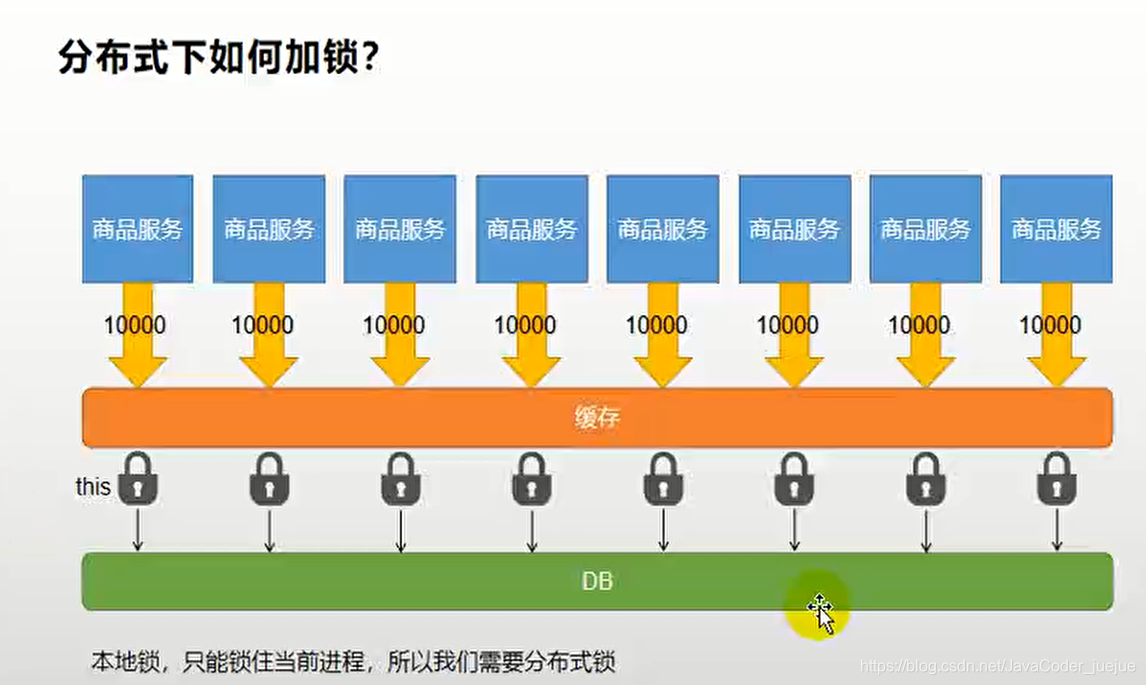
1. Princípio
Um princípio básico de bloqueios distribuídos é que quando vários threads em vários serviços acessam um recurso, todos vão para o mesmo lugar para ocupar o poço. Este lugar é o cache, que é compartilhado por todos os serviços. O primeiro thread a acessar irá para o cache. Configuração intermediária
Um cache de valor de chave, por ser uma operação atômica, o cache falha quando o thread subsequente define a mesma chave, realizando assim um bloqueio distribuído
2. Como implementar comandos do Linux
Referência de comando
http://www.redis.cn/commands/set.html

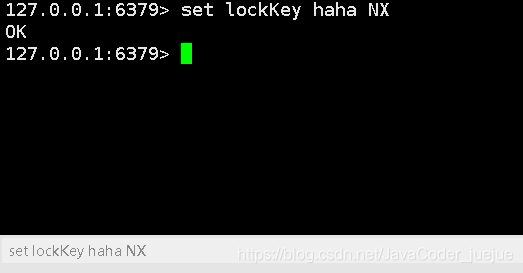
No link acima, podemos ver que quando a opção NX é adicionada à instrução definida, os dados podem ser armazenados em cache apenas quando a chave não existe
(1) Copie quatro links

(2) Envie o mesmo comando para se conectar ao cliente (lembre-se de mudar os privilégios de root primeiro)
(3) Depois de conectar, envie o comando de cache novamente ao mesmo tempo
Conexão 1
As conexões 2, 3 e 4 são todas as interfaces a seguir e todas retornam nulo, que é nulo
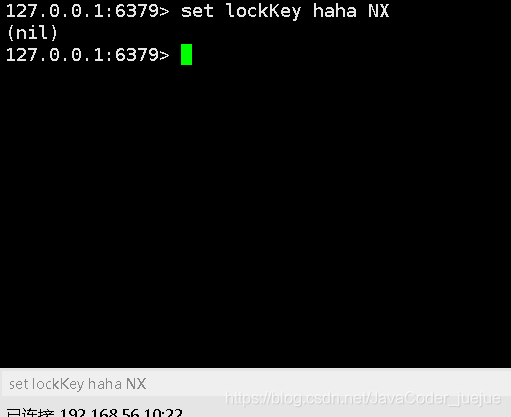
Pode-se observar que no modo cache NX, quando o valor da chave é o mesmo, apenas o primeiro cache terá sucesso, sendo este o princípio básico dos bloqueios distribuídos.

3. Implementação de código e otimização perfeita
A implementação inicial, o código central é o seguinte, quando acessamos um thread (consultamos o banco de dados e salvamos os dados no cache), adicionamos um bloqueio distribuído a ele, ou seja, definimos um cache com chave como bloqueio no modo NX em redis. Quando outros threads acessam, se a configuração do cache falhar, significa que o bloqueio distribuído não foi obtido, e girou, ou seja, chamar este método repetidamente para tentar novamente, é claro, para não tentar muito frequentemente, você pode definir o tempo de sono
@Override
public Map<String, List<Catelog2Vo>> getCatalogJson() {
//先从缓存中尝试获取,若为空则从数据库中获取然后放入缓存
String catalogJson;
synchronized (this) {
ValueOperations<String, String> opsForValue = stringRedisTemplate.opsForValue();
catalogJson = opsForValue.get("catalogJson");
System.out.println("从缓存内查询...");
if (StringUtils.isEmpty(catalogJson)) {
Map<String, List<Catelog2Vo>> catalogJsonFromDb = null;
try {
catalogJsonFromDb = getCatalogJsonFromDbWithRedisLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("从数据库内查询...");
return catalogJsonFromDb;
}
}
Map<String, List<Catelog2Vo>> catalogJsonFromCache = JSON.parseObject(catalogJson, new TypeReference<Map<String, List<Catelog2Vo>>>() {
});
return catalogJsonFromCache;
}
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() throws InterruptedException {
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "111");
if(lock){
Map<String, List<Catelog2Vo>> dataFromDb = getDataFromDb();
//删除锁
stringRedisTemplate.delete("lock");
return dataFromDb;
}else{
Thread.sleep(100);
return getCatalogJsonFromDbWithRedisLock();
}
}Analise os problemas nas implementações acima. Antes de excluir o bloqueio, uma anormalidade, falha de energia ou tempo de inatividade causará um deadlock.
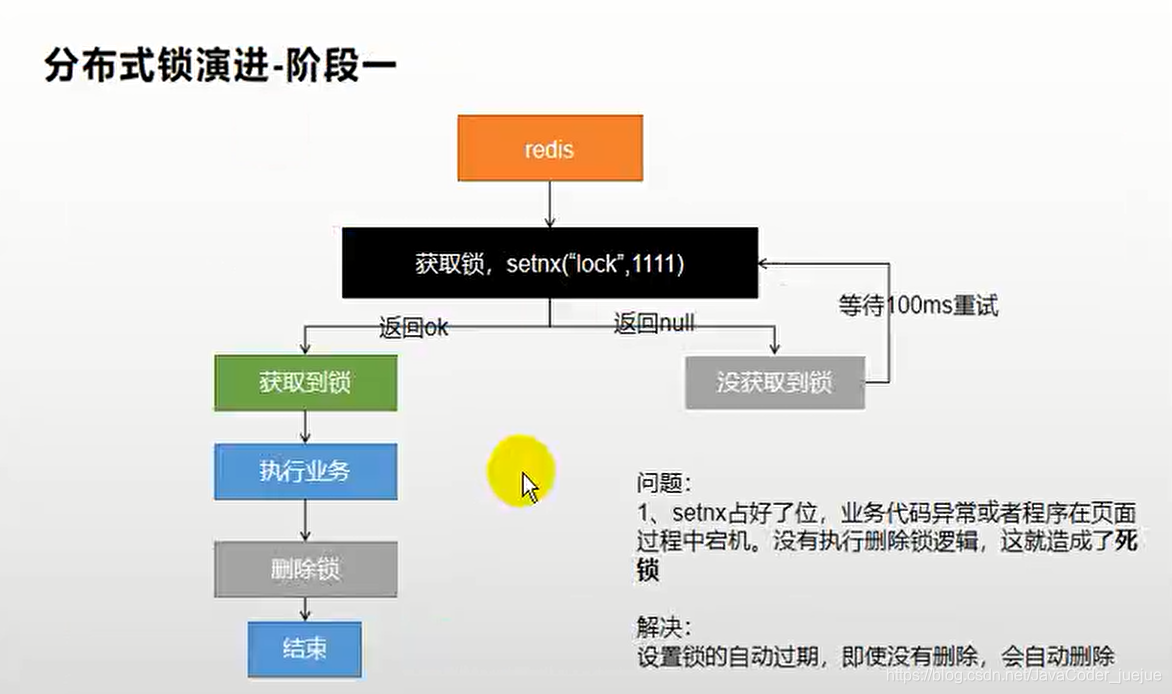
, Portanto, definimos um prazo de validade para a chave (fechadura)
Desta vez, porque configuramos separadamente, se a energia for cortada antes do tempo de expiração ser definido após o bloqueio ser adquirido, isso também causará um deadlock.
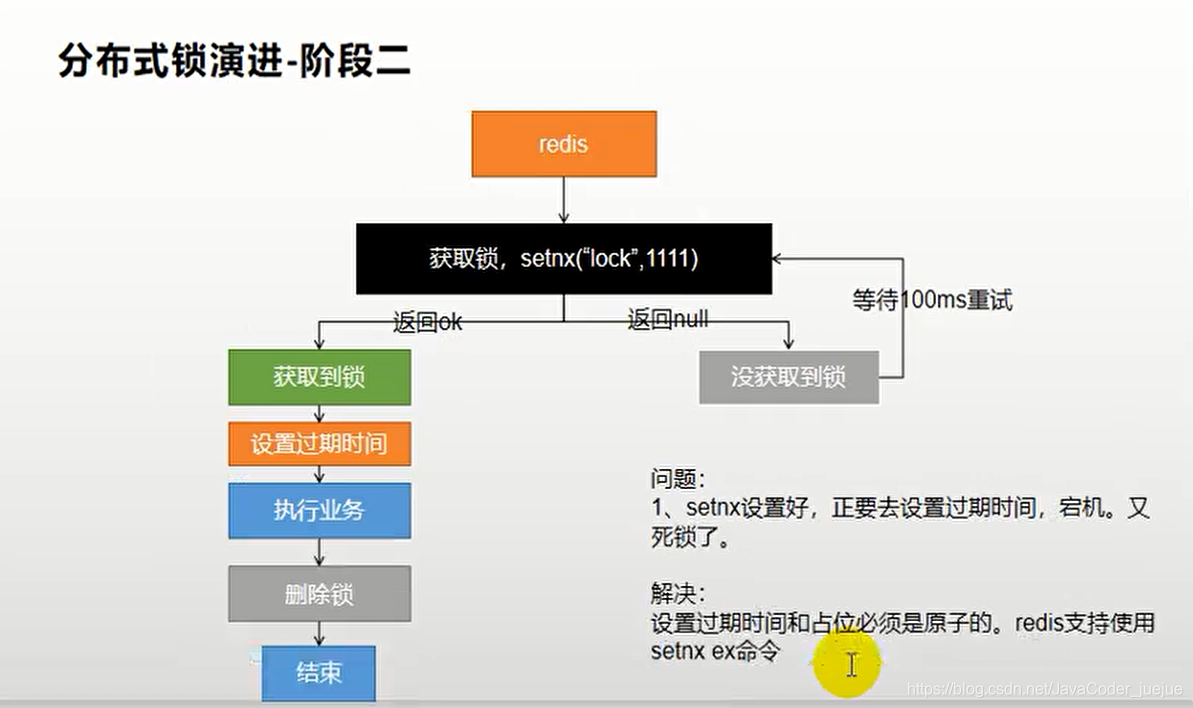
Solução: o tempo de expiração do cache e dos dados em cache deve ser definido atomicamente e o redis oferece suporte, portanto, altere-o para o código a seguir
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "111",30,TimeUnit.SECONDS);
Mas ainda há um problema. Quando consultamos o banco de dados e o adicionamos ao cache ou processamos a lógica de negócios por muito tempo, isso excede o tempo de expiração que definimos. Nesse momento, se o bloqueio for excluído após a lógica ser executada, ele será excluído por outros tópicos.
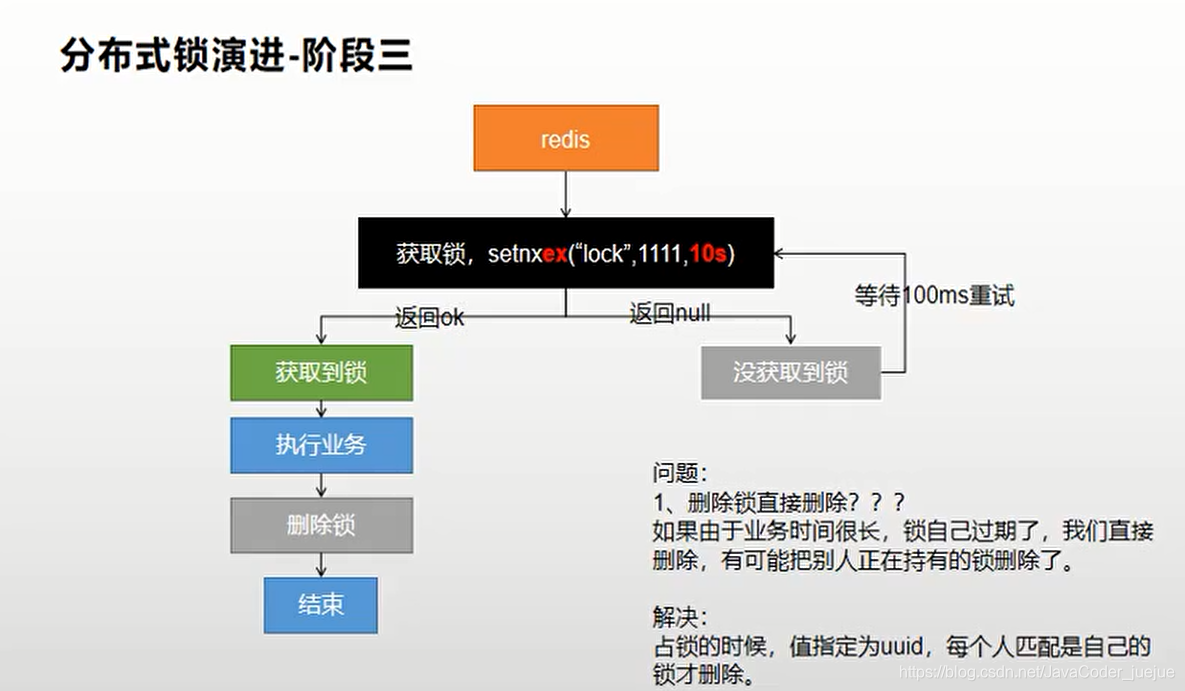
Código do núcleo, o valor é definido como uuid para facilitar a identificação do bloqueio de thread atual ao excluir
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() throws InterruptedException {
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "111",30,TimeUnit.SECONDS);
String uuid = UUID.randomUUID().toString();
if(lock){
Map<String, List<Catelog2Vo>> dataFromDb = getDataFromDb();
//删除锁 如果是当前线程的才删除 不然可能删的是线程的锁
String value = stringRedisTemplate.opsForValue().get("lock");
if(uuid.equals(value)){
stringRedisTemplate.delete("lock");
}
return dataFromDb;
}else{
Thread.sleep(100);
return getCatalogJsonFromDbWithRedisLock();
}
}Porém, ainda há um problema. Como a comparação entre a obtenção do valor e a exclusão do cache não é uma operação atômica, se houver uma falha de energia após a obtenção do valor e antes de excluir o cache, também fará com que o bloqueio de outros , o que equivale a não estar bloqueado.
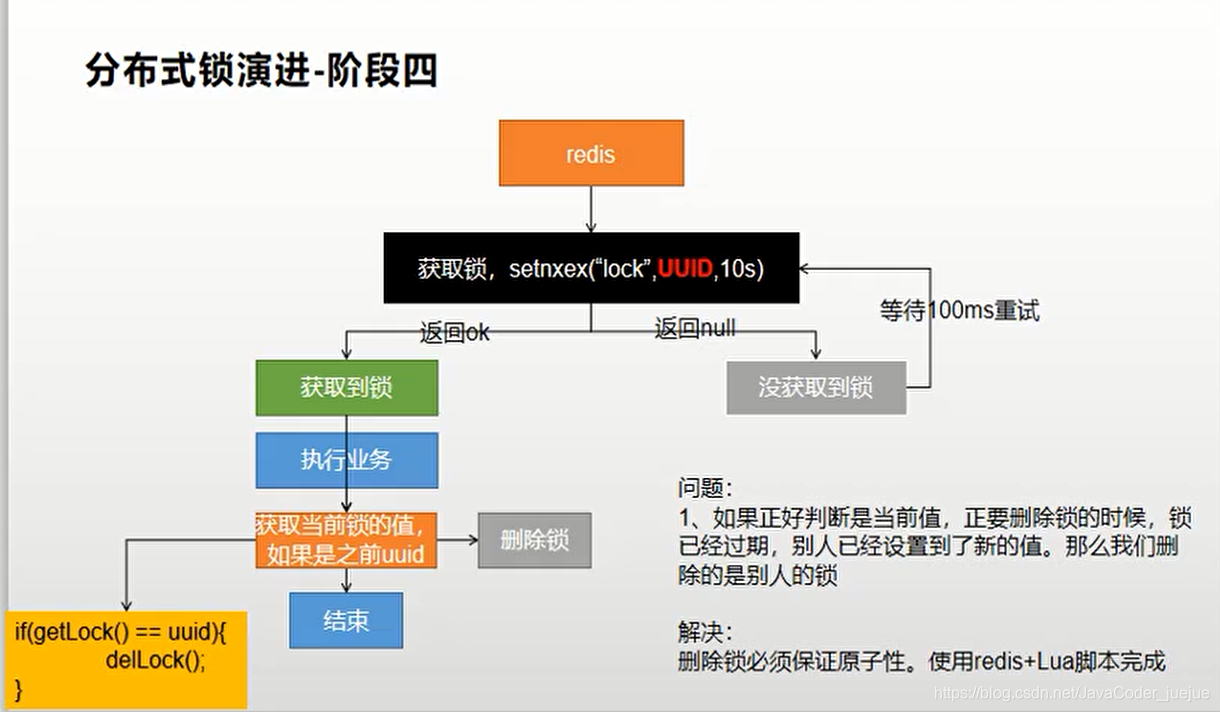
Portanto, o código é modificado novamente, usando o método de bloqueio de exclusão de script fornecido pelo redis para garantir a atomicidade
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() throws InterruptedException {
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "111",300,TimeUnit.SECONDS);
String uuid = UUID.randomUUID().toString();
if(lock){
Map<String, List<Catelog2Vo>> dataFromDb;
try {
dataFromDb = getDataFromDb();
}finally {
String script = "if redis.call(\"get\",KEYS[1]) == ARGV[1]\n" +
"then\n" +
" return redis.call(\"del\",KEYS[1])\n" +
"else\n" +
" return 0\n" +
"end";
//保证获取value对比与删除缓存是原子操作,这里采用redis提供的执行脚本方式
Long lock1 = stringRedisTemplate.execute(new DefaultRedisScript<Long>(), Arrays.asList("lock"), uuid);
}
return dataFromDb;
}else{
Thread.sleep(200);
return getCatalogJsonFromDbWithRedisLock();
}
}Neste momento, ele evoluiu para a forma final do estágio cinco
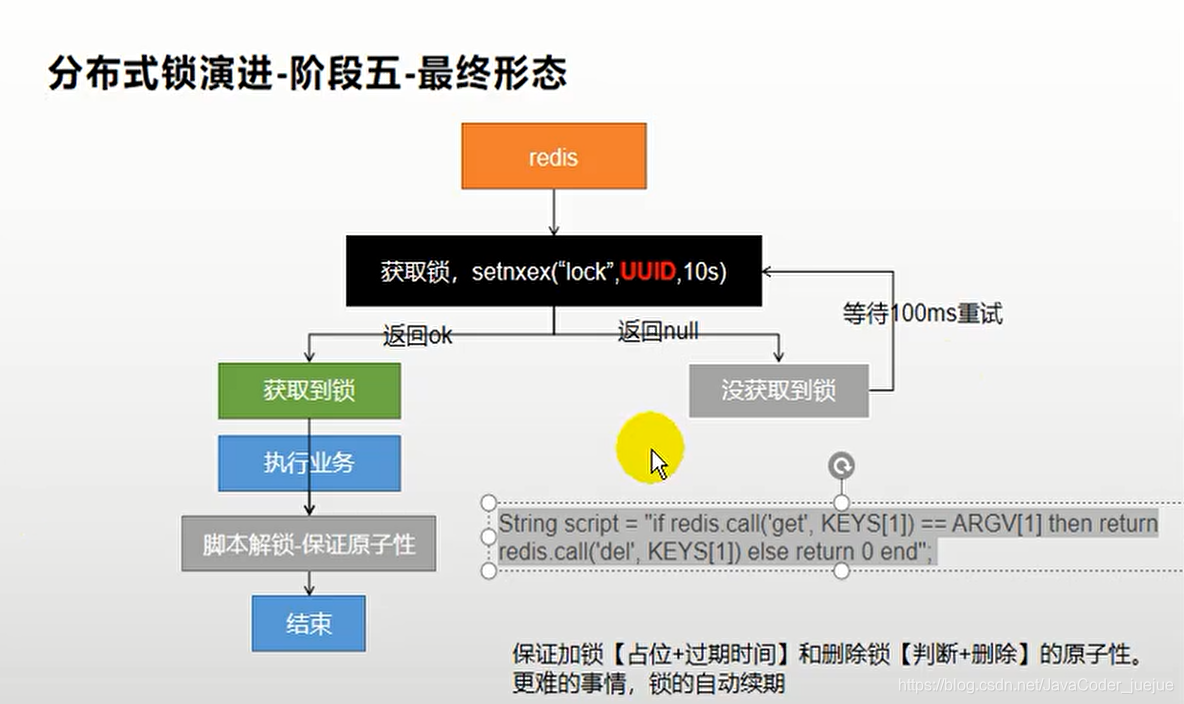
Até agora, o bloqueio distribuído foi basicamente implementado e melhorado. Não vou fazer o teste de estresse aqui. O resultado deve ser bem-sucedido.
Devido à repetitividade do código, ele pode ser encapsulado. Claro, outros já o fizeram. Posteriormente, aprenderemos sobre o framework mais profissional de bloqueios distribuídos - Redisson
Links de referência principais para este artigo:
http://www.redis.cn/commands/set.html