Como um desenvolvimento de serviço em segundo plano, estamos lidando com o banco de dados todos os dias em nosso trabalho diário.Temos realizado várias operações CRUD e usaremos o pool de conexão do banco de dados. De acordo com o histórico de desenvolvimento, existem os seguintes tipos de pools de conexão de banco de dados bem conhecidos na indústria: c3p0, DBCP, Tomcat JDBC Connection Pool, Druid, etc., mas o mais popular é o HiKariCP recentemente.
HiKariCP é conhecido como o pool de conexão de banco de dados mais rápido do mercado. Desde que o SpringBoot 2.0 o adotou como o pool de conexão de banco de dados padrão, seu ímpeto de desenvolvimento tem sido imparável. Por que é tão rápido? Hoje vamos nos concentrar nas razões.
Um, o que é um pool de conexão de banco de dados
Antes de explicar o HiKariCP, vamos apresentar brevemente o que é um pool de conexão de banco de dados (Database Connection Pooling) e por que existe um pool de conexão de banco de dados.
Falando fundamentalmente, o pool de conexão de banco de dados, como nosso pool de thread comumente usado, é um recurso em pool.Ele cria um certo número de objetos de conexão de banco de dados e os armazena em uma área de memória quando o programa é inicializado. Ele permite que o aplicativo reutilize uma conexão de banco de dados existente. Quando SQL precisa ser executado, obtemos uma conexão diretamente do pool de conexão em vez de restabelecer uma conexão de banco de dados. Quando o SQL é executado, a conexão de banco de dados não é verdadeira. Turn desligue-o, mas retorne-o ao pool de conexão do banco de dados. Podemos controlar o número inicial de conexões, conexão mínima, conexão máxima, tempo ocioso máximo e outros parâmetros no pool de conexão, configurando os parâmetros do pool de conexão para garantir que o número de acesso ao banco de dados esteja dentro de um determinado intervalo controlável, evitando falhas no sistema e garantindo uma boa experiência do usuário. O diagrama do conjunto de conexões de banco de dados é o seguinte:
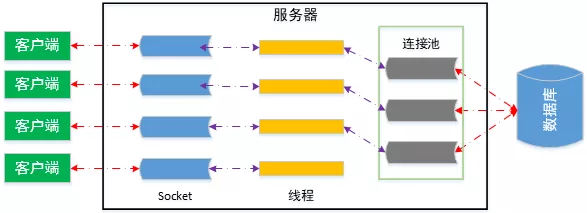
Portanto, a função principal de usar o conjunto de conexões de banco de dados é evitar a criação e destruição freqüentes de conexões de banco de dados e economizar sobrecarga do sistema. Como as conexões de banco de dados são limitadas e caras, a criação e liberação de conexões de banco de dados consomem muito tempo. Essas operações frequentes demandam uma grande sobrecarga de desempenho, o que resultará em uma desaceleração na velocidade de resposta do site e até mesmo em travamentos do servidor.
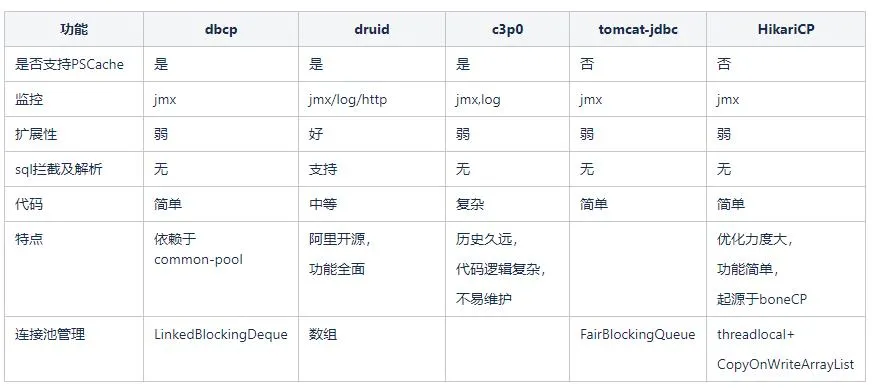
2. Análise comparativa de pools de conexão de banco de dados comum
Aqui está um resumo detalhado da comparação de várias funções de pools de conexão de banco de dados comuns. Focamos na análise do atual Alibaba Druid e HikariCP. O HikariCP é completamente superior em desempenho aos pools de conexão Druid. O desempenho do Druid é um pouco pior devido ao mecanismo de bloqueio diferente, e o Druid fornece funções mais ricas, incluindo monitoramento, interceptação de SQL e análise. O foco dos dois é diferente. O HikariCP busca o máximo desempenho.
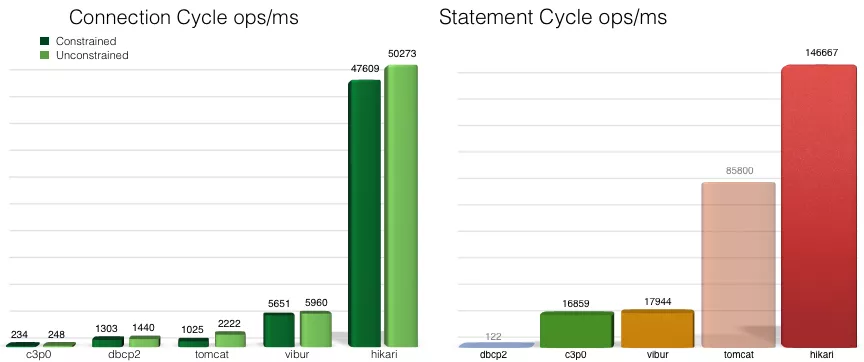
A seguir está o gráfico de comparação de desempenho fornecido pelo site oficial. Em termos de desempenho, a ordem dos cinco pools de conexão de banco de dados é a seguinte: HikariCP> druid> tomcat-jdbc> dbcp> c3p0:
3. Introdução ao pool de conexão de banco de dados HikariCP
O HikariCP afirma ser o melhor pool de conexão de banco de dados da história e o SpringBoot 2.0 o define como o pool de conexão de fonte de dados padrão. Comparado com outros pools de conexão, o Hikari tem um desempenho muito superior. Então, como isso é feito? Ao ver a introdução do site oficial do HikariCP, a otimização do HikariCP é resumida da seguinte forma:
1. Otimização do bytecode: código otimizado, a quantidade de bytecode após a compilação é muito pequena, de forma que o cache da CPU pode carregar mais código do programa;
HikariCP também fez grandes esforços para otimizar e agilizar o bytecode, usando um bytecode Java de terceiros para modificar a biblioteca de classes Javassist para gerar proxy dinâmico delegado. A implementação do proxy dinâmico está na classe ProxyFactory, que é mais rápida, em comparação com JDK Proxy Menos bytecode é gerado, e muitos bytes desnecessários são simplificados.
2. Otimize o proxy e o interceptor: reduza o código, por exemplo, o proxy de declaração do HikariCP tem apenas 100 linhas de código, apenas um décimo do BoneCP;
3. Tipo de array personalizado (FastStatementList) em vez de ArrayList: evite a verificação de intervalo toda vez que get () de ArrayList, evite escanear do início ao fim ao chamar remove () (porque a característica da conexão é que a conexão é liberada após a obtenção da conexão ) ;
4. Tipo de coleção personalizado (ConcurrentBag): melhora a eficiência de leitura e gravação simultâneas;
5. Outras otimizações para defeitos do BoneCP , como o estudo de chamadas de método que ocupam mais de uma fatia de tempo da CPU.
É claro que, como um pool de conexão de banco de dados, não se pode dizer que será respeitado pelos consumidores em breve, além de apresentar excelente robustez e estabilidade. Desde o seu lançamento em 15 anos, o HikariCP tem resistido ao teste do amplo mercado de aplicativos e foi promovido com sucesso pelo SpringBoot2.0 como o pool de conexão de banco de dados padrão. É confiável em termos de confiabilidade. Em segundo lugar, com sua pequena quantidade de código, pequena quantidade de CPU e memória, sua taxa de execução é muito alta. Finalmente, basicamente não há diferença entre a configuração do Spring HikariCP e druid, e a migração é muito conveniente.Estas são as razões pelas quais o HikariCP é tão popular no momento.
Bytecode simplificado, proxy e interceptor otimizados, tipo de array personalizado.
Quatro, análise de código-fonte do núcleo do HikariCP
4.1 Como FastList otimiza problemas de desempenho
Primeiro, vamos dar uma olhada nas etapas para realizar a padronização da operação do banco de dados:
Obtenha uma conexão de banco de dados por meio da fonte de dados;
Criar declaração;
Execute SQL;
Obtenha resultados de execução de SQL por meio de ResultSet;
Libere o ResultSet;
Declaração de liberação;
- Libere a conexão do banco de dados.
Todos os pools de conexão de banco de dados atualmente executam operações de banco de dados estritamente de acordo com esta ordem. Para evitar a operação de liberação final, vários pools de conexão de banco de dados salvarão a declaração criada na matriz ArrayList para garantir que, quando a conexão for fechada, você pode desligar todos Instruções na matriz, por sua vez. No processamento desta etapa, HiKariCP acredita que há espaço para otimização em algumas operações de método de ArrayList, portanto, a implementação simplificada da interface List é otimizada para vários métodos principais na interface List e as outras partes são basicamente as mesmas que ArrayList.
O primeiro é o método get (). ArrayList executará rangeCheck toda vez que o método get () for chamado para verificar se o índice está fora do intervalo. Essa verificação é removida na implementação de FastList porque o pool de conexão do banco de dados atende à legalidade de o índice e pode garantir que não excederá o limite. Neste momento, rangeCheck é uma sobrecarga de cálculo inválida, portanto, não há necessidade de verificar fora dos limites todas as vezes. A eliminação de operações inválidas frequentes pode reduzir significativamente o consumo de desempenho.
- Operação get () de FastList
public T get(int index)
{
// ArrayList 在此多了范围检测 rangeCheck(index);
return elementData[index];
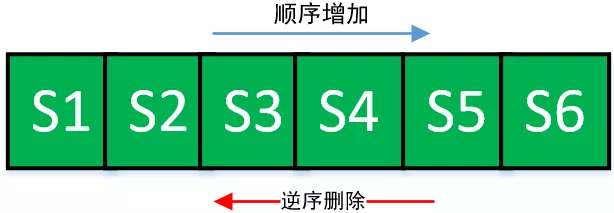
}O segundo é o método remove. Ao criar uma declaração por meio de conn.createStatement (), você precisa chamar o método add () de ArrayList para adicioná-lo à ArrayList. Isso não é problema; mas ao fechar a declaração por meio de stmt.close (), você precisa chamar o método remove () de ArrayList para removê-lo do ArrayList, enquanto o método remove (Object) de ArrayList atravessa a matriz desde o início, enquanto FastList atravessa a partir do final da matriz, então é mais eficiente. Suponha que uma conexão crie 6 declarações em sequência, ou seja, S1, S2, S3, S4, S5, S6, e a ordem das declarações de fechamento é geralmente invertida, de S6 para S1, enquanto o método remove (Object o) de ArrayList é a ordem Busca transversal, exclusão reversa e busca sequencial, a eficiência da busca é muito lenta. Portanto, FastList o otimiza e muda para pesquisa reversa. O código a seguir é a operação de remoção de dados implementada por FastList. Comparado com o código remove () de ArrayList, FastList remove o intervalo de verificação e as etapas de percorrer os elementos de verificação do início ao fim, e seu desempenho é mais rápido.
- Operação de exclusão de FastList
public boolean remove(Object element)
{
// 删除操作使用逆序查找
for (int index = size - 1; index >= 0; index--) {
if (element == elementData[index]) {
final int numMoved = size - index - 1;
// 如果角标不是最后一个,复制一个新的数组结构
if (numMoved > 0) {
System.arraycopy(elementData, index + 1, elementData, index, numMoved);
}
//如果角标是最后面的 直接初始化为null
elementData[--size] = null;
return true;
}
}
return false;
}Por meio da análise do código-fonte acima, os pontos de otimização do FastList ainda são muito simples. Comparado com ArrayList, apenas pequenos ajustes são removidos, como verificação de rack, otimização de expansão, etc. Ao excluir, o array é percorrido para encontrar elementos e outros ajustes menores, de modo a buscar o desempenho final. Claro, a otimização de ArrayList de FastList, não podemos dizer que ArrayList não é bom. O chamado posicionamento é diferente e a busca é diferente. Como um contêiner geral, ArrayList é mais seguro e estável. Ele verifica o rangeCheck antes da operação e lança exceções diretamente para solicitações ilegais, o que está mais de acordo com o mecanismo fail-fast , enquanto FastList busca o melhor desempenho.
Vamos falar sobre ConcurrentBag, outra estrutura de dados em HiKariCP, e ver como ele melhora o desempenho.
4.2 Análise do princípio de realização do ConcurrentBag
Os métodos atuais de implementação do pool de conexão de banco de dados principal são implementados principalmente com duas filas de bloqueio. Um é usado para armazenar conexões de banco de dados inativas na fila e o outro é usado para armazenar conexões de banco de dados ocupadas na fila ocupada; quando uma conexão é obtida, a conexão de banco de dados inativa é movida da fila inativa para a fila ocupada, e quando a conexão é fechada, a conexão do banco de dados é movida de ocupada para inativa. Este esquema delega o problema de simultaneidade para a fila de bloqueio, que é simples de implementar, mas o desempenho não é muito satisfatório. Como a fila de bloqueio no Java SDK é implementada com bloqueios, a contenção de bloqueio em cenários de alta simultaneidade tem um grande impacto no desempenho.
HiKariCP não usa a fila de bloqueio no Java SDK, mas em vez disso implementa um contêiner simultâneo chamado ConcurrentBag sozinho, que tem melhor desempenho do que LinkedBlockingQueue e LinkedTransferQueue na implementação do pool de conexão (interação de dados multi-threaded).
Existem 4 atributos mais críticos em ConcurrentBag, a saber: a fila compartilhada sharedList usada para armazenar todas as conexões de banco de dados, o thread de armazenamento local threadList, o número de threads esperando por conexões de banco de dados, waiters e a ferramenta handoffQueue para alocar conexões de banco de dados. Entre eles, handoffQueue usa SynchronousQueue fornecido pelo Java SDK, e SynchronousQueue é usado principalmente para transferir dados entre threads.
- Atributos principais em ConcurrentBag
// 存放共享元素,用于存储所有的数据库连接
private final CopyOnWriteArrayList<T> sharedList;
// 在 ThreadLocal 缓存线程本地的数据库连接,避免线程争用
private final ThreadLocal<List<Object>> threadList;
// 等待数据库连接的线程数
private final AtomicInteger waiters;
// 接力队列,用来分配数据库连接
private final SynchronousQueue<T> handoffQueue;ConcurrentBag garante que todos os recursos só podem ser adicionados por meio do método add (). Quando o pool de threads cria uma conexão de banco de dados, ele é adicionado ao ConcurrentBag chamando o método add () de ConcurrentBag e removido por meio do método remove (). A seguir está a implementação específica dos métodos add () e remove (). Ao adicionar, a conexão é adicionada à fila compartilhada sharedList. Se houver um encadeamento esperando por uma conexão de banco de dados neste momento, a conexão será atribuída para a espera através do thread handoffQueue.
- Métodos add () e remove () de ConcurrentBag
public void add(final T bagEntry)
{
if (closed) {
LOGGER.info("ConcurrentBag has been closed, ignoring add()");
throw new IllegalStateException("ConcurrentBag has been closed, ignoring add()");
}
// 新添加的资源优先放入sharedList
sharedList.add(bagEntry);
// 当有等待资源的线程时,将资源交到等待线程 handoffQueue 后才返回
while (waiters.get() > 0 && bagEntry.getState() == STATE_NOT_IN_USE && !handoffQueue.offer(bagEntry)) {
yield();
}
}
public boolean remove(final T bagEntry)
{
// 如果资源正在使用且无法进行状态切换,则返回失败
if (!bagEntry.compareAndSet(STATE_IN_USE, STATE_REMOVED) && !bagEntry.compareAndSet(STATE_RESERVED, STATE_REMOVED) && !closed) {
LOGGER.warn("Attempt to remove an object from the bag that was not borrowed or reserved: {}", bagEntry);
return false;
}
// 从sharedList中移出
final boolean removed = sharedList.remove(bagEntry);
if (!removed && !closed) {
LOGGER.warn("Attempt to remove an object from the bag that does not exist: {}", bagEntry);
}
return removed;
}Ao mesmo tempo, ConcurrentBag obtém uma conexão de banco de dados ociosa por meio do método borrow () fornecido e recupera recursos por meio do método return (). A lógica principal de borrow () é:
- Verifique se há uma conexão inativa no thread de armazenamento local threadList, se houver, retorne uma conexão inativa;
- Se não houver conexão inativa no armazenamento local do encadeamento, obtenha-o na fila compartilhada sharedList;
- Se não houver conexões livres na fila compartilhada, o encadeamento solicitante precisará aguardar.
- Métodos de empréstimo () e requite () do ConcurrentBag
// 该方法会从连接池中获取连接, 如果没有连接可用, 会一直等待timeout超时
public T borrow(long timeout, final TimeUnit timeUnit) throws InterruptedException
{
// 首先查看线程本地资源threadList是否有空闲连接
final List<Object> list = threadList.get();
// 从后往前反向遍历是有好处的, 因为最后一次使用的连接, 空闲的可能性比较大, 之前的连接可能会被其他线程提前借走了
for (int i = list.size() - 1; i >= 0; i--) {
final Object entry = list.remove(i);
@SuppressWarnings("unchecked")
final T bagEntry = weakThreadLocals ? ((WeakReference<T>) entry).get() : (T) entry;
// 线程本地存储中的连接也可以被窃取, 所以需要用CAS方法防止重复分配
if (bagEntry != null && bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
}
// 当无可用本地化资源时,遍历全部资源,查看可用资源,并用CAS方法防止资源被重复分配
final int waiting = waiters.incrementAndGet();
try {
for (T bagEntry : sharedList) {
if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
// 因为可能“抢走”了其他线程的资源,因此提醒包裹进行资源添加
if (waiting > 1) {
listener.addBagItem(waiting - 1);
}
return bagEntry;
}
}
listener.addBagItem(waiting);
timeout = timeUnit.toNanos(timeout);
do {
final long start = currentTime();
// 当现有全部资源都在使用中时,等待一个被释放的资源或者一个新资源
final T bagEntry = handoffQueue.poll(timeout, NANOSECONDS);
if (bagEntry == null || bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
timeout -= elapsedNanos(start);
} while (timeout > 10_000);
return null;
}
finally {
waiters.decrementAndGet();
}
}
public void requite(final T bagEntry)
{
// 将资源状态转为未在使用
bagEntry.setState(STATE_NOT_IN_USE);
// 判断是否存在等待线程,若存在,则直接转手资源
for (int i = 0; waiters.get() > 0; i++) {
if (bagEntry.getState() != STATE_NOT_IN_USE || handoffQueue.offer(bagEntry)) {
return;
}
else if ((i & 0xff) == 0xff) {
parkNanos(MICROSECONDS.toNanos(10));
}
else {
yield();
}
}
// 否则,进行资源本地化处理
final List<Object> threadLocalList = threadList.get();
if (threadLocalList.size() < 50) {
threadLocalList.add(weakThreadLocals ? new WeakReference<>(bagEntry) : bagEntry);
}
}O método borrow () pode ser considerado o método mais importante em todo o HikariCP. É o método que eventualmente chamaremos quando obtivermos uma conexão do pool de conexão. Deve-se observar que o método borrow () fornece apenas referências de objeto e não remove o objeto. Portanto, ele deve ser colocado de volta através do método return () ao usá-lo, caso contrário, poderá facilmente causar vazamentos de memória. O método requite () primeiro altera o status de conexão do banco de dados para não utilizado e, em seguida, verifica se há um thread em espera e, se houver, ele é atribuído ao thread em espera; caso contrário, a conexão do banco de dados é salva no armazenamento local do thread.
A implementação de ConcurrentBag usa o mecanismo de roubo de fila para obter elementos: primeiro tente obter elementos pertencentes ao thread atual de ThreadLocal para evitar a competição de bloqueio e, se não houver elementos disponíveis, obtenha-os novamente do CopyOnWriteArrayList compartilhado. Além disso, ThreadLocal e CopyOnWriteArrayList são variáveis de membro em ConcurrentBag e não são compartilhados entre threads, o que evita o falso compartilhamento. Ao mesmo tempo, como a conexão no armazenamento local do encadeamento pode ser roubada por outros encadeamentos e a conexão inativa é obtida na fila compartilhada, o método CAS é necessário para evitar a alocação duplicada.
Cinco, resumo
Como o pool de conexão padrão do SpringBoot2.0, o Hikari é atualmente amplamente usado na indústria. Para a maioria das empresas, ele pode ser acessado rapidamente e usado para obter conexões eficientes.
Referência
Autor: equipe de tecnologia de jogos vivo