Índice
Transformador de token multiclasse para segmentação semântica fracamente supervisionada
Resumo
Neste artigo, propomos uma nova estrutura baseada em Transformer para aprender mapas de localização de objetos específicos de classe como pseudo-rótulos para Segmentação semântica fracamente supervisionada (WSSS).
As regiões de participação de um token em um Transformer visual padrão podem ser exploradas para formar um mapa de localização independente de classe
. .
Este artigo propõe um Multi-class Token Transformer chamado MCTformer, que usa múltiplos Tokens de classe para aprender a interação entre Tokens de classe e Tokens de patch. O MCTformer pode gerar com sucesso mapas de localização de objetos discriminativos de classe a partir das atenções classe-a-patch correspondentes de diferentes tokens de classe.
Os autores também propõem usar relações de afinidade pairwise em nível de patch, que são extraídas do Transformer patch-to-patch, para refinar ainda mais os grafos locais. Além disso, a estrutura proposta complementa totalmente os métodos de mapeamento de ativação de classe (CAM), alcançando resultados WSSS muito bons em conjuntos de dados PASCAL VOC e MS COCO. Esses resultados enfatizam a importância dos tokens de classe para WSSS.
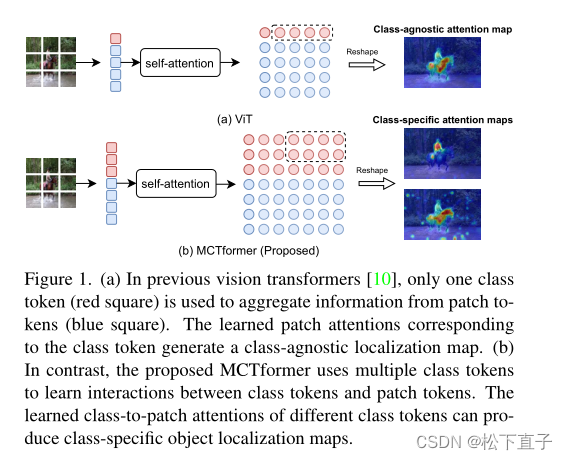
Figura (a) No vit anterior, apenas um token de classe (caixa vermelha) foi usado para agregar informações do token de patch (caixa azul). A atenção de patch aprendida correspondente aos tokens de classe gera um mapa de localização independente de classe.
(b) O MCTformer proposto usa vários tokens de classe para aprender as interações entre tokens de classe e tokens de patch. A atenção aprendida de classe para patch de diferentes tokens de classe gera mapas de localização de objetos específicos de classe.
Método neste artigo
MCTformer-V1
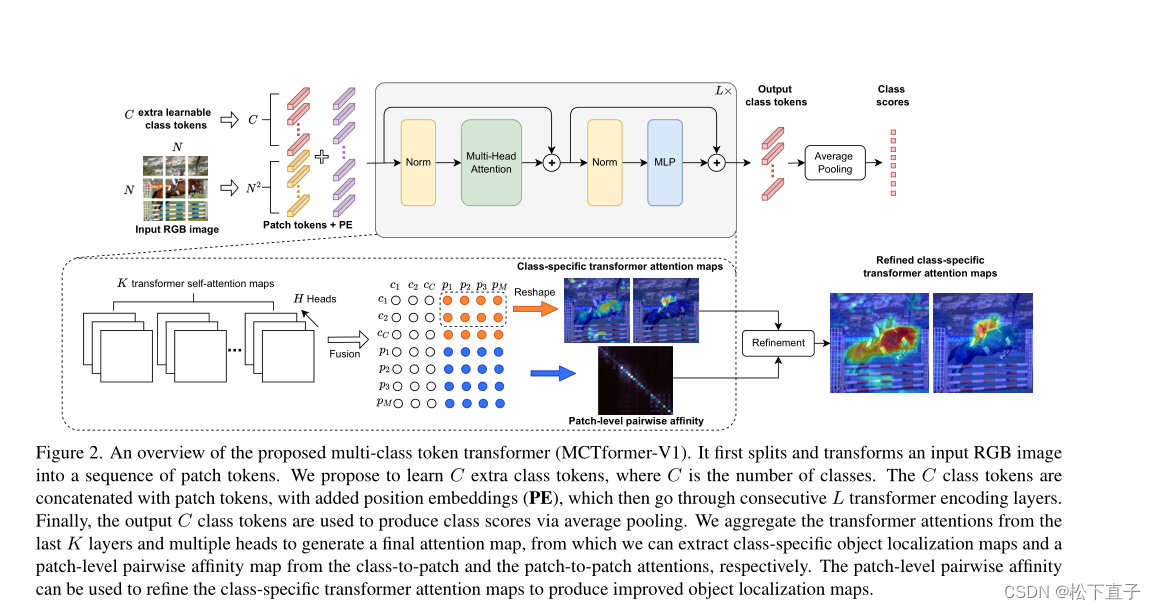
A imagem RGB de entrada é primeiro segmentada e convertida em uma sequência de rótulos de correção. Propomos aprender C tokens de classe adicionais, onde C é o número de classes. Os tokens de classe C são concatenados com tokens de patch e incorporações posicionais (PE) são adicionadas e, em seguida, passadas por sucessivas camadas de codificação do transformador L.
Por fim, os tokens de classe C de saída são usados para gerar pontuações de classe por agrupamento de médias. Reunir as últimas camadas K e a atenção multicabeça produz o mapa de atenção final, do qual podemos extrair mapas de localização de objetos específicos de classe e mapas de afinidade pairwise em nível de patch de atenção de classe para patch e de patch para patch, respectivamente . As afinidades pareadas em nível de patch podem ser usadas para refinar mapas de atenção específicos de classe para gerar mapas de localização de objetos aprimorados
MCTformer-V2
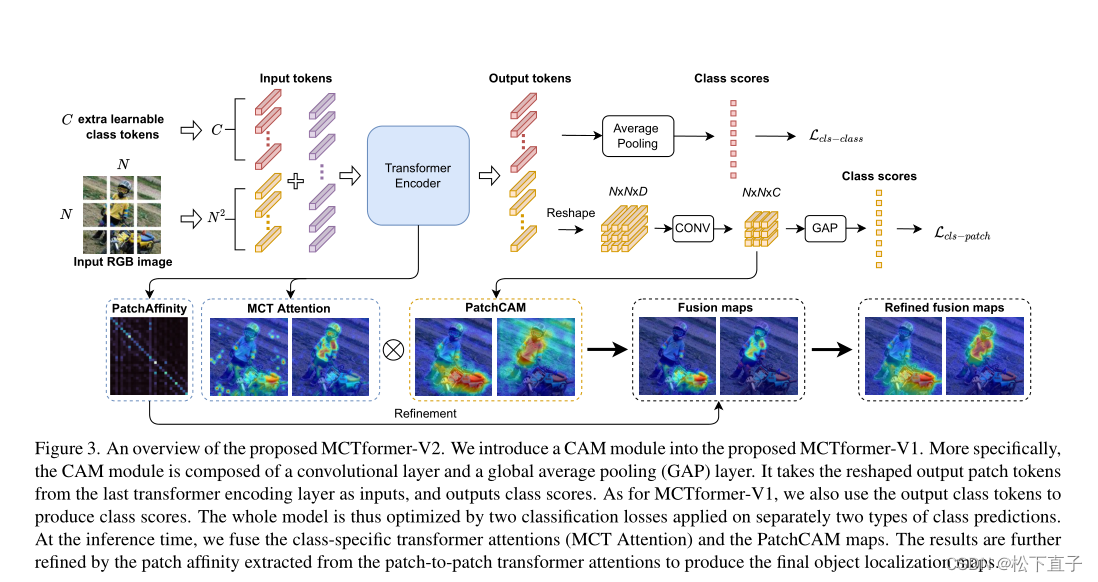
O módulo CAM foi introduzido no MCTformer-V1
.O módulo CAM consiste em uma camada convolucional e uma camada global average pooling (GAP).
Toma os tokens de patch de saída reformulados da última camada de codificação do transformador como entrada e gera pontuações de classe.
Para o MCTformer-V1, também usamos os tokens de classe de saída para gerar pontuações de classe. Portanto, todo o modelo é otimizado aplicando as duas perdas de classificação às duas previsões de classe, respectivamente.
No momento da inferência, fundimos os mapas de atenção MCT e PatchCAM para refinar ainda mais os resultados, extraindo a afinidade do patch da atenção do transformador patch a patch para gerar o mapa final de localização do objeto.
Outros detalhes:
Fusão de módulos:

Refinamento do mapa de localização de objetos específicos da classe:
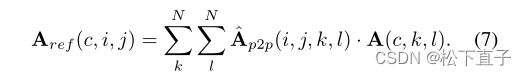
patch2patch otimiza os módulos fundidos acima
Resultados experimentais