1. Modelo de fila de mensagens
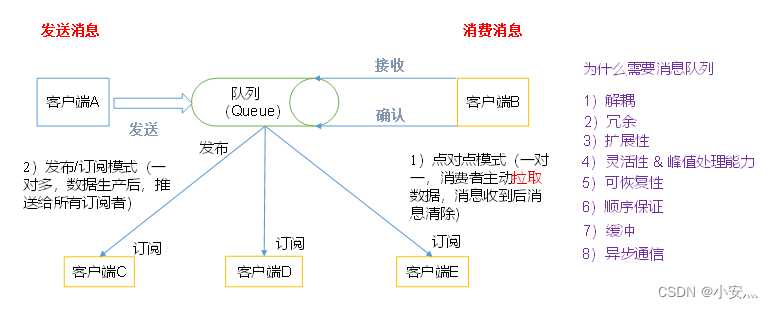
- Modo ponto a ponto
(um para um, os consumidores extraem dados ativamente e a mensagem é apagada após o recebimento da mensagem). O modelo ponto a ponto geralmente é um modelo de mensagens baseado em pull ou polling. Este modelo solicita informações da fila em vez de enviar mensagens Push para o cliente. A característica deste modelo é que a mensagem enviada para a fila é recebida e processada por um e apenas um receptor, mesmo que existam vários ouvintes de mensagens. - O modelo de publicação/assinatura
(um para muitos, após a produção de dados, push para todos os assinantes)
é um modelo de mensagens baseado em push. O modelo de publicação-assinatura pode ter muitos assinantes diferentes: assinantes temporários só recebem mensagens quando estão ouvindo ativamente o tópico, enquanto assinantes duráveis ouvem todas as mensagens do tópico, mesmo que o assinante atual esteja indisponível e offline.
2. Cenários de uso da fila de mensagens
-
Desacoplamento:
permite estender ou modificar o processamento em ambos os lados de forma independente, desde que respeitem as mesmas restrições de interface. -
Redundância:
As filas de mensagens persistem os dados até que sejam totalmente processados, evitando assim o risco de perda de dados. No paradigma "inserir-obter-excluir" adotado por muitas filas de mensagens, antes de excluir uma mensagem da fila, você precisa que seu sistema de processamento indique claramente que a mensagem foi processada, para garantir que seus dados sejam salvos com segurança. até terminar de usá-lo. -
Escalabilidade:
como a fila de mensagens desacopla seu processamento, é fácil aumentar a frequência de enfileiramento e processamento de mensagens, desde que processamento adicional seja adicionado. -
Flexibilidade e capacidade de processamento de pico:
No caso de um aumento acentuado no tráfego, o aplicativo ainda precisa continuar funcionando, mas esse tráfego intermitente não é comum. Sem dúvida, é um grande desperdício investir recursos em modo de espera o tempo todo para lidar com esses picos de acesso. O uso de filas de mensagens pode permitir que os principais componentes resistam à pressão de acesso repentina sem travar completamente devido a solicitações de sobrecarga repentinas. -
Recuperabilidade:
A falha de uma parte do sistema não afeta todo o sistema. A fila de mensagens reduz o acoplamento entre processos, portanto, mesmo que um processo que processa mensagens seja interrompido, as mensagens adicionadas à fila ainda poderão ser processadas após a recuperação do sistema. -
Garantia de ordem:
na maioria dos cenários de uso, a ordem do processamento de dados é importante. A maioria das filas de mensagens é classificada inerentemente e pode garantir que os dados sejam processados em uma ordem específica. (Kafka garante a ordem das mensagens em uma partição) -
Buffering:
ajuda a controlar e otimizar a velocidade do fluxo de dados pelo sistema, além de resolver a inconsistência na velocidade de processamento das mensagens de produção e mensagens de consumo. -
Comunicação assíncrona:
Muitas vezes, os usuários não querem ou não precisam processar as mensagens imediatamente. As filas de mensagens fornecem um mecanismo de processamento assíncrono que permite aos usuários colocar uma mensagem em uma fila sem processá-la imediatamente. Coloque quantas mensagens quiser na fila e processe-as quando necessário.
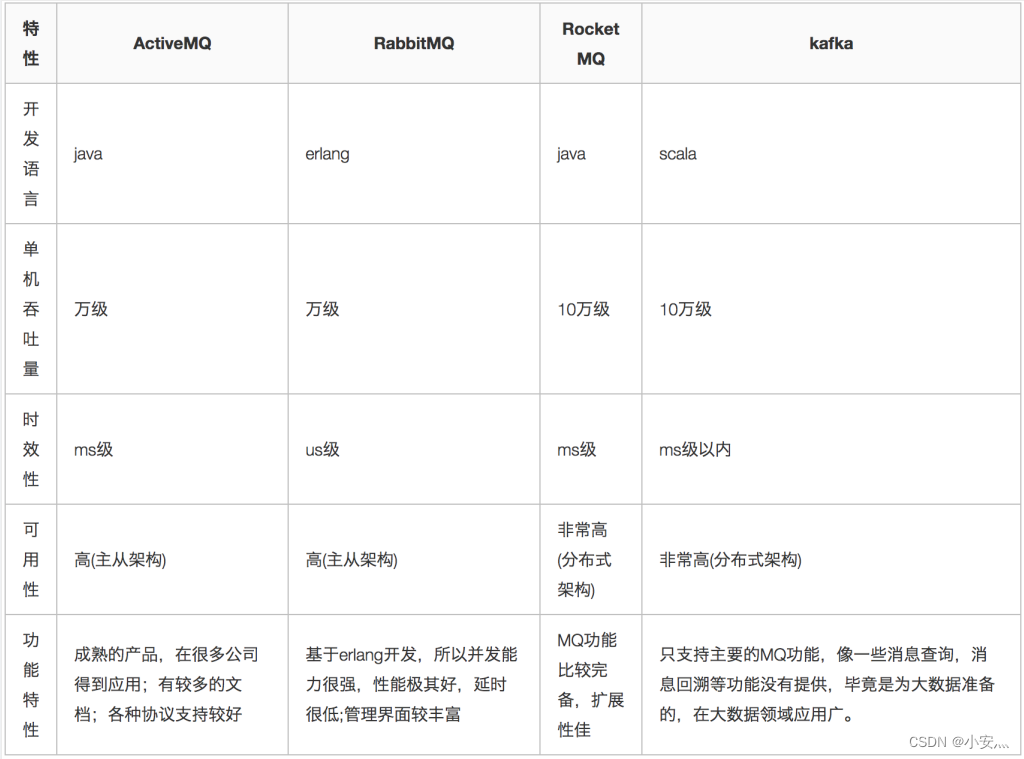
3. Comparação da fila de mensagens
4. Arquitetura da fila de mensagens
4.1, Kafka
-
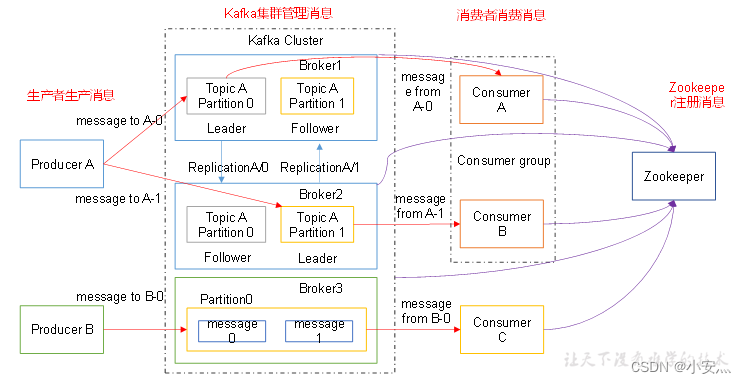
Produtor : O produtor da mensagem é o cliente que envia mensagens para o intermediário kafka;
-
Consumer : consumidor da mensagem, o cliente que busca as mensagens do kafka broker;
-
Tópico : Pode ser entendido como uma fila;
-
Grupo de consumidores (CG) : Este é o método usado pelo Kafka para transmitir (enviar a todos os consumidores) e unicast (enviar a qualquer consumidor) uma mensagem de tópico. Um tópico pode ter vários CGs. A mensagem do tópico será copiada (não realmente copiada, mas conceitualmente) para todos os CGs, mas cada parte enviará a mensagem apenas para um consumidor no CG. Se precisar implementar broadcasting, desde que cada consumidor tenha um CG independente. Para obter unicast desde que todos os consumidores estejam no mesmo CG. Com CG, os consumidores também podem ser agrupados livremente sem enviar mensagens para diferentes tópicos várias vezes;
-
Corretor : Um servidor kafka é um corretor. Um cluster consiste em vários agentes. Um corretor pode acomodar vários tópicos;
-
Partição : Para obter escalabilidade, um tópico muito grande pode ser distribuído para vários intermediários (ou seja, servidores), um tópico pode ser dividido em várias partições e cada partição é uma fila ordenada. A cada mensagem na partição será atribuído um id ordenado (deslocamento). Kafka garante apenas o envio de mensagens aos consumidores na ordem de uma partição e não garante a ordem de um tópico como um todo (entre várias partições);
-
Offset : os arquivos de armazenamento do Kafka são nomeados de acordo com offset.kafka. A vantagem de usar offset como um nome é que é fácil de encontrar. Por exemplo, se você deseja encontrar a localização em 2049, basta encontrar o arquivo 2048.kafka. Claro que o primeiro deslocamento é 00000000000.kafka.
4.、RocketMQ
-
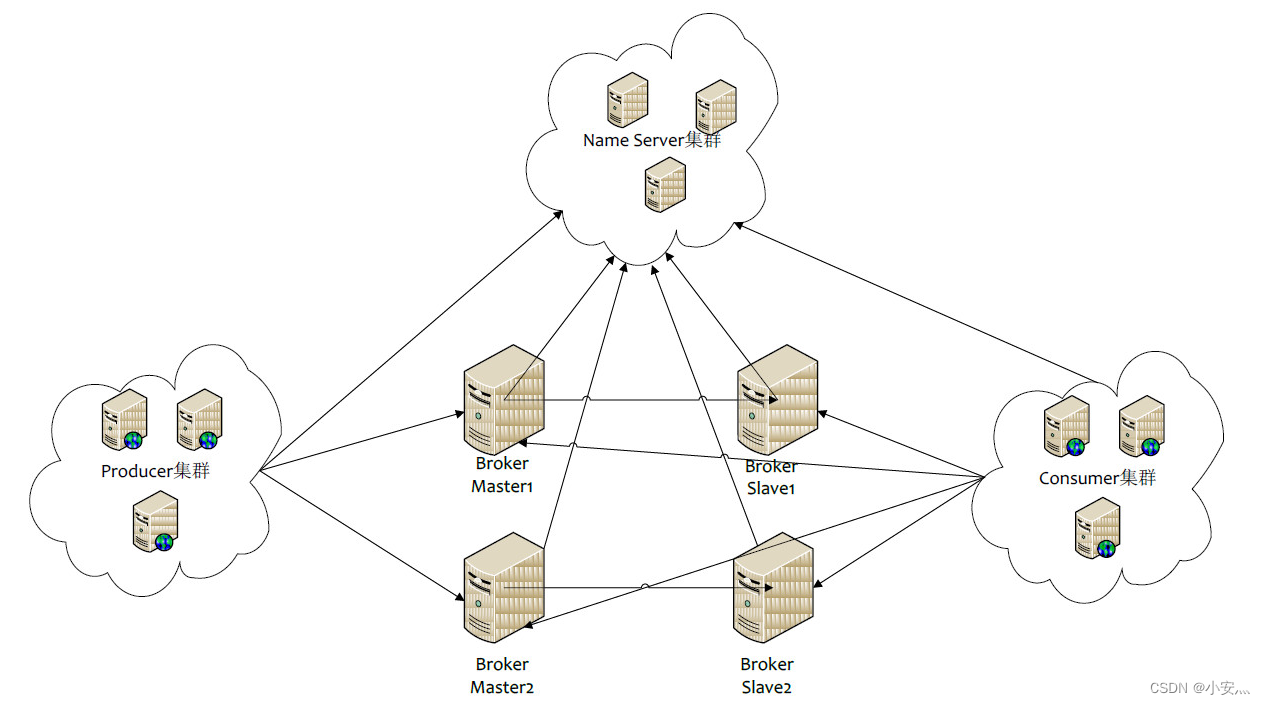
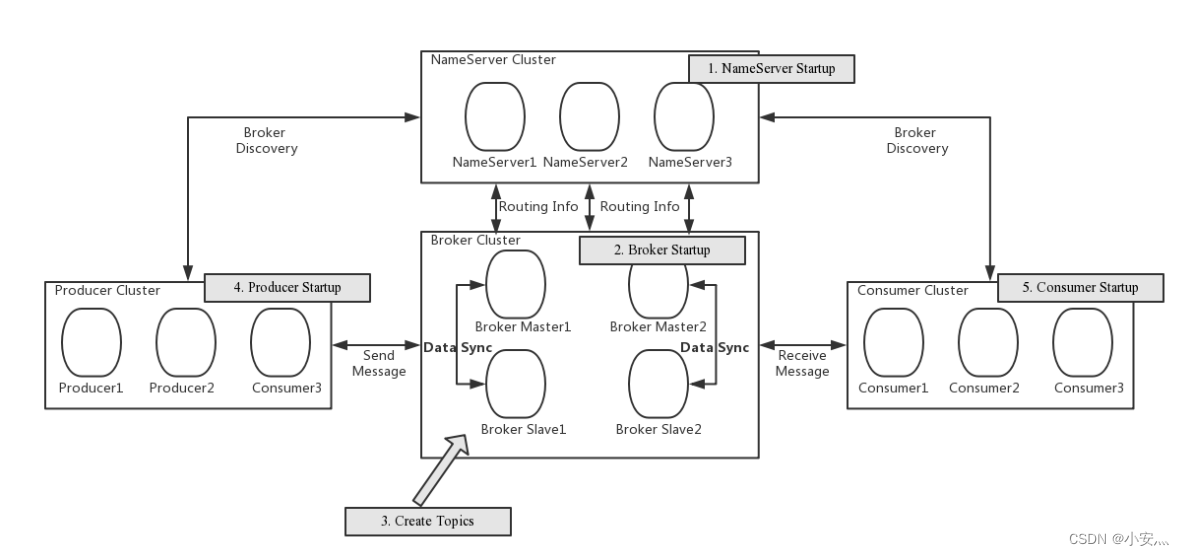
NameServer : É um nó quase sem estado que pode ser implantado em um cluster sem nenhuma sincronização de informações entre os nós.
-
Broker : A implantação do Broker é relativamente complicada. O Broker é dividido em Master e Slave. Um Master pode corresponder a vários Slaves, mas um Slave pode corresponder apenas a um Master. A relação correspondente entre Master e Slave é definida especificando o mesmo BrokerName e diferentes BrokerId. BrokerId 0 significa Mestre, diferente de zero significa Escravo. O mestre também pode implantar vários. Cada Broker estabelece uma conexão persistente com todos os nós no cluster NameServer e registra regularmente as informações do tópico para todos os NameServers.
-
Produtor : O produtor estabelece uma conexão longa com um dos nós no cluster NameServer (selecionado aleatoriamente), busca periodicamente informações de roteamento de tópico do NameServer, estabelece uma conexão longa com o mestre que fornece serviços de tópico e envia pulsações ao mestre regularmente. O produtor é completamente sem estado e pode ser implantado em clusters.
-
Consumidor : o consumidor estabelece uma conexão de longo prazo com um dos nós no cluster NameServer (selecionado aleatoriamente), busca regularmente informações de roteamento de tópico do NameServer, estabelece uma conexão de longo prazo com o mestre e o escravo que fornecem serviços de tópico e envia pulsações para Mestre e Escravo regularmente. Os consumidores podem assinar as mensagens do Mestre ou do Escravo, e as regras de assinatura são determinadas pela configuração do Broker.
5. Processo de escrita de dados
5.1, Kafka
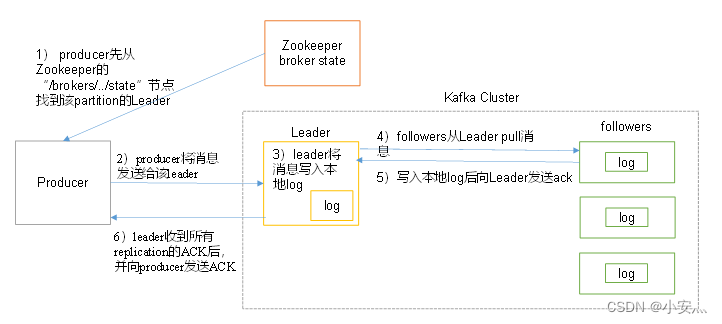
- O produtor primeiro encontra o líder da partição a partir do nó "/brokers/.../state" do zookeeper
- O produtor envia a mensagem ao líder
- O líder grava a mensagem no log local
- Os seguidores extraem mensagens do líder, gravam no log local e enviam ACK para o líder
- Após o líder receber o ACK de todas as replicações no ISR , ele aumenta o HW (high watermark, offset do último commit) e envia o ACK para o produtor
6. Estrutura de armazenamento de dados
6.1, Kafka
6.1.1, corretor
- Divida fisicamente o tópico em uma ou mais áreas
- patition: correspondente à configuração num.partitions=3 em server.properties
- Cada partição corresponde fisicamente a uma pasta (a pasta armazena todas as mensagens e arquivos de índice da partição), conforme segue:
[root@hadoop102 logs]$ ll
drwxrwxr-x. 2 root root 4096 8月 6 14:37 first-0
drwxrwxr-x. 2 root root 4096 8月 6 14:35 first-1
drwxrwxr-x. 2 root root 4096 8月 6 14:37 first-2
[root@hadoop102 logs]$ cd first-0
[root@hadoop102 first-0]$ ll
-rw-rw-r--. 1 root root 10485760 8月 6 14:33 00000000000000000000.index
-rw-rw-r--. 1 root root 219 8月 6 15:07 00000000000000000000.log
-rw-rw-r--. 1 root root 10485756 8月 6 14:33 00000000000000000000.timeindex
-rw-rw-r--. 1 root root 8 8月 6 14:37 leader-epoch-checkpoint
política de armazenamento
Kafka mantém todas as mensagens independentemente de serem consumidas ou não. Existem duas estratégias para remover dados antigos:
- Com base no tempo: log.retention.hours=168
- Com base no tamanho: log.retention.bytes=1073741824
Deve-se notar que, como a complexidade de tempo do Kafka lendo uma mensagem específica é O(1), ou seja, não tem nada a ver com o tamanho do arquivo, portanto, excluir arquivos expirados aqui não tem nada a ver com melhorar o desempenho do Kafka.
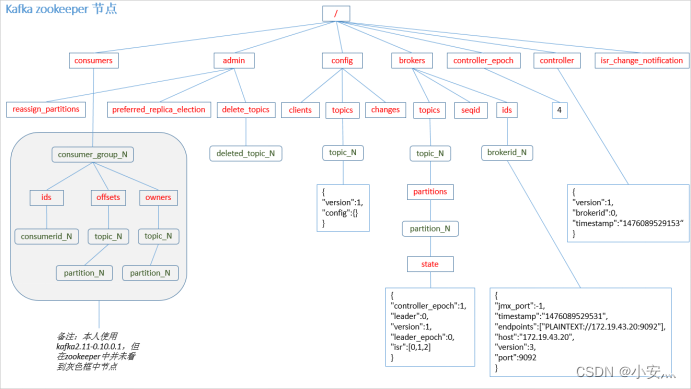
6.1.2, tratador do zoológico
PS: O produtor não está registrado em zk e o consumidor está registrado em zk.
6.2、RocketMQ
- O armazenamento de mensagens RocketMQ é completado pela cooperação de ConsumeQueue e CommitLog.
- CommitLog : é o arquivo de armazenamento físico real da mensagem
- ConsumeQueue : É uma fila lógica de mensagens, semelhante a um arquivo de índice de um banco de dados, que armazena endereços apontando para armazenamento físico.
- Cada Fila de Mensagens em cada Tópico tem um arquivo ConsumeQueue correspondente.

- CommitLog : armazena metadados para mensagens
- ConsumerQueue : Armazena o índice da mensagem no CommitLog
- IndexFile : Fornece um método de consulta de mensagens por chave ou intervalo de tempo para consulta de mensagem. Este método de pesquisa de mensagens por meio de IndexFile não afeta o processo principal de envio e consumo de mensagens
Mecanismo de escova:
- As mensagens do RocketMQ são armazenadas no disco, o que não apenas garante a recuperação após falha de energia, mas também permite que a quantidade de mensagens armazenadas exceda o limite de memória.
- Para melhorar o desempenho, o RocketMQ tentará garantir a gravação sequencial do disco o máximo possível.
- Quando a mensagem é gravada no RocketMQ por meio do Producer, há duas maneiras de gravar no disco, que são síncronas e assíncronas.
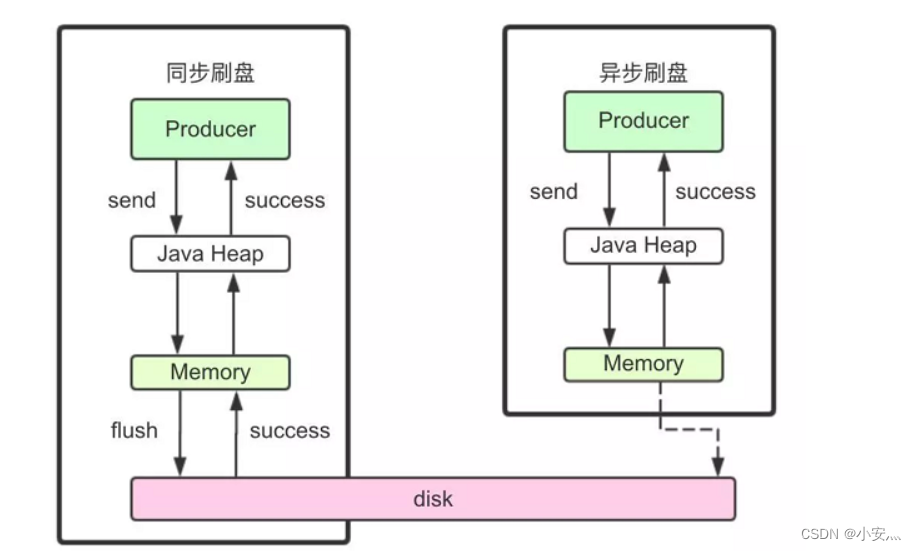
1) Escovação sincronizada
Ao retornar um status de gravação bem-sucedida, a mensagem foi gravada no disco. O processo específico é que, após a mensagem ser gravada no PAGECACHE da memória, o thread para atualizar o disco é imediatamente notificado para liberar o disco e, em seguida, aguardar a conclusão da liberação do disco. concluído, o thread em espera é ativado e o status de gravação da mensagem é retornado com sucesso.
2) Escovação assíncrona
Quando o status de escrita com sucesso é retornado, a mensagem só pode ser escrita no PAGECACHE da memória. O retorno da operação de escrita é rápido e o throughput é grande; quando a quantidade de mensagens na memória acumula até certo nível, o a ação de gravação no disco é acionada uniformemente e gravada rapidamente.
3) Configuração
A liberação do disco de forma síncrona ou assíncrona é definida por meio do parâmetro flushDiskType no arquivo de configuração do Broker.Este parâmetro é configurado como um dos SYNC_FLUSH e ASYNC_FLUSH.
Replicação mestre-escravo de mensagem
Se um grupo Broker tiver um Master e um Slave, as mensagens precisam ser copiadas do Master para o Slave, e existem dois métodos de replicação: síncrona e assíncrona.
1) Replicação síncrona
O método de replicação síncrona é esperar que o mestre e o escravo gravem antes de enviar o status de gravação bem-sucedida ao cliente;
No modo de replicação síncrona, se o mestre falhar, todos os dados de backup no escravo serão facilmente restaurados, mas a replicação síncrona aumentará o atraso na gravação de dados e reduzirá a taxa de transferência do sistema.
2) Replicação assíncrona
O método de replicação assíncrona é que, desde que o mestre grave com êxito, ele pode informar o status de sucesso da gravação para o cliente.
No modo de replicação assíncrona, o sistema tem menor latência e maior throughput, mas se o Master falhar, alguns dados podem ser perdidos porque não foram gravados no Slave;
3) Configuração
A replicação síncrona e a replicação assíncrona são definidas através do parâmetro brokerRole no arquivo de configuração do Broker. Este parâmetro pode ser definido para um dos três valores de ASYNC_MASTER, SYNC_MASTER e SLAVE.
4) Resumo
- Em aplicações práticas, é necessário combinar os cenários de negócios e definir razoavelmente o modo de descarga de disco e o modo de replicação mestre-escravo, especialmente o modo SYNC_FLUSH, que reduzirá significativamente o desempenho devido ao acionamento frequente de ações de gravação de disco.
- Normalmente, o mestre e o escravo devem ser configurados como ASYNC_FLUSH, e o mestre-escravo deve ser configurado como SYNC_MASTER, para que, mesmo que uma máquina falhe, os dados não sejam perdidos, o que é uma boa escolha.