Processo de inicialização de cluster de análise de princípio de Elasticsearch
Vamos começar com o processo de inicialização, primeiro olhe como todo o cluster é iniciado em um nível macro, como o status do cluster muda de vermelho para verde, sem o código envolvido, e então analise os processos de outros módulos.
Neste livro, refere-se ao processo de inicialização do cluster de cluster completamente Lançar processo de reinicialização, para passar durante a eleição realizada nó mestre, distribuição fragmentada (distribuição principal e fatia auxiliar), a recuperação de dados de índice e outra etapa importante para compreender os princípios e detalhes dos quais, para É importante resolver ou evitar problemas como cérebro dividido, ausência de propriedade, recuperação lenta e perda de dados que podem ser encontrados durante a manutenção do cluster .
O processo geral de inicialização do cluster é mostrado na figura a seguir:
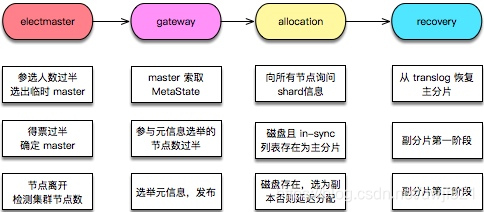
1. Eleição do nó mestre
Supondo que vários nós estejam sendo inicializados, a primeira coisa que o cluster inicia é selecionar um da lista de máquinas ativas conhecidas como o nó mestre.O processo após a eleição é acionado pelo nó mestre.
O algoritmo de seleção mestre de ES é baseado na melhoria do algoritmo de Bully. A ideia principal é classificar os IDs do nó e tomar o nó com o maior valor de ID como mestre, e cada nó executa este processo . É muito simples? O objetivo de selecionar o mestre é determinar o único nó mestre. Os iniciantes podem pensar que o nó mestre escolhido deve conter as informações de metadados mais recentes. Na verdade, esse problema é dividido em duas etapas na implementação: primeiro, determine o único que é reconhecido por todos. O nó mestre, em seguida, encontre uma maneira de copiar os metadados da máquina mais recentes para o nó mestre escolhido .
O algoritmo de eleição simples com base na classificação de ID de nó tem três condições adicionais acordadas:
-
Os participantes precisam ser mais da metade e, depois de atingir o quorum (maioria), um líder temporário é selecionado .
Por que é temporário? Cada nó executa o algoritmo de classificação para obter o valor máximo e os resultados não são necessariamente os mesmos. Por exemplo, o cluster tem 5 hosts e os IDs de nó são 1, 2, 3, 4 e 5. Quando há uma grande diferença na partição de rede ou na velocidade de inicialização do nó, a lista de nós vista pelo nó 1 é 1, 2, 3, 4 e 4 é selecionada; a lista de nós vista pelo nó 2 é 2, 3, 4 e 5, e De 5. Os resultados são inconsistentes, resultando na segunda restrição abaixo.
-
Mais da metade dos votos são necessários .
Quando um nó é selecionado como o nó mestre, deve-se considerar que mais da metade dos nós que se juntaram a ele podem ser confirmados como o mestre. Resolva o primeiro problema.
-
Quando um evento de saída de nó é detectado, deve-se avaliar se o número atual de nós é mais da metade .
Se o quorm não for alcançado, desista do status Mestre e reingresse no cluster. Se você não fizer isso, imagine a seguinte situação: Suponha que um cluster de 5 máquinas produza uma partição de rede, 2 máquinas em um grupo A e 3 máquinas em um grupo B. Antes que a partição seja gerada, o mestre está localizado em A. Neste momento, um grupo de três nós elegerá o mestre novamente com sucesso, resultando em um mestre duplo, comumente conhecido como cérebro dividido .
O cluster não sabe quantos nós ele tem. O valor de quornum é lido na configuração. Precisamos definir os itens de configuração:
discovery.zen.minimun_master_nodes: 3
2. Metainformação do cluster eleitoral
O Mestre eleito não tem nada a ver com a velhice da meta informação do cluster. Como sua primeira tarefa é eleger meta-informação , deixe cada nó enviar a meta-informação armazenada em cada nó, determine a meta-informação mais recente de acordo com o número da versão e, em seguida, transmita essa informação , todos os nós neste cluster têm o mais recente Meta informação.
A eleição de meta informações de cluster inclui dois níveis: nível de cluster e nível de índice . Não inclui informações sobre em qual nó o fragmento está armazenado. Esse tipo de informação está sujeito ao armazenamento em disco do nó e precisa ser relatado . porque? Como o processo de leitura e gravação não passa pelo Master, o Master não conhece as diferenças diretas de dados de cada cópia do shard. O HDFS também possui um mecanismo semelhante e as informações do bloco dependem do relatório do DataNode.
Para consistência do cluster, o número de meta-informação que participa da eleição precisa ser mais da metade, e a regra principal para publicar o status do cluster também é mais da metade do número de nós esperando para ser publicado com sucesso.
Durante o processo de eleição, nenhum pedido de adesão de novo nó é aceito.
Após a conclusão da eleição de meta-informação do cluster, o Mestre anuncia o primeiro status do cluster e, em seguida, começa a eleger meta-informação no nível do shard.
3. Processo de alocação (alocação) de fragmentos
A eleição de meta-informação de nível de shard e a construção da tabela de roteamento de conteúdo são concluídas no módulo de alocação. No estágio inicial, todos os shards estão no estado ** UNASSIGNED (unassigned unassigned) **. O ES determina qual fragmento está localizado em qual nó por meio do processo de alocação e reconstrói a tabela de roteamento de conteúdo. Nesse ponto, a primeira coisa a fazer é alocar o shard principal.
3.1 Selecione o fragmento principal
Agora vamos ver como um determinado segmento principal [website] [0] é alocado. Todo o trabalho de alocação é feito pelo Master. Neste momento, o Master não sabe onde está o shard principal. Ele pergunta a todos os nós do cluster: Todos me enviam a meta informação do shard [website] [0]. Em seguida, o Master espera o retorno de todos os pedidos. Normalmente, ele tem as informações do shard, e então seleciona um shard como shard principal de acordo com uma determinada estratégia. A eficiência é um pouco baixa? A quantidade de tais consultas = o número de fragmentos * o número de nós. Portanto, podemos controlar melhor o tamanho total do fragmento para não ser muito grande.
Agora, existem várias informações sobre o fragmento [site] [0], o número específico depende de quantas cópias são definidas. Agora, considere qual fatia usar como fatia principal. As versões abaixo do ES 5.x são determinadas comparando o número da versão das meta-informações no nível do shard. No caso de várias cópias, considerando que se apenas uma informação de fragmento for relatada, ela definitivamente será selecionada como o fragmento principal, mas talvez os dados não sejam os mais recentes e o nó com um número de versão maior ainda não tenha sido iniciado. Para resolver esse problema, o ES 5.x começou a implementar uma nova estratégia: definir um UUID para cada fragmento e, em seguida, registrar qual fragmento é o mais recente nas metainformações em nível de cluster , porque o ES grava a pontuação principal primeiro Em seguida, o nó do shard principal encaminha a solicitação para gravar o shard de réplica, de modo que o nó onde o shard principal está localizado deve ser o mais recente. Se houver falha no encaminhamento, o nó principal precisará excluir esse nó. Portanto, a partir do ES 5.x, o processo de eleição do shard primário é determinar o shard primário por meio da " lista de shard primário mais recente " registrada nas meta-informações do cluster : ele existe nas informações do relatório e também nesta lista .
Se o cluster estiver configurado:
cluster.routing.allocation.enable: none
A alocação de shards é proibida e o cluster ainda forçará a alocação de shards primários. Portanto, quando as opções acima são definidas, o status do cluster após a reinicialização é Amarelo em vez de Vermelho.
3.2 Selecione Vice Shard
Após a eleição do shard primário ser bem-sucedida, uma cópia é selecionada como shard secundário das informações do shard resumidas no processo anterior. Se as informações de resumo não existirem, uma nova cópia será alocada. A operação depende do item de configuração de atraso:
indexunassigned.node_left.delayed_timeout: 100000
O maior cluster em nosso ambiente on-line tem mais de 100 nós. Não é incomum perder nós. Em muitos casos, isso não pode ser tratado na primeira vez. Esse atraso geralmente é configurado em dias.
Finalmente, o nó recém-iniciado tem permissão para ingressar no cluster durante o processo de alocação.
4. índice de recuperação
Depois que a alocação de shard é bem-sucedida, ele entra no processo de recuperação. A recuperação do shard primário não espera que seus shards de réplica sejam alocados com êxito antes de iniciar a recuperação. Eles são processos independentes, mas a recuperação dos shards de réplica não é iniciada até que o shard primário seja restaurado.
Por que precisamos de recuperação? Para o fragmento primário, pode haver alguns dados que não tiveram tempo de esvaziar; para os fragmentos de réplica: um é que não há limpeza e o outro é que o fragmento primário foi gravado e os fragmentos de réplica não tiveram tempo de gravar, os dados de fragmentos primários e secundários Inconsistente.
4.1 Recuperação de shard primário
Uma vez que cada operação de gravação gravará um log de transações (translog), qual operação é gravada no log de transações e os dados relacionados. Portanto, o translog após o último envio (um envio de Lucene é um processo de flashing fsync) é reproduzido, o índice Lucene é construído e a recuperação do shard principal é concluída.
4.2 Recuperação de shard secundário
A recuperação de fragmentos secundários é mais complicada. Na iteração da versão do ES, a estratégia de recuperação de fragmentos secundários foi bastante ajustada.
O fragmento secundário precisa ser restaurado para ser consistente com o fragmento primário e, ao mesmo tempo, novas operações de índice são permitidas durante a restauração. Na versão 6.0 atual, a recuperação é realizada em duas etapas.
-
phase1: No nó onde o shard primário está localizado, adquira o bloqueio de retenção translog. A partir da aquisição do bloqueio de retenção, o translog será retido sem ser afetado por sua descarga. Em seguida, chame a interface Lucene para obter um instantâneo do fragmento, que são os dados fragmentados no disco que foram liberados. Copie esses dados de shard para o nó de réplica. Antes da fase 1 ser concluída, o nó do shard secundário será notificado para iniciar o mecanismo. Antes da fase 2, o shard de réplica pode processar solicitações de gravação normalmente.
-
phase2: Faça um instantâneo de tanslog.Este instantâneo contém os novos índices da fase1 para a execução do instantâneo translog. Envie esses translogs para o nó onde os fragmentos de réplica estão localizados para reprodução.
Devido à necessidade de oferecer suporte a novas operações de gravação durante a recuperação (para tornar o ES mais utilizável), os seguintes problemas precisam ser focados durante esses dois estágios:
- Integridade dos dados do fragmento : como garantir que o fragmento da cópia não perca dados? O instantâneo tanslog do segundo estágio inclui todas as novas operações no primeiro estágio. Então, durante a execução do primeiro estágio, se ocorrer um ** "commit Lucene" (liberando os dados no buffer de gravação do sistema de arquivos para o disco e limpando o translog) , o que fazer se o translog for limpo? Antes do ES 2.0, a operação de atualização era bloqueada para que todos os translogs fossem mantidos. A partir da versão 2.0, a fim de evitar que esta abordagem gere um translog muito grande, o conceito de translog.view é introduzido, a criação de uma visão pode obter todas as operações subsequentes. A partir da versão 6.0, translog.veiw foi removido. Introduzido o conceito TranslogDetetionPolicy **, será necessário um instantâneo do translog para manter o translog não limpo . Isso permite o Lucene Commit na primeira fase .
- Consistência de dados : antes do ES 2.0, o processo de recuperação de shard secundário tinha três estágios. O terceiro estágio bloquearia novas operações de índice e transmitiria o translog recém-adicionado durante o segundo estágio. Este tempo é muito curto. Desde a versão 2.0, o terceiro estágio foi excluído e não há processo de bloqueio de gravação durante a recuperação. No nó de shard secundário, ao reproduzir o translog, os erros de tempo e conflitos entre a operação de gravação entre a fase1 e a fase2 e a operação de reprodução da fase2 são manipulados por meio do processo de gravação e o número da versão é comparado ao filtro das operações expiradas.
Desta forma, as operações com erros de tempo serão ignoradas. Para um documento específico, apenas a operação mais recente tem efeito, garantindo que os fragmentos primários e secundários sejam consistentes.
O primeiro estágio é particularmente demorado porque precisa extrair toda a quantidade de dados do shard principal. No ES 6.x, o primeiro estágio é otimizado novamente: marque cada operação. Em operações de gravação normais, cada operação de gravação bem-sucedida é atribuída a um número de sequência, e o intervalo de diferença pode ser calculado comparando os números de sequência. Em termos de implementação, um ponto de verificação global e um ponto de verificação local são adicionados. O fragmento principal é responsável por manter o ponto de verificação global. Isso significa que todos os fragmentos foram gravados na posição deste número de sequência. O ponto de verificação local representa a última posição em que o fragmento atual foi gravado com sucesso. Na recuperação, o intervalo de dados ausentes é calculado comparando os dois números de sequência e, em seguida, reproduzindo esta parte por meio de translog Os dados e o translog os reterão por mais tempo.
Portanto, há duas oportunidades para pular a fase 1 da recuperação do fragmento secundário:
- Com base em SequenceNumber, recupere os dados do translog do nó de shard primário
- Os fragmentos primários e secundários têm o mesmo syncid e o mesmo número de documento, portanto, a fase 1 pode ser ignorada.
5. Resumo
Quando o segmento primário de um índice é alocado com sucesso, as operações de gravação para este segmento são permitidas. Quando todos os shards primários de um índice são alocados com êxito, o índice se torna Amarelo. Quando os shards primários de todos os índices são alocados com êxito, todo o cluster se torna Amarelo. Quando um índice é alocado com sucesso, o índice se torna Verde. Quando os fragmentos de índice de todos os índices são alocados com êxito, todo o cluster se torna Verde.
A recuperação de dados do índice é o processo mais longo. Quando o número total de shards atinge o nível 100.000, o tempo para os clusters de versões anteriores a 6.x mudarem de vermelho para verde pode levar horas. A cópia no ES 6.X permite a recuperação do translog local é uma grande melhoria, evitando que o nó onde o shard primário contínuo está localizado extraia a quantidade total de dados, economizando muito tempo para o processo de recuperação.
Quando o volume atinge o nível 100.000, o tempo antes que o cluster da versão 6.x mude de vermelho para verde pode levar horas. A cópia no ES 6.X permite a recuperação do translog local é uma grande melhoria, evitando que o nó onde o shard primário contínuo está localizado extraia a quantidade total de dados, economizando muito tempo para o processo de recuperação.
6. Siga-me
Pesquise a conta pública do WeChat: o caminho para uma arquitetura Java forte
