O conteúdo a seguir é reproduzido de https://mp.weixin.qq.com/s/W9D4Sl-6jYfcpczzdPfByQ
Awa adora escrever programas originais Zhang fonte Viagens 05/05/2019
Este artigo é o décimo segundo capítulo da série "Análise de cenário de código-fonte do programador de linguagem Go" e também é a segunda subseção do Capítulo 2.
Este capítulo tomará o seguinte programa Hello World simples como um exemplo para analisar a inicialização do agendador da linguagem Go, a criação e saída de goroutines, o loop de agendamento de threads de trabalho e a troca de goroutines rastreando o processo de execução completo desde a inicialização para sair. E outros conteúdos importantes.
package main
import "fmt"
func main() {
fmt.Println("Hello World!")
}
Primeiro, analisamos a inicialização do escalonador desde o início do programa.
Antes de analisar o processo de inicialização do programa, vamos primeiro dar uma olhada no estado inicial da pilha do programa antes de executar a primeira instrução.
Qualquer programa escrito em uma linguagem compilada (seja C, C ++, go ou linguagem assembly) passará pelos seguintes estágios em sequência quando for carregado e executado pelo sistema operacional:
-
Leia o programa executável do disco para a memória;
-
Criar processo e thread principal;
-
Alocar espaço de pilha para o encadeamento principal;
-
Copie os parâmetros inseridos pelo usuário na linha de comando para a pilha do thread principal;
-
Coloque o encadeamento principal na fila de execução do sistema operacional e aguarde até que seja agendado para execução.
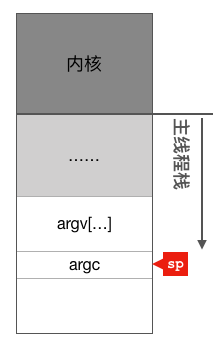
Antes que o thread principal seja programado para executar a primeira instrução pela primeira vez, a pilha de funções do thread principal é mostrada na figura a seguir:
Depois de entender o estado inicial do programa, vamos começar oficialmente.
Entrada no programa
Use go build para compilar hello.go na linha de comando do Linux para obter o programa executável hello e, em seguida, use gdb para depurar. No gdb, primeiro usamos o comando info files para encontrar o endereço do ponto de entrada do programa é 0x452270, e em seguida, use b * 0x452270 em 0x452270 Ao lado do ponto de interrupção no endereço, o gdb nos diz que o código-fonte correspondente a essa entrada é a linha 8 do arquivo runtime / rt0_linux_amd64.s.
bobo@ubuntu:~/study/go$ go build hello.go
bobo@ubuntu:~/study/go$ gdb hello
GNU gdb (GDB) 8.0.1
(gdb) info files
Symbols from "/home/bobo/study/go/main".
Local exec file:
`/home/bobo/study/go/main', file type elf64-x86-64.
Entry point: 0x452270
0x0000000000401000 - 0x0000000000486aac is .text
0x0000000000487000 - 0x00000000004d1a73 is .rodata
0x00000000004d1c20 - 0x00000000004d27f0 is .typelink
0x00000000004d27f0 - 0x00000000004d2838 is .itablink
0x00000000004d2838 - 0x00000000004d2838 is .gosymtab
0x00000000004d2840 - 0x00000000005426d9 is .gopclntab
0x0000000000543000 - 0x000000000054fa9c is .noptrdata
0x000000000054faa0 - 0x0000000000556790 is .data
0x00000000005567a0 - 0x0000000000571ef0 is .bss
0x0000000000571f00 - 0x0000000000574658 is .noptrbss
0x0000000000400f9c - 0x0000000000401000 is .note.go.buildid
(gdb) b *0x452270
Breakpoint 1 at 0x452270: file /usr/local/go/src/runtime/rt0_linux_amd64.s, line 8.Abra o editor de código e encontre o arquivo runtime / rt0_linx_amd64.s, que é um arquivo de código-fonte escrito em linguagem assembly Go. Discutimos seu formato na primeira parte deste livro. Agora olhe para a linha 8:
runtime / rt0_linx_amd64.s: 8
TEXT _rt0_amd64_linux(SB),NOSPLIT,$-8
JMP_rt0_amd64(SB)A primeira linha de código acima define o símbolo _rt0_amd64_linux, que não é uma instrução CPU real. A instrução JMP na segunda linha é a primeira instrução do thread principal. Esta instrução simplesmente salta para (equivalente a go language ou c Goto in) _rt0_amd64 continua a ser executado no símbolo. A definição de _rt0_amd64 está no arquivo runtime / asm_amd64.s:
runtime / asm_amd64.s: 14
TEXT _rt0_amd64(SB),NOSPLIT,$-8
MOVQ0(SP), DI// argc
LEAQ8(SP), SI // argv
JMPruntime·rt0_go(SB)As primeiras duas linhas de instruções colocam os endereços dos parâmetros argc e argv array passados pelo kernel do sistema operacional nos registradores DI e SI, respectivamente, e a terceira linha de instruções pula para rt0_go para execução.
A função rt0_go conclui todo o trabalho de inicialização quando o programa go é iniciado, portanto, essa função é relativamente longa e complicada, mas aqui nos concentramos apenas em algumas inicializações relacionadas ao agendador, vamos examiná-lo nas seções:
runtime / asm_amd64.s: 87
TEXT runtime·rt0_go(SB),NOSPLIT,$0
// copy arguments forward on an even stack
MOVQDI, AX// AX = argc
MOVQSI, BX// BX = argv
SUBQ$(4*8+7), SP// 2args 2auto
ANDQ$~15, SP //调整栈顶寄存器使其按16字节对齐
MOVQAX, 16(SP) //argc放在SP + 16字节处
MOVQBX, 24(SP) //argv放在SP + 24字节处A quarta instrução acima é usada para ajustar o valor do registro superior da pilha a ser alinhado em 16 bytes, ou seja, fazer com que o endereço da memória apontado pelo registro superior SP da pilha seja um múltiplo de 16, e o motivo pelo qual ele está alinhado a 16 bytes é porque a CPU tem um conjunto de instruções SSE. Os endereços de memória que aparecem nessas instruções devem ser múltiplos de 16. As duas últimas instruções movem argc e argv para novos locais. As outras partes deste código foram comentadas com mais detalhes, portanto, não vou explicar muito aqui.
Inicializar g0
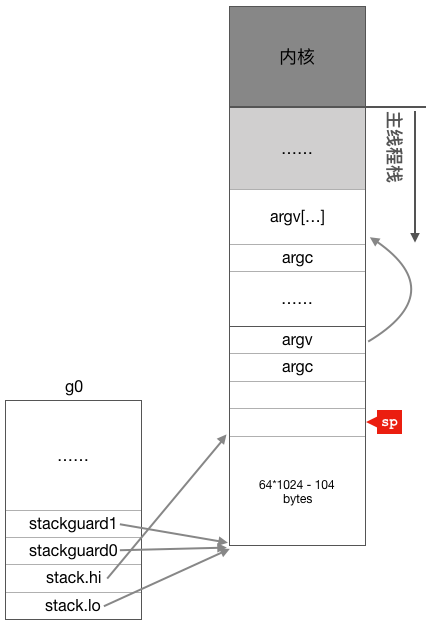
Continuando a examinar o código a seguir, a variável global g0 será inicializada abaixo. Como dissemos anteriormente, a função principal de g0 é fornecer uma pilha para execução de código em tempo de execução, portanto, aqui inicializamos principalmente vários membros relacionados à pilha de g0. A partir daqui, pode-se ver que a pilha de g0 tem cerca de 64K e o intervalo de endereços é SP-64 * 1024 + 104 ~ SP.
runtime / asm_amd64.s: 96
// create istack out of the given (operating system) stack.
// _cgo_init may update stackguard.
//下面这段代码从系统线程的栈空分出一部分当作g0的栈,然后初始化g0的栈信息和stackgard
MOVQ$runtime·g0(SB), DI //g0的地址放入DI寄存器
LEAQ(-64*1024+104)(SP), BX //BX = SP - 64*1024 + 104
MOVQBX, g_stackguard0(DI) //g0.stackguard0 = SP - 64*1024 + 104
MOVQBX, g_stackguard1(DI) //g0.stackguard1 = SP - 64*1024 + 104
MOVQBX, (g_stack+stack_lo)(DI) //g0.stack.lo = SP - 64*1024 + 104
MOVQSP, (g_stack+stack_hi)(DI) //g0.stack.hi = SPA relação entre g0 e a pilha após a execução das linhas de instruções acima é mostrada na figura a seguir:
A linha principal está ligada a m0
Depois de configurar a pilha g0, ignoramos a verificação do modelo da CPU e o código relacionado à inicialização do cgo e continuamos a análise diretamente da linha 164.
runtime / asm_amd64.s: 164
//下面开始初始化tls(thread local storage,线程本地存储)
LEAQruntime·m0+m_tls(SB), DI //DI = &m0.tls,取m0的tls成员的地址到DI寄存器
CALLruntime·settls(SB) //调用settls设置线程本地存储,settls函数的参数在DI寄存器中
// store through it, to make sure it works
//验证settls是否可以正常工作,如果有问题则abort退出程序
get_tls(BX) //获取fs段基地址并放入BX寄存器,其实就是m0.tls[1]的地址,get_tls的代码由编译器生成
MOVQ$0x123, g(BX) //把整型常量0x123拷贝到fs段基地址偏移-8的内存位置,也就是m0.tls[0]= 0x123
MOVQruntime·m0+m_tls(SB), AX //AX = m0.tls[0]
CMPQAX, $0x123 //检查m0.tls[0]的值是否是通过线程本地存储存入的0x123来验证tls功能是否正常
JEQ 2(PC)
CALLruntime·abort(SB) //如果线程本地存储不能正常工作,退出程序Este código primeiro chama a função settls para inicializar o armazenamento local do thread (TLS) do thread principal. O objetivo é associar m0 ao thread principal. Quanto ao motivo de m e o thread de trabalho estarem vinculados, já o apresentamos em a seção anterior. Agora, não vou repetir aqui. Depois de definir o armazenamento local do thread, as próximas instruções são para verificar se a função TLS está normal e, se não estiver, aborte o programa diretamente.
Vamos dar uma olhada detalhada em como a função settls implementa variáveis globais privadas de thread.
runtime / sys_linx_amd64.s: 606
// set tls base to DI
TEXT runtime·settls(SB),NOSPLIT,$32
//......
//DI寄存器中存放的是m.tls[0]的地址,m的tls成员是一个数组,读者如果忘记了可以回头看一下m结构体的定义
//下面这一句代码把DI寄存器中的地址加8,为什么要+8呢,主要跟ELF可执行文件格式中的TLS实现的机制有关
//执行下面这句指令之后DI寄存器中的存放的就是m.tls[1]的地址了
ADDQ$8, DI// ELF wants to use -8(FS)
//下面通过arch_prctl系统调用设置FS段基址
MOVQDI, SI //SI存放arch_prctl系统调用的第二个参数
MOVQ$0x1002, DI// ARCH_SET_FS //arch_prctl的第一个参数
MOVQ$SYS_arch_prctl, AX //系统调用编号
SYSCALL
CMPQAX, $0xfffffffffffff001
JLS2(PC)
MOVL$0xf1, 0xf1 // crash //系统调用失败直接crash
RETComo você pode ver no código, o endereço de m0.tls [1] é definido como o endereço base do segmento fs por meio da chamada de sistema arch_prctl. Há um registrador de segmento chamado fs na CPU correspondente a ele, e cada thread tem seu próprio conjunto de valores de registro de CPU. O sistema operacional nos ajudará a salvar os valores em todos os registradores na memória quando o thread for ajustado longe a CPU. Quando o thread de agendamento estiver ativo e em execução, os valores desses registros serão restaurados da memória para a CPU, para que, depois disso, o código do thread de trabalho possa encontrar m.tls por meio do registrador fs. Os leitores podem consulte a função tls após inicializar tls acima. Verifique o código para entender esse processo.
Vamos continuar a analisar rt0_go,
runtime / asm_amd64.s: 174
ok:
// set the per-goroutine and per-mach "registers"
get_tls(BX) //获取fs段基址到BX寄存器
LEAQruntime·g0(SB), CX //CX = g0的地址
MOVQCX, g(BX) //把g0的地址保存在线程本地存储里面,也就是m0.tls[0]=&g0
LEAQruntime·m0(SB), AX //AX = m0的地址
//把m0和g0关联起来m0->g0 = g0,g0->m = m0
// save m->g0 = g0
MOVQCX, m_g0(AX) //m0.g0 = g0
// save m0 to g0->m
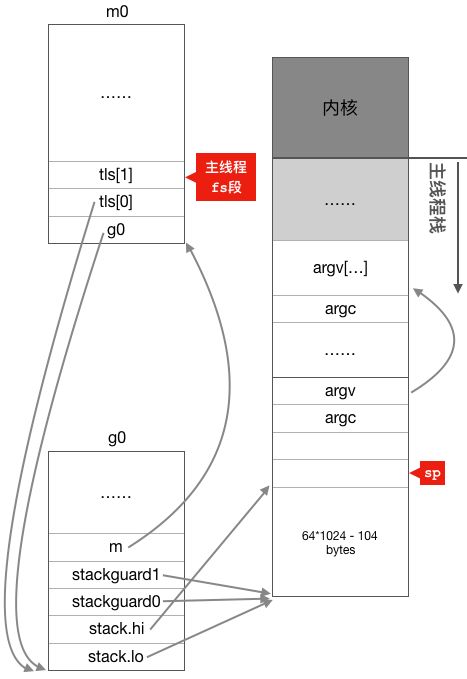
MOVQAX, g_m(CX) //g0.m = m0O código acima primeiro coloca o endereço de g0 no armazenamento local do segmento do segmento principal e, em seguida, passa
m0.g0 = &g0
g0.m = &m0Ligue m0 e g0 juntos, de modo que g0 possa ser obtido através de get_tls na thread principal, e m0 pode ser encontrado através do membro m de g0, então a associação entre m0 e g0 e a thread principal é realizada aqui. Também pode ser visto aqui que o valor armazenado no armazenamento local da thread principal é o endereço de g0, o que significa que a variável global privada da thread de trabalho é na verdade um ponteiro para g em vez de um ponteiro para m. presente, este ponteiro aponta para g0. Indica que o código está sendo executado na pilha g0. Neste momento, a relação entre a pilha do encadeamento principal, m0, g0 e g0 é mostrada na figura a seguir:
Inicializar m0
O código a seguir começa a processar os parâmetros da linha de comando. Não nos importamos com essa parte, então pule-a. Depois que os parâmetros da linha de comando são processados, a função osinit é chamada para obter o número de núcleos da CPU e armazenada na variável global ncpu. Quando o agendador é inicializado, ele precisa saber quantos núcleos da CPU o sistema atual possui.
runtime / asm_amd64.s: 189
//准备调用args函数,前面四条指令把参数放在栈上
MOVL16(SP), AX// AX = argc
MOVLAX, 0(SP) // argc放在栈顶
MOVQ24(SP), AX// AX = argv
MOVQAX, 8(SP) // argv放在SP + 8的位置
CALLruntime·args(SB) //处理操作系统传递过来的参数和env,不需要关心
//对于linx来说,osinit唯一功能就是获取CPU的核数并放在global变量ncpu中,
//调度器初始化时需要知道当前系统有多少CPU核
CALLruntime·osinit(SB) //执行的结果是全局变量 ncpu = CPU核数
CALLruntime·schedinit(SB) //调度系统初始化Em seguida, continue a ver como o agendador é inicializado.
runtime / proc.go: 526
func schedinit() {
// raceinit must be the first call to race detector.
// In particular, it must be done before mallocinit below calls racemapshadow.
//getg函数在源代码中没有对应的定义,由编译器插入类似下面两行代码
//get_tls(CX)
//MOVQ g(CX), BX; BX存器里面现在放的是当前g结构体对象的地址
_g_ := getg() // _g_ = &g0
......
//设置最多启动10000个操作系统线程,也是最多10000个M
sched.maxmcount = 10000
......
mcommoninit(_g_.m) //初始化m0,因为从前面的代码我们知道g0->m = &m0
......
sched.lastpoll = uint64(nanotime())
procs := ncpu //系统中有多少核,就创建和初始化多少个p结构体对象
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n //如果环境变量指定了GOMAXPROCS,则创建指定数量的p
}
if procresize(procs) != nil {//创建和初始化全局变量allp
throw("unknown runnable goroutine during bootstrap")
}
......
}Como vimos antes, o endereço de g0 foi definido para o armazenamento local do thread e schedinit usa a função getg (a função getg é implementada pelo compilador, e não podemos encontrar sua definição no código-fonte) do thread de armazenamento local. Obtenha o g atualmente em execução, aqui está g0, e chame a função mcommoninit para inicializar m0 (g0.m) conforme necessário. Após a inicialização de m0 ser concluída, chame procresize para inicializar o objeto de estrutura p que o sistema necessidades, de acordo com go De acordo com a linguagem oficial, p é o significado de processador, e seu número determina que pode haver no máximo menos goroutines executando em paralelo ao mesmo tempo. Além de inicializar m0 e p, a função schedinit também define o membro maxmcount da variável global sched em 10000, o que limita o número de threads de sistema operacional que podem ser criados em até 10000 para funcionar.
Aqui, precisamos nos concentrar em como mcommoninit inicializa m0 e como a função procresize cria e inicializa p objetos de estrutura. Primeiro, mergulhamos na função mcommoninit para descobrir. Deve-se notar aqui que esta função não só é executada durante a inicialização, mas também se um thread de trabalho é criado durante a operação do programa, então veremos o bloqueio e verificaremos se o número de threads excedeu o máximo na função E outros relacionados código.
runtime / proc.go: 596
func mcommoninit(mp *m) {
_g_ := getg() //初始化过程中_g_ = g0
// g0 stack won't make sense for user (and is not necessary unwindable).
if _g_ != _g_.m.g0 { //函数调用栈traceback,不需要关心
callers(1, mp.createstack[:])
}
lock(&sched.lock)
if sched.mnext+1 < sched.mnext {
throw("runtime: thread ID overflow")
}
mp.id = sched.mnext
sched.mnext++
checkmcount() //检查已创建系统线程是否超过了数量限制(10000)
//random初始化
mp.fastrand[0] = 1597334677 * uint32(mp.id)
mp.fastrand[1] = uint32(cputicks())
if mp.fastrand[0]|mp.fastrand[1] == 0 {
mp.fastrand[1] = 1
}
//创建用于信号处理的gsignal,只是简单的从堆上分配一个g结构体对象,然后把栈设置好就返回了
mpreinit(mp)
if mp.gsignal != nil {
mp.gsignal.stackguard1 = mp.gsignal.stack.lo + _StackGuard
}
//把m挂入全局链表allm之中
// Add to allm so garbage collector doesn't free g->m
// when it is just in a register or thread-local storage.
mp.alllink = allm
// NumCgoCall() iterates over allm w/o schedlock,
// so we need to publish it safely.
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
unlock(&sched.lock)
// Allocate memory to hold a cgo traceback if the cgo call crashes.
if iscgo || GOOS == "solaris" || GOOS == "windows" {
mp.cgoCallers = new(cgoCallers)
}
}Pode-se ver no código-fonte desta função que não há inicialização relacionada ao agendamento para m0, então você pode simplesmente pensar que esta função apenas coloca m0 na lista global vinculada allm e retorna.
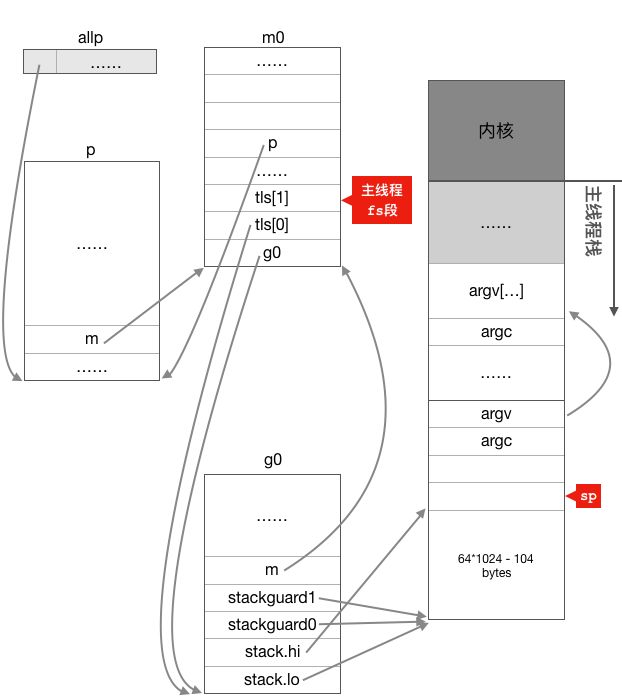
Após m0 completar a inicialização básica, continue a chamar procresize para criar e inicializar o objeto de estrutura p. Nesta função, um número especificado de objetos de estrutura p (determinado pelo número de núcleos de cpu ou variáveis de ambiente) será criado e colocado no variável completa allp, e Ligar m0 e allp [0] juntos, então quando esta função for executada, haverá
m0.p = allp[0]
allp[0].m = &m0Nesse ponto, m0, g0 e p exigidos por m estão completamente relacionados.
Inicializar allp
Vejamos a função procresize. Após a inicialização ser concluída, o código do usuário também pode chamá-lo por meio da função GOMAXPROCS () para recriar e inicializar o objeto de estrutura p. Há muitos problemas envolvidos no ajuste dinâmico de p durante a operação, então O processamento desta função é mais complicado, mas se você considerar apenas a inicialização, é relativamente mais simples, então aqui apenas o código que será executado durante a inicialização é retido:
runtime / proc.go: 3902
func procresize(nprocs int32) *p {
old := gomaxprocs //系统初始化时 gomaxprocs = 0
......
// Grow allp if necessary.
if nprocs > int32(len(allp)) { //初始化时 len(allp) == 0
// Synchronize with retake, which could be running
// concurrently since it doesn't run on a P.
lock(&allpLock)
if nprocs <= int32(cap(allp)) {
allp = allp[:nprocs]
} else { //初始化时进入此分支,创建allp 切片
nallp := make([]*p, nprocs)
// Copy everything up to allp's cap so we
// never lose old allocated Ps.
copy(nallp, allp[:cap(allp)])
allp = nallp
}
unlock(&allpLock)
}
// initialize new P's
//循环创建nprocs个p并完成基本初始化
for i := int32(0); i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)//调用内存分配器从堆上分配一个struct p
pp.id = i
pp.status = _Pgcstop
......
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}
......
}
......
_g_ := getg() // _g_ = g0
if _g_.m.p != 0 && _g_.m.p.ptr().id < nprocs {//初始化时m0->p还未初始化,所以不会执行这个分支
// continue to use the current P
_g_.m.p.ptr().status = _Prunning
_g_.m.p.ptr().mcache.prepareForSweep()
} else {//初始化时执行这个分支
// release the current P and acquire allp[0]
if _g_.m.p != 0 {//初始化时这里不执行
_g_.m.p.ptr().m = 0
}
_g_.m.p = 0
_g_.m.mcache = nil
p := allp[0]
p.m = 0
p.status = _Pidle
acquirep(p) //把p和m0关联起来,其实是这两个strct的成员相互赋值
if trace.enabled {
traceGoStart()
}
}
//下面这个for 循环把所有空闲的p放入空闲链表
var runnablePs *p
for i := nprocs - 1; i >= 0; i-- {
p := allp[i]
if _g_.m.p.ptr() == p {//allp[0]跟m0关联了,所以是不能放任
continue
}
p.status = _Pidle
if runqempty(p) {//初始化时除了allp[0]其它p全部执行这个分支,放入空闲链表
pidleput(p)
} else {
......
}
}
......
return runnablePs
}Este código de função é relativamente longo, mas não complicado. Aqui está um resumo do fluxo principal desta função:
-
Use make ([] * p, nprocs) para inicializar a variável global allp, ou seja, allp = make ([] * p, nprocs)
-
Criar e inicializar objetos de estrutura nprocs p ciclicamente e salvá-los em fatias allp por sua vez
-
Ligue m0 e allp [0] juntos, ou seja, m0.p = allp [0], allp [0] .m = m0
-
Coloque todos os p exceto allp [0] na fila livre do pidle da variável global sched
Após a execução da função procresize, o trabalho de inicialização relacionado ao escalonador está basicamente encerrado.Neste momento, o relacionamento entre os vários componentes de todo o escalonador é mostrado na figura a seguir:
Depois de analisar a inicialização básica do escalonador, na próxima seção veremos como a primeira goroutine no programa é criada.
Por fim, se você acha que este artigo é útil para você, por favor me ajude a clicar em “Olhando” no canto inferior direito do artigo ou encaminhe para o círculo de amigos, muito obrigado!
