Este artigo foi compartilhado por Li Jinsong e Hu Zheng e organizado pelos voluntários da comunidade Yang Weihai e Li Peidian. Ele apresenta principalmente o esquema e o princípio de leitura e gravação em tempo real de dados CDC na arquitetura do data lake. O artigo está dividido principalmente em 4 partes:
- Soluções comuns de análise de CDC
- Por que escolher Flink + Iceberg
- Como escrever e ler em tempo real
- plano futuro
1. Programa de análise comum do CDC
Vamos primeiro dar uma olhada no que precisa ser projetado para o tópico de hoje. A entrada é um CDC ou dados de upsert e a saída é um banco de dados ou armazenamento para análise OLAP de big data.
Nossa entrada comum inclui principalmente dois tipos de dados. O primeiro dado são os dados do CDC do banco de dados, que geram continuamente o changeLog; o outro cenário são os dados de upsert gerados pela computação em fluxo. A versão mais recente do Flink 1.12 já suportou os dados de upsert.
1.1 Dados do CDC de análise de cluster HBase offline
A primeira solução que geralmente pensamos é processar os dados de upsert do CDC por meio do Flink e gravá-los no HBase em tempo real. O HBase é um banco de dados online que pode fornecer recursos de consulta online. Possui alto desempenho em tempo real, é muito amigável para operações de gravação, também pode suportar algumas consultas de pequena escala e o cluster é escalonável.
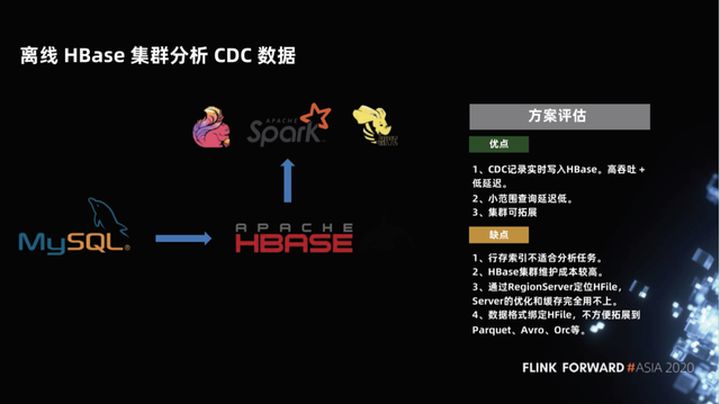
Esse tipo de esquema é na verdade o mesmo que o link em tempo real comum para verificação de pontos. Então, qual é o problema em usar o HBase para análise de consulta OLAP de big data?
Em primeiro lugar, o HBase é um banco de dados projetado para verificação de pontos e um serviço online.Seu índice armazenado em linha não é adequado para tarefas de análise. O design típico do data warehouse deve ser listado, de modo que a eficiência da compressão e da consulta sejam altas. Em segundo lugar, o custo de manutenção do cluster do HBase é relativamente alto. Por fim, os dados do HBase são HFile, o que é inconveniente para combinar com os típicos Parquet, Avro, Orc, etc. no big data warehouse.
1.2 Apache Kudu mantém conjunto de dados CDC
Em resposta aos recursos de análise relativamente fracos do HBase, um novo projeto apareceu na comunidade há alguns anos, que é o projeto Apache Kudu. Embora o projeto Kudu tenha a capacidade de verificação do HBase, ele também usa armazenamento de coluna, de modo que a aceleração de armazenamento de coluna é muito adequada para análise OLAP.
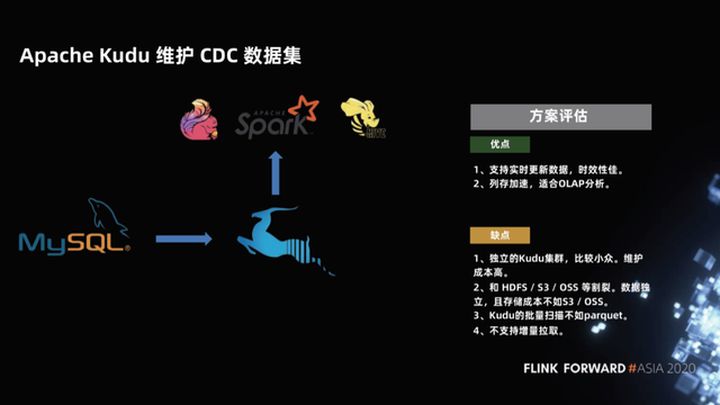
Quais são os problemas com este esquema?
Em primeiro lugar, o Kudu é um cluster relativamente pequeno e independente e seu custo de manutenção é relativamente alto, sendo mais fragmentado do HDFS, S3 e OSS. Em segundo lugar, como o Kudu mantém a capacidade de verificar seu design, seu desempenho de digitalização em lote não é tão bom quanto o parquet.Além disso, o suporte do Kudu para exclusão é relativamente fraco e, por fim, não oferece suporte à tração incremental.
1.3 Importe diretamente o CDC para a análise do Hive
A terceira solução, que também é comumente usada em data warehouses, é gravar dados MySQL no Hive. O processo é: manter uma partição completa, fazer uma partição incremental todos os dias e, finalmente, gravar a partição incremental. Depois disso, execute uma Mesclar e gravar uma nova partição. Isso funciona bem no processo. A partição completa antes do Hive não é afetada pelo incremento. Somente depois que a mesclagem incremental for bem-sucedida, a partição pode ser verificada e os dados são novos. Esse tipo de dado de anexo puramente listado é muito amigável para análise.
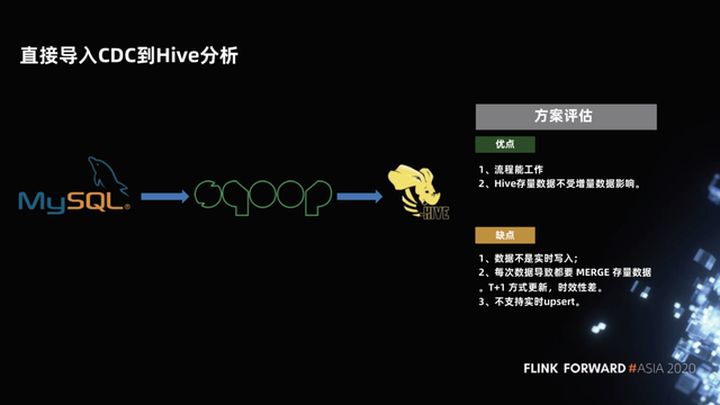
Quais são os problemas com este esquema?
A mesclagem de dados incrementais e dados completos tem um atraso e os dados não são gravados em tempo real. Normalmente, uma mesclagem é realizada uma vez por dia, o que é um dado T + 1. Portanto, a pontualidade é muito baixa e o upsert em tempo real não é compatível. Cada Merge precisa reler e reescrever todos os dados, o que é relativamente ineficiente e desperdiça recursos.
1.4 Dados do CDC de análise Spark + Delta
Em resposta a esse problema, o Spark + Delta fornece a sintaxe MERGE INTO ao analisar os dados do CDC. Isso não é apenas uma simplificação da sintaxe do data warehouse do Hive. Spark + Delta, como uma nova arquitetura de data lake (como Iceberg, Hudi), gerencia dados, não partições, mas arquivos. Portanto, Delta otimiza a sintaxe MERGE INTO e apenas verifica. Basta reescrever os arquivos alterados para que seja muito mais eficiente.
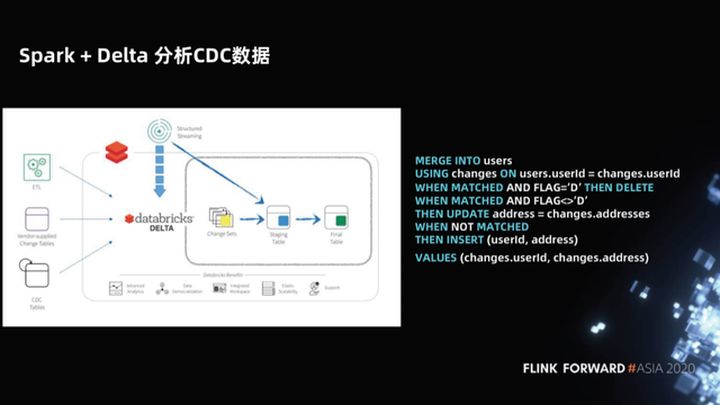
Vamos avaliar esta solução, suas vantagens são que ela conta apenas com Spark + Delta, a arquitetura é simples, não há serviço online, armazenamento de colunas e a velocidade de análise é muito rápida. A velocidade de sintaxe otimizada de MERGE INTO é rápida o suficiente.
Este programa é um programa Copy On Write para empresas, ele só precisa copiar um pequeno número de arquivos, o que pode tornar o atraso relativamente baixo. Teoricamente, se os dados atualizados não se sobrepõem ao estoque existente, o atraso no nível do dia pode ser obtido como um atraso no nível da hora e o desempenho pode ser mantido.
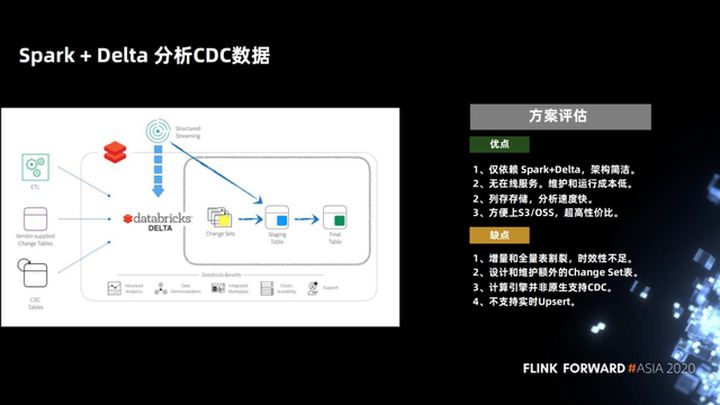
Esta solução deu um pequeno passo à frente na forma de processar dados upsert no warehouse do Hive. Mas o atraso de hora em hora não é tão eficaz quanto o tempo real, afinal, então a maior desvantagem dessa solução é que a mesclagem de cópia na gravação tem uma certa sobrecarga e o atraso não pode ser muito baixo.
Provavelmente, existem tantas soluções na primeira parte. Ao mesmo tempo, é necessário enfatizar que a razão pela qual o upsert é tão importante é que, na solução de data lake, o upsert é um ponto chave de tecnologia para realizar o quase-real - acesso ao banco de dados em tempo e tempo real para o lago.
2. Por que escolher Flink + Iceberg
2.1 Suporte do Flink para consumo de dados CDC
Primeiro, o Flink oferece suporte nativo ao consumo de dados do CDC. Na solução Spark + Delta anterior, a gramática de MARGE INTO, os usuários precisam perceber o conceito de atributos de CDC e, em seguida, escrever a gramática de mesclagem. Mas o Flink oferece suporte nativo aos dados do CDC. Os usuários precisam apenas declarar um Debezium ou outro formato de CDC, e o SQL no Flink não precisa perceber nenhum CDC ou atributos de upsert. O Flink possui uma coluna oculta incorporada para identificar seus dados de tipo CDC, portanto, é mais conciso para os usuários.
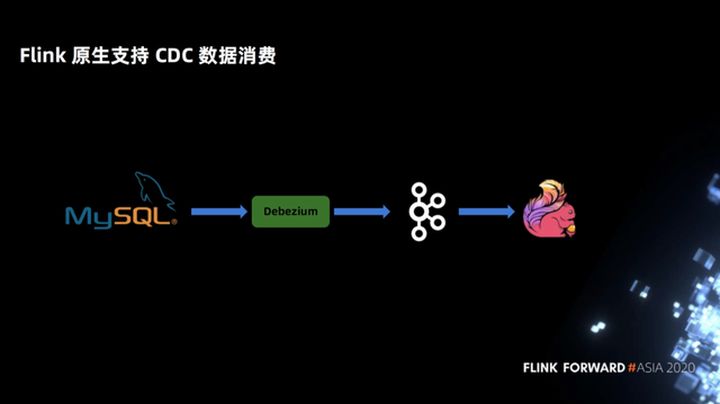
Como exemplo na figura a seguir, no processamento do CDC, Flink declara apenas uma instrução MySQL Binlog DDL e o select a seguir não precisa perceber o atributo CDC.

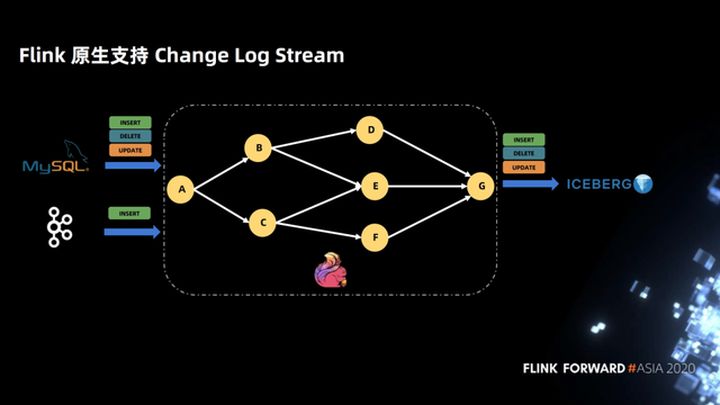
2.2 Suporte do Flink para Change Log Stream
A figura abaixo mostra que o Flink oferece suporte nativo ao Change Log Stream. Depois que o Flink é conectado a um Change Log Stream, a topologia não precisa se preocupar com o SQL do sinalizador do Change Log. A topologia é completamente definida de acordo com sua própria lógica de negócios e é gravada no Iceberg até o final, e não há necessidade de perceber o sinalizador de log de alterações.
2.3 Avaliação do plano de importação Flink + Iceberg CDC
Finalmente, quais são as vantagens da solução de importação de CDC da Flink + Iceberg?
Comparado com o esquema anterior, Copy On Write e Merge On Read têm cenários aplicáveis, com diferentes focos. Copiar na gravação é muito eficiente quando apenas uma parte dos arquivos precisa ser reescrita na cena de atualização de alguns arquivos. Os dados gerados são o conjunto completo de dados de acréscimo puro, que também é o mais rápido quando usado para análise de dados. a vantagem de Copy On Write.
O outro é Merge On Read, ou seja, os dados e a bandeira do CDC são anexados diretamente ao Iceberg. Durante a mesclagem, os dados incrementais são mesclados com a quantidade total dos dados anteriores em um determinado formato organizacional e um determinado método de cálculo eficiente . A vantagem disso é que ele suporta importação quase em tempo real e leitura de dados em tempo real; o Flink SQL desta solução de computação oferece suporte nativo para entrada de CDC e nenhum design de campo de negócios adicional é necessário.
Iceberg é um armazenamento unificado de data lake, oferece suporte a modelos de computação diversificados e também oferece suporte a vários mecanismos (incluindo Spark, Presto, hive) para análise; os arquivos gerados são puro armazenamento de coluna, que é muito rápido para análise posterior; Iceberg é um instantâneo- projeto baseado em data lake e suporta leitura incremental; a arquitetura Iceberg é simples o suficiente, sem nós de serviço online, formato de tabela puro, o que dá à plataforma upstream capacidade suficiente para personalizar sua própria lógica e serviço.

Três, como escrever e ler em tempo real
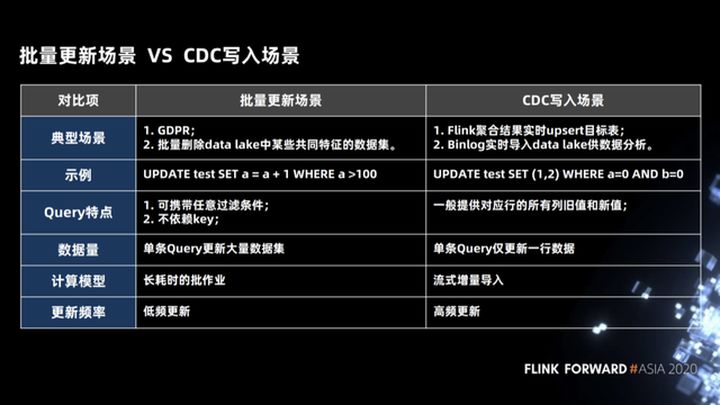
3.1 Cenas de atualização em lote e cenas de gravação de CDC
Primeiro, vamos dar uma olhada em dois cenários para atualizações em lote em todo o data lake.
- Este é o primeiro cenário de atualização em lote. Neste cenário, usamos um SQL para atualizar milhares de linhas de dados, como a política europeia GDPR. Quando um usuário faz logoff de sua conta, o sistema back-end deve alterar isso Todos os dados relacionados do usuário é excluído fisicamente.
- O segundo cenário é que precisamos excluir alguns dados com características comuns no lago de data. Este cenário também é um cenário de atualização em lote. Neste cenário, as condições de exclusão podem ser condições arbitrárias e não há chave primária (chave primária ). Independentemente de qualquer relação, ao mesmo tempo, o conjunto de dados a ser atualizado é muito grande. Este tipo de trabalho é um trabalho demorado e de baixa frequência.
O outro é o cenário escrito pelo CDC. Para Flink, há dois cenários comumente usados. O primeiro cenário é que o Binlog upstream pode ser gravado rapidamente no data lake e, em seguida, usado por diferentes mecanismos de análise para análise; o segundo cenário é para use o Flink para fazer algumas operações de agregação. O fluxo de saída é um fluxo de dados do tipo upsert e também precisa ser capaz de gravar no data lake ou no sistema downstream para análise em tempo real. Conforme mostrado no exemplo na figura a seguir, o CDC grava a instrução SQL na cena. Usamos um único SQL para atualizar uma linha de dados. Este modo de cálculo é uma importação incremental de streaming e uma atualização de alta frequência.
3.2 Problemas que o Apache Iceberg precisa considerar ao projetar uma solução de gravação de CDC
A seguir, vamos dar uma olhada nas questões que o iceberg precisa considerar ao projetar o cenário para a gravação do CDC.
- A primeira é a correção, ou seja, a correção da semântica e dos dados precisa ser garantida. Por exemplo, upstream upstream de dados para o iceberg. Quando o upstream upstream para, os dados no iceberg precisam ser consistentes com os dados no sistema upstream.
- A segunda é a gravação eficiente. Como a frequência de gravação do upsert é muito alta, precisamos manter um alto rendimento e uma alta gravação simultânea.
- O terceiro é a leitura rápida. Quando os dados são gravados, precisamos analisá-los. Isso envolve dois problemas. O primeiro problema é a necessidade de oferecer suporte à simultaneidade refinada. Quando o trabalho usa várias tarefas para ler, você pode garantir que cada tarefa é alocada de forma balanceada para acelerar o cálculo dos dados; o segundo problema é que devemos aproveitar ao máximo as vantagens do armazenamento colunar para acelerar a leitura.
- A quarta é oferecer suporte à leitura incremental, como ETL em alguns data warehouses tradicionais, por meio da leitura incremental para posterior conversão de dados.

3.3 Apache Iceberg Basic
Antes de introduzir os detalhes específicos do programa, vamos primeiro entender o layout do Iceberg no sistema de arquivos. De um modo geral, o Iceberg é dividido em duas partes de dados. A primeira parte é o arquivo de dados. O arquivo parquet na figura abaixo. Cada arquivo de dados corresponde a uma escola. Arquivo de verificação (arquivo .crc). A segunda parte é o arquivo de metadados da tabela (arquivo de metadados), incluindo arquivo de instantâneo (snap- .avro), arquivo de manifesto ( .avro), arquivo TableMetadata (* .json), etc.

A figura a seguir mostra a correspondência entre os arquivos de instantâneo, manifesto e partição no iceberg. A figura a seguir contém três partições: a primeira partição possui dois arquivos f1 e f3, a segunda partição possui dois arquivos f4 e f5 e a terceira partição possui um arquivo f2. Para cada gravação, é gerado um arquivo de manifesto, que registra a correspondência entre o arquivo gravado desta vez e a partição. Existe o conceito de instantâneo para o nível superior. O instantâneo pode ajudar a acessar rapidamente a quantidade total de dados de toda a tabela. O instantâneo registra vários manifestos. Por exemplo, o segundo instantâneo contém manifest2 e manifest3.

3.4 INSERT, UPDATE, DELETE write
Depois de compreender os conceitos básicos, a seguir apresentamos o projeto das operações de inserção, atualização e exclusão no iceberg.
A tabela mostrada no exemplo de SQL na figura abaixo contém dois campos, id e data, ambos do tipo int. Em uma transação, realizamos a operação de fluxo de dados mostrada na figura. Primeiro, um registro (1, 2) foi inserido e, em seguida, esse registro foi atualizado para (1, 3). No iceberg, a operação de atualização será dividida em delete E insira duas operações.
A razão para isso é que, considerando o iceberg como uma camada de armazenamento unificada para lotes de streaming, desmontar a operação de atualização em operações de exclusão e inserção pode garantir a unificação do caminho de leitura quando a cena de lote de streaming é atualizada. Por exemplo, no cenário de exclusão de lote , Hive é usado como Por exemplo, o Hive gravará o deslocamento do arquivo da linha a ser excluída no arquivo delta e, em seguida, fará uma mesclagem na leitura, porque isso será mais rápido. Quando a mesclagem for realizada, o arquivo original e o delta será mapeado através da posição, e será obtido rapidamente Todos, exceto os registros excluídos.
Em seguida, insira o registro (3, 5), apague o registro (1, 3), insira o registro (2, 5), a consulta final é que obtemos o registro (3, 5) (2, 5).
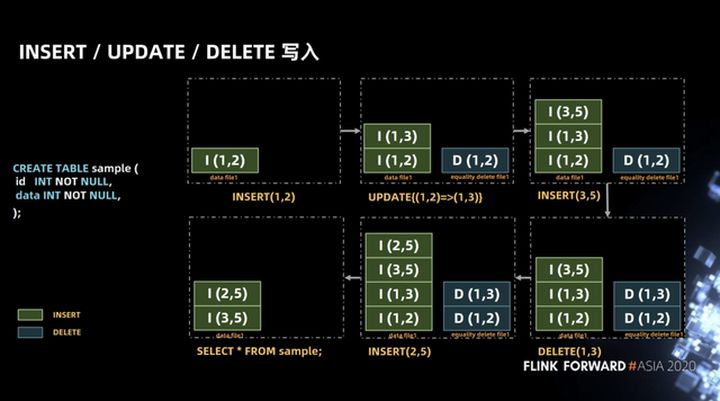
A operação acima parece muito simples, mas existem alguns problemas semânticos na implementação. Conforme mostrado na figura abaixo, em uma transação, a operação de inserção do registro (1, 2) é realizada primeiro. Esta operação irá gravar INSERT (1, 2) no arquivo de dados file1, e então realizar a operação de deleção do registro (1, 2). Esta operação gravará DELETE (1, 2) em igualdade, excluir arquivo1 e, em seguida, realizará a operação de inserção de registro (1, 2), que gravará INSERT (1, 2) no arquivo de dados arquivo1, e, em seguida, execute a operação de consulta.
Em circunstâncias normais, o resultado da consulta deve retornar o registro INSERT (1, 2), mas na implementação, a operação DELETE (1, 2) não pode saber qual linha no arquivo de dados file1 é excluída, então as duas linhas de INSERT (1 , 2)) Todos os registros serão excluídos.

Então, como resolver esse problema, a maneira atual na comunidade é adotar a posição Mixed-delete e a igualdade-delete. Exclusão por igualdade é para excluir especificando uma ou mais colunas, e exclusão de posição é para excluir com base no caminho do arquivo e número da linha. Os dois métodos são combinados para garantir a exatidão da operação de exclusão.
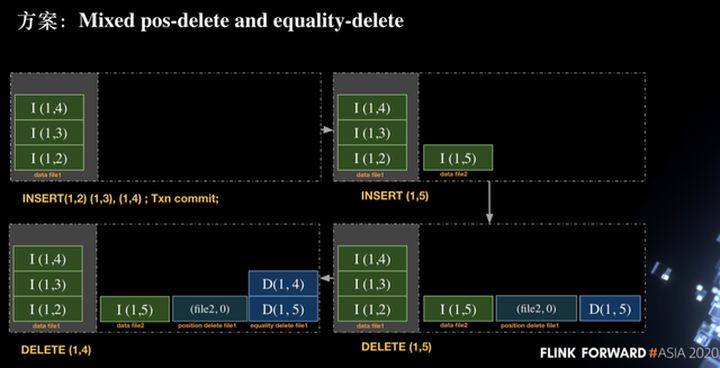
Conforme mostrado na figura abaixo, inserimos três linhas de registros na primeira transação, a saber, INSERT (1, 2), INSERT (1, 3), INSERT (1, 4) e, em seguida, executamos a operação de confirmação para enviar. Em seguida, iniciamos uma nova transação e executamos a inserção de uma linha de dados (1, 5). Por se tratar de uma nova transação, criamos um novo arquivo de dados2 e gravamos o registro INSERT (1, 5) e, em seguida, executamos o registro de exclusão (1, 5) Ao realmente escrever delete, é:
Grave (file2, 0) na posição delete file1 file, que significa deletar o registro da linha 0 no data file 2. Isso resolverá o problema semântico da repetição da inserção e deleção da mesma linha de dados na mesma transação.
Grave DELETE (1,5) no arquivo de exclusão de igualdade file 1. A razão para escrever esta exclusão é garantir que o (1,5) escrito antes deste txn possa ser excluído corretamente.
Em seguida, execute a operação de exclusão (1, 4). Como (1, 4) não foi inserido na transação atual, esta operação usará a operação de exclusão de igualdade, ou seja, escrever o registro (1, 4) na igualdade delete file1. No processo acima, pode ser visto que existem três tipos de arquivos: arquivo de dados, arquivo de exclusão de posição e arquivo de exclusão de igualdade na solução atual.
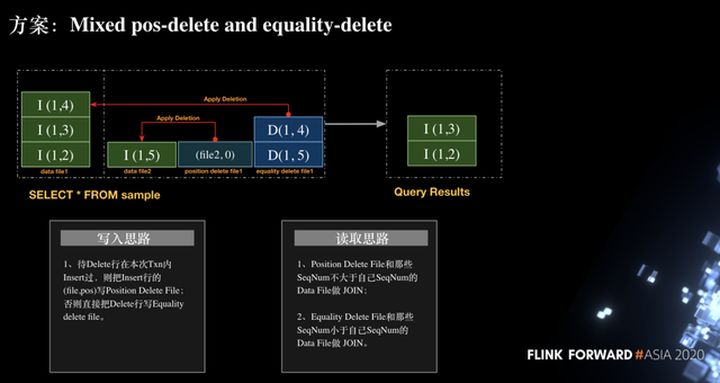
Depois de entender o processo de escrita, como ler. Conforme mostrado na figura abaixo, para o registro (arquivo2, 0) no arquivo de exclusão de posição, apenas o arquivo de dados da transação atual precisa ser unido, e o registro do arquivo de exclusão de igualdade (1, 4) e os dados arquivo da transação anterior são unidos. Por fim, os registros INSERT (1, 3) e INSERT (1, 2) são obtidos para garantir a correção do processo.
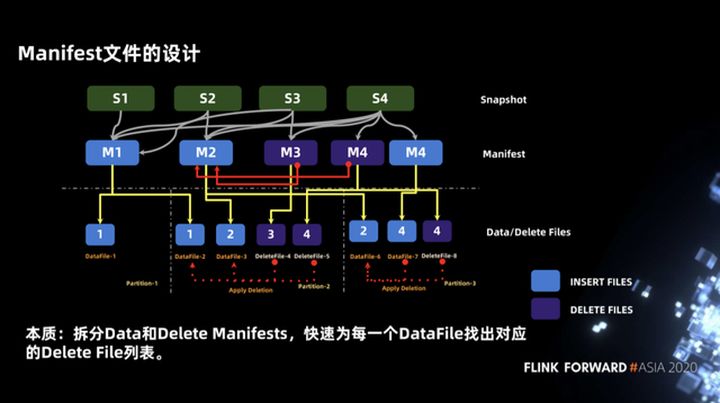
3.5 Design do arquivo de manifesto
A inserção, atualização e exclusão são apresentadas acima, mas ao desenhar o plano de execução da tarefa, desenhamos alguns manifestos. O objetivo é encontrar rapidamente o arquivo de dados através do manifesto e dividi-lo de acordo com o tamanho dos dados para garantir os dados processados por cada tarefa Distribua tão uniformemente quanto possível.
O exemplo mostrado na figura abaixo contém quatro transações. As primeiras duas transações são operações INSERT, correspondendo a M1 e M2, a terceira transação é uma operação DELETE, correspondendo a M3, e a quarta transação é uma operação UPDATE, incluindo dois arquivos de manifesto, ou seja, manifesto de dados e manifesto de exclusão.
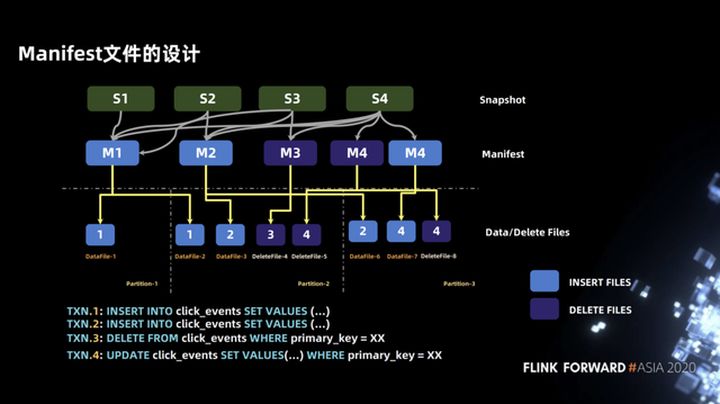
Quanto ao motivo pelo qual o arquivo de manifesto é dividido em manifesto de dados e manifesto de exclusão, é essencialmente para encontrar rapidamente a lista de arquivos de exclusão correspondente para cada arquivo de dados. Você pode ver o exemplo na figura abaixo. Quando lemos na partição-2, precisamos realizar uma operação de junção entre deletefile-4 e datafile-2 e datafile-3, e também precisamos combinar deletefile-5 com datafile- 2 e arquivo de dados 3. Faça uma operação de junção.
Tome datafile-3 como exemplo. A lista deletefile contém dois arquivos, deletefile-4 e deletefile-5. Como encontrar rapidamente a lista deletefile correspondente? Podemos consultar de acordo com o manifesto de nível superior. Quando dividimos o arquivo de manifesto em manifesto de dados Depois que o manifesto de exclusão e M2 (manifesto de dados) podem ser unidos com M3 e M4 (manifesto de exclusão) primeiro, a lista de arquivos de exclusão correspondente ao arquivo de dados pode ser obtida rapidamente.
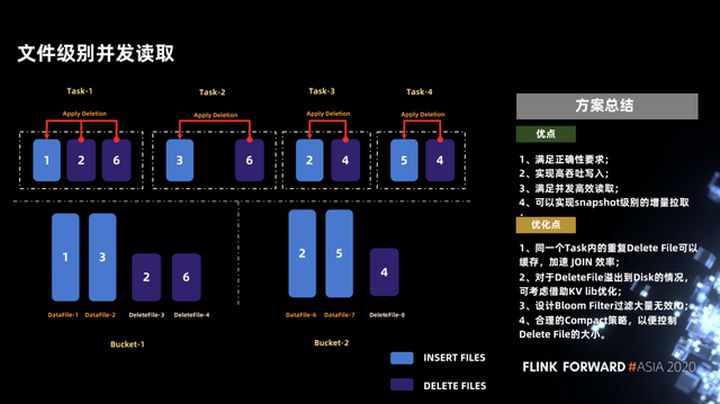
3.6 Simultaneidade em nível de arquivo
Outro problema é que precisamos garantir leituras simultâneas altas o suficiente, o que é feito muito bem no iceberg. A leitura simultânea em nível de arquivo pode ser obtida no iceberg, e uma leitura simultânea ainda mais refinada de segmentos em um arquivo. Por exemplo, um arquivo com 256 MB pode ser dividido em dois 128 MB para leitura simultânea. Aqui está um exemplo: Suponha que o arquivo de inserção e o arquivo de exclusão estejam dispostos em dois depósitos, conforme mostrado na figura abaixo.

Por meio da comparação do manifesto, descobrimos que a lista de exclusão de arquivos do datafile-2 possui apenas deletefile-4, de forma que esses dois arquivos podem ser executados como uma única tarefa (Tarefa-2 na figura), e outros arquivos são semelhantes , para que seja garantido Os dados de cada tarefa são mesclados de forma equilibrada.

Fizemos um breve resumo desse esquema, conforme mostrado na figura abaixo. Em primeiro lugar, as vantagens deste esquema podem atender à exatidão e podem alcançar uma escrita de alto rendimento e uma leitura simultânea e eficiente.Além disso, ele pode alcançar uma extração incremental no nível do instantâneo.
O esquema atual ainda é relativamente difícil e existem alguns pontos que podem ser otimizados a seguir.
- O primeiro ponto é que se o arquivo de exclusão na mesma tarefa for duplicado, ele pode ser armazenado em cache, o que pode melhorar a eficiência da junção.
- O segundo ponto é que kv lib pode ser usado para otimização quando o arquivo de exclusão é relativamente grande e precisa ser sobrescrito no disco, mas não depende de serviços externos ou outros índices pesados.
- Terceiro, você pode projetar um filtro Bloom para filtrar IO inválido, porque a operação upsert comumente usada no Flink gerará uma operação de exclusão e uma operação de inserção, o que levará ao tamanho do arquivo de dados e excluirá o arquivo no iceberg. A diferença não é muito, então a eficiência da junção não será muito alta. Se o filtro Bloom for usado, quando os dados de upsert chegarem, eles serão divididos em operações de inserção e exclusão. Se o filtro Bloom filtrar as operações de exclusão que não inseriram dados anteriormente (ou seja, se esses dados não foram inseridos antes, você deve não é necessário excluir Os registros são gravados no arquivo de exclusão), o que melhorará muito a eficiência do upsert.
- O quarto ponto é que algumas estratégias de compactação em segundo plano são necessárias para controlar o tamanho do arquivo excluído. Quando o arquivo excluído é menor, a eficiência da análise é maior. Obviamente, essas estratégias não afetarão a leitura e a gravação normais.
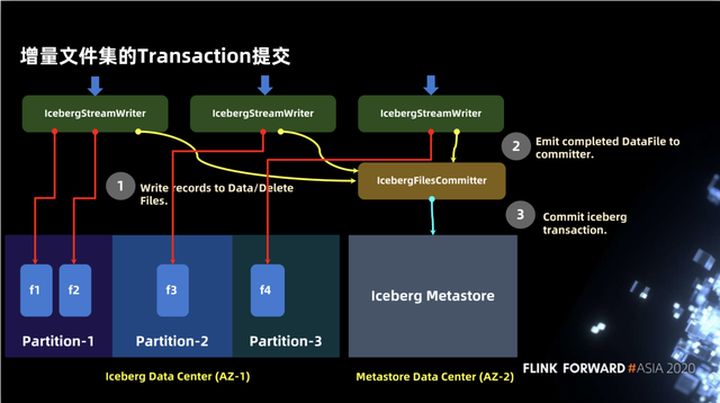
3.7 Envio da transação do conjunto de arquivos incremental
Na seção anterior, apresentamos a escrita de arquivos e, na figura a seguir, apresentamos como escrever de acordo com a semântica do iceberg e disponibilizá-la aos usuários. É principalmente dividido em duas partes: dados e metastore. Primeiro, haverá IcebergStreamWriter para gravar dados, mas neste momento as informações de metadados dos dados gravados não são gravadas no metastore, portanto, não são visíveis para o mundo exterior. O segundo operador é IcebergFileCommitter, que coleta arquivos de dados e, finalmente, conclui a gravação por meio da transação de confirmação.
Não há nenhuma outra dependência de serviço de terceiros no Iceberg, e Hudi fez alguma abstração de serviço em alguns aspectos, como abstrair metastore em uma Timeline independente, que pode contar com alguns índices independentes ou até mesmo outros serviços externos a serem feitos.
Quatro, planejamento futuro
A seguir estão alguns de nossos planos futuros: O primeiro são algumas otimizações do kernel do Iceberg, incluindo o teste de estabilidade de link completo e otimização de desempenho envolvidos no plano, e fornece algumas interfaces de API de tabela relacionadas para pull incremental do CDC.
Na integração do Flink, a capacidade de mesclar arquivos de dados de CDC automática e manualmente será realizada e fornecerá a capacidade do Flink de extrair dados CDC de forma incremental.
Em outra integração ecológica, iremos integrar Spark, Presto e outros motores, e usar o Alluxio para acelerar a consulta de dados.

Este artigo é o conteúdo original do Alibaba Cloud e não pode ser reproduzido sem permissão.