Conhecimento teórico básico do Hadoop
- Design e desenvolvimento de HDFS (Sistema de arquivos distribuídos do Hadoop) com base no artigo publicado pelo Google
- Além das mesmas características de outros sistemas de arquivos distribuídos, também existem recursos exclusivos:
alta tolerância a falhas: o hardware é sempre não confiável e
alto rendimento: aplicativos que acessam grandes quantidades de dados fornecem alto rendimento e suportam
armazenamento de arquivos grandes: armazenamento de suporte Dados no nível PB - Para que é adequado o HDFS?
Armazenamento e acesso a arquivos grandes Acesso a
dados de streaming - Para que o HDFS não é adequado?
Armazenamento em massa de arquivos pequenos Gravação
aleatória Leitura de
baixa latência
Exemplos de cenários de aplicativos HDFS:
-
O HDFS é um sistema de arquivos distribuído na estrutura técnica do Hadoop, que gerencia arquivos implantados em máquinas físicas independentes.
-
Pode ser usado em uma variedade de cenários, como:
-
Armazenamento de dados de comportamento do usuário do site
-
Armazenamento de dados do ecossistema
-
Armazenamento de dados meteorológicos
Arquitetura básica do sistema
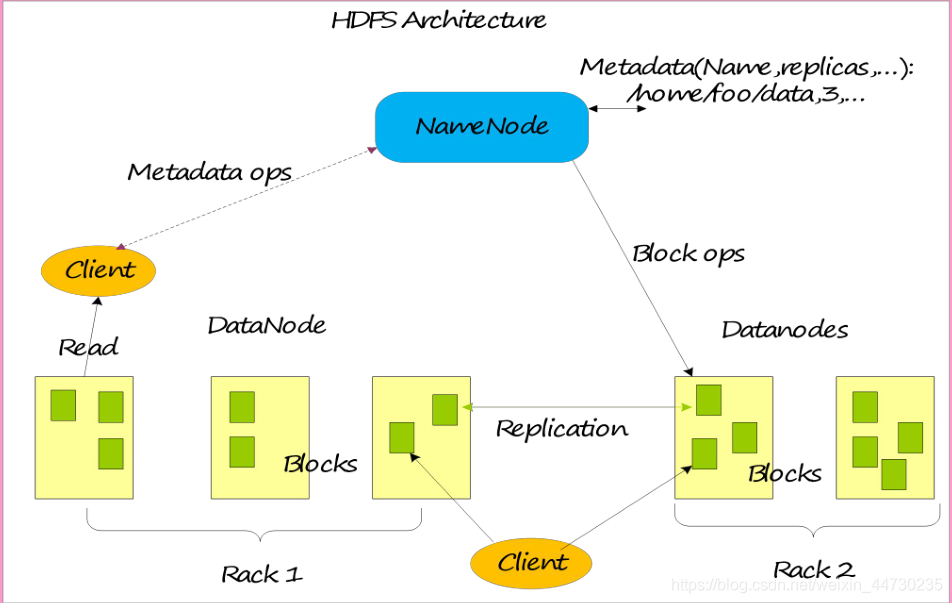
Design da chave da arquitetura HDFS
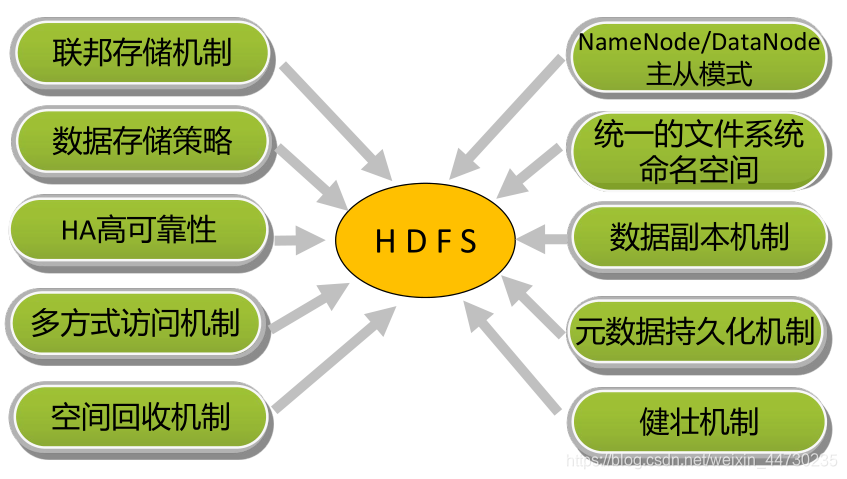
Alta confiabilidade HDFS (HA)
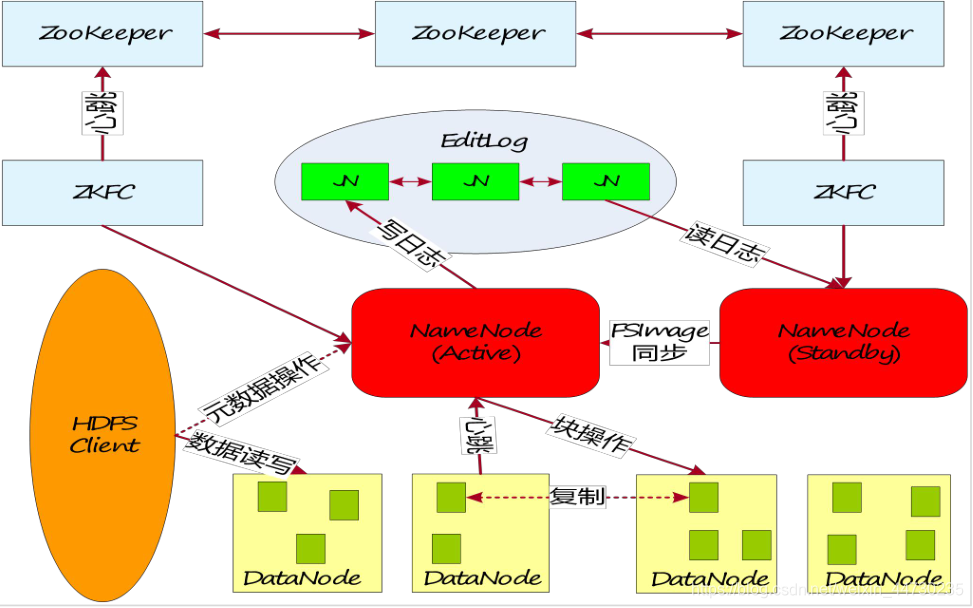
Persistência de metadados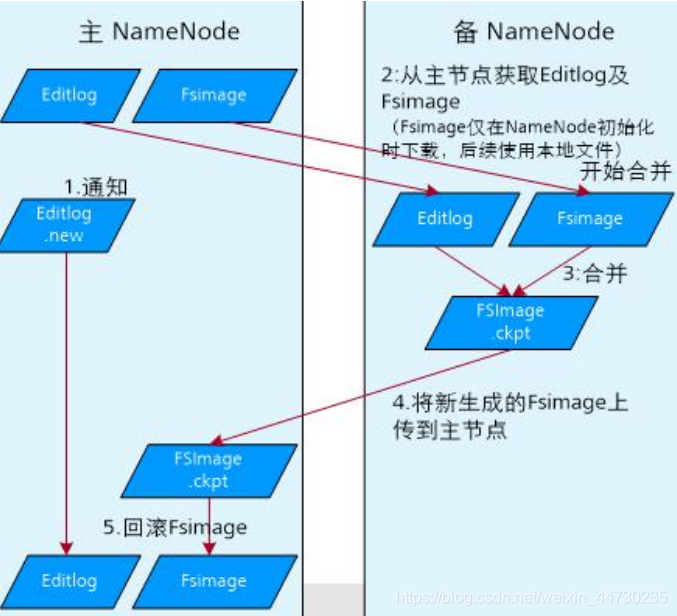
Configurar estratégia de armazenamento de dados HDFS
-
Por padrão, o HDFS NameNode seleciona automaticamente o DataNode para salvar uma cópia dos dados. Nos negócios reais, existem os seguintes cenários:
-
Existem diferentes dispositivos de armazenamento no DataNode, os dados precisam selecionar um dispositivo de armazenamento adequado para armazenar dados hierarquicamente
-
A importância dos dados em diferentes diretórios do DataNode é diferente.Os dados precisam ser selecionados de acordo com o rótulo do diretório para salvar um nó DataNode adequado
-
O cluster DataNode usa servidores heterogêneos e os dados críticos precisam ser armazenados em um grupo de nós altamente confiável.
Garantia de integridade de dados HDFS
-
O principal objetivo do HDFS é garantir a integridade dos dados armazenados e lidar com a confiabilidade de cada falha do componente.
-
Reconstrua os dados duplicados do disco com falha de dados: Quando o DataNode falha ao reportar ao NameNode periodicamente, o NameNode inicia uma ação de reconstrução de cópia para recuperar a cópia perdida.
-
Balanceamento de dados em cluster: mecanismo de balanceamento de dados, esse mecanismo garante que os dados sejam distribuídos igualmente em cada DataNode
-
Garantia de confiabilidade de metadados
-
Use o mecanismo de log para operar os metadados, e os metadados são armazenados no NameNode ativo e em espera
-
O mecanismo de captura instantânea implementa o mecanismo comum de captura instantânea do sistema de arquivos para garantir que ele possa ser restaurado no tempo em que os dados forem utilizados incorretamente.
-
Modo de segurança: no caso de falha no nó de dados e no disco rígido, pode impedir que a falha se espalhe.
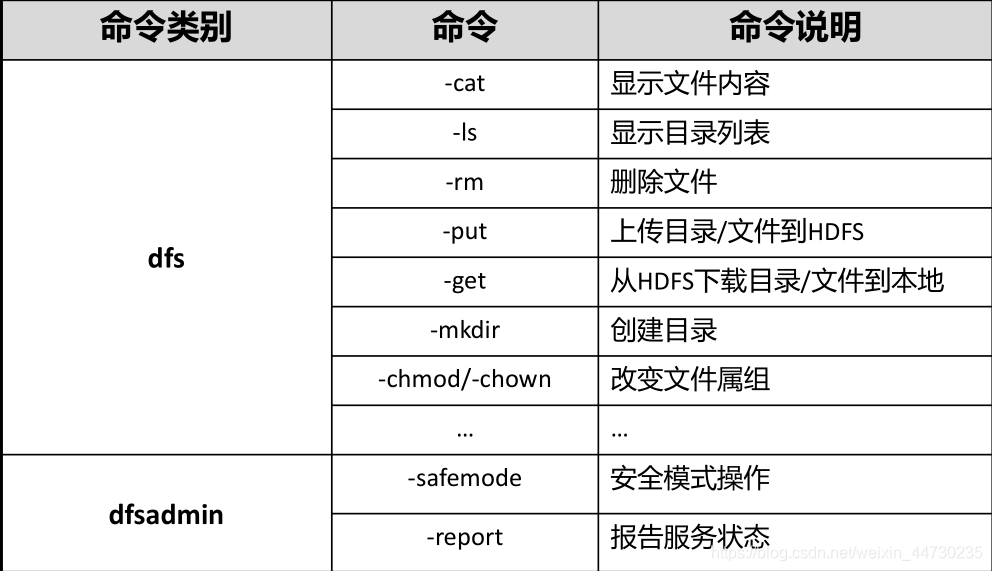
Comandos comuns do shell