Nos últimos anos, o aprendizado profundo se desenvolveu rapidamente como uma tecnologia. Mais e mais soluções de inteligência artificial usam o aprendizado profundo como tecnologia básica. No entanto, construir um modelo de aprendizado profundo não é uma tarefa fácil. Para obter precisão e eficiência satisfatórias, geralmente leva semanas para otimizar o modelo.
A otimização do modelo geralmente inclui dois níveis: a própria estrutura da rede e os parâmetros de treinamento. A estrutura da rede inclui principalmente o número de camadas, nós, pesos e funções de ativação. Os parâmetros de treinamento incluem época, tamanho do lote, taxa de aprendizado, custo funções, normalização, regularização e otimização.
O aprendizado profundo é um subconjunto do aprendizado de máquina. O aprendizado profundo é principalmente a construção e o uso de modelos de redes neurais. As redes neurais geralmente têm três ou mais camadas. As redes neurais simulam o processamento de dados e o processo de tomada de decisão do cérebro humano. O aprendizado profundo é usado no processamento de linguagem natural (reconhecimento e síntese de linguagem), reconhecimento de imagem, direção autônoma e outros campos ganharam aplicações comerciais.
Ao abordar os problemas a serem tratados no aprendizado profundo, o processo de treinamento geralmente é o seguinte:
1. Construir um conjunto de dados de treinamento rotulado de acordo com o objeto do problema de processamento (correspondência um-para-um de entrada e saída);
2. De acordo com experiência (baseada em papel ou com base na intuição, etc.) para construir uma rede neural (TensorFlow, Keras, etc. estão todos disponíveis); 3.
Os pesos e deslocamentos (pesos e viés) de cada nó na rede construída são inicializado com valores aleatórios;
4. De acordo com a relação saída-entrada marcada, minimize o erro de previsão do modelo
5. Ajuste o peso e o valor de deslocamento de cada nó da rede neural de acordo com o erro de previsão;
6. Ajuste os parâmetros do modelo, incluindo camada, nó e outros parâmetros de treinamento para otimizar o modelo;
7. Salve o modelo treinado e estabeleça o raciocínio de implantação
A otimização do modelo pode ser feita a partir dos dois aspectos dos resultados de inferência (cálculo direto) e metas de treinamento. O objetivo da inferência é obter a maior precisão possível com o menor custo de cálculo possível. A otimização do processo de treinamento inclui o tempo de treinamento ( menos iterações) ), evite armadilhas de treinamento (gradientes desaparecendo e explodindo) e superajuste.
Processo de ajuste de aprendizado profundo
Preparação antes da afinação
No início do ajuste, um objetivo razoável (precisão e eficiência) deve ser definido e, em seguida, um conjunto de dados de treinamento apropriado deve ser organizado. A adequação aqui se refere aos dados relativamente equilibrados de várias amostras para o problema de destino e o conjunto de dados pode maximizar Cobrindo a cena de destino, faça um conjunto de teste da cena de destino.
Processo de ajuste
Os parâmetros ajustáveis incluem as duas categorias a seguir,
- Arquitetura do modelo de rede, número de camadas e seus relacionamentos em cascata, tipos de nó, pesos e funções de ativação, etc.
- Parâmetros de treinamento, incluindo épocas e lotes, normalização e regularização,
no processo de ajuste, o otimizador seleciona um ajuste de parâmetro de duas categorias por vez e seleciona um conjunto de parâmetros adequados de acordo com sua própria compreensão e experiência. Selecione um conjunto, como para tamanho do lote, você pode escolher o tamanho do lote 32, 64, 128 e 256 como um grupo de comparações e, para funções de ativação, pode escolher sigmoid, tanh, relu, elu, softmax, etc. como um grupo de comparações e, em seguida, use o mesmo conjunto de dados e conjunto de validação para treinar o modelo e, em seguida, use o conjunto de teste para comparar o impacto de diferentes seleções de parâmetros nos resultados e, em seguida, pegue os parâmetros que têm um grande impacto na precisão e no desempenho em um única etapa como objeto de pesquisa, semelhante a um único parâmetro, e ajustar a etapa anterior ao mesmo tempo com base na experiência Para avaliar o impacto de vários parâmetros que têm grande influência nos resultados do modelo e, finalmente, usar diferentes conjuntos de teste para testar os resultados e selecionar o modelo obtido ajustando o conjunto de parâmetros com o melhor efeito.
Estrutura básica do modelo
O site oficial do TensorFlow recomenda que, ao construir um modelo, comece com um simples e aumente gradualmente a complexidade do modelo, o que ajuda a iterar rapidamente o modelo. Aqui tomamos o Mnist como exemplo para mostrar o processo de otimização de treinamento. Embora o site oficial do keras dê um exemplo de um modelo baseado em uma rede convolucional, quando o exemplo no site oficial itera para 12 épocas, a precisão no conjunto de treinamento é:
Epoch 12/15
237/422 [===============>..............] - ETA: 7s - loss: 0.0398 - accuracy: 0.9877
Este é o resultado original fornecido no site oficial e haverá pequenas diferenças em diferentes processos de treinamento.
Aqui, a rede totalmente conectada sugerida pelo site oficial é usada como modelo inicial. Para simplificar o código de treinamento, o código geral é usado como uma função python independente e o ajuste é implementado em diferentes funções.
O código adota a ideia de design de estrutura. Para o código relacionado ao modelo principal, consulte Base_model. Os diferentes parâmetros testados são realizados pela configuração do loop for. Essa estrutura de código ajuda a estabelecer uma maneira de pensar clara e estruturada. Veja o endereço de download:
Link de download do código- fonte deste blog
Ajuste de hiperparâmetros
Tamanhos de época e lote
from Base_model import *
#--------------------------------------
#Epoch and batch size comparision
#--------------------------------------
accuracy_measures = {
}
for batch_size in range(16, 128, 16):
# Load default configuration
model_config = base_model_config()
# Acquire and process input data
X_train, Y_train, X_test, Y_test = get_data()
# set epoch to 20
model_config["EPOCHS"] = 12
# Set batch size to experiment value
model_config["BATCH_SIZE"] = batch_size
model_name = "Batch-Size-" + str(batch_size)
history = create_and_run_model(model_config, X_train, Y_train, model_name)
accuracy_measures[model_name] = history.history["accuracy"]
plot_graph(accuracy_measures, "Compare Batch Size and Epoch")
Link de download do código- fonte deste blog
Os resultados do teste de 12 épocas são os seguintes
| tamanho do batch | precisão (12 épocas) |
|---|---|
| 16 | 0,9785208106040955 |
| 32 | 0,9809791445732117 |
| 48 | 0,9815000295639038 |
| 64 | 0,981166660785675 |
| 80 | 0,979812502861023 |
| 96 | 0,9786666631698608 |
| 112 | 0,9773333072662354 |
 |
|
| Pode ser visto na tabela e na figura que o tamanho do lote é igual a 48 e a precisão é maior quando a época está acima de 10. |
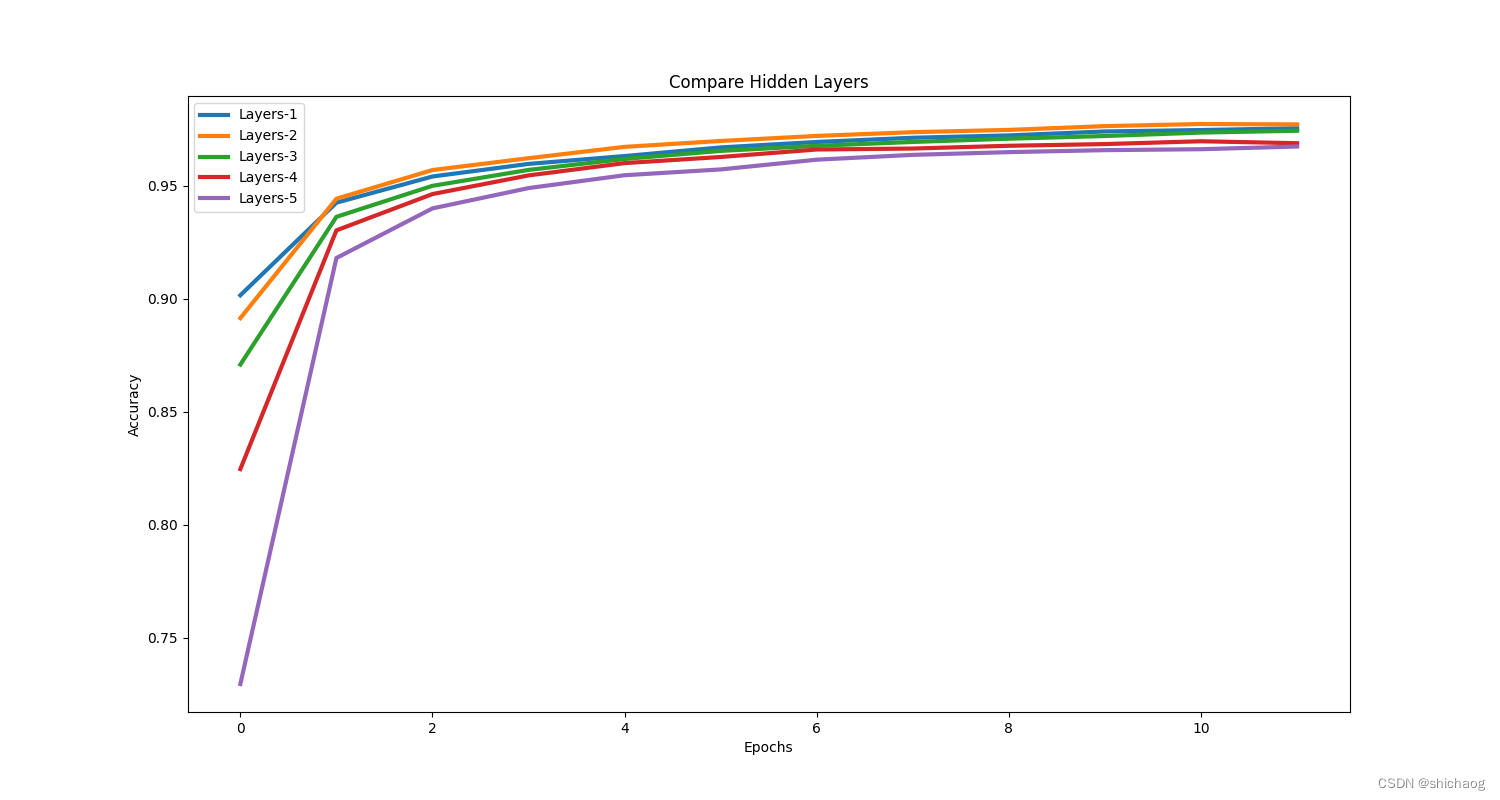
Ajustando o número de camadas
| número de camadas | precisão (12 épocas) |
|---|---|
| 2 (camada não oculta) | 0,9753124713897705 |
| 3 | 0,9770416617393494 |
| 4 | 0,9742291569709778 |
| 5 | 0,968708336353302 |
| 6 | 0,9672499895095825 |
 |
|
| Com isso, podemos ver que quando o número de camadas é igual ou maior que a seção anterior, a precisão não é tão alta quanto o teste da seção anterior. Além disso, o número de camadas não é tão bom quanto possível. É por isso que o site oficial recomenda começar com um modelo simples.O motivo do começo, é claro, também pode ser usado para reproduzir e lidar com o problema-alvo dos trabalhos existentes. |
Diferentes camadas de ajuste de nós
Como o tamanho dos nós afeta a precisão do modelo, é necessário comparar diferentes nós. A tabela a seguir é uma comparação das três camadas
| número de nós | precisão (12 épocas) |
|---|---|
| 8 | 0,9283124804496765 |
| 16 | 0,9551041722297668 |
| 24 | 0,9686458110809326 |
| 32 | 0,9765833616256714 |
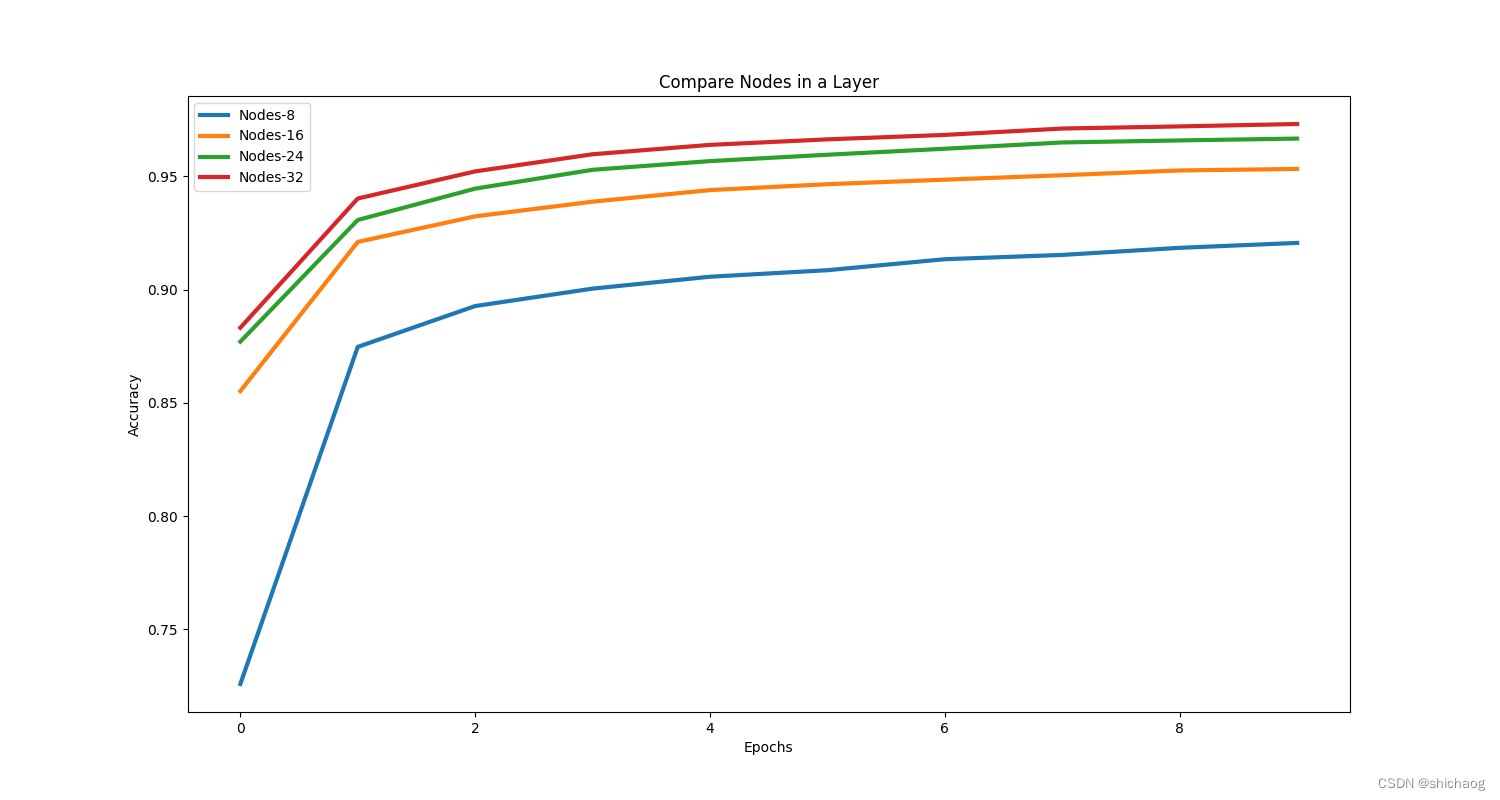
Os nós do modelo padrão são 32 e 64 respectivamente, e aqui ambas as camadas são 32, e o intervalo de teste de nós deve ser expandido.
função de ativação
Existem 10 funções de ativação comuns, aqui é simples, apenas relu, sigmoid e tanh são listados para comparação
| função de ativação | precisão |
|---|---|
| retomar | 0,9792708158493042 |
| sigmoide | 0,971750020980835 |
| duvidoso | 0,9769999980926514 |
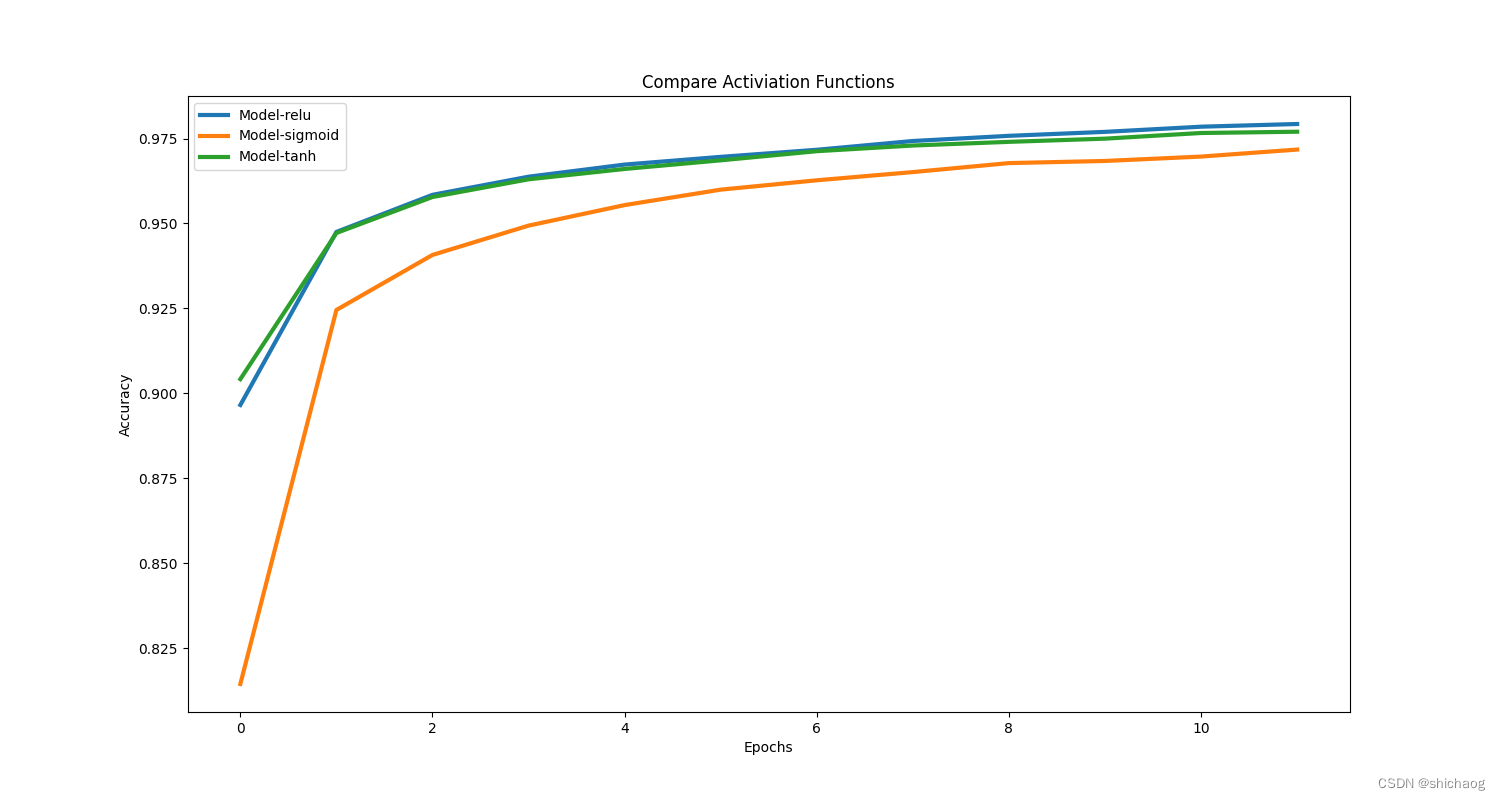 |
### Impacto de inicialização de pesos
| Inicialização de pesos | precisão |
|---|---|
| normal aleatório | 0,9790416955947876 |
| zeros | 0,11395833641290665 |
| uns | 0,11437500268220901 |
| uniforme aleatório | 0,9780833125114441 |
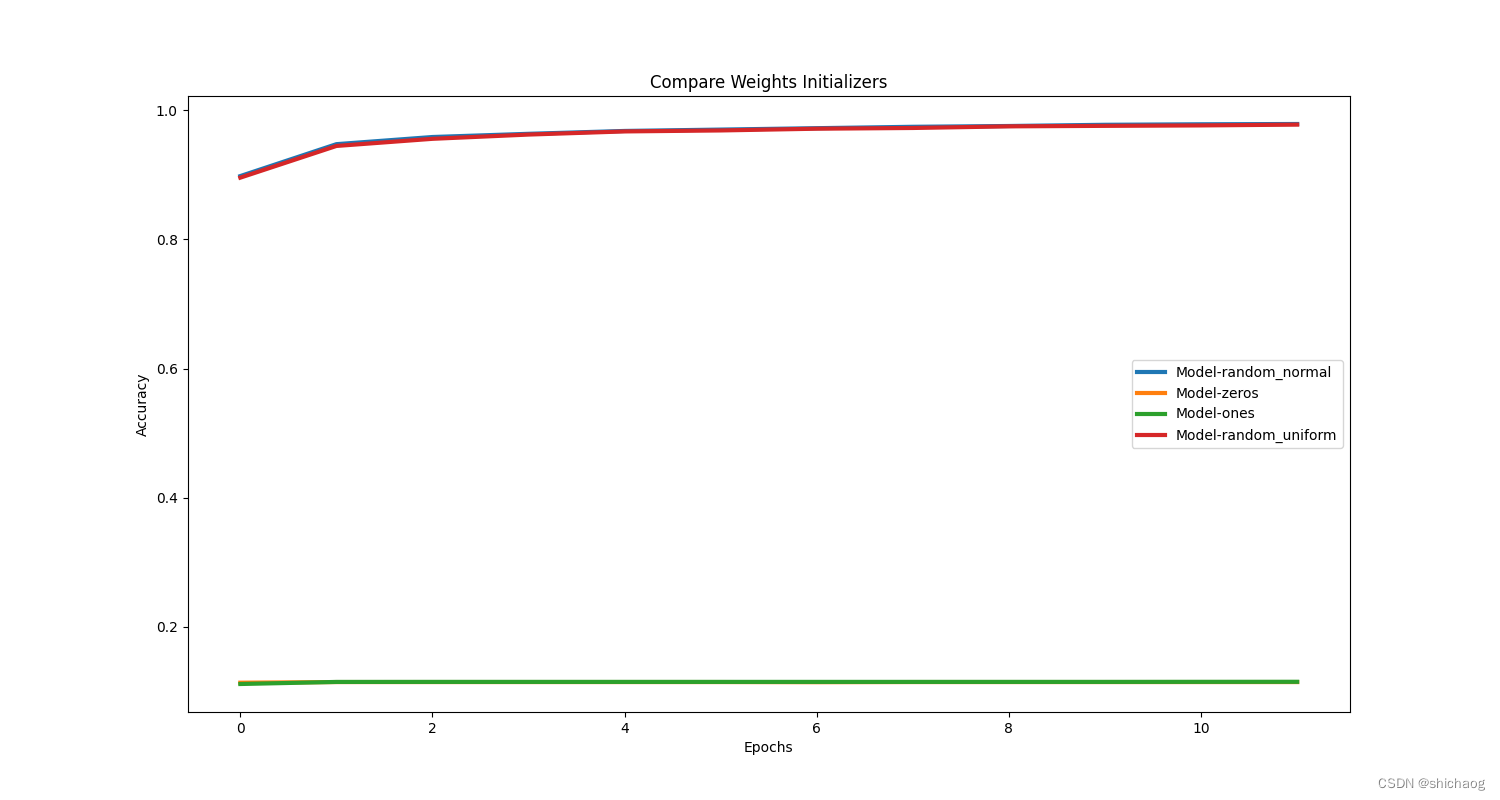
Ajuste do parâmetro de gradiente de treinamento
normalização em lote
| normalização | 12 época |
|---|---|
| com | 0,9826458096504211 |
| Nenhum | 0,9813958406448364 |
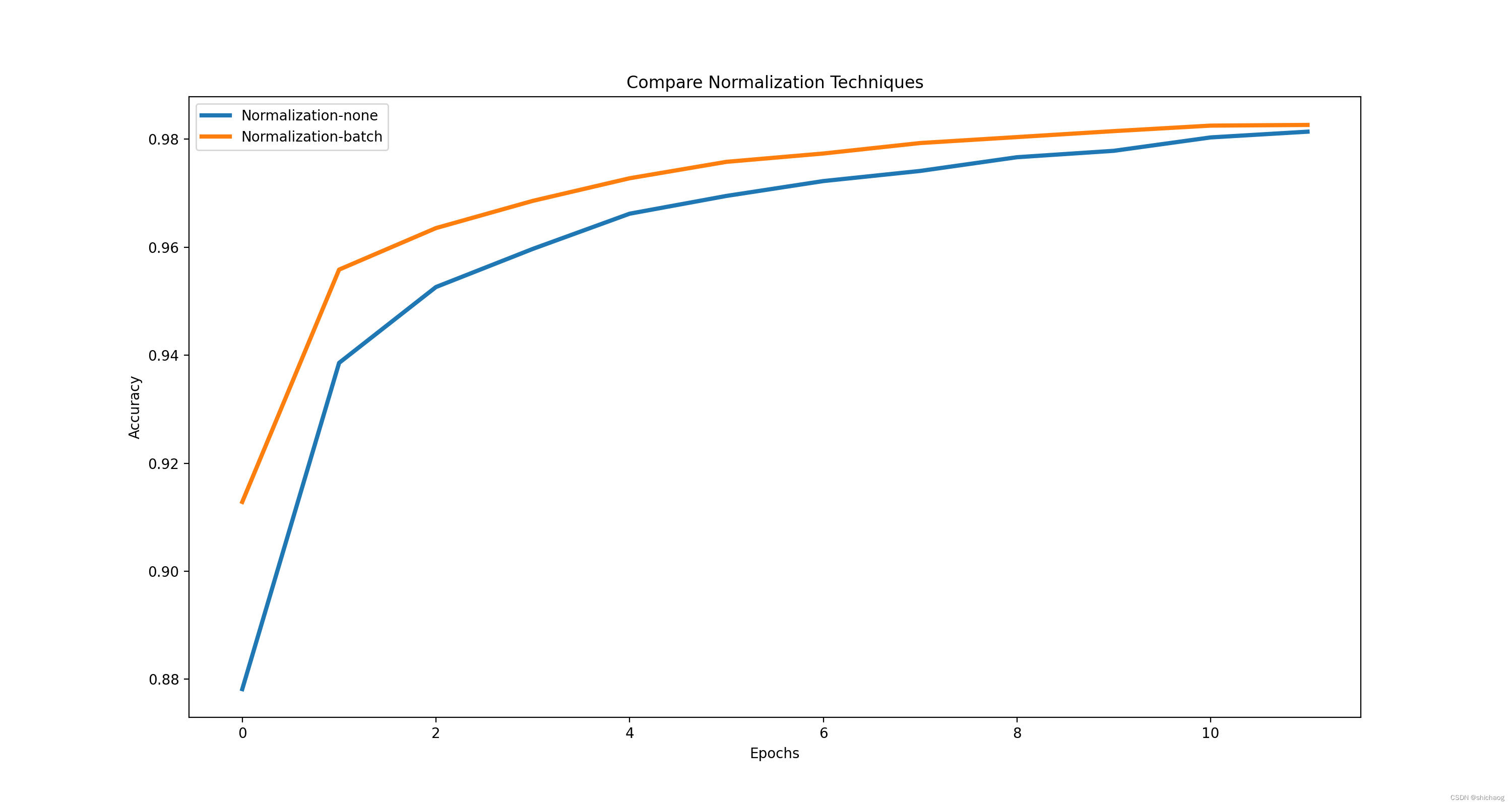
Ajuste de Otimizadores
O otimizador também afeta a convergência da propagação do gradiente reverso. Diferentes otimizadores têm diferentes velocidades de convergência e desempenhos.
| otimizador | precisão |
|---|---|
| sgd | 0,9803333282470703 |
| rmsplug | 0,9818333387374878 |
| Adão | 0,9816458225250244 |
| dose | 0,8760625123977661 |
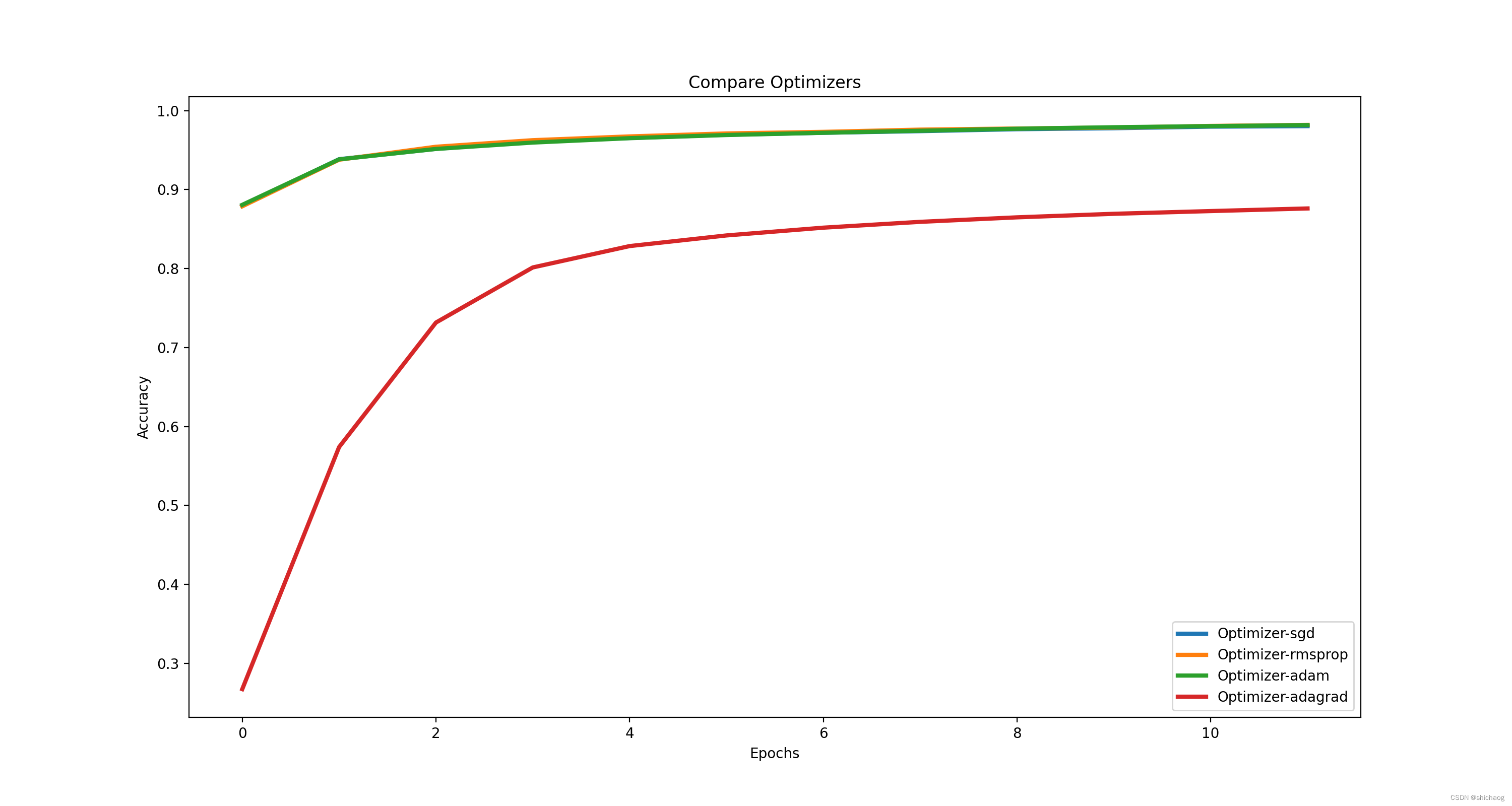
Ajuste da taxa de aprendizado
Taxas de aprendizado diferentes têm diferenças na velocidade e na precisão da convergência. Taxas de aprendizado maiores tendem a ter velocidades de convergência mais rápidas no início, mas muitas vezes falham em alcançar a solução ideal. Portanto, taxas de aprendizado dinâmicas são frequentemente usadas. A implementação do LearningRateScheduler é fornecida em keras Esta função .

controle de sobreajuste
Regularização
Os métodos regulares são L1, L2 e L1_L2
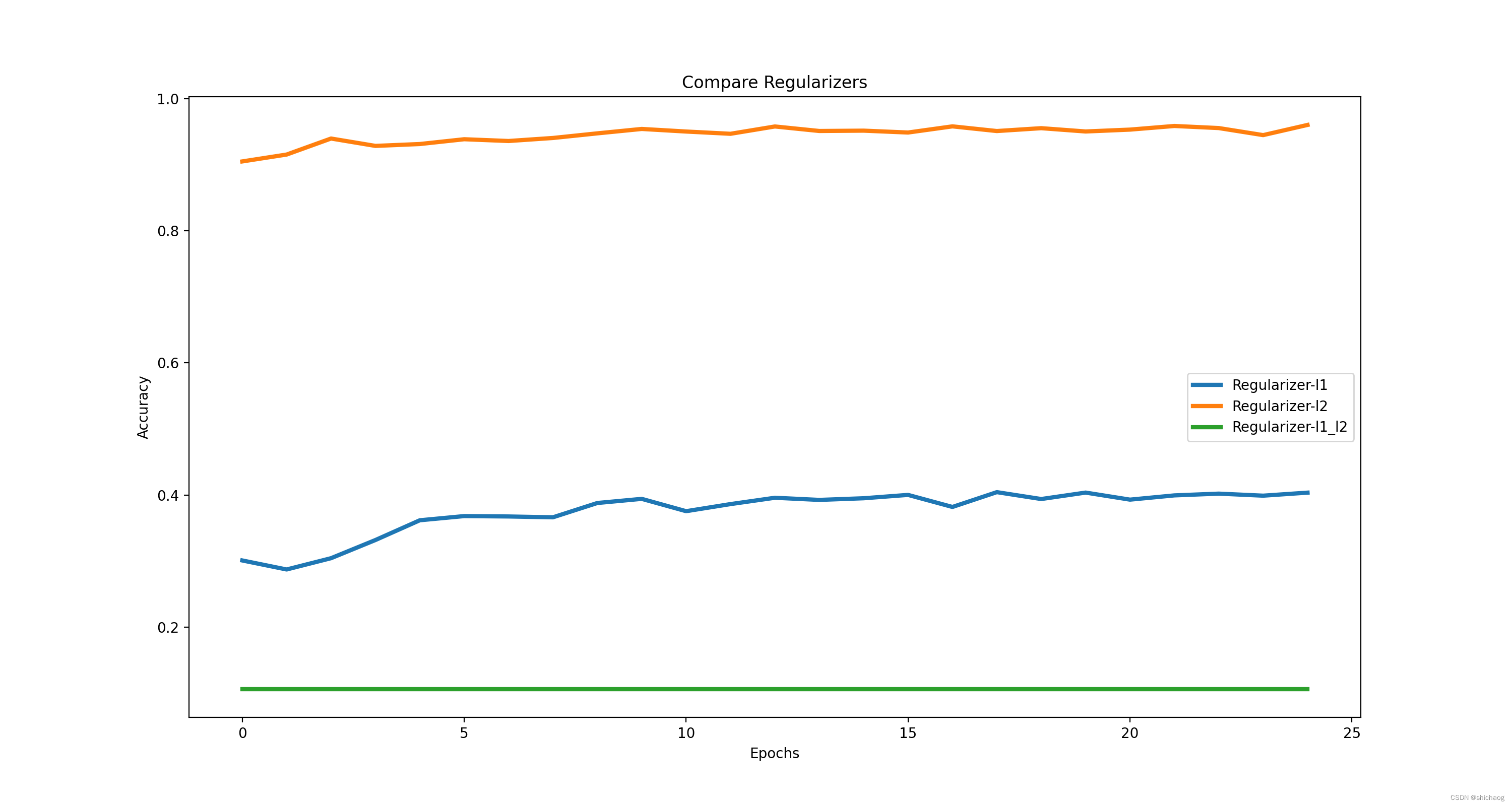
cair fora
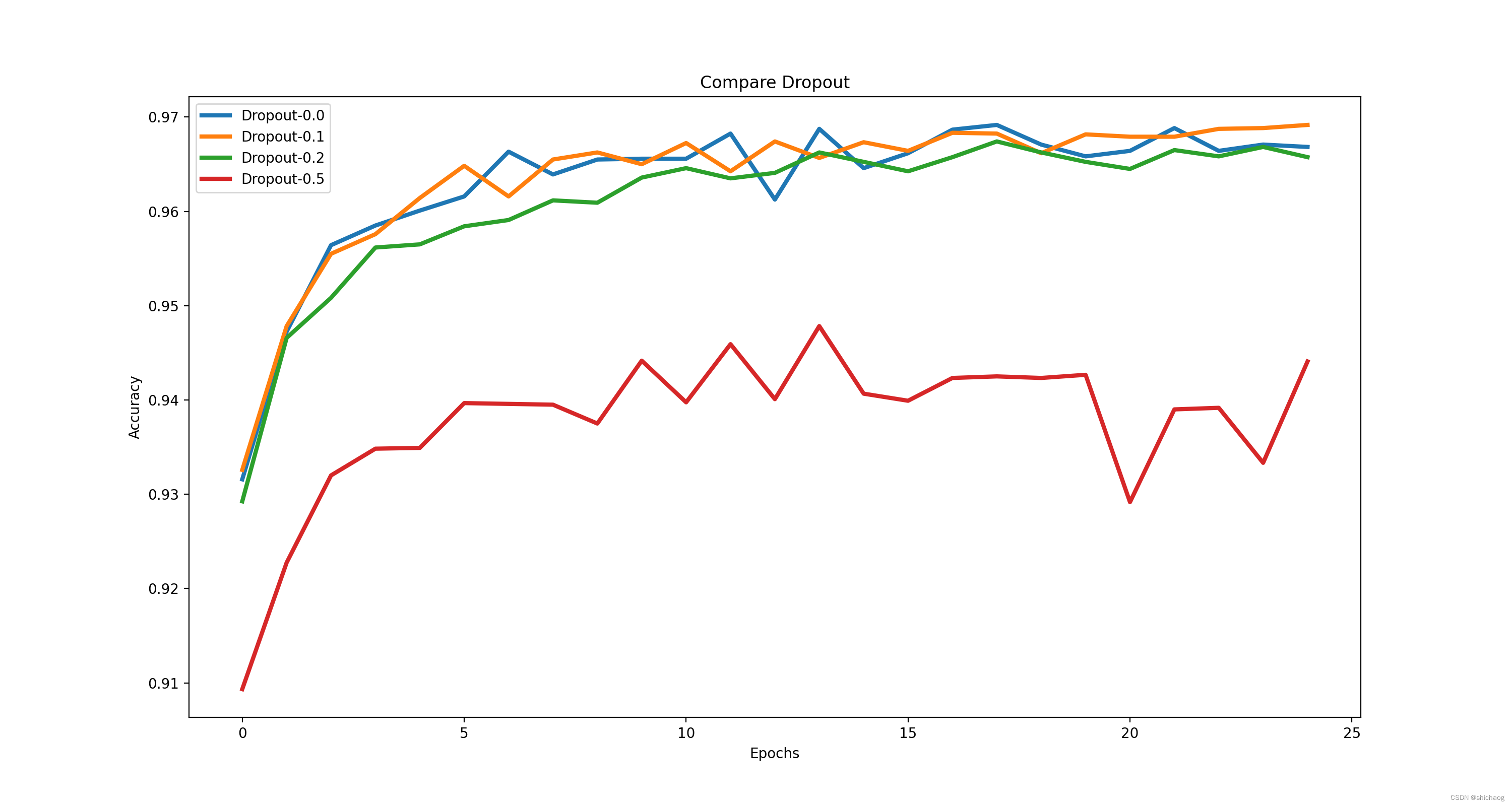
Link de download do código- fonte deste blog
Além disso, existem combinações de diferentes OPs (convolução, LSTM, GRU), diferentes estruturas de rede (Resnet, Densenet, mobileNet, VGG) etc., além de operações como aprimoramento de dados de treinamento, embaralhamento e perda de treinamento.