Primeiro, o uso de fluxos de processamento
A figura a seguir mostra a função do processamento de fluxos: pode ocultar as diferenças de fluxos de nós no dispositivo subjacente e fornecer métodos de entrada / saída mais convenientes para permitir que os programadores relacionem as operações de fluxos avançados.
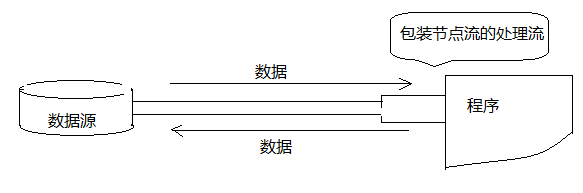
1.1, os pontos de atenção para o processamento de fluxos
1. Use o fluxo de processamento para agrupar o fluxo de nó.O programa usa o fluxo de processamento para executar funções de entrada / saída, permitindo que o fluxo de nó interaja com os dispositivos e arquivos de E / S subjacentes.
2. De fato, precisamos identificar que o fluxo de processamento é muito simples, desde que o parâmetro construtor de fluxo não seja um nó físico, mas um fluxo já existente, esse fluxo deve ser um fluxo de processamento e todos os fluxos de nós são diretamente físicos Nó de E / S como um parâmetro do construtor.
3. É muito simples para o programa usar o fluxo de processamento.Normalmente, você só precisa transmitir um fluxo de nó como parâmetro construtor ao criar o fluxo de processamento.O fluxo de processamento criado é o fluxo de processamento que envolve o fluxo do nó.
1.2 Vantagens dos fluxos de processamento
1. Para os desenvolvedores, é mais fácil usar o fluxo de processamento para operações de entrada / saída
2. A eficiência de execução do fluxo de processamento é
maior.O programa a seguir usa o fluxo de processamento pritStream para agrupar o OutputStream. Conveniente.
package section4;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.PrintStream;
public class PrintStreamTest
{
public static void main(String[] args)
{
try(
var pos=new FileOutputStream("src\\section4\\test.txt");
var ps=new PrintStream(pos))
{
//使用PrintStream执行输出
ps.println("普通字符串");
//直接使用PrintStream输出对象
ps.println(new PrintStreamTest());
}
catch (IOException IOe)
{
IOe.printStackTrace();
}
}
}
test.txt文件的内容:
普通字符串
section4.PrintStreamTest@5f184fc6
O programa acima define primeiro um fluxo de saída do nó FileOutputStream, depois o programa usa o PrintStream para agrupar o fluxo de saída do nó e, finalmente, usa o PrintStream para enviar seqüências de caracteres, objetos de saída ... O PrintStream é muito poderoso e o System.out usado no anterior O tipo a ser obtido é PrintStream.
Depois de usar o fluxo de processamento para quebrar o nó inferior, ao fechar os recursos de fluxo de entrada / saída, basta fechar o fluxo de processamento superior. Ao fechar o fluxo de processamento mais alto, o sistema fechará automaticamente o nó envolvido pelo fluxo de processamento

Segundo, o sistema de fluxo de entrada / saída
2.1 Classificação do sistema de entrada / saída
O sistema de fluxo de entrada / saída Java foi aprimorado em quase 40 categorias e a classificação por função é baseada em certas regras:
| Classificação | Fluxo de entrada de bytes | Fluxo de saída de bytes | Fluxo de entrada de caracteres | Fluxo de saída de caracteres |
|---|---|---|---|---|
| Classe base abstrata | InputStream | OutputStream | Leitor | Escritor |
| Arquivo de acesso | FileInputStream | FileOutputStream | FileReader | FileWriter |
| Matriz de acesso | ByteArrayInputStream | ByteArrayOutputStream | CharArrrayReader | CharArrayWriter |
| Pipeline de acesso | PipedInputStream | PipedOutputStream | PipedReader | PipedWriter |
| Cadeia de acesso | StringReader | StringWriter | ||
| Fluxo do buffer | BufferedInputStream | BufferedOutputStream | BufferedReader | BufferedWriter |
| Fluxo de conversão | ObjectInputStream | ObjectOutputStream | ||
| Classe base abstrata | FilterInputStream | FilterOutputStream | FilterReader | FilterWriter |
| Fluxo de impressão | PrintStream | PrintWriter | ||
| Empurre o fluxo de entrada | PushbackInputStream | PushbackReader | ||
| Fluxo especial | DataInputStream | DataOutputStream |
O vermelho em negrito representa o fluxo do nó, que deve ser associado ao nó físico especificado, o azul em negrito representa a classe base abstrata e a instância não pode ser criada diretamente.
O exemplo acima resume apenas os fluxos no pacote java.io no sistema de entrada / saída, bem como alguns fluxos de bytes como AudioInputStream, CipherInputStream, DeflaterInputStream, ZioInpuStream, etc. que têm acesso a arquivos de áudio, criptografia / descriptografia, compactação / descompressão etc. Possui funções especiais e está localizado em outros pacotes do JDK.
2.2 Arquivos de texto e arquivos binários
De um modo geral, o fluxo de bytes é mais poderoso do que o fluxo de caracteres, porque todos os dados no computador são binários e o fluxo de bytes pode lidar com todos os arquivos binários - mas o problema é que, se você usar o fluxo de bytes para processar arquivos de texto, Você precisa converter esses caracteres em bytes, o que aumenta a complexidade da programação. Portanto, geralmente existe uma regra: se o conteúdo de entrada / saída for de texto, considere o uso de fluxos de caracteres; se o conteúdo de entrada / saída for de conteúdo binário, considere o uso de fluxos de bytes.
Todos os arquivos de conteúdo de caracteres que podem ser abertos com o Bloco de Notas e vistos nele são chamados de arquivos de texto, caso contrário, são chamados de arquivos binários.
Mas, em essência, todo o texto no computador é um arquivo binário, e o arquivo de texto é apenas um caso especial do arquivo binário.Quando o arquivo binário pode ser adequadamente interpretado como caracteres, o arquivo binário se torna um arquivo de texto. E se você quiser ver o conteúdo normal do arquivo de texto, deverá usar o mesmo conjunto de caracteres ao abrir o arquivo (o chinês simplificado no Windows usa o conjunto de caracteres GBK por padrão e o Linux no Linux usa o conjunto de caracteres UTF-8 por padrão).
2.3 Fluxo para acessar a matriz
A tabela acima também lista um fluxo de nós que usa uma matriz como um nó físico, um fluxo de bytes que usa uma matriz de bytes como um nó e um fluxo de caracteres que usa uma matriz de caracteres como um nó; esse fluxo de nós que usa uma matriz como um nó físico, exceto para criar um nó O objeto de fluxo precisa invadir uma matriz de bytes ou de caracteres e seu uso é completamente semelhante ao do fluxo de arquivos. Semelhante a isso, o fluxo de caracteres também pode usar uma sequência como um nó físico, usado para realizar a função de ler conteúdo de uma sequência ou gravar conteúdo em uma sequência (usando StringBuffer como uma sequência). O programa a seguir demonstra o uso de cadeias de caracteres como entrada / saída de nós físicos.
package section4;
import java.io.IOException;
import java.io.StringReader;
import java.io.StringWriter;
public class StringNodeTest
{
public static void main(String[] args)
{
var src="从明天起,做一个幸福的人\n"
+"喂马、劈柴,周游世界\n"
+"从明天起,关心粮食和蔬菜\n"
+"我有一所房子,面朝大海,春暖花开\n"
+"从明天起,和每一个亲人通信\n"
+"告诉他们我的幸福\n";
var cbuffer=new char[32];
var hasRead=0;
try(
var sr=new StringReader(src))
{
//采用循环方式读取的方式读取字符串
while((hasRead=sr.read(cbuffer))>0)
{
System.out.println(new String(cbuffer,0,hasRead));
}
} catch (IOException e) {
e.printStackTrace();
}
try(
//创建StringWriter时,实际上是一个以StringBuffer作为作为输出节点
//下面指定的20就是StringBuffer的初始长度
var sw=new StringWriter(20))
{
//调用StringWriter方法执行输出
sw.write("我有一个美丽的新世界,\n");
sw.write("她在远方等我,\n");
sw.write("那里有天真的孩子,\n");
sw.write("还有姑娘的酒窝\n");
System.out.println("----下面是sw字符串节点里的内容----");
System.out.println(sw.toString());
}
catch (IOException ex)
{
ex.printStackTrace();
}
}
}
O programa acima é basicamente semelhante aos programas FileReader e FileWriter usados anteriormente, exceto que, ao criar objetos StringReader e StringWriter, o nó da string é passado, não o nó do arquivo. Como String é um objeto de sequência imutável, o StringWriter usa o StringBuffer como um nó de saída.
2.4 Fluxos para acessar o pipeline
Quatro fluxos para acessar o pipeline: PipedInputStream, PapedOutputStream, PipedReader, PipedWriter, são usados para alcançar a função de comunicação entre os processos, respectivamente fluxo de entrada de bytes, fluxo de entrada de bytes, fluxo de saída de bytes, fluxo de entrada de caracteres, fluxo de entrada de caracteres, fluxo de saída de caracteres.
2.5 Fluxo do buffer
Os quatro fluxos de buffer BufferedInputStream, BufferedOutputStream, BufferedReader e BufferedWriter aumentam a função de cache.A adição da função de cache pode melhorar a eficiência de entrada e saída. Após adicionar a função de cache, você precisa usar flush () para gravar o conteúdo da área de cache no nó físico real.
2.6 Fluxo de objetos
O fluxo de objetos é usado principalmente para realizar a serialização de objetos.
Três, fluxo de conversão
O fluxo de conversão é usado para converter um fluxo de bytes em um fluxo de caracteres, onde InputStreamReader converte um fluxo de saída de bytes em um fluxo de saída de caracteres; OutputStreamWriter converte uma saída de bytes em um fluxo de caracteres.
Como o fluxo de bytes é mais amplamente utilizado que o fluxo de caracteres, é mais conveniente operar do que o fluxo de bytes.Se um fluxo já for um fluxo de caracteres, ou seja, um fluxo conveniente, não será necessário converter para um fluxo de bytes. . Por outro lado, há um fluxo de bytes, mas pode ser determinado que o conteúdo do fluxo de bytes seja todo texto, portanto, é mais conveniente convertê-lo em um fluxo de caracteres, para que apenas o fluxo de bytes seja convertido no fluxo de caracteres e nenhum fluxo de caracteres seja convertido no fluxo de bytes.
A seguir, a entrada do teclado é usada como exemplo para introduzir o uso do fluxo de conversão. Java usa System.in como entrada padrão, ou seja, entrada do teclado, mas esse fluxo de entrada padrão é uma instância do InputStream, que não é conveniente de usar, e o conteúdo inserido pelo teclado é todo o conteúdo de texto, portanto, você pode usar o InputStreamReader para alterá-lo para um fluxo de entrada de caracteres O Reader comum ainda não é muito conveniente para ler o conteúdo. Você pode agrupar o Reader comum em um BufferedReader novamente. Você pode usar o método ReadeLine () do BufferedReader para ler uma linha de cada vez. Conforme mostrado no procedimento a seguir:
package section4;
import java.io.*;
public class KeyinTest
{
public static void main(String[] args)
{
try (
// 将Sytem.in对象转换成Reader对象
var reader = new InputStreamReader(System.in);
// 将普通Reader包装成BufferedReader
var br = new BufferedReader(reader))
{
String line = null;
// 采用循环方式来一行一行的读取
while ((line = br.readLine()) != null)
{
// 如果读取的字符串为"exit",程序退出
if (line.equals("exit"))
{
System.exit(1);
}
// 打印读取的内容
System.out.println("输入内容为:" + line);
}
}
catch (IOException ioe)
{
ioe.printStackTrace();
}
}
}
O programa acima converte o fluxo de entrada padrão System.in do fluxo de entrada InputStram em um fluxo de entrada de caracteres e o agrupa em um BufferedReader.O BufferedReader possui uma função de buffer, que pode ler uma linha de texto por vez - com uma quebra de linha como marca, se houver Quando uma nova linha é lida, o programa é bloqueado até que a nova linha seja lida.
Como o BufferedReader possui um método readLine (), é fácil ler uma linha de conteúdo; portanto, o fluxo de entrada que lê o conteúdo do texto geralmente é empacotado em um BufferedReader, porque é conveniente ler o conteúdo do texto do fluxo de entrada.
Quarto, empurre o fluxo de entrada
No sistema de fluxo de entrada / saída, existem dois fluxos especiais diferentes, a saber, PushbackInputStream e PushbackReader, que fornecem os três métodos a seguir:
(1) nulo não lido (byte [] / char [] buf): um O conteúdo da matriz de bytes / caracteres é empurrado de volta para o buffer, permitindo a leitura repetida do conteúdo que acabou de ser lido.
(2) nulo não lido (byte [] / char [] b, int desativado, int len): retira o conteúdo de uma matriz de bytes / caracteres, e o comprimento é len bytes / caractere de volta ao buffer de retorno Para permitir a leitura repetida do conteúdo, basta ler.
(3) nulo não lido (int b): insira um byte / caractere de volta no buffer de reserva, permitindo a leitura repetida do conteúdo que acabou de ler.
Os dois fluxos de entrada de retorno têm um buffer de retorno.Quando o programador chama o método não lido () desses dois fluxos de entrada de retorno, o sistema envia o conteúdo da matriz especificado de volta para a área do buffer e pressiona Sempre que o método read () é chamado de volta ao fluxo de entrada, ele é sempre lido no buffer de retorno, somente depois que o conteúdo do buffer de retorno é completamente lido, mas a matriz requerida por read () não é preenchida Irá ler a partir do fluxo de entrada original. A figura a seguir mostra um diagrama esquemático desse processamento de fluxo de entrada push-back:
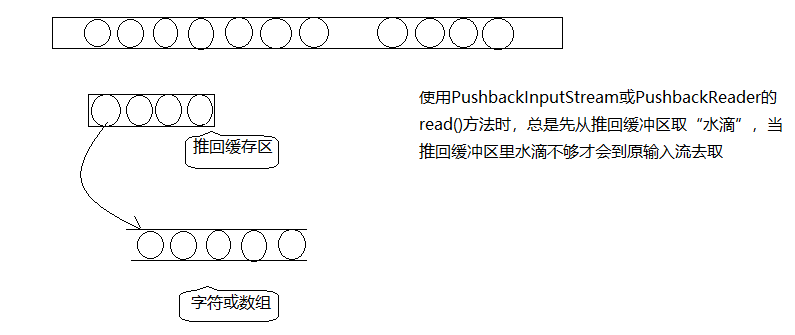
Ao criar um PushbackInputStream e PushbackReader, é necessário especificar o tamanho do buffer de pushback.O comprimento padrão do buffer de pushback é 1. Se o conteúdo do buffer de pushback no programa exceder o tamanho do buffer de pushback, o buffer de pushback será acionado. IOExceção de estouro.
O programa a seguir tenta encontrar a string "new PushbackReader" no programa.Quando a string é encontrada, o programa apenas imprime o conteúdo antes da string de destino.
package section4;
import java.io.FileReader;
import java.io.IOException;
import java.io.PushbackReader;
public class PushbackTest
{
public static void main(String[] args)
{
try(
//创建一个PushbackReader对象,指定推回缓冲区的长度为64
var pr = new PushbackReader(new FileReader("src\\section4\\PushbackTest.java"),64)
)
{
var buf=new char[32];
//用于保存上次读取到的字符串
var lastContent="";
var hasRead=0;
while((hasRead=pr.read(buf))>0)
{
//将读取到的内容转换为字符串
var content=new String(buf,0,hasRead);
var tagetIndex=0;
//将上次读取到的字符串发和本次读取到的字符串相连
//查看是否包含目标字符串,如果包含目标字符串
if((tagetIndex=(lastContent+content).indexOf("new PushbackReader"))>0)
{
//将本次内容和上次内容一起推回缓冲区
pr.unread((lastContent+content).toCharArray());
//重新定义一个长度为targetIndex的cahr数组
if((tagetIndex>32))
{
buf=new char[tagetIndex];
}
//再次读取指定长度的内容(就是目标字符串之前的内容)
pr.read(buf,0,tagetIndex);
//打印读取内容
System.out.print(new String(buf,0,tagetIndex));
System.exit(0);
}
else
{
//打印上次读取内容
System.out.print(lastContent);
//将本次内容设为上次读取到的内容
lastContent=content;
}
}
}
catch (IOException ioe)
{
ioe.printStackTrace();
}
}
}