Introdução: Este artigo é compartilhado por Apache Flink PMC, especialista técnico sênior da Alibaba Li Yu. Ele apresenta principalmente o princípio do mecanismo de tolerância a falhas de Flink em quatro aspectos: computação de fluxo com estado, instantâneos globalmente consistentes, mecanismo de tolerância a falhas de Flink e gerenciamento de estado de Flink.
Autor | Li Yu
Compartilhado por: Este artigo é compartilhado por Apache Flink PMC, especialista técnico sênior da Alibaba Li Yu. Ele apresenta principalmente o princípio do mecanismo de tolerância a falhas de Flink. O esboço do conteúdo é o seguinte:
- Computação de fluxo com estado
- Instantâneo globalmente consistente
- Mecanismo de tolerância a falhas de Flink
- Gestão do estado de Flink
1. Computação de fluxo com estado
Computação em fluxo
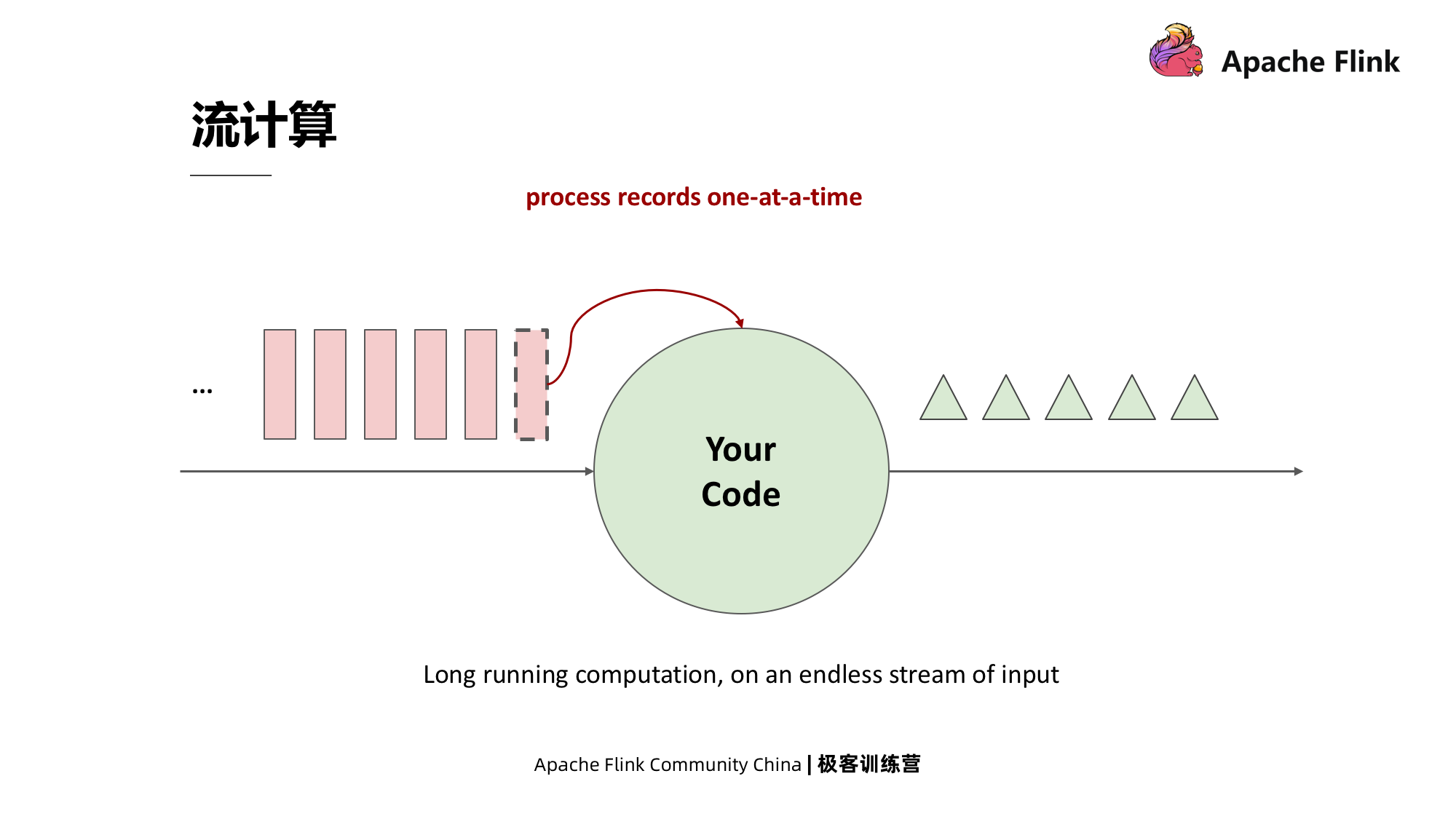
A computação em fluxo significa que há uma fonte de dados que pode enviar mensagens continuamente e, ao mesmo tempo, um programa residente que executa o código. Depois de receber uma mensagem da fonte de dados, ele a processa e, em seguida, envia o resultado para a jusante.
Computação de fluxo distribuído
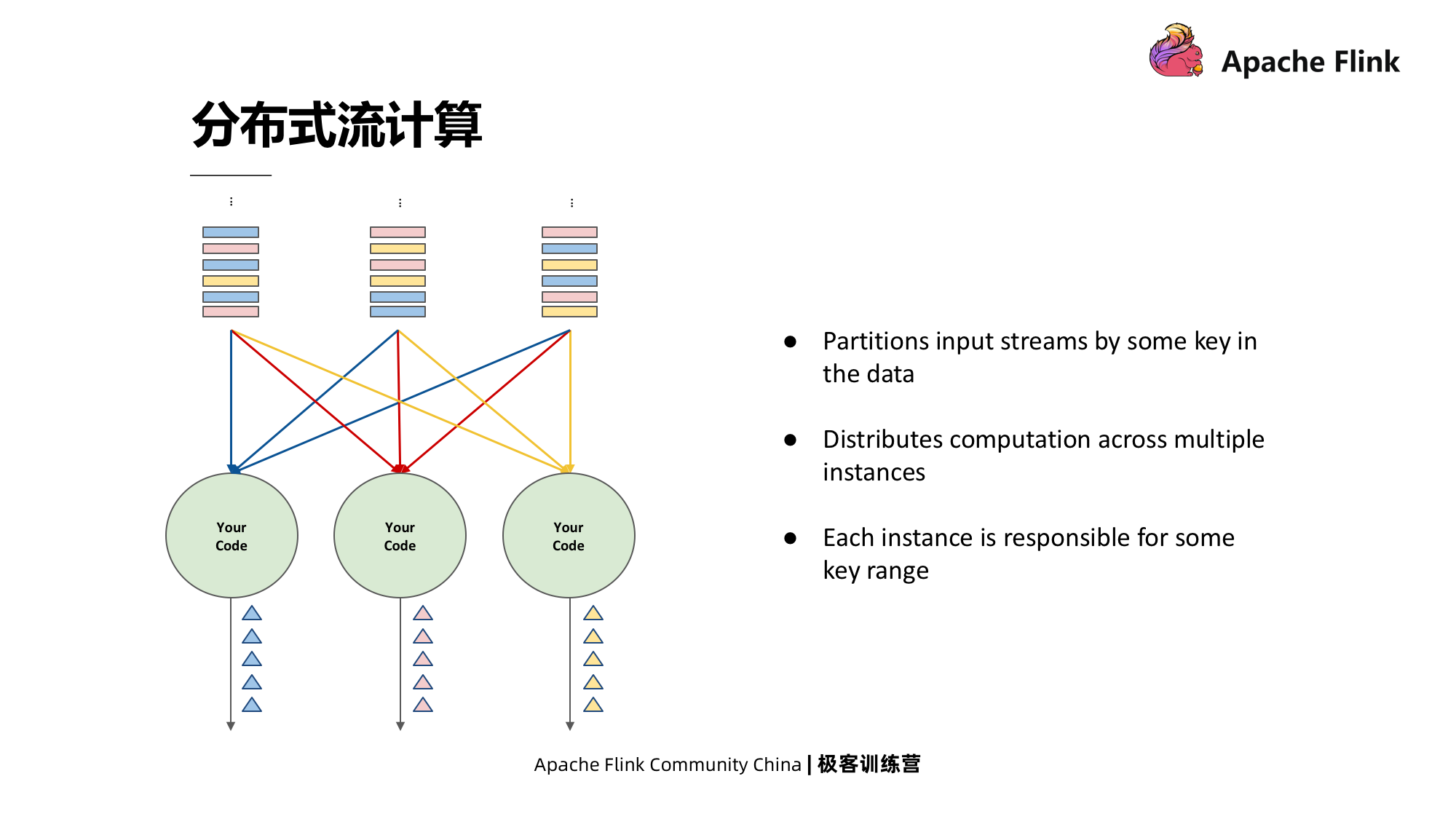
A computação de fluxo distribuído se refere à divisão do fluxo de entrada de uma determinada maneira e, em seguida, ao uso de várias instâncias distribuídas para processar o fluxo.
Estado na computação de fluxo
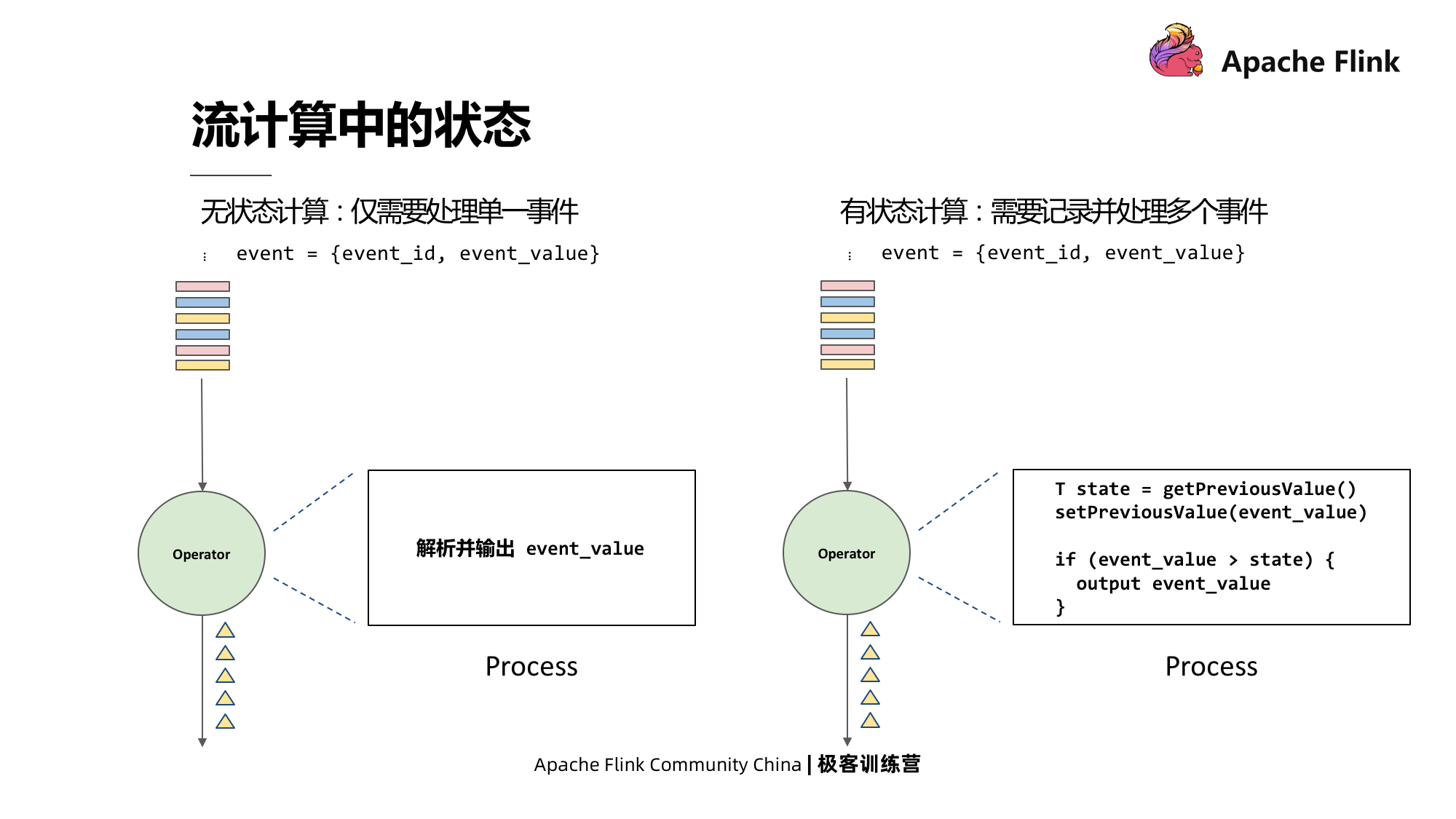
A computação pode ser dividida em com e sem estado. A computação sem estado só precisa processar um único evento, enquanto a computação com estado precisa registrar e processar vários eventos.
Dê um exemplo simples. Por exemplo, um evento consiste em duas partes: ID do evento e valor do evento. Se a lógica de processamento for analisar e emitir o valor do evento toda vez que um evento for obtido, então este é um cálculo sem estado; pelo contrário, se toda vez que um estado é obtido, depois que seu valor é analisado, ele precisa ser comparado com o valor do evento anterior e é emitido apenas quando for maior do que o valor do evento anterior.Este é um cálculo com estado.

Existem muitos estados na computação em fluxo. Por exemplo, no cenário de desduplicação, todas as chaves primárias são registradas; ou no cálculo da janela, os dados que entraram na janela, mas não foram acionados, este também é o estado da computação em fluxo; no cenário de aprendizado de máquina / aprendizado profundo , o modelo treinado e Os dados do parâmetro são o estado da computação em fluxo.
2. Instantâneo globalmente consistente
Instantâneos globalmente consistentes são um mecanismo que pode ser usado para backup e recuperação de falhas de sistemas distribuídos.
Instantâneo global
O que é um instantâneo global

O instantâneo global é, em primeiro lugar, um aplicativo distribuído, que tem vários processos distribuídos em vários servidores; em segundo lugar, tem sua própria lógica de processamento e estado dentro do aplicativo; terceiro, os aplicativos podem se comunicar entre si; quarto, em Este tipo de aplicativo distribuído possui estado e o hardware podem se comunicar.O estado global em um determinado momento é chamado de instantâneo global.
Por que um instantâneo global é necessário

- Primeiro, use-o como um ponto de verificação, você pode fazer backup periodicamente do estado global e, quando o aplicativo falhar, ele pode ser usado para restaurar;
- Em segundo lugar, faça a detecção de deadlock.Depois que o instantâneo é obtido, o programa atual continua a ser executado e, em seguida, o instantâneo pode ser analisado para ver se o aplicativo está em um estado de conflito e, se estiver, pode ser processado de acordo.
Exemplo de instantâneo global
A figura abaixo é um exemplo de instantâneo global em um sistema distribuído.
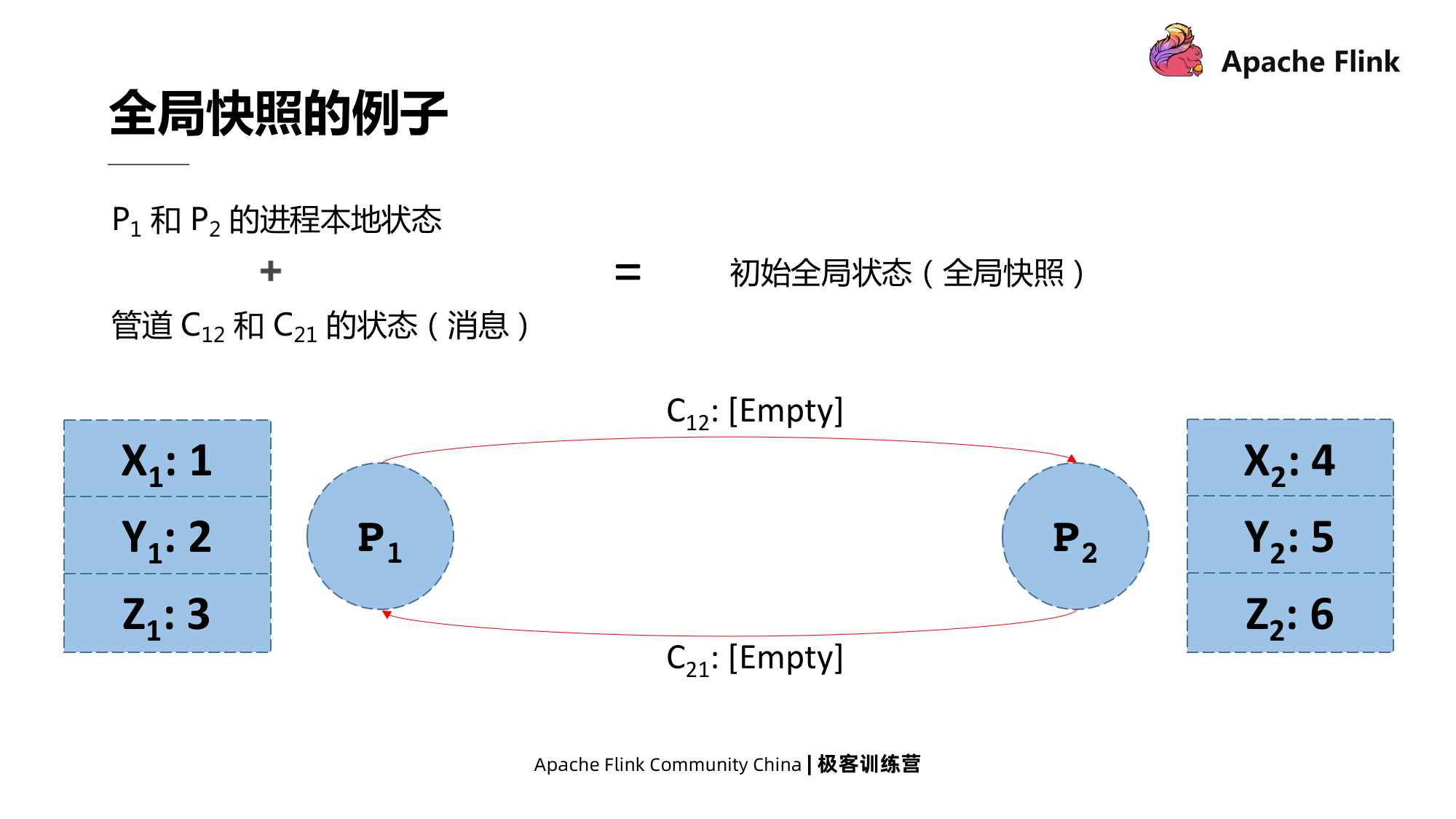
P1 e P2 são dois processos e existem canais para o envio de mensagens entre eles, que são C12 e C21. Para o processo P1, C12 é o canal pelo qual ele envia mensagens, denominado canal de saída; C21 é o canal pelo qual recebe mensagens, denominado canal de entrada.
Exceto para tubos, todo processo tem um estado local. Por exemplo, na memória de cada processo de P1 e P2, existem três variáveis XYZ e valores correspondentes. Então, o estado local dos processos P1 e P2 e o estado do pipeline para enviar mensagens entre eles é um estado global inicial, que também pode ser chamado de instantâneo global.
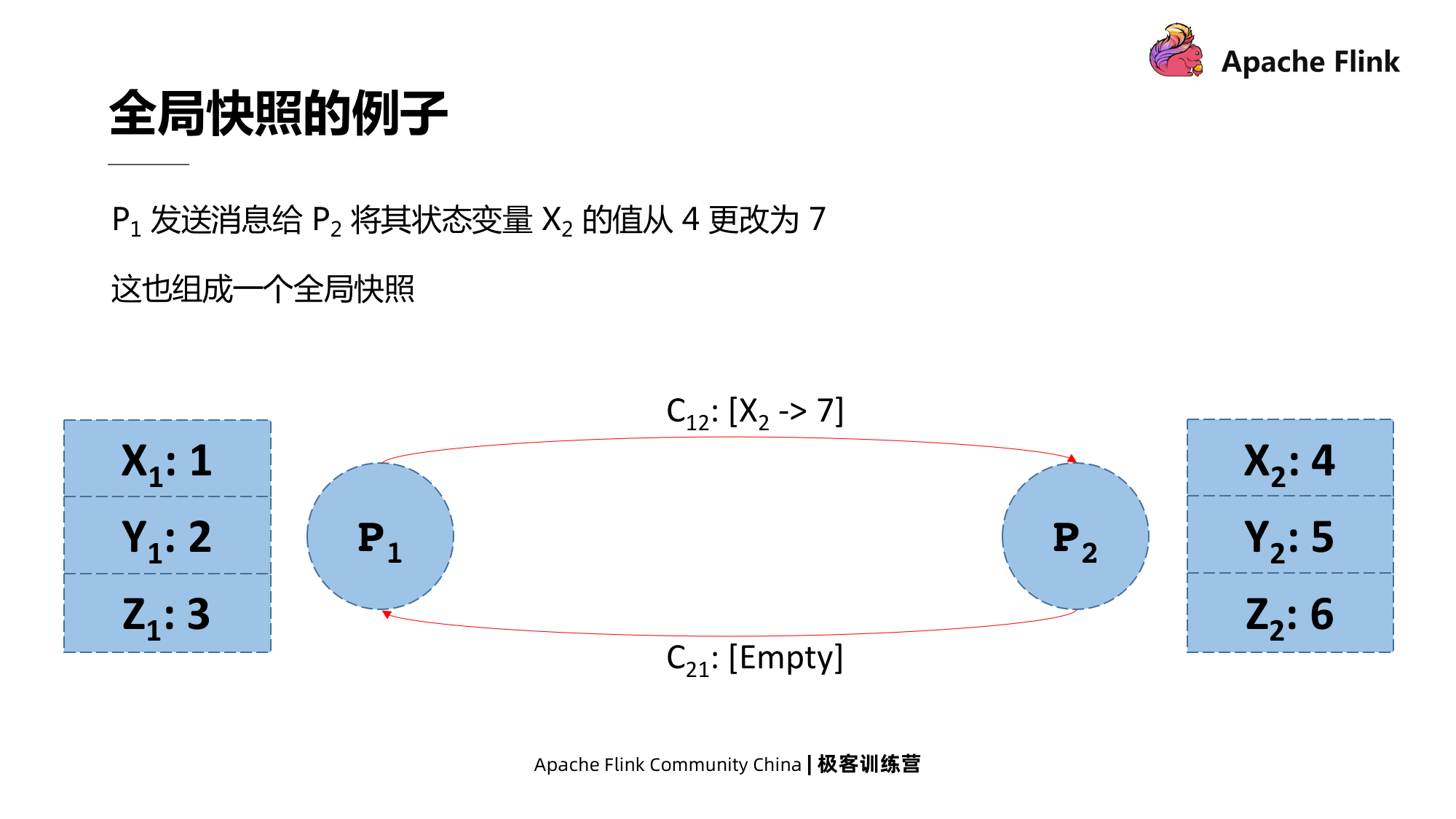
Suponha que P1 envie uma mensagem para P2 e peça a P2 para alterar o valor do estado de x de 4 para 7, mas essa mensagem está no pipeline e ainda não atingiu P2. Este estado também é um instantâneo global.
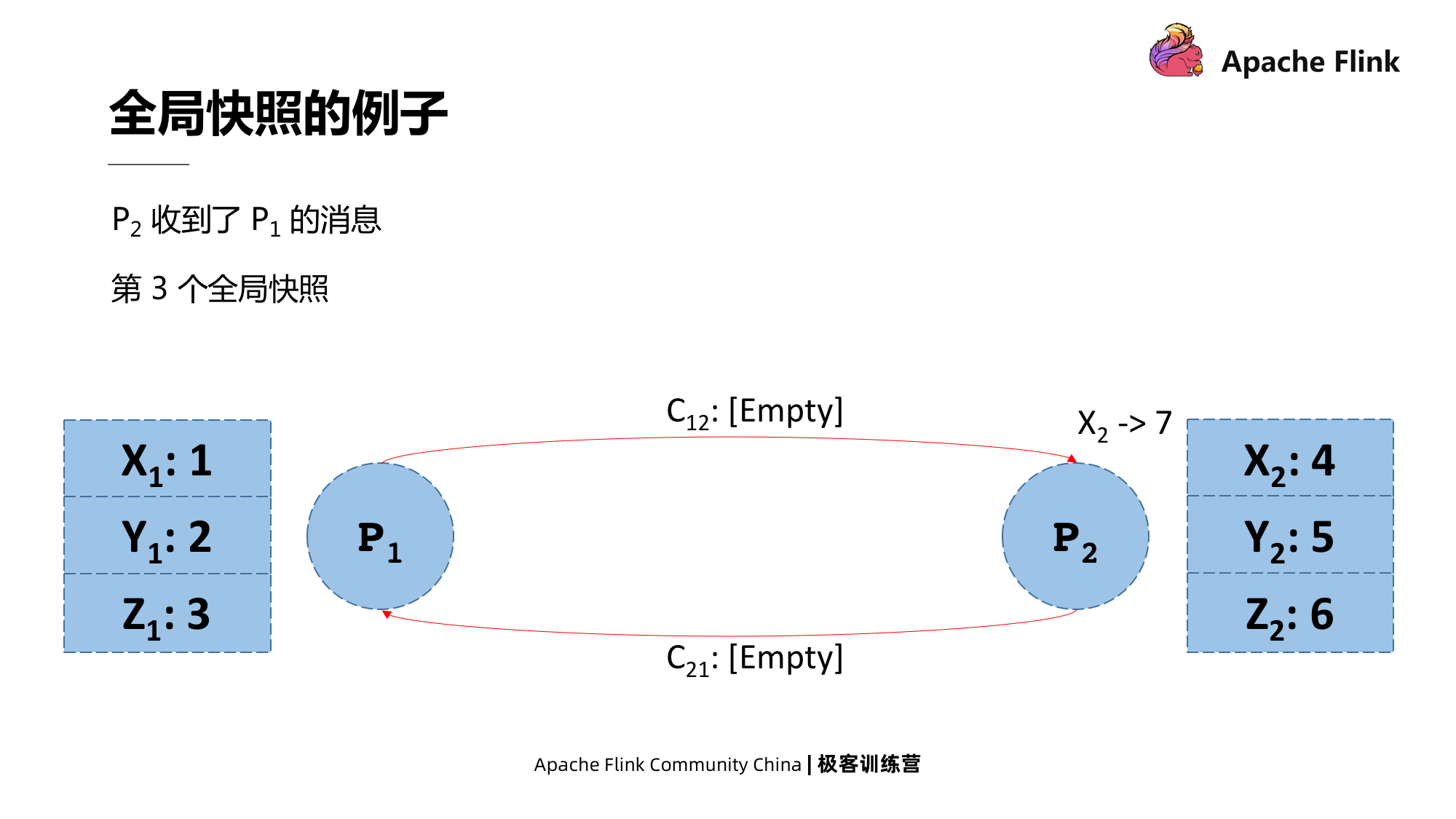
Em seguida, P2 recebeu a mensagem de P1, mas ela ainda não foi processada.Este estado também é um instantâneo global.
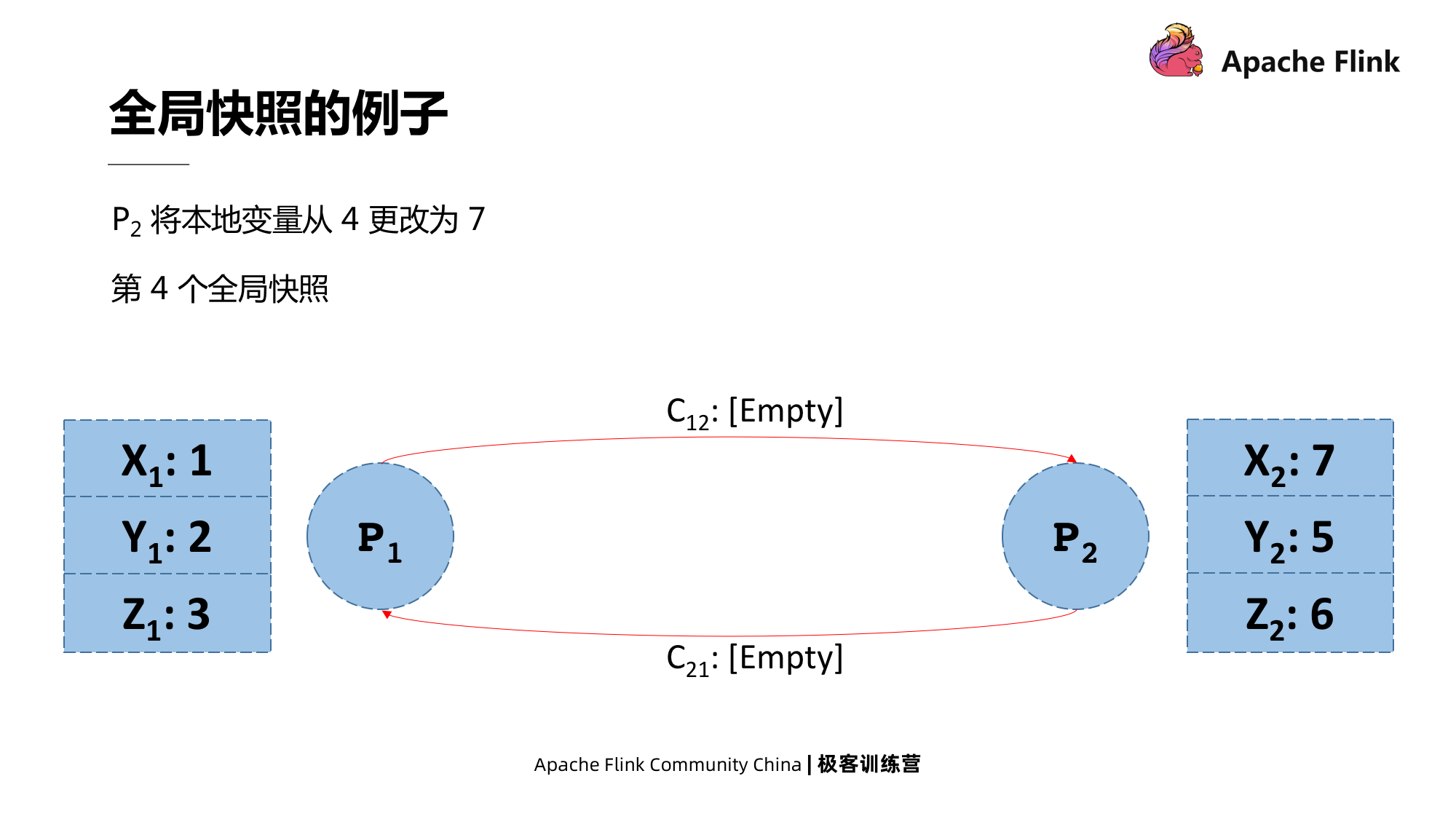
Por fim, P2, que recebeu a mensagem, alterou o valor do local X de 4 para 7, que também é um instantâneo global.
Portanto, quando ocorre um evento, o estado global muda. Os eventos incluem processos de envio de mensagens, processos de recebimento de mensagens e processos de modificação de seu próprio estado.
2. Instantâneos globalmente consistentes

Se houver dois eventos, a e b, em tempo absoluto, se a ocorrer antes de b e b ser incluído no instantâneo, então a também será incluído no instantâneo. Um instantâneo global que atenda a essa condição é chamado de instantâneo consistente globalmente.
2.1 Método de implementação de instantâneo globalmente consistente
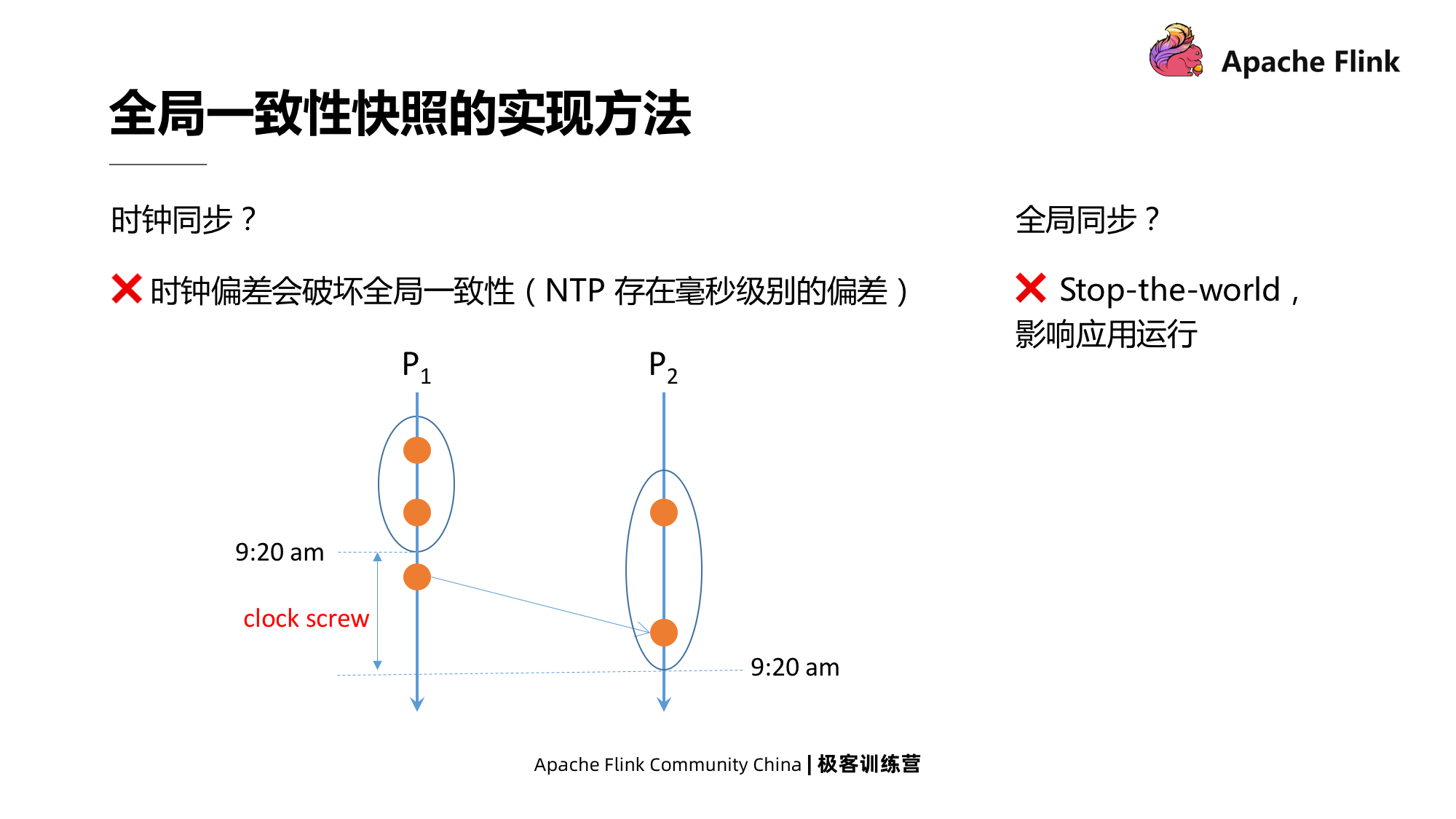
A sincronização do relógio não pode alcançar instantâneos de consistência global; embora a sincronização global possa ser alcançada, suas deficiências também são muito óbvias. Ela interromperá todos os aplicativos e afetará o desempenho global.
3. Algoritmo de instantâneo de consistência global assíncrona - Chandy-Lamport
O algoritmo de instantâneo assíncrono globalmente consistente Chandy-Lamport pode obter um instantâneo consistente globalmente sem afetar a operação do aplicativo.
Os requisitos de sistema de Chandy-Lamport são os seguintes:
- Em primeiro lugar, não afeta o funcionamento do aplicativo, ou seja, não afeta o envio e o recebimento de mensagens, e não há necessidade de interromper o aplicativo;
- Em segundo lugar, cada processo pode registrar o estado local;
- Terceiro, o estado registrado pode ser coletado de maneira distribuída;
- Quarto, qualquer processo pode iniciar um instantâneo
Ao mesmo tempo, existe outro pré-requisito para que o algoritmo Chandy-Lamport possa ser executado: as mensagens são ordenadas e não repetitivas, e a confiabilidade das mensagens pode ser garantida.
3.1 Fluxo do algoritmo Chandy-Lamport
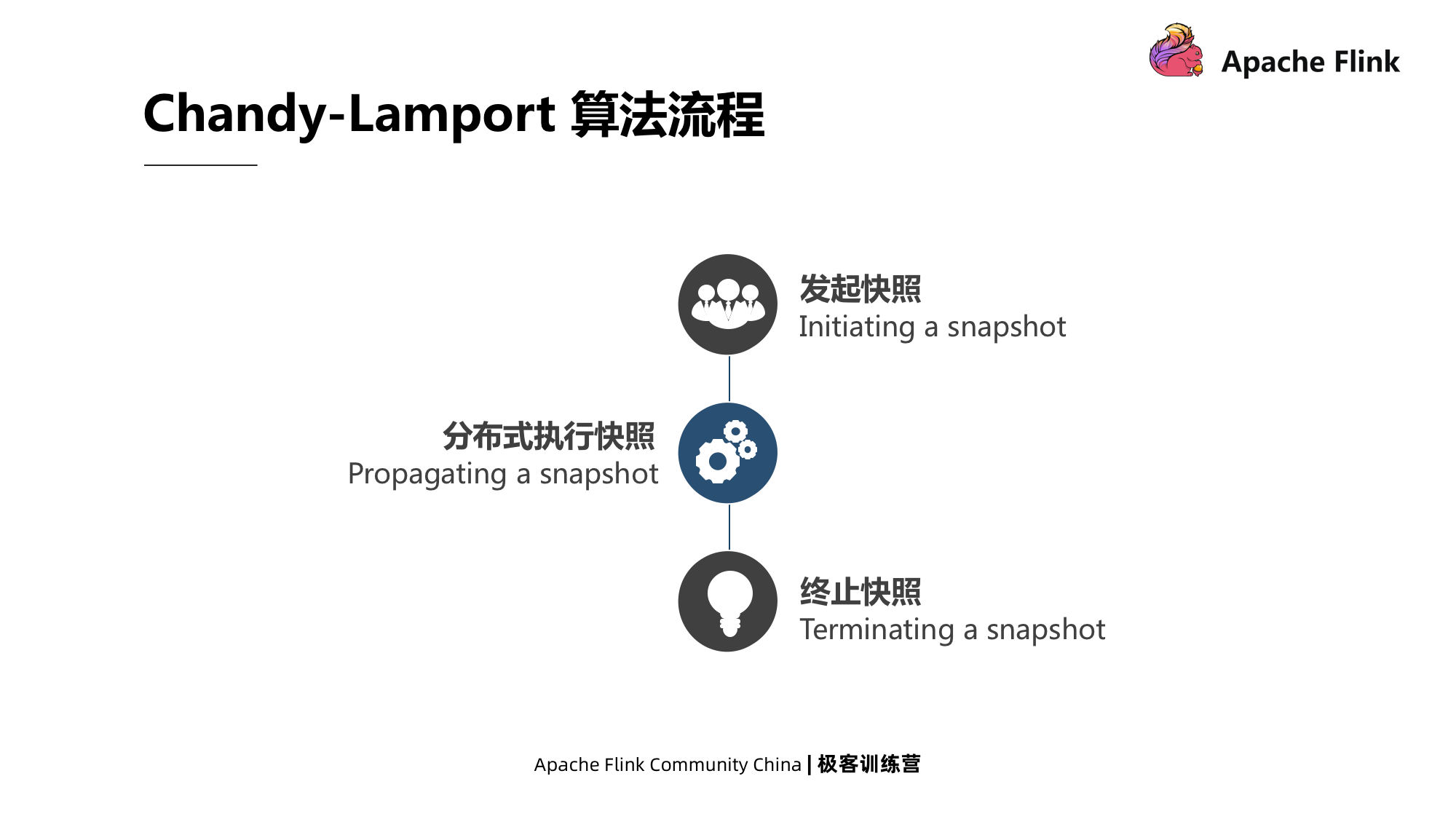
O fluxo do algoritmo de Chandy-Lamport é dividido principalmente em três partes: iniciar instantâneo, instantâneo de execução distribuída e encerrar instantâneo.
Iniciar um instantâneo
Qualquer processo pode iniciar um instantâneo. Conforme mostrado na figura abaixo, quando P1 inicia um instantâneo, a primeira etapa é registrar o estado local, ou seja, fazer um instantâneo do local e, em seguida, enviar imediatamente uma mensagem de marcador para todos os seus canais de saída. intervalo de tempo entre. A mensagem do marcador é uma mensagem especial, diferente das mensagens transmitidas entre os aplicativos.
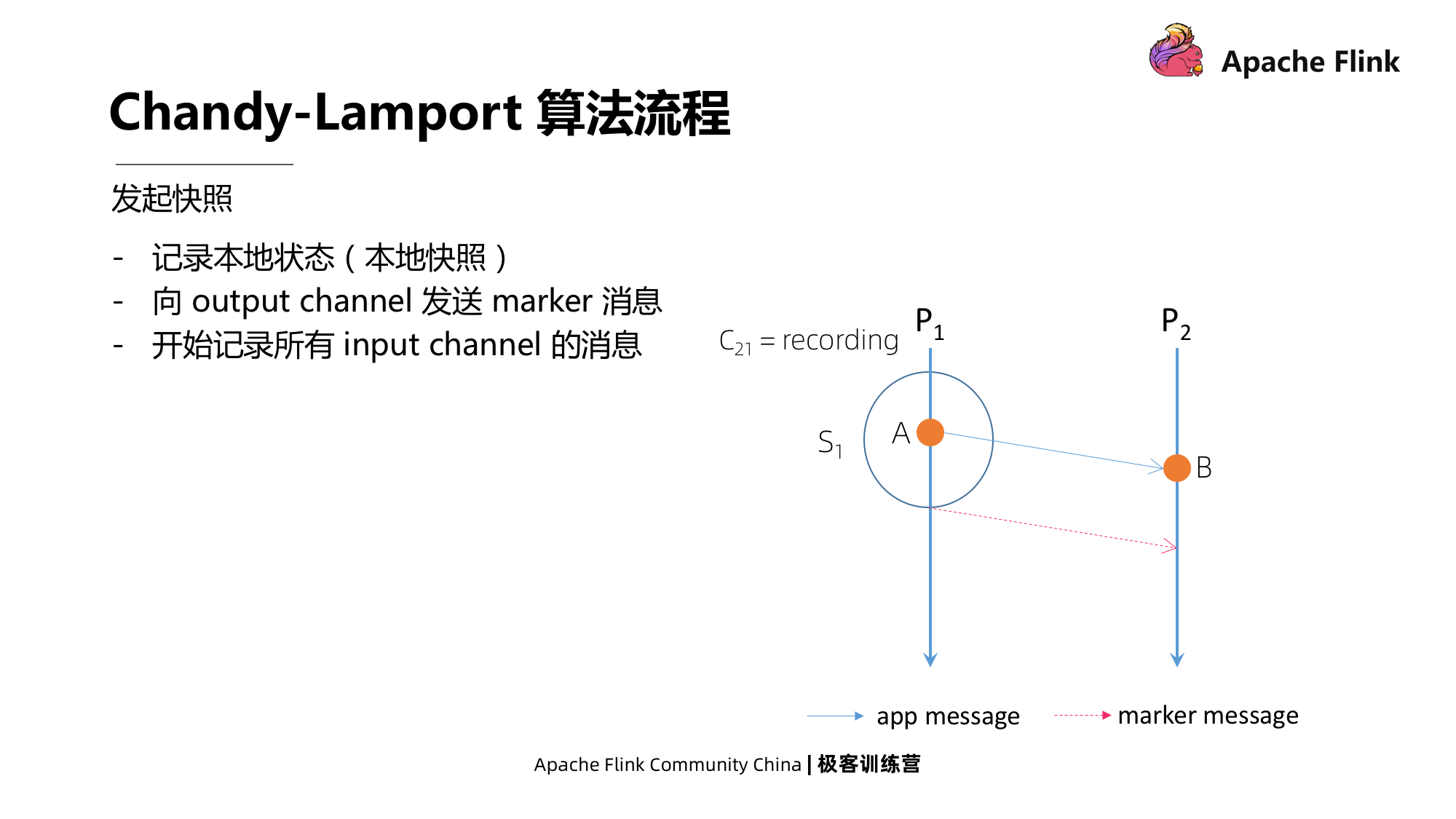
Após o envio da mensagem Marker, P1 passará a registrar todas as mensagens do canal de entrada, que é a mensagem do pipeline C21 mostrada na figura.
Snapshot de execução distribuída
Conforme mostrado na figura abaixo, primeiro suponha que quando Pi recebe uma mensagem de marcador de Cki, isto é, uma mensagem de marcador enviada por Pk para Pi. Pode ser visto em duas situações:
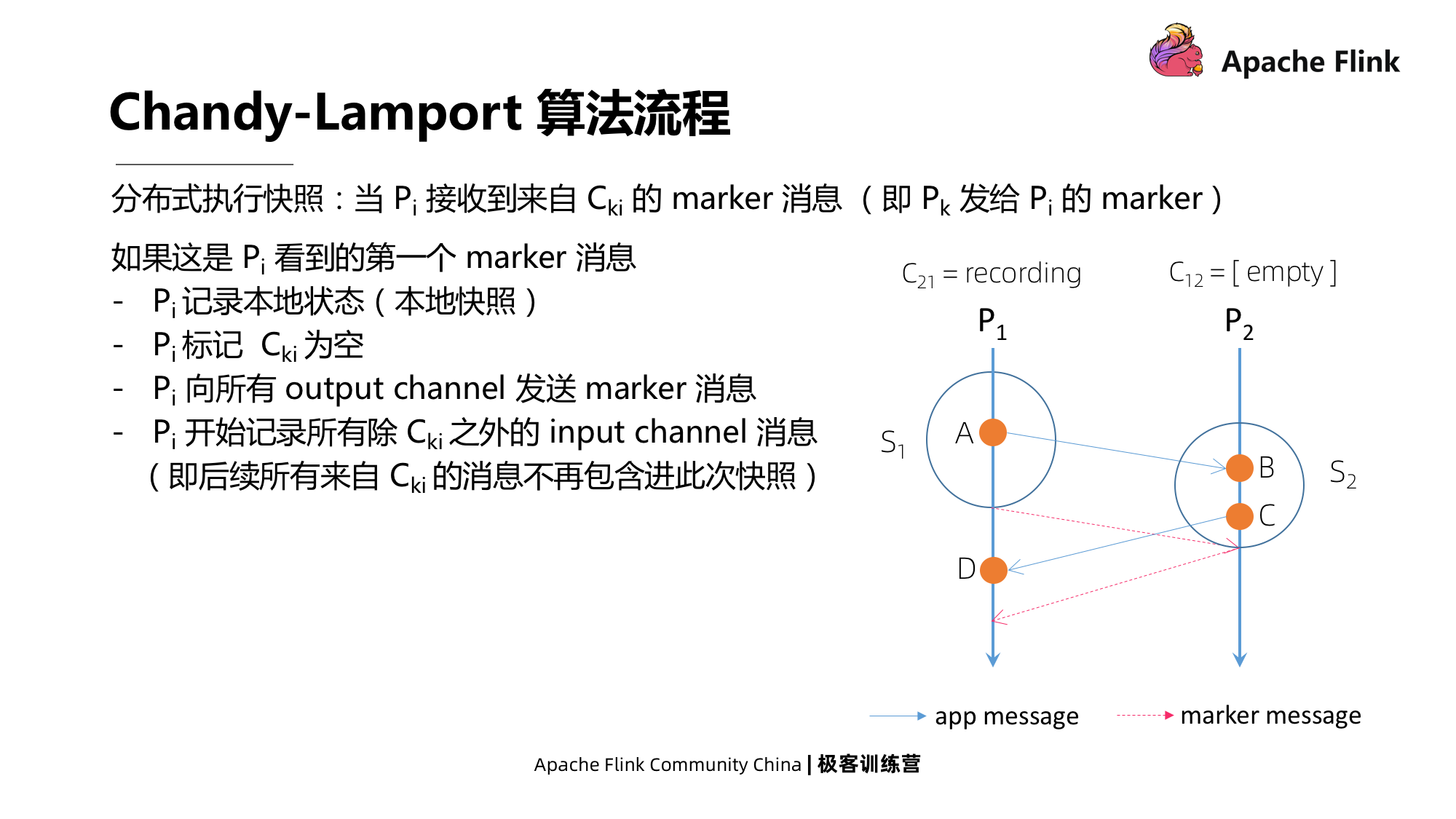
O primeiro caso: Este é o primeiro marcador de mensagem recebido por Pi de outros canais. Ele registrará o estado local primeiro e, em seguida, marcará o canal C12 como vazio. Ou seja, se a mensagem for enviada de P1 posteriormente, ela não Está incluído neste instantâneo e, ao mesmo tempo, envia imediatamente uma mensagem de marcador para todos os seus canais de saída. Finalmente, comece a gravar mensagens de todos os canais de entrada, exceto Cki.
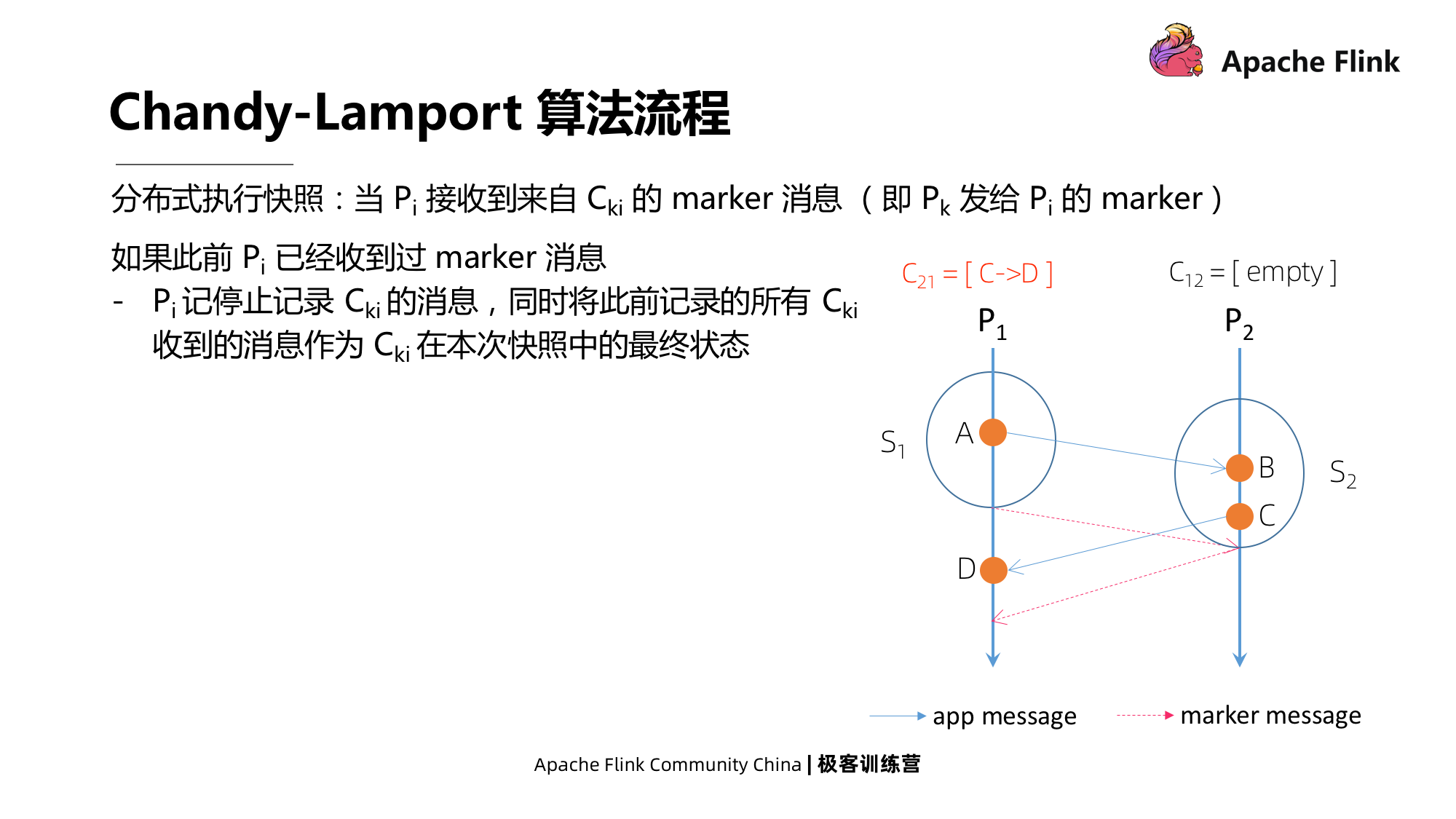
Como mencionado acima, as mensagens Cki não são incluídas no instantâneo em tempo real, mas as mensagens em tempo real ainda ocorrerão, então o segundo caso é que se Pi recebeu mensagens de marcador antes, ele irá parar de gravar mensagens Cki e também gravará todas Mensagens Cki gravadas anteriormente. A mensagem é salva como o estado final de Cki neste instantâneo.
Encerrar instantâneo
Existem duas condições para encerrar um instantâneo:
- Primeiro, todos os processos receberam a mensagem do marcador e a registraram no instantâneo local;
- Em segundo lugar, todos os processos receberam mensagens de marcador de seus canais de entrada n-1 e registraram o status do pipeline.
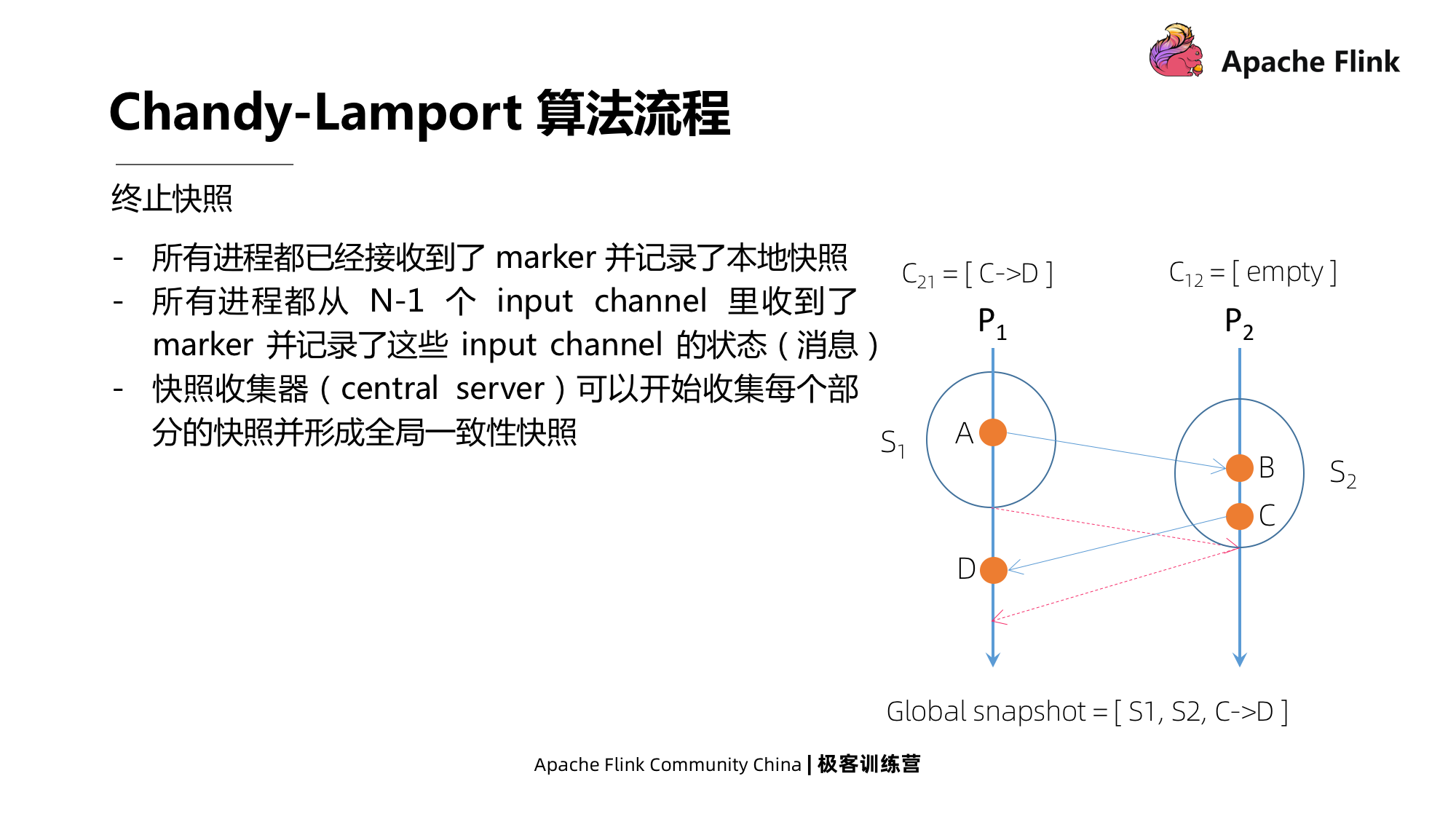
Quando a captura instantânea é finalizada, o coletor de captura instantânea (Servidor Central) começa a coletar cada parte da captura instantânea para formar uma captura instantânea consistente globalmente.
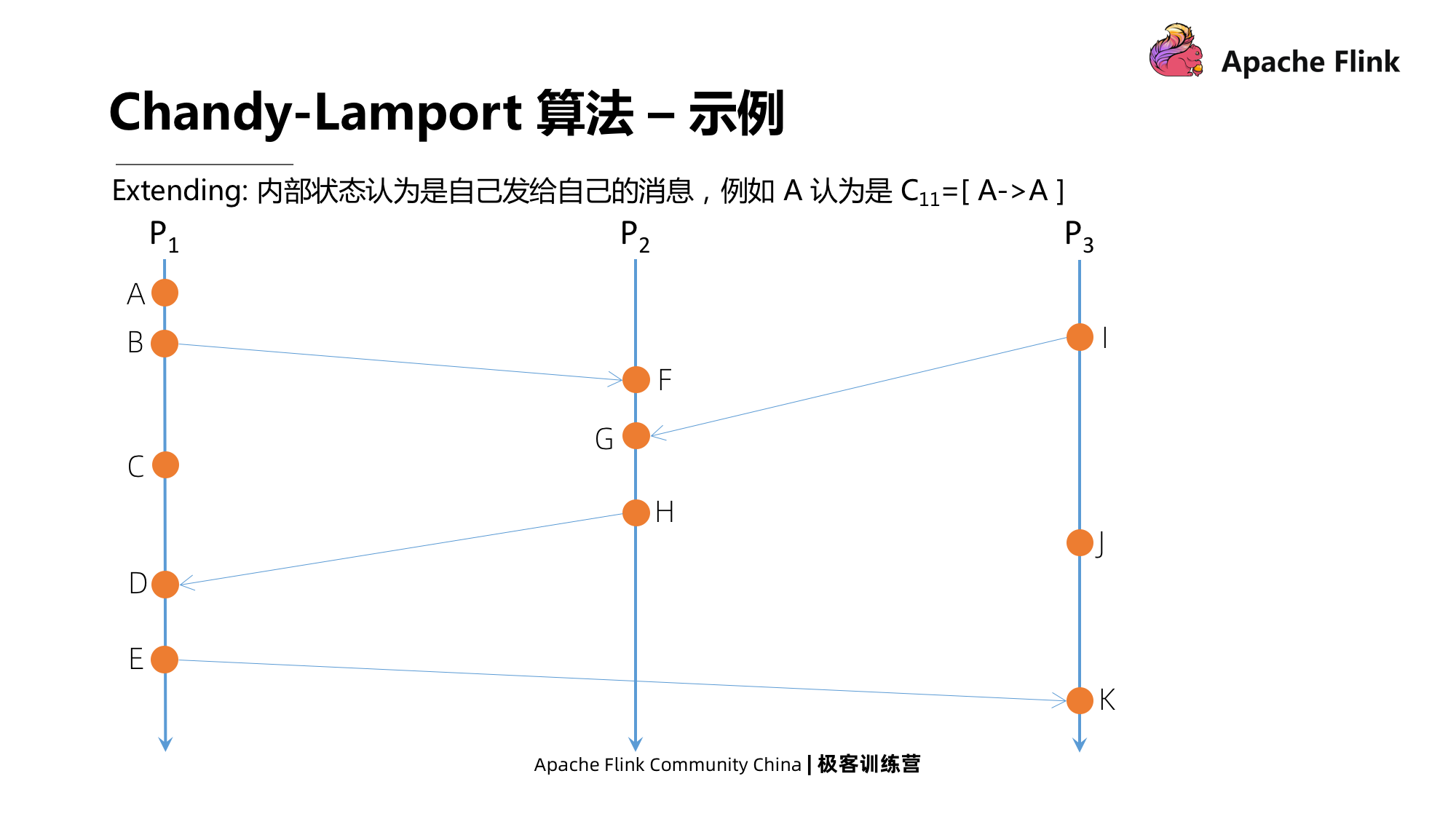
Amostra de exibição
No exemplo da figura abaixo, alguns estados ocorrem internamente, como A, que não tem interação com outros processos. O estado interno é que P1 envia uma mensagem para si mesmo, e A pode ser considerado C11 = [A->].
Como o algoritmo de instantâneo de consistência global Chandy-Lamport é implementado?
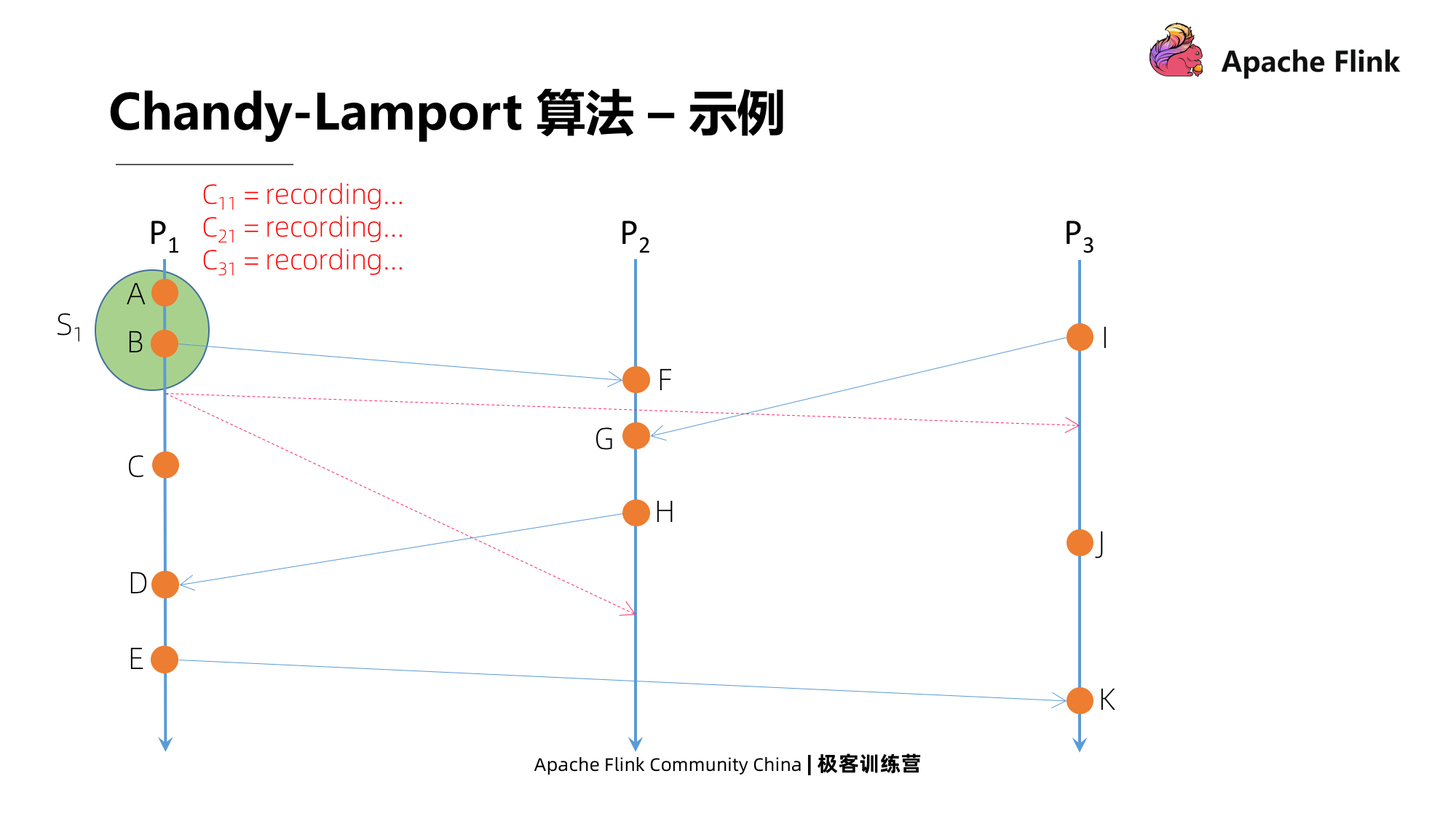
Suponha que um instantâneo seja iniciado a partir de p1. Ao iniciar um instantâneo, ele primeiro tira um instantâneo do estado local, que é chamado de S1 e, em seguida, envia imediatamente mensagens de marcador para todos os seus canais de saída, ou seja, P2 e P3, e então registra A mensagem do canal de entrada é a mensagem de P2 e P3 e dele mesmo.
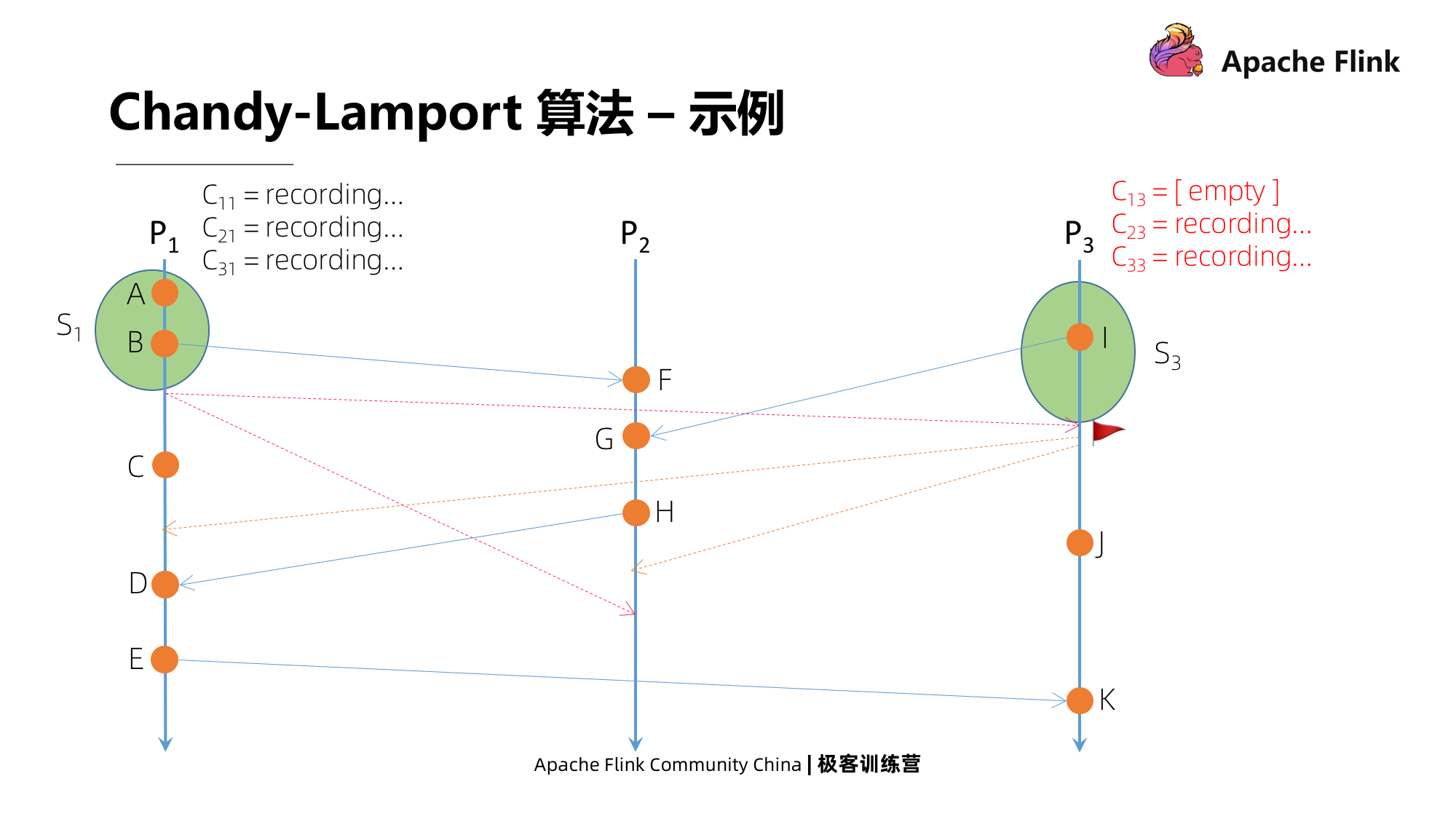
Conforme mostrado na legenda, o eixo vertical é o tempo absoluto. De acordo com o tempo absoluto, por que há uma diferença de tempo entre P3 e P2 quando eles recebem a mensagem do marcador? Porque se este é um processo distribuído em um ambiente físico real, as condições de rede entre os diferentes nós são diferentes, o que levará a diferenças no tempo de entrega da mensagem.
P3 recebe a mensagem do marcador primeiro, e é a primeira mensagem do marcador que recebe. Depois de receber a mensagem, ele primeiro fará um instantâneo do estado local, em seguida, marcará o pipeline C13 como próximo e, ao mesmo tempo, começará a enviar mensagens de marcador para todos os seus canais de saída e, finalmente, enviará todos os canais de entrada de todas as entradas canais exceto C13 A mensagem começa a ser gravada.
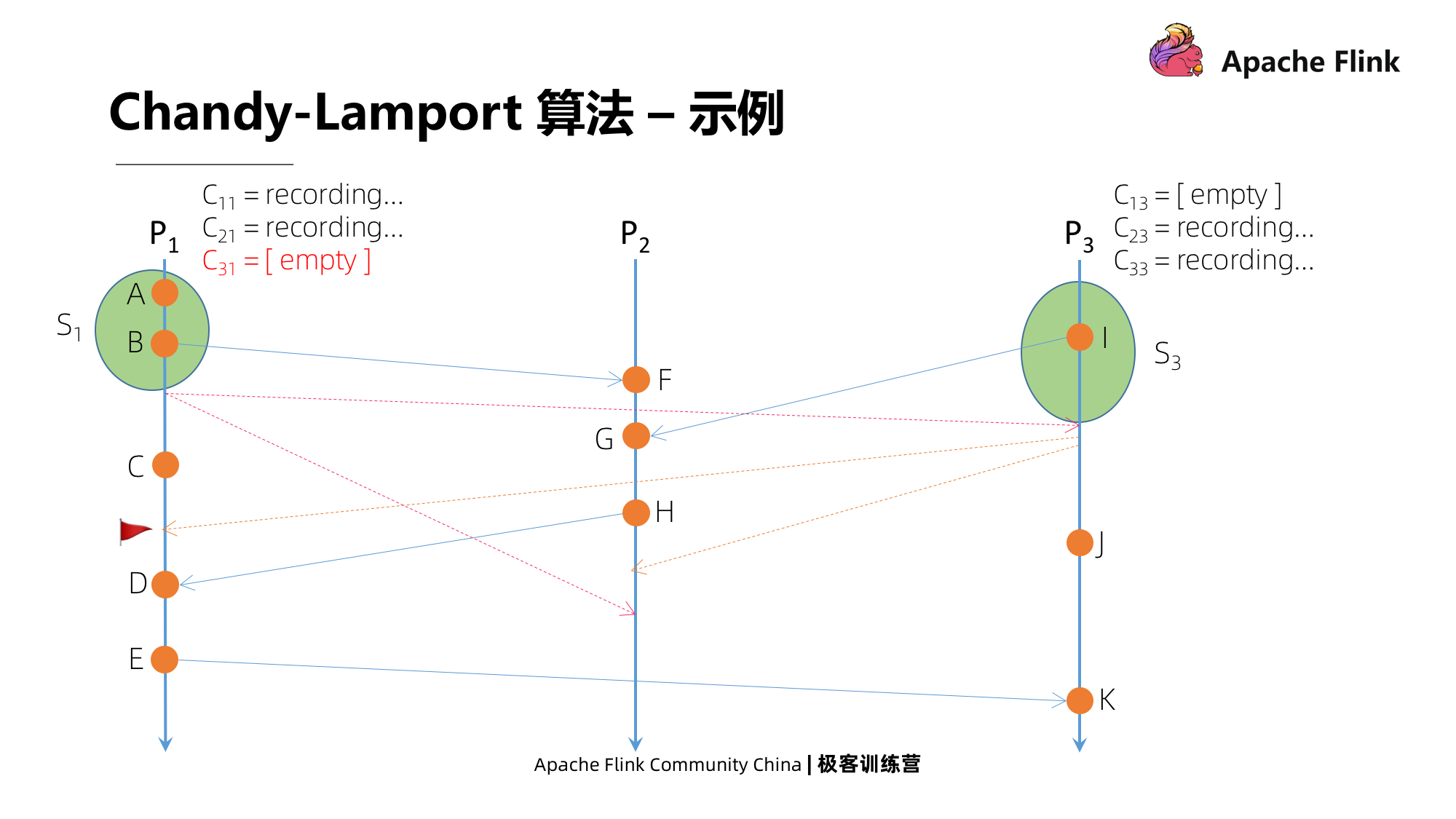
É P1 que recebe as informações do marcador enviadas por P3, mas este não é o primeiro marcador que recebe. Ele fechará imediatamente o pipeline do canal C31 e tomará a mensagem de registro atual como um instantâneo deste canal e, em seguida, receberá de As notícias de P3 não serão atualizadas neste estado de instantâneo.
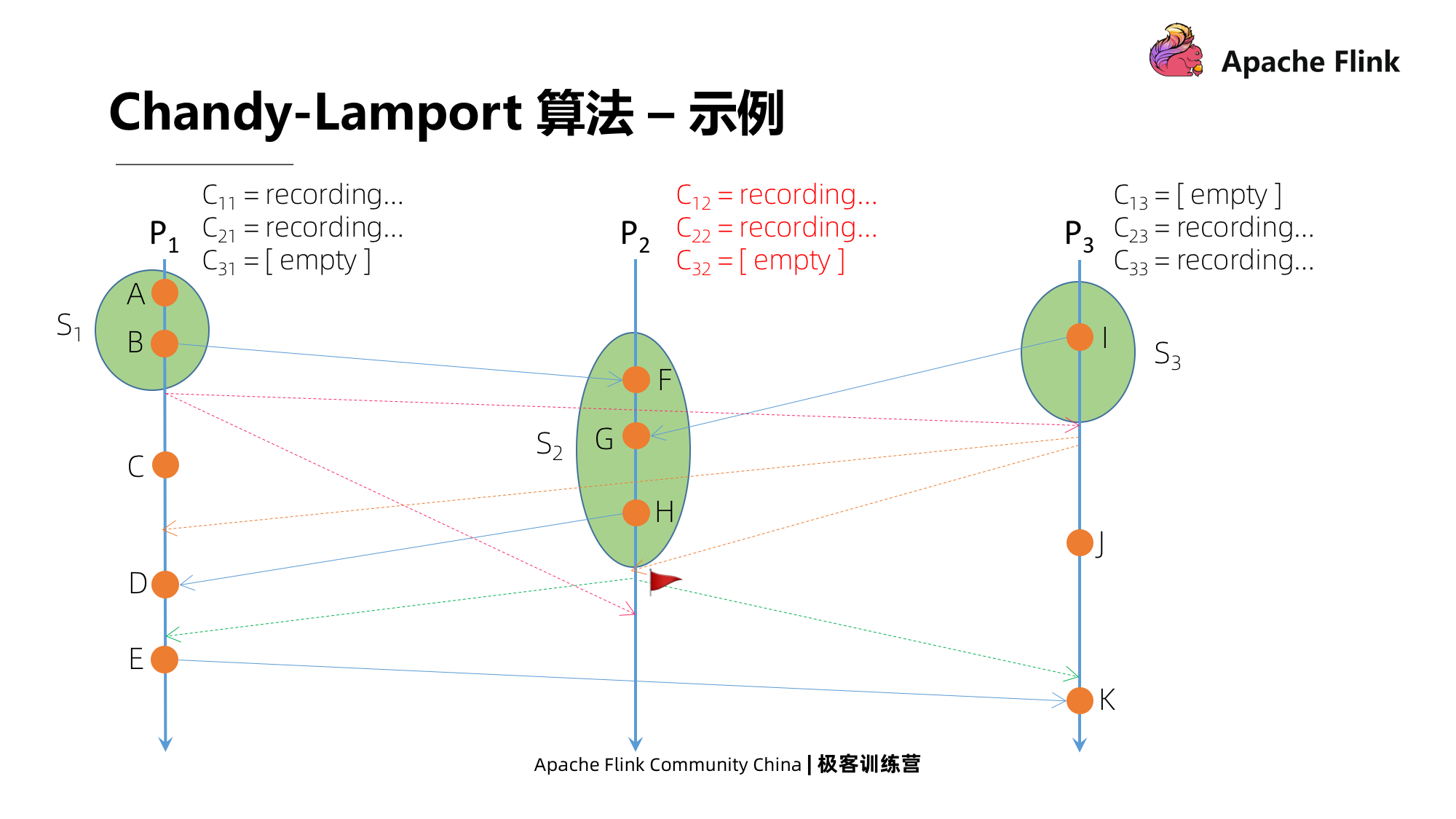
Em seguida, P2 recebe uma mensagem de P3, que é a primeira mensagem de marcador que recebe. Depois de receber a mensagem, ele primeiro tira um instantâneo do estado local, em seguida, marca o pipeline C32 como próximo e, ao mesmo tempo, começa a enviar mensagens de marcador para todos os seus canais de saída e, finalmente, ele tira um instantâneo de todos os canais de entrada exceto C32 A mensagem começa a ser gravada.
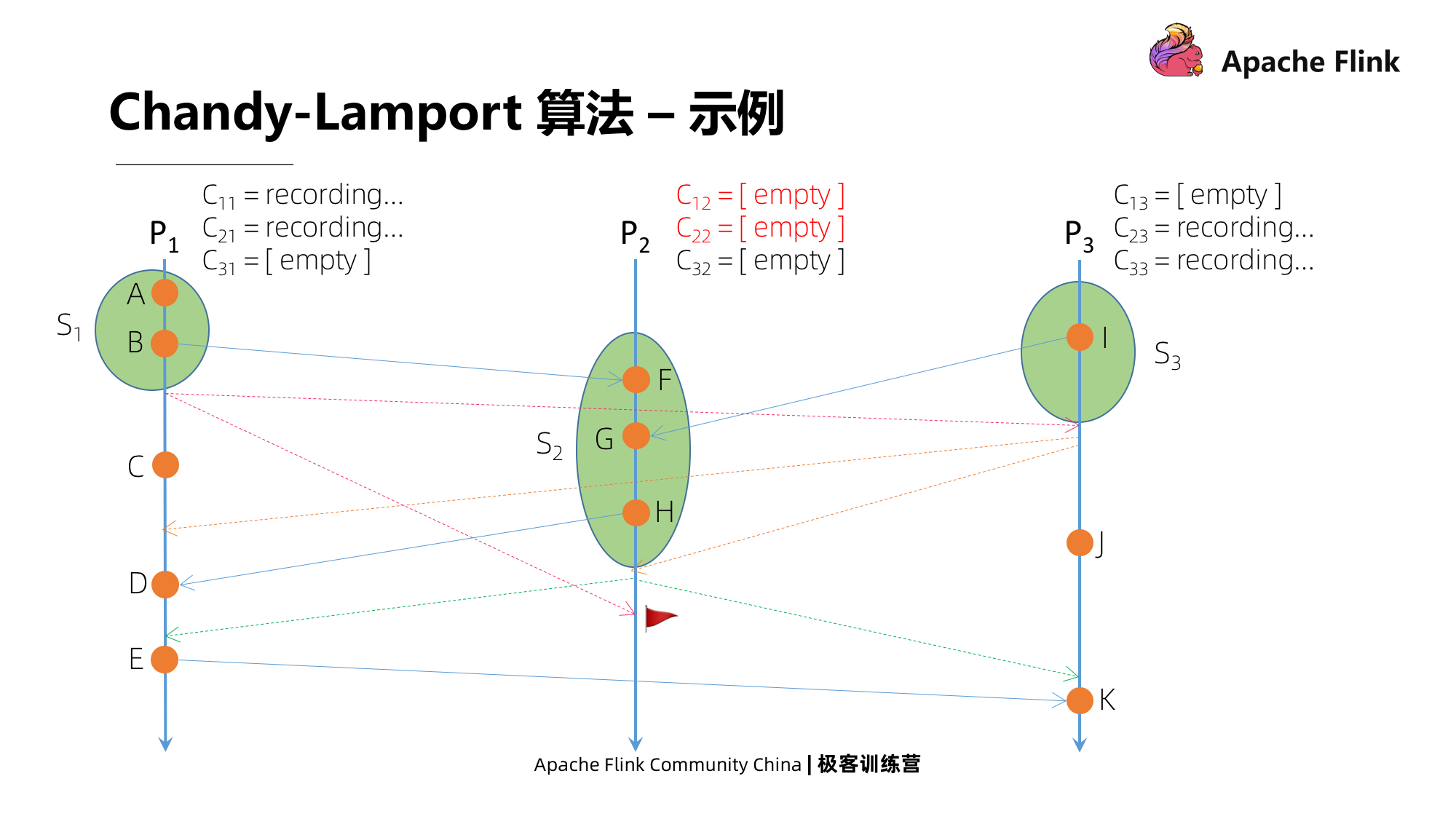
Vejamos P2 recebendo a mensagem de P1. Esta não é a primeira mensagem de marcador recebida por P2, então ele fechará todos os canais de entrada e registrará o status do canal.
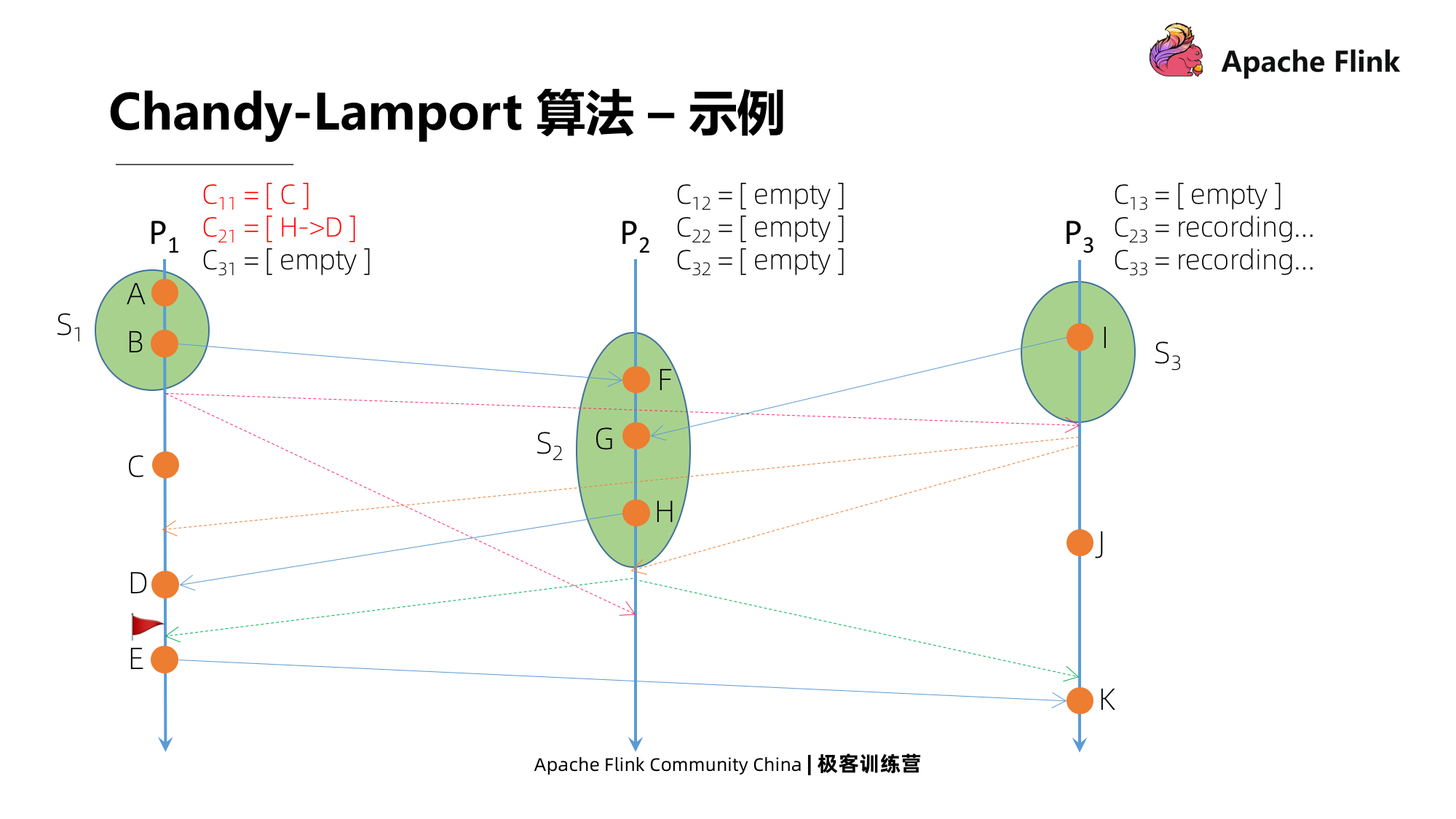
A seguir, vejamos que P1 recebe uma mensagem de P2, não é a primeira mensagem que recebe. Em seguida, ele fechará todos os canais de entrada e usará a mensagem gravada como o status. Então, há dois estados, um é C11, que é uma mensagem enviada para você, e o outro é C21, que é enviado para P1D por H em P2.
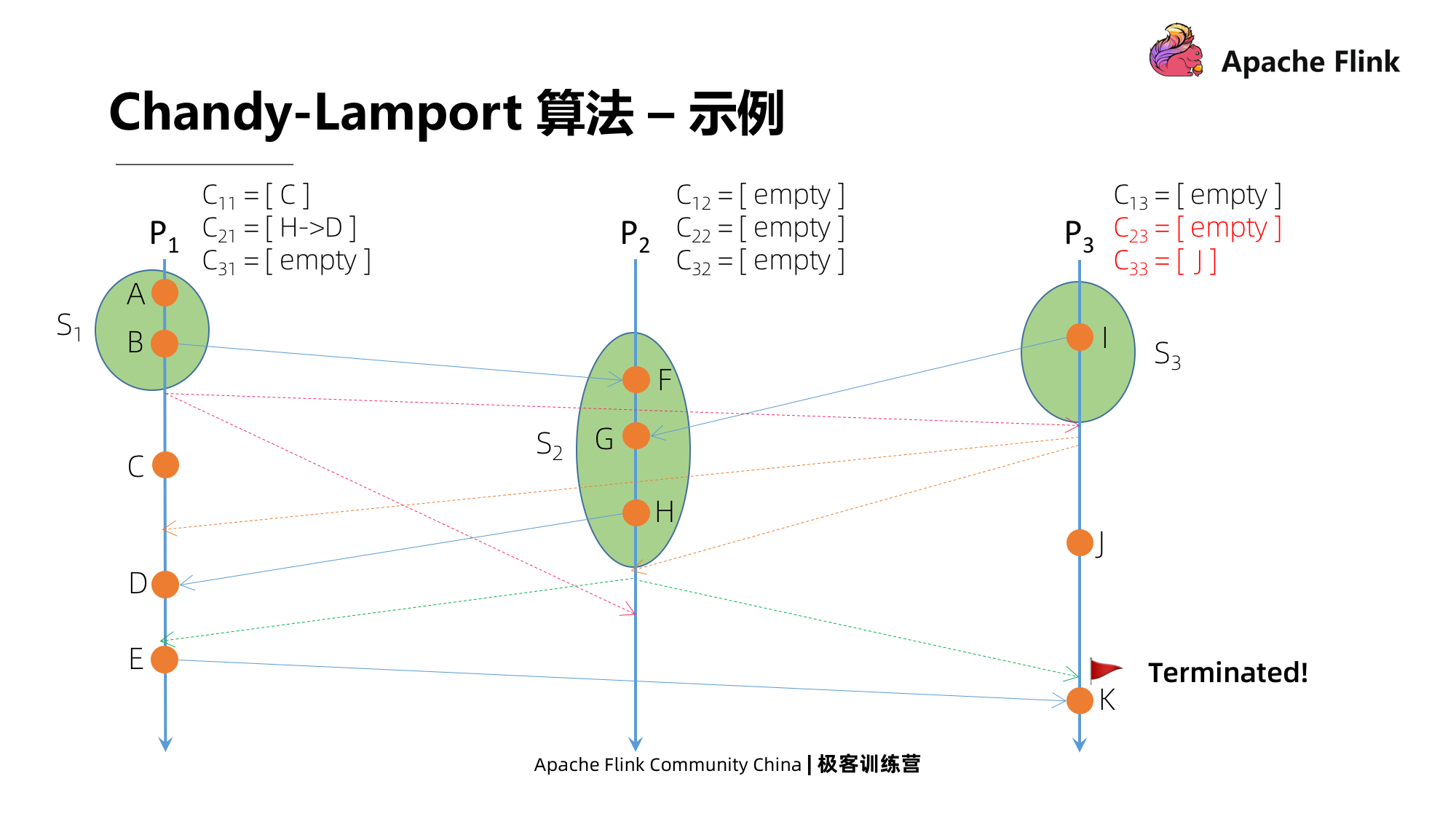
No último momento, P3 recebe uma mensagem de P2, que não é a primeira mensagem que recebe, e a operação é a mesma descrita acima. Durante este período, P3 tem um evento J localmente, e também terá J como seu estado.
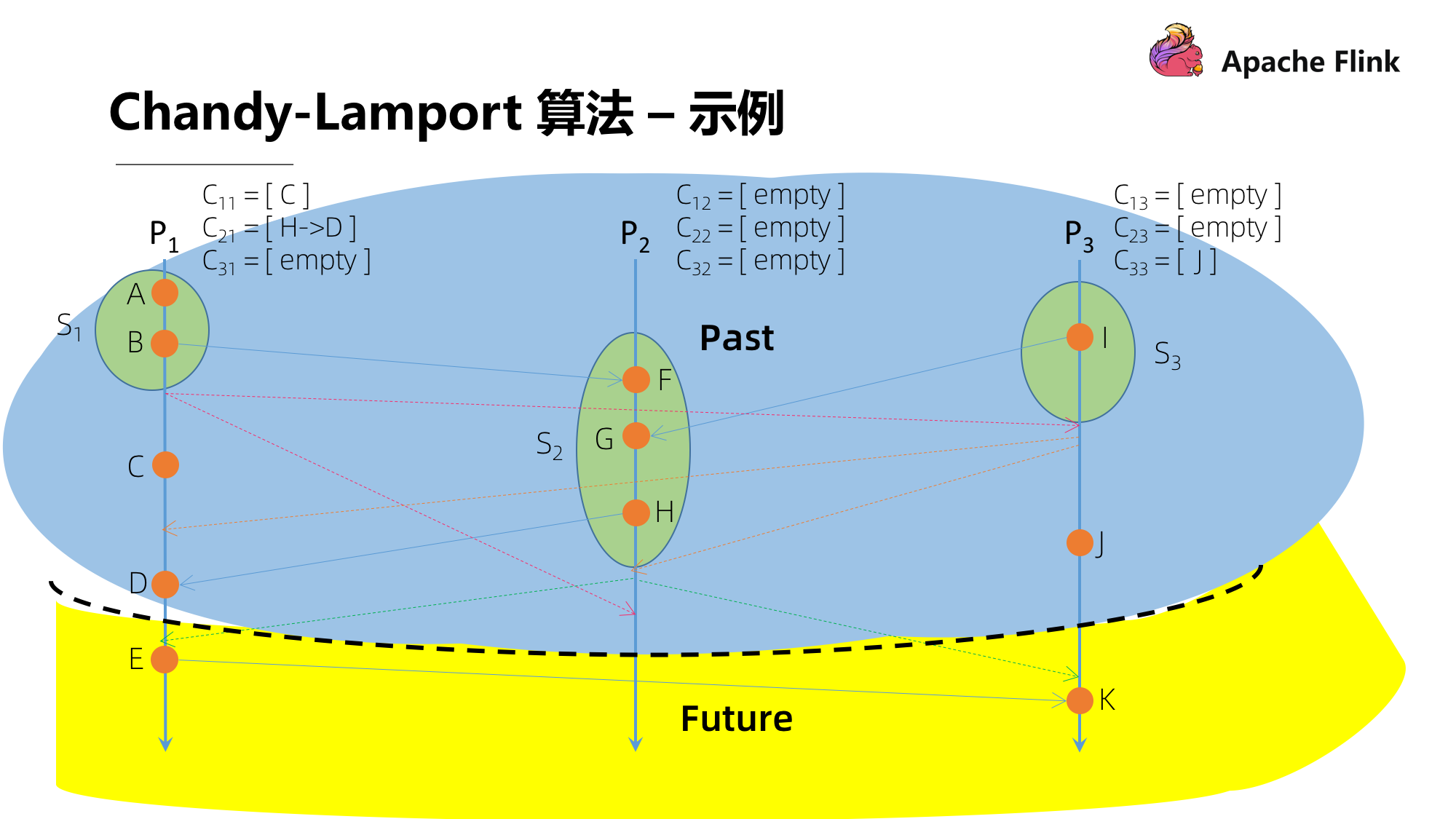
Quando todos os processos registraram o estado local e todos os canais de entrada de cada processo foram fechados, o instantâneo de consistência global acabou, ou seja, o registro do estado global do ponto passado no tempo é concluído.
3.3 A relação entre Chandy-Lamport e Flink
O Flink é um sistema distribuído, portanto, o Flink usará um instantâneo consistente globalmente para formar pontos de verificação para oferecer suporte à recuperação de falhas. As principais diferenças entre o algoritmo de instantâneo globalmente consistente e assíncrono de Flink e o algoritmo Chandy-Lamport são as seguintes:
- Primeiro, Chandy-Lamput oferece suporte a gráficos fortemente conectados, enquanto Flink oferece suporte a gráficos fracamente conectados;
- Em segundo lugar, Flink usa o algoritmo de instantâneo assíncrono de Chandy-Lamput adaptado (sob medida);
- Terceiro, o algoritmo de instantâneo assíncrono do Flink não precisa armazenar o estado do canal em cenários DAG, o que reduz muito o espaço de armazenamento dos instantâneos.
Três, o mecanismo de tolerância a falhas de Flink

Tolerância a falhas significa restaurar o estado anterior ao erro. Existem três tipos de garantias de consistência tolerantes a falhas de computação em fluxo, a saber: Exatamente uma vez, Pelo menos uma vez e No máximo uma vez.
- Exatamente uma vez significa que cada evento terá um impacto no estado apenas uma vez. O "uma vez" aqui não é estrito de ponta a ponta, mas apenas um processamento no Flink, excluindo o processamento de origem e coletor.
- Pelo menos uma vez significa que cada evento afetará o estado pelo menos uma vez, ou seja, existe a possibilidade de processamento repetido.
- No máximo uma vez significa que cada evento afetará o estado no máximo uma vez, ou seja, o estado pode ser perdido quando ocorrer um erro.
Exatamente uma vez de ponta a ponta
Exatamente uma vez significa que o resultado da tarefa está sempre correto, mas é provável que seja produzido várias vezes; portanto, seu requisito é ter uma fonte reproduzível.
End-to-end Exatamente uma vez significa que o resultado do trabalho está correto e será exibido apenas uma vez. Além de uma fonte reproduzível, também requer um coletor transacional e a capacidade de receber resultados de saída idempotentes.
Tolerância a falhas de estado de Flink
Muitos cenários requerem a semântica de Exatamente uma vez, ou seja, para processar e processar apenas uma vez. Como garantir a semântica?
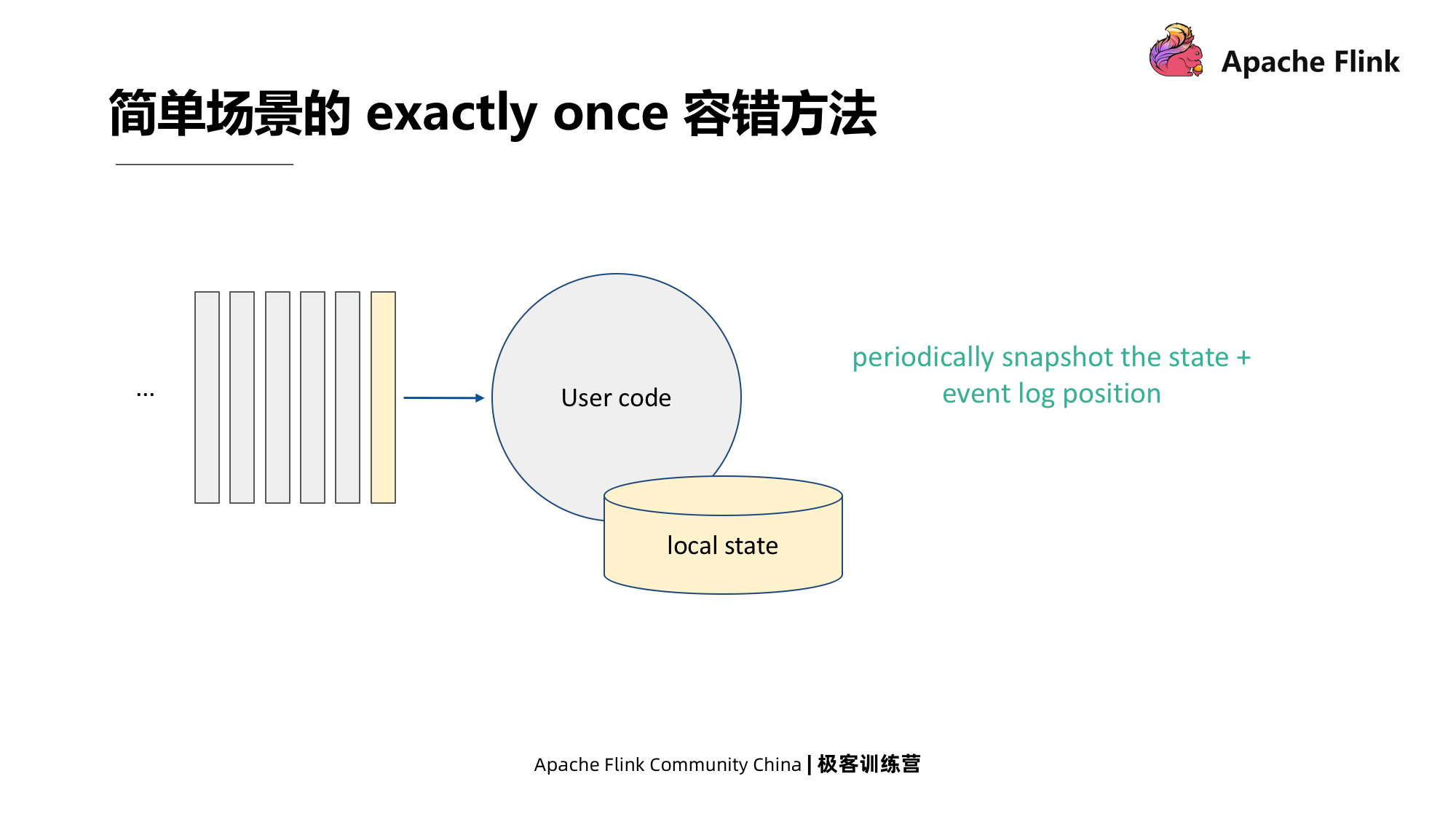
Método tolerante a falhas Exatamente Uma vez para cenários simples
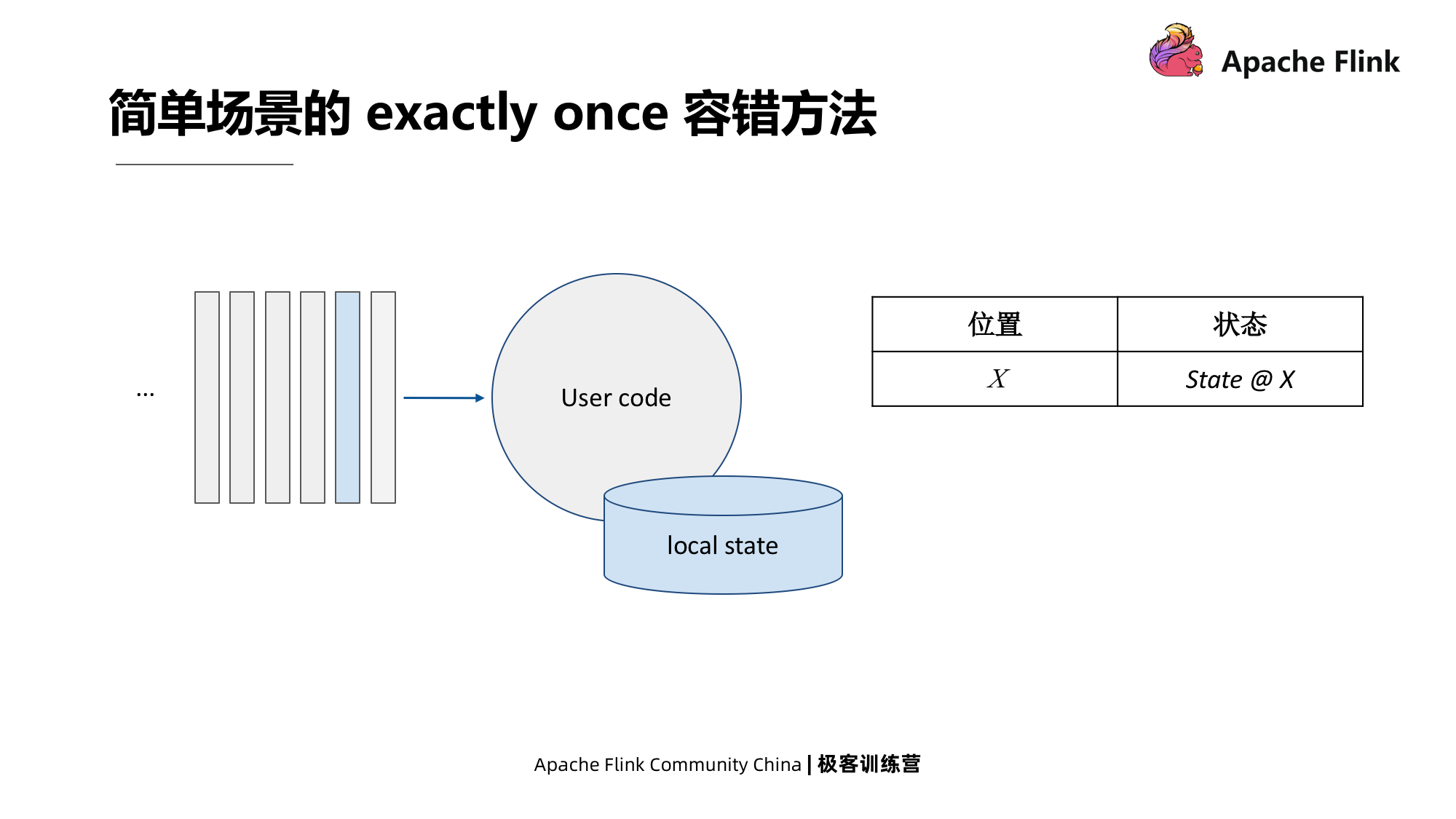
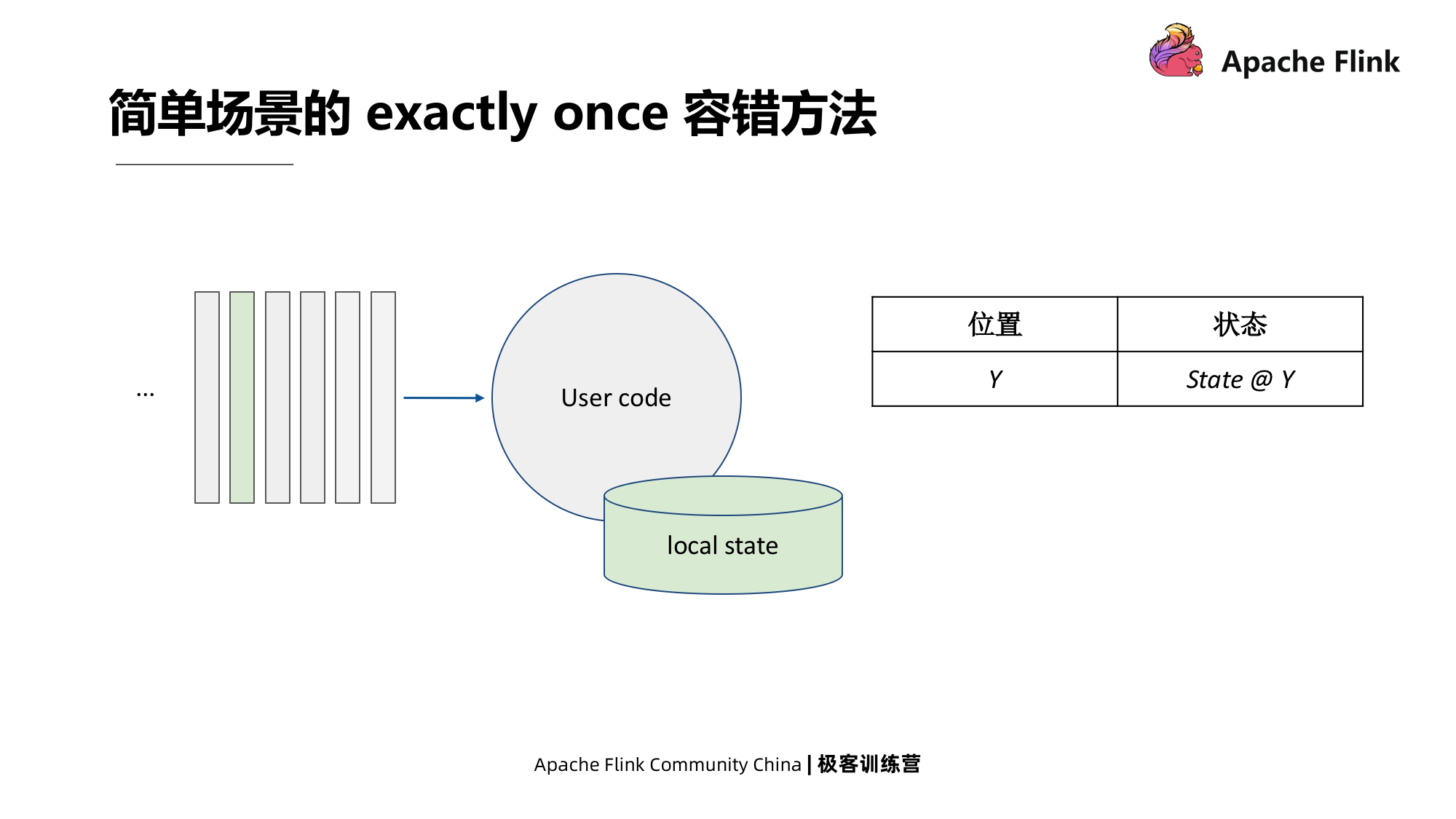
O cenário simples é mostrado na figura abaixo.O método é registrar o estado local e registrar o deslocamento da fonte, ou seja, a localização do registro de eventos.
Tolerância a falhas de estado em cenários distribuídos
Se for um cenário distribuído, precisamos gerar um instantâneo globalmente consistente de vários operadores com estados locais, sem interromper a operação. A topologia de trabalho da cena distribuída de Flink é especial. É um gráfico direcionado acíclico e fracamente conectado. Pode usar um Chandy-Lamport sob medida, ou seja, registra apenas todos os deslocamentos de entrada e o estado de cada operador, e depende de a fonte rebobinável (pode ser A fonte de retrocesso pode ser lida um pouco mais cedo por meio do deslocamento), portanto, não há necessidade de armazenar o estado do canal, o que pode economizar muito espaço de armazenamento na presença da lógica de agregação.
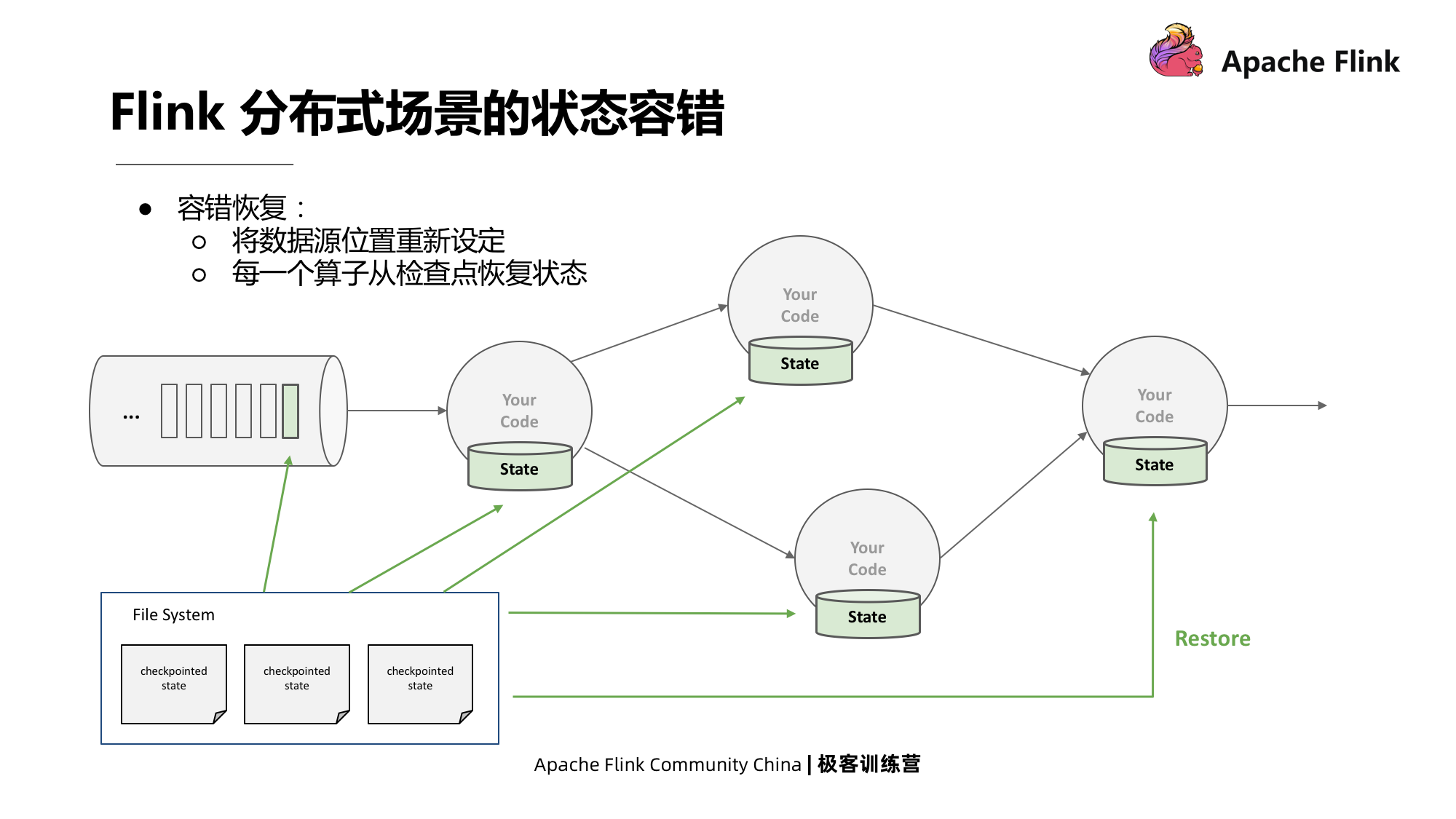
Por fim, restaurar é redefinir a localização da fonte de dados e, em seguida, cada operador restaura o estado do ponto de verificação.
3. Método de instantâneo distribuído de Flink
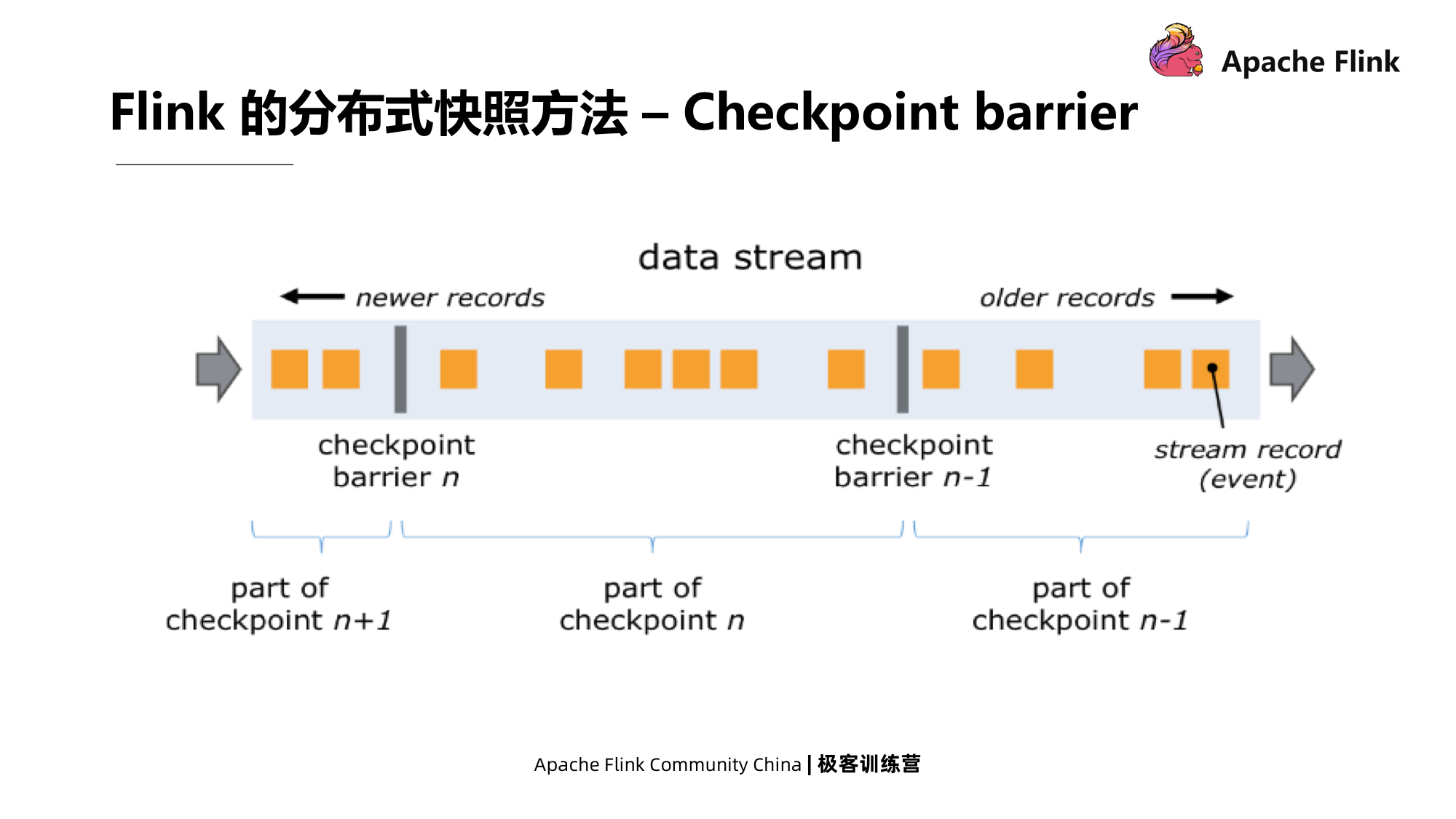
Primeiro, insira uma barreira de Checkpoint no fluxo de dados de origem, que é a mensagem do marcador no algoritmo Chandy-Lamport mencionado acima. Diferentes barreiras de Checkpoint irão naturalmente dividir o fluxo em vários segmentos, e cada segmento contém dados de Checkpoint. ;
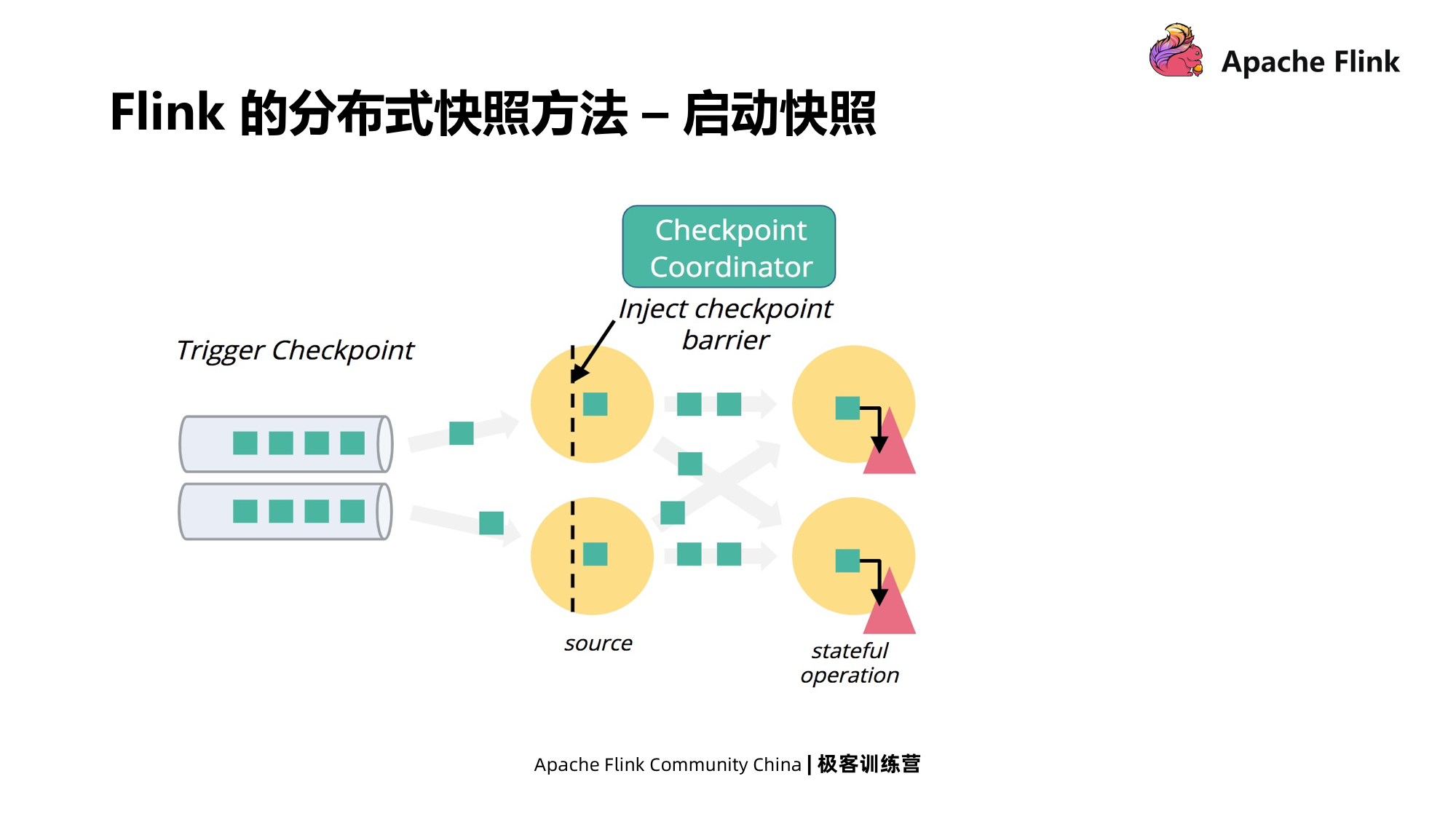
Há um coordenador global em Flink. Ao contrário de Chandy-Lamport, que pode iniciar um instantâneo de qualquer processo, este coordenador centralizado injetará a barreira do Checkpoint em cada fonte e, em seguida, iniciará o instantâneo. Quando cada nó recebe a barreira, por não armazenar o estado do canal no Flink, ele só precisa armazenar o estado local.
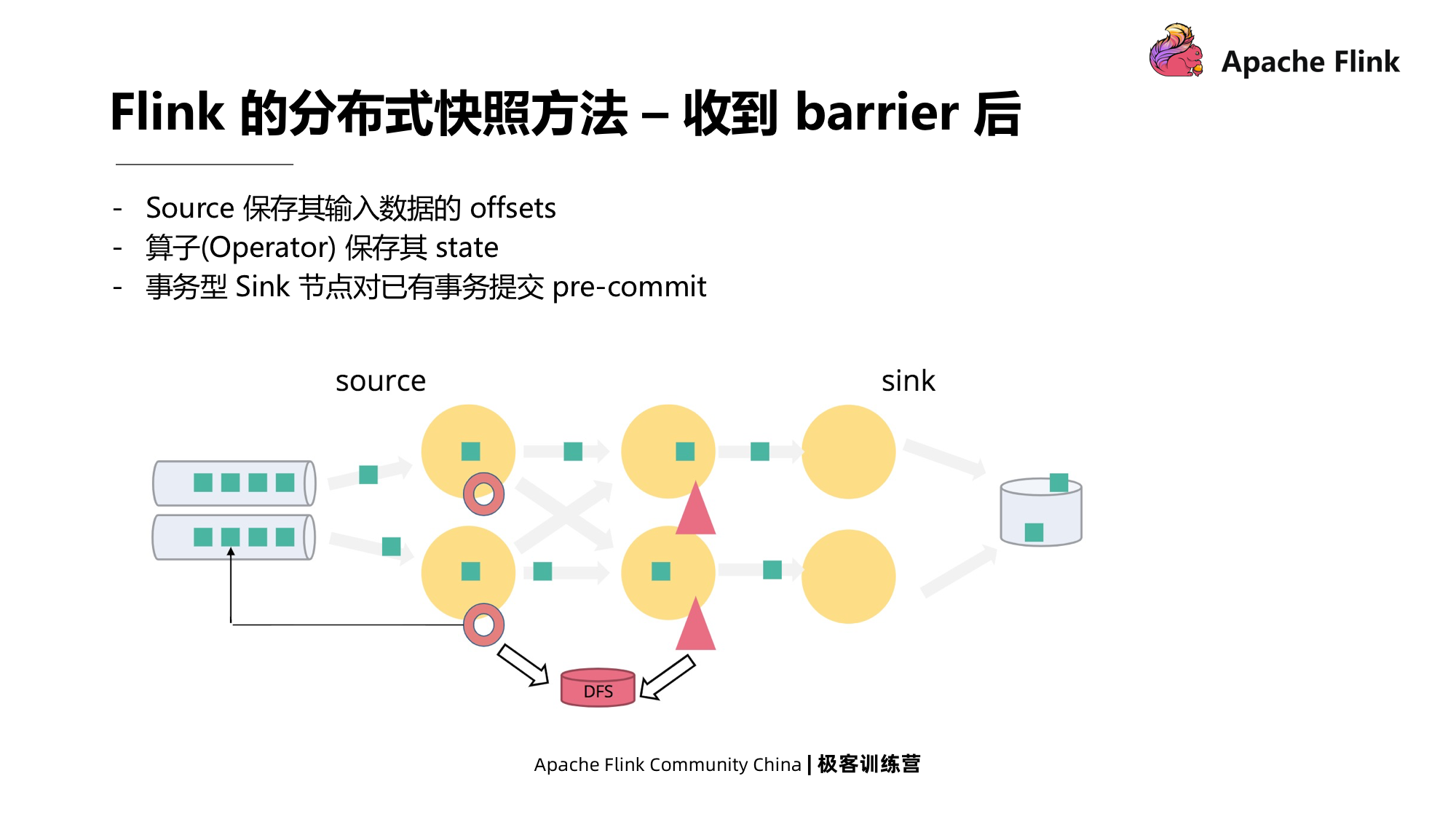
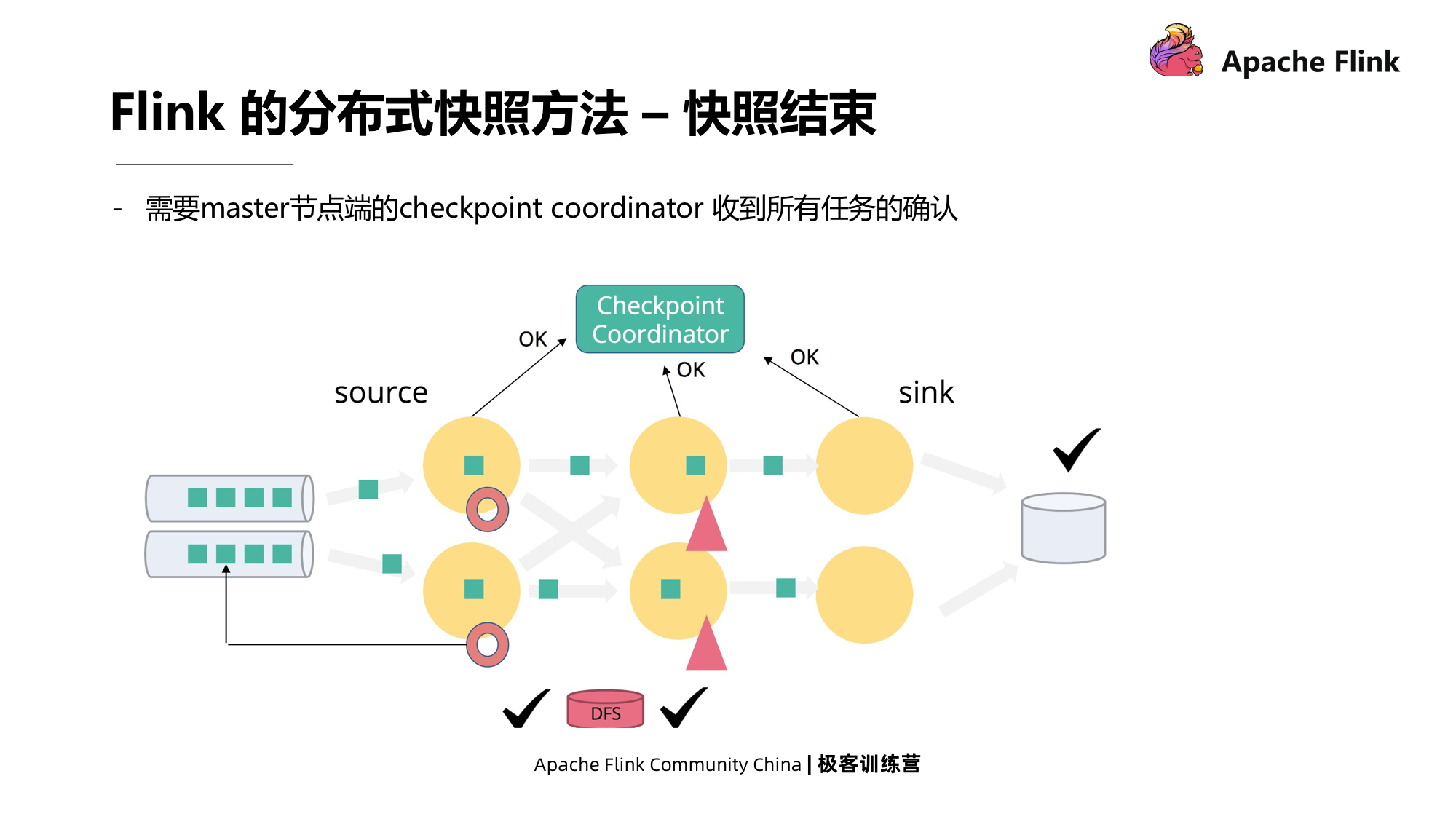
Após a conclusão do Checkpoint, cada simultaneidade de cada operador enviará uma mensagem de confirmação para o Coordenador.Quando as mensagens de confirmação de todas as tarefas forem recebidas pelo Coordenador do Checkpoint, o instantâneo acabou.
4. Demonstração do processo
Conforme mostrado na figura abaixo, supondo que o Checkpoint N seja injetado na origem, a origem registrará primeiro o deslocamento da partição que está processando.
Com o passar do tempo, ele enviará a barreira do Checkpoint para dois downstreams simultâneos. Quando a barreira atingir duas simultaneidades, as duas simultâneas registrarão seu estado local no Checkpoint, respectivamente:
Finalmente, a barreira atinge a subtarefa final e o instantâneo está completo.
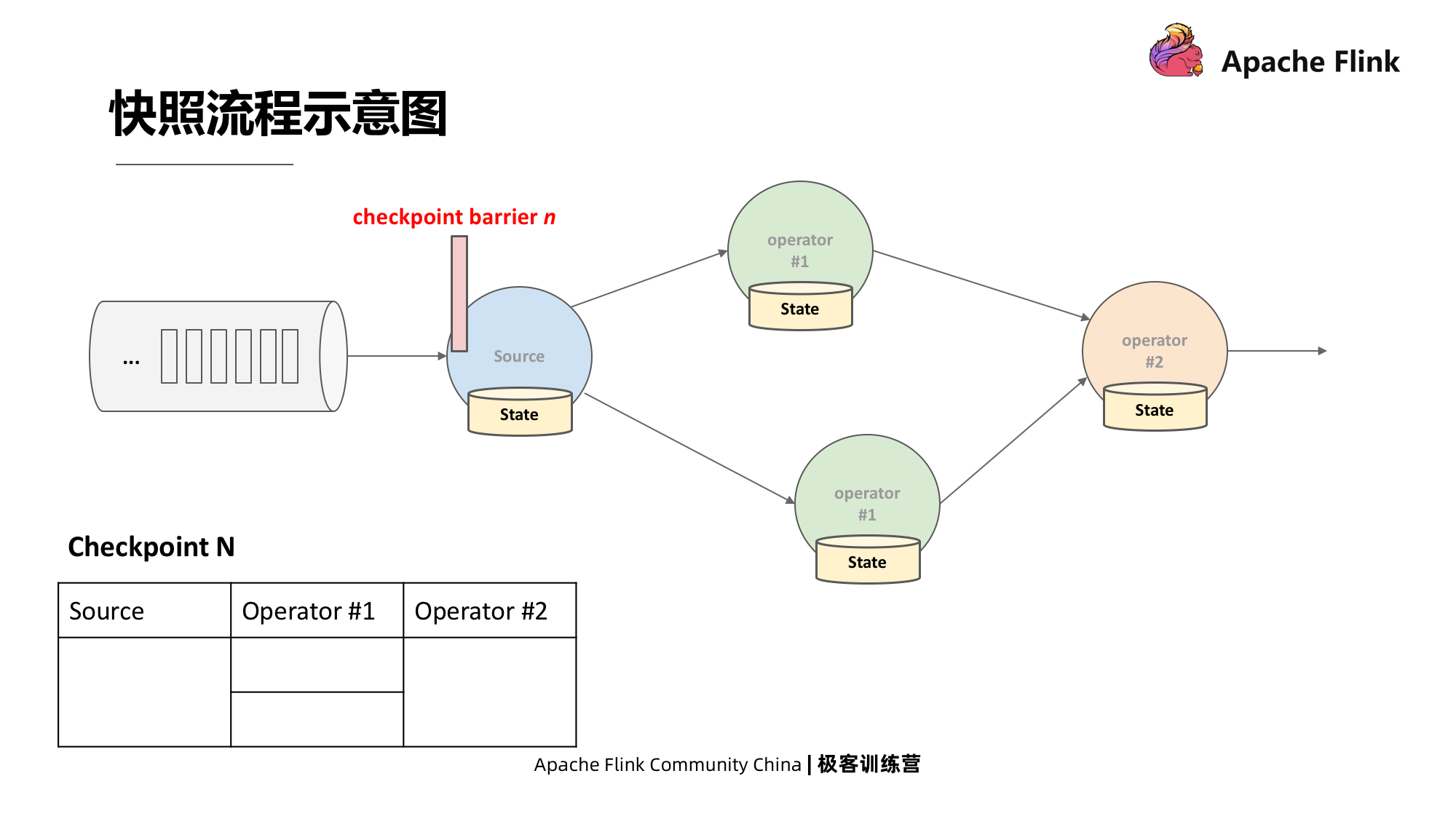
Esta é uma demonstração de cenário relativamente simples. Cada operador tem apenas um único fluxo de entrada. Vejamos o cenário mais complicado na figura abaixo, onde o operador tem vários fluxos de entrada.
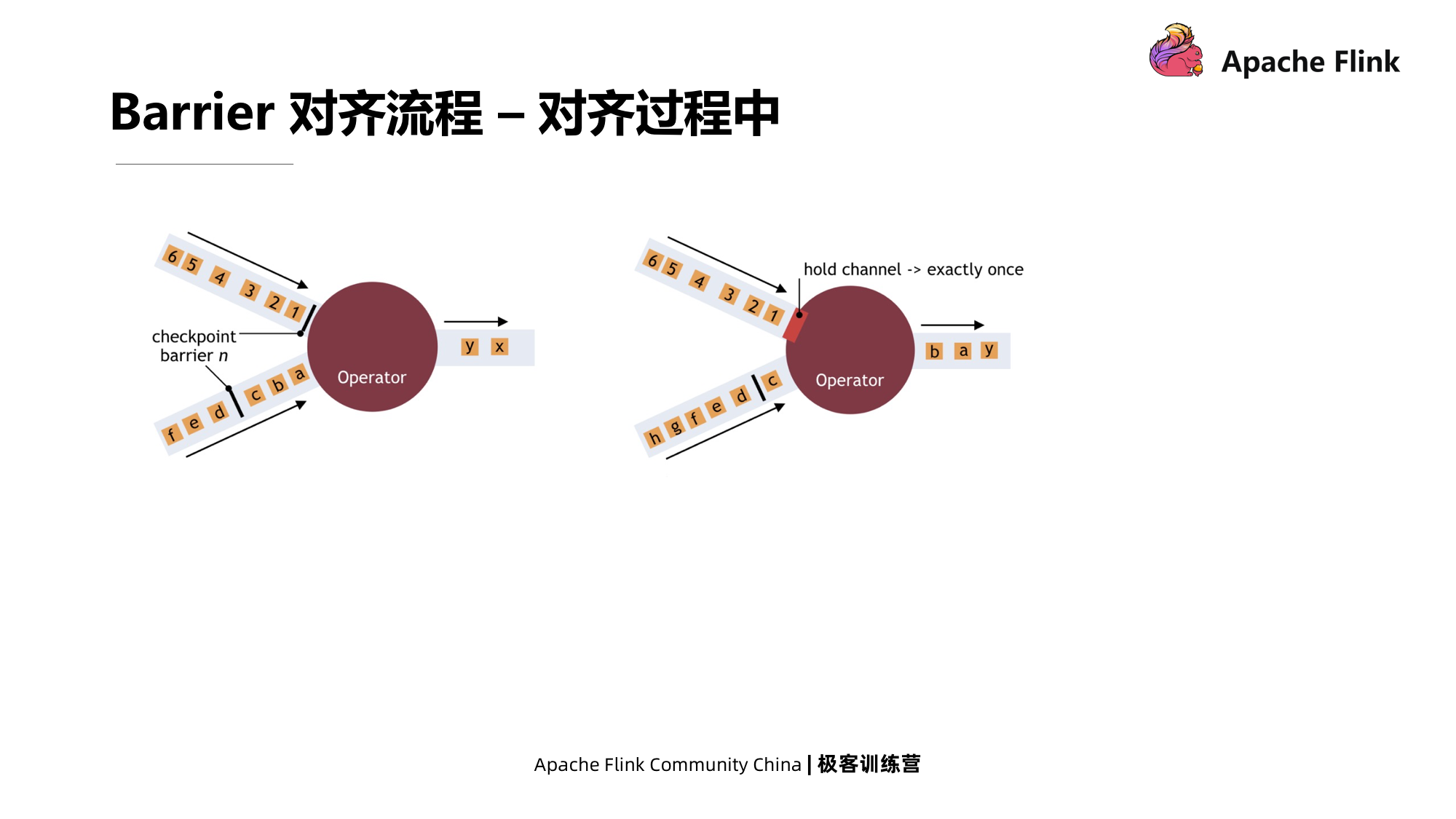
Quando o operador tem várias entradas, as barreiras precisam ser alinhadas. Como alinhar a barreira? Conforme mostrado na figura abaixo, no estado original à esquerda, quando uma das barreiras chega, algumas barreiras do comando da outra barreira não chegaram ao duto. Neste momento, o fluxo que chegou primeiro tem a garantia de ser Exatamente uma vez. Bloqueie diretamente e aguarde o processamento de dados de outro fluxo. Quando outro stream chegar, o stream anterior será desbloqueado e a barreira será enviada para a operadora ao mesmo tempo.
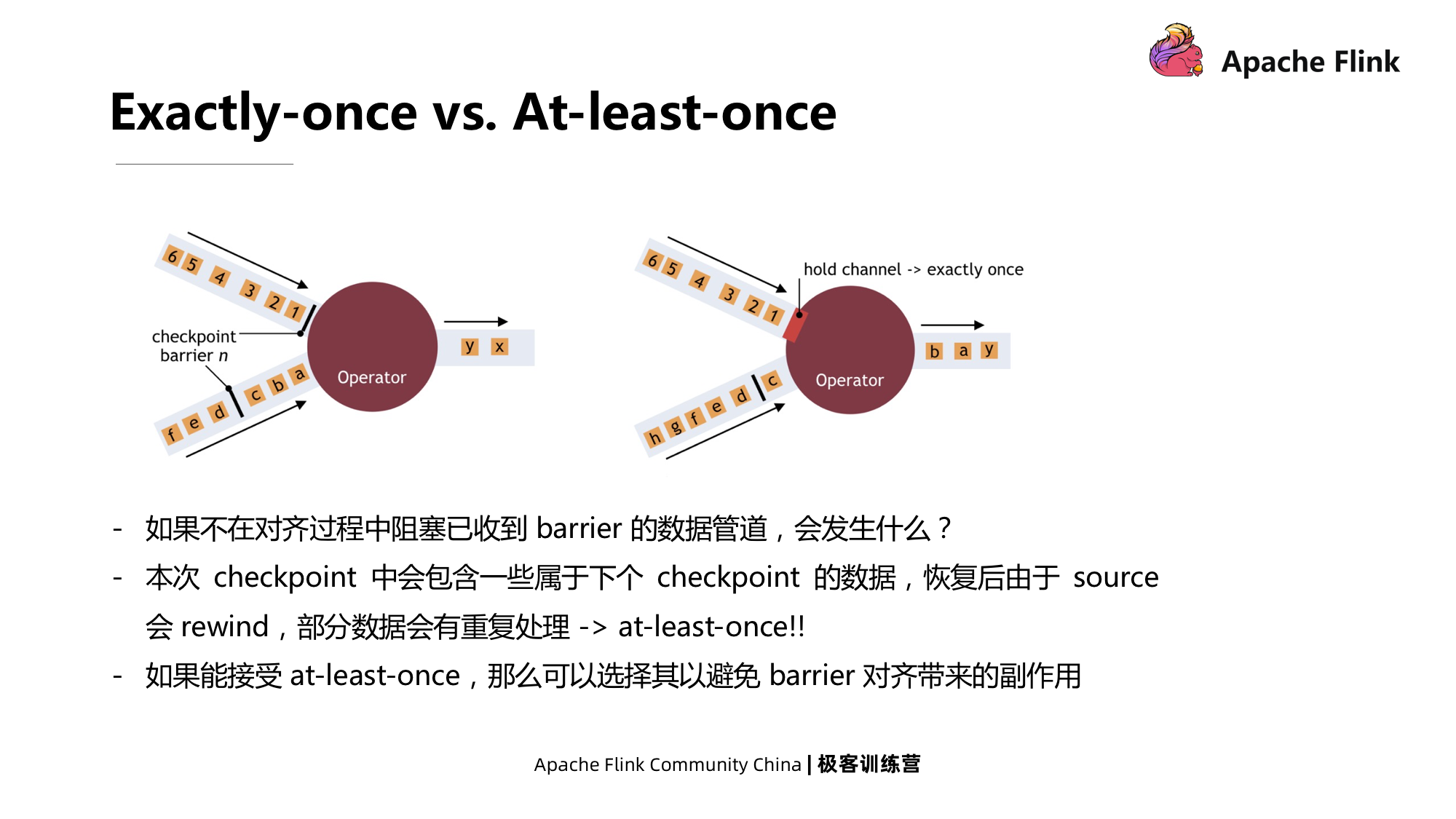
Nesse processo, o efeito de bloquear um dos fluxos é fazer com que ele produza contrapressão. O alinhamento da barreira causará contrapressão e suspenderá o processamento de dados do operador.
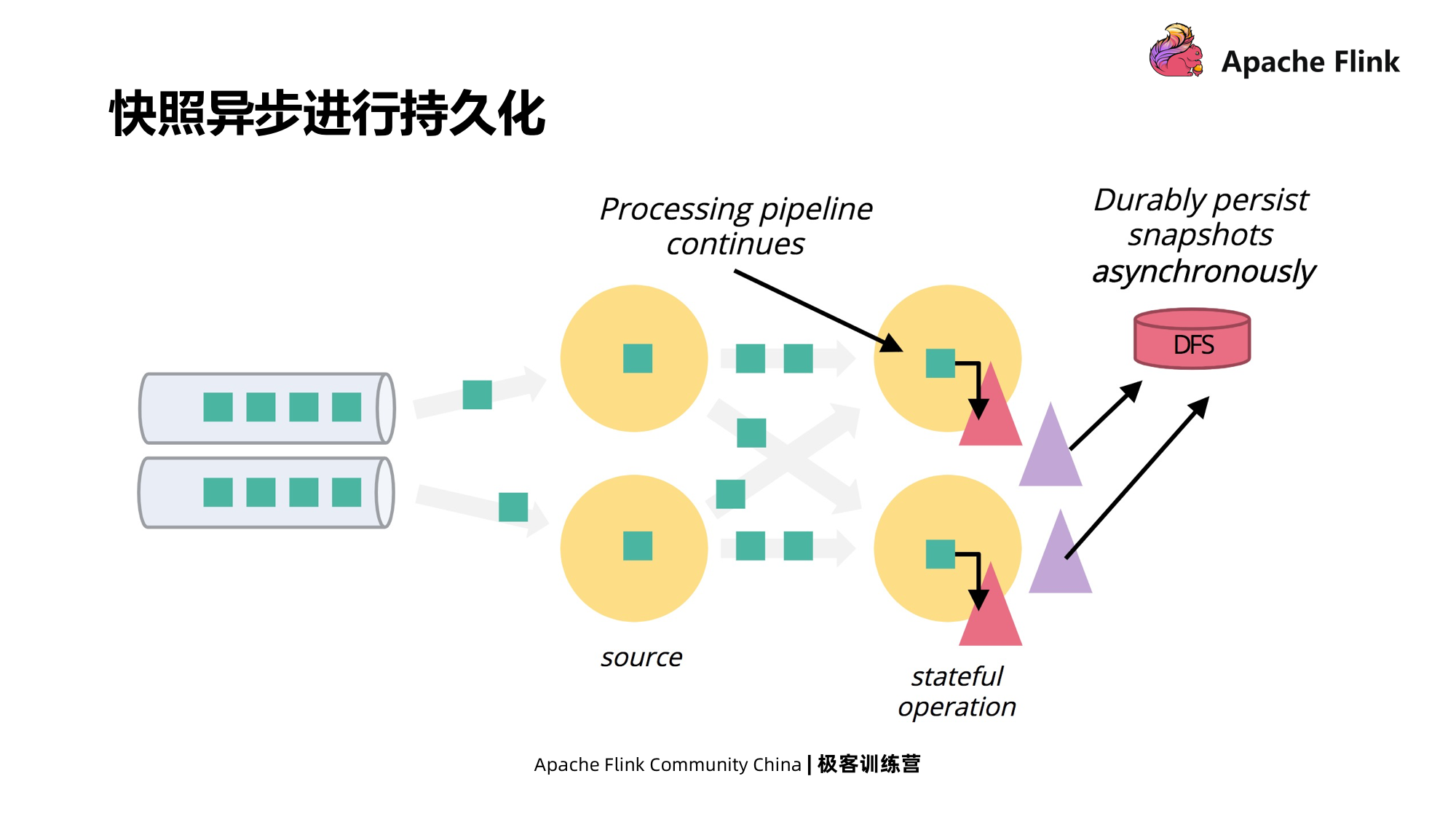
Se o pipeline de dados que recebeu a barreira não estiver bloqueado durante o processo de alinhamento e os dados continuarem a fluir, os dados pertencentes ao próximo Checkpoint serão incluídos no Checkpoint atual. Quando ocorrer uma falha, a fonte será retrocedida , e parte dos dados será retrocedida. Haverá um processamento repetido, que é pelo menos uma vez. Se você pode receber pelo menos uma vez, você pode escolher outros efeitos colaterais que podem evitar o alinhamento da barreira. Além disso, os instantâneos assíncronos também podem ser usados para minimizar paralisações de tarefas e oferecer suporte a vários pontos de verificação ao mesmo tempo.
5. Gatilho instantâneo
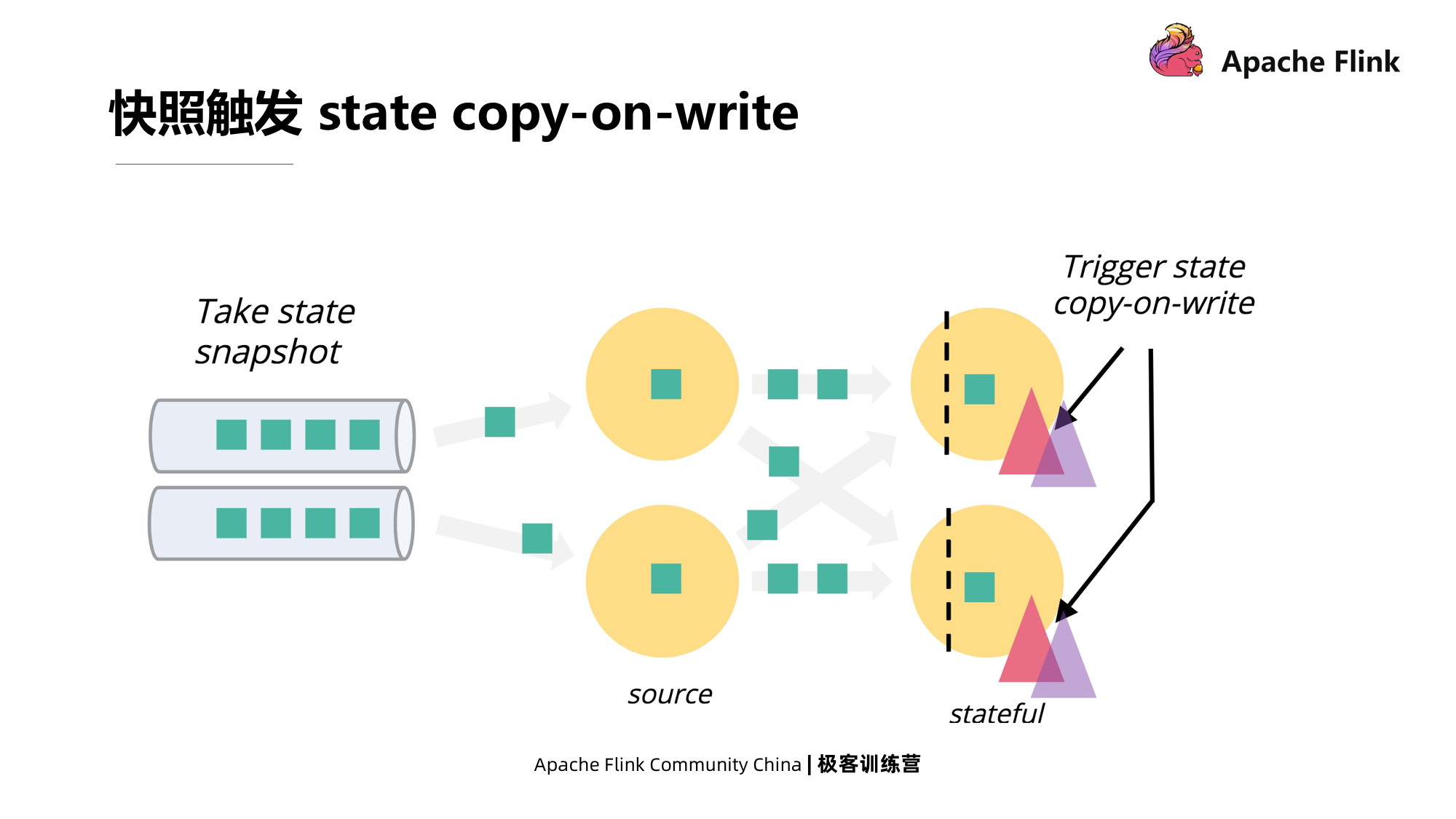
O upload síncrono de instantâneos locais para o sistema requer um mecanismo de cópia na gravação de estado.
Se o processamento de dados for restaurado após um instantâneo das informações de metadados, como garantir que a lógica do aplicativo restaurado não modifique os dados que estão sendo carregados durante o processo de upload de dados? Na verdade, o processamento de back-ends de armazenamento em estados diferentes é diferente. O back-end de heap acionará a cópia na gravação dos dados. Para o back-end do RocksDB, o recurso LSM pode garantir que os dados que foram capturados não sejam modificados.
Em quarto lugar, a gestão do estado de Flink
1. Gerenciamento de status Flink
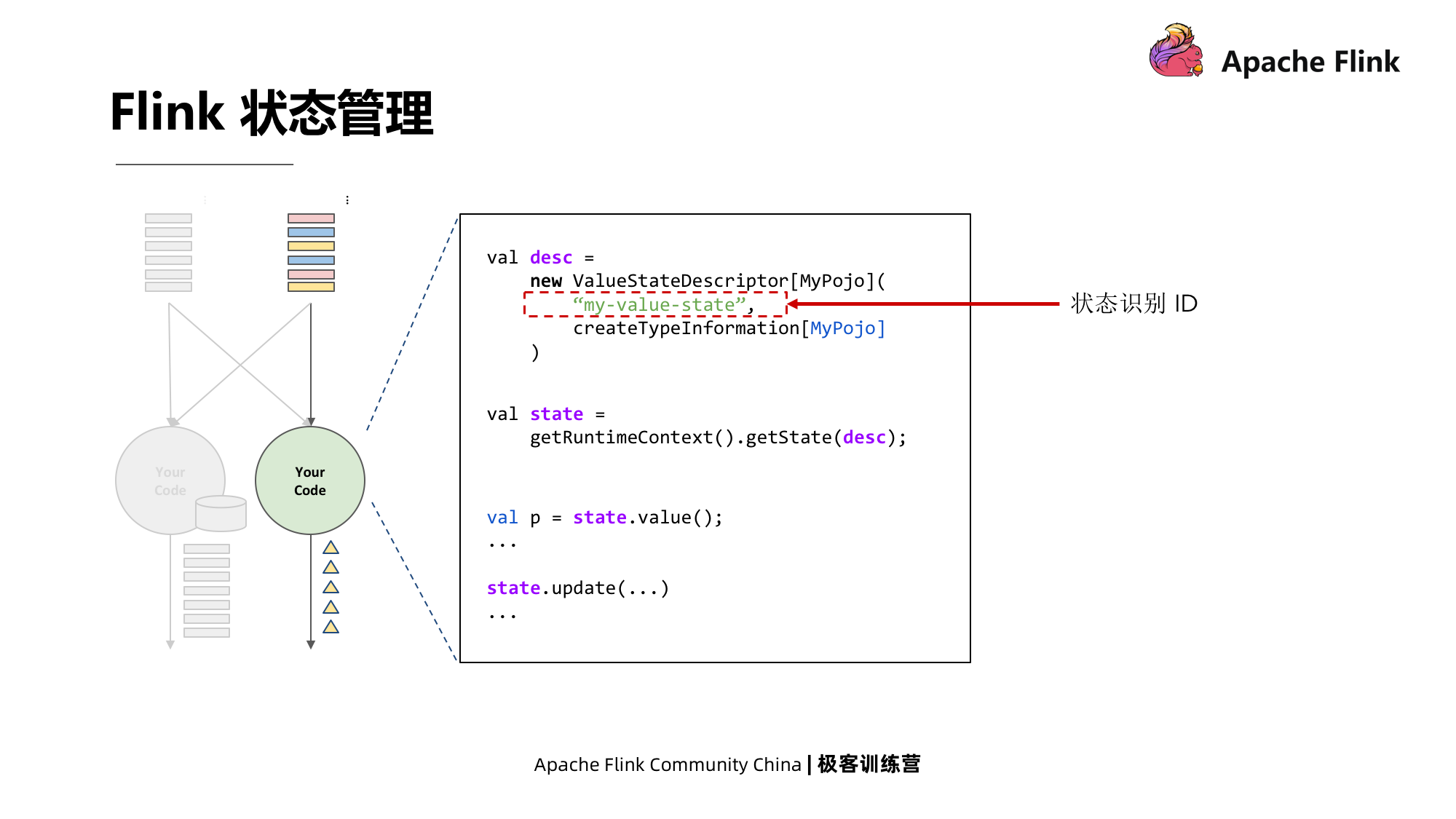
Primeiro, você precisa definir um estado. No exemplo abaixo, defina um estado de valor primeiro.
Ao definir o status, as seguintes informações devem ser fornecidas:
- ID de identificação de status
- Tipo de dados de status
- Status local status de registro de back-end
- Status local de leitura e gravação de back-end
2. Back-end de status do link
Também chamado de back-end de estado, há dois back-ends de estado do Flink;
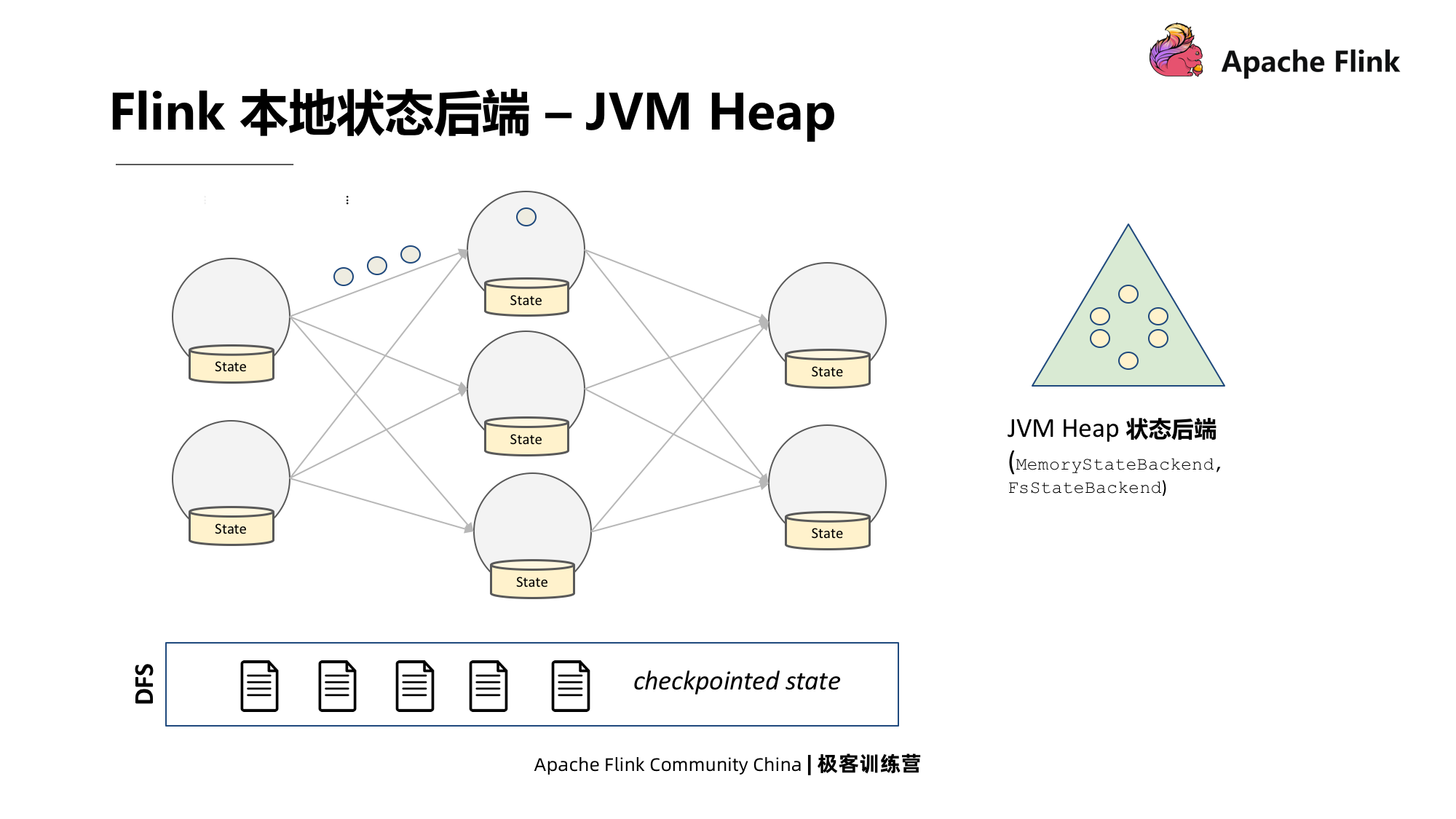
- O primeiro tipo, JVM Heap, os dados existem na forma de objetos Java, e a leitura e a gravação também são feitas na forma de objetos, então a velocidade é muito rápida. Mas também há duas desvantagens: a primeira desvantagem, o espaço necessário para o armazenamento do objeto é muitas vezes o tamanho dos dados serializados e compactados no disco, por isso ocupa muito espaço de memória; a segunda desvantagem, embora seja lendo e gravando Não há necessidade de fazer a serialização, mas ele precisa ser serializado ao formar um instantâneo, portanto, seu processo de instantâneo assíncrono será mais lento.
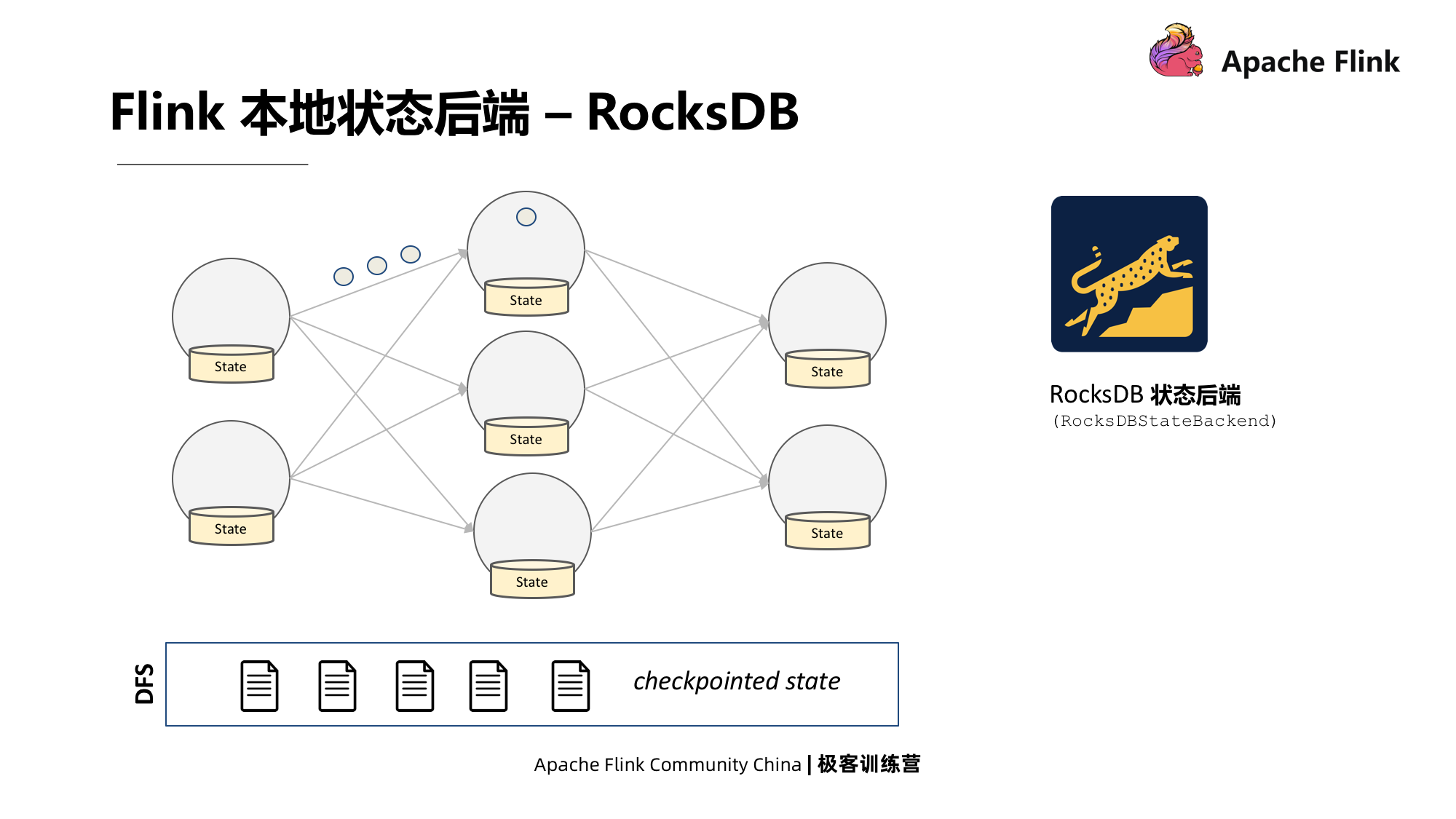
- O segundo tipo é RocksDB. Esse tipo precisa ser serializado durante a leitura e gravação, de modo que sua velocidade de leitura e gravação seja relativamente lenta. Mas tem uma vantagem: a estrutura de dados baseada em LSM formará um arquivo sst após o instantâneo. Seu processo de ponto de verificação assíncrono é o processo de cópia de arquivo, e o consumo de CPU será relativamente baixo.