O aprendizado conjunto refere-se a um modelo de aprendizado de máquina que combina dois ou mais modelos. O aprendizado conjunto é um ramo do aprendizado de máquina que é frequentemente usado em busca de recursos preditivos mais fortes.
As bibliotecas modernas de aprendizado de máquina (scikit-learn, XGBoost) já incorporam métodos comuns de aprendizado de conjunto internamente. O aprendizado conjunto é frequentemente usado pelos principais e vencedores participantes em competições de aprendizado de máquina. Se você gostou deste artigo, lembre-se de marcar, curtir e seguir.
[Nota] A versão completa do código, dados e troca técnica podem ser obtidas no final do artigo
Introdução à Aprendizagem Integrada
O aprendizado conjunto combina vários modelos diferentes e, em seguida, combina um único modelo para concluir a previsão. Muitas vezes, o aprendizado em conjunto encontra um desempenho melhor do que um único modelo.
As técnicas comuns de aprendizado em conjunto se dividem em três categorias:
-
Bagagem , 如. Árvores de decisão ensacadas e floresta aleatória.
-
Impulsionando , 如. Adaboost e aumento de gradiente
-
Empilhamento , 如. Votando e usando um meta-modelo.
O uso do ensemble learning pode reduzir a variação dos resultados da previsão e, ao mesmo tempo, ter um desempenho melhor do que um único modelo.
Acondicionamento
BaggingAo amostrar as amostras do conjunto de dados de treinamento, vários modelos são obtidos por treinamento e, em seguida, vários resultados de previsão são obtidos. Ao combinar as previsões do modelo, as previsões do modelo individual podem ser votadas ou calculadas a média.
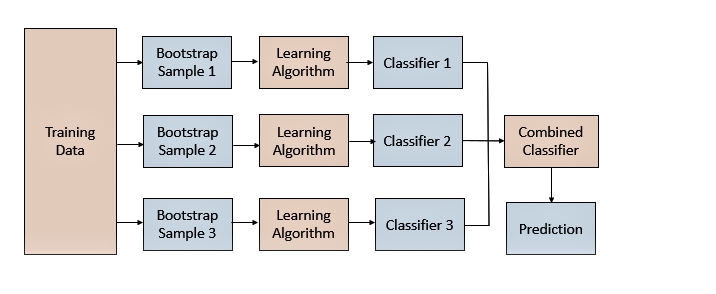
BaggingA chave é o método de amostragem do conjunto de dados. A maneira comum é amostrar da dimensão da linha (amostra), aqui está a amostragem com reposição.
BaggingPode ser passado BaggingClassifiere BaggingRegressorusado, por padrão eles usam uma árvore de decisão como modelo base, n_estimatorso número de árvores a serem criadas pode ser especificado por parâmetro.
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import BaggingClassifier
# 创建样例数据集
X, y = make_classification(random_state=1)
# 创建bagging模型
model = BaggingClassifier(n_estimators=50)
# 设置验证集数据划分方式
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# 验证模型精度
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# 打印模型的精度
print('Mean Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
Floresta Aleatória
Random Forest é uma combinação de Bagging e um modelo de árvore:
-
Um conjunto de floresta aleatória ajusta uma árvore de decisão em diferentes amostras de bootstrap do conjunto de dados de treinamento.
-
O Random Forest também fará uma amostra dos recursos (colunas) de cada conjunto de dados.
Em vez de considerar todos os recursos ao escolher os pontos de divisão, as florestas aleatórias restringem os recursos a um subconjunto aleatório de recursos ao construir cada árvore de decisão.
Os conjuntos de florestas aleatórias estão disponíveis em scikit-learn via RandomForestClassifiere classes. RandomForestRegressorVocê pode n_estimatorsespecificar o número de árvores a serem criadas por meio de max_featuresparâmetros e o número de recursos selecionados aleatoriamente a serem considerados em cada ponto de divisão.
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import RandomForestClassifier
# 创建样例数据集
X, y = make_classification(random_state=1)
# 创建随机森林模型
model = RandomForestClassifier(n_estimators=50)
# 设置验证集数据划分方式
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# 验证模型精度
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# 打印模型的精度
print('Mean Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
AdaBoostGenericName
BoostingTenta iterativamente corrigir os erros cometidos pelo modelo anterior, quanto mais iterações o ensemble produz menos erros, pelo menos dentro dos limites suportados pelos dados e antes de sobreajustar o conjunto de dados de treinamento.
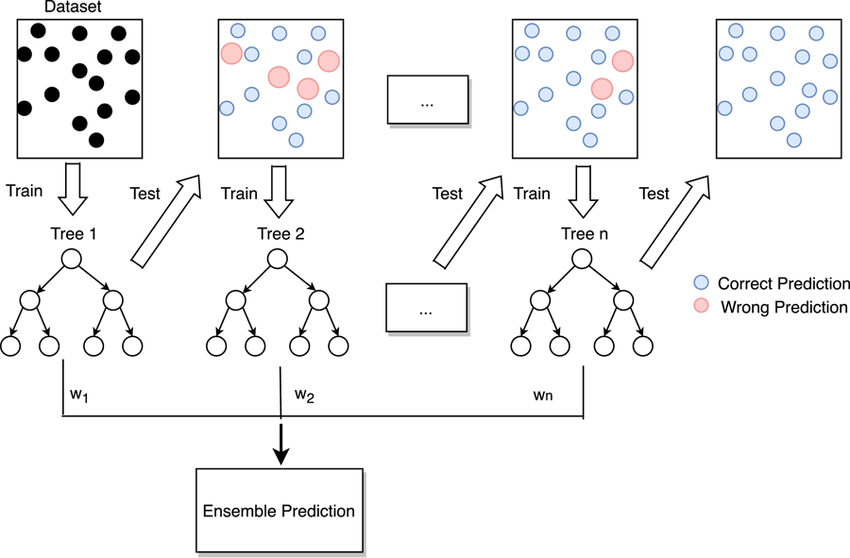
BoostingA ideia foi originalmente desenvolvida como uma ideia teórica, e o AdaBoostalgoritmo foi o primeiro a implementar com sucesso Boostingum algoritmo de conjunto baseado nele.
AdaBoostAjuste uma árvore de decisão em uma versão ponderada do conjunto de dados de treinamento para que a árvore preste mais atenção aos exemplos em que os membros anteriores estavam errados. AdaBoostNão é uma árvore de decisão completa, mas uma árvore muito simples que toma uma única decisão em uma variável de entrada antes de fazer uma previsão. Essas árvores curtas são chamadas de tocos de decisão.
AdaBoostPodem ser passados AdaBoostClassifiere AdaBoostRegressorusados, eles usam uma árvore de decisão (toco de decisão) como modelo base por padrão, e n_estimatorso número de árvores a serem criadas pode ser especificado por parâmetro.
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import AdaBoostClassifier
# 创建样例数据集
X, y = make_classification(random_state=1)
# 创建adaboost模型
model = AdaBoostClassifier(n_estimators=50)
# 设置验证集数据划分方式
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# 验证模型精度
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# 打印模型的精度
print('Mean Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
Aumento de gradiente
Gradient Boostingé uma estrutura para melhorar algoritmos de conjunto, AdaBoostinguma extensão do direito. Gradient BoostingDefinido como um modelo aditivo sob uma estrutura estatística, e permite o uso de funções de perda arbitrárias para torná-lo mais flexível, e o uso de penalidades de perda (shrinkage) para reduzir o overfitting.
Gradient BoostingAs operações introduzidas Bagging, como a amostragem de linhas e colunas do conjunto de dados de treinamento, são chamadas de aumento de gradiente estocástico.
Uma técnica de ensemble muito bem-sucedida para dados estruturados ou tabulares Gradient Boosting, embora o ajuste do modelo possa ser lento, pois os modelos são adicionados sequencialmente. Implementações mais eficientes foram desenvolvidas como XGBoost, LightGBM.
Gradient BoostingQuando disponível GradientBoostingClassifiere GradientBoostingRegressorusada, a árvore de decisão padrão é usada como modelo base. Você pode n_estimatorsespecificar o número de árvores a serem criadas por meio de um learning_rateparâmetro que controla a taxa de aprendizado da contribuição de cada árvore.
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import GradientBoostingClassifier
# 创建样例数据集
X, y = make_classification(random_state=1)
# 创建GradientBoosting模型
model = GradientBoostingClassifier(n_estimators=50)
# 设置验证集数据划分方式
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# 验证模型精度
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# 打印模型的精度
print('Mean Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
Votação
VotingUse estatísticas simples para combinar previsões de vários modelos.
-
Votação difícil: votação na categoria prevista;
-
Votação suave: Média das probabilidades previstas;
VotingPassável VotingClassifiere VotingRegressorutilizável. Você pode pegar uma lista de modelos base como argumento, cada modelo na lista deve ser uma tupla com um nome e um modelo,
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import VotingClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import LogisticRegression
# 创建数据集
X, y = make_classification(random_state=1)
# 模型列表
models = [('lr', LogisticRegression()), ('nb', GaussianNB())]
# 创建voting模型
model = VotingClassifier(models, voting='soft')
# 设置验证集数据划分方式
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# 验证模型精度
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# 打印模型的精度
print('Mean Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
Empilhamento
StackingCombine previsões de muitos tipos diferentes de modelos básicos e Votingsimilares. Mas Stackingos pesos de cada modelo podem ser ajustados com base no conjunto de validação.
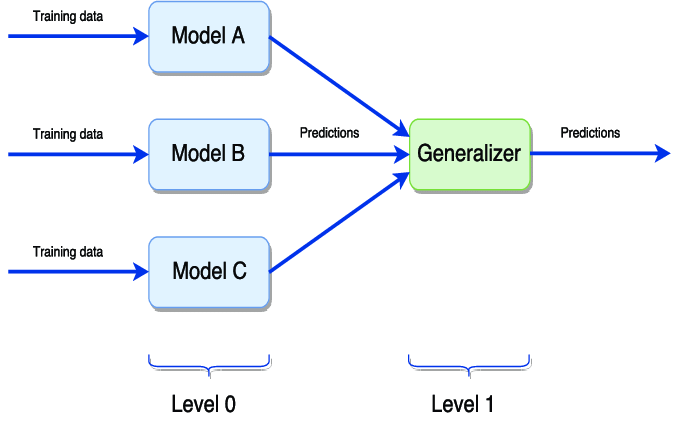
StackingEle precisa ser usado em conjunto com a validação cruzada, e também pode ser passado StackingClassifiere StackingRegressorusado, e o modelo base pode ser fornecido como parâmetro do modelo.
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import StackingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
# 创建数据集
X, y = make_classification(random_state=1)
# 模型列表
models = [('knn', KNeighborsClassifier()), ('tree', DecisionTreeClassifier())]
# 设置验证集数据划分方式
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# 验证模型精度
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# 打印模型的精度
print('Mean Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
artigo recomendado
-
O curso de mandarim "Machine Learning" de Li Hongyi (2022) está aqui
-
Alguém fez uma versão chinesa do aprendizado de máquina e aprendizado profundo do Sr. Wu Enda
-
Estou viciado, e recentemente dei à empresa uma grande tela visual (com código fonte)
-
Tão elegantes, 4 artefatos de análise automática de dados Python são realmente perfumados
Intercâmbio de Tecnologia
Bem-vindo a reimprimir, coletar, curtir e apoiar!

Atualmente, foi aberto um grupo de intercâmbio técnico, com mais de 2.000 membros . A melhor maneira de comentar ao adicionar é: fonte + direção de interesse, o que é conveniente para encontrar amigos com ideias semelhantes
- Método 1. Envie a seguinte imagem para o WeChat, pressione e segure para identificar e responda em segundo plano: adicionar grupo;
- Método ②, adicione micro-sinal: dkl88191 , nota: da CSDN
- Método ③, conta pública de pesquisa do WeChat: aprendizado de Python e mineração de dados , resposta em segundo plano: adicionar grupo
