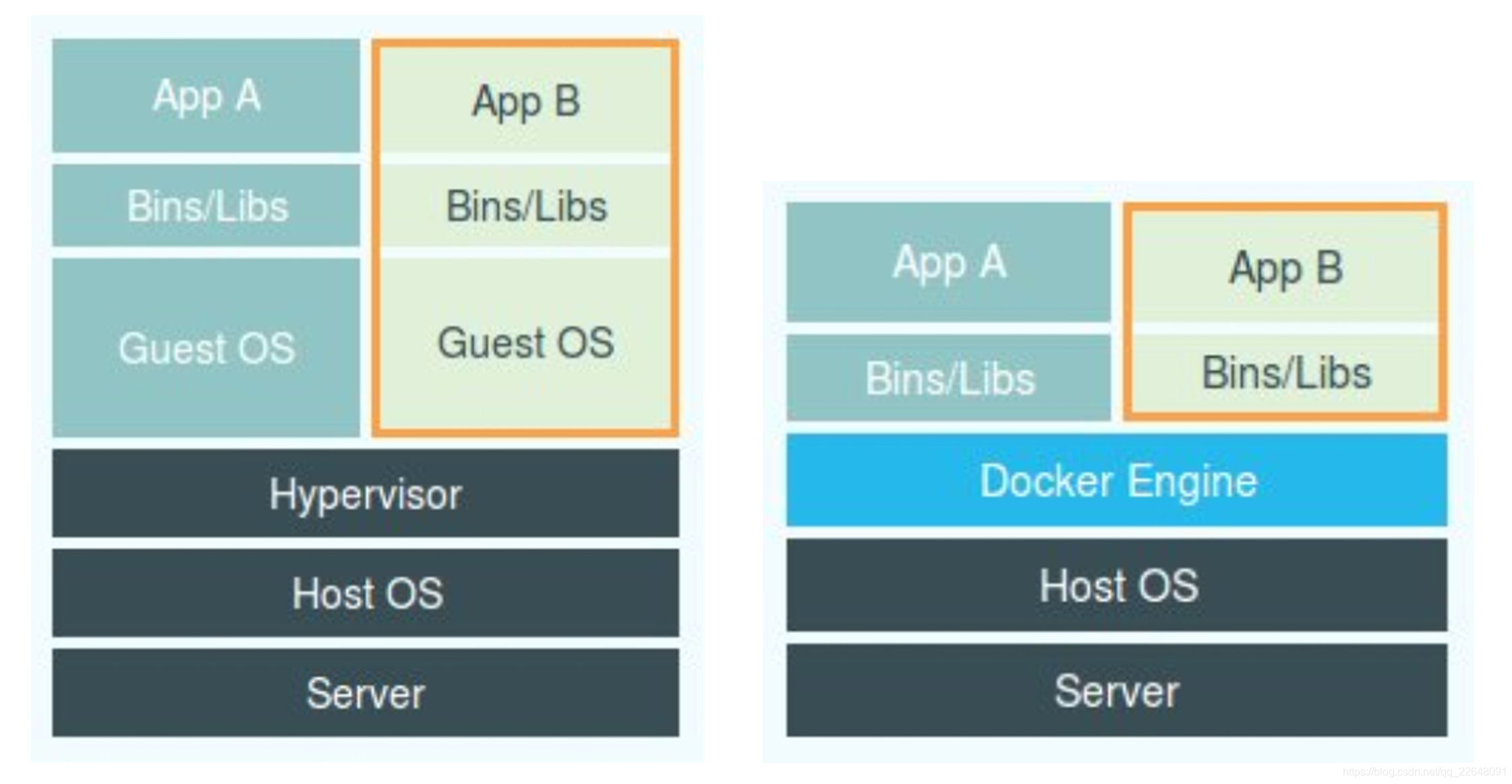
1. A tecnologia central da tecnologia de contêineres
Em primeiro lugar, a tecnologia do contêiner não é a tecnologia do Docker, mas a tecnologia do kernel Linux.
1 Reviva o processo
1.1 Procedimento
Suponha que agora você queira escrever um pequeno programa para calcular a adição. A entrada para este programa vem de um arquivo, e o resultado após o cálculo é enviado para outro arquivo.
Uma vez que o computador reconhece apenas 0 e 1, não importa qual idioma é usado para escrever este código, ele precisa ser traduzido em um arquivo binário de alguma forma antes de poder ser executado no sistema operacional do computador.
Para fazer com que esses códigos funcionem normalmente, muitas vezes temos que fornecer dados, como os arquivos de entrada necessários para nosso programa de adição. Esses dados mais o arquivo binário do próprio código, colocado no disco, é o que costumamos chamar de "programa", também chamado de imagem executável do código.
1.2 Processo
Em primeiro lugar, o sistema operacional descobre no "programa" que os dados de entrada estão armazenados em um arquivo, de modo que esses dados serão carregados na memória em espera. Ao mesmo tempo, o sistema operacional lê a instrução para calcular a adição.Neste momento, ele precisa instruir a CPU para concluir a operação de adição. A CPU coopera com a memória para realizar cálculos de adição e usa registradores para armazenar valores e pilhas de memória para armazenar comandos e variáveis executados. Ao mesmo tempo, existem arquivos abertos no computador e vários dispositivos de E / S estão constantemente ligando para modificar seu próprio estado. Desta forma, uma vez que o "programa" é executado, ele muda do arquivo binário no disco para os dados na memória do computador, o valor no registro, a instrução na pilha, o arquivo aberto e o status de vários dispositivos Uma coleção de informações. A soma do ambiente de execução do computador após a execução de um programa desse tipo é o processo.
A função central da atual tecnologia de contêineres de mãos vazias é criar um "limite" para ela, restringindo e modificando o desempenho dinâmico do processo.
Para a maioria dos contêineres Linux, como Docker, a tecnologia Cgroups é o principal método usado para criar restrições, e a tecnologia Namespace é o principal método usado para modificar a visualização do processo.
2 Isolamento de namespace de namespace
O espaço de nomes é usado para isolar diretamente o processo, o que garante que o processo só possa ver os recursos que especificamos.
Por exemplo, faça o seguinte experimento para entrar em cena.
mkdir -p container/{
lib64,tmp}
cp `ldd /usr/bin/bash | grep -P '/lib64/.*so.\d+' -o` container/lib64
cp -n `ldd /usr/bin/ls | grep -P '/lib64/.*so.\d+' -o` container/lib64/
cp -n `ldd /usr/bin/pwd | grep -P '/lib64/.*so.\d+' -o` container/lib64
cp /usr/bin/{
bash,ls,pwd} container/
Em seguida, execute o seguinte comando
chroot container /bash
chrootA função do comando é ajudá-lo a "mudar o sistema de arquivos raiz", ou seja, mudar o diretório raiz do processo para o local que você especificar.
Após a reexecução /pwde /lscomando
Coisas estranhas acontecem com tanta frequência, e mais importante, para o processo chroot, ele não sentirá que seu diretório raiz foi "modificado".
Este é o efeito de um Mount Namespace de muitos namespaces do Linux.
Na verdade, o Mount Namespace foi inventado com base no aprimoramento contínuo do chroot, sendo também o primeiro Namespace no sistema operacional Linux.
Obviamente, para fazer com que o diretório raiz do contêiner pareça mais "real", geralmente montamos um sistema de arquivos de um sistema operacional completo sob o diretório raiz do contêiner, como a estrutura de diretórios do Centos7. Desta forma, após o container ser iniciado, executamos "ls /" no container para ver o conteúdo do diretório raiz, que são todos os diretórios e arquivos do Centos7.
A tecnologia de namespace, na verdade, modifica a "visão" do processo do aplicativo para todo o computador, ou seja, sua "linha de visão" é restrita pelo sistema operacional e só pode "ver" determinado conteúdo especificado. Mas, para o host, esses processos "isolados" não são muito diferentes de outros processos.
O sistema de arquivos montado no diretório raiz do contêiner e usado para fornecer um ambiente de execução isolado para o processo do contêiner é a chamada "imagem do contêiner". Ele também tem um nome mais profissional, chamado: rootfs (sistema de arquivos raiz)
Nota: No kernel do Linux, há muitos recursos e objetos que não podem ter namespaces. O exemplo mais típico é o tempo.
Limite de recursos de 2 Cgroups
Depois de introduzir a tecnologia de "isolamento" dos contêineres, vamos examinar as "limitações" dos contêineres.
Linux Cgroups é uma função importante no kernel Linux usada para definir limites de recursos para processos.
O nome completo de Linux Cgroups é Linux Control Group. Sua função principal é limitar o limite superior de recursos que um grupo de processos pode usar, incluindo CPU, memória, disco, largura de banda da rede e assim por diante.
Além disso, os Cgroups também podem definir prioridades, auditar processos e suspender e retomar processos.
No momento, vou me concentrar apenas em falar com você sobre os recursos "restritos" que estão mais intimamente relacionados aos contêineres e apresentarei os Cgroups por meio de um conjunto de práticas.
No Linux, Cgroups expostos à interface do usuário é uma operação do sistema de arquivos, ou seja, a forma como está organizado em diretórios e arquivos do sistema operacional /sys/fs/cgroupdo caminho.
mount -t cgroup
Como você pode ver, existem muitos subdiretórios como cpuset, cpu e memory em / sys / fs / cgroup, que também são chamados de subsistemas. Esses são os tipos de recursos que podem ser restringidos por Cgroups em minha máquina. E sob o tipo de recurso correspondente ao subsistema, você pode ver os métodos específicos que podem ser restritos para este tipo de recurso. Por exemplo, para o subsistema CPU, podemos ver os seguintes arquivos de configuração. Este comando é:
[root@localhost ~]# ls /sys/fs/cgroup/cpu
cgroup.clone_children cpuacct.usage_percpu cpu.stat
cgroup.event_control cpu.cfs_period_us notify_on_release
cgroup.procs cpu.cfs_quota_us release_agent
cgroup.sane_behavior cpu.rt_period_us tasks
cpuacct.stat cpu.rt_runtime_us
cpuacct.usage cpu.shares
[root@localhost ~]#
Atenção cpu.cfs_period_usepu.cfs_quota_us
Esses dois parâmetros precisam ser usados em combinação, podem ser usados para limitar a duração do processo em cpu.cfs_period_usum período de tempo, só podem ser atribuídos a uma quantidade total de pu.cfs_quota_ustempo de CPU.
A seguir, vamos usá-los para conduzir um pequeno experimento para entrar em cena.
Agora entre no diretório / sys / fs / cgroup / cpu:
[root@localhost ~]# cd /sys/fs/cgroup/cpu
Em seguida, crie um diretório container
[root@localhost cpu]# mkdir container
Em seguida, observe o conteúdo deste diretório
[root@localhost cpu]# ls container/
cgroup.clone_children cpuacct.usage_percpu cpu.shares
cgroup.event_control cpu.cfs_period_us cpu.stat
cgroup.procs cpu.cfs_quota_us notify_on_release
cpuacct.stat cpu.rt_period_us tasks
cpuacct.usage cpu.rt_runtime_us
[root@localhost cpu]#
Este diretório é denominado "grupo de controle". Você descobrirá que o sistema operacional gerará automaticamente o arquivo de limite de recursos correspondente ao subsistema no diretório de contêiner recém-criado.
Agora, executamos esse script em segundo plano:
while : ; do : ; done &
[root@localhost cpu]# jobs -l
[1]+ 1752 Running while :; do
:;
done &
Em seguida, observe o uso da CPU por meio do comando top
Como você pode ver na saída, o uso da CPU foi de 100%
[root@localhost cpu]# cat /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
-1
[root@localhost cpu]# cat /sys/fs/cgroup/cpu/container/cpu.cfs_period_us
100000
[root@localhost cpu]#
Em seguida, podemos definir restrições modificando o conteúdo desses arquivos. Por exemplo, escreva 20 ms (20000 us) no arquivo cfs_quota no grupo de contêineres
echo 20000 > container2/cpu.cfs_quota_us
Combinado com a introdução anterior, você deve ser capaz de entender o significado desta operação, isso significa que a cada 100 ms de tempo, o processo restrito pelo grupo de controle pode usar apenas 20 ms de tempo de CPU, o que significa que este processo pode use apenas 20% da largura de banda da CPU. Em seguida, gravamos o PID do processo restrito no arquivo de tarefas no grupo de contêineres e as configurações acima entrarão em vigor para o processo:
echo 1752 > /sys/fs/cgroup/cpu/container/tasks
Veja o comando principal novamente
Como você pode ver, o uso da CPU do computador caiu imediatamente para 20%