Índice
1. Resumo
Se você comparar um modelo de linguagem bidirecional baseado no Transformer (como o modelo de linguagem mascarada no modelo BERT) com um modelo de linguagem autorregressivo unidirecional (como o decodificador do modelo BART), poderá descobrir que a diferença entre os dois é principalmente que o modelo pode usar Qual parte da informação na sequência realiza o cálculo da representação da camada oculta em cada momento. Para um Transformer de duas vias, o cálculo da camada oculta em cada momento pode usar qualquer palavra da sequência; para um Transformer de uma via, apenas a palavra informações no momento atual e "histórico" podem ser usadas. Com base nessa ideia, os pesquisadores propuseram
um modelo de linguagem unificado
( Unified LanguageModel, UniLM ) com uma estrutura Transformer unidirecional.
Diferente da estrutura do codificador-decodificador do modelo BART, o UniLM precisa apenas usar uma rede Transformer para concluir o pré-treinamento de representação de linguagem e geração de texto ao mesmo tempo e, em seguida, aplicá-lo a tarefas de compreensão de linguagem e tarefas de geração de texto por meio de ajuste fino do modelo. Sua ideia central é controlar o alcance de atenção de cada palavra usando diferentes matrizes de máscara de auto-atenção, de modo a realizar o controle do fluxo de informações por diferentes modelos de linguagem.
2. Expansão em profundidade
2.1 Tarefa pré-treinamento
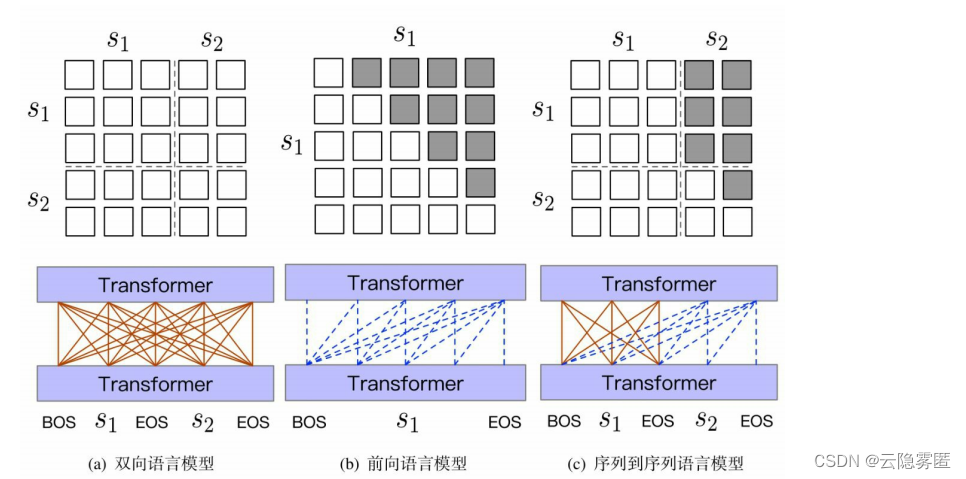
O modelo UniLM fornece uma estrutura unificada para pré-treinamento com modelos de linguagem bidirecionais, modelos de linguagem unidirecionais e modelos de linguagem sequência a sequência. Entre eles, o pré-treinamento baseado no modelo de linguagem bidirecional permite que o modelo tenha a capacidade de representação de linguagem, o que é adequado para tarefas posteriores de compreensão da linguagem; enquanto as tarefas de pré-treinamento baseadas no modelo de linguagem unidirecional e no modelo de linguagem sequência a sequência permitem que o modelo tenha a capacidade de geração de texto. A figura abaixo mostra os padrões de máscara de autoatenção correspondentes a diferentes tarefas de pré-treinamento .
Assumindo que a matriz de auto-atenção do transformador de camada L é AL, em UniLM, AL pode ser calculado pela seguinte fórmula
:
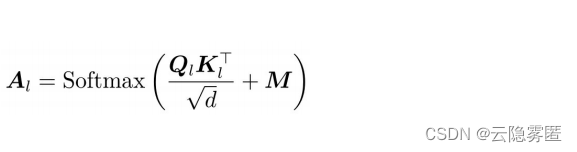
Na fórmula, QL e KL são respectivamente o vetor correspondente à consulta e a chave obtida pela representação do contexto da L-ésima camada após o mapeamento linear: d é a dimensão do vetor. O UniLM adiciona uma matriz de máscara M ∈ R (dimensão: n x n) com base na fórmula de cálculo de auto-atenção original, n é o comprimento da sequência de entrada, M é uma matriz constante, definida da seguinte forma
:

Ao controlar M, diferentes tarefas de pré-treino podem ser realizadas.
(1) Modelo de linguagem bidirecional . A sequência de entrada consiste em dois fragmentos de texto, separados por um token especial [EOS]. Semelhante ao modelo BERT, algumas palavras são amostradas aleatoriamente no texto de entrada e substituídas por tags [MASK] com uma certa probabilidade e, finalmente, a palavra correta é prevista na posição correspondente da camada de saída. Nesta tarefa, quaisquer duas palavras na sequência são "visíveis" uma para a outra e, portanto, podem ser "percebidas" durante o avanço. Refletido no modelo Transformer, é um processo de cálculo de auto-atenção totalmente conectado, conforme mostrado na Figura (a). Neste ponto, nenhuma alteração é feita na matriz original da máscara de auto-atenção, ou seja, M=0.
(2) Modelo de linguagem unidirecional . Inclui modelos de linguagem autorregressivos para frente (da esquerda para a direita) e para trás (da direita para a esquerda). Tome-se como exemplo o modelo de linguagem forward (figura (b)) Para o cálculo da representação da camada oculta em um determinado momento, pode-se utilizar apenas a representação do contexto no momento atual e sua esquerda (camada anterior). A distribuição de auto-atenção correspondente é uma matriz triangular, com cinza representando um valor de atenção de 0. Correspondentemente, o valor da matriz de máscara M na área cinza é infinito negativo (−∞).
(3) Modelo de linguagem sequência a sequência . Usando a matriz de máscara, o modelo de linguagem sequência a sequência também pode ser convenientemente implementado e, em seguida, aplicado à tarefa de geração condicional. Neste ponto, a sequência de entrada consiste em dois fragmentos de texto que servem como condição e o texto de destino (a ser gerado), respectivamente. As palavras no segmento de texto condicional são "visíveis" umas às outras, então a autoatenção totalmente conectada é usada; para o segmento de texto de destino, ela é gerada palavra por palavra de maneira auto-regressiva. A cada momento, todas as representações contextuais no texto condicional pode ser usado. E parte da representação de contexto esquerda que foi gerada, conforme mostrado na Figura (c). Na literatura relacionada, essa estrutura também é chamada de modelo de linguagem de prefixo (PrefixLM)
.
Diferente da estrutura do codificador-decodificador do modelo BART, as partes de codificação e decodificação aqui compartilham o mesmo conjunto de parâmetros , e o mecanismo de atenção cruzada entre o texto condicional e o texto condicional também é diferente no processo de geração autorregressiva.
2.2 Ajuste fino do modelo
(1) Tarefas de classificação . Para tarefas de classificação, o método de ajuste fino do UniLM é semelhante ao do BERT. Aqui, um codificador Transformer bidirecional (M = 0) é usado e a última representação da camada oculta na primeira marca [BOS] da sequência de entrada é usada como a representação do texto, que é inserido no classificador de destino e, em seguida, o rótulo da tarefa de destino é usado Parâmetros do modelo de ajuste fino de dados.
(2) Gerar tarefas . Para a tarefa generativa, as palavras no fragmento de texto de destino são amostradas aleatoriamente e substituídas por tokens [MASK], e o objetivo de aprendizado do processo de ajuste fino é recuperar essas palavras substituídas. Vale a pena notar que o token [EOS] no final da sequência de entrada também é substituído aleatoriamente, permitindo que o modelo aprenda quando parar de gerar.