Este artigo explica a operação usando a ferramenta kibana:
Arranjo kibana
Faça o download e descompacte o kibana, encontre o kibana.yml na pasta config no diretório raiz, modifique a configuração da seguinte maneira

- ** Até o momento (a versão mais recente oficial atual é 6.4), o oficial significa: temporariamente não suporta a conexão de vários nós es, ou seja, apenas um endereço pode ser preenchido no arquivo de configuração acima. ** Outra solução fornecida pelo site oficial: https://www.elastic.co/guide/en/kibana/6.4/production.html#load-balancing
aproximadamente significa:
Crie um nó es que seja usado apenas para "coordenação", deixe-o ingressar no cluster es e, em seguida, o kibana se conecte a esse nó "coordenação" .Este nó "coordenação" não participa da eleição do nó mestre e não armazena dados. É usado apenas para processamento Solicitação HTTP de entrada e redirecione a operação para outros nós do cluster, depois colete e retorne o resultado. Esse nó de "coordenação" também desempenha essencialmente um papel de balanceamento de carga.
Após instalar o plugin xpack, você pode ativar a verificação de login.Se a senha estiver configurada da seguinte maneira:
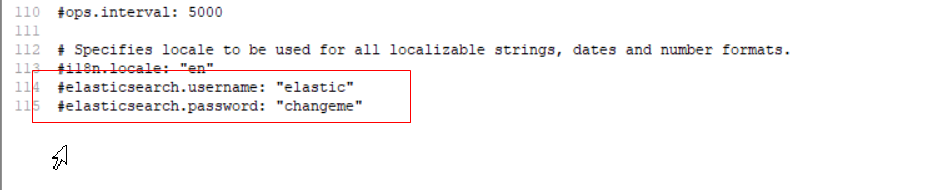
você poderá iniciá-la após a conclusão da configuração, visite: http: // localhost: 5601
Conceitos básicos
_index 文档在哪存放
_type 文档表示的对象类别
_id 文档唯一标识
API de índice
# 创建索引(插入数据,没有索引会创建)
PUT twitter/_doc/1
{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}

total - indica que a operação de índice deve ser executada em várias cópias de fragmentos (fragmento primário e fragmento de réplica).
successful-Indica o número de cópias de shard executadas com sucesso pela operação de índice.
falha - se a operação de índice falhar no fragmento de réplica, a matriz que contém erros relacionados à replicação
# 允许创建 叫twitter,index10 没有其他的折射率匹配index1*,以及任何其他折射率匹配ind*。模式按照给定的顺序进行匹配
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": "twitter,index10,-index1*,+ind*"
}
}
# 不允许 自动创建索引
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": "false"
}
}
# 允许创建所有类型索引
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": "true"
}
}
Obter API
# 根据id查询
GET twitter/_doc/1

Excluir API
# 根据id删除
DELETE /twitter/_doc/1
# 根据查询条件删除
POST twitter/_delete_by_query
{
"query": {
"match": {
"user": "kimchy"
}
}
}

API em massa
#多条命令一起执行
POST _bulk
{ "index" : { "_index" : "test", "_type" : "_doc", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_type" : "_doc", "_id" : "2" } }
{ "create" : { "_index" : "test", "_type" : "_doc", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_type" : "_doc", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
Atualização da API
POST twitter/_doc/3/_update
{
"doc" : {
"user" : "liuli-new"
}
}

Reindexar API
POST _reindex
{
"source": {
"index": "twitter"
},
"dest": {
"index": "new_twitter"
}
}
Este artigo simplesmente lista alguns exemplos. Existem muitos documentos de API em es. Você pode aprender com os documentos oficiais de acordo com suas necessidades.

Documentos de referência:
https://www.elastic.co/guide/en/elasticsearch/reference/6.5/docs.html
