Domain-Driven Design (DDD) als Softwareentwicklungsmethode kann uns dabei helfen, qualitativ hochwertige Softwaremodelle zu entwerfen, die Geschäftsabsichten genau ausdrücken können.
Was können Sie von DDD erwarten?
Zunächst einmal sollte DDD weder ein zeremonieller Prozess noch ein Hindernis für den Fortschritt Ihres Projekts sein.
Zweitens bietet DDD sowohl strategische als auch taktische Modellierungswerkzeuge, die uns beim Entwerfen qualitativ hochwertiger Softwaremodelle unterstützen.
Es sollte beachtet werden, dass es bei DDD nicht um Technologie geht, sondern um Diskussion, Zuhören, Verstehen, Entdeckung und geschäftlichen Wert, die alle dazu dienen, Wissen zu sammeln und ein zentralisiertes geschäftliches Wissenssystem aufzubauen.
Während Sie DDD praktizieren, fügen Sie Ihrem Team besser Leute hinzu, die keine Fachsprache verwenden (Experten für Geschäftsdomänen).
Wer ist der Domänenexperte?
Domänenexperte ist keine Berufsbezeichnung, er kann jeder sein, der sich im Geschäft auskennt - Vertrieb, Produktmanager, Softwareentwickler ...
Was ist ein Domänenmodell?
Ein Domänenmodell ist ein Softwaremodell für eine bestimmte Geschäftsdomäne. Normalerweise wird das Domänenmodell durch das Objektmodell (Objekt = Daten + Verhalten) realisiert und drückt die genaue geschäftliche Bedeutung aus.
Autor: Java Muse
Link: https://juejin.cn/post/7117076459889360933
Quelle: Rare Earth Nuggets
Das Urheberrecht liegt beim Autor. Für den kommerziellen Nachdruck wenden Sie sich bitte zwecks Genehmigung an den Autor, für den nicht kommerziellen Nachdruck geben Sie bitte die Quelle an.
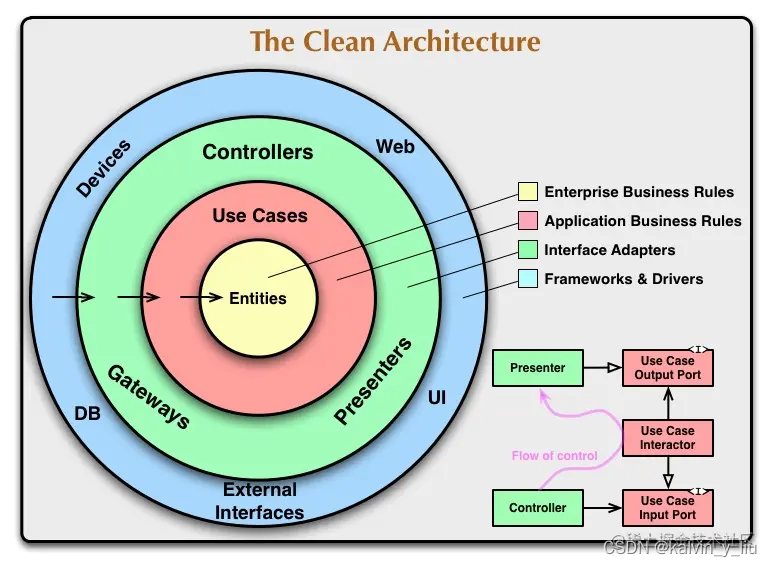
Innerlich abhängige Regeln
Ein sauberes Architekturdiagramm ist ein konzentrischer Kreis. Seine Abhängigkeitsregel lautet: "Die Abhängigkeitsrichtung ist nach innen, und jeder Ring kann von seiner eigenen Schicht und allen internen Schichten abhängen, kann sich jedoch nicht auf seine externen Schichten verlassen." Wie durch den schwarzen horizontalen Pfeil in der Abbildung gezeigt.
Obwohl es in der Figur nur vier Schichten gibt, kann es mehr als vier Schichten sein und kann weiter unterteilt oder nach außen erweitert werden, solange die "innere Abhängigkeitsregel" erfüllt ist.
- Wenn Entitäten
DDD entsprechen, wird diese Schicht verwendet, um Domänenmodelle wie Entitäten, Wertobjekte und Aggregationen zu platzieren. Die Geschäftslogik sollte in dieser Schicht so weit wie möglich kohärent sein.Diese Schicht ist die reinste und muss sich auf nichts anderes verlassen. - Anwendungsfälle
Die Übersetzung ist eine „Anwendungsfallschicht“, die verwendet wird, um den Datenfluss in die und aus der Entitätsschicht zu koordinieren und den Anwendungsfall durch Aufrufen und Orchestrieren des Domänenmodells zu realisieren. In DDD ist diese Schicht normalerweise die Anwendungsdienstschicht, die eine sehr dünne Schicht ist und nur verwendet wird, um einige relativ einfache Dinge zu tun.
- Schnittstellenadapter
Diese Schicht wird als "Schnittstellenanpassungsschicht" bezeichnet, die eigentlich hauptsächlich der Anpassung an die Außenwelt dient. Zum Beispiel Controller (Schreiben) und Präsentatoren (Lesen), die für Webanfragen eingehen. Diese Schicht konvertiert die Datenstruktur, die von der Benutzerfall- oder Entitätsschicht benötigt wird, mit der Datenstruktur der äußeren Schicht. Wie das Betreiben der Datenbank, das Aufrufen von Drittschnittstellen etc.
- Frameworks und Treiber
Diese Schicht ist hauptsächlich die Framework- und Treiberschicht, wie z. B. Datenbanktreiber, WEB-Framework, UI usw. Es ist selten, Code auf dieser Schicht in der täglichen Codierung zu schreiben.
Grenzüberschreitung und Abhängigkeitsumkehr
sind in der unteren rechten Ecke des Diagramms dargestellt. Unser Geschäftsprozess kommt normalerweise zuerst vom Controller und ruft die Use Cases-Schicht auf. Aber manchmal muss die Anwendungsfallebene den Präsentator anrufen. Wenn es direkt aufgerufen wird, wird die „innere Abhängigkeitsregel" gebrochen. Zu diesem Zeitpunkt kann die „Abhängigkeitsinversion" dazu verwendet werden.
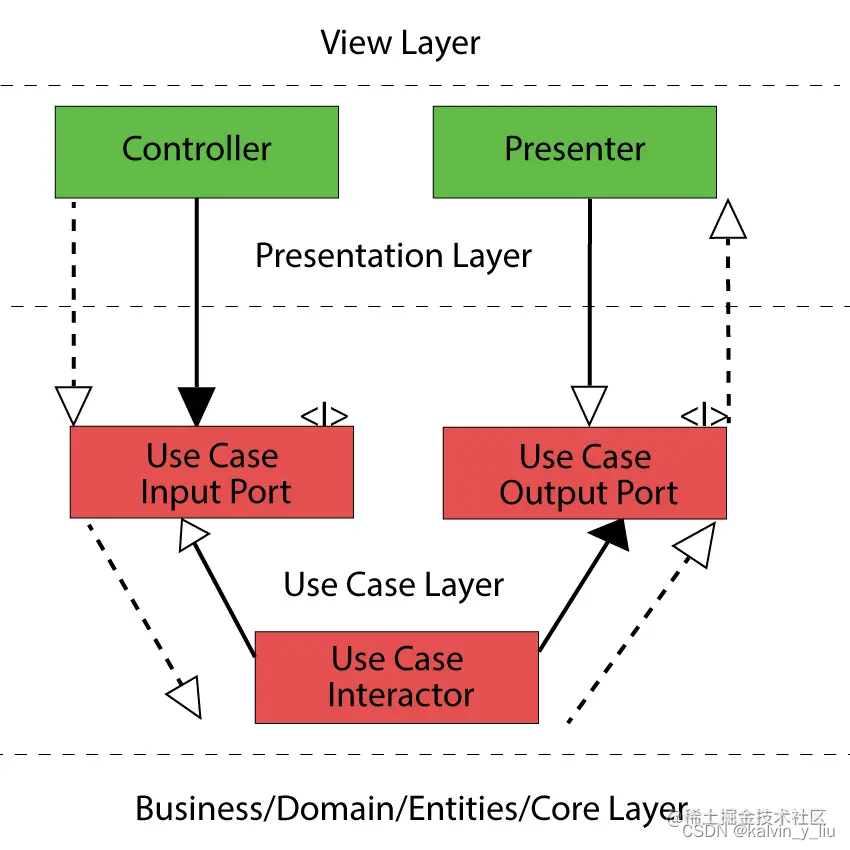
Abhängigkeitsumkehrung
Einfach ausgedrückt definieren wir zwei abstrakte Klassen oder Schnittstellen in der Use Cases-Schicht: Use Case Input Port oder Use Case Output Port. Use Case Interactor implementiert Use Case Input Port und Presenter implementiert Use Case Output Port.
Auf diese Weise muss die Use Cases-Schicht nicht von externen Schichten abhängig sein. Das gleiche Prinzip kann auch in Interaktionsszenarien mit Datenbanken, Schnittstellen von Drittanbietern usw. verwendet werden.
DDD und saubere Architektur
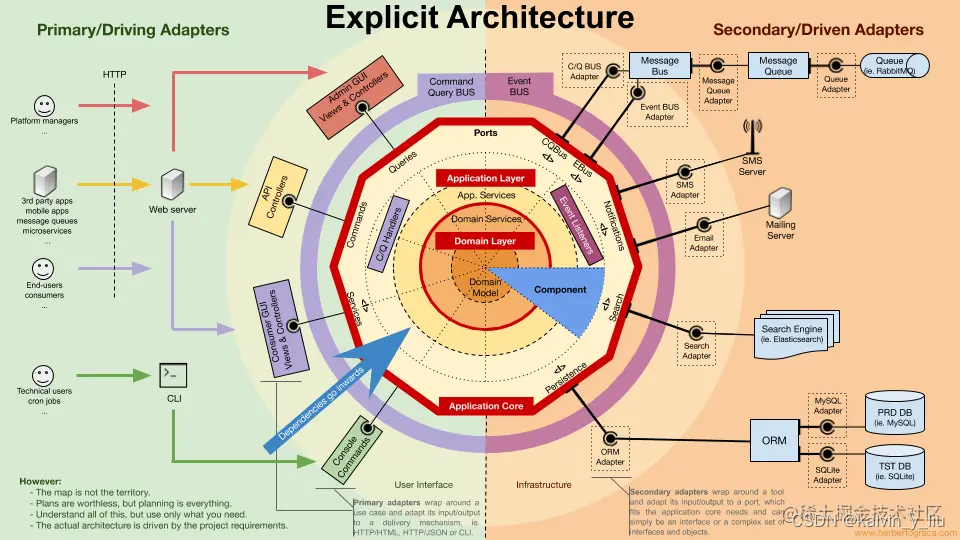
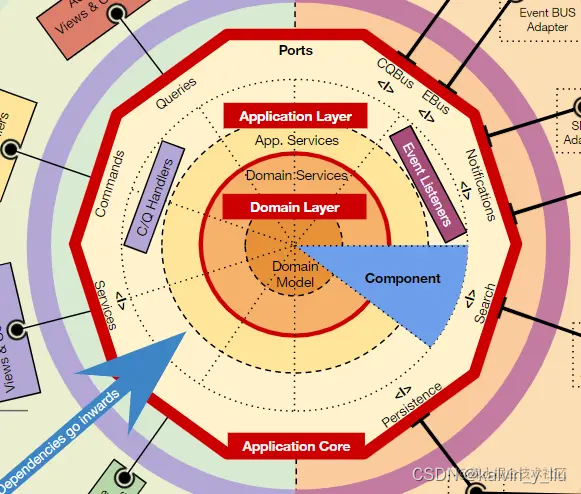
Wie Sie sehen können, befindet sich in der Mitte das Domänenmodell und dann der Domänendienst. Zusammen bilden diese beiden Ringe die Domänenschicht. Die äußere Schicht ist die Anwendungsschicht, die auch zwei Ringe umfasst, das Innere sind App Services und das Äußere sind C/Q-Prozessoren, Ereignis-Listener usw.
Dann raus, ist der Application Core in einen großen roten Umriss gehüllt. Diese Ebene definiert viele Schnittstellen (oder Ports), z. B. Persistenz, Dienste von Drittanbietern, Suche, CQ-Bus, Ereignisbus und so weiter. Natürlich gehen auch Bearbeitungsbefehle und Anfragen ein.
Nachdenken, die Probleme, auf die ich gestoßen bin
Im vorherigen DDD-Projekt bin ich auf einige Probleme im taktischen Modus gestoßen, und jetzt schaue ich zurück und denke darüber nach.
Wann genau wird ein Domain-Service benötigt?
Es lässt sich in einem Satz zusammenfassen: Wenn man nur das Domänenmodell verwendet, geht das nicht. Beide befinden sich auf der Domänenebene, und jeder verlässt sich nicht auf externe Dinge.Unter welchen Umständen kann das Domänenmodell dies nicht tun, aber der Domänendienst kann es tun?
Ein sehr häufiges Szenario ist die Verwendung von Geschäftslogik beim Erstellen eines Modells. Obwohl das Erstellungsmodell normalerweise in der Factory platziert wird, ist es nicht für die Geschäftslogik in der Factory geeignet. Zu diesem Zeitpunkt wurde das Domänenmodell noch nicht erstellt, sodass es nur im Domänendienst platziert werden kann.
Natürlich besteht die beste Vorgehensweise von DDD darin, die Domänendienstschicht so weit wie möglich zu eliminieren, und alle sind in der Modellschicht kohäsiv, aber es ist schwierig, diese perfekte Situation zu erreichen.
Was soll ich tun, wenn ich andere Daten auf der Anwendungsebene abfragen muss?
Manchmal benötigen wir nicht nur die Daten der aktuellen Aggregatwurzel, sondern auch andere Daten. Natürlich kann diese Leseoperation nicht auf der Domänenebene durchgeführt werden und wird normalerweise auf der Anwendungsebene platziert. Aber die Anwendungsschicht ist normalerweise ein aggregierter Stamm, der einem ApplicationService entspricht.Der normale Prozess besteht darin, die Repository-Schnittstelle aufzurufen, um einDomänenmodellobjekt zu erhalten, dann damit zu arbeiten und es dann wieder in derDatenbank zu speichern.
Was also, wenn Sie andere Daten benötigen? Insbesondere Daten, die möglicherweise nicht für das aktuelle Domänenmodell relevant sind, wie z. B. "Zeitpunkt des letzten Kommentars".
Die vorherige Lösung unseres Teams war die Verwendung einer Abfrage. Die Aufgabe der Abfrage besteht darin, die Datenbank abzufragen, und sie kann einige Felder abfragen. Damit es aber nicht missbraucht wird, legt das Team fest, dass es nur zum "Lesen zum Schreiben" im repsenter- oder applicationService verwendet werden darf.
Rückblickend auf die saubere Architektur ist die Abfrage hier eigentlich der User Case Output Port. Allerdings führten weder Repository noch Query unseres Teams zu diesem Zeitpunkt eine abstrakte Verarbeitung durch, das heißt, es gab keine Abhängigkeitsumkehrung, sodass sich die ApplicationService-Schicht auf sie stützte, was nicht mit der „Einwegabhängigkeit“ der saubere Architektur, die Übertragung ist besser.
Wann sollten Domänenereignisse gesendet und empfangen werden?
Dies ist auch ein kontroverser Punkt. Sehen Sie sich zuerst an, wann Domänenereignisse erstellt werden. Einige Leute denken, dass sie auf der Domänenebene erstellt werden sollten, während andere der Meinung sind, dass sie auf der Anwendungsebene erstellt werden sollten. Persönlich denke ich, dass es besser ist, auf Domänenebene zu erstellen, da das Erstellen eines Domänenereignisses eigentlich eine Art Geschäftslogik ist, und wenn Sie nur ein Domänenereignis erstellen, hängt es nicht von externen Dingen ab, und es gibt kein Problem bei der Platzierung auf der Domänenebene.
Wann also Domänenereignisse senden? Nach den Regeln der sauberen Architektur sollte es nicht auf der Domänenschicht gesendet werden, da der Ereignisbus (oder die Implementierung des Ereignissenders) auf der äußersten Schicht liegt.Wenn es auf der Domänenschicht gesendet wird, besteht jedoch eine Abhängigkeit Inversion, es fühlt sich an, als würde es zu viele Ebenen umfassen, nein. Eine gute Übung.
Es ist eine bessere Lösung, Ereignisse auf der Anwendungsebene zu senden. Der vorherige Plan unseres Teams war ziemlich seltsam und wurde in die Implementierung von Repository geschickt. Ich habe irgendwie vergessen, warum ich das damals gemacht habe, aber jetzt scheint es angemessener zu sein, es auf der Anwendungsebene zu tun.
Für den Ereignisempfang, wie in der obigen Abbildung gezeigt, ist es besser, ihn in die Anwendungsschicht (aber außerhalb von App Services) zu legen. Anschließend können Sie die Geschäftslogik über ApplicationService vervollständigen.
Transaktionsprobleme über aggregierte Wurzeln hinweg?
Tatsächlich ist es schwierig, eine stark konsistente Transaktion zu garantieren, da die Ereigniskommunikation über aggregierte Wurzeln hinweg verwendet werden sollte, aber es gibt viele Möglichkeiten, Ereignisse zu implementieren.Wenn sie asynchron ist, kann sie keine stark konsistente Transaktion garantieren. Wir können nur mit einigen technischen Mitteln versuchen, die endgültige Konsistenz sicherzustellen.
Wie kann sichergestellt werden, dass die Struktur nicht beschädigt wird?
Nach bisheriger Praxiserfahrung dürfte die Codestruktur im Laufe der Zeit verfallen. Beispielsweise ist die zuvor erwähnte Abfrage ein Beispiel, und es muss zwischen einigen Teams „Konsens“ bestehen, um sicherzustellen, dass sie nicht missbraucht wird. Wir können nicht garantieren, dass der Code überhaupt nicht beschädigt wird, aber wir können einige Mittel anwenden, um sicherzustellen, dass die Abhängigkeitsebene nicht beschädigt wird.
Es wird empfohlen, Maven/Gradle-Modularisierung zu verwenden, da es Abhängigkeiten zwischen Modulen gibt, solange wir die abhängige Konfiguration nicht ändern, ist sie immer einseitig abhängig. Insbesondere können wir die Schichten über der sauberen Architektur in Module aufteilen und dann ihre Abhängigkeiten in der Konfigurationsdatei definieren. Zum Beispiel hängen Anwendungsschichtmodule von Domänenschichtmodulen ab, Schnittstellen- und Anpassungsschichtmodule hängen von Anwendungsschichtmodulen und Domänenschichtmodulen ab.
Das ewige Problem: die Definition einer geeigneten Aggregatwurzel
Abschließend werde ich über ein schwierigeres Problem sprechen, das darin besteht, die Aggregatwurzel zu finden. Tatsächlich denken Sie vielleicht, dass das Definieren eines aggregierten Stamms sehr einfach sein sollte, basierend auf dem Geschäft, wie z. B. Benutzern, Bestellungen, Waren, Inventar und so weiter. Aber manchmal fällt es uns leicht, die Aggregatwurzel sehr groß zu definieren, denn egal wie groß die Aggregatwurzel ist, sie lässt sich gut erklären. Es gibt einen Witz in der Modellierungswelt: Ich definiere eine "Universumsklasse", die alle Modelle enthalten kann.
Wenn der aggregierte Stamm zu groß ist, können Probleme wie zu viel Code, zu viele Testfälle, schlechte Leistung usw. auftreten. Es ist sehr wahrscheinlich, dass sich eine aggregierte Wurzel dabei ausdehnt Wenn Sie zu diesem Zeitpunkt versuchen, sie zu spalten, werden Sie feststellen, dass es nicht unmöglich ist, sie wie das erste Phänomen zu spalten. Es geht nur darum, eine passende "Ausrede" zu finden und diese mit Rechtfertigung zu demontieren. Aber alles in allem ist es ein harter Job.
Autor: Programm zusammengestellt
Link: https://juejin.cn/post/6887366391675289608
Quelle: Rare Earth Nuggets
Das Urheberrecht liegt beim Autor. Für den kommerziellen Nachdruck wenden Sie sich bitte zwecks Genehmigung an den Autor, für den nicht kommerziellen Nachdruck geben Sie bitte die Quelle an.
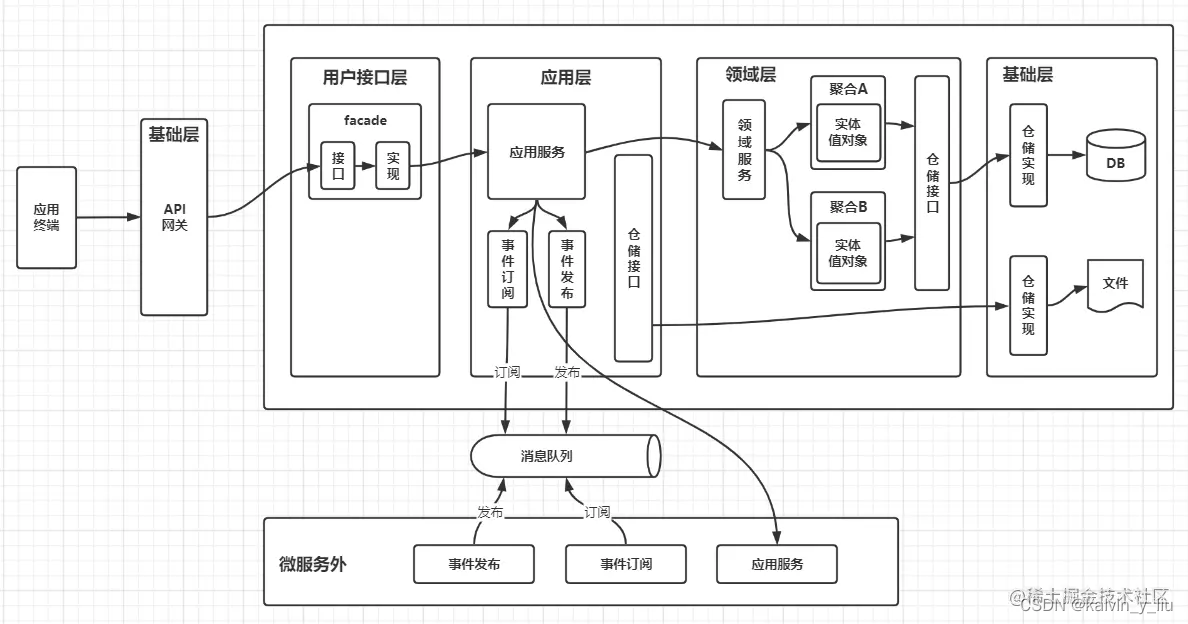
ApplicationService muss den folgenden Prinzipien folgen:
Eins-zu-Eins-Entsprechung zwischen Geschäftsmethoden und Geschäftsanwendungsfällen: Es wurde oben erwähnt, daher werde ich es nicht wiederholen.
Eins-zu-eins-Korrespondenz zwischen Geschäftsmethoden und Transaktionen: Das heißt, jede Geschäftsmethode stellt eine unabhängige Transaktionsgrenze dar. In diesem Beispiel ist die OrderApplicationService.changeProductCount()-Methode mit der @Transactional-Anmerkung von Spring markiert, was darauf hinweist, dass die gesamte Methode gekapselt ist in eine Transaktion.
Sie sollte keine Geschäftslogik selbst enthalten: Die Geschäftslogik sollte im Domänenmodell implementiert werden, genauer gesagt im aggregierten Stamm.In diesem Beispiel ist die Methode order.changeProductCount() dort, wo die Geschäftslogik tatsächlich implementiert ist, und ApplicationService ruft nur auf die Methode order.changeProductCount() als Proxy, daher sollte ApplicationService eine sehr dünne Schicht sein.
Es hat nichts mit UI oder Kommunikationsprotokollen zu tun: Die Positionierung von ApplicationService ist nicht die Fassade des gesamten Softwaresystems, sondern die Fassade des Domänenmodells, was bedeutet, dass sich ApplicationService nicht mit technischen Details wie UI-Interaktion oder Kommunikationsprotokollen befassen sollte . In diesem Beispiel ist der Controller als Aufrufer von ApplicationService für die Verarbeitung des Kommunikationsprotokolls (HTTP) und die direkte Interaktion mit dem Client verantwortlich. Diese Verarbeitungsmethode macht ApplicationService universell, d. h. unabhängig davon, ob der letzte Aufrufer ein HTTP-Client, ein RPC-Client oder sogar eine Main-Funktion ist, auf das Domänenmodell kann nur über ApplicationService zugegriffen werden.
Akzeptieren Sie den ursprünglichen Datentyp: ApplicationService ist der Aufrufer des Domänenmodells, und die Implementierungsdetails des Domänenmodells sollten eine Blackbox dafür sein, sodass ApplicationService nicht auf die Objekte im Domänenmodell verweisen sollte. Außerdem dienen die von ApplicationService akzeptierten Daten im Anforderungsobjekt nur zur Beschreibung der Geschäftsanforderung selbst und sollten unter der Bedingung der Erfüllung der Geschäftsanforderungen so einfach wie möglich sein. Daher verarbeitet ApplicationService normalerweise einige primitive Datentypen. In diesem Beispiel ist die von OrderApplicationService akzeptierte Bestell-ID der ursprüngliche Java-String-Typ und wird beim Aufrufen des Repositorys im Domänenmodell als OrderId-Objekt gekapselt.
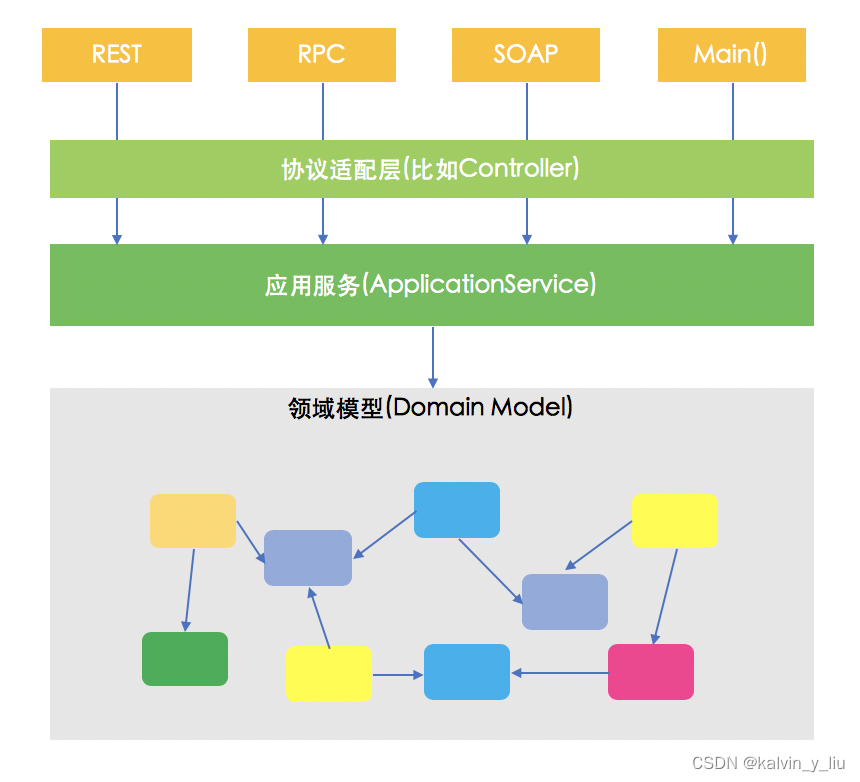
Das einfache Prinzip der ACL-Korrosionsschutzschicht ist wie folgt:
Für abhängige externe Objekte extrahieren wir die erforderlichen Felder und generieren eine intern erforderliche VO- oder DTO-Klasse.
Erstellen Sie eine neue Fassade, kapseln Sie den Anruflink in der Fassade und konvertieren Sie die externe Klasse in eine interne Klasse.
Verwenden Sie für externe Systemaufrufe auch die Facade-Methode, um den externen Aufruflink zu kapseln.
Gehäuse ohne Korrosionsschutzschicht:

Sagen Sie mir, wie lösen Sie das Transaktionsproblem in einem verteilten Szenario?
Die Anwendungsschicht verbindet die Benutzerschnittstellenschicht und die Domänenschicht und koordiniert hauptsächlich die Domänenschicht. Sie orientiert sich an Anwendungsfällen und Geschäftsprozessen und koordiniert mehrere Aggregationen, um die Kombination und Orchestrierung von Diensten zu vervollständigen. Sie implementiert keine Geschäftslogik an dieser Schicht, sondern ist nur eine sehr dünne Schicht.
Die Kernklassen der Anwendungsschicht:
ApplicationService-Anwendungsdienst: Die Kernklasse, die für die Orchestrierung von Geschäftsprozessen verantwortlich ist, aber nicht für die Geschäftslogik selbst verantwortlich ist. Manchmal als "AppService" abgekürzt. Eine ApplicationService-Klasse ist ein vollständiger Geschäftsprozess, bei dem jede Methode für die Bearbeitung eines Anwendungsfalls zuständig ist, beispielsweise verschiedener Anwendungsfälle der Bestellung (Bestellung, Zahlungserfolg, Lieferung, Empfang, Abfrage).
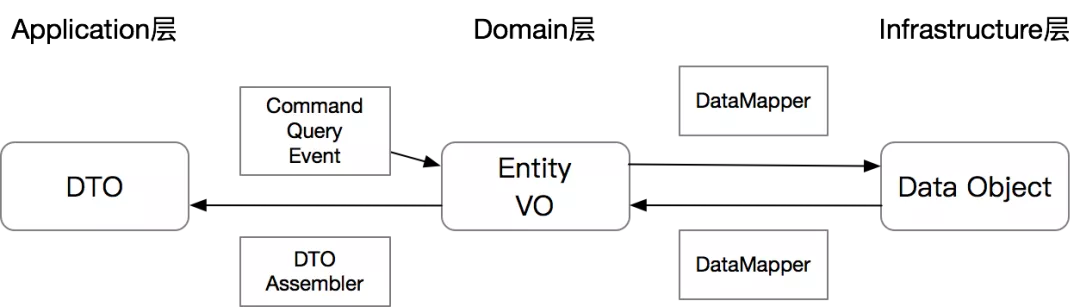
DTO-Assembler: Verantwortlich für die Konvertierung des internen Domänenmodells in ein externes DTO.
Zurückgegebenes DTO: als Ausgabeparameter von ApplicationService.
Befehlsanweisung: bezieht sich auf die Anweisung, dass der Aufrufer eindeutig möchte, dass das System arbeitet, und seine Erwartung darin besteht, eine Auswirkung auf ein System zu haben, d. h. eine Schreiboperation. Normalerweise müssen Befehle einen expliziten Rückgabewert haben (z. B. das Ergebnis einer synchronen Operation oder ein asynchroner Befehl wurde akzeptiert).
Abfrage Abfrage: bezieht sich auf die Dinge, die der Aufrufer eindeutig abfragen möchte, einschließlich Abfrageparameter, Filterung, Paging und andere Bedingungen, von denen erwartet wird, dass sie überhaupt keine Auswirkungen auf die Daten eines Systems haben, dh Nur-Lese-Operationen.
Ereignisereignis: bezieht sich auf eine vorhandene Tatsache, die bereits eingetreten ist und das System entsprechend dieser Tatsache ändern oder reagieren muss.Normalerweise hat die Ereignisverarbeitung bestimmte Schreiboperationen. Event-Handler haben keinen Rückgabewert. Anzumerken ist hier, dass das Event-Konzept des Application-Layers dem DomainEvent des Domain-Layers ähnlich ist, aber nicht unbedingt dasselbe ist, sondern das Event hier eher ein externer Benachrichtigungsmechanismus ist.
Der Schnittstelleneingabeparameter von ApplicationService kann nur ein Command-, Query- oder Event-Objekt sein, und das CQE-Objekt muss die Semantik der aktuellen Methode darstellen. Der Vorteil davon ist, dass es die Stabilität der Schnittstelle verbessert, Wiederholungen auf niedriger Ebene reduziert und Schnittstelleneingaben semantischer macht.
Die Domänenschicht ist der Kern des Domänenmodells, das hauptsächlich die zentrale Geschäftslogik des Domänenmodells implementiert und die Geschäftsfähigkeiten des Domänenmodells widerspiegelt. Die Domänenschicht konzentriert sich auf die Implementierung des Hyperemia-Modells von Domänenobjekten und der atomaren Geschäftslogik der Aggregation selbst. Benutzeroperationen und Geschäftsprozesse werden zur Orchestrierung an die Anwendungsschicht übergeben. Dieses Design kann sicherstellen, dass das Domänenmodell nicht leicht durch Änderungen in externen Anforderungen beeinflusst wird, und die Stabilität des Domänenmodells gewährleisten.
Die Kernklassen der Domänenschicht:
Entitätsklasse (Entity): Der Kern der meisten DDD-Architekturen ist die Entitätsklasse, die den Zustand in einer Domäne und direkte Operationen auf dem Zustand enthält. Das wichtigste Designprinzip von Entity besteht darin, die Invarianten der Entität (Invarianten) sicherzustellen, d. h. sicherzustellen, dass unabhängig davon, wie die externe Operation ausgeführt wird, die internen Attribute einer Entität nicht miteinander und mit dem Zustand in Konflikt geraten können ist inkonsistent.
Wertobjekt (VO): Wird normalerweise verwendet, um Dinge zu messen und zu beschreiben. Wir können es sehr einfach erstellen, testen, verwenden, optimieren und warten, daher versuchen wir beim Modellieren, Wertobjekte zum Modellieren zu verwenden.
Aggregatstamm (Aggr): Die Aggregation besteht aus Entitäten und Wertobjekten, die eng mit Geschäft und Logik verbunden sind. Die Aggregation ist die Grundeinheit der Datenänderung und -persistenz. Jedes Aggregat hat eine Root-Entität, die Aggregat-Root genannt wird, und die Außenwelt kann nur über die Aggregat-Root mit dem Aggregat kommunizieren. Der Hauptzweck des Aggregatstamms besteht darin, das Problem der Dateninkonsistenz zwischen Aggregation und Entitäten aufgrund des Fehlens einer einheitlichen Geschäftsregelsteuerung im komplexen Datenmodell zu vermeiden.
Domänendienst: Wenn eine Operation nicht für Aggregations- und Wertobjekte geeignet ist, ist der beste Weg die Verwendung von Domänendiensten. Wo Domänendienste verwendet werden können, führt eine übermäßige Verwendung von Domänendiensten zu einem anämischen Domänenmodell. Führen Sie einen wichtigen Geschäftsbetriebsprozess aus, transformieren Sie Domänenobjekte, führen Sie Berechnungen mit mehreren Domänenobjekten als Eingabe durch und generieren Sie als Ergebnis ein Wertobjekt.
Repository-Layer-Schnittstelle (Repository): Legen Sie die gewünschten Daten als Sammlung im Repository ab und erhalten Sie sie direkt, wenn Sie sie möchten. Als verbindende Komponente zwischen der Domänenschicht und der Infrastrukturschicht macht es der Speicher für die Domänenschicht unnötig, den Speicherdetails zu viel Aufmerksamkeit zu schenken. Beim Entwerfen wird die Warehouse-Schnittstelle auf der Domänenschicht und die spezifische Implementierung des Warehouses auf der Infrastrukturschicht platziert.Die Domänenschicht greift über die Schnittstelle auf die Datenspeicherung zu, ohne den Details der Warehouse-Speicherung zu viel Aufmerksamkeit zu schenken Daten, so dass die Domänenschicht mehr sein wird. Der Schwerpunkt liegt hauptsächlich auf der Domänenlogik.
Fabrik (Fabrik): Objekte wie Entitäten, die umständlich zu konstruieren sind, können mit Hilfe von Fabriken konstruiert werden.
Autor: Lord Wolf
Link: https://juejin.cn/post/7040826223500967972
Quelle: Rare Earth Nuggets
Das Urheberrecht liegt beim Autor. Für den kommerziellen Nachdruck wenden Sie sich bitte zwecks Genehmigung an den Autor, für den nicht kommerziellen Nachdruck geben Sie bitte die Quelle an.