Diretório de artigos
- I. Introdução
- 2. Separação de leitura e gravação Sharding-JDBC
-
- 2.1 Separação de leitura e gravação
- 2.2 A prática da separação da leitura e da escrita
- 2.3 Roteando solicitações diferentes para bancos de dados diferentes
- 2.4 Experiência na construção de replicação mestre-escravo (notas a serem observadas/poços comuns)
-
- 2.4.1 instalação mínima vmware centos7 duas etapas
- 2.4.2 Passos para instalar o mysql no centos
- 2.4.3 O arquivo de configuração my.cnf não pode ser encontrado no diretório /etc
- 2.4.4 `alterar mestre para xxx` série de perguntas
- 2.4.5 mysql pode ser iniciado e usado no centos, mas navicat local não pode se conectar ao mysql
- 3. Transação Distribuída de Fragmentação JDBC
- Quarto, o fim
I. Introdução
Este artigo apresenta principalmente a separação de leitura /gravação do ShardingJDBC e as transações distribuídas
.
2. Separação de leitura e gravação Sharding-JDBC
2.1 Separação de leitura e gravação
A base teórica da separação leitura-gravação: dividida em biblioteca mestre e biblioteca escrava, as operações de inserção/atualização/exclusão são roteadas para a biblioteca mestre, as operações de seleção são roteadas para a biblioteca escrava e a biblioteca escrava sincroniza os dados da biblioteca mestre através do log binlog (componente do canal).
Configuração de separação de leitura-gravação do MySQL
(1) Habilite o log de log binário do servidor mestre e permita que o nó escravo leia o log de log binário (o mysql não abre o log binário por padrão)
(2) O nó escravo, especifique um arquivo de log binário e o deslocamento sincronizado
- especifique o ip
do nó mestre - nome de usuário e senha para executar o nó mestre
Vamos construir um modelo de banco de dados mestre-escravo para demonstrar o processo de configuração do banco de dados mestre-escravo.Primeiro, prepare dois servidores e instale o mysql8.0 antecipadamente.
2.2 A prática da separação da leitura e da escrita
2.2.1 configuração do nó mestre
Ative o log binlog do servidor mestre e permita que o nó escravo leia o log binlog
O primeiro passo: editar o arquivo my.inf do mysql (porque o mysql não abre o log binlog por padrão, então você precisa abrir manualmente o log binlog do servidor master)
vim /etc/my.inf
log-bin=/var/lib/mysql/mysql-bin
server-id=1001
Etapa 2: use o seguinte comando para reiniciar o mysql
systemctl restart mysqld
Etapa 3: Após a inicialização ser bem-sucedida, dois arquivos podem ser gerados no diretório /var/lib/mysql/mysql-bin.
[root@localhost ~]# ls /var/lib/mysql/mysql-bin.
mysql-bin.000001 mysql-bin.index
Etapa 4: você pode ver o status de abertura do bin-log por meio da seguinte instrução
show variables like 'log_bin%';
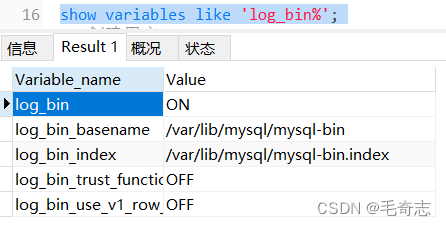
Passo 5: Crie um usuário com a permissão de cópia de dados do banco de dados especificada na biblioteca Master. Quando a biblioteca slave acessa a conexão de dados, ela precisa usar a conta para se conectar, realizar operações de autorização e atualizar as informações de permissão.
-- replication slave 表示授权复制 -- *.* 表示所有的库和表
-- 创建用户,其中repl表示用户名,192.168.100.137表示slave库的ip地址,
-- 也就是只允许这个ip通过repl用户访问master库
grant replication slave on *.* to 'repl'@'192.168.100.137'
identified by '123456' with grant option;
-- 刷新权限信息
flush privileges;
2.2.2 configuração do nó escravo
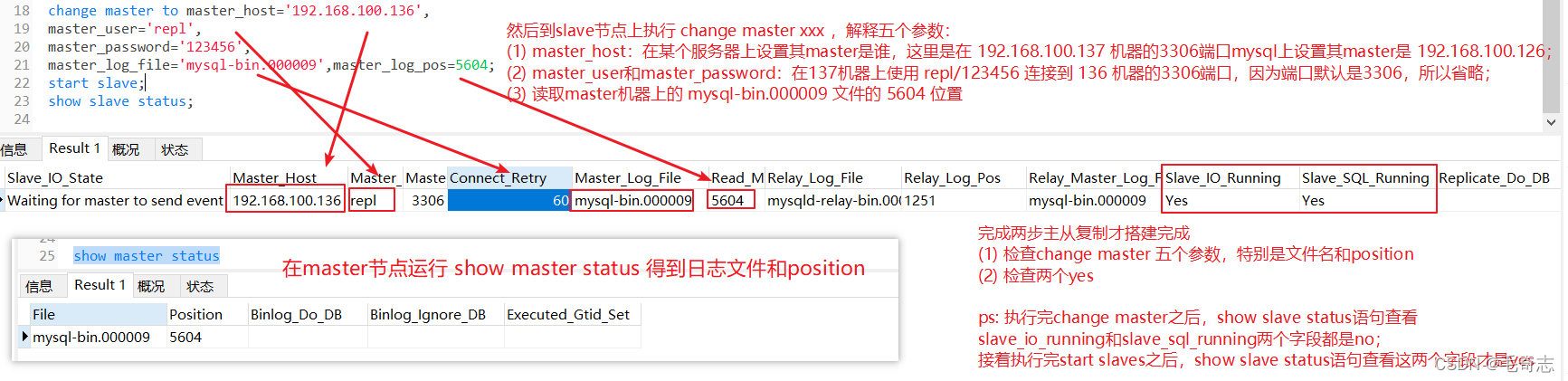
Etapa 1: no nó mestre, use o comando a seguir para entender o status do nó mestre, da seguinte maneira:
show master status

Etapa 2: execute o seguinte comando no nó escravo
change master to master_host='192.168.100.136',
master_user='repl',
master_password='123456',
master_log_file='mysql-bin.000009',master_log_pos=5604;
master_log_file é o nome do arquivo obtido na
primeira etapa master_log_pos é a posição de sincronização obtida na primeira etapa
O valor padrão da porta é 3306, portanto, o nó mestre não é especificado aqui.
Etapa 3: iniciar a sincronização do escravo
start slave;
Passo 4: Teste, verifique o status da sincronização, conforme mostrado na figura abaixo, indicando que a sincronização mestre-escravo foi construída com sucesso, então crie uma nova tabela no nó mestre, insira um dado, e o nó escravo também possui essa mesa.
show slave status

Neste ponto, a estrutura mestre-escravo do mysql é implantada, de modo que select seja roteado para a biblioteca escrava e insert/update/delete seja roteado para a biblioteca principal.
eg1: Você também pode usar o componente de canal para monitorar as mudanças no log binlog do nó mestre.
Se você quiser ver o log binário da biblioteca principal, você pode fazer o seguinte
show binary logs
show binlog events in 'mysql-bin.000009'
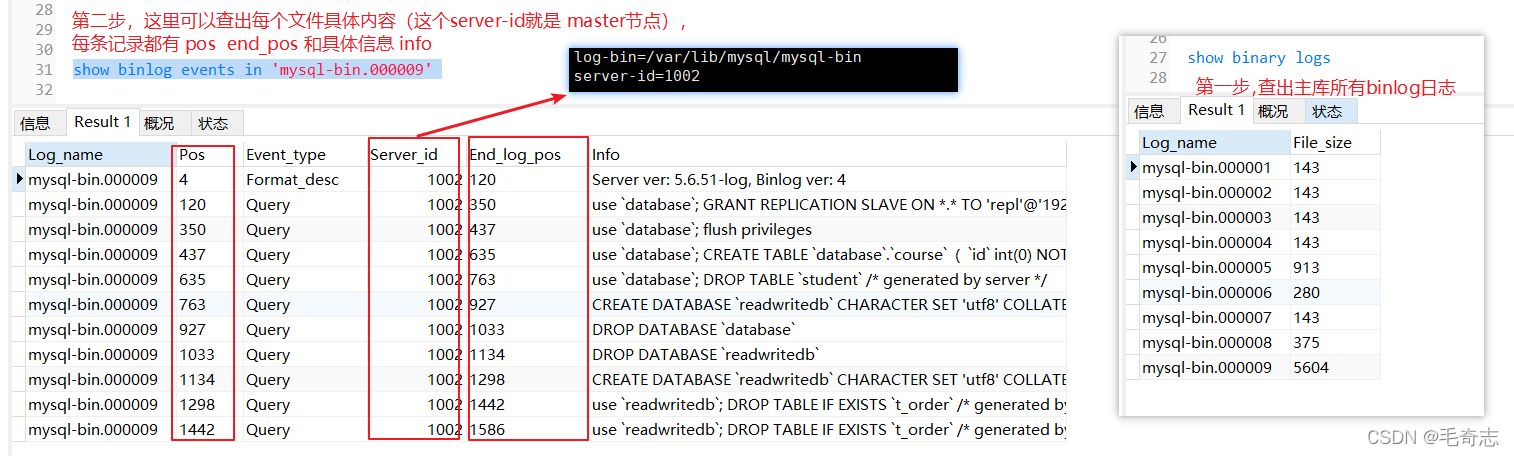
Antes de criar um novo banco de dados e uma nova tabela, verifique dois pontos
(1) No nó escravo, tanto io quanto sql são sim
(2) No nó escravo, o nome do arquivo binlong e o deslocamento monitorado são os mesmos que o nome do arquivo binlong atual e deslocamento do nó mestre
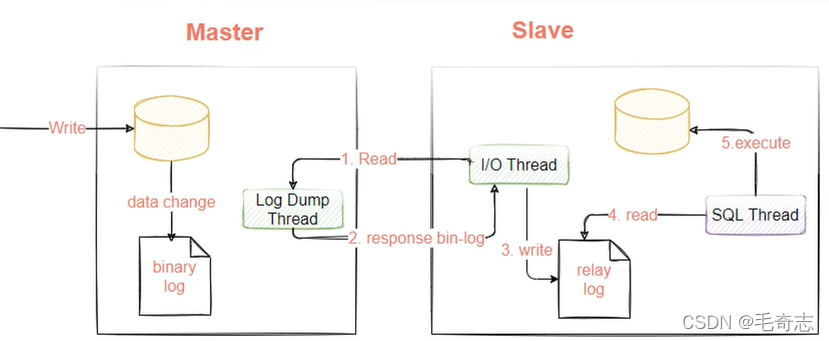
Como o princípio da replicação mestre-escravo é de dois arquivos de log, três threads, o log de binlog do nó mestre e o thread de despejo de log de log, o log de log de retransmissão do nó escravo e o thread de E/S, thread de thread SQL, então o nó escravo deve garantir que tanto io quanto sql são sim, conforme mostrado abaixo:
No nó escravo, o nome e o deslocamento do arquivo binlong monitorado são consistentes com o nome do arquivo binlong atual e o deslocamento do nó mestre, ou seja, o arquivo monitorado pelo nó escravo deve ser o mesmo que a posição atual do arquivo do nó escravo. nó mestre para ler a próxima operação do nó mestre, conforme mostrado na figura a seguir:
Somente após os dois pontos acima serem garantidos, a replicação mestre-escravo pode funcionar normalmente, ou seja, o nó mestre cria um novo banco de dados readwritedb, atualiza o nó escravo, também haverá um readwritedb, o nó mestre cria uma nova tabela t_order em readwritedb, e também haverá um readwritedb no nó escravo.tabela t_order.
Nota 1: Quando o nó mestre cria um novo readwritedb, ele usa o conjunto de caracteres utf8mb4 e não preenche o agrupamento, conforme mostra a figura:
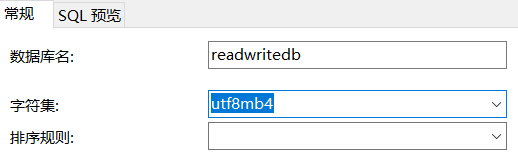
Nota 2: Quando o nó mestre cria uma nova tabela t_order, execute a seguinte
DROP TABLE IF EXISTS `t_order`;
CREATE TABLE `t_order` (
`order_id` bigint NOT NULL AUTO_INCREMENT,
`user_id` int NOT NULL,
`address_id` bigint NOT NULL,
`status` varchar(50) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB AUTO_INCREMENT=624279674839085057 DEFAULT CHARSET=utf8mb4;
2.3 Roteando solicitações diferentes para bancos de dados diferentes
Crie um novo projeto springboot, a interface da classe do controlador é a seguinte:

O arquivo de configuração é o seguinte:
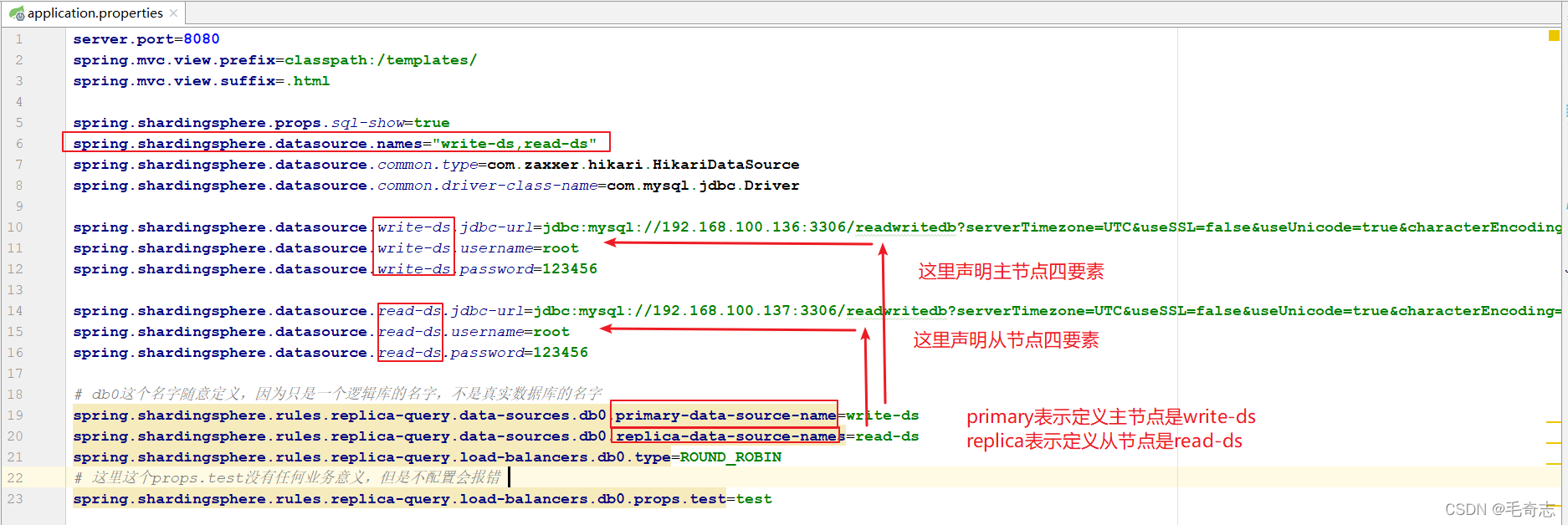
Execute, acesse o navegador Chrome http://localhost:8080/swagger-ui.html e selecione a classe do controlador de interface para entrar
Envie uma solicitação no swagger e teste a interface de postagem
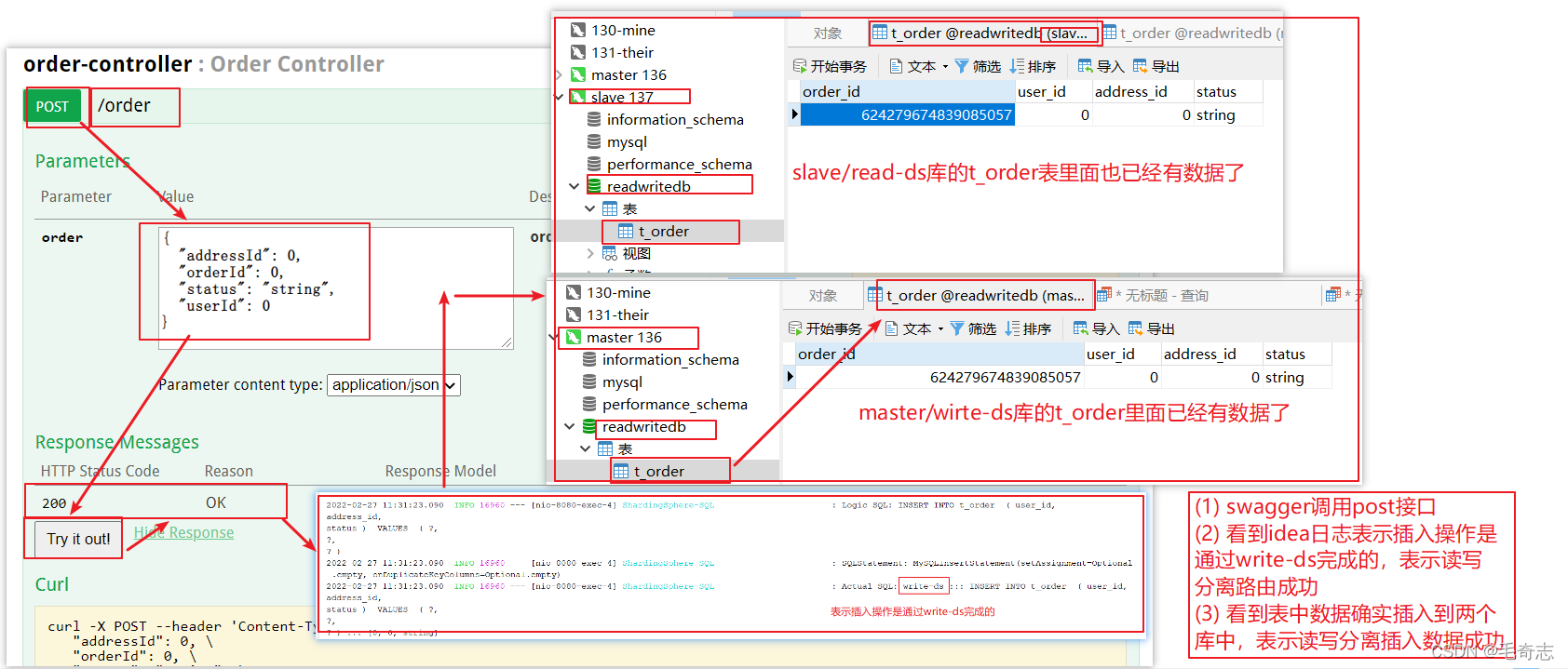
Testar obter interface
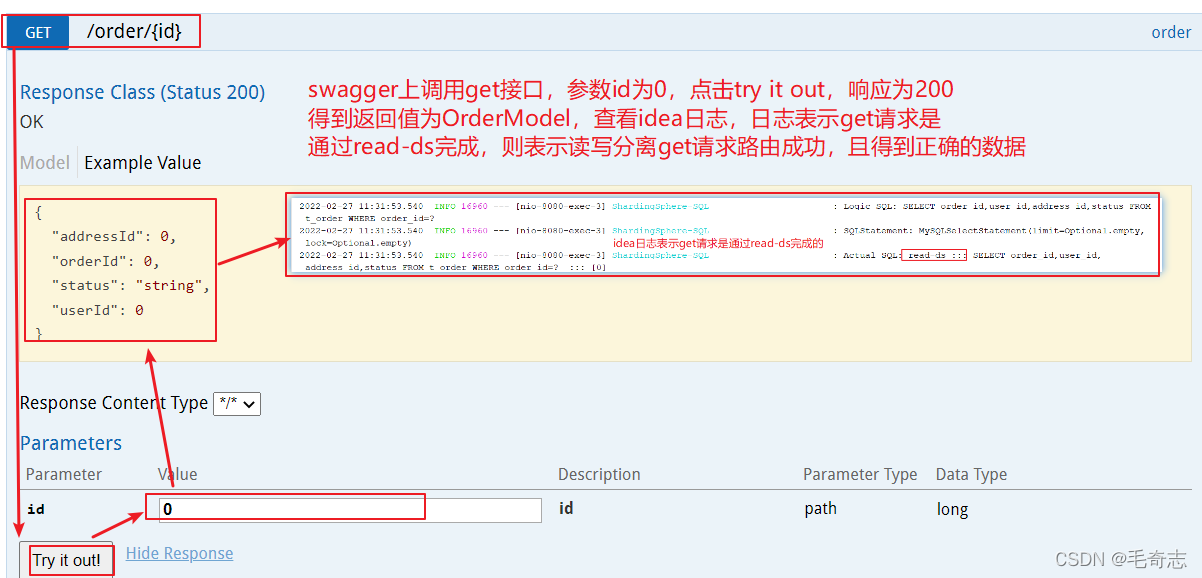
ex.1: Depois que o mestre e o escravo são definidos, as funções não podem ser trocadas automaticamente
2.4 Experiência na construção de replicação mestre-escravo (notas a serem observadas/poços comuns)
As operações a seguir referem-se ao uso do vmware, ao uso do centos7.iso para criar duas novas máquinas virtuais e à instalação do mysql em cada uma, 192.168.100.136 é o mestre e 192.168.100.137 é o escravo
2.4.1 instalação mínima vmware centos7 duas etapas
Existem duas etapas para instalar o centos7 em uma instalação mínima de vmware:
(1) Instalação mínima: primeiro acesse o site oficial https://www.centos.org/download/ para baixar o centos.iso
e selecione diretamente a imagem Alibaba Cloud http ://mirrors.aliyun.com /centos/7.9.2009/isos/x86_64/ Para a
instalação específica, consulte https://www.cnblogs.com/liuhui-xzz/p/10155511.html
Na verdade, é não é tão problemático, você só precisa configurar o disco, o que é obrigatório. Outros não precisam ser configurados
(2) Configurar ip estático: ping www.baidu.com falha após instalação mínima, você precisa configurar ip estático,
digite vi /etc/sysconfig/network-scripts/ifcfg-ens33 e, em seguida, edite como mostrado abaixo e, finalmente, reinicie a rede e salve
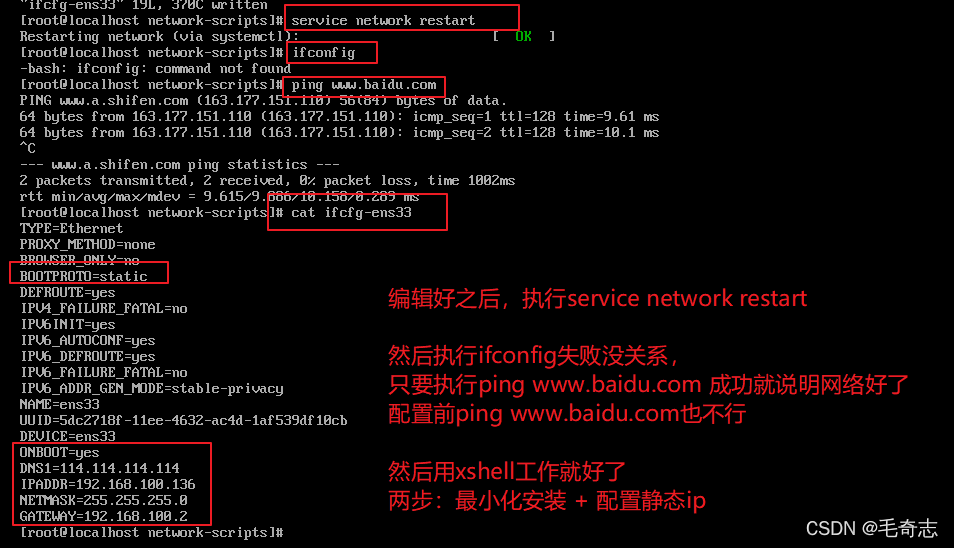
-o. Explique, BOOTPROTO=static ONBOOT=yes DNS1=114.114.114.114 Esses três são codificados, então como os outros três gateways de máscara de sub-rede ip determinados? Isso não tem nada a ver com o ip da máquina, apenas o editor de rede virtual do vmware.
editor de rede virtual do vware, você precisa configurar a máscara de sub-rede, ip de sub-rede, ip de gateway
A primeira é a máscara de sub-rede, que geralmente é de classe C, configurada como 255.255.255.0, não há nada a dizer, e depois o ip de sub-rede, que é limitado pela máscara de sub-rede, apenas os três primeiros bytes, e finalmente um byte é 0, geralmente xxx.xxx.xxx.0, onde o IP da sub-rede é configurado como 192.168.100.0 e, em seguida, o gateway (ou seja, o ip do editor de rede virtual), e o ip do gateway é restrito pelo ip da sub-rede. Os três primeiros bytes precisam ser iguais ao ip da sub-rede, indicando que é o ip deste segmento de sub-rede, que está configurado como 192.168.100.2 aqui, e os demais podem ser configurados como qualquer 192.168.100.1 - 192.168.100.127 em a sub-rede, como mostra a figura a seguir:
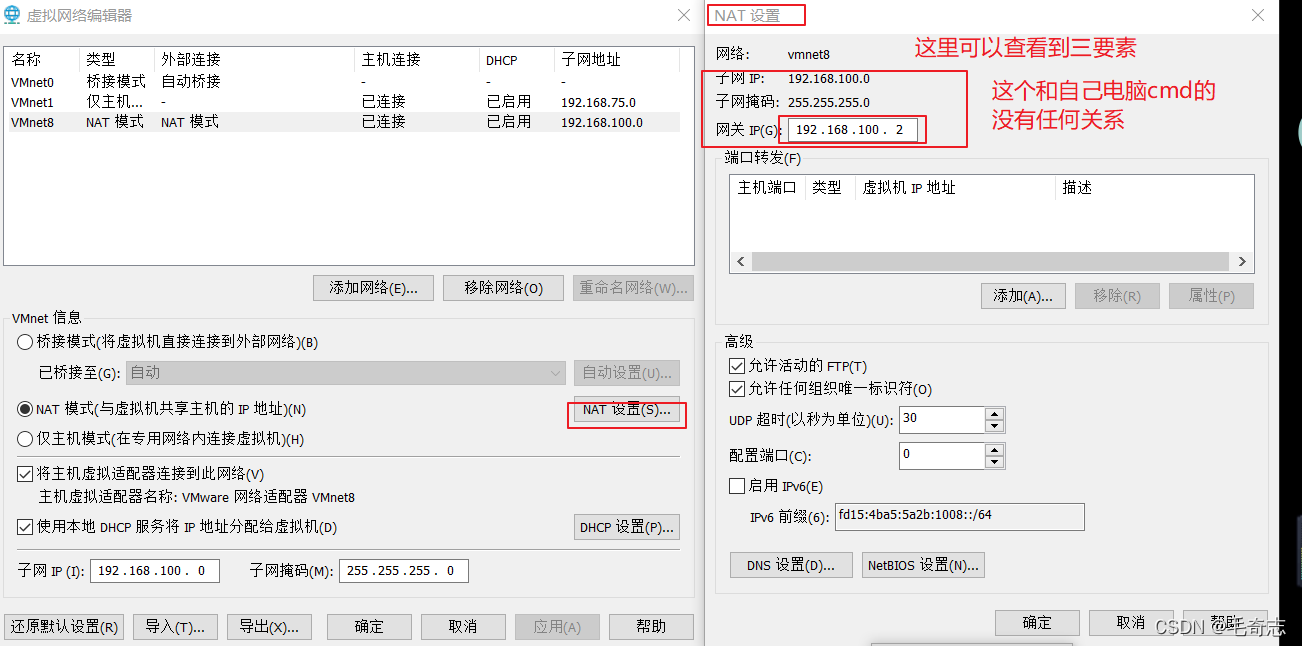
Configuração Após finalizar o editor de rede virtual, observe os três campos do ip estático, NETMASK=255.255.255.0 Sem problemas, a classe c está configurada assim, e então o ip do gateway GATEWAY, que deve ser igual ao ip do gateway do editor de rede virtual. 192.168.100.2, então configure GATEWAY=192.168.100.2, e então ele é seu próprio IPADDR. Para garantir dois pontos, ele está no segmento de sub-rede e não não entra em conflito com o ip do gateway e demais IPs do segmento de sub-rede. No segmento de sub-rede, é a partir de 192.168.100, não entra em conflito com o ip do gateway e demais ips da sub-rede, ou seja, o último não pode ser 2 ou outros usados, então um é 136 e o outro é 137, ou seja, 192.168.100.136 e 192.168.100.137.
Depois de configurar o ip estático, você pode usar xshell para conectar e operar. Você não precisa usar vmware para digitar comandos. Existem também comandos yum. Você pode baixar qualquer coisa que esteja faltando. Por exemplo, não há comando wget em a instalação mínima yum -y install wget.
2.4.2 Passos para instalar o mysql no centos
Passos para instalar o mysql no centos:
(1) Baixar wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
(2) Instalar rpm -ivh mysql-community-release-el7-5.noarch.rpm
(3) Instalação oficial yum install mysql-server
(4) Reiniciar service mysqld restart
(5) Definir senha: Como o root padrão não tem senha, digite # mysql -uroot para efetuar login diretamente e defina um password Neste momento, você deve se lembrar de criptografar com a função password(), conectar-se ao mysql e digitar set password = password('123456');
(6) Definir permissões: Como a raiz padrão é inacessível ao navicat local, defina permissões e atualize
grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option; flush privileges;
(7) Desligue o firewall:systemctl stop firewalld.service
Também pode ser instalado usando o docker
2.4.3 O arquivo de configuração my.cnf não pode ser encontrado no diretório /etc
Se o nó mestre precisar abrir o log binário, é necessário modificar o arquivo de configuração /etc/my.cnf, mas às vezes o arquivo de configuração my.cnf não pode ser encontrado no diretório /etc
Duas possibilidades e soluções:
Possibilidade 1: Pode ser um problema de instalação, ou seja, existe esse arquivo my.cnf em mysql /etc, mas não existe porque a instalação não está boa;
Solução 1: Recriar o arquivo máquina virtual novamente, ou desinstale-a O mysql no centos vem novamente, e as vezes ele é instalado mais uma vez;
talvez 2: problema de versão do mysql, a versão superior do mysql não possui esse arquivo por segurança;
solução 2: precisa alterar o / diretório usr/share/mysql Copie my-default.cnf para o diretório /etc, configure os quatro atributos consultando, e depois configure server-id=xxxe log-bin=/var/lib/mysql/mysql-binpronto, veja como resolver o problema que o MySQL não possui um arquivo de configuração my.cnf
2.4.4 change master to xxxSérie de perguntas
change master to xxxsérie de perguntas
(1) Esta frase é executada no nó escravo, o objetivo é definir o nó mestre deste nó;
(2) Após a execução desta sentença ser completada, os show slave status;dois campos slave_io_running e slave_sql_runing são no, e start slave;estes para serem yes, e então é finalizado;
(3) Deve ser stop slave;executado após a parada, caso contrário será reportado um erro;
(4) O nome do arquivo master_log_file e a localização de master_log_pos devem estar corretos. Se não estiverem corretos, é impossível criar uma nova tabela de banco de dados no banco de dados principal e sincronizar do banco de dados sem relatar um erro. É muito obscuro para encontrar a razão;
(5) /etc/my.cnf O nó mestre deve estar equipado com bin-log e server-id, e o nó escravo deve estar equipado com server-id: Se o nó escravo não configurar o server-id
para executar um change master to xxxerror , a mensagem de erro é Slave não está configurado ou falhou ao inicializar a propriedade. Você deve pelo menos definir --server-id para habilitar um mestre ou um escravo. Mensagens de erro adicionais podem ser encontradas no log de erros do MySQL.
(6) O server-id de cada nó deve ser diferente, ou seja, o server-id dos nós mestre e escravo deve ser diferente: se forem iguais, a execução reportará um change master to xxxerro , e a mensagem de erro será Fatal erro: O encadeamento de E/S escravo para porque mestre e escravo têm ids de servidor MySQL iguais;
(7) O server-uuid de cada nó deve ser diferente. Se eles forem iguais, execute e reporte um change master to xxxerro , e a mensagem de erro é Fatal error: The slave I/O thread pára porque master e slave possuem UUIDs de servidor MySQL iguais ; esses UUIDs devem ser diferentes para que a replicação funcione. Se o server_uuid for o mesmo depois de copiar a pasta de dados diretamente, há esse problema, você pode usar para show variables like '%server_uuid%';visualizar uuid do nó.
2.4.5 mysql pode ser iniciado e usado no centos, mas navicat local não pode se conectar ao mysql
Problema: o mysql pode ser iniciado e usado no centos, mas o navicat local não pode se conectar ao mysql
Solução: Linux pode iniciar o mysql, indicando que a instalação está completa, e são necessários dois passos adicionais para conectar localmente
(1) Abra o sistema de firewall ctl stop firewalld
(2) Abra as permissões remotas grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option; ``flush privileges;
Após completar estes dois passos, o Navicat local pode ser conectado sem a necessidade de reiniciar o serviço mysql mysqld reinicie novamente
3. Transação Distribuída de Fragmentação JDBC
3.1 Transações Distribuídas
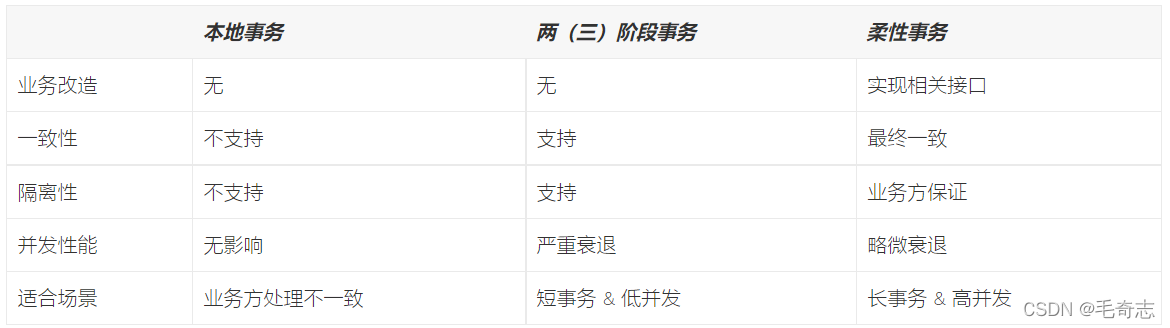
Existem dois tipos de transações, uma é a transação local, a outra é a transação distribuída, e a transação distribuída é dividida em dois tipos, transação XA com consistência forte e transação flexível com consistência final, o site oficial https://shardingsphere.apache. org /document/current/cn/features/transaction/, como segue:

o código correspondente

Se uma transação que implementa o elemento de transação de ACID é chamada de transação rígida, então uma transação baseada no elemento de transação BASE é chamada de transação flexível.

BASE é um acrônimo para disponibilidade básica, estado flexível e consistência eventual.
Basicamente Disponível garante que os participantes da transação distribuída não estejam necessariamente online ao mesmo tempo;
Soft state permite um certo atraso nas atualizações de estado do sistema, que podem não ser detectáveis pelos clientes;
consistência final (consistente eventualmente) geralmente garante a consistência eventual do sistema por meio da passagem de mensagens.
O requisito de isolamento é muito alto em transações ACID e todos os recursos devem ser bloqueados durante a execução da transação. A ideia de uma transação flexível é mover a operação mutex do nível de recurso para o nível de negócios por meio da lógica de negócios. Ao relaxar os requisitos de consistência forte, a taxa de transferência do sistema é aprimorada.
3.2 Transações XA Fortemente Consistentes
3.2.1 Transações Globais
Uma transação global é uma transação de um modelo DTP O chamado modelo DTP refere-se ao X/Open DTP (X/Open Distributed Transaction
Processing Reference Model), que é um conjunto de padrões de transações distribuídas definidos pela organização X/Open.
X/Open, agora o grupo aberto, é uma organização independente responsável principalmente pela formulação de vários padrões técnicos da indústria. Endereço do site oficial
: http://www.opengroup.org/. A organização X/Open é apoiada principalmente por grandes empresas ou fabricantes de renome,
que não apenas seguem os padrões técnicos da indústria definidos pela organização X/Open, mas também participam da formulação dos padrões.
Resumo: X/Open é o nome de uma organização, e o modelo DTP é um padrão de transação distribuído proposto por esta organização, apenas fornece um padrão, e a implementação específica é determinada pelo fabricante.
O X/Open define a especificação e a interface da API, que é implementada pelo fabricante. Este padrão propõe o uso de two-phase commit (2PC-Two-Phase-Commit) para garantir a integridade das transações distribuídas. Posteriormente, o J2EE também seguiu a especificação X/OpenDTP, projetou e implementou a especificação da interface de programação de transações distribuídas em java-JTA, conforme mostrado na figura abaixo, representando um modelo X/Open DTP.
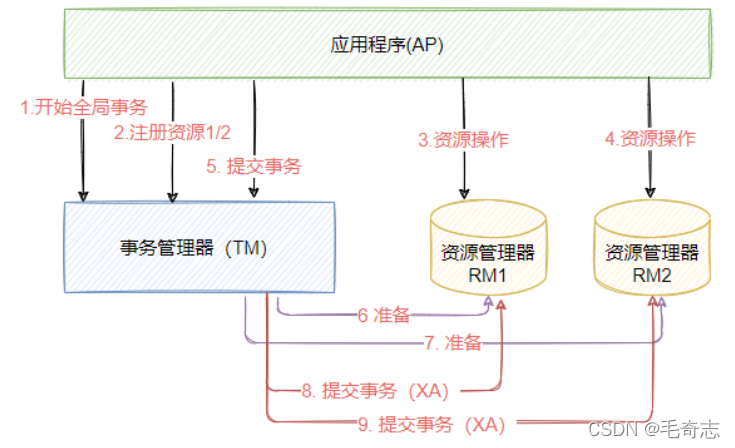
O modelo X/Open DTP define três funções e dois protocolos. As três funções são as seguintes:
AP (Application Program), representando um programa aplicativo, também pode ser entendido como um programa
RM (Resource Manager) utilizando o modelo DTP, um gerenciador de recursos, este recurso pode ser um banco de dados, um programa aplicativo
controla o recurso através do gerenciador de recursos, e o gerenciador de recursos deve implementar a interface
TM (Transaction Manager) definida por XA, representando o gerenciador de transações, responsável por coordenar e gerenciar transações globais. O gerenciador de transações controla toda
a transação global, gerencia o ciclo de vida da transação e coordena os recursos .
Os dois acordos são:
Protocolo XA: XA é a especificação de interface entre o gerenciador de recursos e o gerenciador de transações definido pelo X/Open DTP, TM o utiliza para notificar e coordenar
o início, término, confirmação ou reversão de transações RM relacionadas. Atualmente Oracle, Mysql, DB2 fornecem suporte para XA; A interface XA é uma interface de sistema bidirecional, que forma uma ponte de comunicação entre o gerenciador de transações (TM) e vários gerenciadores de recursos (o XA não pode ser enviado automaticamente) Protocolo XA Sintaxe, mainstream todos os bancos de dados suportam o protocolo XA, permitindo transações entre bancos de dados.
Protocolo TX: A interface para comunicação entre o Global Transaction Manager e o Resource Manager. Em um sistema distribuído, embora cada nó de máquina possa saber claramente se o resultado de sua operação de transação foi bem ou malsucedida, ele não pode obter diretamente os resultados de operação de outros nós distribuídos. Portanto, quando uma operação de transação precisa abranger vários nós distribuídos, para manter as características ACID do processamento da transação, é necessário introduzir um "coordenador" (TM) para escalonar uniformemente a lógica de execução de todos os nós distribuídos. chamados APs. O TM é responsável por agendar o comportamento dos APs e, em última análise, decide se esses APs devem realmente confirmar a transação para (RM).
3.2.2 Protocolo de envio de 2 peças
No modelo X/OpenDTP, a lógica SQL envolvida em uma transação distribuída é toda executada e, no momento crítico em que (RM) finalmente confirma a transação, para evitar a falta de confiabilidade inerente ao sistema distribuído, a transação de confirmação falha inesperadamente A TM decidiu implementar uma solução em duas etapas, que é chamada de commit de segunda ordem.
Ex.: A transação XA também é conhecida como transação bifásica, é a mesma coisa, ou seja, uma transação distribuída fortemente consistente, as duas fases são nomeadas de acordo com sua implementação.
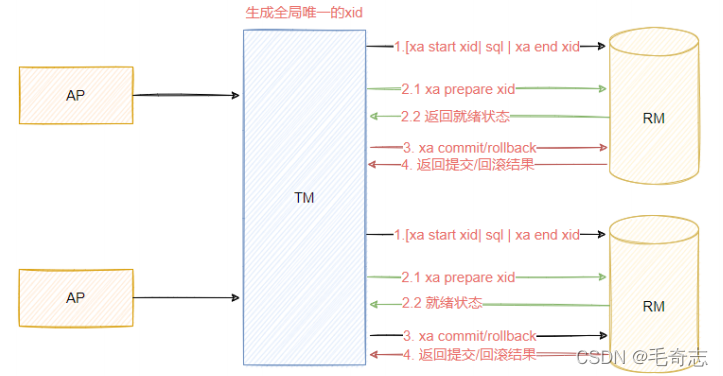
O two-phase commit é um algoritmo projetado para redes de computadores, especialmente no campo de bancos de dados, para manter a atomicidade e a consistência de todos os nós com base em uma arquitetura de sistema distribuída durante o processamento de transações. Normalmente, o protocolo de confirmação de duas fases também é considerado um protocolo de consistência, que é usado para garantir a consistência dos dados do sistema distribuído. Atualmente, a maioria dos bancos de dados relacionais usa o protocolo de confirmação de duas fases para concluir o processamento de transações distribuídas. .Ele pode efetivamente garantir a consistência de dados distribuídos, então 2pc também é amplamente utilizado em muitos sistemas distribuídos.
-- 启动一个XA事务 (xid 必须是一个唯一值; [JOIN|RESUME] 字句不被支持)
mysql> XA START 'xatest';
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO mytable (i) VALUES(10);
Query OK, 1 row affected (0.04 sec)
-- 结束一个XA事务 ( [SUSPEND [FOR MIGRATE]] 字句不被支持)
mysql> XA END 'xatest';
Query OK, 0 rows affected (0.00 sec)
-- 准备 此动作会把这个事务的redo日志写入innodb redo log,只要这一阶段是成功的,那么后续 XACommit一定会成功
mysql> XA PREPARE 'xatest';
Query OK, 0 rows affected (0.00 sec)
--提交XA事务
mysql> XA COMMIT 'xatest';
Query OK, 0 rows affected (0.00 sec)
3.2.3 Problemas com Transações XA
A transação global baseada no protocolo XA é uma transação fortemente consistente, pois na transação global, desde que qualquer RM seja anormal
, a transação global será revertida. Ao mesmo tempo, quando uma transação local bloqueia recursos na fase de Preparação, caso outras transações desejem modificar os
mesmos
dados, elas devem aguardar a conclusão da transação anterior . o desempenho geral.
3.3 Prática: Transações XA Fortemente Consistentes
interface de classe do controlador

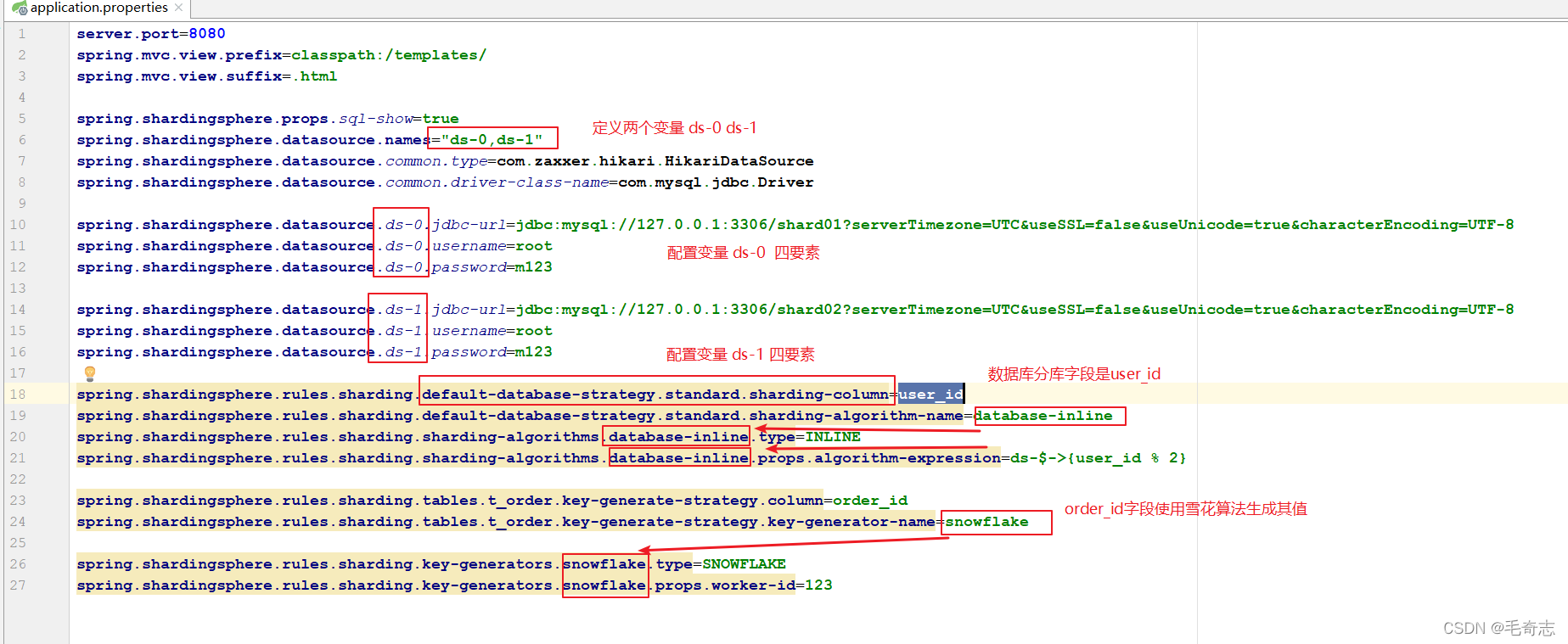
Método de classe de serviço do arquivo de configuração
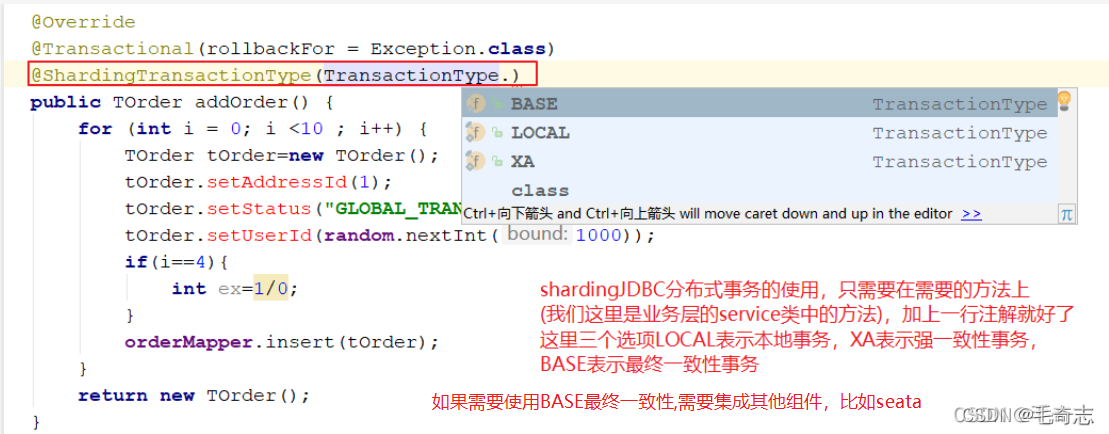
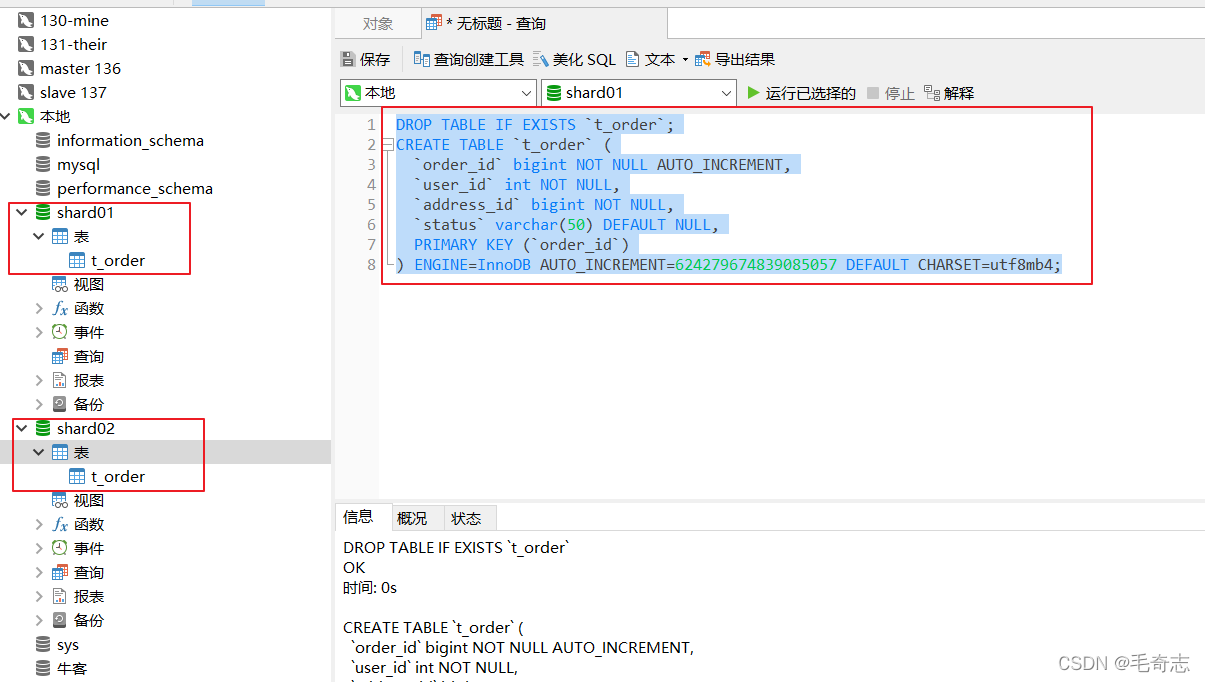
Agora crie uma nova tabela no banco de dados
DROP TABLE IF EXISTS `t_order`;
CREATE TABLE `t_order` (
`order_id` bigint NOT NULL AUTO_INCREMENT,
`user_id` int NOT NULL,
`address_id` bigint NOT NULL,
`status` varchar(50) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB AUTO_INCREMENT=624279674839085057 DEFAULT CHARSET=utf8mb4;
Operação normal:
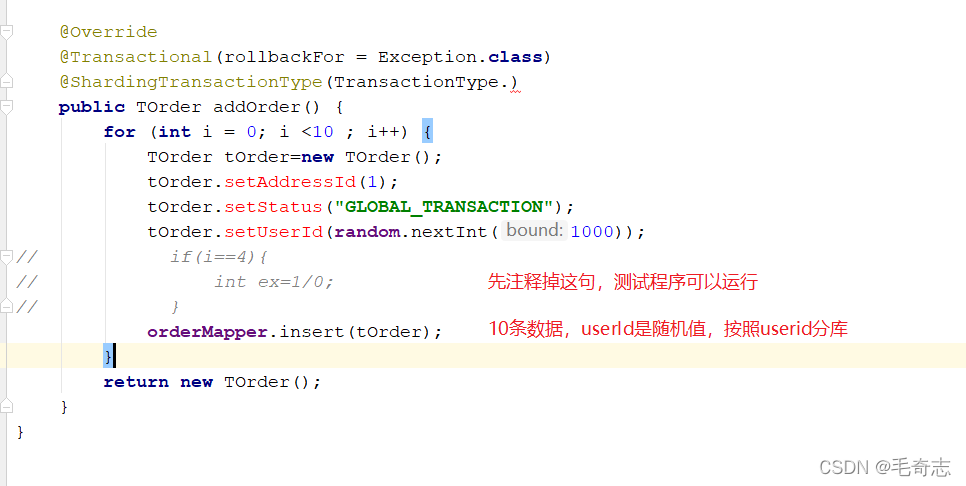
inicie e envie uma solicitação em http://localhost:8080/swagger-ui.html
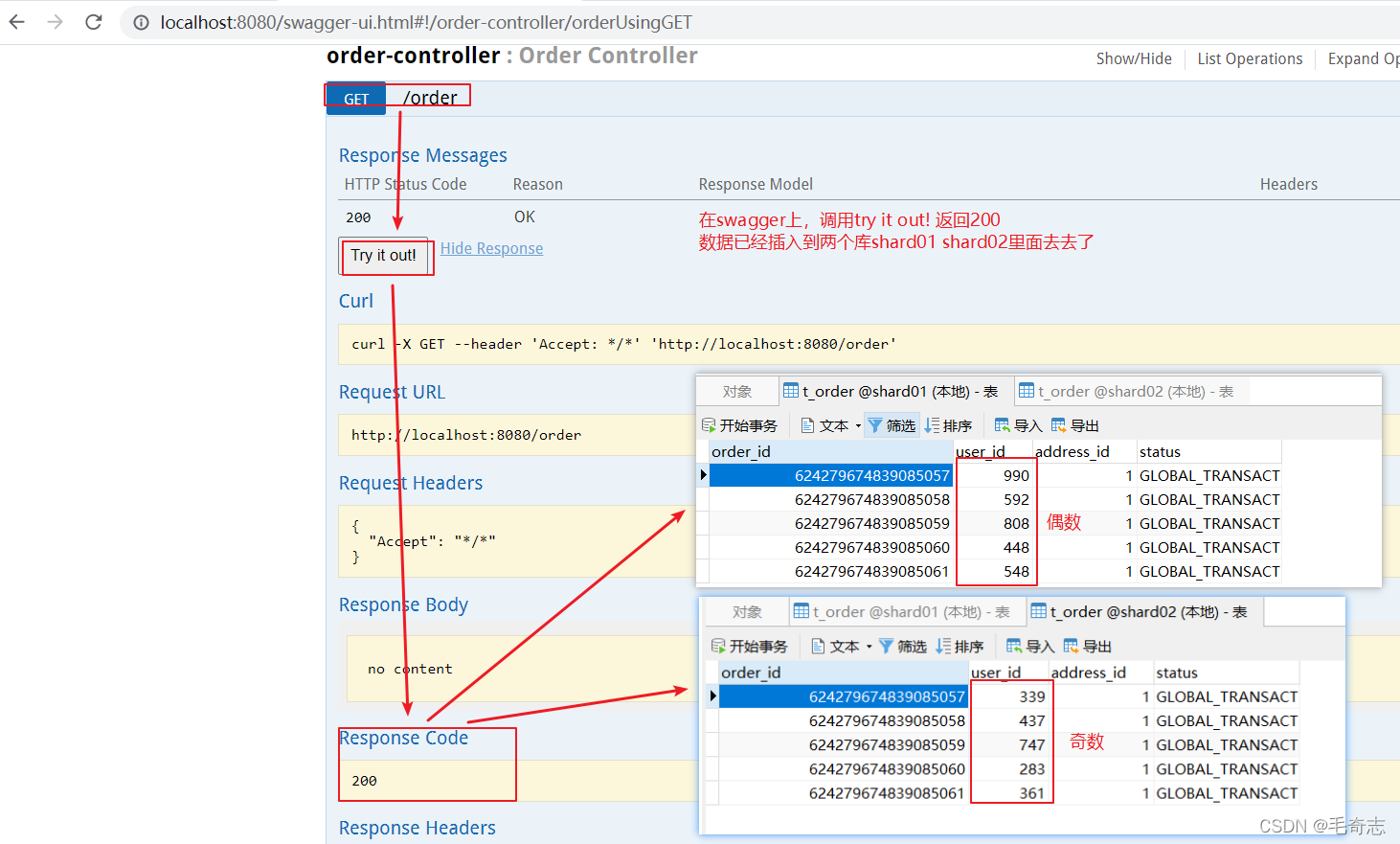
Modifique o programa
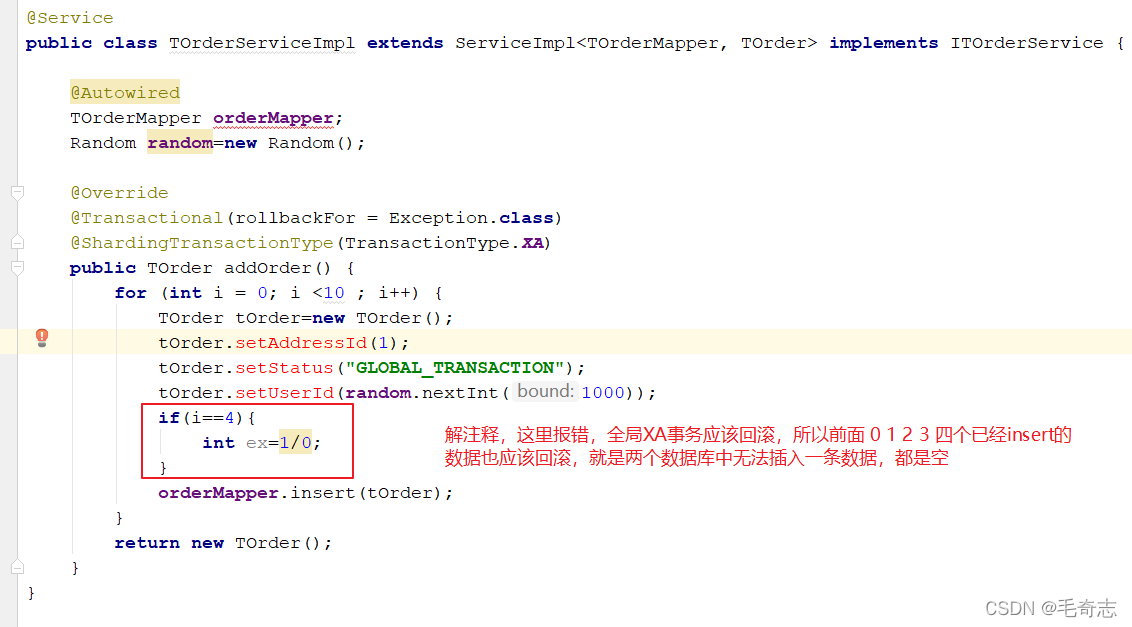
para reiniciar, swagger envia uma solicitação
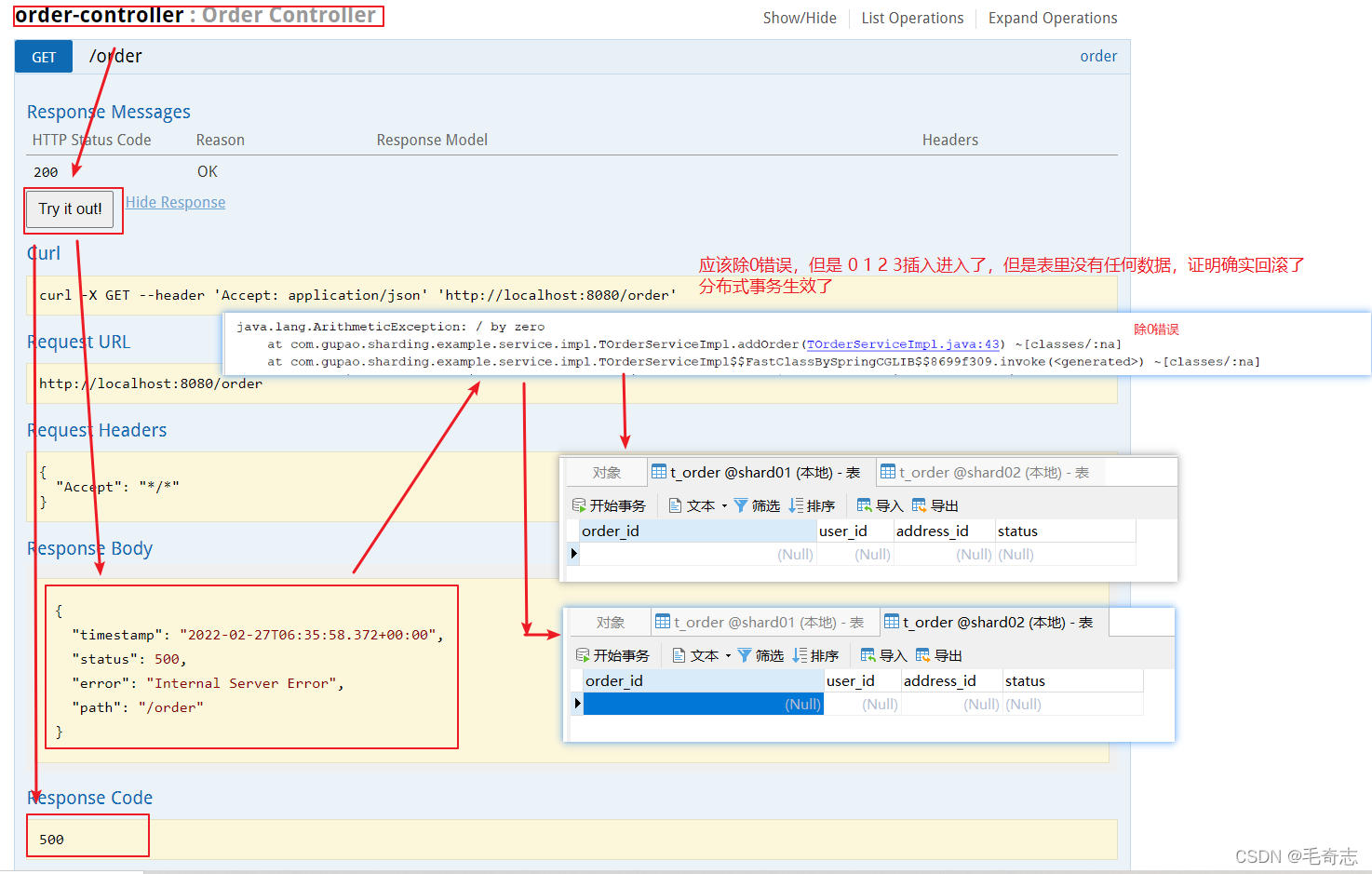
Quarto, o fim
Este artigo apresenta principalmente a separação de leitura /gravação do ShardingJDBC e as transações distribuídas
.
Codifique todos os dias, evolua todos os dias! !