Um, arquitetura de alta disponibilidade ActiveMQ
A arquitetura de alta disponibilidade do ActiveMQ é baseada no modelo Master / Slave. ActiveMQ fornece um total de quatro esquemas de configuração para configurar HA. Entre eles, Shared Nothing Master / Slave não é mais usado após a versão 5.8, e a versão ActiveMQ 5.9 apresenta o esquema Replicated LevelDB Store HA baseado no Zookeeper .
Dicas do site oficial:
(Na verdade, a recomendação oficial é usar o banco de dados KahaDB embutido no activeMQ.)
Em segundo lugar, a explicação da configuração da arquitetura Mestre / Escravo
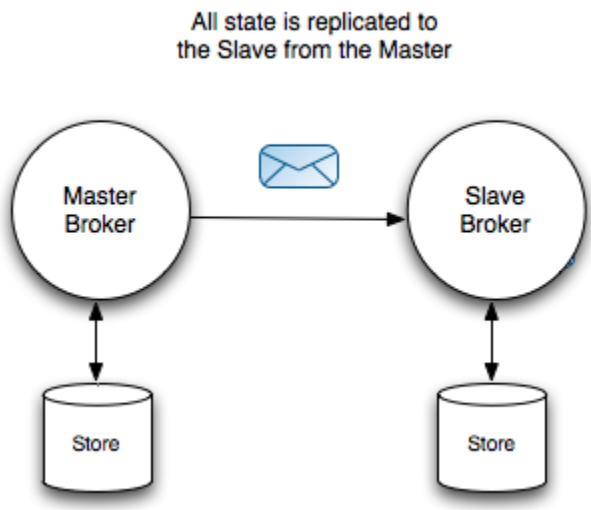
①Shared Nothing Master / Slave
Os maiores recursos dessa arquitetura são:
1) Master e Slave armazenam mensagens persistentes separadamente e não compartilham dados.
2) Quando o Master recebe uma mensagem persistente, ele precisa sincronizar (sincronizar) com o Slave antes de enviar uma confirmação de ACK ao Produtor.
3) Apenas o Mestre é responsável pela solicitação do cliente, e o escravo não recebe a solicitação do cliente. O Slave está conectado ao Master e é responsável por fazer backup das mensagens.
4) Se o Master falhar, o Slave tem duas maneiras de lidar com isso: ❶ Torne-se o Mestre sozinho; ❷ Fechar (interromper o serviço) --- Depende da configuração específica.
5) O fenômeno "Split Brain" pode ocorrer entre Master e Slave. Por exemplo, o próprio Mestre está normal, mas a rede entre o Mestre e o Escravo falha. A falha de rede faz com que o Escravo pense que o Mestre está fora do ar porque se tornará o próprio Mestre (de acordo com a configuração: shutdownOnMasterFailure ). Neste ponto, para o Cliente, haverá dois Mestres.
6) O Slave só pode sincronizar mensagens depois de conectado ao Master. Antes que o Slave seja conectado ao Master, a mensagem enviada pelo Produtor ao Master não será sincronizada com o Slave. Isso pode ser configurado ( waitForSlave ). Somente quando o Slave também é iniciado, o Master começa a inicializar o TransportConnector aceitar o pedido do cliente (pedido do produtor)
7) Se um dos Master ou Slave cair, as mensagens não sincronizadas entre eles não podem ser sincronizadas automaticamente, neste momento, as mensagens não sincronizadas só podem ser restauradas manualmente. Ou seja: "ActiveMQ não fornece nenhum meio eficaz para permitir que o mestre e o escravo sincronizem automaticamente os dados durante o período de recuperação de falha"
8) Para mensagens não persistentes, elas não serão sincronizadas com o Slave. Portanto, se o Master cair, as mensagens não persistentes serão perdidas.
Um pouco de entendimento sobre a configuração de alta disponibilidade do ShareNothing:
❶A partir da etapa 2) acima, pode ser visto que após o produtor enviar uma mensagem ao mestre, o mestre precisa sincronizar a mensagem ao escravo antes de retornar um ACK de confirmação ao produtor. Portanto, há um certo atraso na resposta ao Produtor.
Se para garantir uma resposta rápida, ou seja, após o Produtor enviar uma mensagem ao Mestre, o Mestre responde imediatamente ao Produtor após receber a mensagem, e então sincroniza a mensagem para o Escravo em background. Isso causará problemas de inconsistência de dados.
Porque, se o mestre receber a mensagem e responder imediatamente ao produtor, o mestre irá descer antes que possa sincronizar com o escravo no futuro. Se a mensagem ainda estiver na memória do mestre, a mensagem será perdida após o Mestre desce. Se o mestre receber uma mensagem do produtor, gravá-la no disco primeiro e, em seguida, retornar um ACK ao produtor e, em seguida, sincronizar com o escravo em segundo plano, o mestre precisa marcar se cada mensagem foi sincronizada com sucesso para o Slave, se a mensagem ainda não foi sincronizada Slave, após o Master reiniciar e se recuperar, o Slave precisa ser sincronizado imediatamente. Somente quando o Slave sincroniza com sucesso todas as mensagens no Master, ele pode entrar online. Isso também não pode atingir failover automático.
Em relação a uma boa solução de alta confiabilidade: consulte o mecanismo QJM no Hadoop HA . O núcleo é: 1) O cluster é usado, que pode tolerar não mais do que a falha da maioria das máquinas; 2) Os dados são gravados apenas na maioria das máquinas e a confirmação é retornada para garantir a capacidade de resposta rápida do Cliente; 3) Os dados são sincronizados de forma assíncrona para todos os clusters na Máquina em segundo plano, garantindo assim alta disponibilidade.
❷No mecanismo Master-Slave aqui, há apenas um Slave, não um cluster Slave (veja o diagrama de estrutura acima). O tempo de inatividade do Master ou o tempo de inatividade do Slave causarão grandes riscos a todo o serviço Não há garantia de que "não mais do que a maioria das máquinas irá falhar" como no Hadoop HA, ou seja, nenhuma alta disponibilidade real é alcançada.
❸ Também pode haver um problema de "mestre duplo". Esse é o fenômeno "Dividir Brian" mencionado acima.
②Shared Database Master / Slave
Esta é uma arquitetura muito usada. "Armazenamento compartilhado" significa que os dados entre Mestre e Escravo são compartilhados.
Como evitar conflitos? Ao competir pelo bloqueio exclusivo da tabela do banco de dados, apenas o Mestre fica com o bloqueio, e aquele que não obteve o bloqueio torna-se automaticamente escravo.
ActiveMQ Message Broker usa um banco de dados relacional, ele obtém um bloqueio exclusivo em uma tabela garantindo que nenhum outro corretor ActiveMQ possa acessar o banco de dados ao mesmo tempo
Para "armazenamento compartilhado", apenas mensagens persistentes são "compartilhadas". Para mensagens não persistentes, elas são mantidas na memória. Você pode forçar a persistência de todas as mensagens por meio da propriedade de configuração (forcePersistencyModeBrokerPlugin persistenceFlag).
Quando o Master cai, o Slave pode automaticamente assumir o serviço e se tornar o Master. Como os dados são compartilhados, não há necessidade de copiar e sincronizar os dados entre Mestre e Escravo. Os escravos decidem quem é o Mestre por meio de bloqueios de competição.
③Sistema de arquivos compartilhado mestre / escravo
Este método é basicamente o mesmo que o princípio de armazenamento de banco de dados compartilhado (o sistema de arquivos também possui bloqueios de arquivos), portanto, não será apresentado em detalhes.
④O Replicated LevelDB Store mais próximo
1) Este método usa o Zookeeper para eleger o Mestre. Para conduzir uma eleição, você precisa de uma maioria de "participantes". Como há vários Brokers no Replicated LevelDB Store, um dos vários Brokers é eleito para se tornar o Mestre e os outros se tornam os escravos. Apenas o Mestre recebe a conexão do Cliente, e o Escravo é responsável por se conectar ao Mestre e receber dados (síncronos, assíncronos) no Mestre.
O nó do broker mestre eleito inicia e aceita conexões de cliente. Os outros nós vão para o modo escravo e conectam o mestre e sincronizam seu estado persistente / w it.
O exemplo acima também mostra: Cada corretor armazena dados separadamente . Porque o Master deseja copiar os novos dados para o Slave. Desta perspectiva: é um pouco inapropriado chamar esse método de "Compartilhar armazenamento".
2) Outra aplicação do mecanismo de Quorum
Supondo que existam 3 Corretores, então pelo menos dois Corretores devem concordar (principalmente) durante a eleição antes que o Mestre possa ser eleito. Além disso, você só precisa retornar um ACK ao Produtor quando a nova mensagem for copiada para a maioria dos Brokers. Alguns outros Brokers podem replicar novas mensagens de forma assíncrona em segundo plano .
Todas as operações de mensagens que requerem uma sincronização com o disco irão esperar que a atualização seja replicada para um quorum de nós antes de ser concluída. Portanto, se você configurar o armazenamento com réplicas = "3", o tamanho do quorum será (3/2 + 1) = 2. O mestre armazenará a atualização localmente e esperará por 1 outro escravo para armazenar a atualização antes de relatar o sucesso.
Por exemplo: há um total de 3 Brokers, um Master e dois Slaves. Quando uma nova mensagem chega ao Mestre, o Mestre precisa sincronizar a mensagem para um dos escravos antes de enviar um ACK ao Produtor para confirmar que a mensagem foi enviada com sucesso.
O escravo restante pode copiar a nova mensagem de forma assíncrona em segundo plano . Além disso, pode tolerar um tempo de inatividade do escravo. (Não pode tolerar mais do que o tempo de inatividade da maioria dos corretores)
Este requisito de design pode garantir a confiabilidade das mensagens no cluster.Somente quando os nós (réplicas / 2 + 1) falharem fisicamente, haverá o risco de perda de mensagens. Além disso, também melhora um certo grau de resposta, porque não precisa sincronizar as mensagens para todos os Slaves, mas só precisa ser sincronizado para a maioria dos Brokers.
3) Por quais critérios é usado para julgar quem é o Mestre e quem é o Escravo?
[A eleição será determinada de acordo com o tamanho do “carimbo de versão” e “peso” do “log de mensagens”, ou seja, quanto maior o “carimbo de versão” (os dados mais recentes) e quanto maior o peso, o corretor primeiro se tornará o mestre, e outros corretores agirão como escravos e seguirão o mestre. 】
Referência do blog : https://blog.csdn.net/weixin_33896069/article/details/85820560