Diretório do artigo
- 7.1: Modelo básico do sistema de recomendação
- 7.2: Arquitetura comum recomendada do sistema
- 7.3: Software comumente usado, usado para design de arquitetura.
- 7.4: Alguns problemas comuns
7.1 Modelo básico do sistema de recomendação
- O sistema de recomendação é aprendizado supervisionado
- Aprendizagem supervisionada sub-aprendizagem e previsão
- O sistema de aprendizagem usa uma determinada amostra de treinamento
- O modelo é obtido após o treinamento e, em seguida, o modelo será usado para prever o sistema de previsão.
- O sistema de previsão fornece previsões para as amostras de teste fornecidas pelo modelo
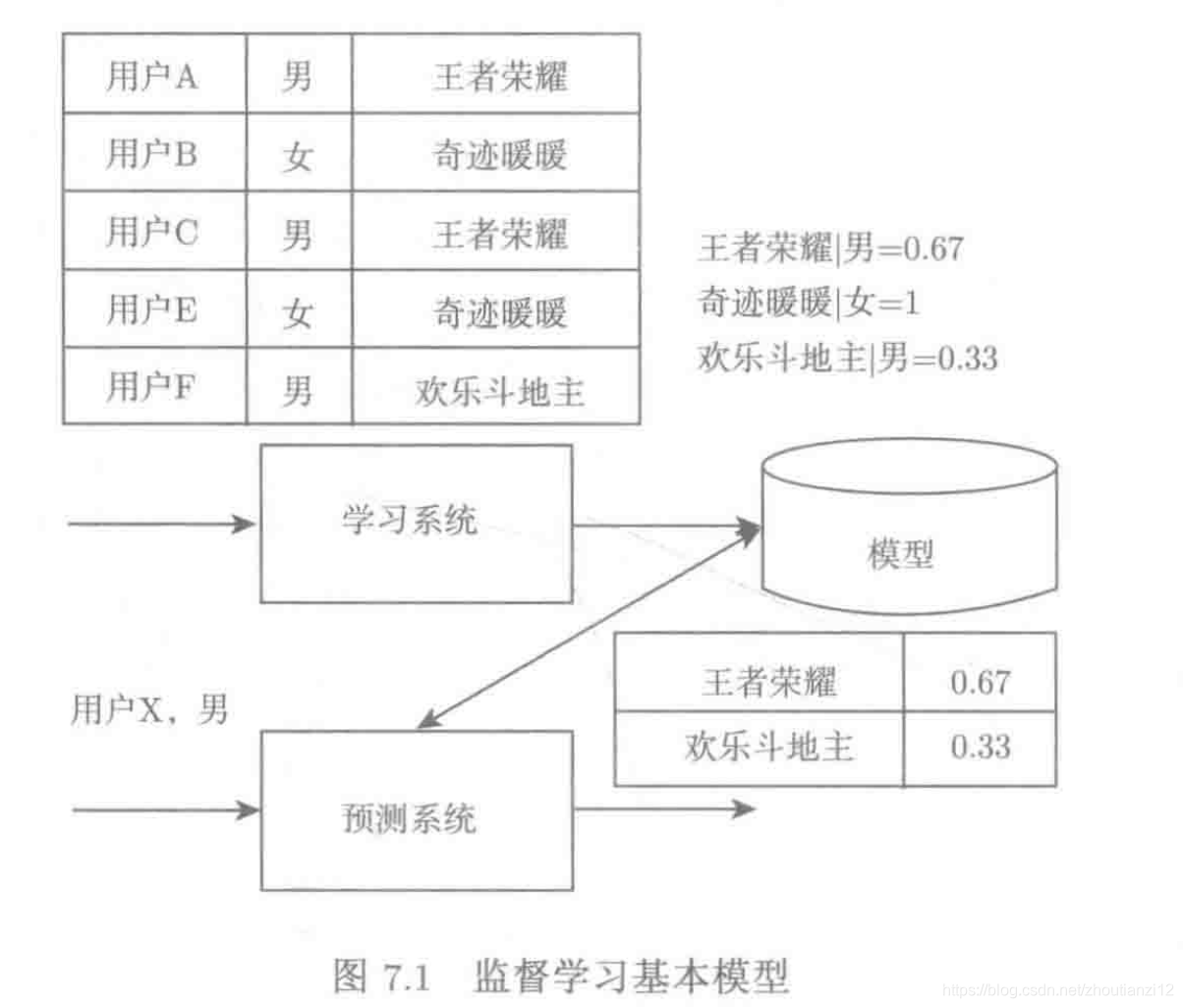
- O objetivo do sistema de recomendação
- Treine efetivamente o modelo através do sistema de aprendizado para que os resultados do sistema de previsão estejam próximos dos resultados reais das amostras de teste
- Conteúdo previsto,
- Gosta de um pedaço de informação, uma música ou um vídeo
- Probabilidade de comprar um determinado produto
- Otimização do sistema de recomendação,
- Passe (modelos, algoritmos, dados, recursos),
- Melhore a precisão dos resultados da previsão,
- Os itens recomendados para o usuário estão mais próximos das verdadeiras preferências do usuário
- A quantidade de dados do usuário processados pelo sistema de aprendizado será maior, os dados terão mais dimensões e o modelo de recomendação usado também será mais complicado
- Modelo de colaboração, modelo de conteúdo e modelo de conhecimento
- O modelo colaborativo adivinha principalmente o que eu gosto com base no que meus amigos gostam;
- O modelo de conteúdo é baseado no próprio item para prever que o usuário gosta de A e também pode gostar de B;
- O modelo de conhecimento é baseado nas condições limitadas do usuário e recomendado de acordo com suas necessidades
- O design da arquitetura do sistema recomendado é baseado no modelo básico de aprendizado supervisionado e personalizado de acordo com as necessidades da empresa. Polir um sistema de recomendação adequado às necessidades do negócio.
- No sistema de aprendizado, os dados devem ser relatados, limpos e estruturados em recursos.
- Você precisa de uma plataforma para armazenar e processar dados.
- Dependendo da quantidade de dados e do tipo de dados, o sistema de aprendizado pode precisar ser personalizado.
- No sistema de previsão, a solicitação de previsão precisa ser atendida e empacotada como uma API para chamadas comerciais.
- Ao mesmo tempo, também precisamos garantir a confiabilidade e a escalabilidade dos serviços online.
- Em seguida, introduza primeiro a arquitetura comumente usada do sistema de recomendação,
- Em seguida, com base no entendimento dessas arquiteturas, introduza alguns componentes comuns de cada módulo,
- Por fim, introduza alguns problemas comuns do sistema de recomendação.
7.2 Arquitetura comum do sistema de recomendação
- As várias arquiteturas de sistema de recomendação apresentadas nesta seção não são independentes, e os sistemas de recomendação reais podem usar uma ou mais dessas arquiteturas.
- Na prática, a arquitetura introduzida neste artigo pode ser usada como ponto de partida para o design, e um pensamento mais independente deve ser combinado com suas próprias características de negócios para projetar um sistema adequado para seus próprios negócios.
- Um sistema de recomendação baseado em treinamento offline e treinamento online em resposta à velocidade do comportamento do usuário.
- Sistema de recomendação usando aprendizado de máquina tradicional e aprendizado profundo
- Devido à importância dos negócios, uma categoria separada é introduzida: sistema de recomendação orientado a conteúdo.
- No final de cada seção, os problemas encontrados no design real do sistema serão introduzidos,
- Para referência de design.
7.2.1 Projeto de arquitetura do sistema de recomendação baseado em treinamento offline
- "Off-line"
- Treine com dados históricos por um período de tempo (uma semana ou semanas),
- O ciclo de iteração do modelo é longo (em horas)
- Montagem é o interesse de médio e longo prazo do usuário.
- Mercado de aplicativos móveis, recomendação de música
- O treinamento "on-line" refere-se ao treinamento incremental em tempo real,
- O modelo é necessário para responder rapidamente a cada amostra de treinamento.
- O usuário está assistindo a um vídeo de comida e permanece por um longo tempo,
- Em seguida, o próximo sistema de recomendação de vídeo recomendará mais vídeos semelhantes a você após detectar seu interesse a curto prazo
- A frequência de atualização dos dados de treinamento é em segundos.
- Informações, compras, recomendação de vídeo curta
- Sistema de recomendação baseado em treinamento offline: regressão logística, árvore de decisão para levantamento de gradiente
- Máquina de fatoração
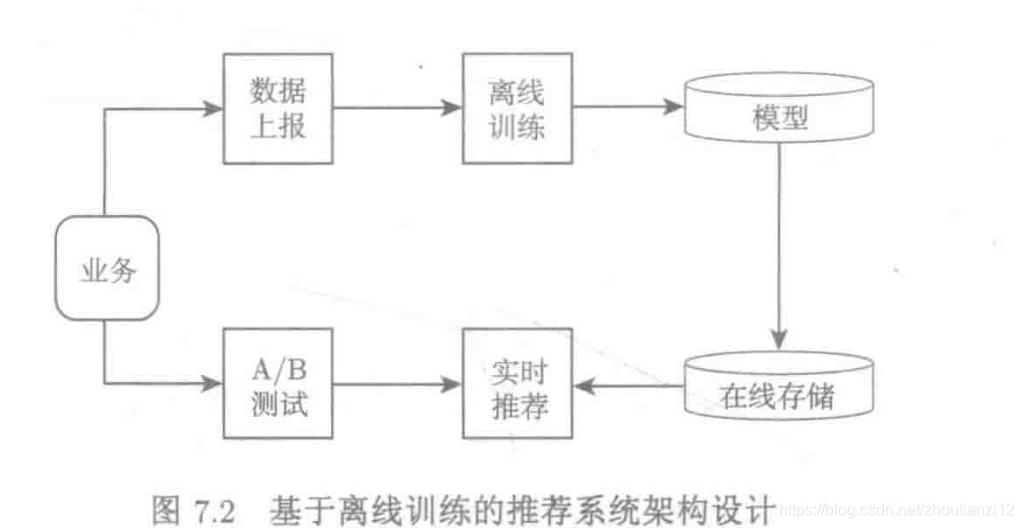
- Relatórios de dados e treinamento offline: sistema de aprendizado
- Cálculo em tempo real e teste A / B: sistema de previsão
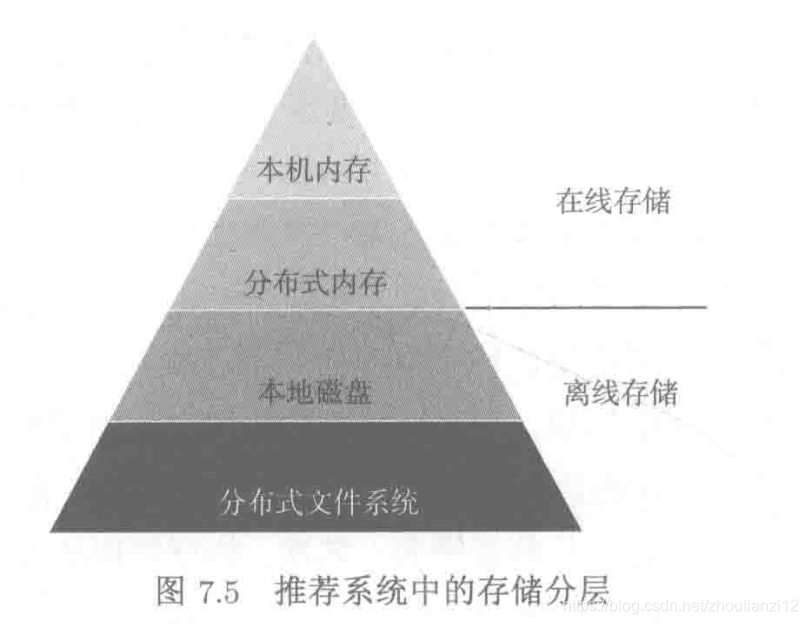
- Há também um módulo de armazenamento online,
- Armazene o modelo e as informações das características exigidas pelo modelo para o módulo de cálculo em tempo real chamar
- Os módulos na figura formam dois fluxos de dados para treinamento e previsão.
- O fluxo de dados de treinamento coleta dados comerciais e, finalmente, gera o modelo e os armazena no módulo de armazenamento online;
- O fluxo de dados previsto aceita a solicitação de previsão de negócios e acessa o módulo de cálculo em tempo real através do módulo de teste AB para obter o resultado da previsão.
- O fluxo de dados de treinamento precisa processar uma grande quantidade de dados de treinamento e o ciclo de atualização é mais longo, em horas,
- Portanto, a arquitetura correspondente é chamada de arquitetura baseada em treinamento offline
- O fluxo de dados previsto é usado para negócios na Internet e o atraso é de dezenas de milissegundos.
- Isso cria requisitos de arquitetura diferentes para cada módulo nos dois fluxos de dados para treinamento e previsão.
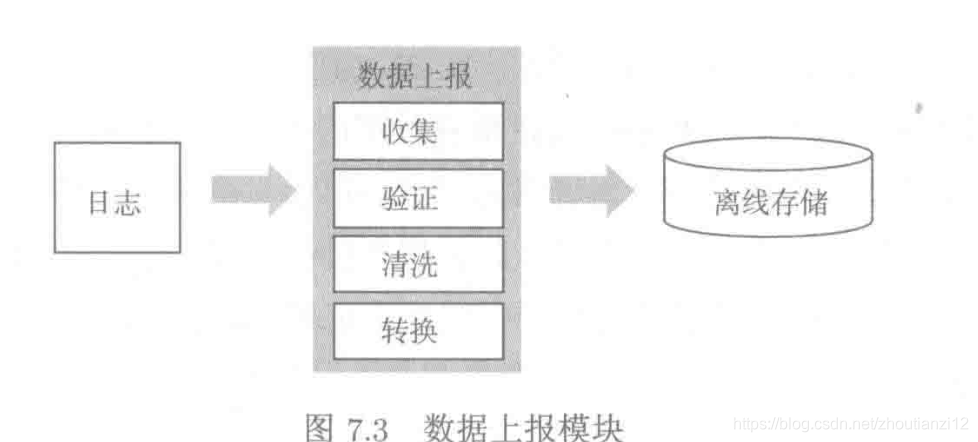
- Definir dados comerciais para formar amostras de treinamento
- Sub-coleta, verificação, limpeza e conversão
- Precisa coletar dados da empresa.
- Dirigido a negócios, coletado de várias dimensões de itens, usuários, cenas,
- As amostras de dados principais devem garantir a qualidade.
- Quantifique tudo, quanto melhor, melhor
- Verifique a precisão dos dados relatados para evitar relatar erros lógicos, desalinhamento de dados ou dados ausentes
- Para garantir a credibilidade dos dados, é necessário limpar os dados sujos.
- Limpeza de dados comum: verificação de valor nulo, valor anormal, tipo anormal, deduplicação de dados
- Conversão de dados, transforme os dados coletados no formato de amostra necessário para o treinamento,
- Salve no módulo de armazenamento offline.
- A qualidade dos dados é muito importante, se o resultado da previsão é preciso,
- Dependendo da força do modelo, mais importante é a qualidade e a quantidade dos dados de treinamento.
- Treinamento offline Módulo de treinamento offline Armazenamento de linha separado e cálculo offline
- O armazenamento offline requer um sistema de arquivos distribuído ou plataforma de armazenamento
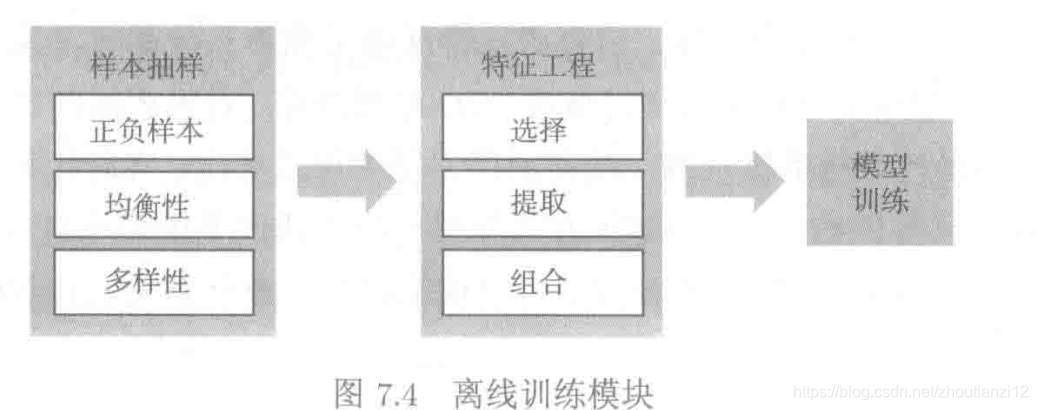
- Operações comuns para cálculo offline: amostragem de amostra, engenharia de recursos, treinamento de modelos, cálculo de similaridade
- A amostragem projeta as amostras razoavelmente e fornece informações de alta qualidade para o treinamento do modelo, treinando assim um modelo mais ideal.
- Definir razoavelmente amostras positivas e negativas, na prática, geralmente encontra desequilíbrio positivo e negativo
- É resolvido com pesos e combinações de punições, etc.
- Combine com o entendimento dos negócios, projete racionalmente amostras positivas e negativas.
- Ao projetar amostras, tente garantir o equilíbrio do número de amostras do usuário.
- Para tráfego malicioso de escova e usuários de robôs, a desduplicação de amostra garante o equilíbrio do número de amostra do usuário.
- Dê a devida consideração à diversidade de amostras. Enriqueça a fonte de amostras coletando amostras de usuários independentes do algoritmo de recomendação atual.
- A engenharia de recursos usa o conhecimento relacionado ao domínio para obter o máximo de informações possível dos dados originais, e os recursos são usados para melhorar os efeitos do treinamento do modelo.
- A seleção de recursos seleciona um conjunto dos subconjuntos de recursos estatisticamente mais significativos do conjunto de recursos através das etapas da função de avaliação, critério de parada e processo de verificação.
- A extração de recursos utiliza análise de componentes, análise discriminante e outros métodos para transformar e combinar recursos originais para construir novos recursos principais com significado comercial ou estatístico.
- Terceiro, a combinação de recursos combina incorporação multimodal e outros métodos para combinar vetores de recursos de usuários, itens e planos de fundo para obter informações complementares.
- Após as duas primeiras etapas, o treinamento do modelo usa um determinado conjunto de dados para obter um modelo por meio do treinamento, que é usado para descrever o mapeamento entre as variáveis de entrada e saída.
- Na prática, considerando a necessidade de lidar com conjuntos de treinamento em larga escala, geralmente serão selecionados algoritmos de tempo lineares que podem ser distribuídos para treinamento.
- Além dos módulos mencionados no sistema de recomendação da Figura 7.1 e Figura 7.2, também há um módulo de armazenamento online
- Os serviços online têm requisitos estritos de latência.
- O usuário abre o aplicativo e espera responder rapidamente
- Isso requer que o sistema de recomendação processe a solicitação do usuário e retorne os resultados da recomendação em dezenas de milissegundos.
- Para serviços online, deve haver um módulo de armazenamento online dedicado,
- Armazene dados de modelo e recurso para online
- O módulo de armazenamento online requer memória local ou memória distribuída
- Para tornar o armazenamento on-line o mais rápido possível, com base no software de código aberto, você também pode fazer algumas personalizações, estratégia de cache, estratégia incremental, estratégia de expiração diferida, unidade de estado sólido
- O módulo de recomendação em tempo real prevê novas solicitações de negócios
- Abra o APP, o APP envia uma solicitação ao servidor em segundo plano,
- Após receber a solicitação, o servidor adivinha suas preferências com base no histórico anterior do usuário no mercado de aplicativos
- Em seguida, retorne uma lista de aplicativos recomendados para o aplicativo móvel e apresente-a ao usuário na interface do aplicativo.
- O módulo de cálculo em tempo real requer os seguintes cálculos:
- (1) Para obter características do usuário, o sistema lê o retrato e o comportamento histórico do usuário no módulo de armazenamento on-line de acordo com o ID do usuário na solicitação e constrói as características do modelo do usuário.
- (2) Chamar o modelo de recomendação, combinar o modelo de usuário para chamar o modelo de algoritmo do sistema de recomendação e obter a probabilidade de preferência do usuário para itens em um determinado pool de candidatos a APP;
- (3) Classifique os resultados, classifique os resultados da pontuação do pool de candidatos e retorne a lista de resultados ao aplicativo móvel.
- O módulo de cálculo em tempo real precisa ler muitos dados do módulo de armazenamento on-line,
- Conclua um grande número de pontuação de modelo em pouco tempo
- O módulo possui requisitos de alto desempenho.
- Este módulo é uma estrutura de computação distribuída para concluir tarefas de computação.
- A lista de itens de negócios é muito grande,
- Cálculo em tempo real para pontuar cada item usando um modelo complexo,
- Demora demais
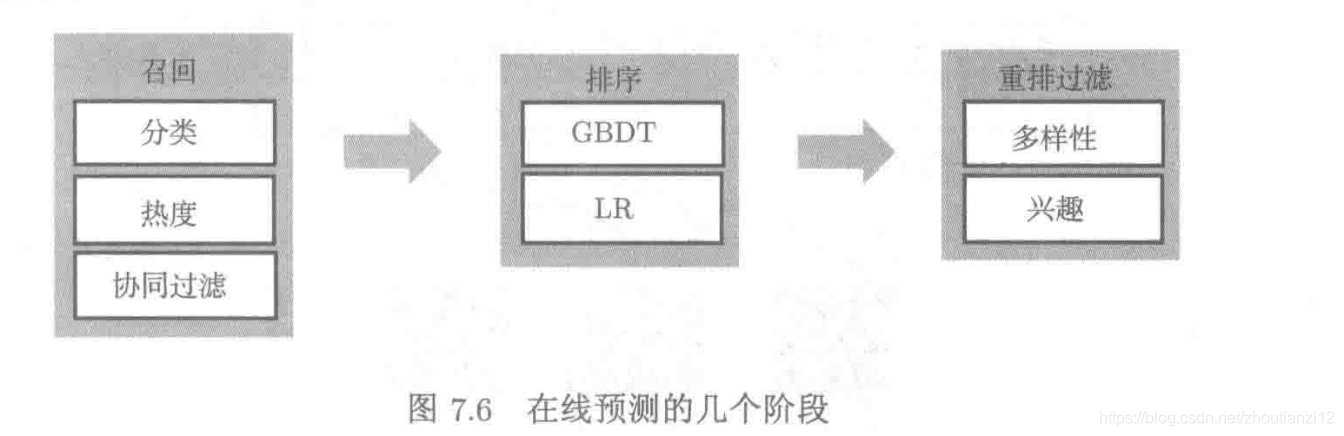
- Divida a geração da lista de recomendações em recall e classificação
- Lembre-se: selecione um conjunto de candidatos (centenas) entre um grande número de candidatos (milhões)
- A classificação usa o modelo de classificação para pontuar o conjunto de candidatos relativamente pequeno obtido pelo recall
- Depois que a lista de recomendações é classificada,
- Por questões de diversidade e operacionais,
- Adicione também a terceira filtragem de reorganização por etapas, usada para processar a lista recomendada após a classificação fina
- A filtragem de rearranjo fornece aos usuários algum conteúdo exploratório,
- Evite que o conteúdo que os usuários veem na plataforma seja muito homogêneo, filtre ilegalmente vulgar
- A arquitetura é mostrada na Figura 7.6
aqui
7.3 Componentes comuns do sistema de recomendação
7.3.1 Componentes comuns para relatórios de dados
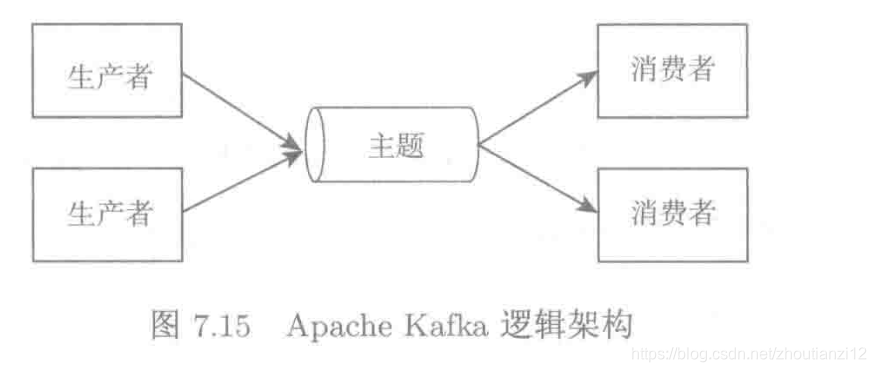
- Plataforma de processamento de fluxo de código aberto Apache Kafka
- Estrutura de processamento de alta produtividade e baixa latência para fontes de dados em tempo real.
- Logicamente, é uma implementação distribuída de filas de múltiplos produtores e vários consumidores
- As mensagens são gerenciadas por tópico, um tópico pode ter vários produtores e consumidores
- Os produtores produzem mensagens e as enviam para um tópico, e os consumidores que assinam o tópico recebem mensagens do tópico
7.3.2 Armazenamento offline de componentes comuns
- O HDFS (Sistema de Arquivos Distribuídos Hadoop) é um sistema de arquivos distribuídos amplamente usado.
- Baixo custo, alta confiabilidade e alto rendimento.
- Seu mecanismo de tolerância a falhas permite ao HDFS criar um sistema de arquivos distribuído com base em hardware de baixo custo e ainda pode fornecer armazenamento confiável, mesmo se houver falhas nos componentes.
- O Hive é um data warehouse baseado no Hadoop, com funções SQL mais completas,
- Use HDFS como o armazenamento subjacente
- É conveniente que pessoas familiarizadas com o SQL operem dados sem programação complicada.
- A escala de dados atinge centenas de PB e suporta o armazenamento de dados estruturados.
7.3.3 Componentes comuns para computação offline
- O Apache Spark é uma estrutura de computação distribuída de alto desempenho baseada no processamento de dados na memória,
- APIs simples, flexíveis e poderosas ajudam os usuários a desenvolver programas eficientes para análises de dados complexas.
- O Spark fornece um modelo de computação Mapreduce semelhante ao Hadoop, mas, diferentemente do Hadoop, o Spark usa uma estrutura de dados intermediária baseada em memória, o que facilita o suporte a cargas de trabalho que exigem várias iterações.
- tensorflow
- Estrutura de software de código aberto para cálculo numérico de gráficos de fluxo de dados.
- API poderosa e diversificada para os pesquisadores desenvolverem várias aplicações.
- O tensorflow distribuído fornece suporte para servidores de parâmetros.
- Diferente de outros servidores de parâmetros
- O servidor de parâmetros do Tensorflow atualiza os parâmetros implicitamente
- Os programadores não precisam pressionar e puxar manualmente esses parâmetros.
- Facilite o desenvolvimento do servidor de parâmetros com base no tensorflow
- A principal tarefa de escrever programas distribuídos de tensor-fluxo,
- Torna-se como distribuir os parâmetros para diferentes servidores de parâmetros razoavelmente,
- Configure os parâmetros por meio da interface de configuração do cluster, da interface designada do dispositivo e da interface do modo síncrono.
