Este diretório de artigos:
-
Histórico da evolução do Spark Shuffle
-
Planejamento de memória on-heap e off-heap
-
alocação de espaço de memória
-
gerenciamento de memória de armazenamento
-
executar gerenciamento de memória
prefácio
Como um mecanismo de computação distribuída baseado em memória, o módulo de gerenciamento de memória do Spark desempenha um papel muito importante em todo o sistema . Compreender os fundamentos do gerenciamento de memória do Spark ajuda você a desenvolver melhor os aplicativos Spark e realizar o ajuste de desempenho. O objetivo deste artigo é classificar o contexto do gerenciamento de memória do Spark, apresentar algumas ideias e suscitar uma discussão aprofundada dos leitores sobre esse tópico. Os princípios descritos neste artigo são baseados na versão Spark 2.1. Para ler este artigo, os leitores precisam ter uma certa base Spark e Java e entender RDD, Shuffle, JVM e outros conceitos relacionados.
Ao executar um aplicativo Spark, o cluster Spark iniciará dois processos JVM, Driver e Executor. O primeiro é o processo mestre, responsável por criar o contexto Spark, enviar jobs Spark (Job) e converter os jobs em tarefas computacionais (Task) Cada processo Executor coordena o escalonamento de tarefas, este último é responsável por executar tarefas computacionais específicas nos nós de trabalho, retornar os resultados ao Driver e fornecer funções de armazenamento para RDDs que precisam ser persistentes. Como o gerenciamento de memória do Driver é relativamente simples, este artigo analisa principalmente o gerenciamento de memória do Executor.A memória Spark abaixo se refere à memória do Executor.
1. Histórico de evolução do Spark Shuffle
Na estrutura MapReduce, shuffle é a ponte entre Map e Reduce. A saída de Map deve passar pelo link de shuffle em Reduce. O desempenho de shuffle afeta diretamente o desempenho e a taxa de transferência de todo o programa. O Spark, como uma implementação do framework MapReduce, naturalmente também implementa a lógica do shuffle.
Shuffle é uma fase específica na estrutura do MapReduce. Ela está entre a fase Map e a fase Reduce. Quando o resultado de saída do Map deve ser usado pelo Reduce, o resultado de saída precisa ser hash por chave e distribuído para cada Reducer. Este processo é aleatório. Como o shuffle envolve leitura e gravação de disco e transmissão de rede, o desempenho do shuffle afeta diretamente a eficiência de execução de todo o programa.
A figura a seguir descreve claramente todo o processo do algoritmo MapReduce, onde a fase de embaralhamento está entre a fase Map e a fase Reduce.
Conceitualmente, shuffle é uma ponte para comunicar a conexão de dados, então como o shuffle (partição) é realmente implementado?Tomemos o Spark como exemplo para falar sobre a implementação do shuffle no Spark.
Vamos pegar a foto como exemplo para descrever brevemente todo o processo de shuffle no Spark:
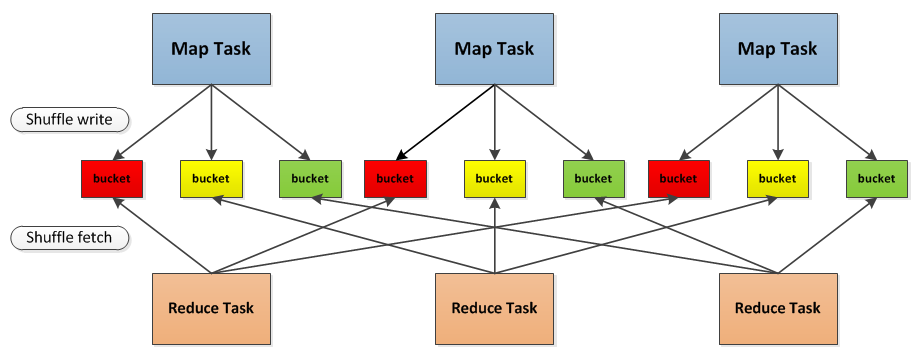
-
Primeiramente, cada Mapeador cria um bucket correspondente de acordo com o número de Redutores, sendo o número de buckets MM×RR, onde MM é o número de Mapas e RR é o número de Redutores.
-
Em segundo lugar, os resultados gerados pelo Mapper serão preenchidos em cada bucket de acordo com o algoritmo de partição definido. O algoritmo de partição aqui pode ser personalizado. Claro, o algoritmo padrão é fazer hash para diferentes buckets de acordo com a chave.
-
Quando o Redutor iniciar, ele obterá o bucket correspondente do gerenciador de bloco remoto ou local como entrada do Redutor de acordo com o id de sua própria tarefa e o id do Mapper do qual depende.
O bucket aqui é um conceito abstrato, na implementação, cada bucket pode corresponder a um arquivo, que pode corresponder a uma parte do arquivo ou outras.
O processo Shuffle do Apache Spark é semelhante ao processo Shuffle do Apache Hadoop, e alguns conceitos podem ser aplicados diretamente. Por exemplo, no processo Shuffle, a extremidade que fornece dados é chamada de extremidade Map, e cada tarefa que gera dados no o lado do mapa é chamado de Mapeador. Correspondentemente, o lado que recebe os dados é chamado de lado de redução, e cada tarefa que extrai dados do lado de redução é chamada de redutor. O processo Shuffle basicamente divide os dados obtidos do lado do mapa usando o particionador e envia os dados para o processo Redutor correspondente.
2. Planejamento de memória on-heap e off-heap
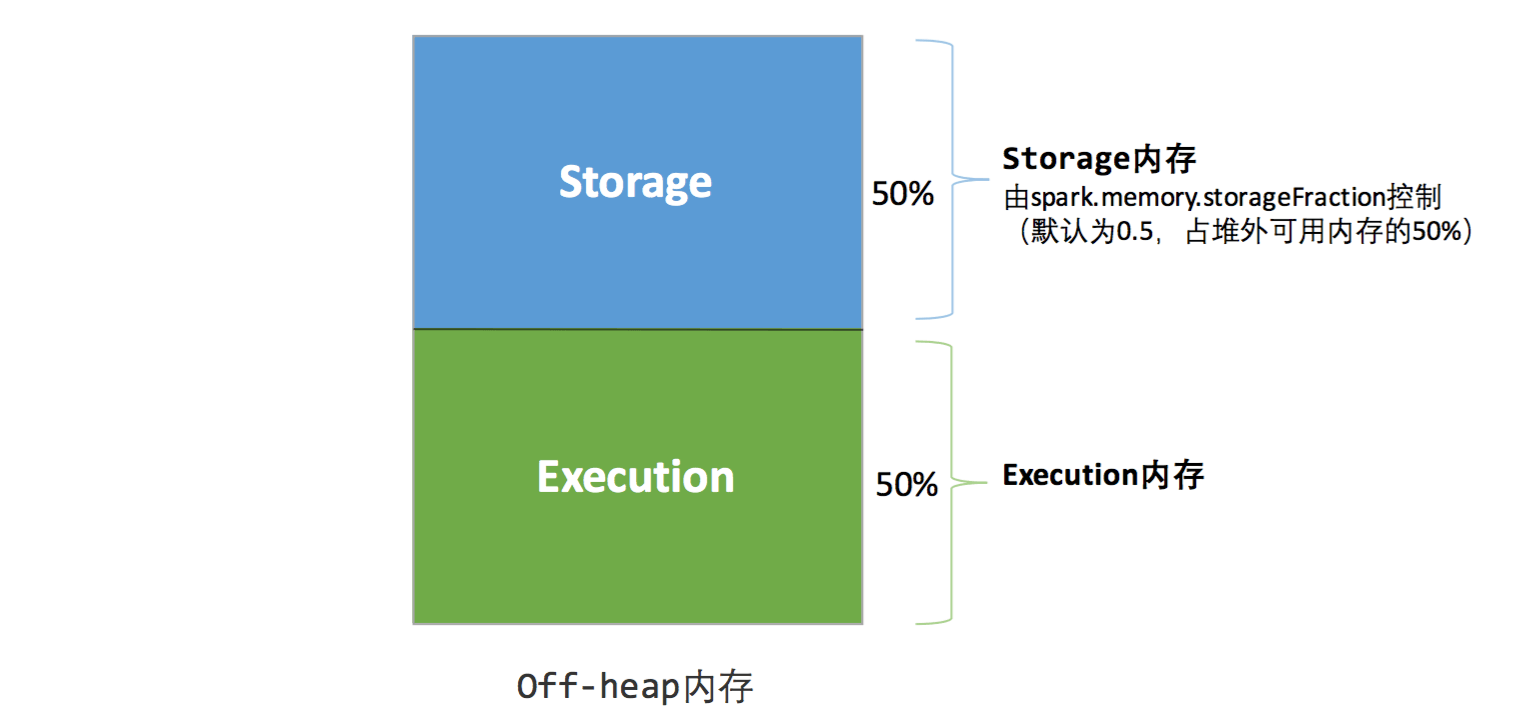
Como um processo JVM, o gerenciamento de memória do Executor é construído no gerenciamento de memória da JVM, e o Spark aloca o espaço no heap da JVM com mais detalhes para fazer uso total da memória. Ao mesmo tempo, o Spark introduz a memória off-heap, para que possa abrir diretamente espaço na memória do sistema do nó do trabalhador, o que otimiza ainda mais o uso da memória.
Diagrama esquemático de memória no heap e fora do heap:
2.1 Memória em heap
O tamanho da memória no heap, configurado pelo parâmetro ou –executor-memoryquando o aplicativo Spark é iniciado . spark.executor.memoryAs tarefas simultâneas em execução no Executor compartilham a memória heap da JVM. A memória ocupada por essas tarefas ao armazenar em cache dados RDD e transmitir dados é planejada como memória de armazenamento e a memória ocupada por essas tarefas ao executar Shuffle é planejada como memória de execução, o restante parte não for especialmente planejada, essas instâncias de objeto dentro do Spark ou instâncias de objeto em aplicativos Spark definidos pelo usuário ocupam o espaço restante. Em diferentes modos de gerenciamento, o espaço ocupado por essas três partes é diferente (apresentado na Seção 2 abaixo).
O gerenciamento de memória in-heap do Spark é um gerenciamento de "planejamento" lógico, pois a aplicação e liberação de memória ocupada por instâncias de objetos são concluídas pela JVM. O Spark só pode gravar a memória após a aplicação e antes do lançamento. Vejamos seu processo específico:
-
Solicitar memória :
-
Spark nova uma instância de objeto no código
-
A JVM aloca espaço da memória no heap, cria objetos e retorna referências de objetos
-
Spark salva uma referência ao objeto e registra a memória ocupada pelo objeto
-
Liberar memória :
-
O Spark grava a memória liberada pelo objeto e exclui a referência ao objeto
-
Aguarde o mecanismo de coleta de lixo da JVM liberar a memória heap ocupada pelo objeto
Sabemos que objetos JVM podem ser armazenados de forma serializada. O processo de serialização é converter objetos em fluxos de bytes binários. Em essência, pode ser entendido como converter armazenamento em cadeia em espaço não contínuo em espaço contínuo ou armazenamento em bloco. Quando Ao acessar, é necessário o processo inverso de serialização - desserialização, que converte o fluxo de bytes em um objeto.O método de serialização pode economizar espaço de armazenamento, mas aumenta a sobrecarga computacional ao armazenar e ler.
Para o objeto serializado no Spark, por estar na forma de fluxo de bytes, o tamanho da memória ocupada por ele pode ser calculado diretamente, enquanto para o objeto não serializado, a memória ocupada pelo objeto é estimada aproximadamente por amostragem periódica, ou seja, nem sempre que um novo item de dados é adicionado, o tamanho da memória ocupada será calculado uma vez. Este método reduz a sobrecarga de tempo, mas pode ter um grande erro, o que pode fazer com que a memória real em um determinado momento esteja muito além expectativas. Além disso, é muito provável que as instâncias de objetos marcadas para liberação pelo Spark não sejam realmente recuperadas pela JVM, resultando na memória real disponível sendo menor do que a memória disponível registrada pelo Spark. Portanto, o Spark não pode registrar com precisão a memória real disponível no heap, portanto, não pode evitar completamente as exceções de falta de memória (OOM, Out of Memory).
Embora a aplicação e a liberação da memória in-heap não possam ser controladas com precisão, o Spark pode decidir se deve armazenar em cache novos RDDs na memória de armazenamento e se deve alocar memória de execução para novas tarefas por meio de planejamento e gerenciamento independentes de memória de armazenamento e memória de execução. extensão, pode melhorar a utilização da memória e reduzir a ocorrência de exceções.
2.2 Memória fora do heap
Para otimizar ainda mais o uso da memória e melhorar a eficiência da classificação durante o Shuffle, o Spark introduz a memória off-heap, para que possa abrir diretamente espaço na memória do sistema de nós de trabalho para armazenar dados binários serializados. Usando a API JDK Unsafe (a partir do Spark 2.0, ela não é mais baseada no Tachyon ao gerenciar a memória de armazenamento fora do heap, mas é implementada com base na API JDK Unsafe como a memória de execução fora do heap), o Spark pode operar diretamente o memória off-heap, reduzindo a sobrecarga de memória desnecessária, bem como varreduras e coletas frequentes de GC, melhorando o desempenho do processamento. A memória off-heap pode ser aplicada e liberada com precisão, e o espaço ocupado pelos dados serializados pode ser calculado com precisão, portanto, comparado com a memória on-heap, a dificuldade de gerenciamento é reduzida e o erro também é reduzido.
Por padrão, a memória off-heap não está habilitada, ela pode ser habilitada através do spark.memory.offHeap.enabledparâmetro e spark.memory.offHeap.sizeo tamanho do espaço off-heap é definido pelo parâmetro. Exceto que não há outro espaço, a memória off-heap é dividida da mesma forma que a memória on-heap e todas as tarefas simultâneas em execução compartilham memória de armazenamento e memória de execução.
2.3 Interface de Gerenciamento de Memória
O Spark fornece uma interface unificada para gerenciamento de memória de armazenamento e memória de execução - MemoryManager. Tarefas no mesmo Executor chamam os métodos dessa interface para solicitar ou liberar memória:
Listagem 1: Principais métodos da interface de gerenciamento de memória
| nome | método |
|---|---|
| 1. Solicite memória de armazenamento | def adquirirStorageMemory(blockId: BlockId, numBytes: Long, memoryMode: MemoryMode): Boolean |
| 2. Aplique para expandir a memória | def adquirirUnrollMemory(blockId: BlockId, numBytes: Long, memoryMode: MemoryMode): Boolean |
| 3. Solicitar memória de execução | def adquirirExecutionMemory(numBytes: Long, taskAttemptId: Long, memoryMode: MemoryMode): Long |
| 4. Libere memória de armazenamento | def releaseStorageMemory(numBytes: Long, memoryMode: MemoryMode): Unidade |
| 5. Libere a memória de execução | def releaseExecutionMemory(numBytes: Long, taskAttemptId: Long, memoryMode: MemoryMode): Unit |
| 6. Memória de desenrolamento livre | def releaseUnrollMemory(numBytes: Long, memoryMode: MemoryMode): Unidade |
Vemos que ao chamar esses métodos, você precisa especificar seu modo de memória (MemoryMode).Esse parâmetro determina se a operação é feita no heap ou fora do heap.
Em termos de implementação específica do MemoryManager, o Spark 1.6 assume como padrão o modo Unified Memory Manager, e o modo Static Memory Manager usado antes do 1.6 ainda está reservado, que pode ser habilitado configurando o parâmetro spark.memory.useLegacyMode. A diferença entre os dois métodos está na forma de alocação de espaço.A seção 2 a seguir apresentará esses dois métodos respectivamente.
3. Alocação de espaço de memória
3.1 Gerenciamento de Memória Estática
Sob o mecanismo de gerenciamento de memória estática originalmente adotado pelo Spark, os tamanhos de memória de armazenamento, memória de execução e outras memórias são fixos durante a execução do aplicativo Spark, mas os usuários podem configurá-lo antes do início do aplicativo. A alocação de memória no heap é mostrada em a figura abaixo. Mostrar:
Diagrama de gerenciamento de memória estática - dentro do heap :
Como você pode ver, o tamanho da memória heap disponível precisa ser calculado da seguinte forma:
Memória de armazenamento disponível =systemMaxMemory * spark.storage.memoryFraction * spark.storage.safetyFraction
Memória de execução disponível =systemMaxMemory * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction
O systemMaxMemory depende do tamanho da memória heap da JVM atual e a última memória de execução ou memória de armazenamento disponível é multiplicada pelos respectivos parâmetros memoryFraction e safetyFraction nessa base. O significado dos dois parâmetros de securityFraction na fórmula de cálculo acima é reservar logicamente uma área de seguro como 1-safetyFraction para reduzir o risco de OOM causado pela memória real excedendo o intervalo predefinido atual (mencionado acima, para amostragem de memória não sequencial estimativa do objeto está sujeita a erro). Vale ressaltar que esta área de seguro reservada é apenas um plano lógico, não o Spark trata de forma diferente quando é utilizado, é entregue à JVM para gerenciar como "outra memória".
A alocação de espaço fora do heap é relativamente simples, apenas memória de armazenamento e memória de execução, conforme mostrado na figura a seguir. O tamanho do espaço ocupado pela memória de execução e memória de armazenamento disponível é determinado diretamente pelo parâmetro spark.memory.storageFraction. Como o espaço ocupado pela memória off-heap pode ser calculado com precisão, não há necessidade de definir a área de seguro .
Diagrama de gerenciamento de memória estática - fora do heap:
O mecanismo de gerenciamento de memória estática é relativamente simples de implementar, mas se os usuários não estiverem familiarizados com o mecanismo de armazenamento do Spark, ou não fizerem as configurações correspondentes de acordo com a escala de dados e tarefas de computação específicas, é fácil causar uma situação de "meia água do mar, half flame", ou seja, armazenamento Um lado da memória e memória de execução tem muito espaço sobrando, enquanto o outro lado se enche cedo e precisa despejar ou mover conteúdo antigo para armazenar conteúdo novo. Devido ao surgimento do novo mecanismo de gerenciamento de memória, esse método é raramente utilizado pelos desenvolvedores.Para fins de compatibilidade com versões mais antigas de aplicativos, o Spark ainda mantém sua implementação.
3.2 Gerenciamento de Memória Unificado
O mecanismo de gerenciamento de memória unificado introduzido após o Spark 1.6 difere do gerenciamento de memória estática, pois a memória de armazenamento e a memória de execução compartilham o mesmo espaço e podem ocupar dinamicamente a área livre uma da outra, conforme mostrado nas duas figuras a seguir
Diagrama de gerenciamento de memória unificado - dentro do heap:

Diagrama de gerenciamento de memória unificado - fora do heap:
Uma das otimizações mais importantes é o mecanismo de ocupação dinâmica, cujas regras são as seguintes:
-
Defina a memória de armazenamento básica e a área de memória de execução (
spark.storage.storageFraction 参数), que determina o intervalo de espaço que cada um possui -
Quando o espaço de ambas as partes for insuficiente, será armazenado no disco rígido; se o espaço de uma parte for insuficiente e o espaço da outra parte estiver livre, o espaço da outra parte poderá ser emprestado; (espaço de armazenamento insuficiente significa que não é suficiente colocar um bloco completo)
-
Após o espaço de memória de execução ser ocupado pela outra parte, a outra parte pode transferir a parte ocupada para o disco rígido e, em seguida, "devolver" o espaço emprestado
-
Depois que o espaço de armazenamento é ocupado pela outra parte, ele não pode ser "devolvido" pela outra parte, pois muitos fatores no processo de embaralhamento precisam ser considerados, o que é mais complicado de implementar.
Diagrama do mecanismo de ocupação dinâmica:
Com o mecanismo de gerenciamento de memória unificado, o Spark melhora a utilização de recursos de memória on-heap e off-heap até certo ponto e reduz a dificuldade para os desenvolvedores manterem a memória Spark, mas isso não significa que os desenvolvedores possam sentar e relaxar. Por exemplo, se o espaço de memória de armazenamento for muito grande ou os dados armazenados em cache forem muito grandes, isso levará à coleta de lixo completa frequente e reduzirá o desempenho da execução da tarefa, porque os dados RDD armazenados em cache geralmente residem na memória por um longo tempo . Portanto, para aproveitar ao máximo o desempenho do Spark, os desenvolvedores precisam entender melhor os métodos de gerenciamento e os princípios de implementação de memória de armazenamento e memória de execução.
4. Gerenciamento de memória de armazenamento
4.1 Mecanismo de Persistência de RDD
Resilient Distributed Dataset (RDD), como a abstração de dados mais fundamental do Spark, é uma coleção de registros de partição somente leitura (Partition), que só podem ser criados com base em conjuntos de dados em armazenamento físico estável ou em outros RDDs existentes. (Transformação) para gerar um novo RDD. As dependências resultantes entre o RDD transformado e o RDD original constituem a linhagem. Com a linhagem, o Spark garante que todo RDD pode ser recuperado. Mas todas as transformações do RDD são preguiçosas, ou seja, somente quando ocorre uma ação (Action) que retorna um resultado para o Driver, o Spark criará uma tarefa para ler o RDD, e então acionará de fato a execução da transformação.
Quando a Tarefa lê uma partição no início da inicialização, ela primeiro determinará se a partição foi persistida, caso contrário, ela precisa verificar o Checkpoint ou recalcular de acordo com a linhagem. Portanto, se você deseja executar várias ações em um RDD, pode usar o método persist ou cache na primeira ação para persistir ou armazenar em cache o RDD na memória ou no disco, para melhorar a velocidade de cálculo nas ações subsequentes. Na verdade, o método de cache usa o nível de armazenamento MEMORY_ONLY padrão para persistir o RDD na memória, portanto, o cache é um tipo especial de persistência. O design de memória de armazenamento on-heap e off-heap permite planejamento e gerenciamento unificados da memória usada ao armazenar em cache RDDs (outros cenários de aplicativos de memória de armazenamento, como armazenamento em cache de dados de transmissão, estão temporariamente fora do escopo deste artigo).
A persistência do RDD fica a cargo do módulo Storage do Spark, que realiza o desacoplamento do RDD e do armazenamento físico. O módulo Storage é responsável por gerenciar os dados gerados pelo Spark no processo de computação, e encapsula as funções de acesso a dados em memória ou disco, local ou remotamente. Na implementação específica, os módulos Storage do lado do Driver e do lado do Executor constituem uma arquitetura mestre-escravo, ou seja, o BlockManager do lado do Driver é o Mestre e o BlockManager do lado do Executor é o Escravo. O módulo de armazenamento usa logicamente o bloco como a unidade básica de armazenamento, e cada partição do RDD corresponde exclusivamente a um bloco após o processamento (o formato do BlockId é rdd_RDD-ID_PARTITION-ID). O Mestre é responsável pelo gerenciamento e manutenção das informações de metadados do Bloco de toda a aplicação Spark, e o Escravo precisa reportar a atualização do bloco e demais status ao Mestre, e receber comandos do Mestre, como adicionar ou deletar um RDD.
Diagrama do módulo de armazenamento:
Ao persistir RDDs, o Spark especifica 7 níveis de armazenamento diferentes, como , e o nível de armazenamento é uma combinação das 5 variáveis a seguir MEMORY_ONLY:MEMORY_AND_DISK
class StorageLevel private(
private var _useDisk: Boolean, //磁盘
private var _useMemory: Boolean, //这里其实是指堆内内存
private var _useOffHeap: Boolean, //堆外内存
private var _deserialized: Boolean, //是否为非序列化
private var _replication: Int = 1 //副本个数
)
Através da análise da estrutura de dados, pode-se observar que o nível de armazenamento define o método de armazenamento da Partição do RDD (também conhecido como Bloco) a partir de três dimensões:
-
Local de armazenamento : Disco/memória no heap/memória fora do heap. Por exemplo, MEMORY_AND_DISK é armazenado no disco e na memória heap ao mesmo tempo, realizando backup redundante. OFF_HEAP é armazenado apenas na memória off-heap. Atualmente, quando a memória off-heap é selecionada, ela não pode ser armazenada em outros locais ao mesmo tempo.
-
Forma de armazenamento : se o bloco está em um formato não serializado após ser armazenado em cache na memória de armazenamento. Por exemplo, MEMORY_ONLY é armazenado no modo não serializado e OFF_HEAP é armazenado no modo serializado.
-
O número de réplicas : quando for maior que 1, o backup redundante remoto é necessário para outros nós. Por exemplo, DISK_ONLY_2 requer uma cópia de backup remota.
4.2 O processo de cache RDD
Antes que o RDD seja armazenado em cache na memória de armazenamento, os dados em Partition geralmente são acessados como uma estrutura de dados iteradora (Iterator), que é um método de percorrer uma coleção de dados na linguagem Scala. Iterator pode ser usado para obter cada item de dados serializado ou não serializado (Record) na partição. As instâncias de objeto desses Records ocupam logicamente o espaço da outra parte da memória no heap da JVM. O espaço de diferentes Records no mesma partição não é contínua.
Depois que o RDD é armazenado em cache na memória de armazenamento, a partição é convertida em um bloco e o registro ocupa um espaço contínuo na memória de armazenamento heap ou off-heap. O processo de conversão de partição de espaço de armazenamento descontínuo para espaço de armazenamento contínuo, Spark chama de "Unroll". Block possui dois formatos de armazenamento, serializado e não serializado, dependendo do nível de armazenamento do RDD. O bloco não serializado é definido por uma estrutura de dados DeserializedMemoryEntry, e um array é usado para armazenar todas as instâncias do objeto, enquanto o bloco serializado é definido pela estrutura de dados SerializedMemoryEntry, usando um buffer de bytes (ByteBuffer) para armazenar dados binários. O módulo Storage de cada Executor utiliza uma estrutura de Map vinculado (LinkedHashMap) para gerenciar as instâncias de todos os objetos Block na memória de armazenamento heap e off-heap. Adicionar e excluir este LinkedHashMap indiretamente registra a aplicação e liberação de memória.
Como não há garantia de que o espaço de armazenamento possa acomodar todos os dados no Iterator de uma só vez, a tarefa de computação atual precisa solicitar espaço suficiente de Unroll para o MemoryManager ocupar temporariamente o espaço durante o Unroll. Para uma partição serializada, o espaço de desbloqueio necessário pode ser calculado diretamente e aplicado de uma só vez. Partições não serializadas precisam ser aplicadas por sua vez durante o processo de travessia de Registros, ou seja, cada vez que um Registro for lido, amostrar e estimar o espaço necessário para Unroll e solicitar. o espaço de Unroll ocupado pode ser liberado. Se o Unroll final for bem-sucedido, o espaço de Unroll ocupado pela partição atual será convertido no espaço de armazenamento RDD de cache normal, conforme mostrado na figura a seguir.
Diagrama esquemático do Spark Unroll :
Como você pode ver na seção sobre gerenciamento de memória estática acima, durante o gerenciamento de memória estática, o Spark divide especialmente uma parte do espaço Unroll na memória de armazenamento e seu tamanho é fixo. Quando o espaço de armazenamento for insuficiente, será processado de acordo com o mecanismo de ocupação dinâmica.
4.3 Eliminação e colocação
Como todas as tarefas computacionais de um mesmo Executor compartilham espaço de memória de armazenamento limitado, quando há um novo Bloco que precisa ser armazenado em cache, mas o espaço restante é insuficiente e não pode ser ocupado dinamicamente, o Bloco antigo no LinkedHashMap deve ser Despejado e eliminado. o nível de armazenamento do bloco também inclui o requisito de armazenamento em disco, ele precisa ser descartado (Drop), caso contrário o bloco é excluído diretamente.
As regras de eliminação para memória de armazenamento são :
-
O Bloco antigo que foi eliminado deve ter o mesmo MemoryMode que o novo Bloco, ou seja, ambos pertencem à memória off-heap ou on-heap
-
Blocos antigos e novos não podem pertencer ao mesmo RDD para evitar a eliminação circular
-
O RDD ao qual o bloco antigo pertence não pode ser lido para evitar problemas de consistência
-
Percorra os blocos no LinkedHashMap e elimine-os na ordem de uso menos recente (LRU) até que o espaço requerido pelo novo bloco seja satisfeito. Onde LRU é a característica de LinkedHashMap.
-
O processo de colocação do disco é relativamente simples. Se seu nível de armazenamento atender à condição de que _useDisk seja verdadeiro, julgue se ele está em uma forma não serializada de acordo com seu _desserializado e, em caso afirmativo, serialize-o e, finalmente, armazene os dados para o disco, atualize suas informações no módulo.
5. Execute o gerenciamento de memória
5.1 Alocação de memória entre multitarefa
As tarefas executadas no Executor também compartilham a memória de execução e o Spark usa uma estrutura HashMap para salvar o mapeamento das tarefas para o consumo de memória. O tamanho da memória de execução que cada tarefa pode ocupar varia de 1/2N a 1/N, onde N é o número de tarefas em execução no Executor atual. Quando cada tarefa é iniciada, ela precisa solicitar pelo menos 1/2 N de memória de execução do MemoryManager. Se o requisito não puder ser atendido, a tarefa será bloqueada e a tarefa poderá ser despertada até que outra tarefa libere memória de execução suficiente.
5.2 Uso de memória aleatória
A memória de execução é usada principalmente para armazenar a memória ocupada pela tarefa ao executar o Shuffle. Shuffle é o processo de reparticionamento de dados RDD de acordo com certas regras. Vejamos o uso da memória de execução nas fases Write e Read do Shuffle:
Gravação aleatória
-
Se o método de ordenação normal for selecionado no lado do mapa, o ExternalSorter será usado para saída, e o espaço de execução no heap será ocupado principalmente ao armazenar dados na memória.
-
Se o método de classificação Tungsten for selecionado no lado do mapa, ShuffleExternalSorter é usado para classificar diretamente os dados armazenados no formato serializado. Ao armazenar dados na memória, eles podem ocupar espaço de execução fora do heap ou no heap, dependendo do se o usuário habilitou a memória fora do heap e se a memória de execução fora do heap é suficiente.
Leitura aleatória
Quando os dados no lado de redução são agregados, os dados devem ser entregues ao Agregador para processamento e o espaço de execução no heap é ocupado quando os dados são armazenados na memória.
Se o resultado final precisar ser classificado, os dados devem ser entregues ao ExternalSorter para processamento novamente, ocupando o espaço de execução no heap.
Em ExternalSorter e Aggregator, o Spark usará uma tabela de hash chamada AppendOnlyMap para armazenar dados na memória de execução do heap, mas nem todos os dados podem ser armazenados na tabela de hash durante o processo Shuffle, quando a tabela de hash ocupa A memória será amostrada e estimada periodicamente. Quando for muito grande para solicitar uma nova memória de execução do MemoryManager, o Spark armazenará todo o seu conteúdo no arquivo do disco. Esse processo é chamado de estouro ( Spill), os arquivos que são derramados no disco serão mesclados (Merge) .
O Tungstênio usado na fase Shuffle Write é um plano proposto pela Databricks para otimizar o uso de memória e CPU para Spark, que resolve algumas limitações e desvantagens de desempenho da JVM. O Spark escolherá automaticamente se deseja usar a classificação de tungstênio de acordo com o Shuffle. O mecanismo de gerenciamento de memória baseado em página adotado pelo Tungsten é construído no MemoryManager, ou seja, o Tungsten abstrai o uso da memória de execução em uma etapa, de modo que no processo Shuffle, você não precisa se preocupar se os dados são armazenados no pilha ou fora da pilha. Cada página de memória é definida por um MemoryBlock, e as duas variáveis de Object obj e long offset são usadas para identificar uniformemente o endereço de uma página de memória na memória do sistema. O MemoryBlock no heap é a memória alocada na forma de um array longo. O valor de obj é a referência do objeto do array. O deslocamento é o endereço de deslocamento inicial do array longo na JVM. Os dois podem ser usados juntos O endereço absoluto no heap, o MemoryBlock fora do heap é o bloco de memória diretamente aplicado, seu obj é nulo e o deslocamento é o endereço absoluto de 64 bits desse bloco de memória na memória do sistema. O Spark usa MemoryBlock para encapsular de forma sutil e abstrata as páginas de memória no heap e fora do heap e usa a tabela de páginas (pageTable) para gerenciar as páginas de memória aplicadas por cada tarefa.
Toda a memória sob o gerenciamento de página Tungsten é representada por um endereço lógico de 64 bits, consistindo em um número de página e um deslocamento dentro da página:
-
Número de página: ocupa 13 bits e identifica exclusivamente uma página de memória. O Spark deve solicitar um número de página livre antes de solicitar uma página de memória.
-
Deslocamento na página: ocupando 51 bits, é o endereço de deslocamento dos dados na página quando a página de memória é usada para armazenar os dados.
Com um método de endereçamento unificado, o Spark pode usar um ponteiro de endereço lógico de 64 bits para localizar a memória dentro ou fora do heap. Todo o processo de classificação Shuffle Write só precisa classificar os ponteiros e não requer desserialização. Todo o processo é muito eficiente . , o que melhora significativamente a eficiência do acesso à memória e a eficiência do uso da CPU.
A memória de armazenamento e a memória de execução do Spark têm métodos de gerenciamento completamente diferentes : para memória de armazenamento, o Spark usa um LinkedHashMap para gerenciar centralmente todos os Blocos, que são convertidos da partição do RDD que precisa ser armazenada em cache; e para memória de execução, o Spark usa AppendOnlyMap é usado para armazenar os dados no processo Shuffle e até mesmo abstraído no gerenciamento de memória baseado em página na classificação Tungsten, abrindo um novo mecanismo de gerenciamento de memória JVM.