Artigo Diretório
Prefácio:
Antes, estudamos tabelas lineares, arrays, strings e árvores. Todos eles têm um defeito tão grande que a pesquisa das condições numéricas dos dados exige o cruzamento de todos ou de parte dos dados . Então, há uma maneira de omitir o processo de comparação de dados, melhorando ainda mais a eficiência da busca por condições numéricas?
A resposta é, claro, sim! Nesta lição, apresentaremos um artefato de pesquisa eficiente: a tabela hash.

Um, o que é uma mesa de hash
O nome da tabela hash é derivado de Hash e também pode ser chamado de tabela hash . A tabela de hash é uma estrutura de dados especial, que é muito diferente das estruturas de dados que aprendemos antes, como arrays, listas vinculadas e árvores.
1.1 Princípio da Tabela de Hash
Uma tabela hash é uma estrutura de dados que usa funções hash para organizar os dados para oferecer suporte à inserção e pesquisa rápidas . A ideia central de uma tabela hash é usar uma função hash para mapear as chaves para os depósitos . mais especificamente:
- Quando inserimos uma nova chave, a função hash determinará para qual depósito a chave deve ser alocada e armazenará a chave no depósito correspondente;
- Quando queremos pesquisar uma chave, a tabela hash usará a mesma função hash para encontrar o depósito correspondente e pesquisar apenas em um depósito específico.
Aqui está um exemplo simples, vamos entender:
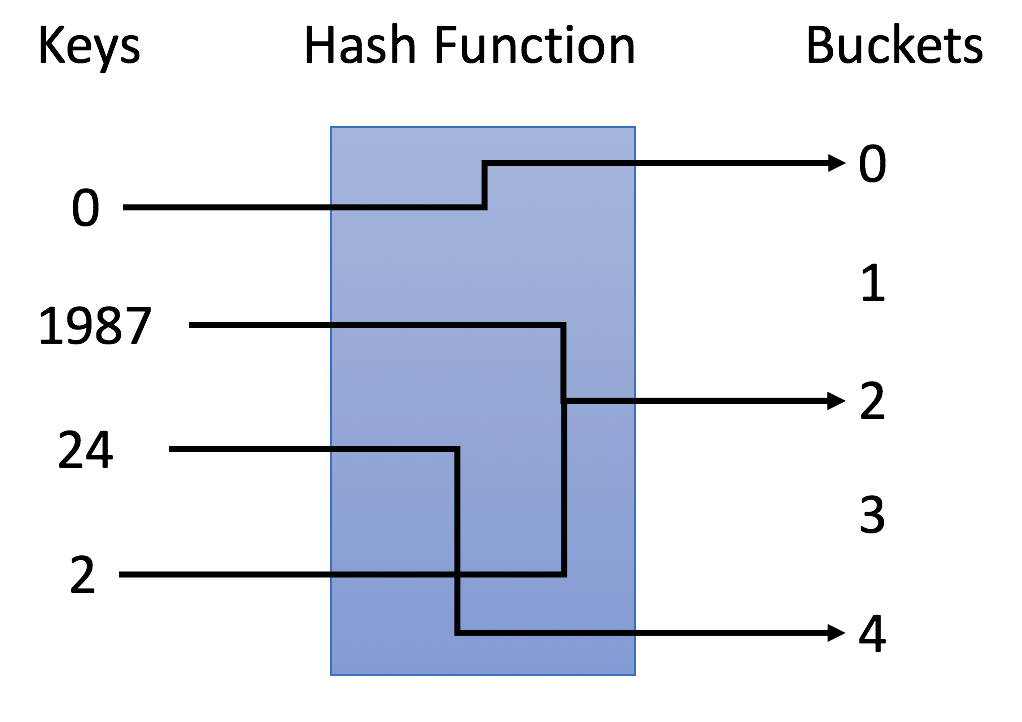
No exemplo, usamos y = x% 5 como a função hash. Vamos usar este exemplo para completar a estratégia de inserção e pesquisa:
- Inserção: analisamos as chaves por meio da função hash e as mapeamos para os depósitos correspondentes. Por exemplo, 1987 é atribuído ao segmento 2 e 24 é atribuído ao segmento 4.
- Pesquisa: analisamos as chaves por meio da mesma função hash e pesquisamos apenas em depósitos específicos. Por exemplo, se pesquisarmos 23, mapearemos 23 a 3 e pesquisaremos no intervalo 3. Descobrimos que 23 não está no intervalo 3, o que significa que 23 não está na tabela de hash.
1.2 Projetar uma função hash
A função hash é uma tabela hash dos componentes mais importantes, a tabela hash é usada para mapear as chaves para um determinado depósito . No exemplo anterior, usamos y = x% 5 como a função hash, onde x é o valor da chave ey é o índice do intervalo alocado .
A função hash dependerá do intervalo de valores-chave e do número de depósitos . Aqui estão alguns exemplos de
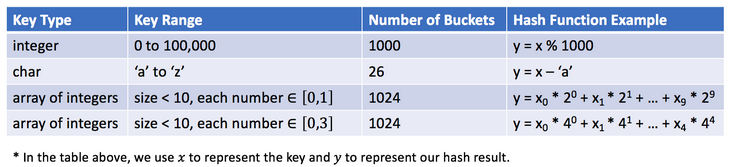
funções hash : O design de funções hash é uma questão em aberto. A ideia é atribuir chaves a depósitos o máximo possível. Idealmente, a função de hash perfeita será um mapeamento um para um entre chaves e depósitos. No entanto, na maioria dos casos, a função hash não é perfeita. Ela requer uma compensação entre o número de depósitos e a capacidade do depósito.
Claro, também podemos personalizar algumas funções hash. Os métodos gerais são:
- Método de personalização direta . A função hash é uma função linear de palavras-chave para endereços. Por exemplo, H (tecla) = a * tecla + b. Aqui, a e b são constantes definidas.
- Método de análise digital . Suponha que cada chave no conjunto de chaves seja composta de números de s dígitos (k1, k2, ..., Ks) e vários bits uniformemente distribuídos sejam extraídos dela para formar um endereço hash.
- O quadrado é o método chinês . Se cada dígito da palavra-chave tiver certos dígitos repetidos e a frequência for muito alta, podemos primeiro encontrar o valor do quadrado da palavra-chave, expandir a diferença pelo quadrado e, em seguida, usar os dígitos do meio como o endereço de armazenamento final.
- Método de dobragem . Se a palavra-chave tiver muitos dígitos, você pode dividir a palavra-chave em várias partes de comprimento igual e obter o valor de sua sobreposição e (arredondar para cima) como o endereço hash.
- Além do método de resto . Defina um número p antecipadamente e, em seguida, execute a operação restante com a palavra-chave. Ou seja, o endereço é a chave% p.
Dois, resolver conflitos de hash
Idealmente, se nossa função hash for um mapeamento um-para-um perfeito, não precisaremos lidar com conflitos. Infelizmente, na maioria dos casos, o conflito é quase inevitável. Por exemplo, em nossa função hash anterior (y = x% 5), 1987 e 2 são atribuídos ao intervalo 2, que é uma colisão de hash.
As seguintes questões devem ser consideradas para resolver conflitos de hash:
- Como organizar os valores no mesmo balde?
- E se muitos valores forem atribuídos ao mesmo intervalo?
- Como pesquisar o valor alvo em um intervalo específico?
Portanto, quando ocorre um conflito, como o resolvemos?
Existem dois métodos comumente usados: método de endereçamento aberto e método de endereçamento em cadeia .
2.1 Método de endereçamento aberto
Ou seja, quando uma palavra-chave entra em conflito com outra palavra-chave, uma sequência de detecção é formada na tabela de hash usando uma determinada tecnologia de detecção e, em seguida, a sequência de detecção é pesquisada por sua vez. Quando uma célula vazia é encontrada, ela é inserida nela.
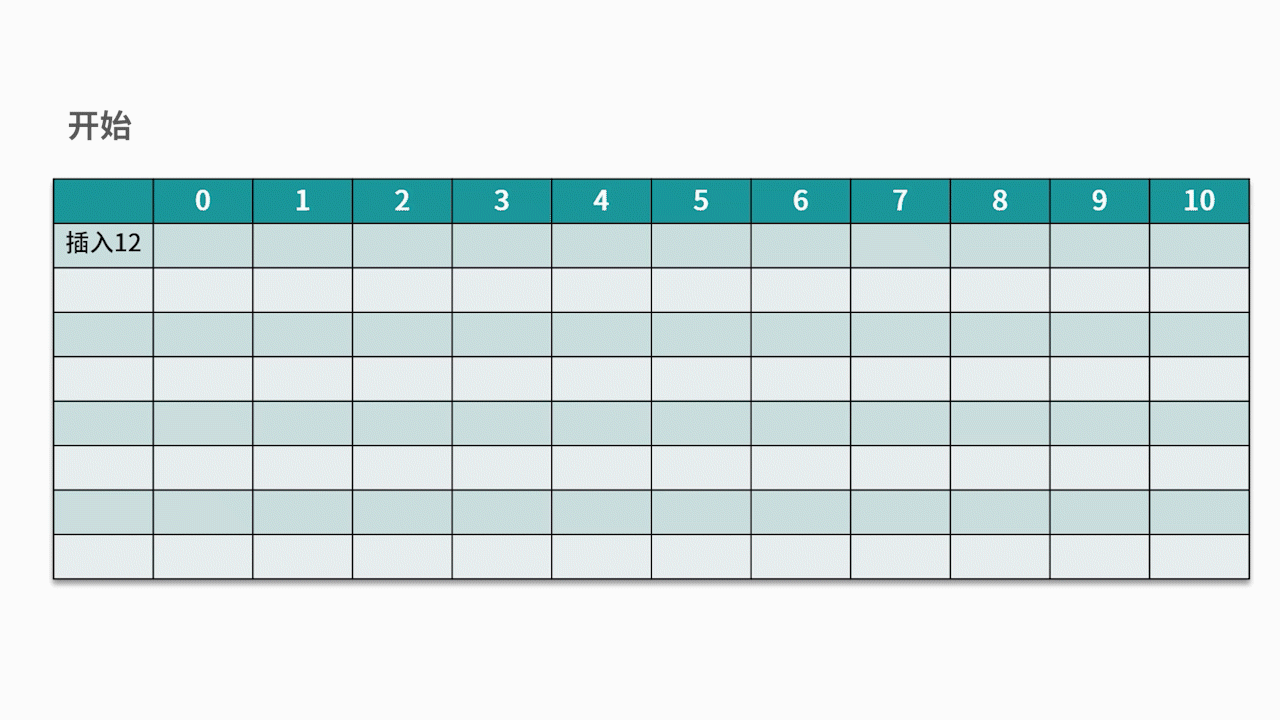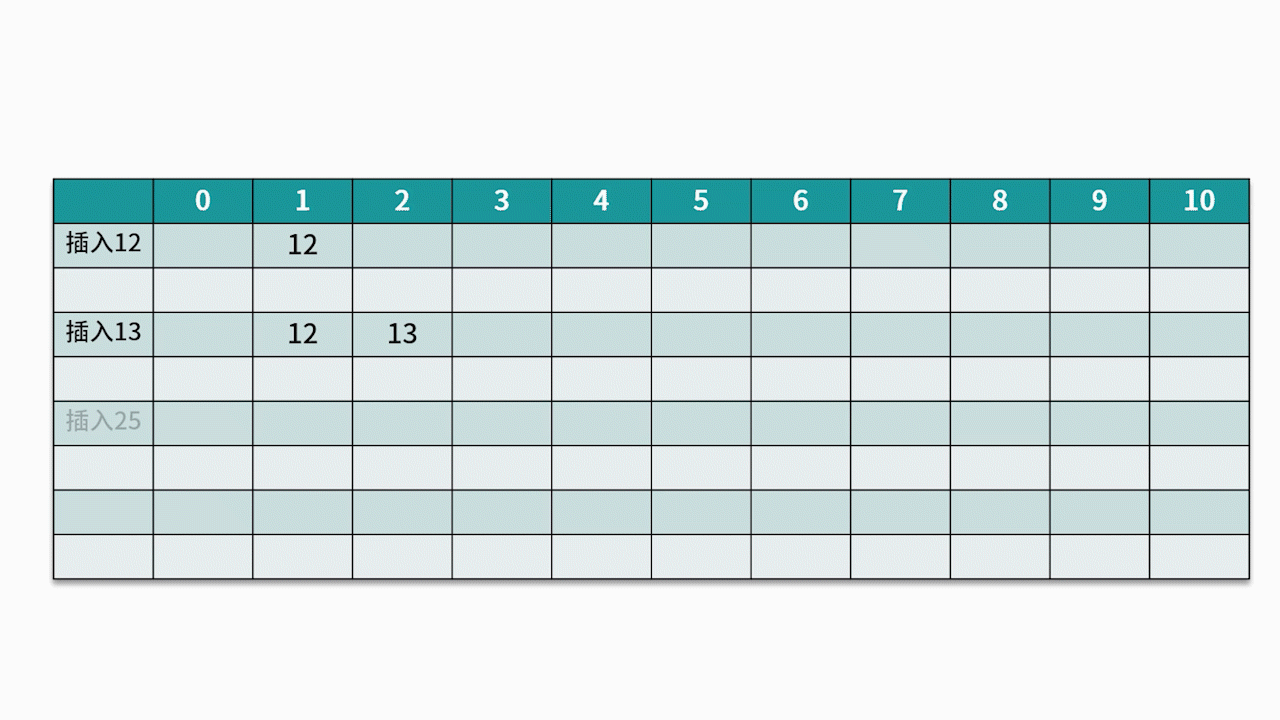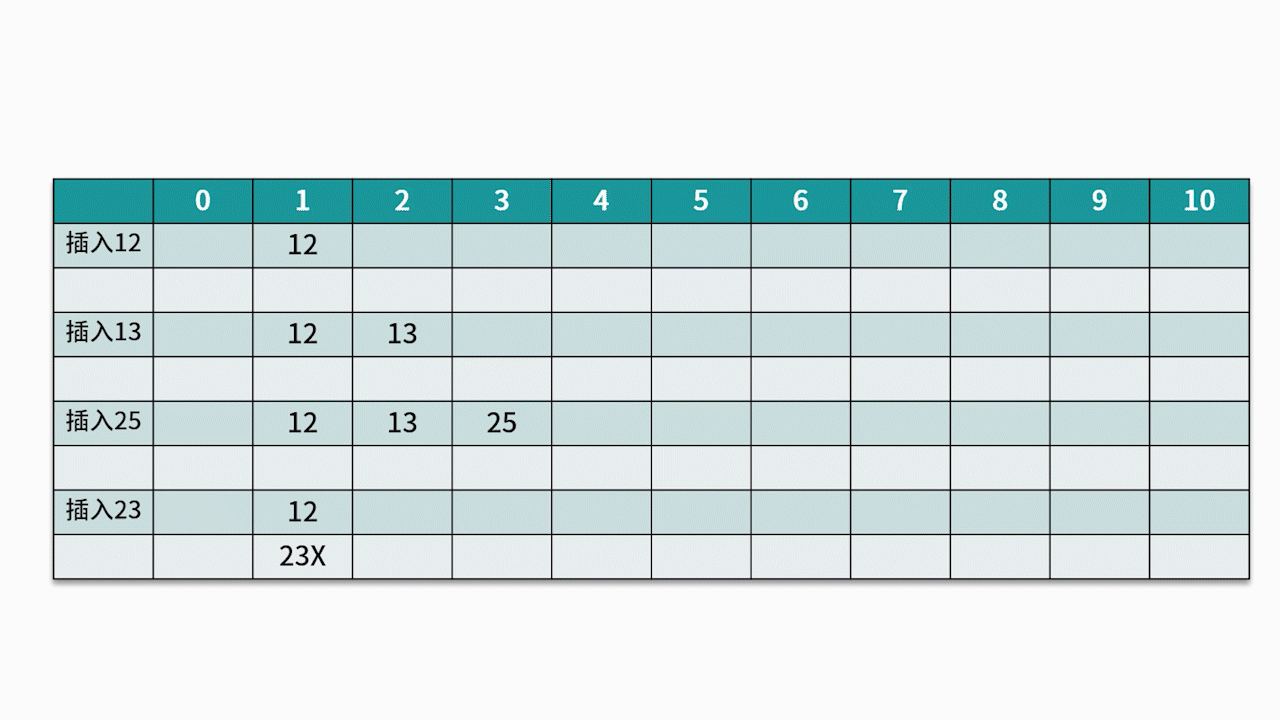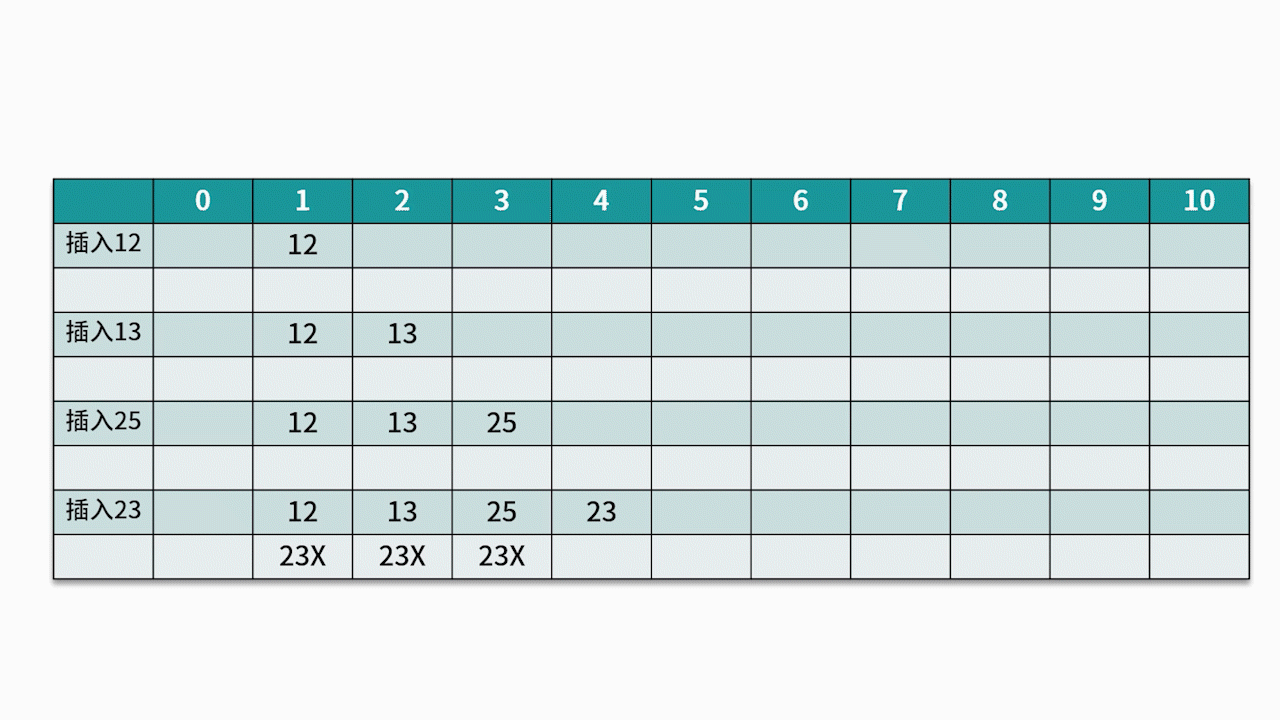
O método de detecção comumente usado é o método de detecção linear . Por exemplo, existe um conjunto de palavras-chave {12, 13, 25, 23} e a função hash usada é a chave% 11 . Ao inserir 12, 13, 25, ele pode ser inserido diretamente, os endereços são 1, 2 e 3, respectivamente. Quando 23 é inserido, o endereço hash é 23% 11 = 1.
No entanto, o endereço 1 já está ocupado, então siga o endereço 1 na seqüência até que o endereço 4 seja detectado e esteja vazio, então 23 é inserido nele. Como mostrado abaixo:
2.2 Método de endereço de cadeia
Armazene os registros com o mesmo endereço hash em uma lista vinculada linear. Por exemplo, há um conjunto de palavras-chave {12,13,25,23,38,84,6,91,34} e a função hash usada é a chave% 11. Como mostrado abaixo:
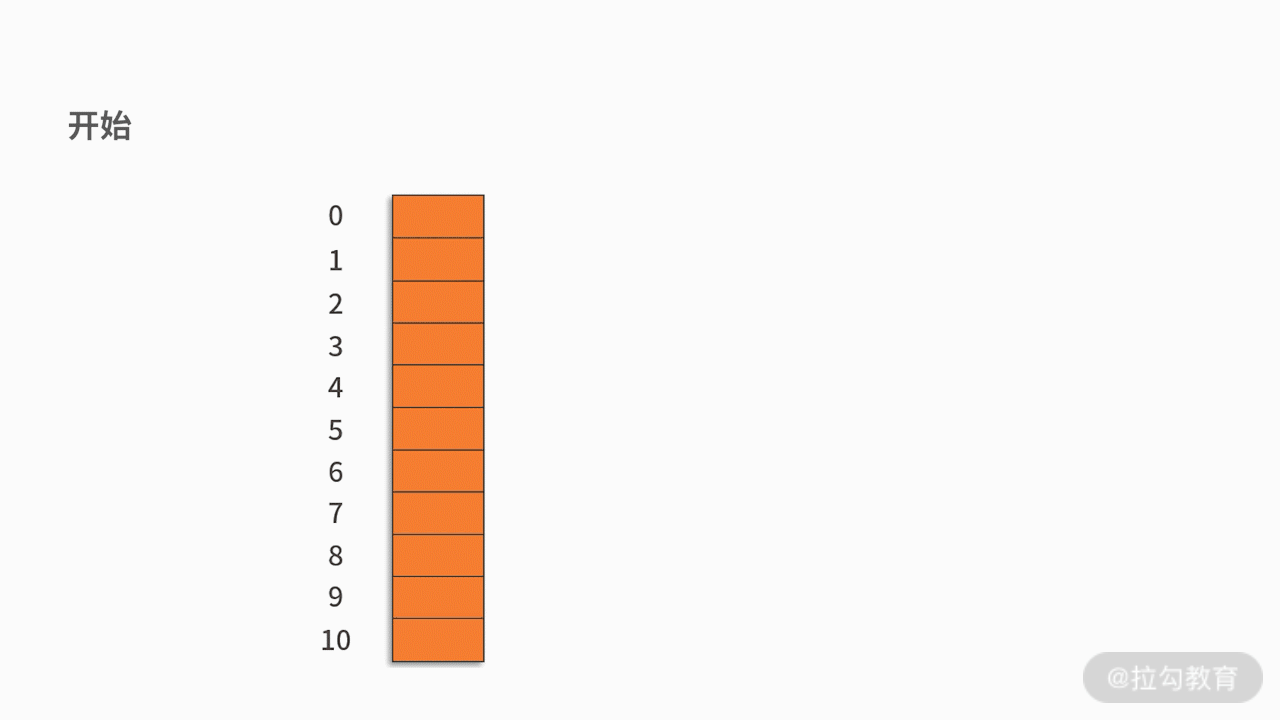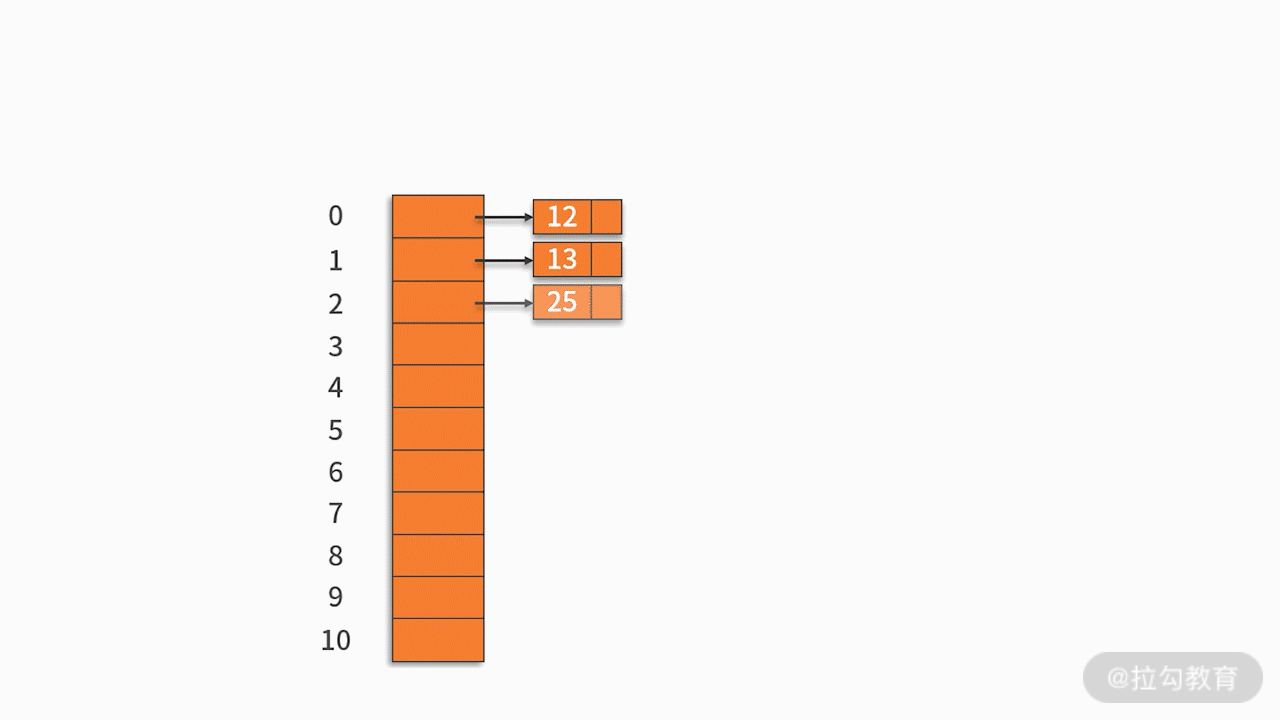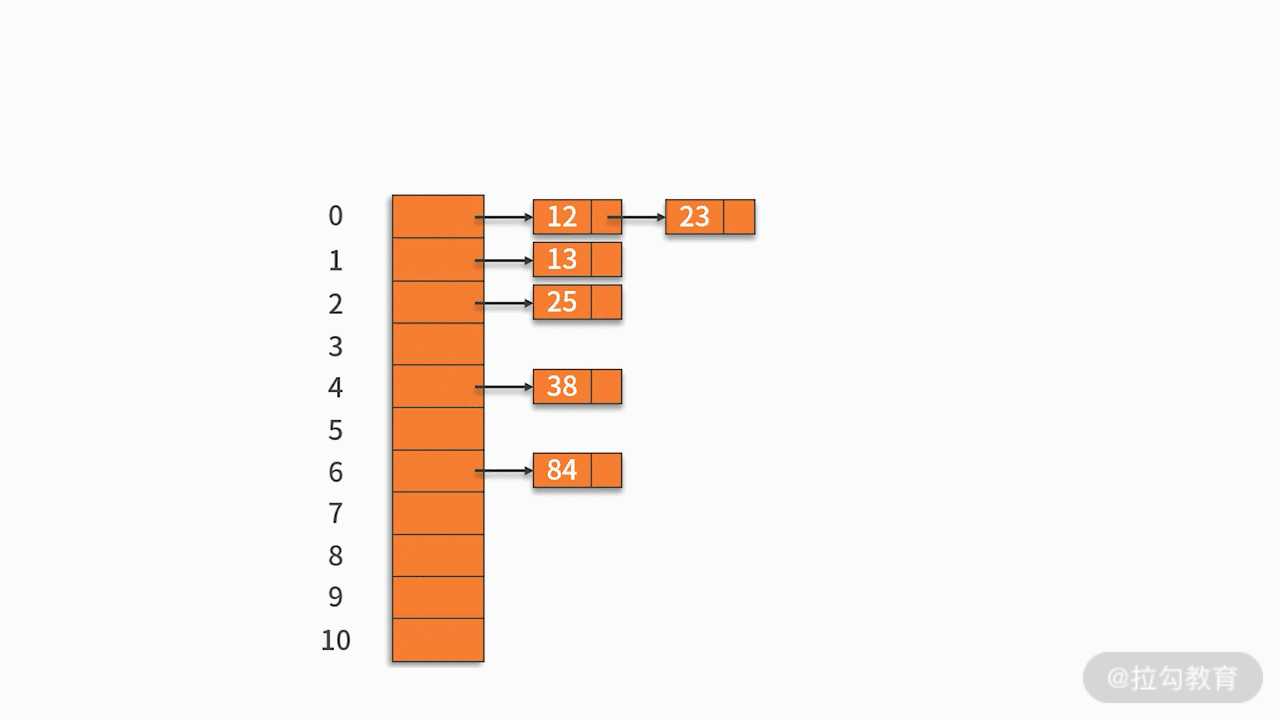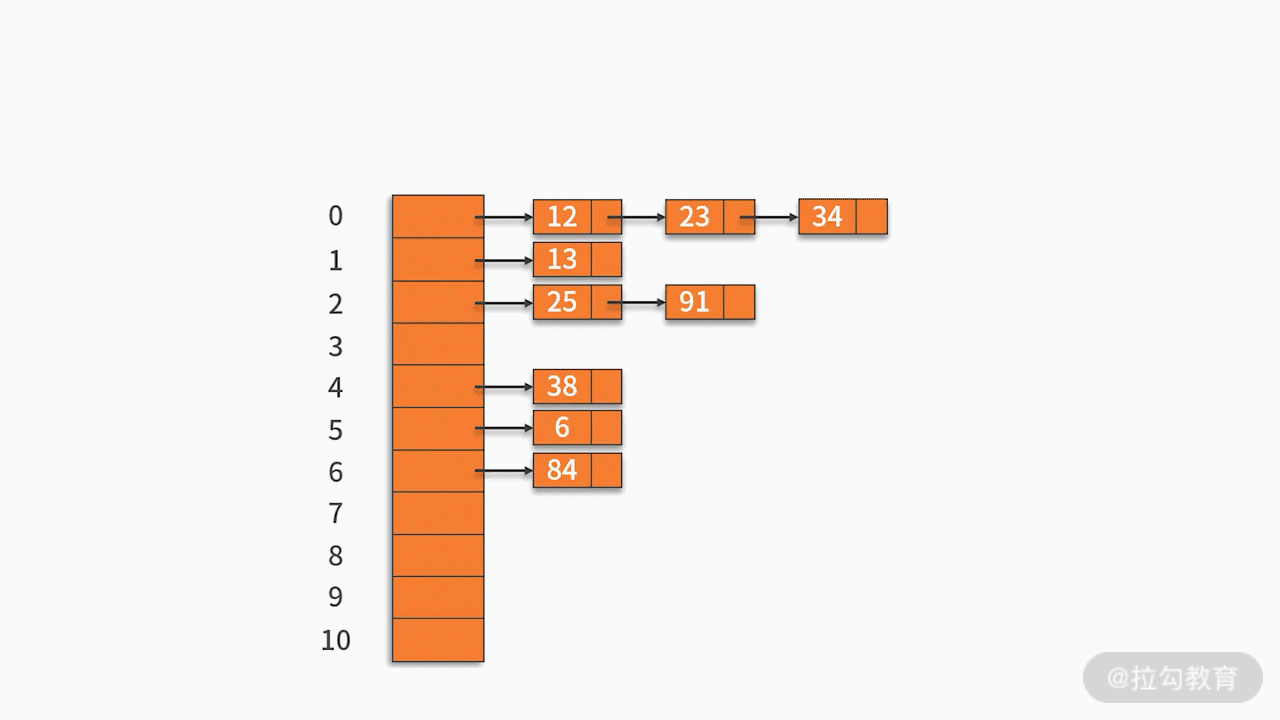
Três, a aplicação de tabela de hash
3.1 Operação básica da tabela hash
Em muitas linguagens de alto nível, as funções hash e os conflitos hash foram colocados em uma caixa preta na parte inferior e os desenvolvedores não precisam projetar a si próprios. Em outras palavras, a tabela hash completa o mapeamento de palavras-chave para endereços e os dados podem ser encontrados por meio de palavras-chave em um nível constante de complexidade de tempo.
Quanto aos detalhes de implementação, como qual função hash é usada, qual tratamento de conflito é usado e até mesmo o endereço hash de um determinado registro de dados, não é necessário que os desenvolvedores prestem atenção. A seguir, do ponto de vista do desenvolvimento real, vamos dar uma olhada na adição, exclusão e verificação de dados pela tabela hash.
A operação de adicionar e excluir dados na tabela hash não envolve o problema de deslocamento de dados após a adição ou exclusão (matrizes devem ser consideradas), portanto, o processamento é bom.
O processo detalhado da pesquisa da tabela hash é: para uma determinada chave, o endereço hash H (chave) é calculado por meio de uma função hash.
- Se o valor correspondente ao endereço hash estiver vazio, a pesquisa será malsucedida.
- Caso contrário, a pesquisa foi bem-sucedida.
Embora o processo detalhado de pesquisa de tabela hash seja ainda mais problemático, por causa do processamento de caixa preta de algumas linguagens de alto nível, os desenvolvedores não precisam realmente desenvolver o código subjacente, basta chamar as funções relevantes.
3.2 Vantagens e desvantagens das tabelas de hash
- Vantagens : Ele pode fornecer operações de inserção-exclusão-pesquisa muito rápidas, não importa a quantidade de dados, valores de inserção e exclusão requerem quase um tempo constante . Em termos de pesquisa, a velocidade da tabela hash é maior do que a da árvore, e o elemento desejado pode ser encontrado em um instante.
- Desvantagem : os dados na tabela hash não têm nenhum conceito de ordem , portanto, os elementos não podem ser percorridos de uma maneira fixa (como de pequeno a grande). Quando a ordem de processamento de dados é confidencial, escolher uma tabela hash não é uma boa solução. Ao mesmo tempo, as
chaves na tabela hash não podem ser repetidas, e a tabela hash não é uma boa escolha para dados com repetibilidade muito alta.
Quarto, projete um mapa hash
4.1 Requisitos de projeto
Afirmação:
Projete um mapa de hash sem usar nenhuma biblioteca de tabelas de hash embutida. Especificamente, o design deve incluir as seguintes funções:
- put (chave, valor) : Insira o par de valores de (chave, valor) no mapa hash. Se o valor correspondente à chave já existir, atualize este valor.
- get (key) : Retorna o valor correspondente à chave fornecida, se a chave não estiver incluída no mapa, retorna -1.
- remover (chave ): Se a chave existir no mapa, exclua o par de valores.
Exemplo:
MyHashMap hashMap = new MyHashMap();
hashMap.put(1, 1);
hashMap.put(2, 2);
hashMap.get(1); // 返回 1
hashMap.get(3); // 返回 -1 (未找到)
hashMap.put(2, 1); // 更新已有的值
hashMap.get(2); // 返回 1
hashMap.remove(2); // 删除键为2的数据
hashMap.get(2); // 返回 -1 (未找到)
Nota:
所有的值都在 [0, 1000000]的范围内。
操作的总数目在[1, 10000]范围内。
不要使用内建的哈希库。
4.2 Idéias de Design
A tabela de hash é uma estrutura de dados comum disponível em diferentes idiomas. Por exemplo, dict em Python, map em C ++ e Hashmap em Java. A característica da tabela hash é que o valor pode ser acessado rapidamente de acordo com a chave fornecida.
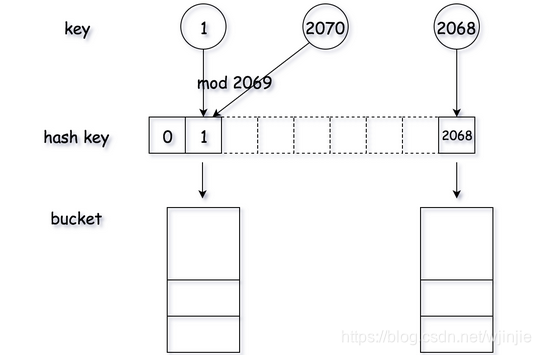
A ideia mais simples é usar a aritmética modular como o método hash. Para reduzir a probabilidade de colisões hash, o módulo de números primos geralmente é usado, como o módulo 2069.
Defina o array como espaço de armazenamento e calcule o subscrito do array pelo método hash. Para resolver a colisão de hash (ou seja, o valor da chave é diferente, mas o subscrito de mapeamento é o mesmo), um depósito é usado para armazenar todos os valores correspondentes. Buckets podem ser implementados como arrays ou listas vinculadas. Nas implementações específicas a seguir, arrays são usados em Python.
Defina os métodos da tabela hash, get (), put () e remove (). O processo de endereçamento é o seguinte:
- Para um determinado valor-chave, use o método hash para gerar o código hash do valor-chave e use o código hash para localizar o espaço de armazenamento. Para cada código hash, um depósito pode ser encontrado para armazenar o valor correspondente ao valor da chave.
- Depois de encontrar um intervalo, verifique se o par de valores-chave já existe por meio de passagem .
4.3 Caso prático
A implementação do Python é a seguinte:
class Bucket:
def __init__(self):
self.bucket = []
def get(self, key):
for (k, v) in self.bucket:
if k == key:
return v
return -1
def update(self, key, value):
found = False
for i, kv in enumerate(self.bucket):
if key == kv[0]:
self.bucket[i] = (key, value)
found = True
break
if not found:
self.bucket.append((key, value))
def remove(self, key):
for i, kv in enumerate(self.bucket):
if key == kv[0]:
del self.bucket[i]
class MyHashMap(object):
def __init__(self):
"""
Initialize your data structure here.
"""
# better to be a prime number, less collision
self.key_space = 2069
self.hash_table = [Bucket() for i in range(self.key_space)]
def put(self, key, value):
"""
value will always be non-negative.
:type key: int
:type value: int
:rtype: None
"""
hash_key = key % self.key_space
self.hash_table[hash_key].update(key, value)
def get(self, key):
"""
Returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key
:type key: int
:rtype: int
"""
hash_key = key % self.key_space
return self.hash_table[hash_key].get(key)
def remove(self, key):
"""
Removes the mapping of the specified value key if this map contains a mapping for the key
:type key: int
:rtype: None
"""
hash_key = key % self.key_space
self.hash_table[hash_key].remove(key)
# Your MyHashMap object will be instantiated and called as such:
# obj = MyHashMap()
# obj.put(key,value)
# param_2 = obj.get(key)
# obj.remove(key)
Análise de complexidade:
- Complexidade de tempo: a complexidade de tempo de cada método é O (N / K), onde N é o número de todos os valores-chave possíveis, K é o número de intervalos predefinidos na tabela hash, onde K é 2069. Aqui, assumimos que o valor da chave é distribuído uniformemente em todos os intervalos e o tamanho médio do intervalo é N / K. No pior caso, um intervalo completo precisa ser percorrido, então a complexidade do tempo é O (N / K).
- Complexidade do espaço: O (K + M), onde K é o número de depósitos predefinidos na tabela hash e M é o número de valores-chave inseridos na tabela hash.
O compartilhamento de hoje acabou, espero que seja útil para o seu estudo!
