Este artigo apresenta principalmente como usar o ELK Stack para nos ajudar a construir um sistema de monitoramento de log que suporte o nível de TB da Nissan. Muito conhecimento detalhado, um artigo não é suficiente, este artigo apresenta principalmente os principais pontos de conhecimento.
Em um ambiente de microsserviço de nível empresarial, a execução de centenas de serviços é considerada uma escala relativamente pequena. No ambiente de produção, os logs desempenham um papel muito importante. Logs são necessários para solucionar problemas de exceções, logs são necessários para otimização de desempenho e serviços são necessários para solução de problemas de negócios. No entanto, existem centenas de serviços em execução na produção e cada serviço é simplesmente localizado e armazenado. Quando os logs são necessários para ajudar a solucionar problemas, é difícil encontrar o nó onde os logs estão localizados. Também é difícil explorar o valor dos dados dos logs de negócios. Em seguida, a saída unificada de logs para um local para gerenciamento centralizado e, em seguida, o processamento de logs e a saída dos resultados em dados disponíveis para operação e manutenção, pesquisa e desenvolvimento é uma solução viável para gerenciamento de log e assistência na operação e manutenção, e também é uma necessidade urgente para as empresas resolverem o log.
Nossa solução
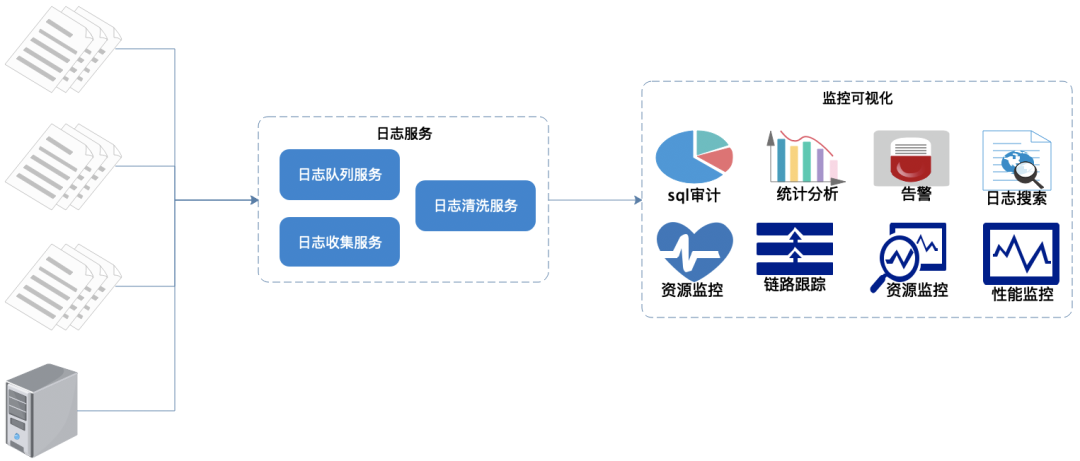
Com base nos requisitos acima, lançamos um sistema de monitoramento de log, conforme mostrado na figura acima:
- Os logs são coletados, filtrados e limpos uniformemente.
- Gere interface visual, monitoramento, alarme, pesquisa de log.
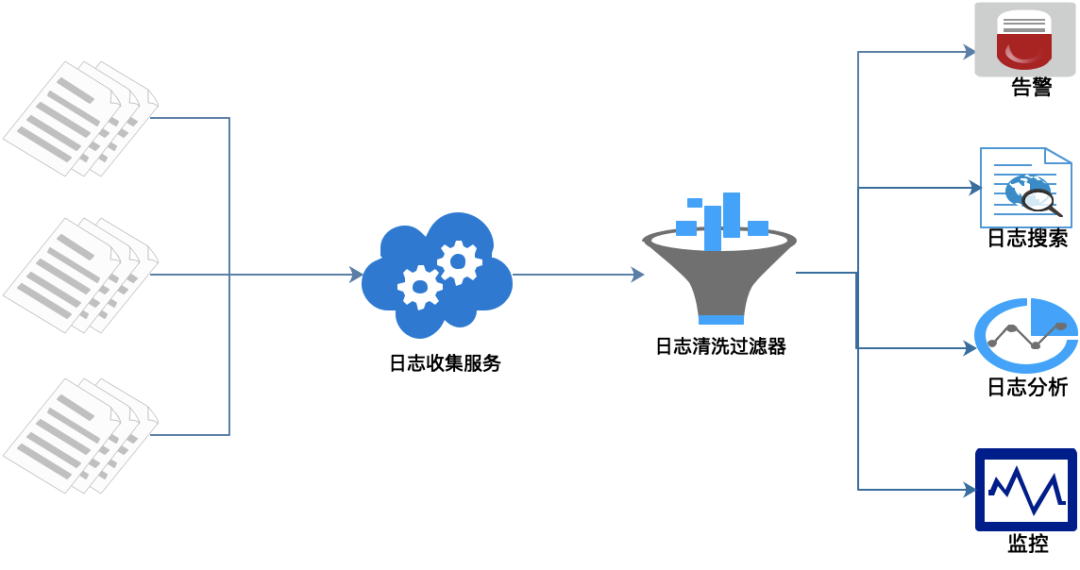
Uma visão geral do processo funcional é mostrada acima:
- Enterre pontos em cada nó de serviço e colete os registros relevantes em tempo real.
- Após o serviço unificado de coleta de logs, filtragem e limpeza dos logs, uma interface visual e função de alarme são geradas.
Nossa arquitetura
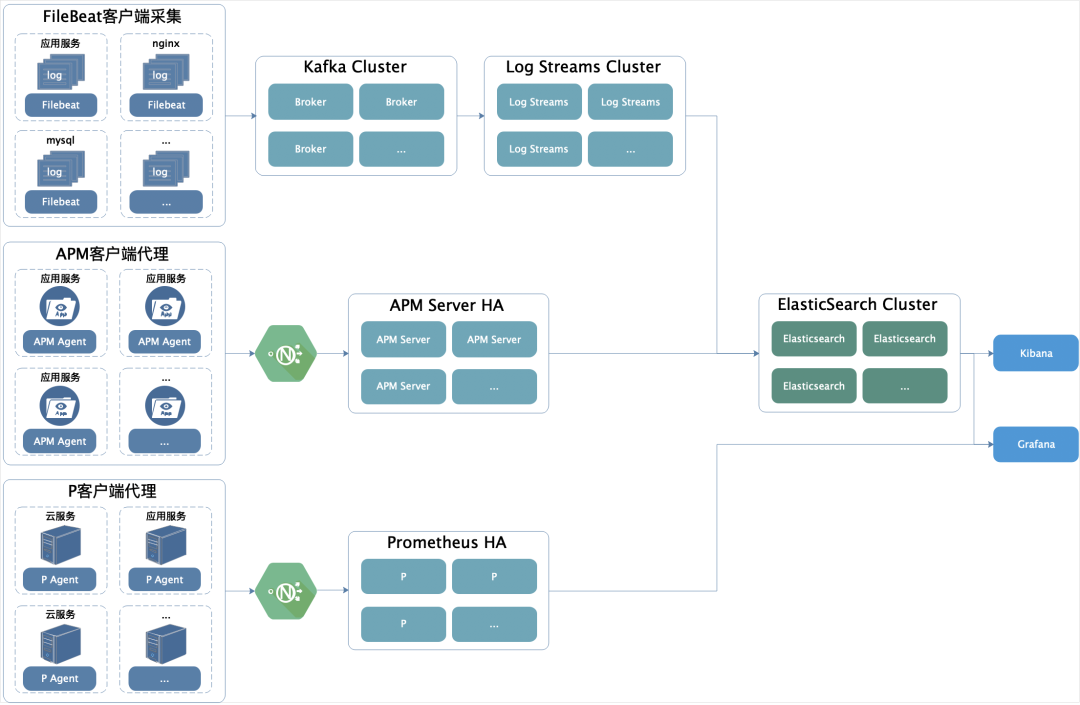
① nós usar FileBeat para o terminal de refercia ficheiro de registo. A operação e manutenção são configuradas através de interface de gestão de back-end. Cada máquina corresponde a um FileBeat. O Tópico correspondente a cada registo FileBeat pode ser um-para-um ou muitos-para-um, de acordo com a configuração diária volume de log Estratégias diferentes.
Além de coletar logs de serviço de negócios, também coletamos logs de consulta lenta do MySQL e logs de erro, bem como outros logs de serviço de terceiros, como Nginx.
Finalmente, combinado com nossa plataforma de publicação automatizada, publique e inicie automaticamente cada processo FileBeat.
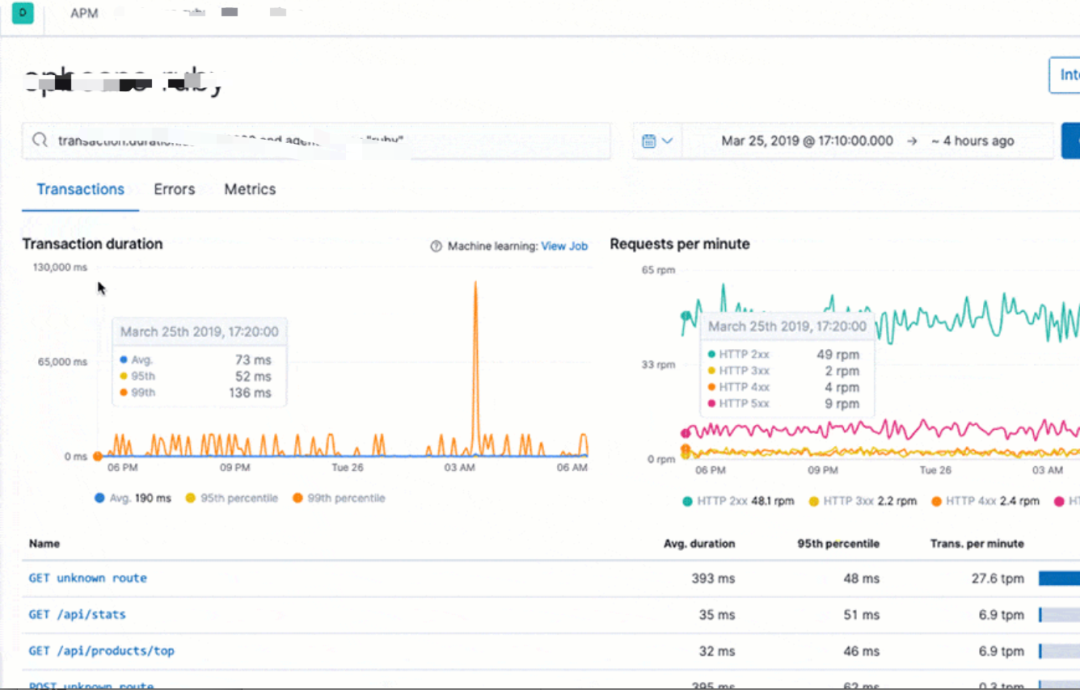
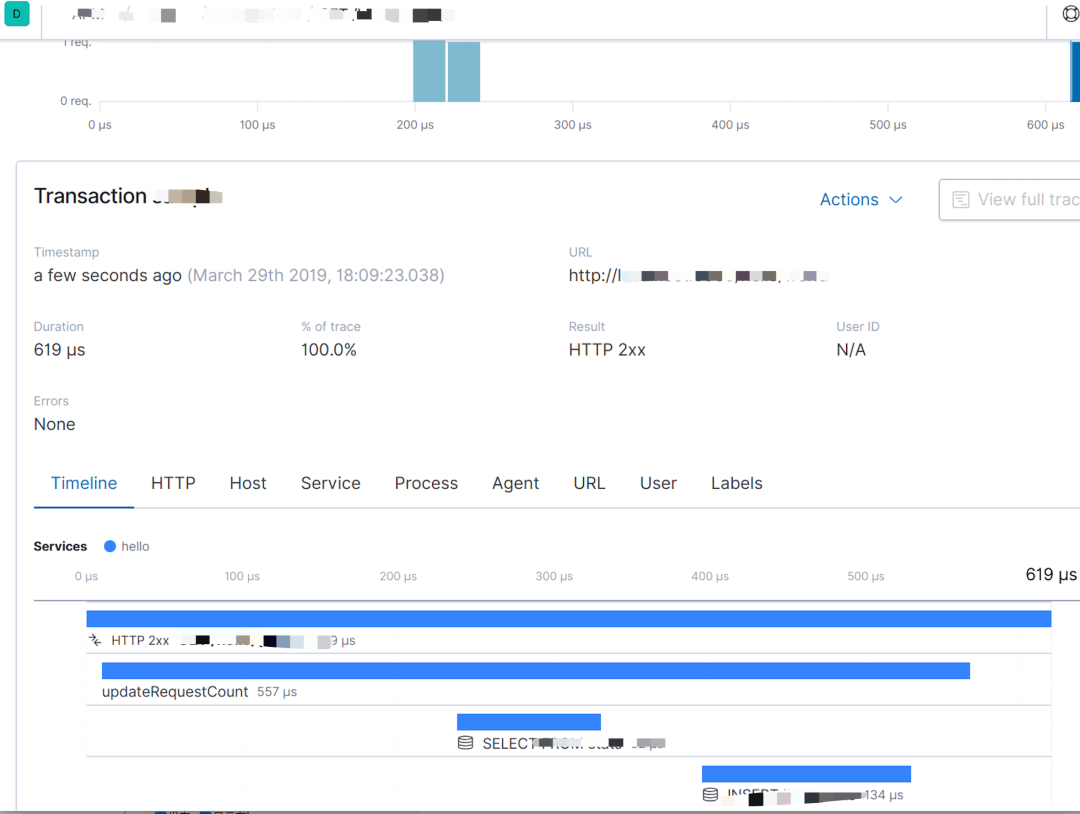
② O método de proxy que usamos para indicadores de pilha de chamadas, link e monitoramento de processo: Elastic APM, para que não haja necessidade de alterar o programa no lado comercial.
Para um sistema de negócios que já está em operação, é indesejável e inaceitável alterar o código para ingressar no monitoramento.
Elastic APM pode nos ajudar a coletar links de chamadas de interface HTTP, pilhas de chamadas de métodos internos, SQL usado, CPU de processo, indicadores de uso de memória, etc.
Algumas pessoas podem ter dúvidas. Com o Elastic APM, outros registros podem ser basicamente coletados. Por que usar o FileBeat?
Sim, as informações coletadas pelo Elastic APM podem realmente nos ajudar a localizar mais de 80% dos problemas, mas não são suportadas por todos os idiomas, como C.
Em segundo lugar, ele não pode ajudá-lo a coletar os logs de não erros e os chamados logs críticos que você deseja, como: ocorreu um erro quando uma interface foi chamada e você deseja ver os logs antes e depois da hora do erro; há também a impressão de negócios relacionados para facilitar a análise Registro.
Terceiro, exceções de negócios customizadas, que não são exceções do sistema e pertencem à categoria de negócios.O APM relatará tais exceções como exceções do sistema.
Se você avisar sobre anormalidades do sistema posteriormente, essas anormalidades irão interferir na precisão do alarme e você não pode filtrar exceções de negócios porque existem muitos tipos de exceções de negócios personalizadas.
“Ao mesmo tempo, abrimos o Agente duas vezes. Colete informações mais detalhadas sobre GC, pilha, memória e thread.
④Usamos Prometheus para a coleção do servidor.
⑤Uma vez que somos orientados a serviços Saas, existem muitos serviços, e muitos logs de serviço não podem ser unificados e padronizados. Isso também está relacionado a problemas históricos. Um sistema que não tem nada a ver com sistemas de negócios se conecta indiretamente ou diretamente com os sistemas de negócios existentes. Se você permitir que ele mude o código para se adaptar a você, ele não pode ser empurrado.
O design incrível é permitir-se ser compatível com os outros e tratar a outra parte como um objeto de ataque. Muitos logs não fazem sentido. Por exemplo, no processo de desenvolvimento, a fim de facilitar a solução de problemas e rastreamento de problemas, imprimir if else é apenas um log de assinatura, que representa se o bloco de código if ou o bloco de código else se foi.
Alguns serviços até imprimem registros de nível de depuração. Nas condições limitadas de custo e recursos, todas as toras não são realistas. Mesmo se os recursos permitirem, será uma grande despesa em um ano.
Portanto, adotamos soluções como filtragem, limpeza e ajuste dinâmico da coleta de prioridade de log. Primeiro, reúna todos os logs no cluster Kafka e defina um período de validade curto.
Atualmente, definimos um volume de dados de uma hora, uma hora, e nossos recursos ainda são aceitáveis por enquanto.
⑥ Log Streams é nosso serviço de processamento de stream para filtragem e limpeza de logs. Por que precisamos de filtros ETL?
Como nosso serviço de registro tem recursos limitados, isso não está certo. Os registros originais estão espalhados na mídia de armazenamento local de cada serviço, que também requer recursos.
Agora estamos apenas coletando, após coletá-lo, os recursos originais de cada serviço podem liberar parte dos recursos ocupados pelo log.
Isso mesmo, este cálculo realmente divide a resourceization dos serviços originais nos recursos do serviço de log, e não aumenta os recursos.
No entanto, isso é apenas teórico. Com os serviços online, os recursos são fáceis de expandir, mas encolher não é tão fácil. É extremamente difícil de implementar.
Portanto, é impossível alocar os recursos de log usados em cada serviço para o serviço de log em um curto espaço de tempo. Nesse caso, o recurso do serviço de log é a quantidade de recursos usados por todos os logs de serviço atuais.
Quanto mais tempo de armazenamento, maior será o consumo de recursos. Se o custo de resolver um problema não empresarial ou indispensável é maior do que os benefícios de resolver o problema atual em um curto espaço de tempo, acho que com recursos limitados, nenhum líder ou empresa está disposto a adotar uma solução.
Portanto, do ponto de vista de custo, introduzimos filtros no serviço Log Streams para filtrar dados de log que não têm valor, reduzindo assim o custo do recurso usado pelo serviço de log.
Tecnologia Usamos Kafka Streams como processamento de stream ETL. Perceba filtragem dinâmica e regras de limpeza por meio da configuração da interface.
As regras gerais são as seguintes:
- Coleta de logs de configuração baseada em interface. Todos os logs do nível de erro padrão são coletados.
- Considere o tempo do erro como o centro, abra uma janela no processamento de fluxo e colete registros de nível de não erro em pontos de tempo N que podem ser configurados para cima e para baixo. Por padrão, apenas o nível de informação é usado.
- Cada serviço pode ser equipado com 100 registros de chaves, e todos os registros de chaves são coletados por padrão.
- Com base no SQL lento, configure diferentes filtros demorados de acordo com a classificação do negócio.
- Estatísticas em tempo real de SQL de negócios de acordo com as necessidades de negócios, tais como: durante o período de pico, estatísticas da frequência de consulta de SQL de negócios semelhante em uma hora. Ele pode fornecer ao DBA uma base para otimizar o banco de dados, como a criação de um índice baseado na consulta SQL.
- Durante os horários de pico, os logs são limpos e filtrados dinamicamente de acordo com o índice de peso do tipo de negócio, o índice de nível de log, o índice de limite máximo de log de cada serviço em um período de tempo e o índice do período de tempo.
- Reduza dinamicamente a janela de tempo de acordo com os diferentes períodos de tempo.
- Regras de geração de índice de log: gere o índice correspondente de acordo com as regras de arquivo de log geradas pelo serviço, por exemplo: um log de serviço é dividido em: debug, info, error, xx_keyword, então o índice gerado também é debug, info, error, xx_keyword mais data como sufixo . O objetivo disso é usar logs habitualmente para pesquisa e desenvolvimento.
Interface de visualização ⑦ Usamos principalmente o Grafana. Entre as muitas fontes de dados que ele suporta, estão o Prometheus e o Elasticsearch, que podem ser descritos como acoplamento contínuo ao Prometheus. Usamos principalmente Kibana para análise visual de APM.
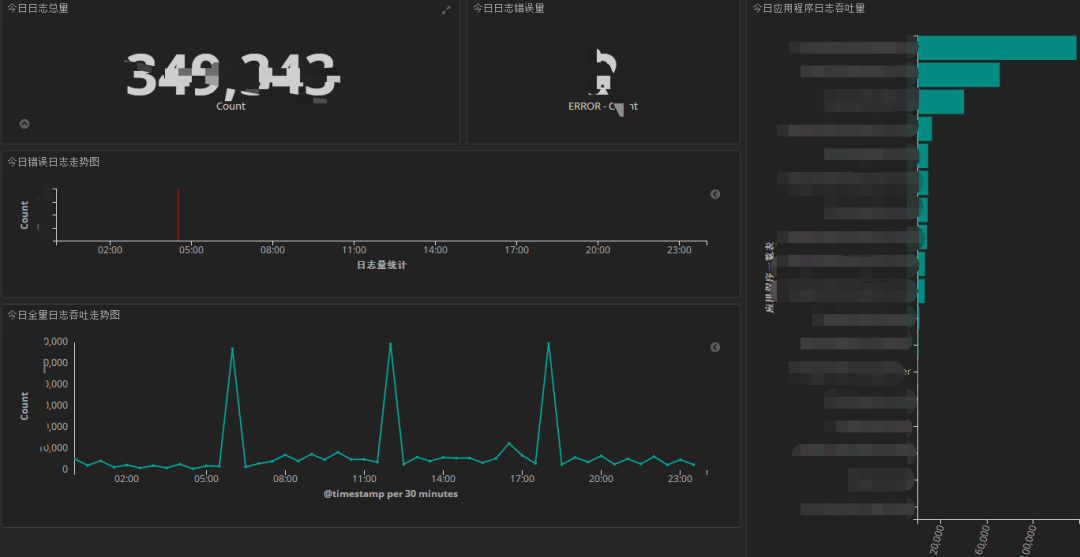
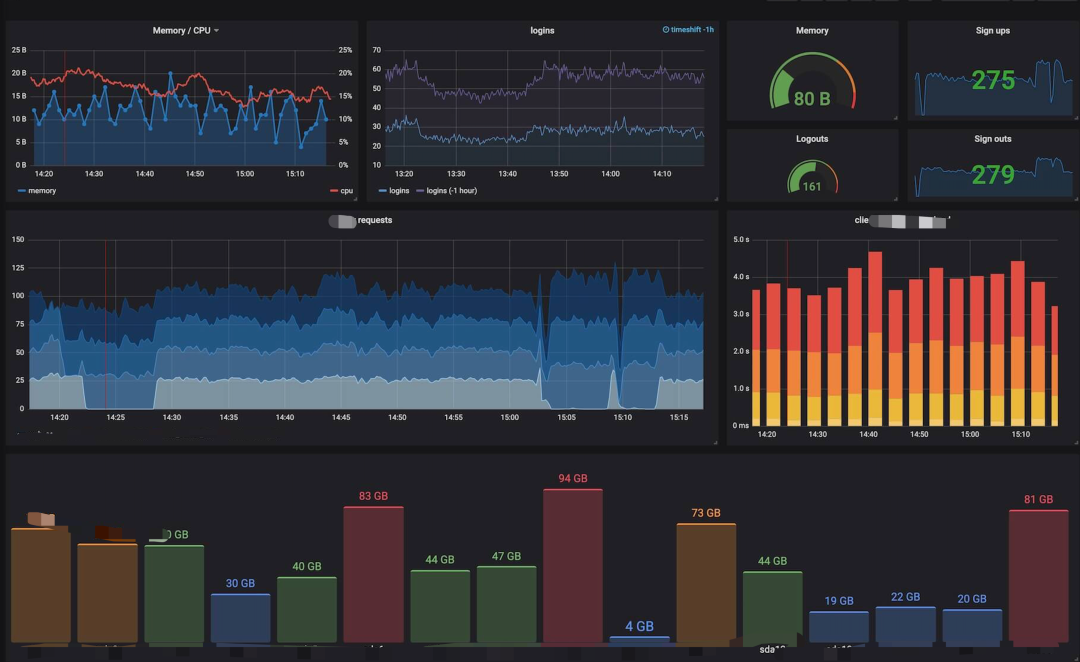
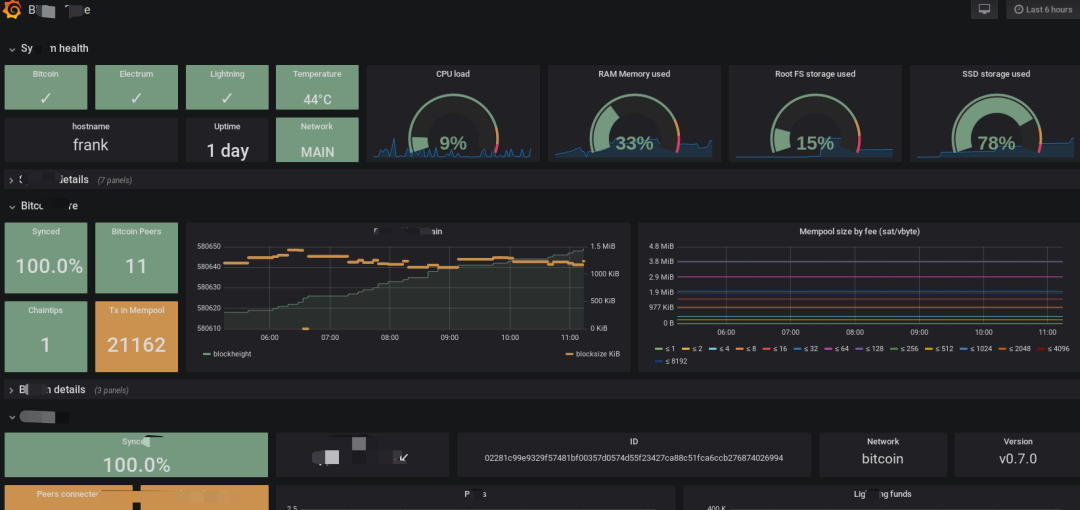
Visualização de log
Nossa visualização de log é a seguinte: