Preparação ambiental:
Instalado com antecedência, o pycharm
abre Arquivo ——> Configurações ——> Projext ——> Project Interpriter
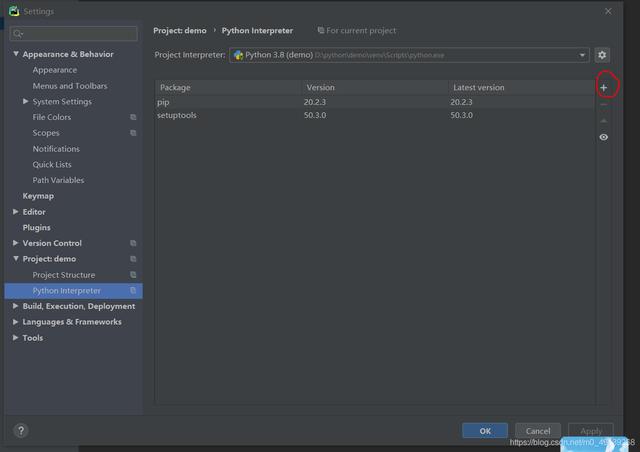
Clique no sinal de mais (no círculo vermelho na imagem)
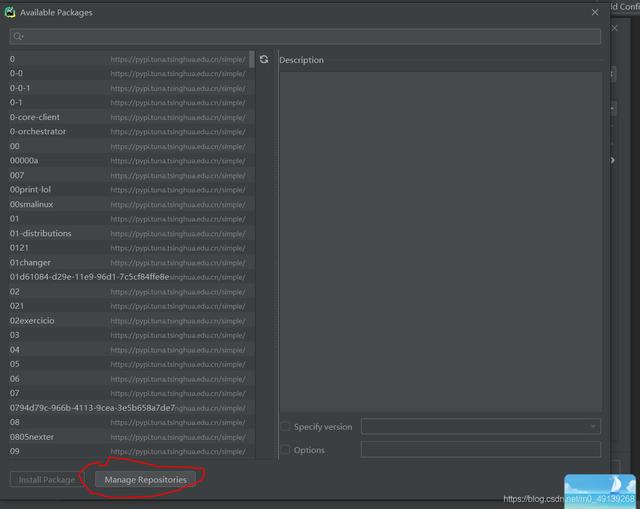
Clique no botão no círculo vermelho
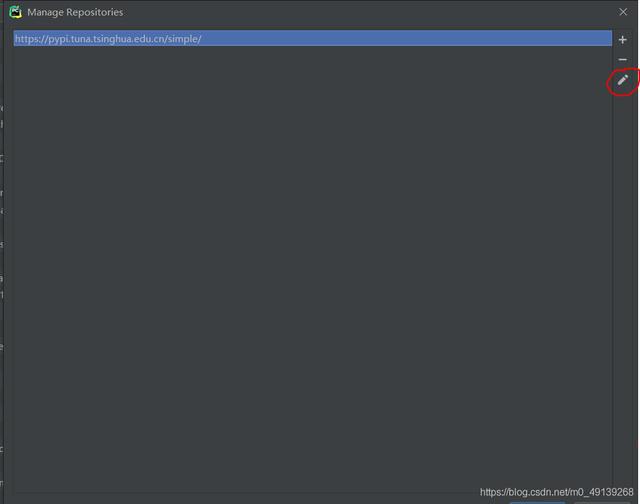
Selecione o primeiro, clique no lápis e substitua o link original por (ele foi substituído aqui):
https://pypi.tuna.tsinghua.edu.cn/simple/ Após
clicar em OK, digite requests-html e pressione Enter para
selecionar Clique em Instalar Pacote após requisições-html

Espere que a instalação tenha sucesso, feche
Analisando o código-fonte da página da web
Conteúdo de exemplo:
rastreie o conteúdo desejado de todos os artigos de um determinado blogueiro.
Exemplo de fundo:
obtenha o título, o tempo e o volume de leitura de cada artigo de todos os artigos do blogger (https://me.csdn.net/weixin_44286745).
- Importe o método HTMLSession em requests_html e crie seu objeto
from request_html import HTMLSession session = HTMLSession () 123
- Use get request para que o site seja rastreado e obtenha o código-fonte da página.
html = session.get ("https://me.csdn.net/weixin_44286745") .html
12
- Encontre todos os artigos
allBlog = html.xpath ("// dl [@ class = 'tab_page_list']")
1
- Digite a página inicial do site (neste exemplo: https://me.csdn.net/weixin_44286745)
- Clique com o botão direito no espaço em branco do artigo para localizar o rótulo deste artigo
- Opere como outros artigos e, a seguir, encontre as tags comuns de todos os artigos (a classe de todos os artigos aqui é 'my_tab_page_con')
- O xpath pode percorrer as várias tags e atributos do html para localizar e extrair as informações de que precisamos.
- Análise da página da Web para obter o título, volume de leitura, data.
para i em allBlog:
title = i.xpath ("dl / dt / h3 / a") [0] .text
views = i.xpath ("// div [@ class = 'tab_page_b_l fl']") [0] .text
date = i.xpath ("// div [@ class = 'tab_page_b_r fr']") [0] .text
print (title + '' + views + '' + date)
12345
Análise da web:
- Como existem vários artigos, eles são obtidos separadamente usando um loop for, e o código acima obteve todos os artigos, então, significa um artigo
- A segunda linha de código para obter o título do artigo é semelhante a obter o artigo. Coloque o mouse sobre o título e clique com o botão direito para verificar. Como o artigo tem apenas um título, você pode usar o caminho absoluto para chegar à posição do título camada por etiqueta.
- O que xpath retorna é uma lista, queremos a primeira, então precisamos adicionar um subscrito (há apenas um elemento na lista), e o que queremos produzir é o texto, então o texto obtém o texto.
- Leitura de volume e tempo também são operações repetidas
- Você pode usar um caminho relativo ou absoluto. Geralmente, um caminho relativo é usado e o formato é modelado após o código.
- A quinta linha de código é gerada sempre que as informações sobre um artigo são obtidas e todas as informações podem ser obtidas após a travessia.
Código completo:
from request_html import HTMLSession
session = HTMLSession ()
html = session.get ("https://me.csdn.net/weixin_44286745") .html
allBlog = html.xpath ("// dl [@ class = 'tab_page_list']" )
para i em allBlog:
title = i.xpath ("dl / dt / h3 / a") [0] .text
views = i.xpath ("// div [@ class = 'tab_page_b_l fl']") [0 ] .text
date = i.xpath ("// div [@ class = 'tab_page_b_r fr']") [0] .text
print (title + '' + views + '' + date)
1234567891011121314
Você mesmo pode rastrear outras coisas, como fotos de artigos, experimente! ! !
Continua
Solicitar via html
Clique aqui para obter o código completo do projeto