1. Algoritmo de regressão logística
1. O que é Regressão Logística
A regressão logística é um desses processos: enfrentar um problema de regressão ou classificação, estabelecer uma função de custo, resolver iterativamente os parâmetros do modelo ideal por meio de métodos de otimização e, em seguida, testar e verificar a qualidade do nosso modelo resolvido.
Embora a regressão logística tenha "regressão" em seu nome, na verdade é um método de classificação, usado principalmente para problemas de duas categorias (ou seja, existem apenas dois tipos de saída, representando duas categorias respectivamente)
No modelo de regressão, y é uma variável qualitativa, como y=0 ou 1, e o método logístico é usado principalmente para estudar a probabilidade de certos eventos
2. Vantagens e desvantagens da regressão logística
vantagem:
1) Rápido, adequado para problemas de classificação binária
2) Simples e fácil de entender, veja diretamente o peso de cada recurso
3) O modelo pode ser facilmente atualizado para absorver novos dados
deficiência:
A capacidade de adaptação a dados e cenários tem limitações e não é tão adaptável quanto o algoritmo de árvore de decisão
3. A diferença entre regressão logística e regressão linear múltipla
A regressão logística e a regressão linear múltipla realmente possuem muitas semelhanças, a maior diferença é que suas variáveis dependentes são diferentes, e as outras são basicamente as mesmas. Por causa disso, as duas regressões podem ser atribuídas à mesma família, modelos lineares generalizados.
4. Usos da regressão logística
Encontrar fatores de risco: procurar fatores de risco para uma determinada doença, etc.;
Predição: De acordo com o modelo, prever a probabilidade de uma determinada doença ou uma determinada situação sob diferentes variáveis independentes;
Discriminação: Na verdade, é um pouco semelhante à previsão. Também se baseia no modelo para julgar a probabilidade de uma pessoa pertencer a uma determinada doença ou a uma determinada situação, ou seja, para ver a probabilidade dessa pessoa pertencer a uma determinada doença.
5. Etapas gerais de regressão
Encontre a função h (ou seja, a função de previsão)
Construa a função J (função de perda)
Encontre uma maneira de minimizar a função J e encontre os parâmetros de regressão (θ)
6. Construa a função de previsão h(x)
1) Função logística (ou chamada função Sigmóide), a forma da função é:
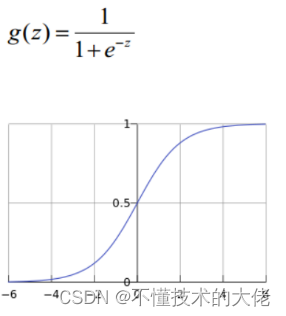
Para o caso de um limite linear, a forma do limite é a seguinte:
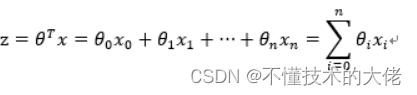
Entre eles, os dados de treinamento são um vetor

O valor da função h(x) tem um significado especial, que representa a probabilidade do resultado ser 1, então as probabilidades da classe 1 e classe 0 para a entrada x são:
P(y=1│x;θ)=h_θ (x)
P(y=0│x;θ)=1-h_θ (x)
7. Construa a função de perda J (m amostras, cada amostra tem n características)
A função Custo e a função J são as seguintes, derivadas com base na estimativa de máxima verossimilhança.
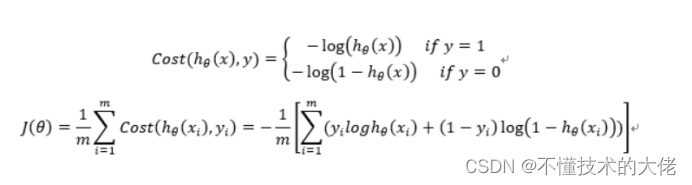
8. Processo de derivação detalhado da função de perda
1) A probabilidade da função de custo
é combinada e escrita como:
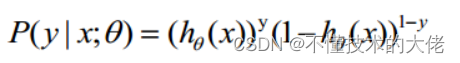
Considere a função de verossimilhança como:
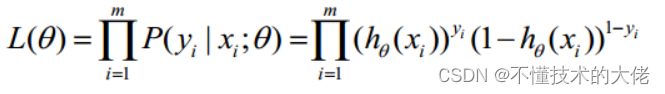
A função log-verossimilhança é:

A estimativa de máxima verossimilhança é encontrar o θ quando l(θ) assume o valor máximo.Na verdade, o método de gradiente ascendente pode ser usado aqui para resolver o problema.O θ obtido é o parâmetro ótimo necessário.
No curso de Andrew Ng, J(θ) é tomado como a seguinte fórmula, a saber:

- Método de descida de gradiente para encontrar o valor mínimo

O processo de atualização θ pode ser escrito como:
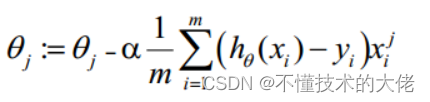
9. Vetorização
A ectorização usa cálculos de matriz em vez de loops for para simplificar o processo de cálculo e melhorar a eficiência.
Processo de vetorização:
A forma de matriz dos dados de treinamento acordados é a seguinte, cada linha de x é uma amostra de treinamento e cada coluna é um valor especial diferente:

O parâmetro A de g(A) é um vetor de coluna, então a implementação da função g deve suportar vetores de coluna como parâmetros e retornar vetores de coluna.
O processo de atualização θ pode ser alterado para:

Resumindo, as etapas de atualização de θ após a Vetorização são as seguintes:
- Encontre A=x*θ
- E=g(A)-y

10. Regularização
(1) Problema de sobreajuste
Sobreajuste significa sobreajustar os dados de treinamento, o que aumenta a complexidade do modelo e o torna menos próspero (a capacidade de prever dados desconhecidos)
. a imagem do meio é o ajuste adequado, com overfitting à direita.
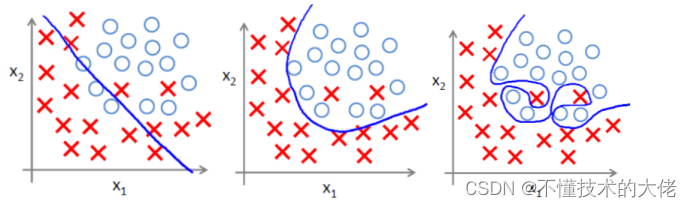
(2) A principal razão para o overfitting
Problemas de superajuste geralmente surgem por ter muitos recursos
Solução
1) Reduza o número de recursos (reduzir recursos perderá algumas informações, mesmo que os recursos sejam bem selecionados)
• Os recursos a serem retidos podem ser selecionados manualmente;
• Algoritmo de seleção de modelo;
2) Regularização (mais eficaz quando há muitos recursos)
• Preservar todos os recursos, mas reduzir o tamanho de θ
(3) Método de regularização
A regularização é a concretização da estratégia de minimização do risco estrutural, que consiste em adicionar ao risco empírico um item de regularização ou item de penalização. O termo de regularização é geralmente uma função monotonicamente crescente da complexidade do modelo, quanto mais complexo o modelo, maior o termo de regularização.
O termo regular pode assumir diferentes formas.No problema de regressão, a perda quadrada é tomada, que é a norma L2 do parâmetro, e também pode ser tomada a norma L1. Ao tomar a perda ao quadrado, a função de perda do modelo torna-se:
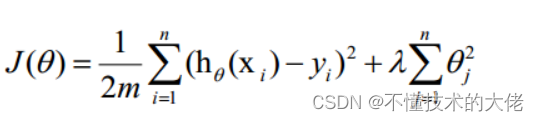
lambda é o coeficiente de regularização:
• Se seu valor for grande, significa que a penalidade de complexidade para o modelo é grande e a penalidade de perda para os dados de ajuste é pequena, de modo que não superajuste os dados, o desvio nos dados de treinamento é grande e o penalidade de perda nos dados desconhecidos A variância é pequena, mas pode ocorrer subajuste;
• Se seu valor for pequeno, significa que mais atenção é dada ao ajuste dos dados de treinamento, e o desvio nos dados de treinamento será pequeno, mas pode levar ao overfitting.
A atualização do algoritmo de descida de gradiente regularizado θ torna-se:

11. Python implementa regressão logística:
from sklearn.linear_model import LogisticRegression
Model = LogisticRegression()
Model.fit(X_train, y_train)
Model.score(X_train,y_train)
# Coeficiente de equação e interceptação
Print('Coeficiente',model.coef_)
Print('Intercept',model. intercept_)
# Predict Output
Predicted = Model.predict(x_test)
----- Parte do conteúdo é referenciado em: Logistic Regression-Theory _pakko's Blog-CSDN Blog_Logistic Regression Binomial Distribution
2. Algoritmo K-means
1. Visão Geral
O algoritmo K-means é o método de agrupamento baseado em partição mais clássico e um dos dez principais algoritmos clássicos de mineração de dados. A ideia básica do algoritmo K-means é agrupar os k pontos no espaço e classificar os objetos mais próximos a eles. Através do método iterativo, o valor de cada centro de agrupamento é atualizado sucessivamente até que o melhor resultado de agrupamento seja obtido.
O algoritmo k-means aceita o parâmetro k e, em seguida, divide a entrada de n objetos de dados antecipadamente em k clusters para que os clusters obtidos satisfaçam a similaridade de objetos no mesmo cluster, enquanto objetos em clusters diferentes A similaridade é pequena. A similaridade do cluster é calculada usando um "objeto central" (centro de gravidade) obtido a partir do valor médio dos objetos em cada cluster.
2. Princípio de implementação
A ideia básica do algoritmo KMeans é inicialmente definir aleatoriamente K centros de clusters e dividir os pontos amostrais a serem classificados em cada cluster de acordo com o princípio do vizinho mais próximo. Em seguida, recalcule os centróides de cada cluster de acordo com o método da média, de modo a determinar o novo centro do cluster. Itera até que a distância móvel do centro do cluster seja menor que um determinado valor.
O algoritmo de agrupamento K-Means é dividido principalmente em três etapas:
(1) O primeiro passo é encontrar o centro do cluster para os pontos a serem agrupados;
(2) O segundo passo é calcular a distância de cada ponto ao centro do cluster e agrupar cada ponto no cluster mais próximo do ponto;
(3) O terceiro passo é calcular o valor médio das coordenadas de todos os pontos em cada cluster e usar esse valor médio como o novo centro do cluster;
Repita (2) e (3) até que o centro do cluster não se mova mais em uma grande faixa ou o número de clusters atinja o requisito.
A figura abaixo mostra o efeito do agrupamento K-means em n pontos de amostra, onde k é 2:
(a) Conjunto de pontos inicial não agrupado;
(b) Selecione aleatoriamente dois pontos como centros de cluster;
(c) Calcule a distância de cada ponto até o centro do cluster e do cluster até o cluster mais próximo do ponto;
(d) Calcule o valor médio das coordenadas de todos os pontos em cada cluster e use esse valor médio como o novo centro do cluster;
(e) Repita (c), calcule a distância de cada ponto até o centro do cluster e agrupe o cluster mais próximo do ponto;
(f) Repita (d), calcule as coordenadas médias de todos os pontos em cada cluster e use essa média como o novo centro do cluster.
A maior vantagem deste algoritmo é a sua simplicidade e rapidez. A chave do algoritmo está na seleção do centro inicial e na fórmula da distância.
O valor de K:
Não existe um método ótimo para determinar o número de clusters K e geralmente precisa ser selecionado manualmente de acordo com o problema específico. Não há um método direto de avaliação de agrupamento para agrupamento não supervisionado, mas o efeito do agrupamento pode ser avaliado a partir do grau de densidade dentro de um agrupamento e do grau de dispersão entre agrupamentos. Os métodos mais comuns são o Coeficiente de Silhueta e o Índice de Calinski-Harabaz. Dentre eles, o cálculo do Índice de Calinski-Harabaz é direto e simples, e quanto maior o resultado obtido, melhor o efeito de agrupamento. Calculado da seguinte forma:
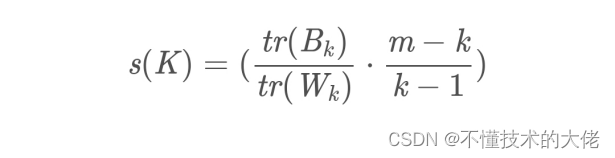
Entre eles: m é o número de amostras no conjunto de treinamento e k é o número de categorias. Bk é a matriz de covariância entre categorias e Wk é a matriz de covariância entre dados internos. tr é o traço da matriz. Ou seja, quanto menor a covariância dos dados internos, melhor, e quanto maior a covariância entre as categorias, melhor, de modo que a pontuação do
Índice Calinski-Harabaz correspondente será maior. selecione os dados K (isto é, o agrupamento final é a classe K) como o centro inicial do agrupamento. Calcule a distância euclidiana de cada ponto de dados para os K pontos centrais separadamente e atribua-a ao cluster mais próximo do ponto central. Recalcule a média coordenada dos dados do cluster K e use a nova média como o centro do cluster. Repita as etapas 2 e 3 até que as coordenadas dos centros dos clusters não sejam mais transformadas ou o número especificado de iterações seja alcançado para formar os K clusters finais. O algoritmo k-Means, também conhecido como k-means ou k-means, é um algoritmo de agrupamento amplamente usado ou forma a base de outros algoritmos de agrupamento. Assumindo que a amostra de entrada é S=x...m, os passos do algoritmo são: selecionar os k centros de categoria iniciais μ2.Hk para cada amostra x;, marcá-la como a categoria mais próxima do centro de categoria, a saber:
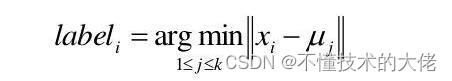
Atualize cada centro de classe para ser a média de todas as amostras pertencentes a essa classe

As duas últimas etapas são repetidas até que a variação dos centros de classe seja menor que algum limite.
Condição de término:
número de iterações) taxa de mudança do centro do cluster/erro quadrado mínimo MSE (Erro Quadrado Mínimo)
Registre K centros de cluster como M,μ,,k e o número de amostras em cada cluster como N,N2,..,N.
Use o erro quadrado como a função objetivo:
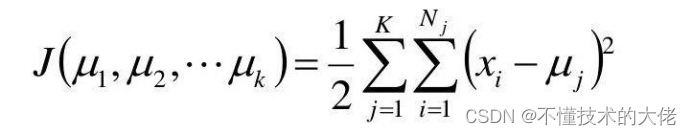
Encontre a derivada parcial da função em relação a from,...,Hp, seu ponto de estagnação é:

- Resumo do método de agrupamento k-Means
(1) Vantagens:
É um algoritmo clássico para resolver problemas de agrupamento. É simples e rápido para processar grandes conjuntos de dados. O algoritmo mantém escalabilidade e alta eficiência. Quando o cluster é distribuído aproximadamente Gaussiano, ele O efeito é melhor
(2) Desvantagem:
só pode ser usado quando o valor médio do cluster pode ser definido, pode não ser adequado para algumas aplicações,
k (o número de clusters a serem gerados) deve ser fornecido antecipadamente, e é sensível ao valor inicial, valores iniciais diferentes podem levar a resultados diferentes.
Não é adequado para encontrar clusters com formas não convexas ou clusters com grandes diferenças de tamanho. Sensível a ruído e dados atípicos,
mas pode ser usado como algoritmo básico para outros métodos de agrupamento, como agrupamento espectral. - Realize o código com JAVA:
class point { public float x = 0; public float y = 0; public int flage = -1; public float getX() { return x; } public void setX(float x) { this.x = x ; return y; } public void setY(float y) { this.y = y; } } public class Kcluster { point[] ypo;// set point [] pacore = null;// old cluster center point [] pacoren = null ;// novo centro de agrupamento // centro de agrupamento preliminar, conjunto de pontos public void productpoint() { Scanner cina = new Scanner(System.in);
System.out.print("Insira o número de pontos no cluster (gerados aleatoriamente):");
int num = cina.nextInt();
ypo = new point[num];
// Gera pontos aleatoriamente
para (int i = 0; i < num; i++) { float x = (int) (new Random().nextInt(10)); float y = (int) (new Random().nextInt(10)); ypo[i] = new point();// Criação do objeto ypo[i].setX(x); ypo[i].setY(y); } // Inicializa a posição central do cluster System.out.print("Insira o cluster de inicialização O número de centros (gerados aleatoriamente): "); int core = cina.nextInt(); this.pacore = new point[core];// armazena o centro do cluster this.pacoren = new point[core]; Random rand = novo Aleatório();
int temp[] = new int[core];
temp[0] = rand.nextInt(num);
pacore[0] = new point();
pacore[0].x = ypo[temp[0]].x;
pacore[0].y = ypo[temp[0]].y;
pacore[0].flage = 0;
// Evita centros duplicados
for (int i = 1; i < core; i++) { int flage = 0; int thistemp = rand.nextInt(num); for (int j = 0; j < i; j++) { if (temp[j] == thistemp) { flage = 1;// tem intervalo repetido; } } if (flage == 1) { i--;
} else { pacore[i] = new point(); pacore[i].x = ypo[estemp].x; pacore[i].y = ypo[estemp].y; pacore[i].flage = 0; // 0 significa centro do cluster } } System.out.println("Initial cluster center:"); for (int i = 0; i < pacore.length; i++) { System.out.println(pacore[i] .x + " " + pacore[i].y); } } // /// Descubra a qual centro de cluster cada ponto pertence public void searchbelong()// Descubra a qual centro de cluster cada ponto pertence { for (int i = 0; i < ypo.length; i++) { double dist = 999; int lable = -1;
for (int j = 0; j < pacore.length; j++) { double distance = distpoint(ypo[i], pacore[j]); if (distância < dist) { dist = distância; etiqueta = j; // po[i].flage = j + 1;// 1,2,3...... } } ypo[i].flage = lable + 1; } } // 更新聚类中心 public void calaverage() { for (int i = 0; i < pacore.length; i++) { System.out.println("以<" + pacore[i].x + ", " + pacore[i].y + ">为中心的点:"); int num = 0;
for (int j = 0; j < ypo.length; j++) { if (ypo[j].flage == (i + 1)) { System.out.println(ypo[j].x + "," + ypo[j].y); numc += 1; newcore.x += ypo[j].x; newcore.y += ypo[j].y; } } // novo centro do cluster (isto é, toda a agregação O centro do ponto) pacoren[i] = new point(); pacoren[i].x = newcore.x / numc;//soma das coordenadas x de todos os elementos agrupados/número de elementos pacoren[i].y = newcore.y / numc; pacoren[i].flage = 0; System.out.println("Novo centro do cluster: " + pacoren[i].x + "," + pacoren[i].y); } }
public double distpoint(point px, point py) { return Math.sqrt(Math.pow((px.x - py.x), 2) + Math.pow((px.y - py.y), 2)) ; } public void change_oldtonew(point[] old, point[] news) { for (int i = 0; i < old.length; i++) { old[i].x = news[i].x; old[i ].y = news[i].y; old[i].flage = 0;//Representado como o sinalizador do centro do cluster. } } public void movecore() { // this.productpoint();//inicialização, conjunto de amostra, centro do cluster, this.searchbelong(); this.calaverage();// double moveddistance = 0; int biao = - 1 ;// sinal, se o movimento do ponto central do cluster atende à distância mínima
for (int i = 0; i < pacore.length; i++) { movedistance = distpoint(pacore[i], pacoren[i]);//Calcular a distância entre os pontos centrais novos e antigos System.out.println(" distcore: " +moveddistance);// A distância de movimento do centro do cluster if (movedistance < 0.01) { biao = 0; } else { biao = 0; } else { biao = 1;// Continue iterando, break; } } if ( biao == 0) { System.out.print("iteração completa!!!!"); } else { change_oldtonew(pacore, pacoren); movecore(); } }
public static void main(String[] args) { // TODO Método gerado automaticamente stub Kcluster kmean = new Kcluster(); kmean.productpoint(); kmean.movecore(); }
}
----Parte do conteúdo é referenciado em: https://blog.csdn.net/weixin_40479663/article/details/82974625?utm_source=app&app_version=4.10.0&code=app_1562916241&uLinkId=usr1mkqgl919blen