Diferentes linguagens e conjuntos de caracteres precisam ser armazenados e recuperados de maneiras diferentes.O MySQL precisa se adaptar a diferentes conjuntos de caracteres, métodos de classificação e recuperação de dados.
Terminologia:
1. Conjunto de caracteres: uma coleção de letras e símbolos.
2. Codificação: a representação interna de um membro de um conjunto de caracteres.
3. Revisão: uma instrução que especifica como os caracteres são comparados.
Veja a lista de conjuntos de caracteres suportados pelo MySQL:
SHOW CHARACTER SET;
Execute:
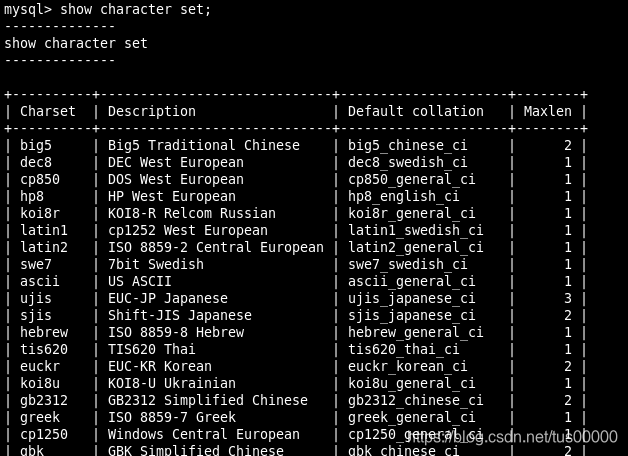
Esta instrução mostra todos os conjuntos de caracteres disponíveis e a descrição e agrupamento padrão de cada conjunto de caracteres.
Veja a lista de revisões suportadas:
SHOW COLLATION;
Execute:
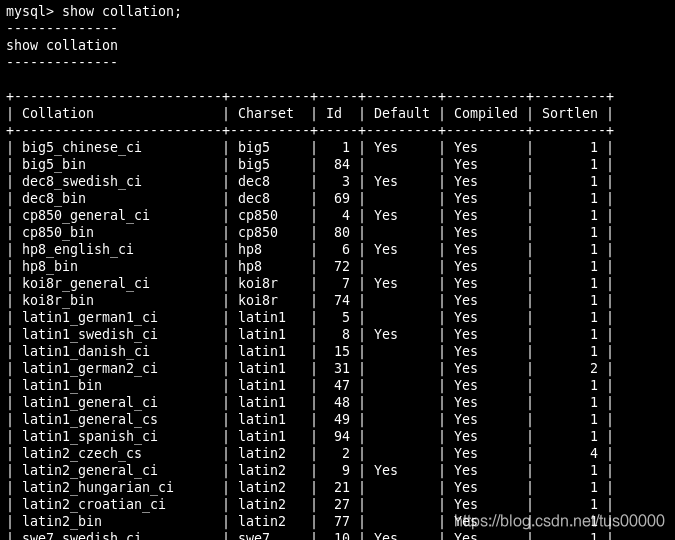
Esta instrução mostra todos os agrupamentos disponíveis e seus conjuntos de caracteres aplicáveis. Um conjunto de caracteres pode ter várias revisões. Por exemplo, lation1 tem revisão para diferentes idiomas europeus e muitas revisões aparecem duas vezes, uma com distinção entre maiúsculas e minúsculas (representado por _cs) e outra sem distinção entre maiúsculas e minúsculas (representado por _ci).
Defina um conjunto de caracteres padrão e a revisão quando o sistema de gerenciamento for instalado. Além disso, você pode especificar o conjunto de caracteres padrão e a revisão do banco de dados ao criar o banco de dados e exibir o conjunto de caracteres e a revisão usados:
SHOW VARIABLES LIKE 'character%';
SHOW VARIABLES LIKE 'collation%';
Execute: você
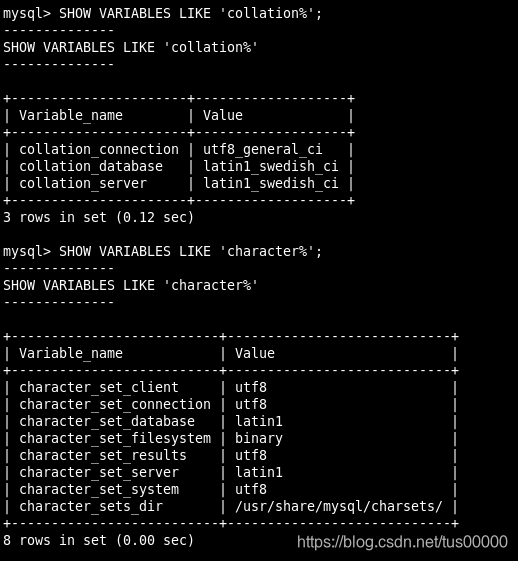
pode especificar conjuntos de caracteres para diferentes tabelas e diferentes colunas na tabela. Especifique o conjunto de caracteres e agrupamento para a tabela:
CREATE TABLE tableName
(
列定义
) DEFAULT CHARACTER SET hebrew
COLLATE hebrew_general_ci;
Se apenas CHARACTER SET for especificado, o agrupamento padrão deste conjunto de caracteres será usado. Se nenhum for especificado, os dados de caractere padrão e agrupamento do banco de dados são usados.
Especifique o conjunto de caracteres para uma coluna:
CREATE TABLE tableName
(
column1 INT,
column2 VARCHAR(10) CHARACTER SET latin1 COLLATE latin1_general_ci
) DEFAULT CHARACTER SET hebrew
COLLATE hebrew_general_ci;
O agrupamento funciona na cláusula ORDER BY. Se você precisar classificar os resultados de uma instrução SELECT específica em uma ordem de agrupamento diferente de quando a tabela foi criada:
SELECT * FROM tableName
ORDER BY columnName COLLATE latin1_general_cs;
O texto acima é uma revisão que diferencia maiúsculas de minúsculas, mesmo ao pesquisar em uma tabela que não diferencia maiúsculas de minúsculas. COLLATE pode ser usado em cláusulas ORDER BY, mas também em GROUP BY, HAVING, funções de agregação e aliases.
Strings podem ser convertidos entre conjuntos de caracteres, basta usar a função Cast ou Converter.