Código-fonte deste artigo: GitHub · clique aqui || GitEE · clique aqui
1. Mecanismo de trabalho
1. Descrição básica
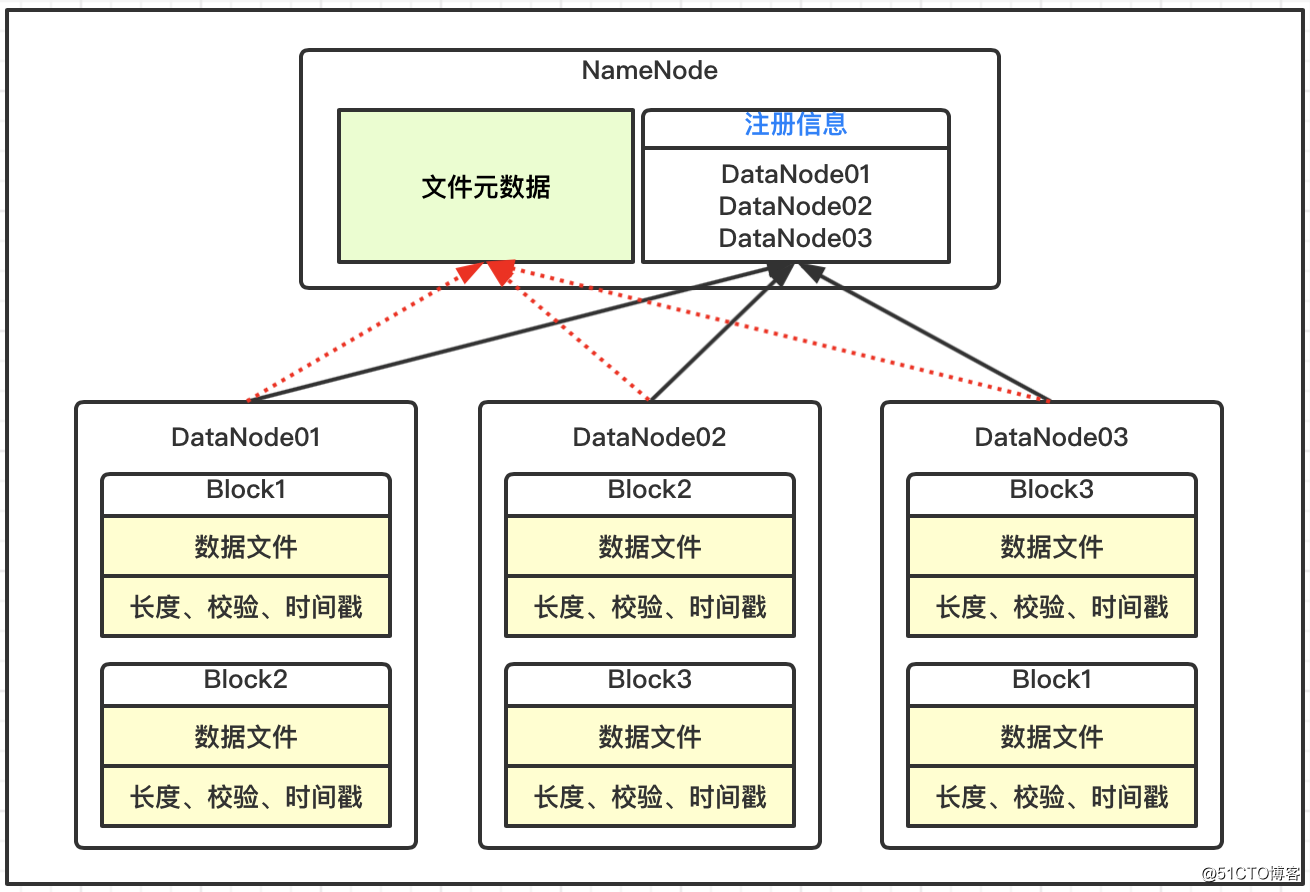
Os blocos de dados no DataNode são armazenados no disco na forma de arquivos, incluindo dois arquivos, um são os próprios dados e o outro são os metadados do bloco de dados, incluindo comprimento, soma de verificação e registro de data e hora;
Depois que o DataNode é iniciado, ele se registra no serviço NameNode e relata periodicamente todas as informações de metadados do bloco de dados para o NameNode;
Há um mecanismo de pulsação entre o DataNode e o NameNode. A cada 3 segundos, o resultado é retornado com o comando de execução do NameNode para o DataNode, como replicação e exclusão de dados. Se a pulsação do DataNode não for recebida por mais de 10 minutos, o nó é considerado indisponível.
2. Duração personalizada
Por meio do arquivo de configuração hdfs-site.xml, modifique a duração do tempo limite e a pulsação. A unidade de heartbeat.recheck.interval é milissegundos e a unidade de dfs.heartbeat.interval é segundos.
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>600000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>6</value>
</property>3. O novo nó está online
Os nós da máquina atual são hop01, hop02, hop03 e um novo nó hop04 é adicionado nesta base.
Os passos básicos
Obtenha o ambiente hop04 com base no clone do nó de serviço atual;
Modifique a configuração básica do Centos7 e exclua os dados e arquivos de log;
Inicie o DataNode para associar ao cluster;
4. Configuração de vários diretórios
A configuração sincroniza os serviços no cluster, formatados para iniciar hdfs e yarn, e arquivos carregados para teste.
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/data01,file:///${hadoop.tmp.dir}/dfs/data02</value>
</property>Dois, configuração de lista negra e branca
1. Configuração da lista de permissões
Configure a lista de desbloqueio e distribua a configuração para o serviço de cluster;
[root@hop01 hadoop]# pwd
/opt/hadoop2.7/etc/hadoop
[root@hop01 hadoop]# vim dfs.hosts
hop01
hop02
hop03Configure hdfs-site.xml, que é distribuído para o serviço de cluster;
<property>
<name>dfs.hosts</name>
<value>/opt/hadoop2.7/etc/hadoop/dfs.hosts</value>
</property>Atualizar NameNode
[root@hop01 hadoop2.7]# hdfs dfsadmin -refreshNodesAtualizar ResourceManager
[root@hop01 hadoop2.7]# yarn rmadmin -refreshNodes2. Configuração da lista negra
Configure a lista negra e distribua a configuração para o serviço de cluster;
[root@hop01 hadoop]# pwd
/opt/hadoop2.7/etc/hadoop
[root@hop01 hadoop]# vim dfs.hosts.exclude
hop04Configure hdfs-site.xml, que é distribuído para o serviço de cluster;
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/hadoop2.7/etc/hadoop/dfs.hosts.exclude</value>
</property>Atualizar NameNode
[root@hop01 hadoop2.7]# hdfs dfsadmin -refreshNodesAtualizar ResourceManager
[root@hop01 hadoop2.7]# yarn rmadmin -refreshNodes3. Arquivamento de arquivos
1. Descrição básica
As características do armazenamento HDFS são adequadas para arquivos grandes com dados massivos. Se cada arquivo for muito pequeno, uma grande quantidade de informações de metadados será gerada, ocupando muita memória, e ficará lento quando NaemNode e DataNode interagirem.
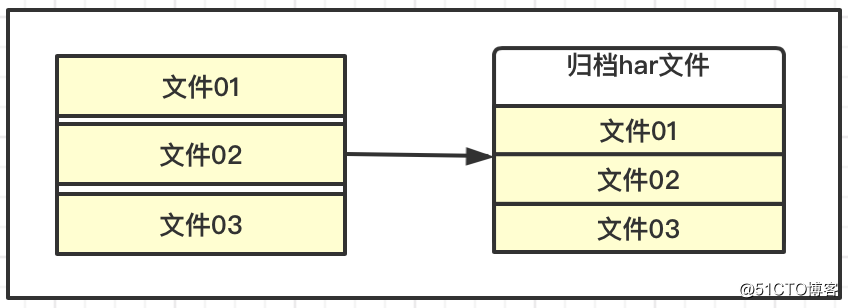
O HDFS pode arquivar e armazenar alguns arquivos pequenos, que podem ser entendidos como armazenamento compactado, o que reduz o consumo de NameNode e reduz a carga de interação.Ao mesmo tempo, também permite o acesso a pequenos arquivos arquivados para melhorar a eficiência geral.
2. Processo de operação
Crie dois diretórios
# 存放小文件
[root@hop01 hadoop2.7]# hadoop fs -mkdir -p /hopdir/harinput
# 存放归档文件
[root@hop01 hadoop2.7]# hadoop fs -mkdir -p /hopdir/haroutputCarregar arquivo de teste
[root@hop01 hadoop2.7]# hadoop fs -moveFromLocal LICENSE.txt /hopdir/harinput
[root@hop01 hadoop2.7]# hadoop fs -moveFromLocal README.txt /hopdir/harinputOperação de arquivo
[root@hop01 hadoop2.7]# bin/hadoop archive -archiveName output.har -p /hopdir/harinput /hopdir/haroutputVer arquivos de arquivo
[root@hop01 hadoop2.7]# hadoop fs -lsr har:///hopdir/haroutput/output.har
Desta forma, os pequenos blocos de arquivos originais podem ser excluídos.
Desarquivar arquivos
# 执行解除
[root@hop01 hadoop2.7]# hadoop fs -cp har:///hopdir/haroutput/output.har/* /hopdir/haroutput
# 查看文件
[root@hop01 hadoop2.7]# hadoop fs -ls /hopdir/haroutputQuarto, o mecanismo da lixeira
1. Descrição básica
Se a função de lixeira estiver ativada, os arquivos excluídos podem ser restaurados dentro de um tempo especificado para evitar a exclusão acidental de dados. A implementação específica dentro do HDFS é iniciar um thread em segundo plano Emptier no NameNode. Este thread gerencia e monitora especificamente os arquivos na lixeira do sistema. Os arquivos que são colocados na lixeira e excedem seu ciclo de vida serão excluídos automaticamente.
2. Ligue a configuração
Essa configuração precisa ser sincronizada com todos os serviços do cluster;
[root@hop01 hadoop]# vim /opt/hadoop2.7/etc/hadoop/core-site.xml
# 添加内容
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>fs.trash.interval = 0, significa que o mecanismo da lixeira está desativado e = 1 significa que está ativado.
Cinco, endereço do código-fonte
GitHub·地址
https://github.com/cicadasmile/big-data-parent
GitEE·地址
https://gitee.com/cicadasmile/big-data-parentLeitura recomendada: sistema de programação de acabamento
| Número de série | Nome do Projeto | Endereço GitHub | Endereço GitEE | Recomendado |
|---|---|---|---|---|
| 01 | Java descreve padrões de design, algoritmos e estruturas de dados | GitHub · clique aqui | GitEE · Clique aqui | ☆☆☆☆☆ |
| 02 | Fundação Java, simultaneidade, orientado a objetos, desenvolvimento web | GitHub · clique aqui | GitEE · Clique aqui | ☆☆☆☆ |
| 03 | Explicação detalhada do caso do componente básico do microsserviço SpringCloud | GitHub · clique aqui | GitEE · Clique aqui | ☆☆☆ |
| 04 | Caso abrangente de combate real da arquitetura de microsserviço SpringCloud | GitHub · clique aqui | GitEE · Clique aqui | ☆☆☆☆☆ |
| 05 | Introdução ao aplicativo básico do framework SpringBoot para avançado | GitHub · clique aqui | GitEE · Clique aqui | ☆☆☆☆ |
| 06 | O framework SpringBoot integra e desenvolve middleware comum | GitHub · clique aqui | GitEE · Clique aqui | ☆☆☆☆☆ |
| 07 | Caso básico de gerenciamento de dados, distribuição, design de arquitetura | GitHub · clique aqui | GitEE · Clique aqui | ☆☆☆☆☆ |
| 08 | Série de Big Data, armazenamento, componentes, computação e outras estruturas | GitHub · clique aqui | GitEE · Clique aqui | ☆☆☆☆☆ |