1. Fundo
Este artigo foi escrito na semana passada depois que fui ao salão de tecnologia para ouvir Java Cache Road da iQiyi. Vamos apresentar brevemente o desenvolvimento do java cache road do iQIYI. 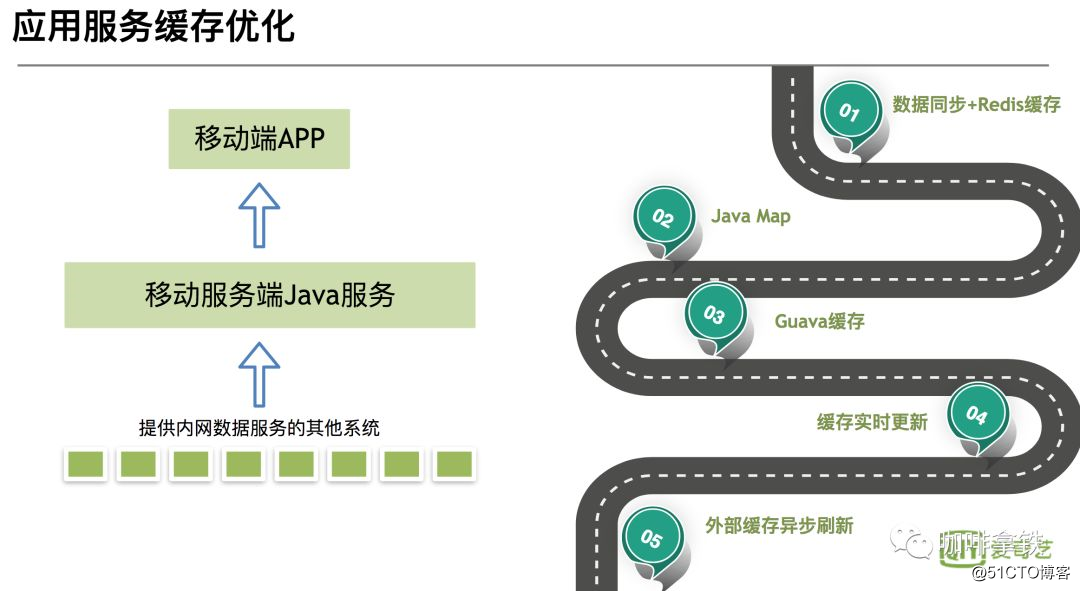
Percebe-se que a figura está dividida em várias etapas:
-
O primeiro estágio: sincronização de dados e redis sincroniza dados para redis
através da fila de mensagens, e então o aplicativo Java busca diretamente o cache.A vantagem deste estágio é: como o cache distribuído é usado, os dados são atualizados rapidamente. As deficiências também são óbvias: confiar na estabilidade do Redis, uma vez que o redis trava, todo o sistema de cache fica indisponível, causando uma avalanche de cache, e todas as solicitações chegam ao banco de dados. -
O segundo e terceiro estágios: De JavaMap para o cache Guava,
o cache em processo é usado como o cache de primeiro nível e o redis é usado como o segundo nível. Vantagens: Não afetado por sistemas externos, outros sistemas ainda podem ser usados se eles travarem. Desvantagem: o cache em processo não pode ser atualizado em tempo real como o cache distribuído. Devido à memória limitada do Java, o tamanho do cache deve ser definido, e depois alguns caches serão eliminados, haverá um problema de taxa de acerto. -
O quarto estágio: Atualização do Guava Cache
A fim de resolver os problemas acima, use o Guava Cache para definir o tempo de atualização após escrever para atualizar. Resolvido o problema de não atualizar, mas ainda não resolvia a atualização em tempo real. - Quinto estágio: atualização de cache externo assíncrono
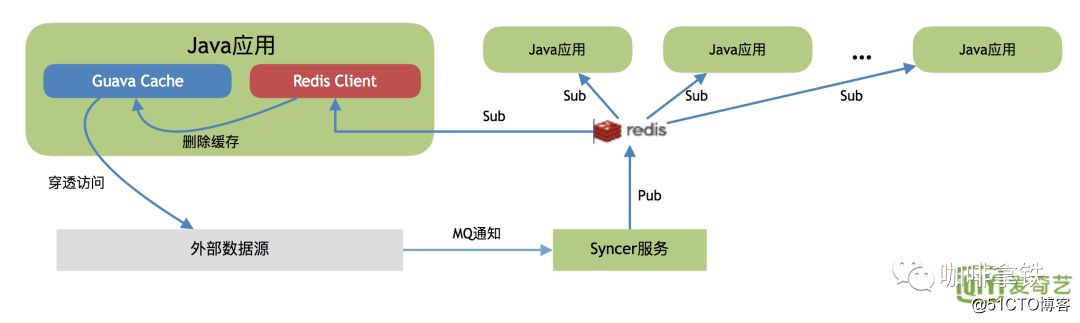
este estágio estende o Guava Cache, use redis como um mecanismo de notificação de fila de mensagens para informar a atualização de outros aplicativos java.
Aqui está uma breve introdução aos cinco estágios de desenvolvimento de cache do iQiyi. Claro, existem algumas outras otimizações, como ajuste de GC, penetração de cache e algumas otimizações de cobertura de cache. Os alunos interessados podem seguir o relato oficial e entrar em contato comigo para comunicação.
2. Biblioteca de pesquisa da sociedade primitiva
O acima é um caminho evolutivo do iQiyi, mas em seu processo de desenvolvimento geral, a primeira etapa geralmente é sem redis, mas verificando diretamente a biblioteca.
Quando o tráfego está baixo, é mais conveniente verificar o banco de dados ou ler o arquivo, e ele pode atender totalmente aos nossos requisitos de negócios.
3. Sociedade antiga - HashMap
Quando nosso aplicativo tem uma certa quantidade de tráfego ou consulta o banco de dados com muita frequência, neste momento podemos sacrificar o HashMap ou ConcurrentHashMap que vem com nosso java. Podemos escrever isso no código:
public
class
CustomerService
{
private
HashMap
<
String
,
String
>
hashMap
=
new
HashMap
<>();
private
CustomerMapper
customerMapper
;
public
String
getCustomer
(
String
name
){
String
customer
=
hashMap
.
get
(
name
);
if
(
customer
==
null
){
customer
=
customerMapper
.
get
(
name
);
hashMap
.
put
(
name
,
customer
);
}
return
customer
;
}
}Mas há um problema em fazer isso: o HashMap não pode eliminar dados e a memória aumentará indefinidamente, portanto, o hashMap é eliminado rapidamente. Claro que isso não significa que ele seja completamente inútil. Assim como nossa sociedade antiga, nem tudo está desatualizado. Por exemplo, as virtudes tradicionais do nosso clã chinês são atemporais, como este hashMap, que pode ser usado em determinados cenários. Como um cache, quando não precisamos do mecanismo de eliminação, por exemplo, usamos reflexão. Se pesquisarmos Método e campo por meio de reflexão todas as vezes, o desempenho deve ser ineficiente. Neste momento, usamos HashMap para armazená-lo em cache, e o desempenho pode ser muito melhorado.
4. Sociedade moderna-LRUHashMap
Nas sociedades antigas, o problema com o qual lutamos não pode ser eliminado pelos dados, o que nos levará a uma expansão ilimitada da memória, o que obviamente é inaceitável para nós. Tem gente que fala que eliminei alguns dados, o que não seria certo, mas como eliminar? É eliminado aleatoriamente? Claro que não. Imagine que você acabou de carregar A no cache, e ele será eliminado na próxima vez que você quiser acessá-lo. Então, acessaremos nosso banco de dados novamente. Então, por que queremos fazer o cache?
Então, pessoas inteligentes inventaram vários algoritmos de eliminação. Aqui estão os três FIFO, LRU, LFU comuns (existem alguns ARC, MRU interessados, você pode pesquisar por si mesmo):
- FIFO: Primeiro a entrar, primeiro a sair Neste algoritmo de eliminação, aquele que entrar primeiro no buffer será eliminado primeiro. Este é o mais simples, mas levará a uma taxa de acerto muito baixa. Imagine se tivermos um dado acessado com muita frequência em que todos os dados são acessados primeiro, e aqueles que não são muito altos são acessados posteriormente, então nossos primeiros dados serão acessados mas sua frequência de acesso é muito alta. Espremer.
- LRU: O algoritmo menos usado recentemente. Neste algoritmo, o problema acima é evitado. Cada vez que acessamos os dados, eles serão colocados no final de nossa equipe. Se precisarmos eliminar dados, só precisamos eliminar o chefe da equipe. Mas isso ainda tem um problema. Se houver um dado que é acessado 10.000 vezes nos primeiros 59 minutos de uma hora (pode-se ver que se trata de um dado quente), os dados não são acessados no minuto seguinte, mas existem outros acessos de dados, que levarão a Nossos dados quentes são eliminados.
- LFU: O uso menos frequente recentemente. Neste algoritmo, o acima é otimizado novamente, usando espaço adicional para registrar a frequência de uso de cada dado e, em seguida, selecionando a frequência mais baixa para eliminação. Isso evita o problema de que o LRU não consegue lidar com o período de tempo.
As três estratégias de eliminação estão listadas acima. Para essas três, o custo de implementação é maior do que um e a taxa de acerto também é melhor do que um. De um modo geral, a solução que escolhemos fica no meio, ou seja, o custo de implantação não é muito alto e a taxa de acerto também é boa.Como implantar um LRUMap? Podemos completar um LRUMap simples herdando LinkedHashMap e reescrevendo o método removeEldestEntry.
class
LRUMap
extends
LinkedHashMap
{
private
final
int
max
;
private
Object
lock
;
public
LRUMap
(
int
max
,
Object
lock
)
{
//无需扩容
super
((
int
)
(
max
*
1.4f
),
0.75f
,
true
);
this
.
max
=
max
;
this
.
lock
=
lock
;
}
/**
* 重写LinkedHashMap的removeEldestEntry方法即可
* 在Put的时候判断,如果为true,就会删除最老的
* @param eldest
* @return
*/
@Override
protected
boolean
removeEldestEntry
(
Map
.
Entry
eldest
)
{
return
size
()
>
max
;
}
public
Object
getValue
(
Object
key
)
{
synchronized
(
lock
)
{
return
get
(
key
);
}
}
public
void
putValue
(
Object
key
,
Object
value
)
{
synchronized
(
lock
)
{
put
(
key
,
value
);
}
}
public
boolean
removeValue
(
Object
key
)
{
synchronized
(
lock
)
{
return
remove
(
key
)
!=
null
;
}
}
public
boolean
removeAll
(){
clear
();
return
true
;
}
}Uma lista vinculada de entradas (objetos para chave e valor) é mantida em LinkedHashMap. Em cada get ou put, a nova entrada inserida ou a entrada antiga consultada será colocada no final de nossa lista vinculada. Pode-se notar que no método de construção, o tamanho definido é definido para max * 1,4. No método removeEldestEntry abaixo, apenas size> max é necessário para eliminar, para que nosso mapa nunca alcance a lógica de expansão. Reescrevendo LinkedHashMap, implementamos nosso LruMap de algumas maneiras simples.
5. Sociedade moderna - cache de goiaba
O LRUMap foi inventado na sociedade moderna para eliminar os dados armazenados em cache, mas existem vários problemas:
- A competição de bloqueio é séria.Pode ser visto que no meu código, o bloqueio é um bloqueio global.No nível do método, quando a quantidade de chamadas é grande, o desempenho será inevitavelmente menor.
- Não suporta tempo de expiração
- Não suporta atualização automática
Então, os figurões do Google não puderam deixar de lidar com esses problemas e inventaram o cache Guava. No cache Guava você pode usá-lo tão facilmente quanto o seguinte código:
public
static
void
main
(
String
[]
args
)
throws
ExecutionException
{
LoadingCache
<
String
,
String
>
cache
=
CacheBuilder
.
newBuilder
()
.
maximumSize
(
100
)
//写之后30ms过期
.
expireAfterWrite
(
30L
,
TimeUnit
.
MILLISECONDS
)
//访问之后30ms过期
.
expireAfterAccess
(
30L
,
TimeUnit
.
MILLISECONDS
)
//20ms之后刷新
.
refreshAfterWrite
(
20L
,
TimeUnit
.
MILLISECONDS
)
//开启weakKey key 当启动垃圾回收时,该缓存也被回收
.
weakKeys
()
.
build
(
createCacheLoader
());
System
.
out
.
println
(
cache
.
get
(
"hello"
));
cache
.
put
(
"hello1"
,
"我是hello1"
);
System
.
out
.
println
(
cache
.
get
(
"hello1"
));
cache
.
put
(
"hello1"
,
"我是hello2"
);
System
.
out
.
println
(
cache
.
get
(
"hello1"
));
}
public
static
com
.
google
.
common
.
cache
.
CacheLoader
<
String
,
String
>
createCacheLoader
()
{
return
new
com
.
google
.
common
.
cache
.
CacheLoader
<
String
,
String
>()
{
@Override
public
String
load
(
String
key
)
throws
Exception
{
return
key
;
}
};
}Vou explicar como o goiaba cache resolve vários problemas do LRUMap a partir do princípio do goiaba cache.
5.1 Bloquear competição
O cache Guava adota a ideia semelhante ao ConcurrentHashMap, bloqueia os segmentos e é responsável por sua própria eliminação em cada segmento. A goiaba é segmentada de acordo com um determinado algoritmo. Deve-se notar que se houver poucos segmentos, a competição ainda é muito séria. Se houver muitos segmentos, eles serão facilmente eliminados de forma aleatória. Por exemplo, se o tamanho for 100, divida-o em 100 segmentos. Isso é para permitir que cada dado ocupe um segmento, e cada segmento tratará do processo de eliminação por si mesmo, de forma que a eliminação aleatória ocorrerá. No cache de goiaba, use o código a seguir para calcular como segmentar.
int
segmentShift
=
0
;
int
segmentCount
=
1
;
while
(
segmentCount
<
concurrencyLevel
&&
(!
evictsBySize
()
||
segmentCount
*
20
<=
maxWeight
))
{
++
segmentShift
;
segmentCount
<<=
1
;
}O segmentCount acima é nosso número final de segmentos, o que garante pelo menos 10 entradas por segmento. Se o parâmetro concurrencyLevel não for definido, o padrão será 4 e o número final de segmentos será até 4. Por exemplo, se nosso tamanho for 100, ele será dividido em 4 segmentos, e o tamanho máximo de cada segmento será 25. No cache de goiaba, a operação de gravação é travada diretamente. Para a operação de leitura, se os dados lidos não expiraram e estão prontos para serem carregados, não há necessidade de travar. Se não for lido, será travado novamente para uma segunda leitura. É necessário carregar o cache, ou seja, através do CacheLoader que configuramos, o que eu configurei aqui é retornar a Chave diretamente, e a consulta do banco de dados costuma ser configurada no próprio negócio. Como mostrado abaixo: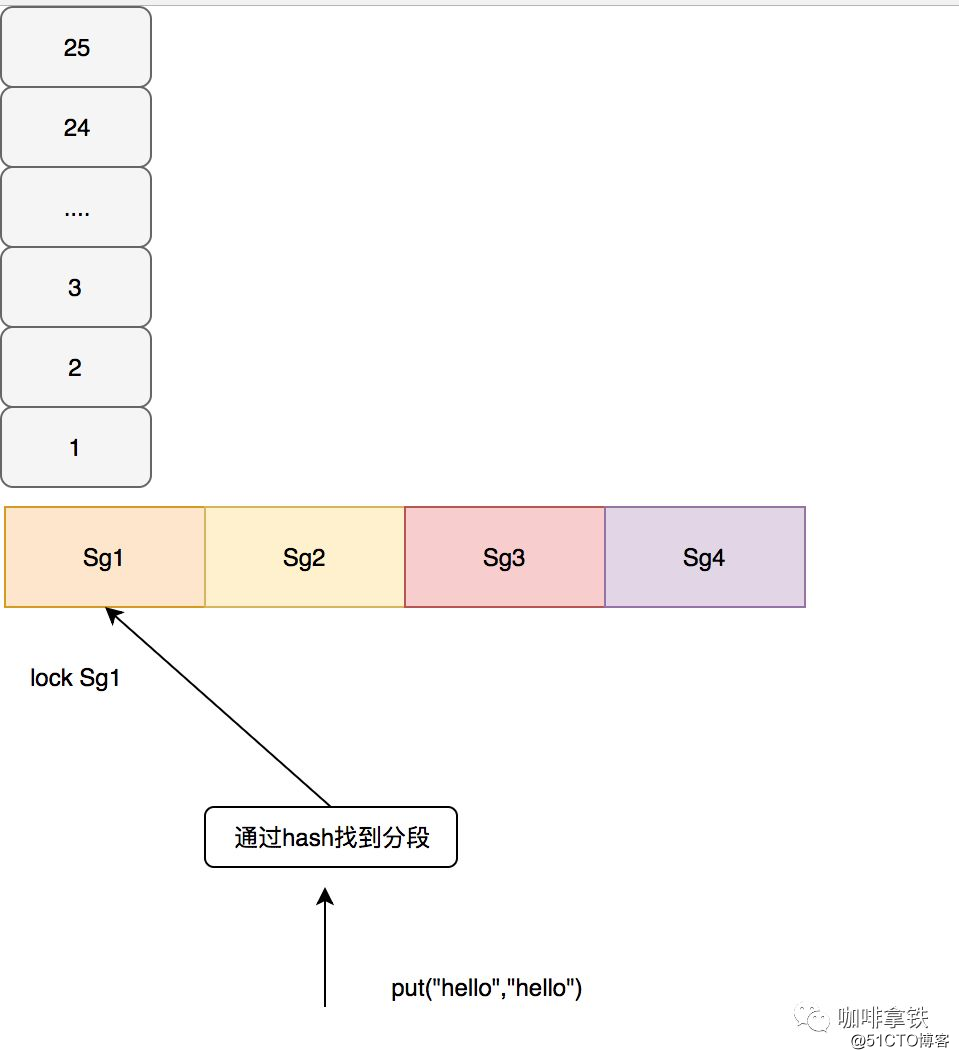
5.2 Tempo de expiração
Em comparação com LRUMap, existem mais dois tempos de expiração, um é quanto tempo ele expira após a gravação de expireAfterWrite, o outro é quanto tempo ele expira após a leitura de expireAfterAccess. O interessante é que a entrada expirada no cache de goiaba não expira imediatamente (ou seja, não há thread de segundo plano que foi escaneada), mas o processo de expiração é executado durante as operações de leitura e gravação. A vantagem disso é evitar o segundo plano Execute bloqueios globais durante a varredura de thread. Observe o seguinte código:
public
static
void
main
(
String
[]
args
)
throws
ExecutionException
,
InterruptedException
{
Cache
<
String
,
String
>
cache
=
CacheBuilder
.
newBuilder
()
.
maximumSize
(
100
)
//写之后5s过期
.
expireAfterWrite
(
5
,
TimeUnit
.
MILLISECONDS
)
.
concurrencyLevel
(
1
)
.
build
();
cache
.
put
(
"hello1"
,
"我是hello1"
);
cache
.
put
(
"hello2"
,
"我是hello2"
);
cache
.
put
(
"hello3"
,
"我是hello3"
);
cache
.
put
(
"hello4"
,
"我是hello4"
);
//至少睡眠5ms
Thread
.
sleep
(
5
);
System
.
out
.
println
(
cache
.
size
());
cache
.
put
(
"hello5"
,
"我是hello5"
);
System
.
out
.
println
(
cache
.
size
());
}
输出:
4
1A partir desse resultado, sabemos que o processo de expiração só é realizado quando colocado. Preste atenção especial ao nível de concorrência (1) acima. Eu defino o segmento máximo como 1 aqui, caso contrário, este efeito experimental não aparecerá. Conforme mencionado na seção anterior, usamos a unidade de nível para processamento de expiração. Duas filas são mantidas em cada segmento:
final
Queue
<
ReferenceEntry
<
K
,
V
>>
writeQueue
;
final
Queue
<
ReferenceEntry
<
K
,
V
>>
accessQueue
;writeQueue mantém uma fila de gravação.A cabeça da fila representa os dados gravados antecipadamente e o final da fila representa os dados gravados tardiamente. accessQueue mantém a fila de acesso, como LRU, ela é usada para eliminar o tempo de acesso.Se o segmento ultrapassar a capacidade máxima, como os 25 mencionados acima, o primeiro elemento da fila accessQueue será processado. Eliminado.
void
expireEntries
(
long
now
)
{
drainRecencyQueue
();
ReferenceEntry
<
K
,
V
>
e
;
while
((
e
=
writeQueue
.
peek
())
!=
null
&&
map
.
isExpired
(
e
,
now
))
{
if
(!
removeEntry
(
e
,
e
.
getHash
(),
RemovalCause
.
EXPIRED
))
{
throw
new
AssertionError
();
}
}
while
((
e
=
accessQueue
.
peek
())
!=
null
&&
map
.
isExpired
(
e
,
now
))
{
if
(!
removeEntry
(
e
,
e
.
getHash
(),
RemovalCause
.
EXPIRED
))
{
throw
new
AssertionError
();
}
}
}O acima é o processo de cache de goiaba que processa entradas expiradas, ele irá ver as duas filas de uma vez e excluí-las se expirarem. Geralmente, o processamento de Entries expirados pode ser chamado antes e depois de nossa operação put ou quando descobrimos que ele expirou ao ler os dados e, em seguida, executar o processamento expirado de todo o segmento ou chamá-lo durante a segunda operação de leitura lockedGetOrLoad.
void
evictEntries
(
ReferenceEntry
<
K
,
V
>
newest
)
{
///... 省略无用代码
while
(
totalWeight
>
maxSegmentWeight
)
{
ReferenceEntry
<
K
,
V
>
e
=
getNextEvictable
();
if
(!
removeEntry
(
e
,
e
.
getHash
(),
RemovalCause
.
SIZE
))
{
throw
new
AssertionError
();
}
}
}
/**
**返回accessQueue的entry
**/
ReferenceEntry
<
K
,
V
>
getNextEvictable
()
{
for
(
ReferenceEntry
<
K
,
V
>
e
:
accessQueue
)
{
int
weight
=
e
.
getValueReference
().
getWeight
();
if
(
weight
>
0
)
{
return
e
;
}
}
throw
new
AssertionError
();
}O código acima é o código quando expulsamos Entry, podemos ver que a Fila de acesso está expulsando o chefe da fila. A estratégia de remoção geralmente é chamada quando os elementos no segmento mudam, como operações de inserção, operações de atualização e operações de carregamento de dados.
5.3 Atualização automática
A operação de atualização automática é relativamente simples de implementar no cache de goiaba. Você pode verificar diretamente se ela atende às condições de atualização e atualização.
5.4 Outros recursos
Existem alguns outros recursos no cache do Guava:
Referência fantasma
No cache Guava, a chave e o valor podem ser definidos para referências virtuais. Existem duas filas de referência no segmento:
final
@Nullable
ReferenceQueue
<
K
>
keyReferenceQueue
;
final
@Nullable
ReferenceQueue
<
V
>
valueReferenceQueue
;Essas duas filas são usadas para registrar as referências que são recicladas, cada uma registrando o hash de cada Entrada reciclada, de modo que, após a reciclagem, a Entrada anterior possa ser excluída por meio do valor de hash nessa fila.
Excluir ouvinte
No cache de goiaba, quando algum dado é eliminado, mas você não sabe se está desatualizado, expulso ou reciclado por causa do objeto referenciado fantasma? Neste momento, você pode chamar este método removeListener (RemovalListener listener) para adicionar um ouvinte para monitorar a eliminação de dados.Você pode registrar ou algum outro processamento, que pode ser usado para análise de eliminação de dados.
Todos os motivos de eliminação são registrados em RemovalCause: excluído pelo usuário, substituído pelo usuário, expirado, coleção expulsa, eliminado pelo tamanho.
Resumo do cache de goiaba
Leia com atenção o código-fonte do cache de goiaba e resuma, na verdade é um mapa LRU com bom desempenho e API rica. O desenvolvimento do cache do iQiyi também é baseado nisso, por meio do desenvolvimento secundário do cache de goiaba, ele pode atualizar o cache entre os serviços de aplicativos java.
6. Para o futuro - cafeína
A função do cache de goiaba é realmente muito poderosa e atende às necessidades da maioria das pessoas, mas é essencialmente uma camada de encapsulamento LRU, por isso empalidece em comparação com muitos outros algoritmos de eliminação melhores. O cache de cafeína implementa W-TinyLFU (uma variante do algoritmo LFU + LRU). A seguir está uma comparação das taxas de acerto de diferentes algoritmos: 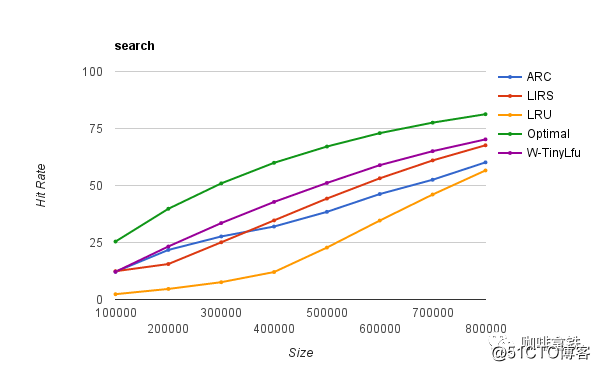
Ideal é a taxa de acerto mais ideal e LRU é de fato um irmão mais novo em comparação com outros algoritmos. E nosso W-TinyLFU é o mais próximo da taxa de acerto ideal. Claro, não apenas a taxa de acerto da cafeína é melhor do que o cache de goiaba, mas também o cache de goiaba em termos de taxa de transferência de leitura e gravação. 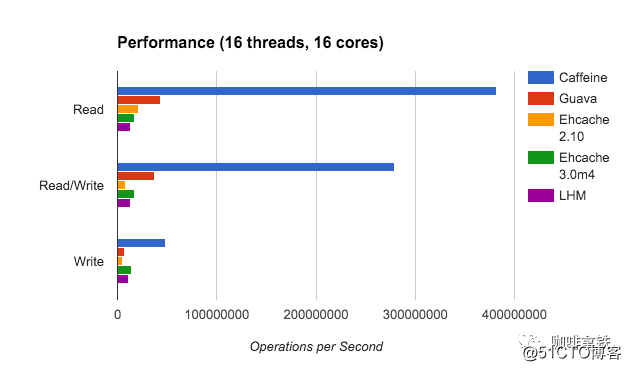
Neste momento, você definitivamente ficará curioso sobre por que a cafeína é tão incrível? Não se preocupe, vou te contar devagar.
6.1W-TinyLFU
Já disse do que se trata o LFU tradicional. Em LFU, enquanto a distribuição de probabilidade dos padrões de acesso a dados permanecer inalterada ao longo do tempo, a taxa de acerto pode se tornar muito alta. Ainda tomo iQiyi como exemplo. Por exemplo, um novo drama foi lançado e usamos LFU para armazená-lo em cache para ele. Esse novo drama foi acessado centenas de milhões de vezes nos últimos dias, e essa frequência de acesso também está registrada em nosso LFU. Centenas de milhões de vezes. Mas novos dramas sempre estarão desatualizados. Por exemplo, os primeiros episódios deste novo programa estão realmente desatualizados depois de um mês, mas o tráfego dele está realmente muito alto. Outros programas de TV não podem eliminar este novo programa, então aqui Este modelo tem limitações. Assim, várias variantes LFU surgiram, com base no período de tempo para a atenuação, ou a frequência em um determinado período de tempo. O mesmo LFU também usa espaço extra para registrar a frequência de cada acesso aos dados, mesmo que os dados não estejam no cache, eles precisam ser gravados, portanto, o espaço extra que precisa ser mantido é grande.
Imagine que criamos um hashMap para este espaço de manutenção. Cada item de dados será armazenado neste hashMap. Quando a quantidade de dados for particularmente grande, o hashMap será particularmente grande.
De volta ao LRU, nosso LRU não é tão inútil. O LRU pode lidar muito bem com situações repentinas de tráfego, pois não precisa acumular frequência de dados.
Portanto, W-TinyLFU combina LRU e LFU, bem como alguns recursos de outros algoritmos.
6.2 Registro de frequência
A primeira coisa a falar é o problema de registro de frequência.O objetivo que queremos alcançar é usar um espaço limitado para registrar a frequência de acesso que muda com o tempo. Usamos Count-Min Sketch para registrar nossa frequência de visita no W-TinyLFU, e esta também é uma variante do filtro Bloom. Conforme mostrado na figura abaixo: 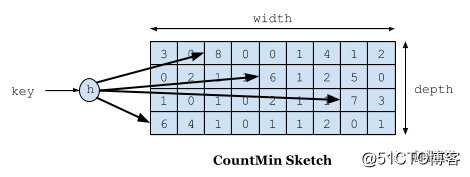
Se precisarmos registrar um valor, precisamos fazer o hash por meio de vários algoritmos de hash e, em seguida, adicionar +1 ao registro do algoritmo de hash correspondente. Por que precisamos de vários algoritmos de hash? Como este é um algoritmo de compressão, haverá conflitos. Por exemplo, criamos uma matriz longa e calculamos a posição do hash de cada dado. Por exemplo, Zhang San e Li Si, ambos podem ter o mesmo valor de hash. Por exemplo, se ambos forem 1, a posição de Long [1] aumentará a frequência correspondente. Zhang San visita 10.000 vezes, e Li Si visita 1 vez, e Long [ 1] Este local é 10: 1. Se você pegar a taxa de entrevista de Li Si, ela será retirada como 101, mas Li Si visitou apenas uma vez. Para resolver esse problema, usamos vários O algoritmo hash pode ser entendido como um conceito de uma matriz bidimensional longa [] []. Por exemplo, no primeiro algoritmo, Zhang San e Li Si estão em conflito, mas no segundo e terceiro algoritmos, há uma alta probabilidade de que eles não entrem em conflito, como um O algoritmo tem uma probabilidade de colisão de cerca de 1% e a probabilidade dos quatro algoritmos colidirem é de 1% elevado à quarta potência. Por meio desse modelo, quando tomamos a taxa de acesso de Li Si, tomamos o número de vezes que Li Si tem a menor frequência entre todos os algoritmos. Portanto, seu nome é Count-Min Sketch.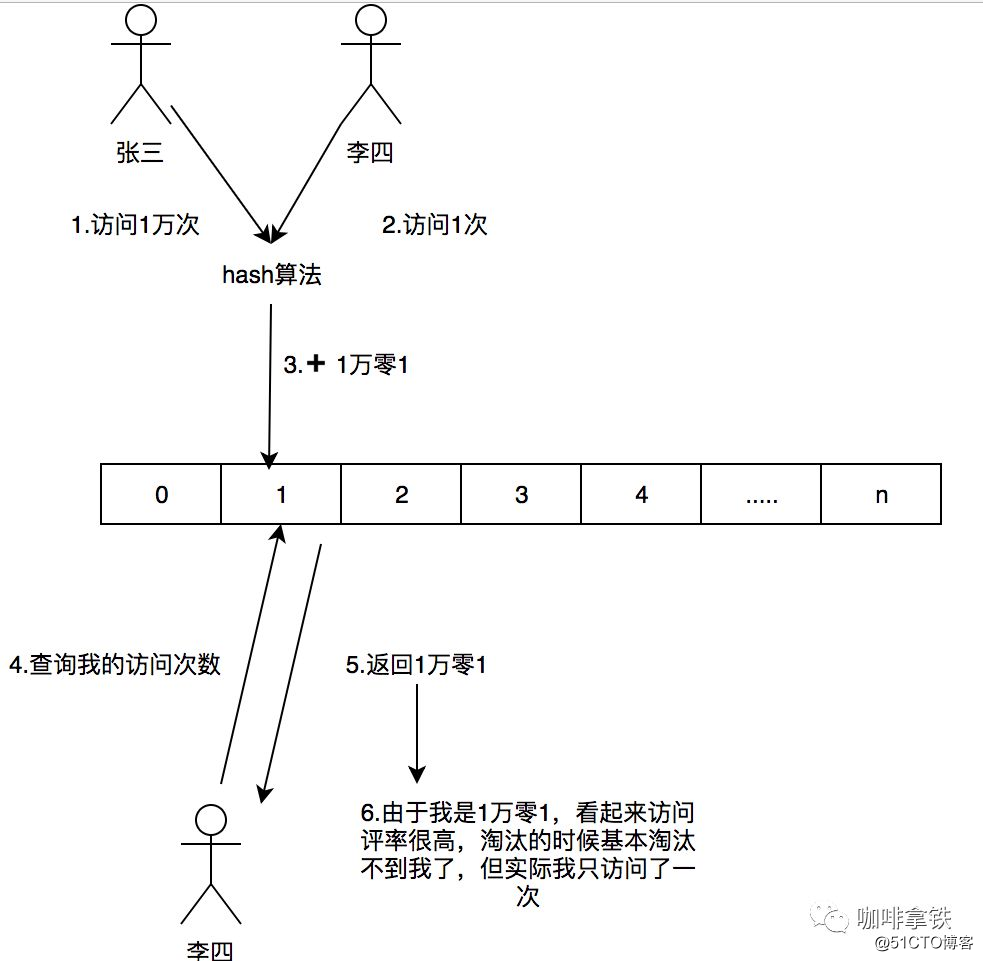
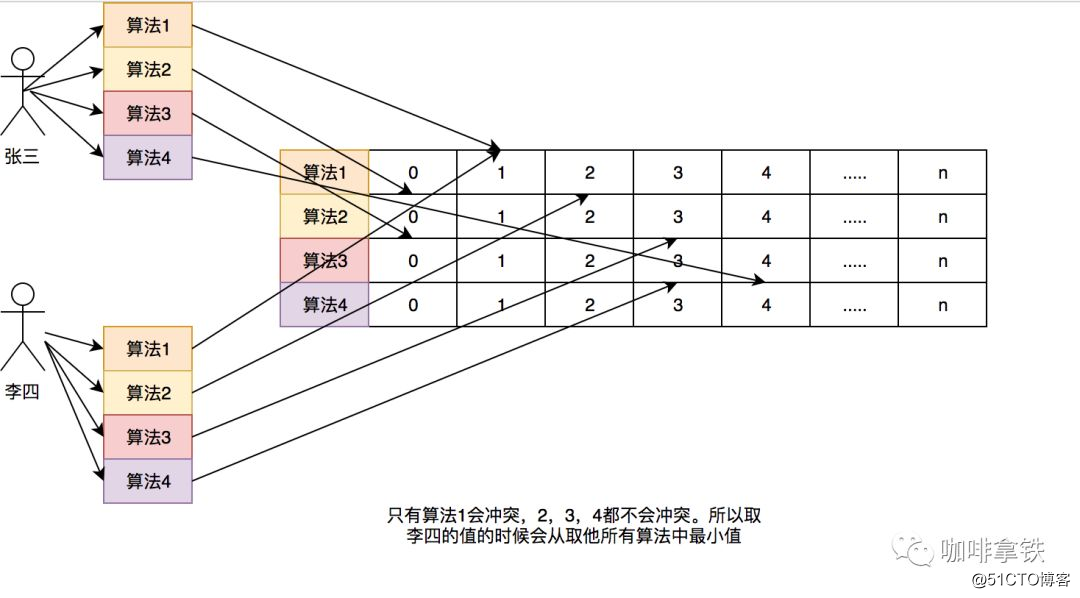
Aqui está uma comparação com o anterior: Um exemplo simples: Se um hashMap registra esta frequência, se eu tiver 100 dados, então este HashMap deve armazenar 100 frequências de acesso desses dados. Mesmo que a capacidade do meu cache seja 1, por causa das regras de Lfu, devo registrar a frequência de acesso de todos os 100 dados. Se houver mais dados, gravarei mais.
Em Count-Min Sketch, deixe-me falar diretamente sobre a implementação em cafeína (na classe FrequencySketch). Se o tamanho do seu cache for 100, ele irá gerar uma longa matriz cujo tamanho é a potência mais próxima de 2 a 100. , Que é 128. E esta matriz irá registrar nossa frequência de acesso. Na cafeína, a frequência regular máxima é 15, 15 bits binários 1111, 4 bits no total e o tipo longo é 64 bits. Portanto, cada tipo Long pode colocar 16 algoritmos, mas a cafeína não faz isso. Ele usa apenas quatro algoritmos hash. Cada tipo Long é dividido em quatro seções, e cada seção armazena as frequências dos quatro algoritmos. A vantagem disso é que ele pode reduzir ainda mais os conflitos de Hash. O hash de tamanho 128 original se torna 128X4.
A estrutura de um Long é a seguinte: 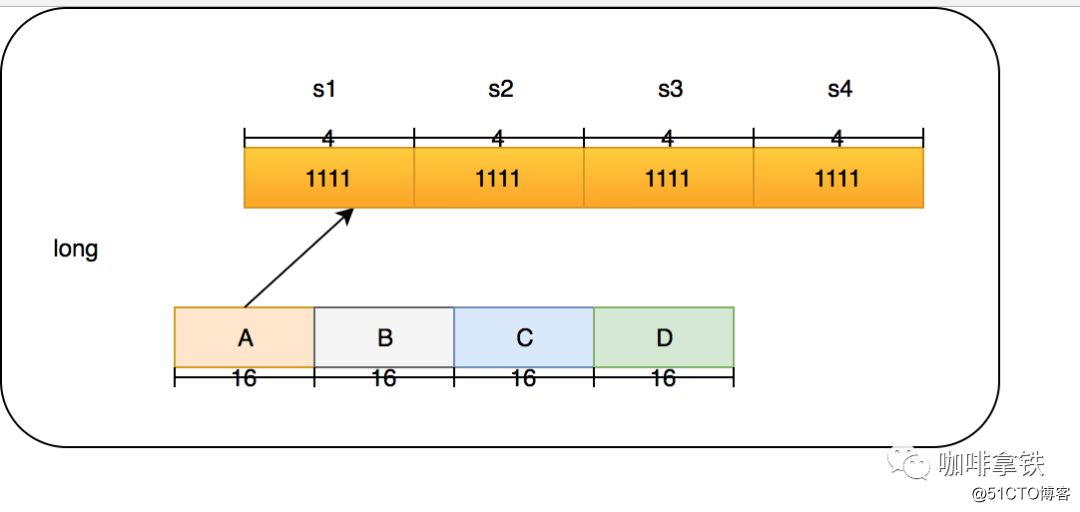
Nossos 4 segmentos são divididos em A, B, C, D, que vou chamá-los mais tarde. Eu chamo os quatro algoritmos em cada segmento de s1, s2, s3 e s4. Aqui está um exemplo: O que devo fazer se quiser adicionar uma frequência digital para acessar 50? Usamos size = 100 como exemplo aqui.
- Primeiro, determine em qual segmento está o hash de 50. Por meio do hash & 3, pode-se obter um número menor que 4. Supondo que o hash & 3 = 0, ele está no segmento A.
- Use outro algoritmo de hash para hash o hash 50 para obter a posição da matriz longa. Suponha que o algoritmo s1 seja usado para obter 1, o algoritmo s2 seja 3, o algoritmo s3 seja 4 e o algoritmo s4 seja 0.
- Em seguida, execute +1 na posição s1 na seção A de [1], que é referido como 1As1 mais 1, então 3As2 mais 1, 4As3 mais 1 e 0As4 mais 1.
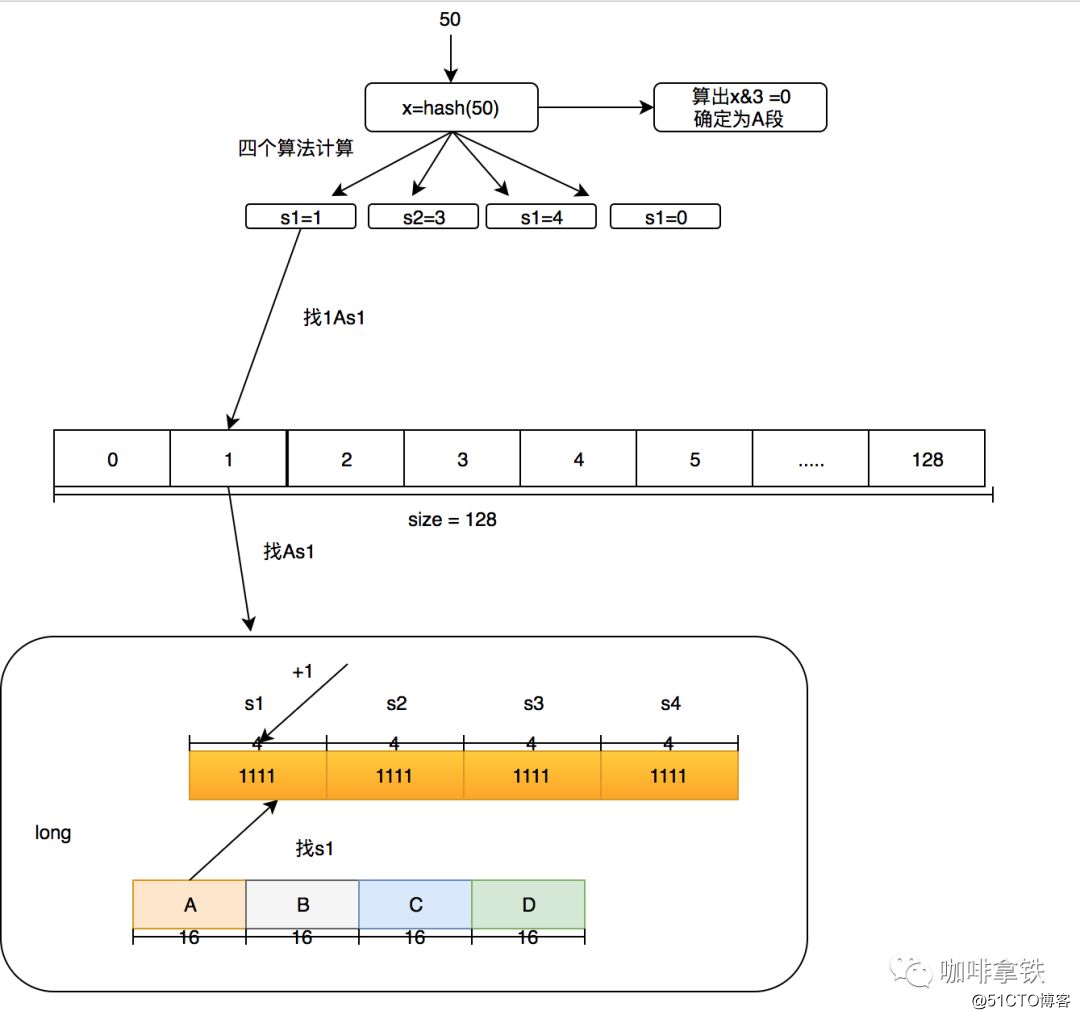
Neste momento, algumas pessoas vão questionar se a frequência máxima de 15 é muito pequena? Está tudo bem. Neste algoritmo, por exemplo, se o tamanho for igual a 100, se for globalmente aumentado 1000 vezes, será dividido globalmente por 2 atenuação. Após a atenuação, pode continuar a aumentar. Este algoritmo foi provado no artigo W-TinyLFU para ser melhor adaptado Frequência de acesso durante o período.
6.2 Desempenho de leitura e gravação
No cache de goiaba, dissemos que suas operações de leitura e gravação são mescladas com o processamento do tempo de expiração, ou seja, você também pode realizar operações de eliminação em uma operação Put, de forma que seu desempenho de leitura e gravação será afetado em certa medida, você pode ver a figura acima A cafeína explodiu o cache de goiaba em operações de leitura e gravação. Principalmente porque na cafeína as operações nesses eventos são realizadas de forma assíncrona. Ele envia os eventos para a fila. A estrutura de dados da fila aqui é RingBuffer. Se não tiver certeza, você pode ler este artigo. Você ainda está usando BlockingQueue? Leia este artigo para saber mais sobre o Disruptor. Em seguida, por meio do ForkJoinPool.commonPool () padrão, ou configure você mesmo o pool de threads, execute a operação de fila e, em seguida, execute as operações de eliminação e expiração subsequentes.
Claro, existem diferentes filas para leitura e gravação.Na cafeína, considera-se que há muito mais leituras de cache do que gravações, portanto, para operações de gravação, todos os threads compartilham um Ringbuffer.
Para operações de leitura com mais frequência do que operações de gravação, para reduzir ainda mais a competição, ele é equipado com um RingBuffer para cada thread: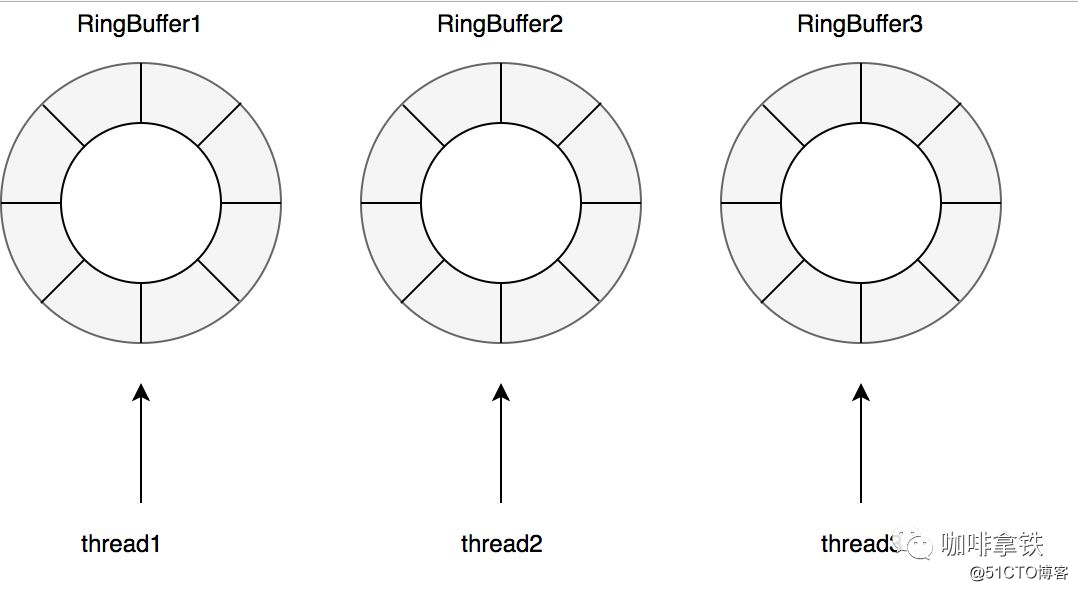
6.3 Estratégia de eliminação de dados
Todos os dados da cafeína estão em ConcurrentHashMap, que é diferente do cache de goiaba, que implementa uma estrutura semelhante ao ConcurrentHashMap por si só. Existem três filas LRU referenciadas por registros em cafeína:
-
Fila Eden: É especificado na cafeína que ela pode ter apenas% 1 da capacidade do cache. Se tamanho = 100, o tamanho efetivo desta fila é igual a 1. O que é registrado nessa fila são os dados recém-chegados, para evitar que o tráfego de burst seja eliminado por não haver frequência de acesso anterior. Por exemplo, se um novo drama é lançado, ele não tem frequência de acesso no início, de modo a evitar que seja eliminado por outros caches após ser lançado e se juntar a esta área. A área Eden, a área mais confortável e confortável, é difícil de ser eliminada por outros dados aqui.
-
Fila de teste: é chamada de fila de teste.Nesta fila, seus dados estão relativamente frios e serão eliminados em breve. O tamanho efetivo é tamanho menos eden menos protegido.
- Fila protegida: Nesta fila, você pode ter certeza de que não será eliminado por enquanto, mas não se preocupe, se não houver dados na fila de Probação ou os dados protegidos estiverem cheios, você também se deparará com a embaraçosa situação da eliminação. Claro, se você quiser se tornar esta fila, você precisa visitar a Probação uma vez, e ela será promovida à fila Protegida. O tamanho efetivo é (tamanho menos eden) X 80%. Se o tamanho = 100, será 79.
As três filas estão relacionadas da seguinte forma: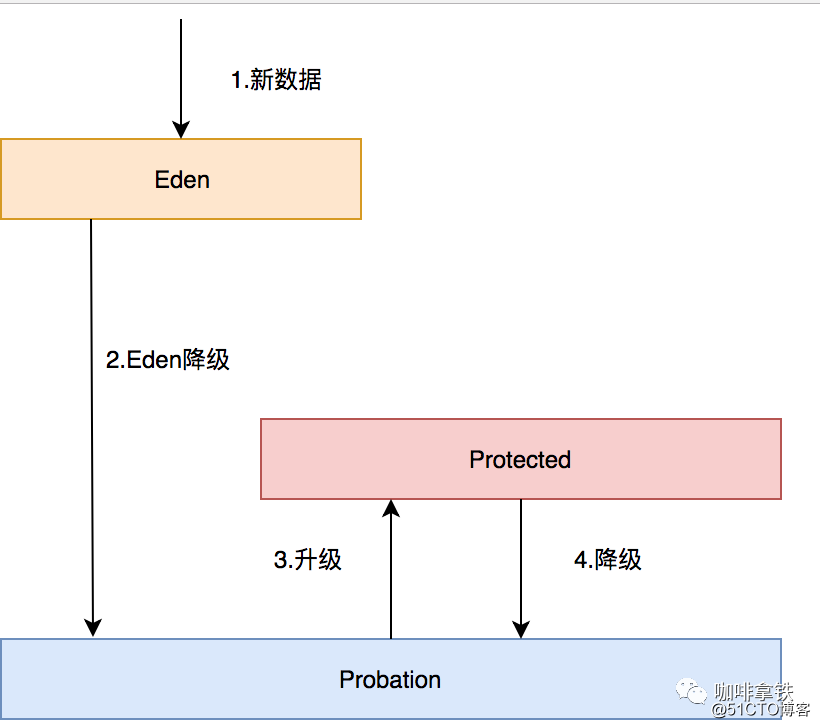
- Todos os novos dados irão para o Eden.
- O Éden está cheio, eliminado na Provação.
- Se um dos dados for acessado em Probation, esses dados serão atualizados para Protected.
- Se Protected estiver cheio, ele continuará a ser rebaixado para Probation.
Quando ocorrer a eliminação de dados, eles serão eliminados da Probação, e o líder da equipe de dados nesta fila será chamado de vítima. Esse líder de equipe deve ser o primeiro a entrar. De acordo com o algoritmo da fila LRU, ele realmente deve ser eliminado. Eliminado, mas aqui só pode ser chamado de vítima.Esta fila é uma fila de liberdade condicional, e o representante está prestes a executá-lo. Aqui, a ponta da equipe será retirada e chamada de candidatos, também chamados de *** ers. Aqui, a vítima fará uma PK com a vítima, e os seguintes julgamentos podem ser feitos a partir dos dados de frequência registrados em nosso Contagem-Minuto:
- Se a pessoa *** for maior que a vítima, a vítima é eliminada diretamente.
- Se a *** pessoa <= 5, a *** pessoa é eliminada diretamente. Essa lógica é explicada em suas notas:
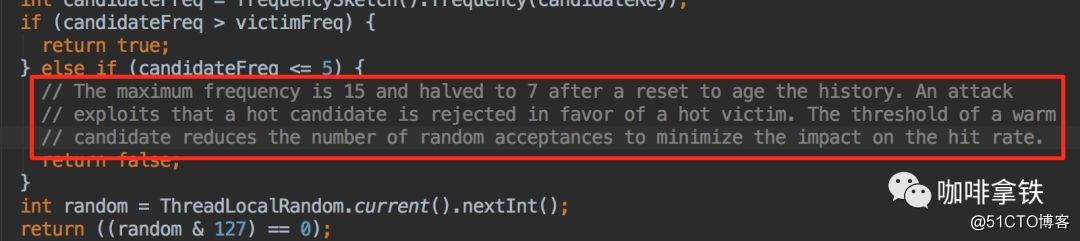
Ele acredita que definir um limite de aquecimento aumentará a taxa de acertos geral. - Em outros casos, ele será eliminado aleatoriamente.
6.4 Como usar
Para jogadores que estão familiarizados com Guava, se você está preocupado com os custos de troca, deve se preocupar com isso. A API do Caffeine baseia-se na API do Guava, e você pode descobrir que é basicamente o mesmo.
public
static
void
main
(
String
[]
args
)
{
Cache
<
String
,
String
>
cache
=
Caffeine
.
newBuilder
()
.
expireAfterWrite
(
1
,
TimeUnit
.
SECONDS
)
.
expireAfterAccess
(
1
,
TimeUnit
.
SECONDS
)
.
maximumSize
(
10
)
.
build
();
cache
.
put
(
"hello"
,
"hello"
);
}A propósito, mais e mais frameworks de código aberto abandonaram o cache Guava, como o Spring5. Nos negócios, eu mesmo comparei o cache de goiaba com a cafeína e finalmente escolhi a cafeína, que também tem bons resultados online. Portanto, não se preocupe que a cafeína seja imatura e ninguém a use.
7. Finalmente
Este artigo fala principalmente sobre o caminho de cache de iQiyi e uma história de cache local (desde os tempos antigos até o futuro), bem como os princípios básicos de cada tipo de cache. Claro, não é suficiente usar bem o cache, por exemplo, como o cache local é atualizado de forma síncrona após mudanças em outros lugares, cache distribuído, cache multinível, etc. Uma seção será escrita posteriormente para apresentar como fazer bom uso do cache. Para os princípios do cache de goiaba e da cafeína, também irei reservar um tempo para escrever a análise do código-fonte desses dois mais tarde. Se amigos interessados podem seguir a conta pública para verificar os artigos atualizados pela primeira vez.
Por fim, faça um anúncio. Se você acha que este artigo tem um artigo para você, pode seguir minha conta técnica pública. Recentemente, o autor reuniu muitos dos mais recentes materiais de aprendizagem, vídeos e entrevistas, e você pode recebê-los depois de prestar atenção. Sua atenção e encaminhamento são O maior apoio para mim, O (∩_∩) O
