Jingdong Mathematics (11h, 13 de janeiro de 2021)
O entrevistador foi muito bom, todo o processo foi paciente e me ouviu e analisou comigo.Foi uma experiência de entrevista muito gratificante.
Tempo total da entrevista: 43 minutos
-
Auto apresentação
(Eu não falei sobre o projeto ... talvez seja muito simples olhar para a pilha de tecnologia)
-
Basta perguntar o que você sabe sobre JVM?
Resposta: não entendo
-
Uma pergunta sobre TCP / IP
Resposta: Não (não ouvi claramente e não me preparei para este, então apenas disse não)
De acordo com o currículo, escrevi familiaridade com multithreading e perguntei ...
-
Você aprendeu sobre o CAS?
Resposta: √
CAS (Compare-and-Swap), ou seja, compare e substitua, é uma tecnologia comumente usada na implementação de algoritmos concorrentes.Muitas classes em pacotes simultâneos Java usam a tecnologia CAS.
As operações CAS precisam contar com os métodos da classe Unsafe. Todos os métodos da classe Unsafe são modificados nativamente e todos os métodos chamam diretamente os recursos subjacentes do sistema operacional para realizar tarefas. O CAS é uma primitiva de simultaneidade da CPU e, no sistema operacional, a execução da primitiva deve ser contínua e nenhuma interrupção é permitida durante a execução, o que significa que o CAS é uma instrução atômica.
O CAS precisa ter 3 operandos: endereço de memória V, antigo valor esperado A e valor alvo B a ser atualizado.
Quando a instrução CAS é executada, se e somente se o valor do endereço de memória V for igual ao valor esperado A, o valor do endereço de memória V é modificado para B, caso contrário, ele não faz nada. Toda a comparação e operação de substituição é uma operação atômica.
-
Quais são as desvantagens do CAS?
Resposta: √ Eu disse três
1. Loop infinito afeta o desempenho
2. Garanta apenas a atomicidade de uma variável compartilhada
3. Problema ABA
-
Você pode me falar sobre o problema ABA?
Resposta: √ Há uma breve descrição, mas também dou um exemplo para ilustrar.
O processo CAS é geralmente o seguinte:
- Leia primeiro A a partir do endereço V
- Calcule o valor alvo B de acordo com A
- Altere o valor do endereço V de A para B de maneira atômica por meio de CAS
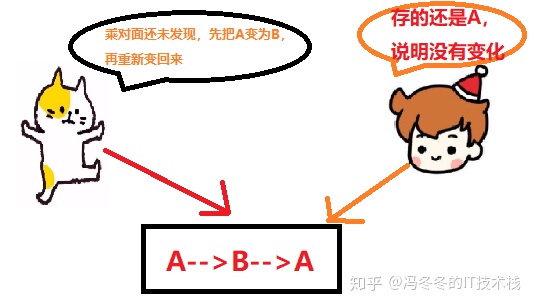
O valor lido na etapa 1 é A e a modificação foi bem-sucedida na etapa 3. Podemos dizer que seu valor não foi alterado por outros threads entre as etapas 1 e 3?
Se seu valor foi alterado para B durante este período e, em seguida, alterado novamente para A, a operação CAS acreditará erroneamente que ele nunca foi alterado. Essa vulnerabilidade é chamada de problema "ABA" das operações CAS.
-
Como resolver o problema ABA?
Resposta: √
Para resolver esse problema, o Java Concurrent Package fornece uma classe de referência atômica marcada "AtomicStampedReference", que pode garantir a correção do CAS controlando a versão do valor da variável. Portanto, antes de usar o CAS, você deve considerar se o problema "ABA" afetará a exatidão da simultaneidade do programa. Se você precisar resolver o problema ABA, mudar para a sincronização mutuamente exclusiva tradicional pode ser mais eficiente do que as classes atômicas.
-
Então você usa a referência atômica AtmoicRefence para explicar o exemplo agora. Como resolver isso?
Resposta: Meio √, acho que não respondi. Mais tarde, pensei sobre isso. Deveria ser que eu quisesse me atrair para isso e isso não poderia resolver completamente o problema ABA. A solução final foi usar AtomicStampRefence para apresentar o mecanismo de número de versão (sou um idiota ...)
No pacote de simultaneidade java.util.concurrent.atomic no JDK, é fornecido AtomicStampedReference . Ao estabelecer um número de versão semelhante ao Stamp para a referência, ele pode resolver o problema ABA no mecanismo CAS.
Leia o código-fonte! ! !
Em primeiro lugar, existem quatro parâmetros na função compareAndSet de AtomicStampedReference. Observe o código-fonte:
compareAndSet(V expectedReference, V newReference, int expectedStamp, int newStamp)- EsperadaReferência: indica o valor esperado
- newReference: o valor a ser atualizado
- carimbo esperado: carimbo de data / hora esperado
- newStamp: carimbo de data / hora atualizado
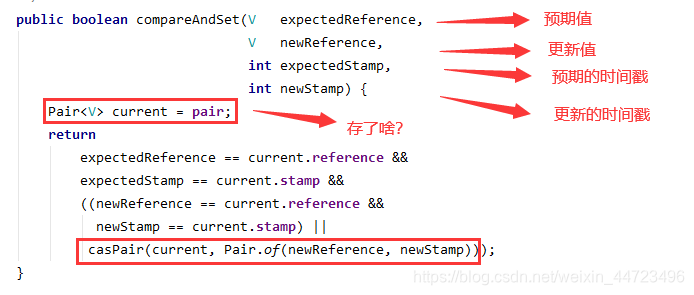
Aqui, descobriremos que apenas a referência de valor e o carimbo de data e hora são armazenados no Par. A 
chave está no método casPair, que consiste principalmente em usar o mecanismo CAS para atualizar a nova referência de valor e o carimbo de data e hora.

9. Então eu digo que o CAS depende do método da classe Unsafe.A camada inferior é implementada em C ++. Você pode me dizer como implementá-la em C ++?
答 : O que ?? C ++ ?? Vejo você
A classe de pacote inseguro é sun.misc.Unsafe
-
Você conhece o pool de threads em multithreading?
Resposta: Depois de algumas palavras simples, ele não me deixou envergonhado ...
Não há resposta aqui, sugiro entender estas questões:
- O que é pool de threads
- Por que existe um pool de threads? Qual é o objetivo principal de resolver o problema e os benefícios do pool de threads?
- Olhe para o código fonte
- Otimização do pool de threads
- Como criar um pool de threads?
…
-
Você conhece palavras-chave voláteis?
Resposta: √ (Olhando para a entrevista, descobri que os entrevistadores da JD Mathematics sempre perguntam isso, então eu revisei cuidadosamente na noite passada)
Volatile é um mecanismo de sincronização leve fornecido pela máquina virtual Java. As variáveis definidas por Volatile são lidas da memória principal toda vez que o sistema o usa, em vez da memória de trabalho de cada encadeamento. Possui três características:
-
Visibilidade da memória
-
Sem garantia de atomicidade
-
Proibir reorganização de ordem
- Visibilidade da memória
A operação de cada thread na variável compartilhada na memória principal é a operação de cada thread copiando para sua própria memória de trabalho e depois gravando de volta na memória principal
- Sem garantia de atomicidade
Indivisível, completo, ou seja, quando um thread está fazendo um negócio específico, o tempo não pode ser bloqueado ou dividido. Precisa ser completo como um todo para ter sucesso ou falhar ao mesmo tempo
Por exemplo: crie 20 threads, cada thread i ++ 1000 operações causará problemas (como resolver? 1. Adicionar sincronizado 2. Use o método AtmoicInteger.getincrement () da classe atômica)
- Proibição de reorganização da ordem ("ordem")
Em um ambiente multi-threaded, os threads são executados alternadamente. Devido ao reordenamento da otimização pelo compilador, é impossível determinar se as variáveis utilizadas pelos dois threads podem ser consistentes, e o resultado é imprevisível.
-
-
Fale sobre a "visibilidade da memória" em seus recursos?
Resposta: √ Ei, eu fiz muitas pesquisas. De acordo com meu próprio entendimento, posso dizer isso facilmente
Quando uma variável é modificada por volatile, a modificação nela será imediatamente liberada para a memória principal.Quando outros threads precisam ler a variável, eles irão para a memória para ler o novo valor. As variáveis comuns não podem garantir isso.
Sugestão: Quando o entrevistador lhe fizer esta pergunta, você deve responder da seguinte forma: Fale-me sobre o modelo de memória Java, porque sua existência leva à existência de problemas de visibilidade, introduzindo assim a visibilidade do Volatile!
-
Você pode me dizer como isso é implementado no nível inferior?
Resposta: Uh ... eu não sei ... Olhe o que eu disse suavemente e comece a me foder
Anteriormente, dissemos que quando as tarefas de computação de vários processadores envolvem a mesma área de memória principal, isso pode levar a inconsistências em seus respectivos dados de cache.Um exemplo é o compartilhamento de variáveis entre várias CPUs.
Se isso acontecer, quais dados em cache prevalecerão ao sincronizar de volta para a memória principal?
Para resolver o problema de consistência, cada processador precisa seguir alguns protocolos ao acessar o cache e operar de acordo com o protocolo ao ler e escrever, como MSI
MESI(IllinoisProtocol),, MOSI, Synapse, Firefly e DragonProtocol.MESI (Protocolo de Coerência de Cache)
Quando a CPU grava dados, se a variável operacional for uma variável compartilhada, ou seja, existe uma cópia da variável em outras CPUs, ela enviará um sinal para notificar outras CPUs para invalidar a linha de cache da variável, então quando outras CPUs precisam ler Quando você busca esta variável, se você descobrir que a linha de cache que armazena a variável em seu cache é inválida, então ele a lerá da memória novamente.
Sobre como descobrir se os dados são inválidos?
Farejar
Cada processador verifica se o valor de seu cache expirou ao farejar a disseminação de dados no barramento. Quando o processador descobrir que o endereço de memória correspondente à sua linha de cache foi modificado, ele definirá a linha de cache do processador atual como inválida. Estado , quando o processador modificar esses dados, ele lerá os dados da memória do sistema para o cache do processador novamente.
Tempestade de ônibus
Como o protocolo de coerência de cache MESI do Volatile requer um sniffing contínuo da memória principal e um loop contínuo de cas, a interação inválida fará com que a largura de banda do barramento atinja seu pico.
Portanto, não use Volátil em grandes quantidades, quanto a quando usar Volátil e quando usar fechaduras, diferencie de acordo com a cena.
-
O AQS entende?
Resposta: Apenas algumas palavras (meu progresso não está aqui ainda ...)
-
A diferença entre thread e processo?
Resposta: √
- Processo é a unidade básica de alocação de recursos; thread é a unidade básica de execução do programa.
- Um processo tem seu próprio espaço de recursos. Cada vez que um processo é iniciado, o sistema aloca um espaço de endereço para ele; os threads não têm nada a ver com a alocação de recursos da CPU. Vários threads compartilham os recursos no mesmo processo e os usam espaço de endereço.
- Um processo pode conter vários threads
-
Como se comunicar entre processos? (Eu quero que você se orgulhe ... veja se você consegue)
Resposta: Eu disse IPC, só vi acidentalmente e esqueci
A comunicação entre processos (IPC, comunicação entre processos) é um conjunto de interfaces de programação,
Permite que os programadores coordenem diferentes processos para que possam ser executados simultaneamente em um sistema operacional e transferir e trocar informações entre si.
Os métodos IPC incluem tubos (PIPE), filas de mensagens, sinais, memória compartilhada e soquetes.
Você é um estranho multi-threaded? Não aguento mais
-
Você sabe sobre bloqueios reentrantes? É a fechadura reentrante no JUC
Resposta: em ... Eu não sei se isso significa sincronizado e ReetrentLock bloqueia
https://blog.csdn.net/w8y56f/article/details/89554060
-
Fale-me sobre ReetrentLock
Resposta: √ Quase tudo dito, e uma comparação simples com o sincronizado
https://zhuanlan.zhihu.com/p/65727594
-
Conte-me sobre sua compreensão de bloqueios justos e bloqueios injustos
Resposta: √
simplesmente diga:
- Bloqueio justo: garanta justiça absoluta, os fios vêm primeiro, vêm primeiro
- Bloqueio injusto: muito injusto, você pode pular na fila
O padrão diz:
Bloqueio justo: vários threads adquirem bloqueios na ordem em que se aplicam aos bloqueios. Os threads entrarão diretamente na fila para fazer fila e serão sempre os primeiros na fila a obter o bloqueio.
- Vantagens: Todos os threads podem obter recursos e não morrerão de fome na fila.
- Desvantagens: a taxa de transferência cairá muito, exceto para o primeiro encadeamento na fila, outros encadeamentos serão bloqueados e a sobrecarga da cpu ativando os encadeamentos bloqueados será muito grande.
Bloqueio injusto: quando vários threads adquirem um bloqueio, eles tentarão adquiri-lo diretamente. Se não puderem adquiri-lo, entrarão na fila de espera. Se conseguirem obter o bloqueio, eles o adquirirão diretamente.
- Vantagens: Pode reduzir a sobrecarga da CPU que ativa os threads, e a eficiência geral do throughput será maior. A CPU não precisa despertar todos os threads, o que reduzirá o número de threads a serem chamados.
- Desvantagens: você também pode ter descoberto que isso pode fazer com que o encadeamento no meio da fila não consiga adquirir o bloqueio ou adquiri-lo por um longo tempo, resultando em inanição.
-
Qual você acha que é mais eficiente? porque?
Resposta: Acho que deve estar errado. Ele analisou comigo por muito tempo
Os bloqueios justos precisam manter uma fila e os threads subsequentes precisam ser bloqueados. Mesmo se o bloqueio estiver livre, primeiro verifique se há outros threads em espera. Se houver algum que precise ser suspenso, adicione-o ao final da fila, e, em seguida, desperte o thread da frente da fila. Neste caso, em comparação com o bloqueio injusto, há mais um suspender e despertar
A sobrecarga da troca de thread é na verdade a razão pela qual bloqueios injustos são mais eficientes do que bloqueios justos, porque bloqueios injustos reduzem a probabilidade de suspensão de thread e threads subsequentes têm uma certa chance de escapar da sobrecarga suspensa.
Ok, acho que você pode ter uma compreensão mais profunda da simultaneidade multi-threaded ...
-
Vamos falar sobre coleções, você conhece HashMap?
Resposta: √ (Vamos lá, vou me mexer, comi muito bem desde a última vez que li o byte)
HashMap usa matrizes Entry para armazenar valores-chave. Cada par de valores-chave forma uma entidade Entry (jdk1.7, jdk1.8 alterado para Node). A classe Entry é, na verdade, uma estrutura de lista vinculada unilateral, que tem um próximo ponteiro ., Você pode se conectar à próxima entidade de entrada. No JDK 1.8, quando o comprimento da lista vinculada é maior que 8, a lista vinculada será convertida em uma árvore vermelho-preto!
-
Conte-me sobre todo o processo de seu método put, certo?
Resposta: √
- Chame a função hash do objeto para obter o valor hash correspondente à chave e, a seguir, calcule o subscrito da matriz;
- Se não houver conflito de hash, coloque-o diretamente na matriz
- Se houver um conflito de hash, coloque-o atrás da lista vinculada na forma de uma lista vinculada
-
Se o comprimento da lista vinculada exceder o limite (TREEIFY THRESHOLD == 8), a lista vinculada é convertida em uma árvore vermelho-preto. Quando o comprimento da lista vinculada é menor que 6, volte a árvore vermelho-preto para a lista vinculada;
-
Se a chave do nó já existir, substitua o valor do valor;
-
Se o número de pares de valores-chave na coleção for maior que 12, chame o método resize para expandir a matriz
De acordo com o código-fonte que você leu e seu próprio entendimento, basta dizê-lo passo a passo.
-
Como isso se expande? Vamos falar sobre o mecanismo de expansão
Resposta: √
Capacidade padrão = 16, fator de carga = 0,75f
Depois de atingir o limite = capacidade * fator de carga, ele é expandido para 2 vezes.
Depois de refazer o hash, recalcule o subscrito. Dependendo de os resultados antes e depois da repetição serem os mesmos, ela é dividida em lista vinculada baixa e lista vinculada alta para repetição
-
Como o código específico é implementado?
Resposta: √
Execute uma operação de bit no tamanho original e desloque um bit para a esquerda
-
Por que você diz que o tamanho da expansão deve ser uma potência de 2?
Resposta: √ Como a operação AND é usada, a eficiência do cálculo do valor de hash é melhorada
Porque o algoritmo de HashMap para encontrar a posição do balde correspondente usa a operação AND em vez da operação tradicional de módulo
A premissa de hash% length == hash & (length-1) é que o comprimento é uma potência de 2.
-
Você disse que se o comprimento da lista vinculada chegar a 8, ela será convertida em uma árvore vermelho-preta. Por que é 8?
Resposta: √ Eu disse a partir de muitos aspectos, a distribuição de Poisson da teoria da probabilidade e desempenho de pesquisa. Deve estar certo ... porque não diz nada
- De acordo com a distribuição de Poisson, quando o fator de carga é 0,75, a probabilidade de que o número de elementos em um único slot de hash seja 8 é menor que um em um milhão
- Quando o comprimento é 8, em vez de garantir a sobrecarga de pesquisa da estrutura da lista vinculada, é melhor converter para uma árvore vermelho-preto e manter seu equilíbrio geral.
-
Qual é a complexidade do tempo de pesquisa da árvore vermelho-preto?
Resposta: √
O (logN)
em ... este entende muito bem, então eu não vou te perguntar
O que eu pensei em meu coração, não ... Você não gosta de perguntar sobre multithreading? Não fale sobre a segurança de thread do HashMap?
-
(Em seguida, vou olhar para o algoritmo novamente e começar a brincar comigo) Você entende os problemas clássicos de TopK? Como você resolve isso?
Resposta: Meio √, deveria estar bem aqui, sou autista ... respondi pilha mínima, seleção rápida, hash
-
Hash falar sobre o processo
Resposta: Eu dei um exemplo e falei sobre o processo (não sei, certo?)
-
Em seguida, analise a complexidade de tempo do seu hash
Resposta: Estou morto ... Não entendi o processo agora, ele entendeu?
Questão retórica
-
Qual departamento? Qual é o número de ciência e tecnologia em Taiwan
-
Você pode me dar um breve comentário sobre a avaliação da minha entrevista? Ou no que devo prestar atenção no futuro?
Resposta: Você precisa aprender um pouco mais sobre a simultaneidade multithread (como pool de threads, AQS, etc.) e é recomendável se preparar bem para o algoritmo.
Minha própria sensação: o frio deve ser frio. Mas como dizer, respondendo a algumas perguntas, sinto que a preparação diária durante este período também é gratificante, pelo menos saberei quais aspectos precisam de um estudo e pesquisa mais aprofundados. Afinal, o tempo de preparação realmente não é longo (formalmente e seriamente preparado no dia 1.9, apenas ... no quarto dia). Continue trabalhando duro! ! !
-