características da transação
A (Atômica): Atomicidade, todas as operações que constituem uma transação são executadas ou não são executadas, sendo impossível ter sucesso parcial e falha parcial.
C (Consistência): Consistência, antes e depois da execução da transação, as restrições de consistência do banco de dados não são quebradas. Por exemplo: Zhang San transfere 100 yuans para Li Si, e os dados antes e depois da transferência estão corretos, o que é chamado de consistência. Se Zhang San transferir 100 yuans, mas a conta de Li Si não aumentar em 100 yuans, haverá um erro de dados. A consistência não foi alcançada.
I (Isolamento): Isolamento. As transações no banco de dados são geralmente simultâneas. Isolamento significa que a execução de duas transações simultâneas não interfere uma na outra. Uma transação não pode ver o estado intermediário de outras transações. Ao configurar o nível de isolamento da transação, problemas como leituras sujas e leituras repetidas podem ser evitados.
D (Durabilidade): Persistência.Depois que a transação for concluída, as alterações feitas nos dados pela transação serão persistidas no banco de dados e não serão revertidas.
Classificação
Transações autônomas : transações de controle por meio de bancos de dados relacionais, que são realizadas usando as características da transação do próprio banco de dados
Transações distribuídas : participantes de transações, servidores de suporte a transações, servidores de recursos e gerenciadores de transações estão localizados em diferentes nós de diferentes sistemas distribuídos e pertencem a diferentes aplicativos.As transações distribuídas precisam garantir que todas essas operações sejam bem-sucedidas ou todas falhem. Em essência, as transações distribuídas são para garantir a consistência dos dados em diferentes bancos de dados.
Teoria da Transação Distribuída
BONÉ
O conteúdo deste teorema refere-se a que em um sistema distribuído, Consistência (consistência), Disponibilidade (disponibilidade) e Tolerância de partição (tolerância a falhas de partição) não podem ser combinados.
Consistência (C)
Se todos os backups de dados em um sistema distribuído têm o mesmo valor ao mesmo tempo. (equivalente a todos os nós acessando a mesma cópia de dados mais recente)
Disponibilidade (A)
Após a falha de alguns nós no cluster, se o cluster como um todo ainda pode responder às solicitações de leitura e gravação do cliente. (alta disponibilidade para atualizações de dados)
Tolerância de partição (P)
Em termos práticos, o particionamento equivale a um requisito de limite de tempo para comunicação. Se o sistema não conseguir obter consistência de dados dentro do limite de tempo, significa que ocorreu uma partição e deve ser feita uma escolha entre C e A para a operação atual
teoria BASE
BASE é um acrônimo para as três frases Basicamente Disponíveis (basicamente disponíveis), Soft state (estado soft) e Eventualmente consistente (consistência final). A teoria BASE é o resultado do trade-off entre consistência e disponibilidade no CAP, vem do resumo da prática distribuída de sistemas de Internet de grande escala e evolui gradualmente com base no teorema CAP. A ideia central da teoria BASE é: Mesmo que uma consistência forte não possa ser alcançada, cada aplicativo pode usar um método apropriado de acordo com suas próprias características de negócios para fazer com que o sistema atinja a consistência final.
basicamente disponível
Disponibilidade básica significa que o sistema distribuído pode perder parte de sua disponibilidade quando ocorrem falhas imprevisíveis - observe que isso não é de forma alguma equivalente à indisponibilidade do sistema. por exemplo:
(1) Perda no tempo de resposta. Em circunstâncias normais, um mecanismo de pesquisa on-line precisa retornar os resultados correspondentes da consulta aos usuários em 0,5 segundo, mas devido a falhas, o tempo de resposta dos resultados da consulta aumenta em 1 a 2 segundos
(2) Perda de funções do sistema: Em circunstâncias normais, ao fazer compras em um site de comércio eletrônico, os consumidores podem concluir quase todos os pedidos sem problemas, mas durante alguns picos de compras de feriados, devido ao aumento do comportamento de compra dos consumidores, a fim de proteger a estabilidade do sistema de compras, alguns consumidores podem ser direcionados para uma página de downgrade
estado suave
Soft state significa que os dados no sistema podem ter um estado intermediário, e acredita-se que a existência desse estado intermediário não afetará a disponibilidade geral do sistema, ou seja, há um atraso no processo de permissão o sistema para sincronizar dados entre cópias de dados de nós diferentes
eventual consistência
A consistência final enfatiza que todas as cópias de dados podem eventualmente atingir um estado consistente após um período de sincronização. Portanto, a essência da consistência final é que o sistema precisa garantir que os dados finais possam ser consistentes e não precisa garantir a forte consistência dos dados do sistema em tempo real.
Introdução ao SEATA
Site oficial: https://seata.io/zh-cn/docs/overview/what-is-seata.html
Seata é uma solução de transação distribuída de código aberto dedicada a fornecer serviços de transação distribuída de alto desempenho e fáceis de usar. A Seata fornecerá aos usuários os modos de transação AT, TCC, SAGA e XA para criar uma solução distribuída completa para os usuários.

TC (Coordenador de Transações) - coordenador de transações
Mantenha o estado das transações globais e de filiais e impulsione a confirmação ou reversão de transações globais.
TM (Transaction Manager) - gerenciador de transações
Defina o escopo de uma transação global: inicie uma transação global, confirme ou reverta uma transação global.
RM (Gerente de Recursos) - Gerente de Recursos
Gerenciar recursos para transações de filiais, conversar com TCs para registrar transações de filiais e relatar o status das transações de filiais e direcionar transações de filiais para confirmação ou reversão.
SEATADOWNLOAD
Endereço de download oficial: https://seata.io/zh-cn/blog/download.html
configuração do servidor Seata
Abra o arquivo Registry.conf no diretório conf
Modifique o centro de registro e centro de configuração da Seata para Nacos

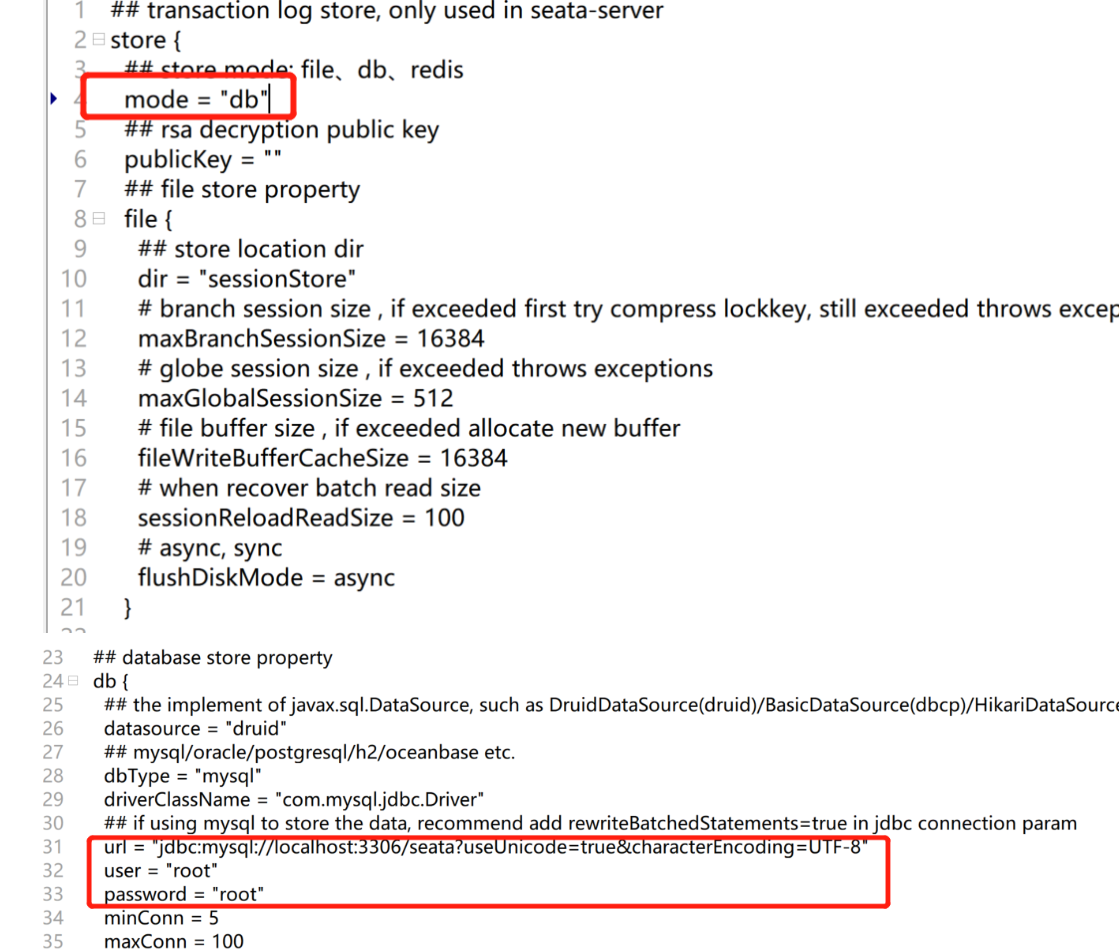
Modifique o modo de armazenamento do Seata, modifique o arquivo file.conf, altere o modo de armazenamento padrão do Seata para o banco de dados "DB", e também precisa configurar o JDBC
comece
Inicie o nacos primeiro e depois inicie o Seata-Server
A maneira de iniciar o Seata-Server é muito simples, basta clicar duas vezes em seata-server.bat
Então você pode ver Seata-Server no console nacos
A porta padrão do Seata é 8091
O modo de armazenamento do lado do servidor (store.mode) suporta três
arquivo: modo autônomo, a informação da sessão de transação global lê e escreve na memória e persiste o arquivo local root.data, com alto desempenho (padrão)
DB: modo de alta disponibilidade, as informações da sessão de transação global são compartilhadas por meio do banco de dados, desempenho relativamente ruim
redis: suportado pelo Seata-Server 1.3 e superior, com alto desempenho e risco de perda de informações da transação, precisa ser usado em conjunto com cenários reais.
O banco de dados seata configurado em file.conf e o correspondente global_table, branch_table e lock_table precisam ser construídos por você mesmo

建表语句地址: https://github.com/seata/seata/blob/develop/script/server/db/mysql.sql
完成以后需要重启seata
配置nacos
Seata支持注册服务到Nacos,以及支持Seata所有配置放到Nacos配置中心,在Nacos中统一维护;
高可用模式下就需要配合Nacos来完成

注册中心
Seata-server端配置注册中心,在registry.conf中加入配置注册中心nacos
注意:确保client与server的注册处于同一个namespace和group,不然会找不到服务。
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "nacos"
nacos {
application = "seata-server"
serverAddr = "127.0.0.1:8848"
group = "SEATA_GROUP" # 这里的配置要和客户端保持一致
namespace = "" # 这里的配置要和客户端保持一致
cluster = "default"
username = "nacos"
password = "nacos"
}配置中心
Seata-Server配置配置中心,在registry.conf中加入配置使用nacos作为配置中心
config {
# file、nacos 、apollo、zk、consul、etcd3
type = "nacos"
nacos {
serverAddr = "127.0.0.1:8848"
namespace = ""
group = "SEATA_GROUP"
username = ""
password = ""
dataId = "seataServer.properties"
}我们需要把Seata的一些配置上传到Nacos中,配置比较多,所以官方给我们提供了一个config.txt,我们下载并且修改其中参数,上传到Nacos中
下载地址:https://github.com/seata/seata/tree/develop/script/config-center
具体修改:
注意:事务分组:用于防护机房停电,来启用备用机房,或者异地机房,容错机制,当然如果Seata-Server配置了对应的事务分组,Client也需要配置相同的事务分组
service.vgroupMapping.可以自定义=default
default这里必须等于 registry.config 中的cluster="default"(当然可以更改 )
修改好这个文件以后,我们就需要把这个文件放到seata目录下
此时我们需要把这些配置一个个的加入到Nacos配置中,所以我们需要一个脚本来进行执行,官方已经提供好了
地址为:https://github.com/seata/seata/blob/develop/script/config-center/nacos/nacos-config.sh
我们需要在seata-server-1.4.2文件夹中新建一个脚本文件nacos-config.sh,然后把脚本内容复制进去
利用git来进行执行命令:
sh nacos-config.sh -h localhost -p 8848 -g SEATA_GROUP -t 命名空间 -u nacos -w nacos
参数说明:
-h:host,默认值localhost
-p:port,默认值8848
-g:配置分组,默认为SEATA_GROUP
-t:租户信息,对应Nacos的命名空间ID,默认为空
在执行naocs-config文件的时候要注意,它默认寻找config.txt的路径和我们的路径不同,所以要打开naocs-config文件进行修改,否则无法执行。

当以上的这些配置完成以后,我们就可以启动nacos和seata-server了,此时我们查看Nacos的配置中心,就会看到我们传入的所有配置信息
AT模式(常用)
AT模式是一种无侵入的分布式事务解决方案,在 AT 模式下,用户只需关注自己的“业务 SQL”,用户的 “业务 SQL” 作为一阶段,Seata 框架会自动生成事务的二阶段提交和回滚操作。
通过Seata的AT模式解决分布式事务
首先增加对应的Seata依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>在对应的微服务数据库上加上undo_log表,此表用于数据的回滚
具体的建表语句
https://github.com/seata/seata/blob/master/script/client/at/db/mysql.sql
配置yml(8801和8802Seata的配置保持一致)
server:
port: 8801
spring:
application:
name: seata-order
cloud:
nacos:
discovery:
server-addr: localhost:8848
alibaba:
seata:
tx-service-group: mygroup # 事务组, 随便写
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/test_at?characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true
username: root
password: root
type: com.alibaba.druid.pool.DruidDataSource
seata:
tx-service-group: mygroup # 事务组名称,要和服务端对应
service:
vgroup-mapping:
mygroup: default # key是事务组名称 value要和服务端的机房名称保持一致在order8801(TM)的Controller上添加注解
@GlobalTransactional,加在TM上
@RestController
public class OrderController {
@Autowired
private OrderService orderService;
@GetMapping("/order/create")
@GlobalTransactional// 开启分布式事务
public String create(){
orderService.create();
return "生成订单";
}
}把8801和8802都跑起来,当然Nacos和Seata都要进行启动
这个时候我们进行访问Order的REST接口:http://localhost:8801/order/create,我们就会发现此时已经解决了分布式事务问题
XA模式
在 Seata 定义的分布式事务框架内,利用事务资源(数据库、消息服务等)对 XA 协议的支持,以 XA 协议的机制来管理分支事务的一种 事务模式。
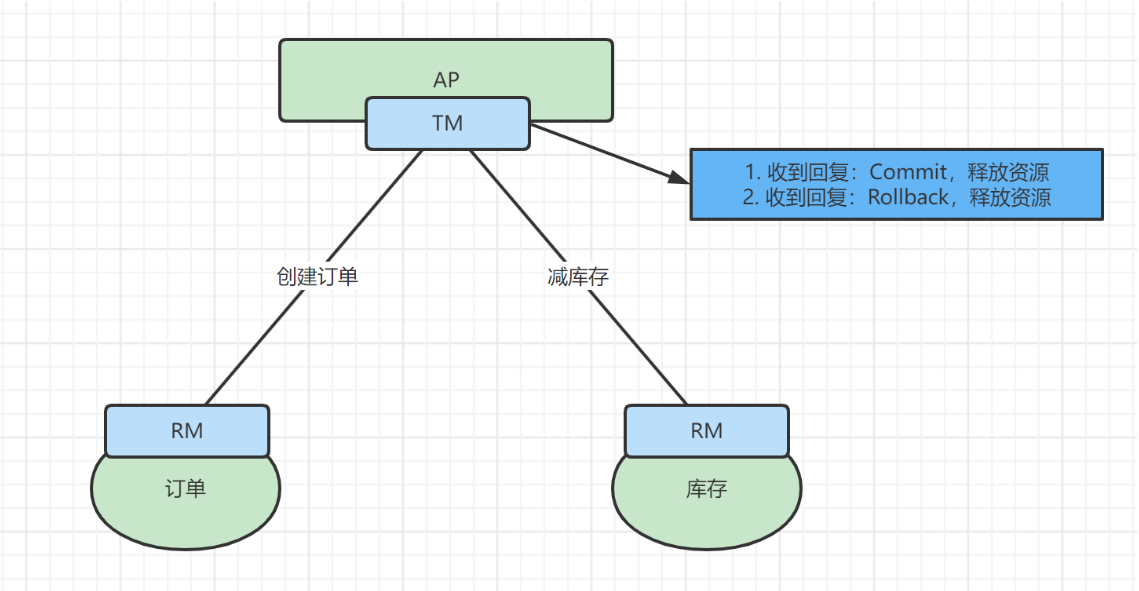
应用程序(AP)持有订单库和商品库两个数据源。
应用程序(AP)通过TM通知订单库(RM)和商品库(RM),来创建订单和减库存,RM此时未提交事务,此时商品和订单资源锁定。
TM收到执行回复,只要有一方失败则分别向其他RM发送回滚事务,回滚完毕,资源锁释放。
TM收到执行回复,全部成功,此时向所有的RM发起提交事务,提交完毕,资源锁释放。
XA协议的痛点
如果一个参与全局事务的资源 “失联” 了(收不到分支事务结束的命令),那么它锁定的数据,将一直被锁定。进而,甚至可能因此产生死锁。
这是 XA 协议的核心痛点,也是 Seata 引入 XA 模式要重点解决的问题。

与AT不同的是,XA没有undo_log表;
AT利用undo log实现了最终一致性,会有中间状态(可能会导致脏读);
XA实现了强一致性,没有中间状态,利用数据库自带的事务进行回滚
XA模式优点:
业务无侵入:和 AT 一样,XA 模式将是业务无侵入的,不给应用设计和开发带来额外负担。
数据库的支持广泛:XA 协议被主流关系型数据库广泛支持,不需要额外的适配即可使用。
多语言支持容易:因为不涉及 SQL 解析,XA 模式对 Seata 的 RM 的要求比较少。
传统基于 XA 应用的迁移:传统的,基于 XA 协议的应用,迁移到 Seata 平台,使用 XA 模式将更平滑。

从编程模型上,XA 模式与 AT 模式保持完全一致。
在样例中,上层编程模型与 AT 模式完全相同。只需要修改数据源代理,即可实现 XA 模式与 AT 模式之间的切换。
@Bean("dataSource")
public DataSource dataSource(DruidDataSource druidDataSource) {
// DataSourceProxy for AT mode
// return new DataSourceProxy(druidDataSource);
// DataSourceProxyXA for XA mode
return new DataSourceProxyXA(druidDataSource);
}TCC模式
TCC 是分布式事务中的二阶段提交协议,它的全称为 Try-Confirm-Cancel,即资源预留(Try)、确认操作(Confirm)、取消操作(Cancel),他们的具体含义如下:
1. Try:对业务资源的检查并预留;
2. Confirm:对业务处理进行提交,即 commit 操作,只要 Try 成功,那么该步骤一定成功;
3. Cancel:对业务处理进行取消,即回滚操作,该步骤回对 Try 预留的资源进行释放。
TCC和AT的区别是TCC不依赖数据库本身的ACID,都是调用自定义的方法;
侵入性比较强,并且需要自己实现相关事务控制逻辑
在整个过程基本没有锁,性能较强
SAGA模式
Saga模式是SEATA提供的长事务解决方案,在Saga模式中,业务流程中每个参与者都提交本地事务,当出现某一个参与者失败则补偿前面已经成功的参与者,一阶段正向服务和二阶段补偿服务都由业务开发实现。

适用场景:
业务流程长、业务流程多
参与者包含其它公司或遗留系统服务,无法提供 TCC 模式要求的三个接口
优势:
一阶段提交本地事务,无锁,高性能
事件驱动架构,参与者可异步执行,高吞吐
补偿服务易于实现
缺点:
不保证隔离性(应对方案见后面文档)
Saga的实现:
基于状态机引擎的 Saga 实现:
目前SEATA提供的Saga模式是基于状态机引擎来实现的,机制是:
通过状态图来定义服务调用的流程并生成 json 状态语言定义文件
状态图中一个节点可以是调用一个服务,节点可以配置它的补偿节点
状态图 json 由状态机引擎驱动执行,当出现异常时状态引擎反向执行已成功节点对应的补偿节点将事务回滚
注意: 异常发生时是否进行补偿也可由用户自定义决定
可以实现服务编排需求,支持单项选择、并发、子流程、参数转换、参数映射、服务执行状态判断、异常捕获等功能