Há um ssqdatav2dado, para encontrar Shenzhen e substituí-lo por Shenzhen.
Devido a erros nos dados coletados, Shenzhen aparece onde apenas a província é abreviada.
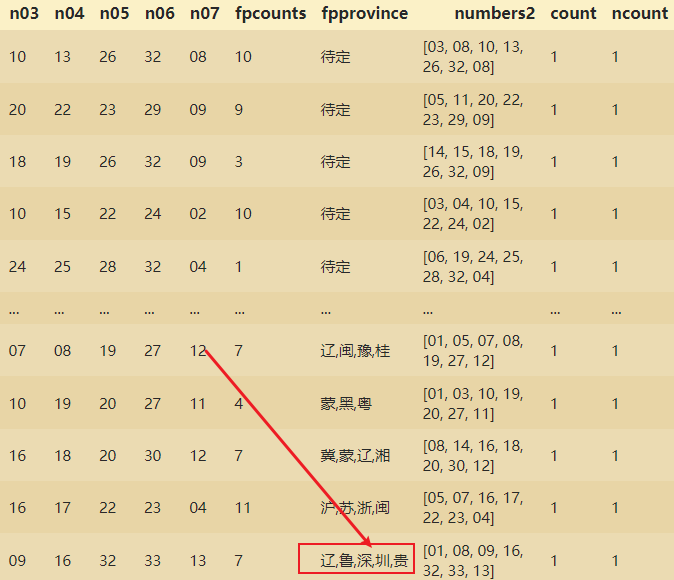
Como encontrar dados que contenham Shenzhen no DF?
cond=ssqdatav2['first'].str.contains('深圳')
ssqdatav2.loc[cond]
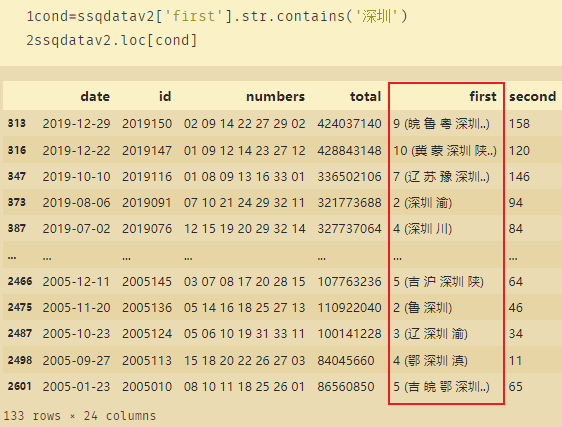
Neste ponto, os dados contendo Shenzhen no primeiro são encontrados.
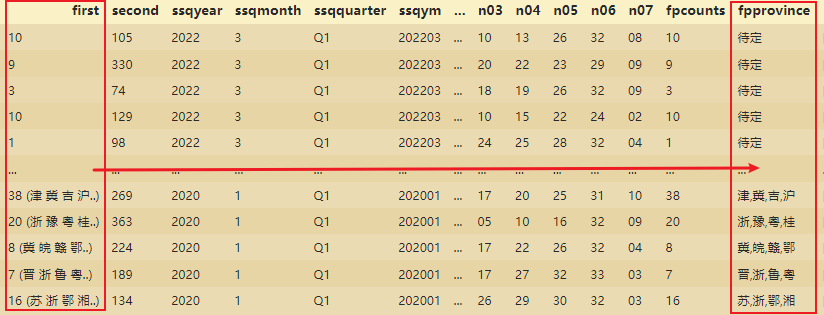
1. Encontre os caracteres chineses primeiro
# 为分解firstprize定义函数
def fpp(x):
if len(x)<=2: # 判断是否只有汉字,还是也有数字
return "待定" # 没有汉字的用待定表示
else: # 使用正则表达式获取中文
pattern="[\u4e00-\u9fa5]" # 汉字专用字符ASCII区间
pat=re.compile(pattern)
return ','.join(pat.findall(x)) # 使用逗号作为每个省份的分隔符
#使用fp()
ssqdatav2['fpprovince']=ssqdatav2['first'].apply(lambda x:fpp(x))
ssqdatav2.head()
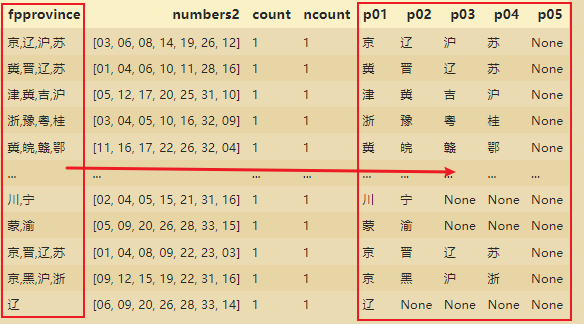
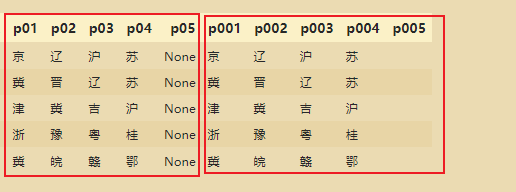
Forme cada província em uma coluna separada:
fpnames=['p01','p02','p03','p04','p05']
ssqdatav3[fpnames]=ssqdatav3['fpprovince'].str.split(',',expand=True)
ssqdatav3
Remova o valor None e o lugar de None se torna um valor nulo:
# 逐个分割
ssqdatav3['p001']=ssqdatav3['fpprovince'].apply(lambda x:x if x.count(',')==0 else x.split(',')[0])
ssqdatav3['p002']=ssqdatav3['fpprovince'].apply(lambda x:x.split(',')[1] if x.count(',')>=1 else '')
ssqdatav3['p003']=ssqdatav3['fpprovince'].apply(lambda x:x.split(',')[2] if x.count(',')>=2 else '')
ssqdatav3['p004']=ssqdatav3['fpprovince'].apply(lambda x:x.split(',')[3] if x.count(',')>=3 else '')
ssqdatav3['p005']=ssqdatav3['fpprovince'].apply(lambda x:x.split(',')[4] if x.count(',')>=4 else '')
ssqdatav3.to_excel('ssqdatav3p05.xlsx',index=False)
ssqdatav3.head()
# 让双色球的期号ID成为订单号,7个号码都有对应的订单号,即每个期号都有7个订单号且分成不同的行
import numpy as np
ssqdatav3['province2']=ssqdatav3['fpprovince'].apply(lambda x:x.split(','))
ssqdatav3
province2=ssqdatav3['province2'].to_list()
province2
rs=[len(r) for r in province2]
rs
a=np.repeat(ssqdatav3['id'],rs)
a
ssqdataprov=pd.DataFrame(np.column_stack((a,np.concatenate(province2))),columns=['ID','PROVINCE'])
# ssqdataprov=ssqdataprov[(ssqdataprov['PROVINCE']!='深')] # 等价
# ssqdataprov=ssqdataprov[~(ssqdataprov['PROVINCE']=='深')] # 等价
ssqdataprov=ssqdataprov[~(ssqdataprov['PROVINCE'].str.contains('深'))]
ssqdataprov
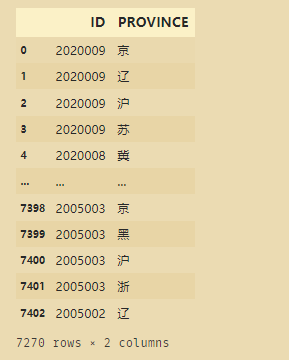
Divida de acordo com cada campo e exclua os campos que contêm deep, para que apenas a palavra "Zhen" seja mantida.