Um artigo que li depois de estudar, reimprimir, ler com frequência, são tantos os benefícios!
O objetivo do nosso programa é fazer com que ele funcione de forma estável em qualquer circunstância. Um programa que roda rápido, mas acaba se revelando errado, é inútil. No processo de desenvolvimento e otimização do programa, devemos considerar a forma como o código é usado e os principais fatores que o afetam. Normalmente, temos que fazer uma compensação entre a simplicidade do programa e sua velocidade de execução. Hoje vamos falar sobre como otimizar o desempenho do programa.
1. Reduza a quantidade de cálculos do programa
1.1 Amostra de código
for (i = 0; i < n; i++) {
int ni = n*i;
for (j = 0; j < n; j++)
a[ni + j] = b[j];
}
1.2 Código de análise
O código é mostrado acima, cada vez que o loop externo é executado, precisamos realizar um cálculo de multiplicação. i = 0, ni = 0; i = 1, ni = n; i = 2, ni = 2n. Portanto, podemos substituir a multiplicação pela adição, usando n como o tamanho do passo, o que reduz a quantidade de código no loop externo.
1.3 Melhorar o código
int ni = 0;
for (i = 0; i < n; i++) {
for (j = 0; j < n; j++)
a[ni + j] = b[j];
ni += n; //乘法改加法
}
As instruções de multiplicação em um computador são muito mais lentas do que as instruções de adição.
2. Extraia as partes comuns do código
2.1 Amostra de código
Imagine que temos uma imagem. Representamos a imagem como um array bidimensional e os elementos do array representam pixels. Queremos obter a soma dos quatro vizinhos leste, sul, oeste e norte de um determinado pixel. E encontre sua média ou sua soma. O código é mostrado abaixo.
up = val[(i-1)*n + j ];
down = val[(i+1)*n + j ];
left = val[i*n + j-1];
right = val[i*n + j+1];
sum = up + down + left + right;
2.2 Código de análise
Depois de compilar o código acima, o código assembly é o mostrado abaixo. Observe que nas linhas 3, 4 e 5, existem três operações de multiplicação que se multiplicam por n. Depois de expandir o acima e para baixo, descobriremos que i * n + j está presente na expressão de quatro células. Portanto, a parte comum pode ser extraída e os valores de up, down, etc. podem ser obtidos por meio de operações de adição e subtração.
leaq 1(%rsi), %rax # i+1
leaq -1(%rsi), %r8 # i-1
imulq %rcx, %rsi # i*n
imulq %rcx, %rax # (i+1)*n
imulq %rcx, %r8 # (i-1)*n
addq %rdx, %rsi # i*n+j
addq %rdx, %rax # (i+1)*n+j
addq %rdx, %r8 # (i-1)*n+j
2.3 Melhore o código
long inj = i*n + j;
up = val[inj - n];
down = val[inj + n];
left = val[inj - 1];
right = val[inj + 1];
sum = up + down + left + right;
A compilação do código aprimorado é mostrada abaixo. Existe apenas uma multiplicação após a compilação. Reduzido em 6 ciclos de clock (um ciclo de multiplicação tem cerca de 3 ciclos de clock).
imulq %rcx, %rsi # i*n
addq %rdx, %rsi # i*n+j
movq %rsi, %rax # i*n+j
subq %rcx, %rax # i*n+j-n
leaq (%rsi,%rcx), %rcx # i*n+j+n
...
Para o compilador GCC, o compilador pode ter diferentes métodos de otimização de acordo com diferentes níveis de otimização e irá automaticamente completar as operações de otimização acima. Abaixo apresentamos, aqueles devem ser otimizados manualmente.
3. Elimine o código ineficiente no loop
3.1 Amostra de código
O programa não parece ser um problema, um código de conversão de caso muito comum, mas por que o tempo de execução do código aumenta exponencialmente à medida que o comprimento da string de entrada se torna mais longo?
void lower1(char *s)
{
size_t i;
for (i = 0; i < strlen(s); i++)
if (s[i] >= 'A' && s[i] <= 'Z')
s[i] -= ('A' - 'a');
}
3.2 Código de análise
Em seguida, testamos o código e inserimos uma série de strings.
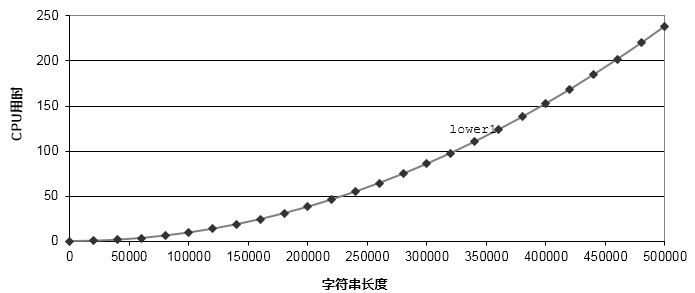
Teste de desempenho de código Lower1
Quando o comprimento da string de entrada é inferior a 100.000, o tempo de execução do programa tem pouca diferença. No entanto, à medida que o comprimento da string aumenta, o tempo de execução do programa aumenta exponencialmente.
Vamos dar uma olhada no código convertido para a forma goto.
void lower1(char *s)
{
size_t i = 0;
if (i >= strlen(s))
goto done;
loop:
if (s[i] >= 'A' && s[i] <= 'Z')
s[i] -= ('A' - 'a');
i++;
if (i < strlen(s))
goto loop;
done:
}
O código acima é dividido em três partes: inicialização (linha 3), teste (linha 4) e atualização (linha 9, 10). A inicialização será realizada apenas uma vez. Mas o teste e a atualização serão executados todas as vezes. Strlen é chamado uma vez sempre que o loop é executado.
Vamos dar uma olhada em como o código-fonte da função strlen calcula o comprimento de uma string.
size_t strlen(const char *s)
{
size_t length = 0;
while (*s != '\0') {
s++;
length++;
}
return length;
}
O princípio da função strlen para calcular o comprimento de uma string é: atravesse a string e pare até encontrar '\ 0'. Portanto, a complexidade de tempo da função strlen é O (N). Em lower1, para uma string de comprimento N, o número de chamadas para strlen é N, N-1, N-2 ... 1. Para uma chamada de função de tempo linear N vezes, a complexidade de tempo é próxima de O (N2).
3.3 Melhorar o código
Para esse tipo de chamada redundante que aparece no loop, podemos movê-la para fora do loop. Use o resultado do cálculo no loop. O código aprimorado é mostrado abaixo.
void lower2(char *s)
{
size_t i;
size_t len = strlen(s);
for (i = 0; i < len; i++)
if (s[i] >= 'A' && s[i] <= 'Z')
s[i] -= ('A' - 'a');
}
Compare as duas funções, conforme mostrado na figura abaixo. O tempo de execução da função lower2 foi significativamente melhorado.
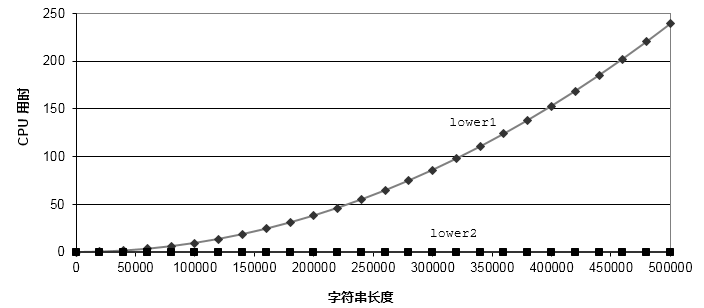
Eficiência de código inferior 1 e inferior 2
4. Elimine referências de memória desnecessárias
4.1 Amostra de código
O código a seguir é usado para calcular a soma de todos os elementos em cada linha do array a e armazená-lo em b [i].
void sum_rows1(double *a, double *b, long n) {
long i, j;
for (i = 0; i < n; i++) {
b[i] = 0;
for (j = 0; j < n; j++)
b[i] += a[i*n + j];
}
}
4.2 Código de análise
O código de montagem é mostrado abaixo.
# sum_rows1 inner loop
.L4:
movsd (%rsi,%rax,8), %xmm0 # 从内存中读取某个值放到%xmm0
addsd (%rdi), %xmm0 # %xmm0 加上某个值
movsd %xmm0, (%rsi,%rax,8) # %xmm0 的值写回内存,其实就是b[i]
addq $8, %rdi
cmpq %rcx, %rdi
jne .L4
Isso significa que cada loop precisa ler b [i] da memória e, em seguida, escrever b [i] de volta na memória. b [i] + = b [i] + a [i * n + j]; Na verdade, no início de cada loop, b [i] é o último valor. Por que você tem que ler da memória e escrever de volta todas as vezes?
4.3 Melhorar o código
/* Sum rows is of n X n matrix a
and store in vector b */
void sum_rows2(double *a, double *b, long n) {
long i, j;
for (i = 0; i < n; i++) {
double val = 0;
for (j = 0; j < n; j++)
val += a[i*n + j];
b[i] = val;
}
}
A montagem é mostrada abaixo.
# sum_rows2 inner loop
.L10:
addsd (%rdi), %xmm0 # FP load + add
addq $8, %rdi
cmpq %rax, %rdi
jne .L10
O código aprimorado introduz variáveis temporárias para armazenar resultados intermediários e apenas armazena os resultados em uma matriz ou variável global quando o valor final é calculado.
5. Reduza chamadas desnecessárias
5.1 Código de amostra
A título de exemplo, definimos uma estrutura que contém o array e o comprimento do array, principalmente para evitar que o acesso ao array saia dos limites, data_t pode ser int, long e outros tipos. Os detalhes são os seguintes.
typedef struct{
size_t len;
data_t *data;
} vec;

diagrama vetorial vec
A função de get_vec_element é percorrer os elementos na matriz de dados e armazená-los em val.
int get_vec_element (*vec v, size_t idx, data_t *val)
{
if (idx >= v->len)
return 0;
*val = v->data[idx];
return 1;
}
Usaremos o seguinte código como exemplo para começar a otimizar o programa passo a passo.
void combine1(vec_ptr v, data_t *dest)
{
long int i;
*dest = NULL;
for (i = 0; i < vec_length(v); i++) {
data_t val;
get_vec_element(v, i, &val);
*dest = *dest * val;
}
}
5.2 Código de análise
A função da função get_vec_element é obter o próximo elemento.Na função get_vec_element, cada ciclo deve ser comparado com v-> len para evitar cruzar o limite. É um bom hábito realizar verificações de limites, mas fazê-lo sempre resultará em eficiência reduzida.
5.3 Melhorar o código
Podemos mover o código para calcular o comprimento do vetor fora do loop e adicionar uma função get_vec_start ao tipo de dados abstrato. Esta função retorna o endereço inicial da matriz. Dessa forma, não há chamada de função no corpo do loop, mas acesso direto ao array.
data_t *get_vec_start(vec_ptr v)
{
return v-data;
}
void combine2 (vec_ptr v, data_t *dest)
{
long i;
long length = vec_length(v);
data_t *data = get_vec_start(v);
*dest = NULL;
for (i=0;i < length;i++)
{
*dest = *dest * data[i];
}
}
6. Loop desenrolando
6.1 Amostra de código
Fazemos melhorias no código de combine2.
6.2 Código de análise
Desenrolando aumentando cada iteração do número de elementos , reduzindo as iterações do loop .
6.3 Melhorar o código
void combine3(vec_ptr v, data_t *dest)
{
long i;
long length = vec_length(v);
long limit = length-1;
data_t *data = get_vec_start(v);
data_t acc = NULL;
/* 一次循环处理两个元素 */
for (i = 0; i < limit; i+=2) {
acc = (acc * data[i]) * data[i+1];
}
/* 完成剩余数组元素的计算 */
for (; i < length; i++) {
acc = acc * data[i];
}
*dest = acc;
}
No código aprimorado, o primeiro loop processa dois elementos da matriz por vez. Ou seja, para cada iteração, o índice do loop i é aumentado em 2 e, em uma iteração, a operação de mesclagem é usada nos elementos da matriz i e i + 1. Geralmente chamamos isso de desenrolamento de loop 2 × 1, e essa transformação pode reduzir o impacto da sobrecarga do loop.
Preste atenção para não ultrapassar o limite de acesso, defina o limite corretamente, n elementos, geralmente defina o limite n-1
7. Acumule variáveis, paralelo multicanal
7.1 Amostra de código
Fazemos melhorias no código de combine3.
7.2 Código de análise
Para uma operação de combinação combinável e comutativa, como adição ou multiplicação de inteiro, podemos melhorar o desempenho dividindo um conjunto de operações de combinação em duas ou mais partes e combinando os resultados no final.
Atenção especial: não combine facilmente números de ponto flutuante. O formato de codificação dos números de ponto flutuante é diferente de outros números inteiros.
7.3 Melhorar o código
void combine4(vec_ptr v, data_t *dest)
{
long i;
long length = vec_length(v);
long limit = length-1;
data_t *data = get_vec_start(v);
data_t acc0 = 0;
data_t acc1 = 0;
/* 循环展开,并维护两个累计变量 */
for (i = 0; i < limit; i+=2) {
acc0 = acc0 * data[i];
acc1 = acc1 * data[i+1];
}
/* 完成剩余数组元素的计算 */
for (; i < length; i++) {
acc0 = acc0 * data[i];
}
*dest = acc0 * acc1;
}
O código acima usa duas expansões de loop para mesclar mais elementos em cada iteração. Ele também usa dois caminhos paralelos para acumular os elementos com um índice par na variável acc0, e os elementos com um índice ímpar são acumulados na variável. Acc1. Portanto, chamamos isso de "desenrolamento de loop 2 × 2". Use o desenrolamento de loop 2 × 2. Ao manter várias variáveis cumulativas, este método tira proveito de várias unidades funcionais e seus recursos de pipeline
8. Recombinação e transformação
8.1 Amostra de código
Fazemos melhorias no código de combine3.
8.2 Código de análise
Neste ponto, o desempenho do código está basicamente próximo do limite, mesmo se você fizer mais desdobramentos de loop, a melhoria de desempenho não é óbvia. Precisamos mudar nosso pensamento, preste atenção ao código na linha 12 no código combine3, podemos mudar a ordem de fusão dos elementos do próximo vetor (números de ponto flutuante não são aplicáveis). O caminho da chave do código combine3 antes da recombinação é mostrado na figura abaixo.
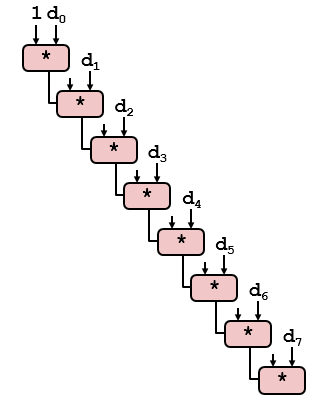
O caminho crítico do código combine3
8.3 Melhorar o código
void combine7(vec_ptr v, data_t *dest)
{
long i;
long length = vec_length(v);
long limit = length-1;
data_t *data = get_vec_start(v);
data_t acc = IDENT;
/* Combine 2 elements at a time */
for (i = 0; i < limit; i+=2) {
acc = acc OP (data[i] OP data[i+1]);
}
/* Finish any remaining elements */
for (; i < length; i++) {
acc = acc OP data[i];
}
*dest = acc;
}
A recombinação de transformações pode reduzir o número de operações no caminho crítico do cálculo.Este método aumenta o número de operações que podem ser executadas em paralelo e faz melhor uso dos recursos de pipeline das unidades funcionais para obter um melhor desempenho. O caminho crítico após a recombinação é o seguinte.
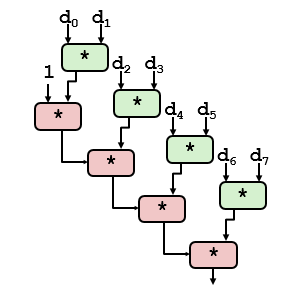
Caminho crítico após a recombinação combine3
9 Código de estilo de transferência condicional
9.1 Amostra de código
void minmax1(long a[],long b[],long n){
long i;
for(i = 0;i,n;i++){
if(a[i]>b[i]){
long t = a[i];
a[i] = b[i];
b[i] = t;
}
}
}
9.2 Código de análise
O desempenho do pipeline dos processadores modernos torna o trabalho do processador muito à frente das instruções que estão sendo executadas. A previsão de desvio no processador prevê para onde saltar em seguida ao encontrar uma instrução de comparação. Se a previsão estiver errada, é preciso voltar para onde o galho saltou. Erros de previsão de ramificação afetarão seriamente a eficiência de execução do programa. Portanto, devemos escrever um código que permita ao processador melhorar a precisão da predição, ou seja, usar instruções de transferência condicional. Usamos operações condicionais para calcular valores e, em seguida, usamos esses valores para atualizar o estado do programa, conforme mostrado no código aprimorado.
9.3 Melhorar o código
void minmax2(long a[],long b[],long n){
long i;
for(i = 0;i,n;i++){
long min = a[i] < b[i] ? a[i]:b[i];
long max = a[i] < b[i] ? b[i]:a[i];
a[i] = min;
b[i] = max;
}
}
Na 4ª linha do código original, a [i] e b [i] precisam ser comparados, e então o próximo passo é executado, a conseqüência é que uma previsão deve ser feita a cada vez. O código aprimorado implementa essa função para calcular os valores máximo e mínimo de cada posição i e, em seguida, atribuir esses valores a a [i] e b [i], em vez da previsão de ramo.
10. Resumo
Introduzimos várias técnicas para melhorar a eficiência do código, algumas das quais podem ser otimizadas automaticamente pelo compilador e outras precisam ser implementadas por nós mesmos. Ele é resumido da seguinte forma.
-
Elimine chamadas de função consecutivas. Quando possível, mova os cálculos para fora do loop. Considere comprometer seletivamente a modularidade do programa para maior eficiência.
-
Elimine referências de memória desnecessárias. Introduza variáveis temporárias para salvar resultados intermediários. Somente quando o valor final é calculado, o resultado é armazenado em uma matriz ou variável global.
-
Desenrole o loop, reduza a sobrecarga e torne possível a otimização adicional.
-
Usando técnicas como múltiplas variáveis de acumulação e recombinação, encontre maneiras de melhorar o paralelismo no nível de instrução.
-
Reescreva a operação condicional em um estilo funcional para que o compilador use a transferência de dados condicional.