segundo as estatísticas, existem 3.464 contas anormais identificadas por meio de códigos de verificação nessa atividade. Então, neste cenário de negócios, como o código de verificação identifica contas arriscadas?
O código de verificação usado nesta atividade é o código de verificação comportamental extremamente experimental. Esse código de verificação é baseado em características de comportamento biológico e usa aprendizado profundo de inteligência artificial para conduzir análises de alta dimensão nos dados de comportamento gerados durante o processo de verificação e descobre que reais usuários humanos e padrões de comportamento da máquina são consistentes com As diferenças nas características comportamentais podem distinguir com precisão entre humanos e máquinas nesta cena.
0 1
Análise e identificação de ideias de hacking
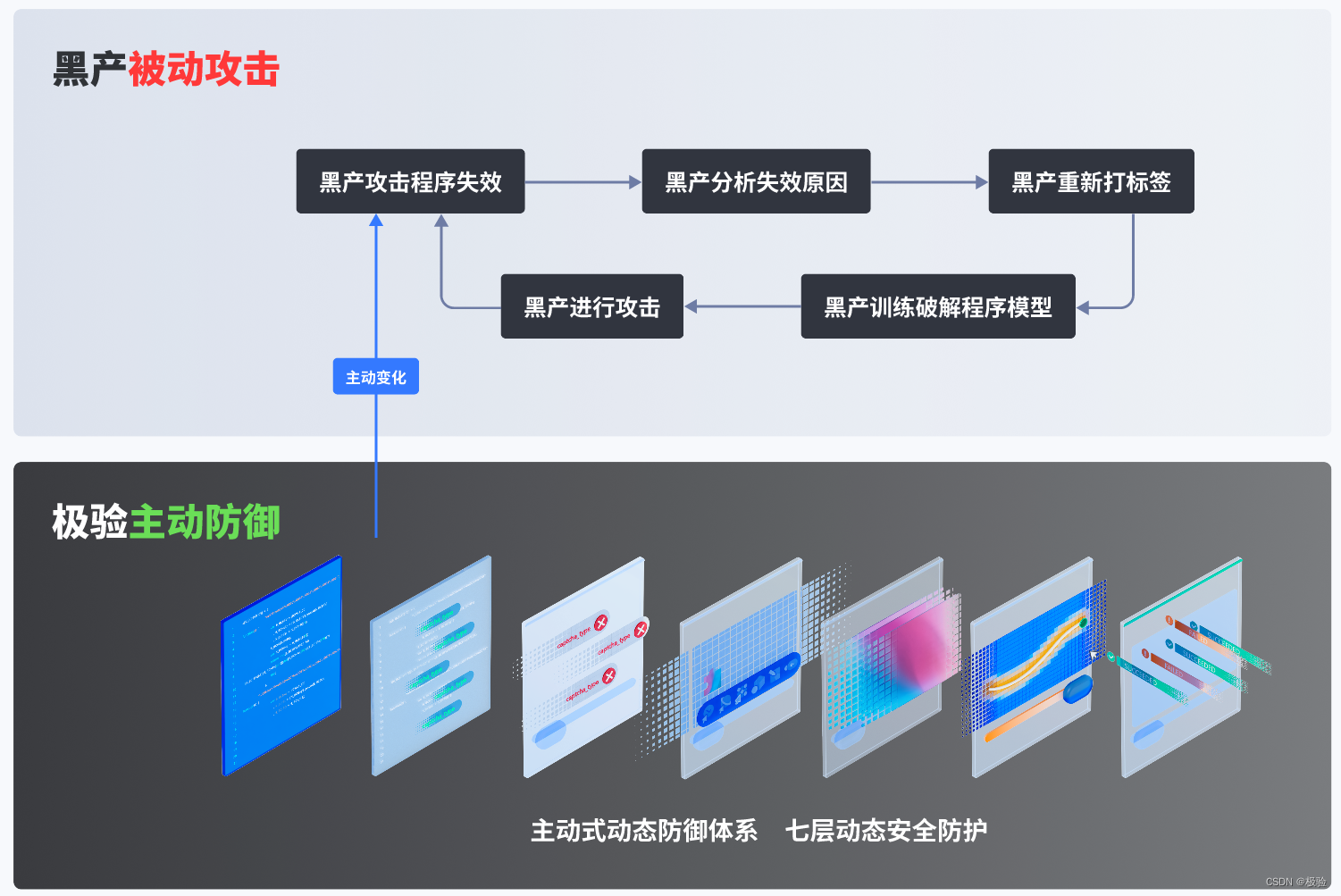
Por meio da análise de rastreamento da plataforma de cracking e da pesquisa reversa de produtos de segurança relacionados, o Jiexperi Interactive Security Lab descobriu que os códigos de verificação de cracking dependem principalmente do cracking do simulador e do cracking da interface.
Rachadura do simulador: através de várias ferramentas de teste automatizadas, como o Selenium para operar o kernel do cromo para realizar arrastar, clicar e outras operações automatizadas;
Quebra de interface: Use o programa de interface para quebrar os parâmetros-chave corretos, de modo a quebrar o código de verificação. Uma vez que a quebra de interface requer a restauração reversa do JS front-end e a lógica da geração de parâmetros precisa ser totalmente esclarecida, o limite técnico e o custo de implementação da quebra com simuladores são maiores.
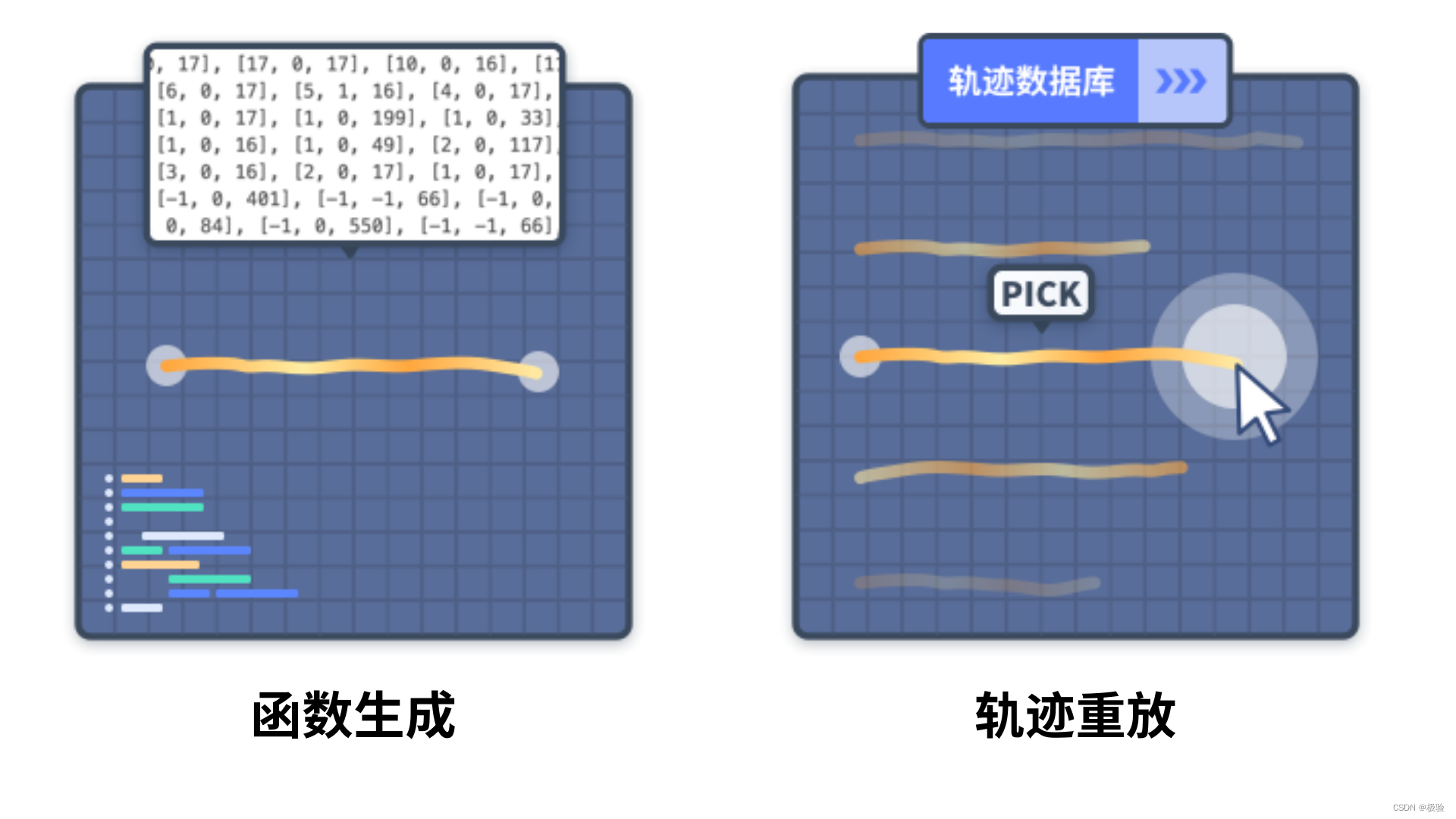
O cracking do simulador e o cracking da interface são dois caminhos técnicos para automatizar o processo de cracking, mas não importa qual seja usado, as respostas de verificação devem ser obtidas por meio de imagens manuais, exaustivas, reconhecimento de IA, etc., e então gerar uma trajetória de comportamento o mais realista possível . A geração automática de trajetórias inclui:
Geração de função: Ao escrever funções, dados de trajetória com padrões de comportamento específicos são gerados automaticamente e as características da máquina são relativamente óbvias.
Repetição da trajetória: Através de vários canais, amostras reais de trajetória de diferentes tipos e comprimentos são acumuladas, e os dados da trajetória são entregues repetidamente de acordo com a adaptação da resposta.
 Com base nisso, o captcha pode identificar exceções por meio dos três modelos a seguir:
Com base nisso, o captcha pode identificar exceções por meio dos três modelos a seguir:
Modelo CNN: O nome completo é o modelo de rede neural convolucional, que aprende automaticamente as características das trajetórias das máquinas a partir de bancos de dados massivos, distingue trajetórias homem-máquina em tempo real e bloqueia trajetórias de risco anormais.
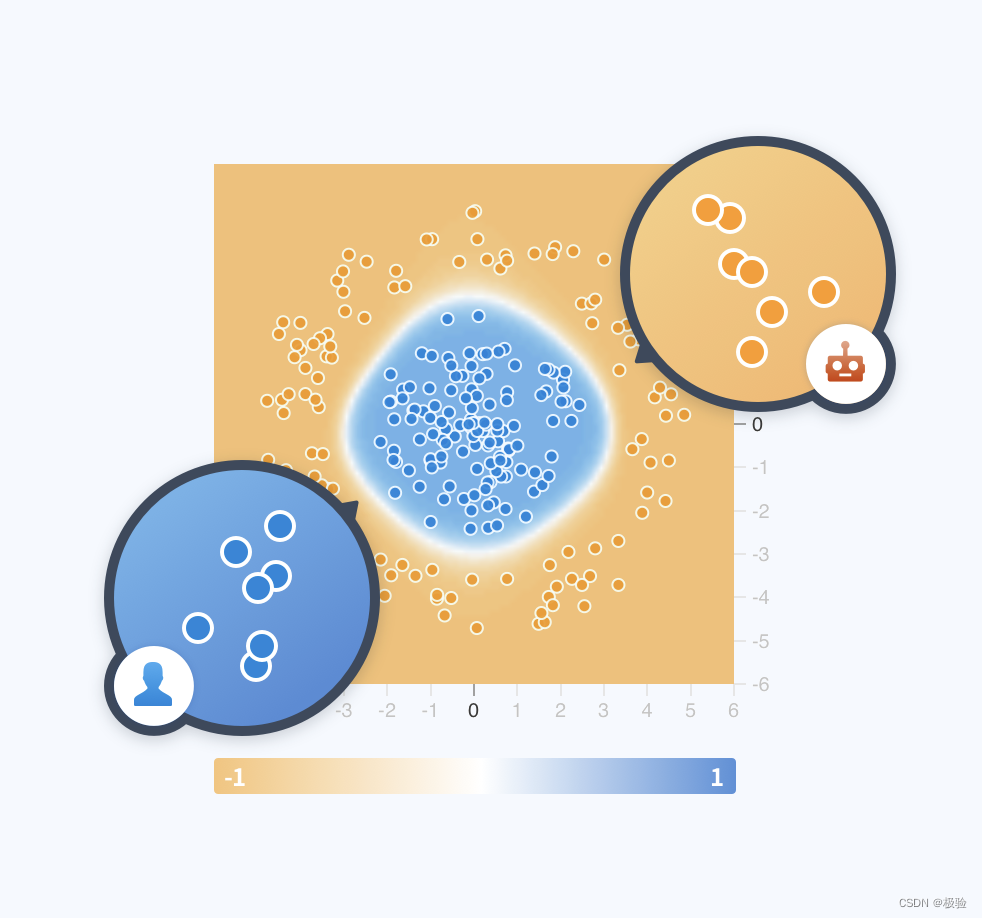
Modelo de cluster: a trajetória gerada pela função é muito fácil de gerar padrões de agregação no espaço de recursos, e o modelo de cluster dinâmico descobre automaticamente novos dados de máquina variantes por meio da agregação desse padrão de comportamento. O modelo de agrupamento calcula a distribuição de probabilidade dos dados no espaço de baixa dimensão no período atual, realizando o mapeamento de baixa dimensão dos dados no espaço de recurso de alta dimensão em tempo real. Se a probabilidade de uma determinada área for superior ao limite, a nova queda Os dados de trajetória nesta área serão banidos.
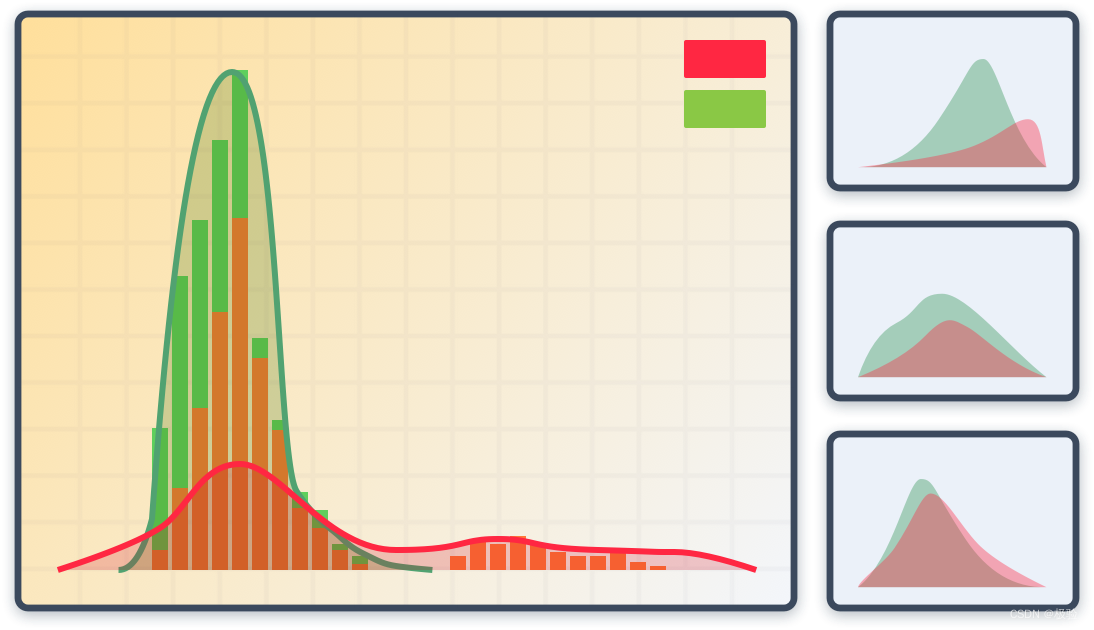
Modelo de hash: o modelo de hash processa os dados em um espaço de recursos de alta dimensão e cada trajetória real tem seu código de hash exclusivo correspondente. Quando os hackers tentam quebrar a verificação repetindo a trajetória ou gerando uma biblioteca de trajetória aleatória, a trajetória irá gerar uma colisão de hash, expondo assim as características da máquina.
0 2
Máquina de contra interceptação dinâmica em tempo real
Diante da invasão da máquina, o código de verificação pode desempenhar um papel de defesa em tempo real, ou seja, a máquina precisa responder a resposta correta na cena correspondente antes de prosseguir para a próxima etapa. Nesse evento, são coletadas recompensas por passar a verificação, para que a máquina possa ser interceptada em tempo real, reduza os usuários anormais da máquina em sites, software ou applets e reduza o risco de danos aos negócios.
Além disso, se os hackers atualizarem seus métodos de invasão por meio do aprendizado de máquina durante o processo de ataque, o código de verificação também poderá ser defendido de forma científica e eficaz por meio de mudanças dinâmicas, como ofuscação regular e transformação do front-end JS, alterações regulares da dinâmica do front-end parâmetros, a biblioteca de risco em toda a rede será atualizada regularmente e o algoritmo de criptografia de parâmetro será alterado de forma flexível. No entanto, entre os códigos de verificação existentes, apenas o GeeExperiment 4.0 pode fazer isso.
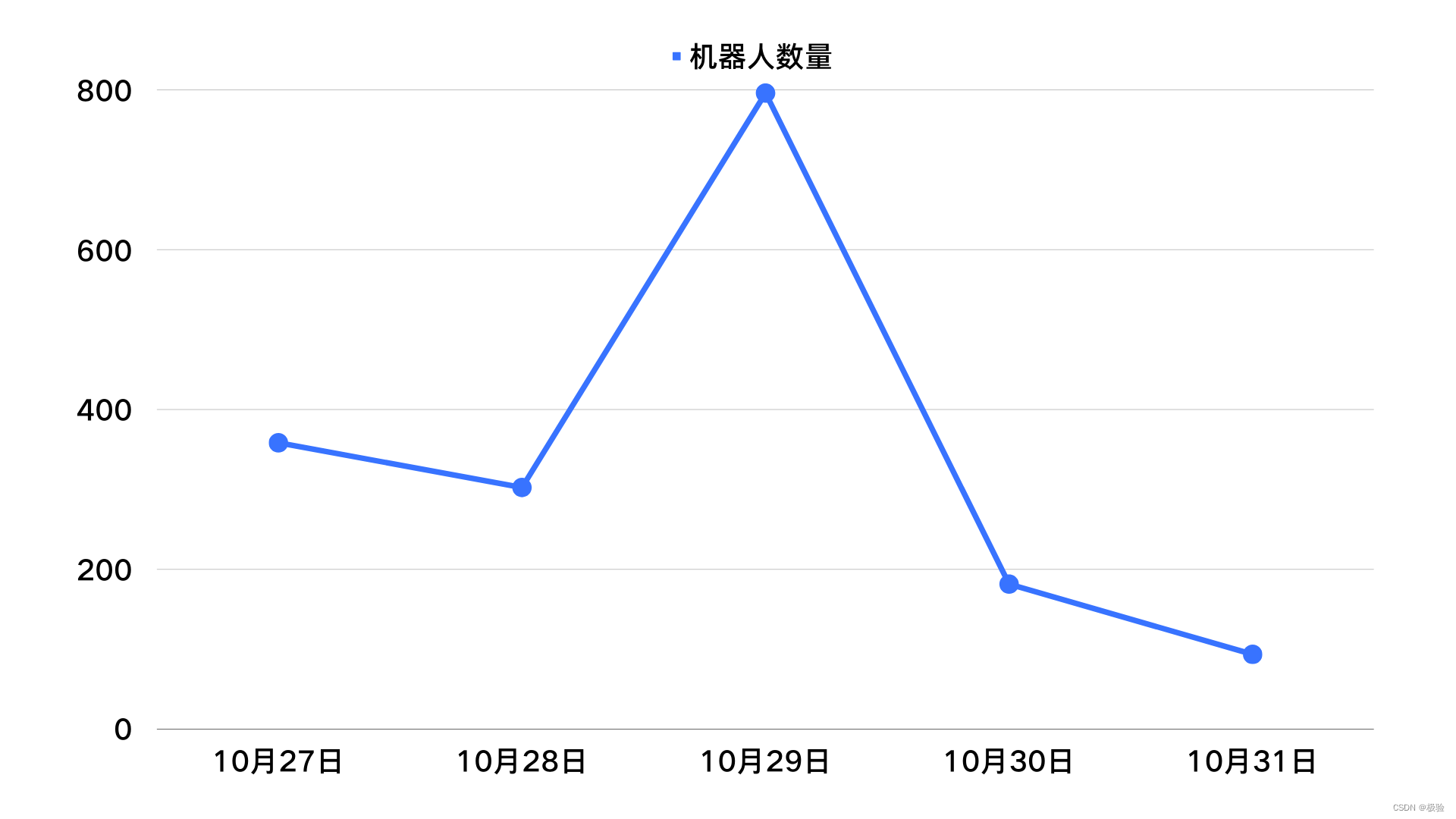
Por exemplo, sob a proteção do código de verificação, o número de prêmios recebidos nos dias 27 e 28 do evento diminuiu significativamente em comparação com o 26º dia em que nenhum código de verificação foi configurado, mas o número de prêmios recebidos no dia 29 aumentou ligeiramente. Com dez anos de rica experiência, julgamos que a indústria negra atualizou seus métodos de ataque por meio do aprendizado de máquina neste momento.
Imediatamente, atualizamos a estratégia do modelo de verificação. Diante de solicitações arriscadas, o cérebro de IA de verificação fortalecerá automaticamente a estratégia de confronto, como: alternar dinamicamente o formulário de verificação, atualizar automaticamente o modelo visual etc. O modelo de código de verificação que muda dinamicamente trouxe grandes desafios para a produção negra, aumentou o custo e o tempo de quebra e melhorou a capacidade de interceptação, então podemos ver claramente que o número de máquinas nos últimos dois dias do evento está em queda tendência novamente.
0 3
A importância dos códigos de verificação em aplicações práticas
Hoje, os hackers utilizam meios mais diversificados de ataques a máquinas. Através dos casos reais acima, podemos ver que os códigos de verificação têm o seguinte significado prático no controle de risco:
1) Auxiliar as empresas a fazer julgamentos de risco: os dados comportamentais coletados pelos códigos de verificação podem efetivamente enriquecer a dimensão de coleta de informações do sistema de controle de risco e fornecer perspectivas mais diversas e base para o julgamento final. Por exemplo, a verificação de quebra-cabeça deslizante pode coletar trilhas deslizantes do usuário e a verificação de reconhecimento de imagem pode coletar eventos de clique do mouse do usuário.
2) Melhorar a dificuldade de ataques de hackers: o código de verificação é implantado como um componente necessário na entrada de negócios importantes, como login, recuperação de senha, colocação de pedidos e postagem de comentários, o que pode efetivamente impedir ataques como colisão de banco de dados e ataques violentos adivinhação de força A implantação de códigos de verificação Aumentou a dificuldade de ataque de produtos pretos.
3) Lidando com tráfego malicioso: Além do significado direto acima, muitas empresas de Internet estiveram ou estão trabalhando na construção de seus próprios sistemas de controle de risco com base nas condições reais de negócios. Sob a premissa do resultado do julgamento do sistema de controle de risco, ele pode ser processado em combinação com códigos de verificação de diferentes níveis de dificuldade para melhorar a experiência do usuário e reduzir erros de julgamento.