Uma pequena nota sobre os canais de comunicação entre os processos Linux
1. Tubo sem nome
O pipe é um mecanismo básico de comunicação entre processos, que atua entre processos relativos para completar a transferência de dados. Um tubo pode ser criado chamando a função do sistema de tubo. O protótipo da função do tubo é o seguinte:
#include <unistd.h>
int pipe(int pipefd[2]);
pipefd[0]:读端
pipefd[1]:写端
return: 0 成功 -1 失败
Algumas características de tubos sem nome:
- O pipeline parece que um arquivo aberto é inserido aqui no programa do usuário, e lê e grava dados neste arquivo por meio de leitura (filedes [0]) ou gravação (filedes [1])
- Em essência, o pipeline é um buffer de tamanho fixo no espaço do kernel; o pipeline de leitura e gravação serve para ler e gravar esse buffer do kernel
- O kernel usa o mecanismo de fila de anel para realizar o pipeline com sua implementação de buffer (4K); portanto, o pipeline tem uma característica de fluxo de dados unidirecional
- O pipe não pertence a nenhum tipo de sistema de arquivos, então não será gravado no disco; ele existe apenas na memória e é espaço do kernel
- Desta forma, você pode entender por que os tubos só podem ser usados entre processos relacionados; como eles são armazenados apenas na memória, os tubos obtidos por tubo são diferentes a cada vez e apenas os tubos herdados do ancestral comum são os mesmos.
- O conteúdo escrito é adicionado ao final do buffer do pipeline todas as vezes, e os dados são lidos da cabeça do buffer todas as vezes
- A particularidade do pipeline torna impossível usar a função lseek para saltar dentro do pipeline
- Depois de entender a natureza do pipeline, você pode entender muitas características do pipeline; por exemplo,
uma vez que os dados são lidos, eles não existem no pipeline e não podem ser lidos repetidamente.
Isso ocorre porque o pipeline é um mecanismo de fila circular e não existe depois que os dados são recuperados. A fila é
uma comunicação half-duplex.
Não é também por causa da fila circular? . . - Conduíte para comunicação entre o processo genético, o tubo como um arquivo especial, incorpora totalmente o filho herda a propriedade de arquivos abertos do processo pai
- Os descritores pipefd [0] e pipefd [1] obtidos pelo pipe pipe não são diferentes dos descritores de arquivo comuns e compartilham uma fila de descritores com descritores de arquivo comuns.
- O tubo pode usar a operação IO na parte inferior do sistema de fechamento para fechar uma porta (leitor / gravação final), ou ambas as portas podem ser fechadas
- O tubo sem nome continua com o processo, o que significa que quando o último processo que abriu o tubo sair, o tubo morrerá e deixará de existir.
- A capacidade do pipeline é dividida em PIPE_CAPACITY e PIPE_BUF. A diferença entre os dois é que PIPE_BUF define o tamanho do buffer do pipeline do kernel. O tamanho desse valor é definido pelo kernel (geralmente 4K); e PIPE_CAPACITY se refere ao valor máximo do pipeline , Ou seja, capacidade, é um buffer na memória do kernel
- A capacidade do tubo PIPE_CAPACITY significa o número máximo de bytes que podem ser gravados em um tubo cada vez que a função do tubo é usada para criá-lo (65535 testado nesta máquina)
- As características de leitura e gravação do tubo (ambas as extremidades de leitura e gravação estão abertas): Quando a capacidade do tubo estiver cheia, a gravação de dados nele será bloqueada; quando o tubo estiver vazio, a leitura será bloqueada
- Quando uma extremidade da extremidade de leitura e gravação é fechada, ela tem as seguintes características: a
extremidade de gravação do tubo é fechada e não há dados no tubo, a leitura retorna 0 (como se estivesse lendo até o final do arquivo),
todas as extremidades de leitura do tubo são fechadas e o processo termina de forma anormal
pipeline
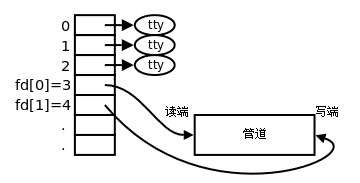
A seguir está uma descrição da implementação da estrutura de dados do pipeline, que pode lhe dar uma sensação de realização repentina:
No Linux, a implementação do pipeline não usa uma estrutura de dados especial, mas usa a estrutura de arquivos do sistema de arquivos e o inode do nó de índice do VFS. Isso é obtido apontando duas estruturas de arquivo para o mesmo nó de índice VFS temporário, e esse nó de índice VFS aponta para uma página física. Existem duas estruturas de dados de arquivo (representando dois descritores de arquivo), mas elas definem o endereço das rotinas de operação de arquivo são diferentes. Uma é o endereço de rotina que grava dados no tubo e o outro é lido no tubo O endereço de rotina dos dados. Desta forma, a chamada do sistema do programa do usuário ainda é a operação de arquivo usual, mas o kernel usa esse mecanismo abstrato para realizar a operação especial do pipeline.
2. Tubos famosos
Um canal conhecido é uma maneira que pode ser usada para se comunicar entre processos não relacionados; também conhecido como arquivo FIFO, é um tipo especial de arquivo que existe no sistema de arquivos como um nome de arquivo, mas seu comportamento Semelhante ao tubo sem nome mencionado anteriormente.
Para usar um tubo conhecido, primeiro você precisa criar um arquivo de tubo conhecido. Existem dois métodos, os seguintes:
- Criar por comando:
mkfifo fifo
- Criado pela função:
#include<sys/types.h>
#include<sys/stat.h>
int mkfifo(const char *pathname,mode_t mode);
mkfifo () criará um arquivo FIFO especial baseado no nome do caminho do parâmetro, o arquivo não deve existir e o modo do parâmetro é a permissão do arquivo (modo% ~ umask)
Outra coisa a observar é que você não pode criar um arquivo pipe fifo em uma pasta compartilhada
As operações de leitura e gravação de um canal nomeado são iguais às de um canal não nomeado. Todas usam as operações de leitura e gravação de E / S do sistema: leitura / gravação; abrir um arquivo de canal também usa a função de abertura de E / S do sistema: abrir, mas seus parâmetros têm alguns pontos dignos de nota:
int fifo_fd = open("xxx",flags);
Os parâmetros opcionais dos sinalizadores são:
O_RDWR
O_RDONLY
O_WRONLY
O_NONBLOCK
A opção O_NONBLOCK significa não bloqueador. Após adicionar esta opção, significa que a chamada aberta é não bloqueadora. Se não houver tal opção, significa que a chamada aberta está bloqueando.
- Para um arquivo FIFO aberto em modo somente leitura (O_RDONLY), se a chamada de abertura for bloqueada (ou seja, o segundo parâmetro é O_RDONLY), ele não retornará a menos que um processo abra o mesmo FIFO para gravação; se aberto for chamado Não é bloqueador (ou seja, o segundo parâmetro é O_RDONLY | O_NONBLOCK), mesmo que nenhum outro processo abra o mesmo arquivo FIFO no modo de gravação, a chamada aberta será bem-sucedida e retornará imediatamente.
- Para arquivos FIFO abertos no modo somente gravação (O_WRONLY), se a chamada aberta for bloqueada (ou seja, o segundo parâmetro é O_WRONLY), a chamada aberta será bloqueada até que um processo abra o mesmo arquivo FIFO no modo somente leitura; Se a chamada aberta não for bloqueadora (ou seja, o segundo parâmetro é O_WRONLY | O_NONBLOCK), a abertura sempre retornará imediatamente, mas se nenhum outro processo abrir o mesmo arquivo FIFO no modo somente leitura, a chamada aberta retornará -1 e a FIFO não será Será aberto.
Tubos famosos têm outras características:
- O conhecido arquivo de pipe não é um arquivo comum, mas na verdade é um buffer no kernel, então você não pode usar lseek para operar o conhecido arquivo de pipe
- Depois de gravar dados no pipeline, quando usamos ls -l fifo para visualizar o arquivo do pipeline, descobriremos que o tamanho do arquivo do pipeline é sempre 0; isso significa que os dados no pipeline não são visíveis no sistema de arquivos. Ele ainda é trocado por meio do buffer do kernel, mas em comparação com o canal não nomeado, mais um nome de arquivo aparece no sistema de arquivos, por isso é chamado de canal nomeado
Resumo: Por meio do pipeline, você pode ter um vislumbre da comunicação entre processos e conhecer as características essenciais de algumas comunicações entre processos.
Toda a comunicação entre processos precisa ser realizada através do kernel; como o espaço de memória virtual entre diferentes processos é independente um do outro, se você quiser trocar dados, deve ignorar o espaço do kernel. Um determinado processo coloca os dados no espaço do kernel primeiro e, em seguida, Outros processos obtêm dados do espaço do kernel.
referência:
- https://blog.csdn.net/qq_42914528/article/details/82023408
- https://blog.csdn.net/rannianzhixia/article/details/72793895
- "Programação Avançada UNIX"