Prefácio
Redis é um banco de dados de pares de valores-chave, cujas chaves são armazenadas por meio de hashes. Todo o Redis pode ser considerado um hash externo. O motivo pelo qual é chamado de hash externo é porque o Redis também fornece um tipo de hash internamente, que pode ser chamado de hash interno. Quando usamos objetos hash para armazenamento de dados, para todo o Redis, ele passa por duas camadas de armazenamento hash.
Objeto Hash
O próprio objeto hash também é uma estrutura de armazenamento de valor-chave e a estrutura de armazenamento subjacente também pode ser dividida em dois tipos: ziplist (lista compactada) e hashtable (tabela hash). Essas duas estruturas de armazenamento também são distinguidas pela codificação:
Descrição do atributo de codificação valor de retorno do comando de codificação de objeto OBJ_ENCODING_ZIPLIST Use lista compactada para implementar ziplist de objeto hash OBJ_ENCODING_HT Use dicionário para implementar hashtable de objeto hash
hashtable
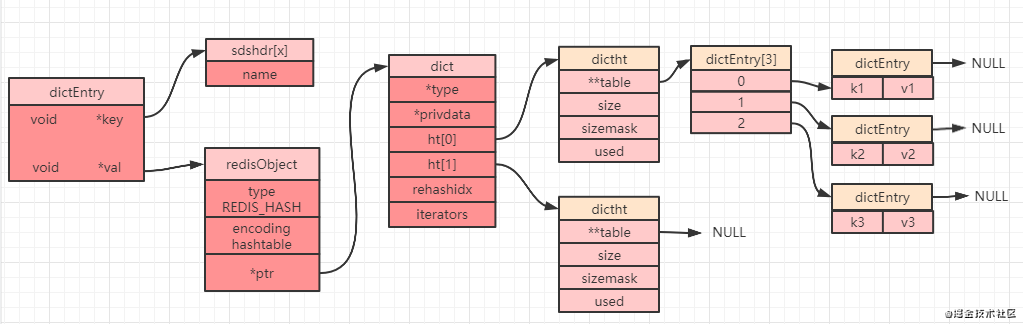
O valor-chave no Redis é agrupado pelo objeto dictEntry e a tabela hash é obtida empacotando o objeto dictEntry novamente. Este é o objeto da tabela hash dictht:
typedef struct dictht { dictEntry **table;//哈希表数组 unsigned long size;//哈希表大小 unsigned long sizemask;//掩码大小,用于计算索引值,总是等于size-1 unsigned long used;//哈希表中的已有节点数} dictht;复制代码Nota: A tabela na definição de estrutura acima é uma matriz, cada elemento da qual é um objeto dictEntry.
dicionário
Um dicionário, também conhecido como tabela de símbolos, matriz associativa ou mapa, tem um objeto dictht de tabela hash aninhado dentro do dicionário. A seguir está a definição de um dicionário ht:
typedef struct dictType { uint64_t (*hashFunction)(const void *key);//计算哈希值函数 void *(*keyDup)(void *privdata, const void *key);//复制键函数 void *(*valDup)(void *privdata, const void *obj);//复制值函数 int (*keyCompare)(void *privdata, const void *key1, const void *key2);//对比键函数 void (*keyDestructor)(void *privdata, void *key);//销毁键函数 void (*valDestructor)(void *privdata, void *obj);//销毁值函数} dictType;复制代码Entre eles, dictType define algumas funções comumente usadas, e sua estrutura de dados é definida da seguinte forma:
typedef struct dictType { uint64_t (*hashFunction)(const void *key);//计算哈希值函数 void *(*keyDup)(void *privdata, const void *key);//复制键函数 void *(*valDup)(void *privdata, const void *obj);//复制值函数 int (*keyCompare)(void *privdata, const void *key1, const void *key2);//对比键函数 void (*keyDestructor)(void *privdata, void *key);//销毁键函数 void (*valDestructor)(void *privdata, void *obj);//销毁值函数} dictType;复制代码Quando criamos um objeto hash, podemos obter o seguinte diagrama (alguns atributos são omitidos):
operação de refazer
Uma matriz ht [2] é definida em dict, e duas tabelas de hash são definidas em ht [2]: ht [0] e ht [1]. O Redis usará apenas ht [0] por padrão e não usará ht [1], nem alocará espaço para a inicialização de ht [1].
Ao definir um objeto hash, qual subscrito no array hash (dictEntry [3] na figura acima) irá cair é determinado pelo cálculo do valor hash. Se ocorrer uma colisão de hash (o valor de hash calculado é o mesmo), o mesmo subscrito terá vários dictEntry, formando assim uma lista vinculada (o ponto mais à direita na figura acima aponta para a posição NULL), mas deve-se notar que a última inserção O elemento está sempre no topo da lista vinculada (ou seja, quando ocorre um conflito de hash, o nó é sempre colocado no topo da lista vinculada).
Ao ler dados, ao encontrar um nó com vários elementos, você precisa percorrer a lista vinculada, portanto, quanto mais longa a lista vinculada, pior é o desempenho. Para garantir o desempenho da tabela de hash, a tabela de hash precisa ser refeita quando uma das duas condições a seguir for atendida:
- Quando o fator de carga é maior ou igual a 1 e dict_can_resize é 1.
- Quando o fator de carga é maior ou igual ao limite de segurança (dict_force_resize_ratio = 5).
PS: Fator de carga = número de nós usados na tabela hash / tamanho da tabela hash (ou seja: h [0] .used / h [0] .size).
etapa de refazer
O hash de expansão e o hash de redução são concluídos pela execução de um novo hash, que envolve alocação e liberação de espaço, principalmente por meio das cinco etapas a seguir:
- Alocar espaço para a tabela hash ht [1] do dicionário dict, cujo tamanho depende do número de nós salvos na tabela hash atual (ou seja: ht [0] .used):
- Defina o valor do atributo rehashix no dicionário como 0, indicando que a operação de rehash está sendo executada.
- Recalcule os valores de hash de todos os pares de valores-chave em ht [0] por sua vez e coloque-os na posição correspondente da matriz ht [1]. O valor de rehashix precisa ser incrementado em 1 após a conclusão do rehash de um par de valor-chave.
- Quando todos os pares de valores-chave em ht [0] são migrados para ht [1], libere ht [0], altere ht [1] para ht [0] e crie uma nova matriz ht [1], para preparar para o próximo rehash.
- Defina o atributo rehashix no dicionário como -1, o que significa que esta operação de rehash acabou e aguarde o próximo rehash.
Rehash progressivo
Essa operação de refazer o hash no Redis não é refazer tudo de uma vez, mas refazer lentamente o par de valores-chave em ht [0] para ht [1] em várias vezes , portanto, essa operação também é chamada de É refazer progressivo . O rehash progressivo pode evitar a enorme quantidade de cálculos trazidos pelo rehash centralizado, que é uma ideia de dividir para conquistar.
No processo de rehash progressivo, como pode haver novos pares de valores-chave armazenados, neste momento ** a abordagem do Redis é colocar os pares de valores-chave recém-adicionados em ht [1] uniformemente, de modo a garantir ht [0] O número de pares de valores-chave só diminuirá **.
Quando o rehash da operação está sendo executado, se o servidor receber um comando da operação de solicitação do cliente, primeiro consultará ht [0] , então os resultados parecerão menores que ht [1] query .
tirolesa
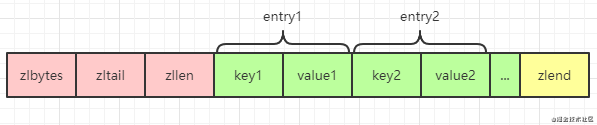
Algumas características do Ziplist foram analisadas separadamente no artigo anterior. Se você quiser saber mais, clique aqui. Mas deve-se notar que a diferença entre o ziplist no objeto hash e o ziplist no objeto de lista é que o objeto hash é uma forma de valor-chave, então o ziplist também aparece como um valor-chave, e a chave e o valor estão próximos:
ziplist e conversão de codificação hashtable
Quando um objeto hash pode atender a qualquer uma das duas condições a seguir, o objeto hash escolherá usar a codificação ziplist para armazenamento:
- O comprimento total de todos os pares de valor-chave no objeto hash (incluindo chaves e valores) é menor ou igual a 64 bytes (esse limite pode ser controlado pelo parâmetro hash-max-ziplist-value).
- O número de pares de valores-chave no objeto hash é menor ou igual a 512 (esse limite pode ser controlado pelo parâmetro hash-max-ziplist-entries).
Quando qualquer uma dessas duas condições não for atendida, o objeto hash escolherá usar a codificação hashtable para armazenamento.
Comandos comuns para objetos hash
- valor do campo-chave hset: Defina um único campo (valor-chave do objeto hash).
- hmset key field1 value1 field2 value2: Defina vários campos (valores-chave de objetos hash).
- Valor do campo-chave hsetnx: Defina o valor do campo do campo na chave da tabela hash como valor.Se o campo já existir, nenhuma operação será executada.
- hget key field: Obtenha o valor correspondente ao campo do campo na chave da tabela hash.
- hmget key field1 field2: obtenha o valor correspondente a vários campos na chave da tabela hash.
- hdel key field1 field2: Exclua um ou mais campos na chave da tabela hash.
- Chave hlen: Retorna o número de campos na chave da tabela hash.
- Incremento do campo da chave Hincrby: adiciona um incremento ao valor do campo do campo na chave da tabela hash. O incremento pode ser um número negativo. Se o campo não for um número, um erro será relatado.
- Incremento do campo-chave hincrbyfloat: adiciona incremento ao valor do campo do campo na chave da tabela hash. O incremento pode ser um número negativo. Se o campo não for do tipo flutuante, um erro será relatado.
- chave hkeys: obtém todos os campos na chave da tabela hash.
- Chave hvals: obtenha os valores de todos os campos da tabela hash.
Conhecendo os comandos comuns para operar objetos hash, podemos verificar o tipo e a codificação dos objetos hash mencionados anteriormente. Para evitar a interferência de outros valores de chave antes do teste, primeiro executamos o comando flushall para limpar o banco de dados Redis.
Em seguida, execute os seguintes comandos em sequência:
hset address country chinatype addressobject encoding address复制代码Obtenha os seguintes efeitos:
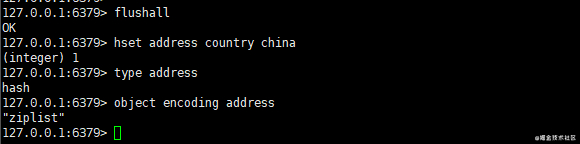
Você pode ver que, quando há apenas um par de valor-chave em nosso objeto hash, a codificação subjacente é ziplist.
Agora alteramos o parâmetro hash-max-ziplist-entries para 2, reiniciamos o Redis e, por fim, inserimos o seguinte comando para testar:
hmset key field1 value1 field2 value2 field3 value3object encoding key复制代码Após a saída, os seguintes resultados são obtidos:

Como você pode ver, a codificação tornou-se uma hashtable.
Resumindo
Este artigo apresenta principalmente o uso de hashtable, a estrutura de armazenamento subjacente do tipo hash entre os cinco tipos de dados comumente usados no Redis e como o Redis executa o re-hash quando a distribuição de hash é desigual. Por fim, aprendi sobre alguns hash comumente usados objetos Solicite e verifique a conclusão deste artigo através de alguns exemplos.