índice
Quatro, consulta de combinação es
Seis, faz parte da RESTful-api
1. Introdução
ElasticSearch é um servidor de pesquisa baseado em Lucene, que fornece um mecanismo de pesquisa de texto completo multiusuário distribuído com base em uma interface RESTful-web. ElasticSearch é orientado a documentos, o que significa que pode armazenar objetos ou documentos inteiros e indexar o conteúdo de cada documento para que possa ser pesquisado (cada campo tem um índice invertido). Em ElasticSearch, você pode realizar indexação, pesquisa, classificação , e a filtragem são uma das razões pelas quais ele pode realizar pesquisas complexas de texto completo.
O texto acima está em mandarim. Um grande motivo para escolher usar es é que a biblioteca pg tem um gargalo de desempenho de consulta. Por motivos históricos, o SQL precisa realizar um grande número de consultas relacionadas e é mais lento. Portanto, es precisa ser habilitado para armazenar uma tabela de negócios inteira. Parte redundante dos dados, quando os dados são atualizados, eles são sincronizados para es através do mq, e então todas as operações de consulta anteriores são transferidas para es
2. Conceitos básicos
Aqui estão alguns conceitos que costumam aparecer no ES
- Nó : uma instância ES é um nó, e uma máquina pode ter várias instâncias
- Índice : uma coleção de uma série de documentos, onde os documentos relacionados são armazenados. Não é recomendado construir muitos índices para um nó es, caso contrário, o desempenho da pesquisa será afetado
- Fragmento (fragmento): ES são motores de busca distribuídos, cada índice tem uma ou mais fatias, os dados do índice são alocados para cada fatia, o equivalente a um balde de água, com o copo significa N; fragmento Existência é útil para expansão horizontal. N shards serão distribuídos em diferentes nós da forma mais uniforme possível; cada shard é uma unidade mínima de trabalho, carregando parte dos dados, instância de lucene, indexação completa e capacidade de solicitações de processamento
- Réplica : pode ser entendido como um fragmento de backup, correspondendo ao fragmento primário, cada fragmento pode ter várias cópias; o fragmento primário e o fragmento de backup não aparecerão no mesmo nó, e um índice é criado por padrão 5 fragmentos e um backup (ou seja, 5 principais + 5 backups = 10 fragmentos)
- Tipo (tipo): Em ElasticSearch, um objeto de índice pode armazenar muitos objetos para diferentes propósitos, e o tipo de documento nos permite distinguir facilmente diferentes objetos em um único índice. Cada documento pode ter uma estrutura diferente, mas devemos prestar atenção ao diferença O tipo de documento não pode ser definido para tipos diferentes para o mesmo atributo (por exemplo, em todos os tipos de documentos no mesmo índice, um campo chamado título deve ter o mesmo tipo); ES6 não recomenda mais a estrutura de vários tipos de índice único, mas ele ainda mantém a compatibilidade, no momento do ES7, não é suportado de forma alguma.
- Documentos : cada tipo pode conter vários documentos, e cada documento contém vários campos
ES tem dois números de porta, 9200 e 9300, 9200 é usado como protocolo http, usado principalmente para comunicação externa, geralmente quando usamos é 9200; 9300 é usado como protocolo tcp, a comunicação entre jars é através do protocolo tcp e também entre ES clusters Comunicam-se via 9300.
O tipo de dados do campo não é registrado aqui, apenas uma frase, após es5.0, o campo de string é dividido em dois novos tipos de dados:
- texto : realize a segmentação de palavras de acordo com o tokenizer e crie um índice invertido com base no conteúdo após a segmentação de palavras
- palavra - chave : sem segmentação de palavra, índice invertido diretamente com base no conteúdo da string
Se você não especificou o tipo de dados do campo ao criar o índice , es mapeará dinamicamente o campo , ou seja, o campo de resultado é numérico antes do armazenamento e es será mapeado para longo. Se o resultado subsequente se tornar uma string, vai ser jogado errado
Três, integração
Devido às necessidades do projeto, a versão do es selecionada aqui é a 6.7.2, que registra a integração básica e o uso do springboot
Primeiro apresente o arquivo pom:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>6.7.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.7.2</version>
</dependency>Em seguida, adicione as informações básicas de configuração de es no arquivo de configuração
es.ip=
es.port=9200
es.enabled=true
es.index.name=
es.authentication.active=false // 是否需要密码校验
es.user.name=
es.user.password=é o código de inicialização do cliente
private RestHighLevelClient client;
private BulkProcessor bulkProcessor;
@PostConstruct
public void establishElasticConnection() throws ServiceException {
if (!appEnv.isEsEnabled()){
return;
}
try {
if (appEnv.isEsAuthActive()){
final CredentialsProvider credentialsProvider =
new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY,
new UsernamePasswordCredentials(appEnv.getEsUserName(), appEnv.getEsPassword()));
RestClientBuilder builder = RestClient.builder(
new HttpHost(appEnv.getElasticSearchIp(), appEnv.getElasticSearchPort()))
.setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback() {
@Override
public HttpAsyncClientBuilder customizeHttpClient(
HttpAsyncClientBuilder httpClientBuilder) {
return httpClientBuilder
.setDefaultCredentialsProvider(credentialsProvider);
}
});
client = new RestHighLevelClient(builder);
} else {
client = new RestHighLevelClient(
RestClient.builder(
new HttpHost(appEnv.getElasticSearchIp(), appEnv.getElasticSearchPort(), "http")));
}
// 初始化批量处理器
initBulkProcessor();
GetIndexRequest getIndexRequest = new GetIndexRequest(appEnv.getEsIndexName());
boolean result = client.indices().exists(getIndexRequest, RequestOptions.DEFAULT);
if (!result) {
// 指定索引结构并创建
createIndexStructure(appEnv.getEsIndexName());
}
} catch (ElasticsearchException ex){
throw new ServiceException(ErrorCode.INTERNAL_SERVER_ERROR, new String[] {ex.getMessage()});
} catch (Exception ex){
logger.error("Fail to establish ES connection, error:{}", ex.getMessage());
}
}
private void createIndexStructure(String indexName){
CreateIndexRequest request = new CreateIndexRequest(indexName);
request.settings(Settings.builder()
.put("index.number_of_shards", 1)
.put("index.number_of_replicas", 1)
);
String[] booleanFields = Constant.ES_BOOLEAN_FIELDS;
String[] keywordFields = Constant.ES_KEYWORD_TYPE_FIELDS;
String[] textFields = Constant.ES_TEXT_TYPE_FIELDS;
Map<String, Object> properties = new HashMap<>();
Map<String, Object> mapping = new HashMap<>();
assembleBooleanFields(booleanFields, properties);
assembleKeywordFields(keywordFields, properties);
assembleTextFields(textFields, properties);
mapping.put("properties", properties);
request.mapping(indexName, mapping);
try {
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
if (!createIndexResponse.isAcknowledged()) {
logger.error("Aux costTracking Item Index Creation Failed, createIndexResponse:{}", createIndexResponse.toString());
}
} catch (IOException ioEx){
logger.info("Aux costTracking Item Index Creation Failed");
}
}
// 标识该字段既是text又是keyword,es的默认映射也是这种类型
private void assembleTextFields(String[] stringFields, Map<String, Object> properties){
for (String fieldName : stringFields) {
Map<String, Object> fieldMeta = new HashMap<>();
Map<String, Object> Fields = new HashMap<>();
Map<String, Object> KeyWord = new HashMap<>();
KeyWord.put(Constant.ES_KEYWORD_TYPE, Constant.ES_KEYWORD_KEYWORD);
KeyWord.put(Constant.ES_KEYWORD_IGNORE_ABOVE, 256);
Fields.put(Constant.ES_KEYWORD_KEYWORD, KeyWord);
fieldMeta.put(Constant.ES_KEYWORD_TYPE, Constant.ES_KEYWORD_TEXT);
fieldMeta.put(Constant.ES_KEYWORD_FIELDS, Fields);
properties.put(fieldName, fieldMeta);
}
}
// 批量处理器
private void initBulkProcessor() {
BulkProcessor.Listener listener = new BulkProcessor.Listener() {
@Override
public void beforeBulk(long executionId, BulkRequest request) {
logger.info("Try to bulk {} data", request.numberOfActions());
}
@Override
public void afterBulk(long executionId, BulkRequest request, BulkResponse response) {
logger.info("{} data bulk success", request.numberOfActions());
}
@Override
public void afterBulk(long executionId, BulkRequest request, Throwable failure) {
logger.error("{} data bulk failed, reason:{}", request.numberOfActions(), failure);
}
};
BiConsumer<BulkRequest, ActionListener<BulkResponse>> bulkConsumer =
(request, bulkListener) ->
client.bulkAsync(request, RequestOptions.DEFAULT, bulkListener);
bulkProcessor = BulkProcessor.builder(bulkConsumer, listener)
.setBulkActions(10000) // 每添加1w条数据执行一次操作
.setBulkSize(new ByteSizeValue(5, ByteSizeUnit.MB)) // 每达到5m请求size执行一次操作
.setFlushInterval(TimeValue.timeValueSeconds(5)) // 每5s执行一次操作
.setConcurrentRequests(1) // 允许并发
.setBackoffPolicy(BackoffPolicy.exponentialBackoff(TimeValue.timeValueMillis(100), 3)) // 100ms后执行,最大请求3次
.build();
}O acima é para especificar o tipo de dados do campo usando o método api. Se a estrutura de dados da maioria dos índices for semelhante, você pode usar o modelo de índice para criá-lo. Não é demonstrado aqui. Os tipos de mapeamento acima são os seguintes:
"properties": {
"DstIp": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},Em relação à adição, exclusão e modificação de es, consulte o documento. Quando o processamento em lote é necessário, é recomendado usar o BulkProcessor acima em vez de BulkRequest. Parte do processamento lógico usado na consulta será apresentado abaixo.
endereço do documento es api: https://www.elastic.co/guide/en/elasticsearch/client/java-rest/6.7/java-rest-high-document-index.html
Quatro, consulta de combinação es
Esse também é um dos principais motivos pelos quais escolhemos usar o es: excelente desempenho de pesquisa. Aqui apenas apresenta a consulta combinada de es: bool query. A consulta bool corresponde a BooleanQuary em lucene. Consiste em uma ou mais cláusulas. Cada cláusula tem um tipo específico. Primeiro, apresentaremos as quatro combinações lógicas de consultas combinadas:
- deve: O documento devolvido deve atender às condições da cláusula must e participar do cálculo da pontuação
- filtro: O documento devolvido deve cumprir as condições da cláusula de filtro. Mas não participará do cálculo das pontuações como deve
- deve: O documento devolvido pode atender às condições da cláusula deve. Em uma consulta bool, se não houver must ou filter, e houver uma ou mais cláusulas should, ele pode ser retornado desde que uma seja satisfeita. O parâmetro minimum_should_match define pelo menos várias cláusulas a serem satisfeitas
- must_nout: O documento retornado não deve atender às condições definidas por must_not
Usar as quatro combinações acima pode basicamente satisfazer qualquer consulta complexa. Se uma consulta tiver um filtro e um deveria, então pelo menos uma cláusula deveria será incluída. O seguinte descreve o método de consulta específico: (o nome da classe entre colchetes abaixo corresponde a a api de es)
- match (matchQuery): consulta de correspondência, quando a consulta é executada, o termo de pesquisa será segmentado, desde que o documento corresponda a algum resultado da segmentação, será considerado um match
- match_phrase (matchPhraseQuery): consulta de correspondência de frase, o termo de pesquisa não será segmentado, mas diretamente na forma de uma consulta de frase, desde que os resultados da segmentação de palavras do campo estejam conectados para corresponder ao termo de pesquisa, é considerado satisfeito
- term (termQuery): consulta exata, não segmentará o termo de pesquisa, mas corresponderá ao campo de destino como um todo, se corresponder exatamente, pode ser consultado
- Termos (termsQuery): Encontre vários valores exatos, a consulta de termos é muito útil para encontrar um único valor, mas geralmente podemos querer pesquisar vários valores, os termos são uma operação de contenção e apenas um deles pode ser satisfeito
- range (rangeQuery): consulta de intervalo, geralmente usada para campos de número e data
- existe (existingQuery): consulta não vazia. Quando es serializa o documento, o valor nulo não é serializado por padrão. Se você deseja consultar dados onde um campo não está vazio, você pode usar existing para consultar
- wildcard (wildcardQuery): consulta difusa, semelhante a bancos de dados relacionais, tente usar match ou match_phrase para combinar (com índice)
A diferença entre termQuery e matchPhraseQuery : o primeiro não considera o conteúdo da segmentação da palavra, e apenas corresponde ao conteúdo do campo de acordo com o termo de pesquisa. Se for igual, está satisfeito; o último combinará as condições do campo correspondente após a segmentação da palavra, e se puder ser combinado em um termo de pesquisa e espaçado Is 0, é considerado
Cinco, interface gráfica
Para o desenvolvimento normal, é recomendado usar diretamente o plug-in chrome head, que é simples e fácil de usar, como:

Ou use a ferramenta de suporte kibana do es, e você pode fazer o download e instalá-la diretamente através do brew no mac: (observe que a versão do kibana e a versão do es precisam ser iguais, eu sou o kibana da 6.7.0 aqui)
brew install kibanaObserve que kibana depende do node.js. O endereço es ao qual kibana se conecta por padrão é local. Você pode ir para o diretório de instalação do kibana para modificar seu arquivo de configuração e, em seguida, inserir kibana diretamente na linha de comando para iniciá-lo. o sucesso é o seguinte:
Em seguida, visite localhost: 5601

Versões diferentes de kibana têm interfaces diferentes, então, contanto que você conheça a consulta de API básica
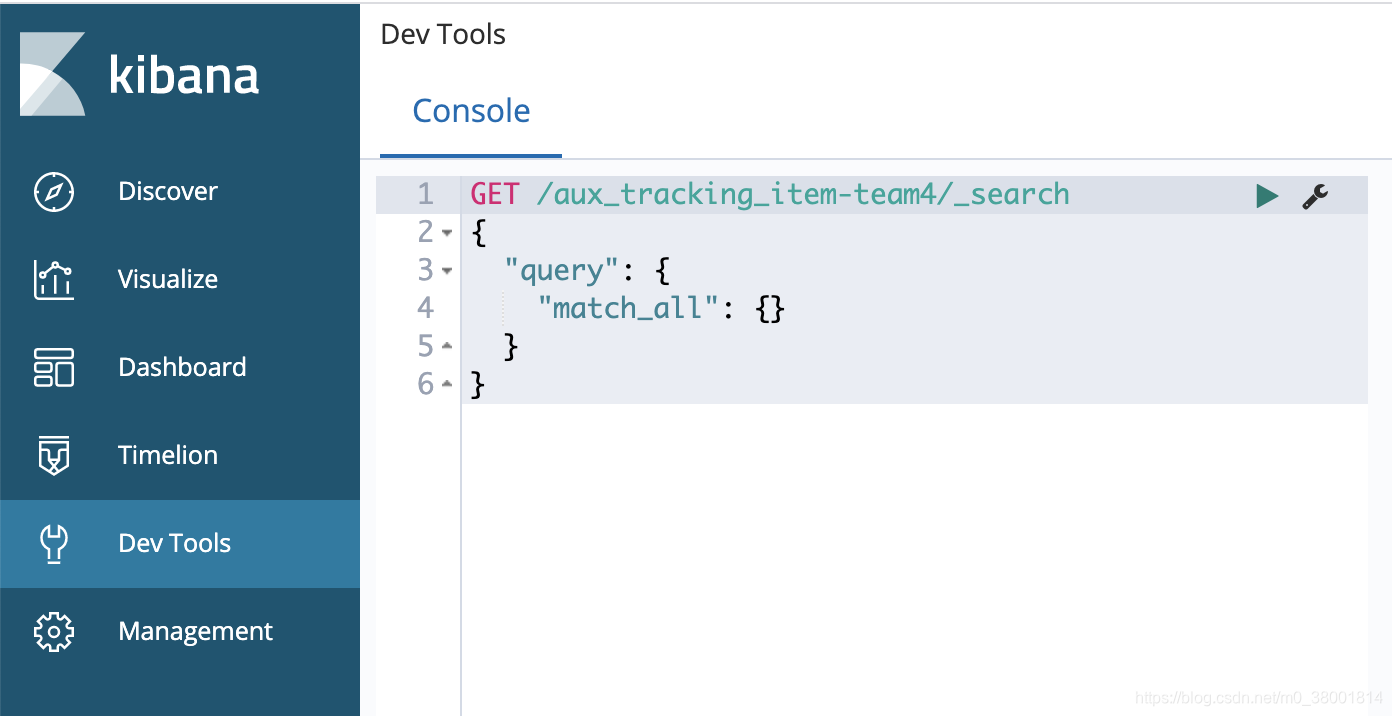
Seis, faz parte da RESTful-api
1. Exclua o índice: curl -XDELETE http: // xxx: 9200 / aux_tracking_item-team4
Suporte regular, como curl -XDELETE http: // xxx: 9200 / * _ tracking_item-team4
2. Visualize o resultado da segmentação de palavras de um determinado campo de dados: GET / $ {index} / $ {type} / $ {id} / _ termvectors? Fields = $ {fields_name}
3. Interface de segmentação de palavras de teste: post _analyze
{
"analyzer": "standard",
"text": "hello world"
}