Questões de entrevista
Qual é o princípio de funcionamento da gravação de dados ES? Como funcionam os dados de consulta ES? E quanto ao Lucene na parte inferior? Você entende o índice invertido?
Entrevistador psicanálise
Pergunte isso, de fato, o entrevistador quer ver se você entende alguns princípios básicos de es, porque usar es nada mais é do que escrever e pesquisar dados. Se você não entende o que o es está fazendo quando inicia uma solicitação de escrita e pesquisa, então você realmente é ...
Sim, es é basicamente uma caixa preta. O que mais você pode fazer? A única coisa que você pode fazer é usar a API es para ler e gravar dados. Se algo der errado e você não souber de nada, o que pode esperar de você?
Análise das perguntas da entrevista
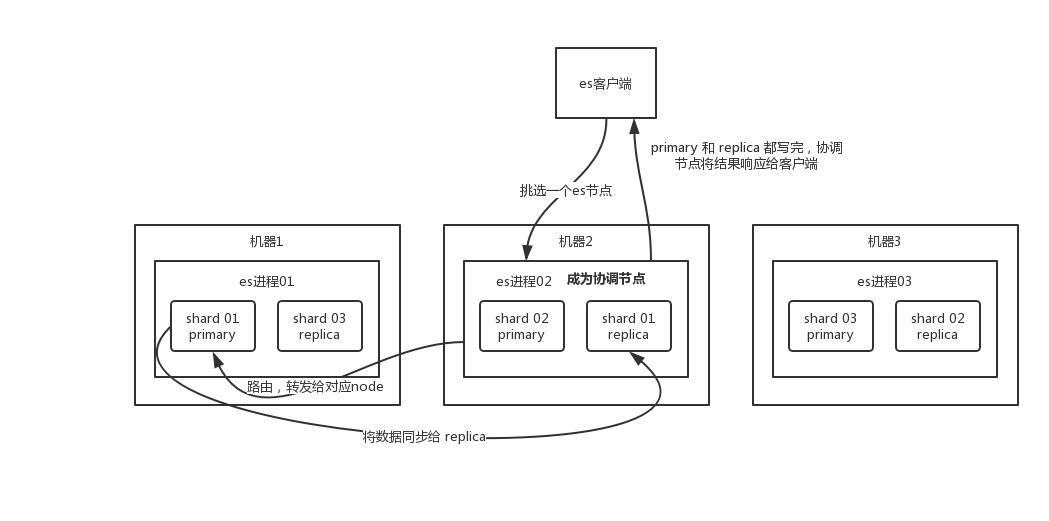
é escrever processo de dados
- O cliente seleciona um nó para enviar a solicitação, e esse nó é o
coordinating node(nó coordenador). coordinating nodeO documento é roteado e a solicitação é encaminhada ao nó correspondente (há um shard primário).primary shardProcesse a solicitação no nó real e sincronize os dados com elereplica node.coordinating nodeSe for encontradoprimary nodee tudoreplica nodefor feito, ele retorna o resultado da resposta ao cliente.
é ler o processo de dados
Ele pode doc id ser consultado por meio e, com base doc id no hash, será julgado para doc id qual fragmento está alocado naquele momento , e o fragmento será consultado.
- O cliente envia uma solicitação a qualquer nó e se torna
coordinate node. coordinate nodeDadoc idrota Hash, encaminha a solicitação para o Nó correspondente, desta vez utilizandoround-robinum algoritmo de polling aleatório , aprimary shardseleção aleatória e uma réplica de tudo, para que a solicitação de leitura seja balanceada.- O nó que recebe a solicitação retorna o documento para
coordinate node. coordinate nodeDevolva o documento ao cliente.
é o processo de pesquisa de dados
O mais poderoso deles é fazer uma pesquisa de texto completo, ou seja, por exemplo, você tem três dados:
java真好玩儿啊
java好难学啊
j2ee特别牛Copiar para a área de transferênciaErrorCopiedVocê java pesquisar com base em palavras-chave e procurar as contidos java queridos document . Voltaremos para você: java é tão divertido, java é tão difícil de aprender.
- O cliente envia uma solicitação a um
coordinate node. - O nó coordenador encaminha a solicitação de pesquisa para o OR correspondente de todos os shards .
primary shardreplica shard - Fase de consulta: cada fragmento retorna seus próprios resultados de pesquisa (na verdade, alguns
doc id) para o nó coordenador, e o nó coordenador executa operações como fusão, classificação e paginação de dados para produzir o resultado final. - Fetch phase: seguido pelo nó coordenador de acordo com os
doc idvários nós para puxar o real dosdocumentdados, eventualmente devolvidos ao cliente.
A solicitação de gravação é gravada no shard primário e, em seguida, sincronizada com todos os shards de réplica; a solicitação de leitura pode ser lida a partir do shard primário ou shard de réplica, usando um algoritmo de pesquisa aleatório.
O princípio básico da gravação de dados
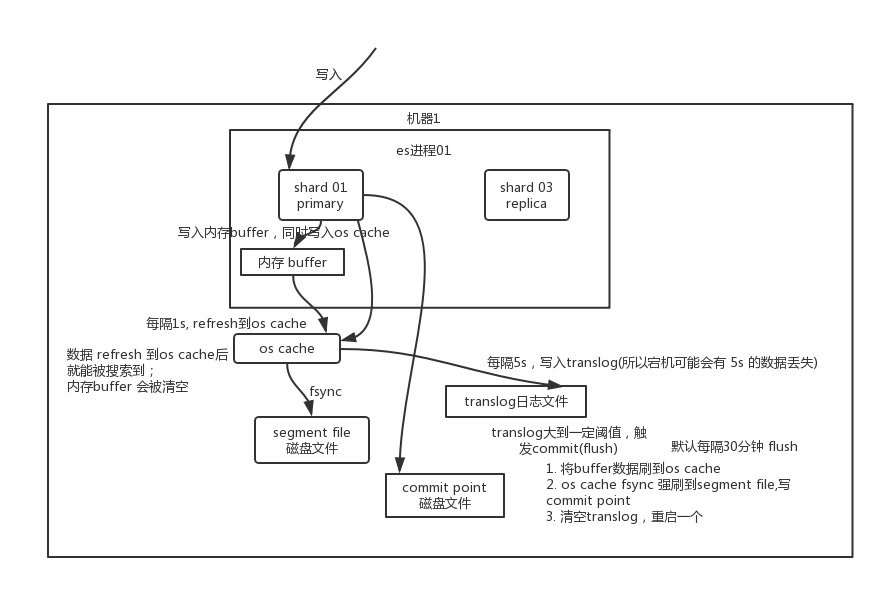
Grave no buffer de memória primeiro, os dados não podem ser pesquisados enquanto no buffer; ao mesmo tempo, grave os dados no arquivo de log translog.
Se o buffer estiver quase cheio, ou após um certo período de tempo, os dados refresh no buffer da memória serão transferidos para um novo segment file , mas neste momento os dados não entrarão no segment filearquivo do disco diretamente , mas primeiro os cache . Este processo é apenas isso refresh .
A cada 1 segundo, es grava os dados do buffer em um novo segment file , e um novo arquivo de disco é gerado a cada segundo segment file , que segment file armazena os dados gravados no buffer no último 1 segundo.
Mas se não houver dados no buffer neste momento, então é claro que a operação de atualização não será executada. Se houver dados no buffer, a operação de atualização será executada uma vez por segundo por padrão e flashed em um novo arquivo de segmento .
No sistema operacional, os arquivos de disco têm, na verdade, algo chamado os cache cache do sistema operacional, ou seja, antes que os dados sejam gravados no arquivo de disco, eles primeiro entram os cache , primeiro entram em um cache de memória no nível do sistema operacional. Contanto buffer que os dados em sejam atualizados pela operação de atualização os cache , esses dados podem ser pesquisados.
Por que é chamado de es em tempo quase real ? NRT , O nome completo near real-time . O padrão é atualizar a cada 1 segundo, então es é quase em tempo real, porque os dados gravados só podem ser vistos após 1 segundo. Por meio de restful api ou java api , execute manualmente uma operação de atualização, o buffer de dados é manualmente no pincel os cache , de modo que os dados podem ser encontrados imediatamente. Enquanto os dados são inseridos os cache , o buffer será esvaziado, porque não há necessidade de reter o buffer e os dados foram persistidos no disco no translog.
Repetindo as etapas acima, novos dados entram continuamente no buffer e no translog, e continuamente gravam os buffer dados um após o outro segment file . Cada vez que refresh o buffer é limpo, o translog é retido. Conforme esse processo avança, o translog se tornará cada vez maior. Quando o translog atinge um determinado comprimento, a commit operação é acionada .
A operação de confirmação da primeira etapa ocorre, é para armazenar os dados em buffer antes refresh de os cache esvaziar o buffer. Em seguida, grave um commit point no arquivo do disco, que identifica commit point todos os correspondentes segment file e, ao mesmo tempo, força os cache todos os dados atuais fsync para o arquivo do disco. Por fim, limpe o arquivo de log translog existente, reinicie um translog e a operação de confirmação estará concluída.
Esta operação de confirmação é chamada flush . O padrão é executado automaticamente a cada 30 minutos flush , mas se o translog for muito grande, ele também será acionado flush . A operação flush corresponde a todo o processo de confirmação. Podemos executar manualmente a operação flush por meio da api es, e flush manualmente os dados no cache do sistema operacional para fsync no disco.
Qual é a finalidade dos arquivos de log translog? Antes de executar a operação de confirmação, os dados permanecem no buffer ou no cache do sistema operacional. Tanto o buffer quanto o cache do sistema operacional são memória. Uma vez que a máquina morre, todos os dados na memória são perdidos. Portanto, as operações correspondentes aos dados precisam ser gravadas em um arquivo de log especial.Uma translog vez que a máquina seja desligada e reiniciada novamente, o es irá ler automaticamente os dados no arquivo de log translog e restaurá-lo no buffer de memória e no cache do sistema operacional.
O translog é realmente gravado no cache do sistema operacional primeiro. Por padrão, ele é descarregado no disco a cada 5 segundos, então, por padrão, pode haver 5 segundos de dados que ficarão apenas no cache do sistema operacional do buffer ou arquivo translog. Se a máquina estiver neste momento Se você desligar, você perderá 5 segundos de dados. Porém, esse desempenho é melhor, perdendo até 5 segundos de dados. Você também pode definir o translog para que cada operação de gravação seja diretamente fsync no disco, mas o desempenho será muito pior.
Na verdade, você está aqui. Se o entrevistador não fez a pergunta sobre a perda de dados, você pode exibi-lo aqui. Você disse que o es primeiro é quase em tempo real e os dados podem ser pesquisados após 1 segundo .; Pode perder dados. Há 5 segundos de dados que permanecem no buffer, no cache translog os e no cache do OS do arquivo de segmento, mas não no disco. Se ele cair neste momento, causará 5 segundos de perda de dados .
Para resumir , os dados são primeiro gravados no buffer de memória e, em seguida, a cada 1s, os dados são atualizados para o cache do sistema operacional, e os dados podem ser pesquisados no cache do sistema operacional (então dissemos que os dados podem ser pesquisados durante a gravação em , e há 1s no meio. atraso). A cada 5s, grave os dados no arquivo translog (portanto, se a máquina estiver desligada e os dados da memória acabarem, haverá no máximo 5s de perda de dados), o translog é grande até certo ponto, ou a cada 30 minutos por padrão, a operação de confirmação será disparada e o buffer será armazenado em buffer. Os dados na zona são descarregados no arquivo de disco do arquivo de segmento.
Depois que os dados são gravados no arquivo de segmento, um índice invertido é criado ao mesmo tempo.
O princípio básico de exclusão / atualização de dados
Se for uma operação de exclusão, um .del arquivo será gerado durante o commit , e um determinado documento será marcado como um deleted status.Em seguida, durante a pesquisa, você .del pode saber se o documento foi excluído de acordo com o arquivo.
Se for uma operação de atualização, o documento original é marcado como um deleted estado e, em seguida, uma nova parte dos dados é gravada.
Um buffer é gerado a cada atualização segment file , portanto, por padrão, é um a cada 1 segundo segment file , portanto, ele segment file será desativado mais e mais.Neste momento, a fusão será executada regularmente. Cada vez que você mesclar, vários documentos serão segment file mesclados em um. Ao mesmo tempo, o deleteddocumento identificado será excluído fisicamente e o novo segment file será gravado no disco. Um será gravado aqui para commit point identificar todos os novos segment file e em seguida, abra segment file para pesquisa e exclua o antigo ao mesmo tempo segment file .
Lucene de baixo nível
Para simplificar, lucene é um pacote jar que contém vários códigos de algoritmo encapsulados para estabelecer índices invertidos. Quando desenvolvemos em Java, introduzimos o jar lucene e, em seguida, o desenvolvemos com base na API lucene.
Por meio de lucene, podemos indexar os dados existentes e lucene organizará a estrutura de dados do índice no disco local.
Índice invertido
Em um mecanismo de pesquisa, cada documento possui um ID de documento correspondente e o conteúdo do documento é representado como uma coleção de uma série de palavras-chave. Por exemplo, o documento 1 foi segmentado por palavras e 20 palavras-chave foram extraídas, e cada palavra-chave registrará o número de vezes que aparece no documento e onde aparece.
Em seguida, o índice invertido é o mapeamento de palavras-chave para IDs de documentos . Cada palavra-chave corresponde a uma série de arquivos e as palavras-chave aparecem nesses arquivos.
Dê uma castanha.
Os seguintes documentos estão disponíveis:
| DocId | Doc |
|---|---|
| 1 | O pai do Google Maps salta para o Facebook |
| 2 | O pai do Google Maps se junta ao Facebook |
| 3 | O fundador do Google Maps, Russ, deixa o Google para se juntar ao Facebook |
| 4 | O pai do Google Maps saiu do Facebook por causa do cancelamento do projeto Wave |
| 5 | Russ, o pai do Google Maps, entra para o site de rede social Facebook |
Após a segmentação por palavra do documento, obtém-se o seguinte índice invertido .
| WordId | Palavra | DocIds |
|---|---|---|
| 1 | o Google | 1, 2, 3, 4, 5 |
| 2 | mapa | 1, 2, 3, 4, 5 |
| 3 | Pai | 1, 2, 4, 5 |
| 4 | Trabalho saltitante | 1, 4 |
| 5 | 1, 2, 3, 4, 5 | |
| 6 | Junte-se | 2, 3, 5 |
| 7 | Fundador | 3 |
| 8 | Las | 3, 5 |
| 9 | vá embora | 3 |
| 10 | contra | 4 |
| .. | .. | .. |
Além disso, um índice invertido prático também pode registrar mais informações, como informações de frequência do documento, indicando quantos documentos na coleção de documentos contêm uma determinada palavra.
Então, com o índice invertido, os mecanismos de pesquisa podem responder facilmente às consultas do usuário. Por exemplo, o usuário insere uma consulta Facebook , o sistema de pesquisa procura o índice invertido e lê os documentos que contêm a palavra dele, que são os resultados da pesquisa fornecidos ao usuário.
Preste atenção a dois detalhes importantes do índice invertido:
- Todos os termos do índice invertido correspondem a um ou mais documentos;
- Os termos no índice invertido são classificados em ordem lexicográfica crescente