Artigo Diretório
Introdução à arquitetura Flink
A instalação e implantação do Flink são divididas principalmente em modo local (máquina única) e modo de cluster. O modo local pode ser usado descompactando diretamente sem modificar nenhum parâmetro. Geralmente é usado ao fazer alguns testes simples. O modo local não será repetido em nosso curso. O modo de cluster inclui:
Independente.
Flink on Yarn.
Mesos.
Docker.
Kubernetes.
AWS.
Goole Compute Engine.
Aqui, primeiro implante o cluster de modo independente
Estrutura básica
Todo o sistema Flink é composto principalmente por dois componentes, nomeadamente JobManager e TaskManager. A arquitetura Flink também segue os princípios de design da arquitetura Master-Slave. O JobManager é o nó Master e o TaskManager é o nó Worker (Slave). A comunicação entre todos os componentes é feita por meio do Akka Framework, incluindo o status da tarefa e o esquema de informações de acionamento do Checkpoint é o seguinte:
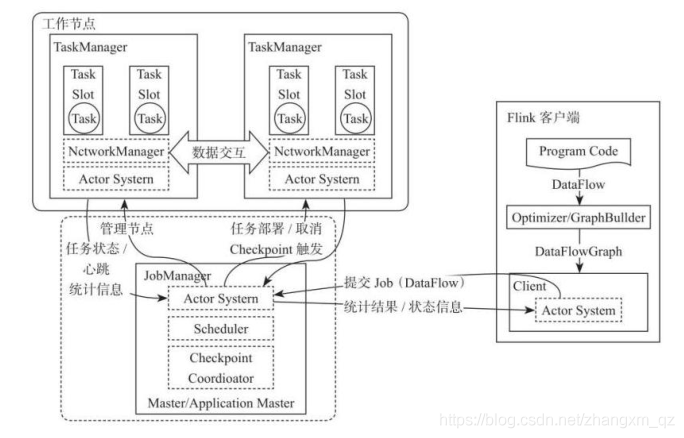
Cliente
O cliente é responsável por enviar tarefas ao cluster, o conector JobManager Akka construído e enviar tarefas ao JobManager, obtenha o status de execução da tarefa interagindo com o JobManager. Os clientes podem enviar tarefas por CLI ou usando Flink WebUI. Você também pode especificar a porta de rede RPC do JobManager no aplicativo para construir ExecutionEnvironment. Envie o aplicativo Flink.
JobManager
JobManager é responsável pelo agendamento de tarefas e gerenciamento de recursos de todo o Flink A partir do cliente Obtenha o aplicativo enviado e, em seguida, aloque recursos TaskSlots para o aplicativo enviado de acordo com o uso de TaskSlot no TaskManager no cluster e instrua o TaskManger a iniciar o aplicativo. JobManager é equivalente ao nó Master de todo o cluster, e há apenas um JobManager ativo em todo o cluster, responsável pelo gerenciamento de tarefas e gerenciamento de recursos de todo o cluster.
O JobManager e o TaskManager se comunicam por meio do Actor System para obter o status de execução da tarefa e enviar o status de execução ao cliente por meio do Actor System. Ao mesmo tempo, no processo de execução da tarefa, Flink JobManager acionará a operação de Checkpoints. Depois que cada nó TaskManager recebe a instrução de gatilho de Checkpoint, ele conclui a operação de Checkpoint. Todos os processos de coordenação de checkpoint são concluídos no Flink JobManager. Quando a tarefa for concluída, Flink retornará as informações da execução da tarefa ao cliente e liberará os recursos no TaskManager para o próximo envio de tarefa.
TaskManager
TaskManager é equivalente ao nó escravo de todo o cluster, responsável pela execução de tarefas específicas e aplicação de recursos e gerenciamento de tarefas correspondentes em cada nó. O cliente compila e empacota o aplicativo Flink preparado, envia-o ao JobManager e, em seguida, o JobManager atribui a tarefa ao nó TaskManager com recursos de acordo com a situação do recurso do TaskManager registrado e, a seguir, inicia e executa a tarefa. O TaskManager recebe as tarefas que precisam ser implantadas do JobManager e, a seguir, usa o recurso Slot para iniciar a Tarefa, estabelece uma conexão de rede para acesso aos dados, recebe os dados e inicia o processamento dos dados. Ao mesmo tempo, a interação de dados entre TaskManagers é realizada por meio de fluxo de dados.
A operação de tarefa do Flink é, na verdade, multiencadeada, o que é muito diferente do processo MapReduce multi-JVM. O Fink pode melhorar muito a eficiência do uso da CPU. Os recursos do sistema são compartilhados entre várias tarefas e tarefas por meio do TaskSlot. Gerenciamento eficaz de recursos gerenciando vários Pools de recursos do TaskSlot em um TaskManager
Instalação e implantação
Preparação de documentos e planejamento de implantação
Preparamos três servidores server01, server02, server03
server01 como jobManager (master) server01, server02, server03 como TaskManager (slave) server01 como master e slave para
baixar e instalar o arquivo flink-1.9.1-bin-scala_2.12 .tgz, endereço de download: https://download.csdn.net/download/zhangxm_qz/12732760
Faça upload de arquivos para o servidor e descompacte
Faça upload do arquivo flink-1.9.1-bin-scala_2.12.tgz para o diretório server01 server / opt / apps
e descompacte-o da seguinte forma:
[root@server01 apps]# ll
total 750912
lrwxrwxrwx. 1 root root 11 Jun 14 22:54 flink -> flink-1.9.1
drwxr-xr-x. 10 502 games 156 Sep 30 2019 flink-1.9.1
-rw-r--r--. 1 root root 246364329 Aug 20 2020 flink-1.9.1-bin-scala_2.12.tgz
Modifique o arquivo de configuração
Acesse o diretório conf em flink para modificar o arquivo de configuração flink-conf.yaml e modifique os dois itens a seguir
jobmanager.rpc.address: server01 # 修改master节点服务器 我这里是 server01 做master
taskmanager.numberOfTaskSlots: 3 # taskmanager.numberOfTaskSlot 参数默认值为 1,修改成 3。表示数每一个TaskManager 上有 3 个 Slot
Modifique o conteúdo do arquivo slaves da seguinte forma:
"flink-conf.yaml" 259L, 10326C written
[root@server01 conf]# vi slaves
server01
server02
server03
~
Distribuir arquivos de instalação para outros servidores
Copie o diretório flink modificado para server02 e server03, o comando é o seguinte:
[root@server01 apps]# scp -r flink-1.9.1 root@server02:/opt/apps
[root@server01 apps]# scp -r flink-1.9.1 root@server03:/opt/apps
Inicie o cluster
Execute o comando start-cluster.sh em bin para iniciar o cluster da seguinte maneira:
[root@server01 flink]# bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host server01.
Starting taskexecutor daemon on host server01.
Starting taskexecutor daemon on host server02.
Starting taskexecutor daemon on host server03.
Visite webUI
Após a inicialização bem-sucedida, visite http: // server01: 8081 para acessar flinkwebUI da seguinte forma:
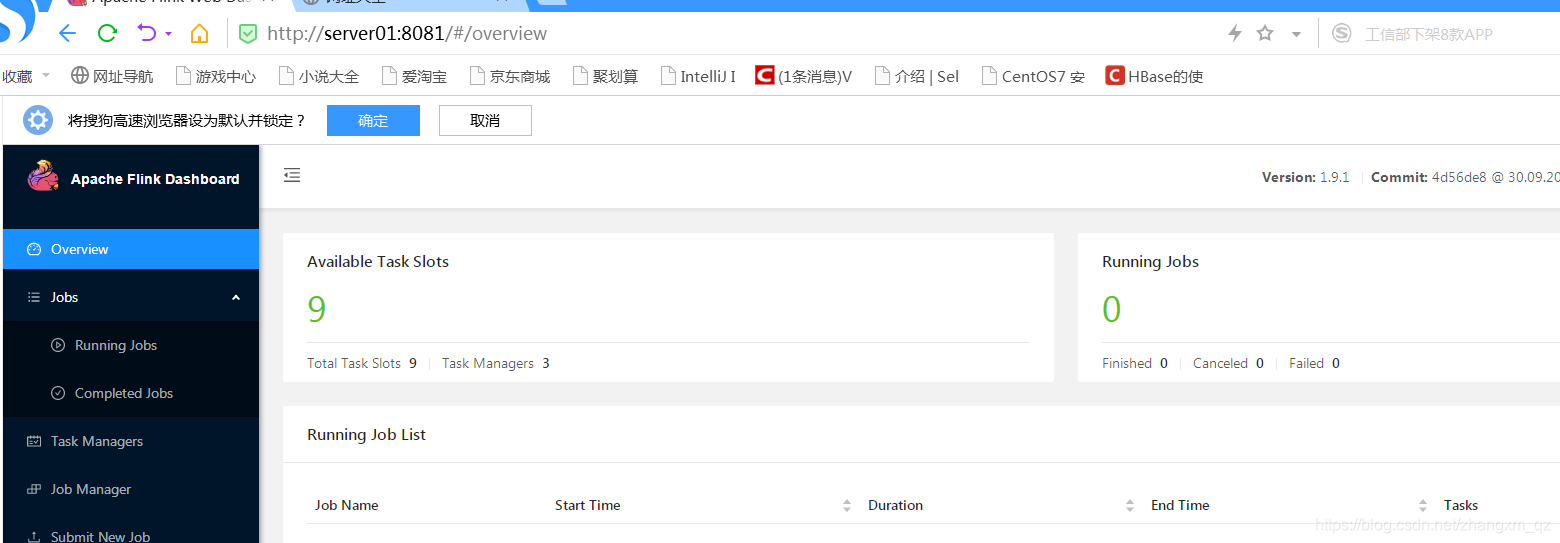
Upload de tarefas para o cluster
Desenvolver programa de exemplo WordCount
código mostrado abaixo
package com.test.flink.wc
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object StreamWordCount {
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment =
StreamExecutionEnvironment.getExecutionEnvironment
//导入隐式转换,建议写在这里,可以防止IDEA代码提示出错的问题
import org.apache.flink.streaming.api.scala._
//读取数据
val stream: DataStream[String] = streamEnv.socketTextStream("server01",8888)
//转换计算
val result: DataStream[(String, Int)] = stream.flatMap(_.split(","))
.map((_, 1))
.keyBy(0)
.sum(1)
//打印结果到控制台
result.print()
//启动流式处理,如果没有该行代码上面的程序不会运行
streamEnv.execute("wordcount")
}
}
Faça upload de tarefas para o cluster Flink por meio de comandos
Faça upload do pacote jar do programa para o local server01 da seguinte maneira:
[root@server01 flink]# ll appjars
total 24
-rw-r--r--. 1 root root 22361 Aug 20 2020 test-1.0-SNAPSHOT.jar
Executar tarefa de upload de comando
Como o programa precisa se conectar à porta 8888 do server01, você deve primeiro iniciar o programa de envio de dados por meio do seguinte comando, caso contrário, a tarefa falhará ao iniciar devido a uma falha de conexão
. Execute o seguinte comando no server01 (se o comando não existir , execute yum install -y nc para instalar):
[root@server01 flink]# nc -lk 8888
Faça o upload do pacote para o motor flink
[root@server01 flink]# bin/flink run -d -c com.test.flink.wc.StreamWordCount ./appjars/test-1.0-SNAPSHOT.jar
Starting execution of program
Job has been submitted with JobID 75fd7304caa7d429b343b77dff4ce65d
Ao enviar uma string para o manipulador no terminal, você pode ver a execução da tarefa no webUI
[root@server01 flink]# nc -lk 8888
a
a
a
a
a
a
a
a

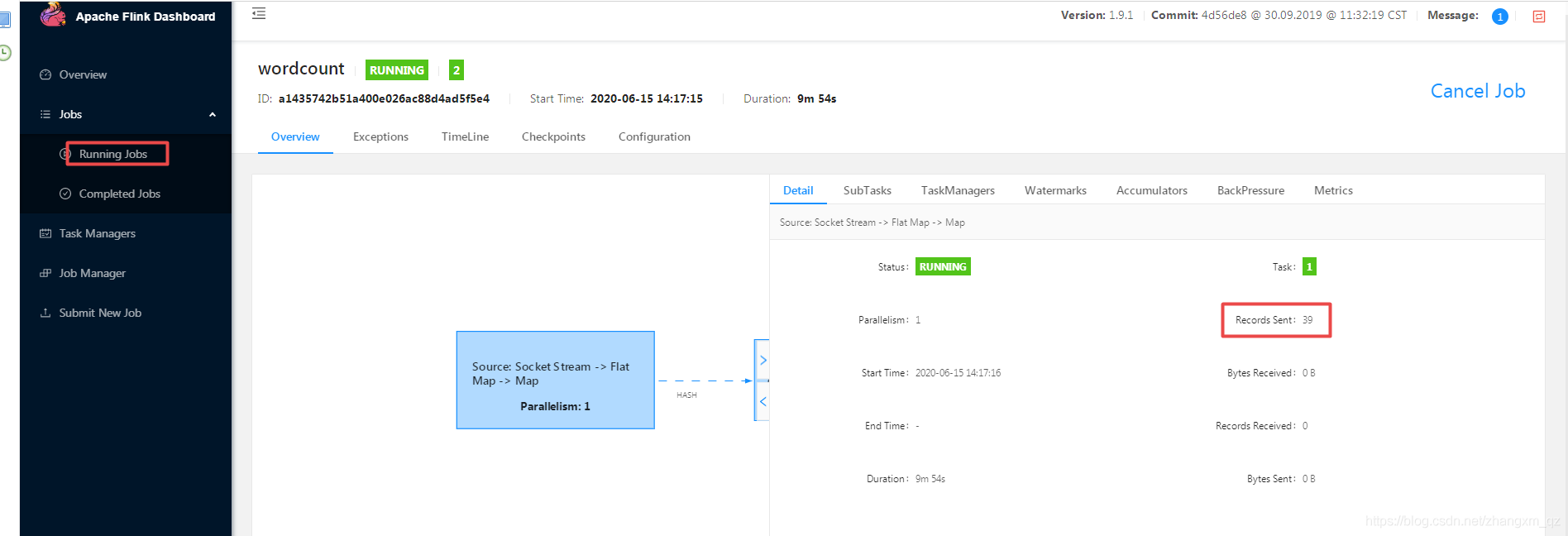
Carregar tarefas para o cluster Flink por meio de webUI
Você também pode fazer upload do programa de tarefas por meio da interface webUI
