O Kafka é um sistema de mensagens distribuído, particionável e replicável. Ele fornece as funções de um sistema de mensagens comum, mas possui um design exclusivo. Como é esse design exclusivo?
1. Introdução
O Kafka é um sistema de mensagens distribuído, particionável e replicável. Ele fornece as funções de um sistema de mensagens comum, mas possui um design exclusivo. Como é esse design exclusivo?
Primeiro, vamos examinar alguns termos básicos do sistema de mensagens:
• Kafka resume as mensagens nas unidades de tópicos.
• Kafka tema do programa será a disseminação de produtores de informação.
• O programa temas de livros e informação do consumidor para se tornar Consumidor.
• Kafka de execução em um cluster, pode consistir em um ou mais serviços, cada um é chamado um corretor.
Produtores de A rede envia mensagens para o cluster Kafka, e o cluster fornece mensagens para os consumidores, conforme mostrado na figura a seguir:
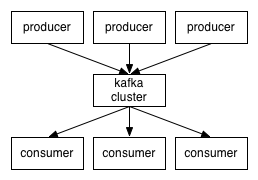
O cliente e o servidor se comunicam via protocolo TCP. Kafka fornece um cliente Java e suporta vários idiomas.
Descrição:
Sistema operacional: CentOS 6.x 64 bits
Edição Kafka: kafka_2.11-0.8.2.1
Para atingir a meta:
Instalação de máquina única e configuração kafka
Operação específica:
1. Desligue o firewall
Fechar: service iptables stop
disable: chkconfig iptables off
Segundo, instale o JDK
A operação Kadka requer suporte ao JDK
1. Faça o download do JDK
http://download.oracle.com/otn-pub/java/jdk/7u79-b15/jdk-7u79-linux-x64.rpm
Nota: Copie diretamente para a ferramenta de download para download.Use JDK7 para a versão.
Após a conclusão do download, faça o upload para o diretório / usr / local / src
2. Instale o JDK
cd / usr / local / src
chmod + x jdk-7u79-linux-x64.rpm # add permissão de execução
rpm -ivh jdk-7u79-linux-x64.rpm #install
Após a conclusão da instalação, você pode cd / usr / java / para o diretório de instalação para visualizar
3. Inclua o JDK nas variáveis de ambiente do sistema
vi / etc / profile #Edit, adicione o seguinte código no final
JAVA_HOME = / usr / java / jdk1.7.0_79
PATH = $ PATH: $ JAVA_HOME / bin: / usr / bin: / usr / sbin: / bin: / sbin: / usr / X11R6 / bin
CLASSPATH =.: $ JAVA_HOME / lib / tools.jar: $ JAVA_HOME / lib / dt.jar
exportar JAVA_HOME
PATH de exportação
exportação CLASSPATH
: wq! #Guardar e sair
source / etc / profile # efetue o arquivo de configuração imediatamente
java -version #Ver informações da versão do JDK
Neste ponto, a instalação do JDK está concluída.
Três, instale kafka
1. Faça o download do kafka
cd / usr / local / src
wget http://archive.apache.org/dist/kafka/0.8.2.1/kafka_2.11-0.8.2.1.tgz
Observe que a versão do kafka_2.11-0.8.2.1.tgz é uma versão compilada e pode ser usada após a descompressão.
tar -xzvf kafka_2.11-0.8.2.1.tgz #decompress
mv kafka_2.11-0.8.2.1 / usr / local / kafka #Mover para o diretório de instalação
2, arranjo kafka
mkdir / usr / local / kafka / log / kafka #Criar diretório de log kafka
cd / usr / local / kafka / config #Insira o diretório de configuração
vi server.properties #Editar e modificar os parâmetros correspondentes
broker.id = 0
port = 9092 # Número da porta
host.name = 192.168.5.56 # Endereço IP do servidor, altere para o próprio IP do servidor
log.dirs = / usr / local / kafka / log / kafka #Log caminho de armazenamento, o diretório criado acima
zookeeper.connect = localhost: 2181 # endereço e porta do zookeeper, implantação de configuração autônoma, localhost: 2181
: wq! #Guardar e sair
3. Configure o tratador
diretório mkdir / usr / local / kafka / zookeeper #create zookeeper
diretório mkdir / usr / local / kafka / log / zookeeper #create zookeeper log
cd / usr / local / kafka / config #Insira o diretório de configuração
vi zookeeper.properties #Editar e modificar os parâmetros correspondentes
dataDir = / usr / local / kafka / zookeeper # diretório de dados do zookeeper
dataLogDir = / usr / local / kafka / log / zookeeper # diretório de log do zookeeper
clientPort = 2181
maxClientCnxns = 100
tickTime = 2000
initLimit = 10
syncLimit = 5
: wq! #Guardar e sair
Quarto, crie um script kafka de inicialização e desligamento
cd / usr / local / kafka
#Criar script de inicialização
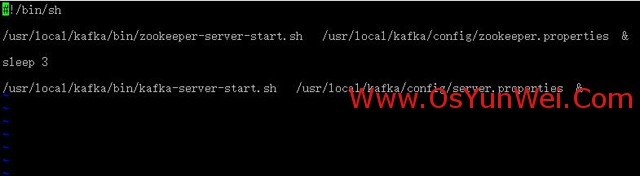
vi kafkastart.sh #Editar, adicione o seguinte código
#! / bin / sh
#Iniciar zookeeper
/usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties &
dormir 3 #Espere 3 segundos depois
#Iniciar kafka
/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties &
: wq! #Guardar e sair
#Criar script de fechamento
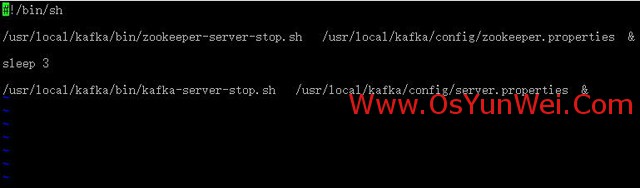
vi kafkastop.sh #Edit, adicione o seguinte código
#! / bin / sh
#Fechar zookeeper
/usr/local/kafka/bin/zookeeper-server-stop.sh /usr/local/kafka/config/zookeeper.properties &
dormir 3 #Espere 3 segundos depois
#Fechar kafka
/usr/local/kafka/bin/kafka-server-stop.sh /usr/local/kafka/config/server.properties &
: wq! #Guardar e sair
#Adicionar permissão de execução de script
chmod + x kafkastart.sh
chmod + x kafkastop.sh
Quinto, defina o script para executar automaticamente na inicialização
vi /etc/rc.d/rc.local #Edit, adicione uma linha no final
sh /usr/local/kafka/kafkastart.sh & # Defina o script para ser executado automaticamente em segundo plano na inicialização
: wq! #Guardar e sair
sh /usr/local/kafka/kafkastart.sh #Start kafka
sh /usr/local/kafka/kafkastop.sh #Fechar kafka
Neste ponto, a instalação e configuração independentes do Kafka no Linux estão concluídas.
O Kafka é um sistema de mensagens distribuído, particionável e replicável. Ele fornece as funções de um sistema de mensagens comum, mas possui um design exclusivo. Como é esse design exclusivo?
1. Introdução
O Kafka é um sistema de mensagens distribuído, particionável e replicável. Ele fornece as funções de um sistema de mensagens comum, mas possui um design exclusivo. Como é esse design exclusivo?
Primeiro, vamos examinar alguns termos básicos do sistema de mensagens:
• Kafka resume as mensagens nas unidades de tópicos.
• Kafka tema do programa será a disseminação de produtores de informação.
• O programa temas de livros e informação do consumidor para se tornar Consumidor.
• Kafka de execução em um cluster, pode consistir em um ou mais serviços, cada um é chamado um corretor.
Produtores de A rede envia mensagens para o cluster Kafka, e o cluster fornece mensagens para os consumidores, conforme mostrado na figura a seguir:
O cliente e o servidor se comunicam via protocolo TCP. Kafka fornece um cliente Java e suporta vários idiomas.
Descrição:
Sistema operacional: CentOS 6.x 64 bits
Edição Kafka: kafka_2.11-0.8.2.1
Para atingir a meta:
Instalação de máquina única e configuração kafka
Operação específica:
1. Desligue o firewall
Fechar: service iptables stop
disable: chkconfig iptables off
Segundo, instale o JDK
A operação Kadka requer suporte ao JDK
1. Faça o download do JDK
http://download.oracle.com/otn-pub/java/jdk/7u79-b15/jdk-7u79-linux-x64.rpm
Nota: Copie diretamente para a ferramenta de download para download.Use JDK7 para a versão.
Após a conclusão do download, faça o upload para o diretório / usr / local / src
2. Instale o JDK
cd / usr / local / src
chmod + x jdk-7u79-linux-x64.rpm # add permissão de execução
rpm -ivh jdk-7u79-linux-x64.rpm #install
Após a conclusão da instalação, você pode cd / usr / java / para o diretório de instalação para visualizar
3. Inclua o JDK nas variáveis de ambiente do sistema
vi / etc / profile #Edit, adicione o seguinte código no final
JAVA_HOME = / usr / java / jdk1.7.0_79
PATH = $ PATH: $ JAVA_HOME / bin: / usr / bin: / usr / sbin: / bin: / sbin: / usr / X11R6 / bin
CLASSPATH =.: $ JAVA_HOME / lib / tools.jar: $ JAVA_HOME / lib / dt.jar
exportar JAVA_HOME
PATH de exportação
exportação CLASSPATH
: wq! #Guardar e sair
source / etc / profile # efetue o arquivo de configuração imediatamente
java -version #Ver informações da versão do JDK
Neste ponto, a instalação do JDK está concluída.
Três, instale kafka
1. Faça o download do kafka
cd / usr / local / src
wget http://archive.apache.org/dist/kafka/0.8.2.1/kafka_2.11-0.8.2.1.tgz
Observe que a versão do kafka_2.11-0.8.2.1.tgz é uma versão compilada e pode ser usada após a descompressão.
tar -xzvf kafka_2.11-0.8.2.1.tgz #decompress
mv kafka_2.11-0.8.2.1 / usr / local / kafka #Mover para o diretório de instalação
2, arranjo kafka
mkdir / usr / local / kafka / log / kafka #Criar diretório de log kafka
cd / usr / local / kafka / config #Insira o diretório de configuração
vi server.properties #Editar e modificar os parâmetros correspondentes
broker.id = 0
port = 9092 # Número da porta
host.name = 192.168.5.56 # Endereço IP do servidor, altere para o próprio IP do servidor
log.dirs = / usr / local / kafka / log / kafka #Log caminho de armazenamento, o diretório criado acima
zookeeper.connect = localhost: 2181 # endereço e porta do zookeeper, implantação de configuração autônoma, localhost: 2181
: wq! #Guardar e sair
3. Configure o tratador
diretório mkdir / usr / local / kafka / zookeeper #create zookeeper
diretório mkdir / usr / local / kafka / log / zookeeper #create zookeeper log
cd / usr / local / kafka / config #Insira o diretório de configuração
vi zookeeper.properties #Editar e modificar os parâmetros correspondentes
dataDir = / usr / local / kafka / zookeeper # diretório de dados do zookeeper
dataLogDir = / usr / local / kafka / log / zookeeper # diretório de log do zookeeper
clientPort = 2181
maxClientCnxns = 100
tickTime = 2000
initLimit = 10
syncLimit = 5
: wq! #Guardar e sair
Quarto, crie um script kafka de inicialização e desligamento
cd / usr / local / kafka
#Criar script de inicialização
vi kafkastart.sh #Editar, adicione o seguinte código
#! / bin / sh
#Iniciar zookeeper
/usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties &
dormir 3 #Espere 3 segundos depois
#Iniciar kafka
/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties &
: wq! #Guardar e sair
#Criar script de fechamento
vi kafkastop.sh #Edit, adicione o seguinte código
#! / bin / sh
#Fechar zookeeper
/usr/local/kafka/bin/zookeeper-server-stop.sh /usr/local/kafka/config/zookeeper.properties &
dormir 3 #Espere 3 segundos depois
#Fechar kafka
/usr/local/kafka/bin/kafka-server-stop.sh /usr/local/kafka/config/server.properties &
: wq! #Guardar e sair
#Adicionar permissão de execução de script
chmod + x kafkastart.sh
chmod + x kafkastop.sh
Quinto, defina o script para executar automaticamente na inicialização
vi /etc/rc.d/rc.local #Edit, adicione uma linha no final
sh /usr/local/kafka/kafkastart.sh & # Defina o script para ser executado automaticamente em segundo plano na inicialização
: wq! #Guardar e sair
sh /usr/local/kafka/kafkastart.sh #Start kafka
sh /usr/local/kafka/kafkastop.sh #Fechar kafka
Neste ponto, a instalação e configuração independentes do Kafka no Linux estão concluídas.