Capítulo V implantar ambiente de dados grande para construir um pseudo---Spark distribuído
Introdução: esta série de tutoriais, trazendo o leitor padrão foi instalado Hadoop, jdk;
se já não estiver configurado esses serviços, você pode ver a configuração Bowen conduta de referência anterior autor
Primeiro, a fase preparatória
- download do arquivo scala e configuração
(1) no site do scala oficial para copiar o link de download
para baixar o site oficial: https://www.scala-lang.org/download/
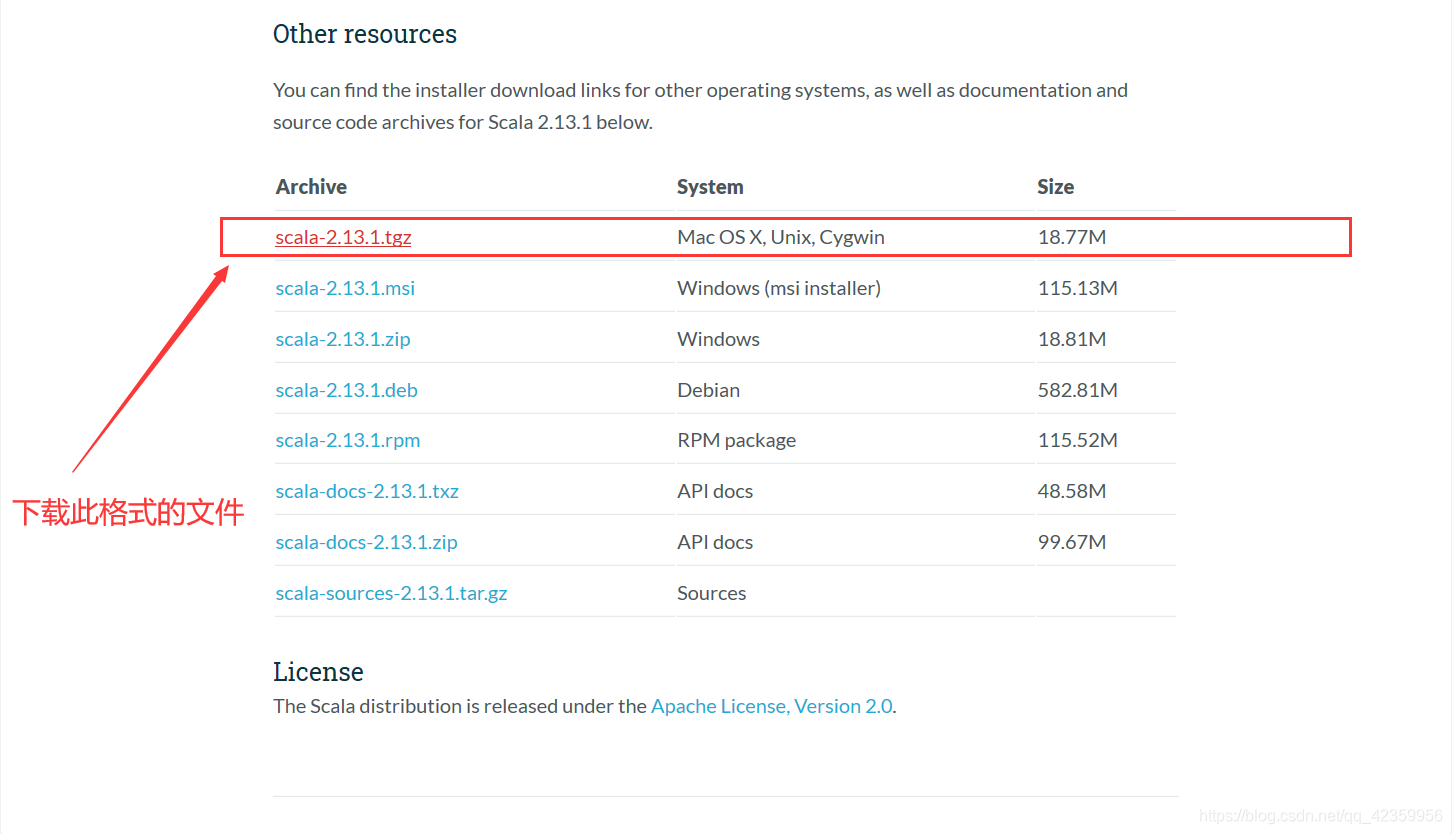
no site oficial do Ministério do drop-down no final escolher este formato de arquivo para copiar o link de download
(2) Baixe e descompacte arquivo de
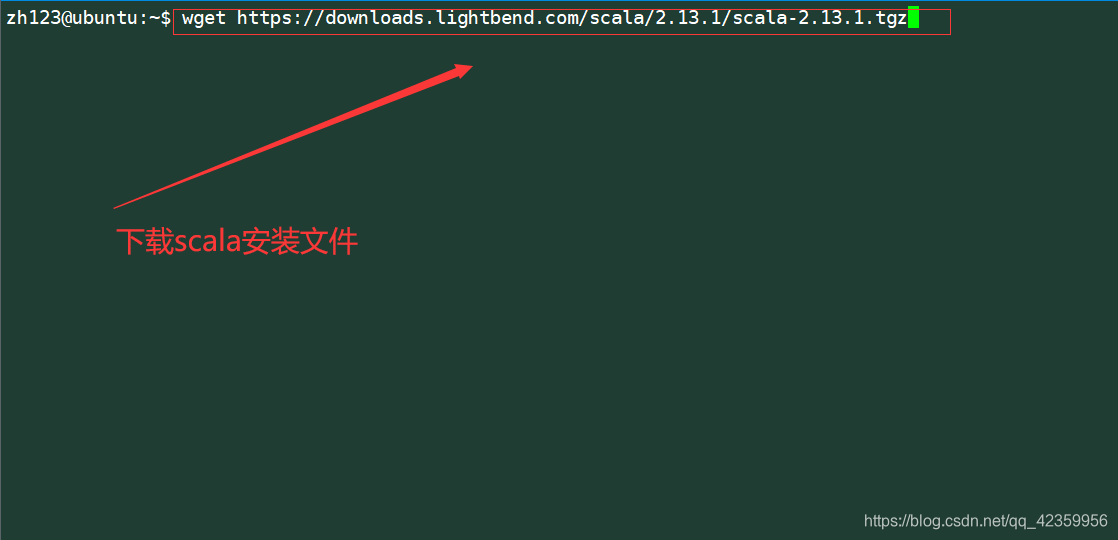
comando: wget https://downloads.lightbend.com/scala/2.13.1/scala-2.13.1.tgz
o extrato arquivo baixado para ~ / opt / diretório
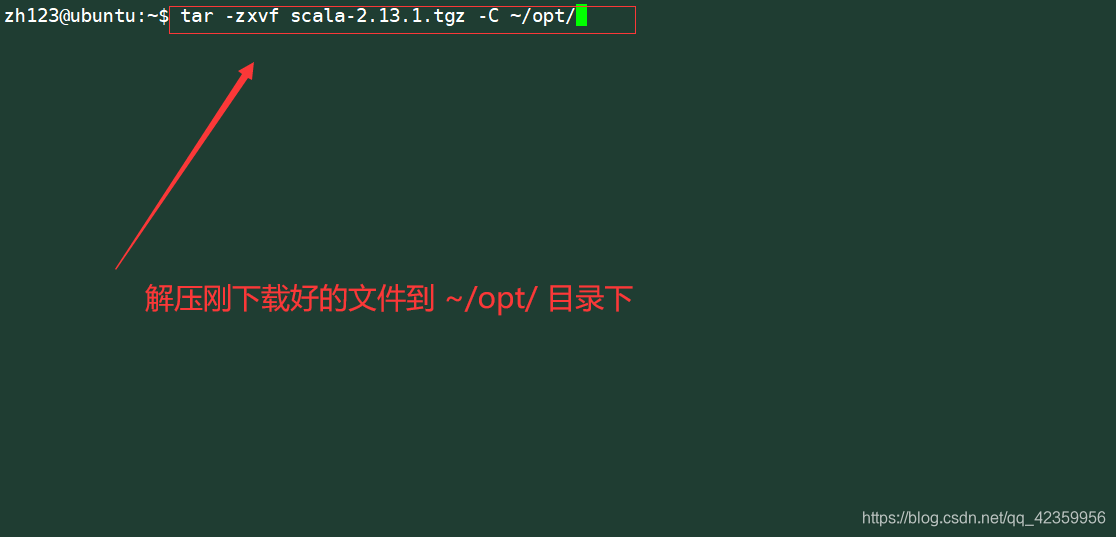
comando: tar -zxvf scala-2.13.1 .tgz -C ~ / opt /
criar uma ligação suave da parte traseira para fácil manutenção
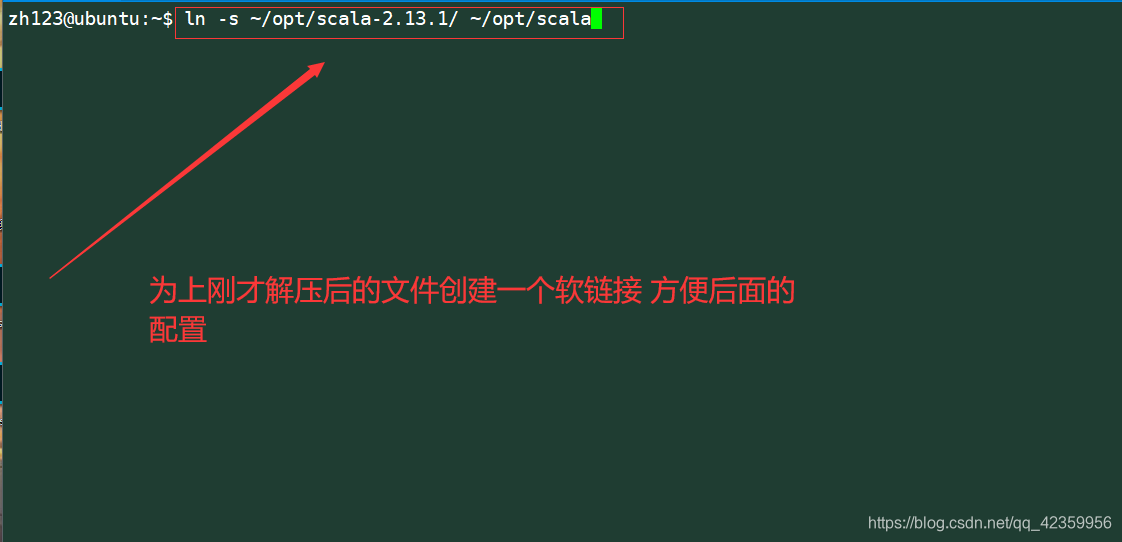
Comando: ln -s ~ / opt / scala-2.13.1 / ~ / opt / scala
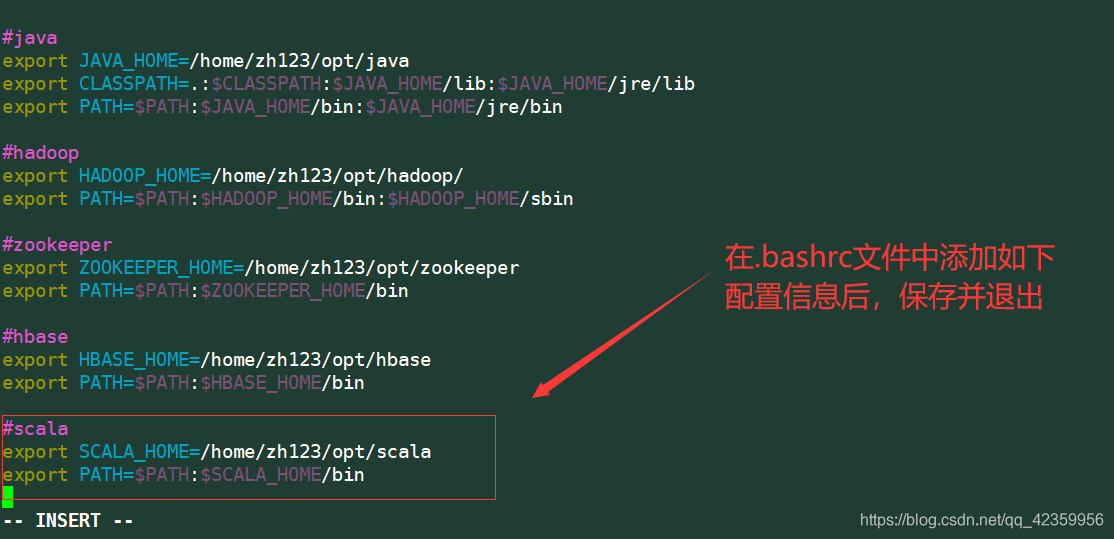
Modificar o ambiente scala o arquivo de configuração .bashrc
Comando: vim .bashrc
在文件的末尾插入scala的位置信息
exportação SCALA_HOME = / home / zh123 / opt / scala
export PATH = $ PATH: $ SCALA_HOME / bin
Depois que você terminar de usar o comando:
.bashrc fonte de modo que apenas a configuração tenha efeito
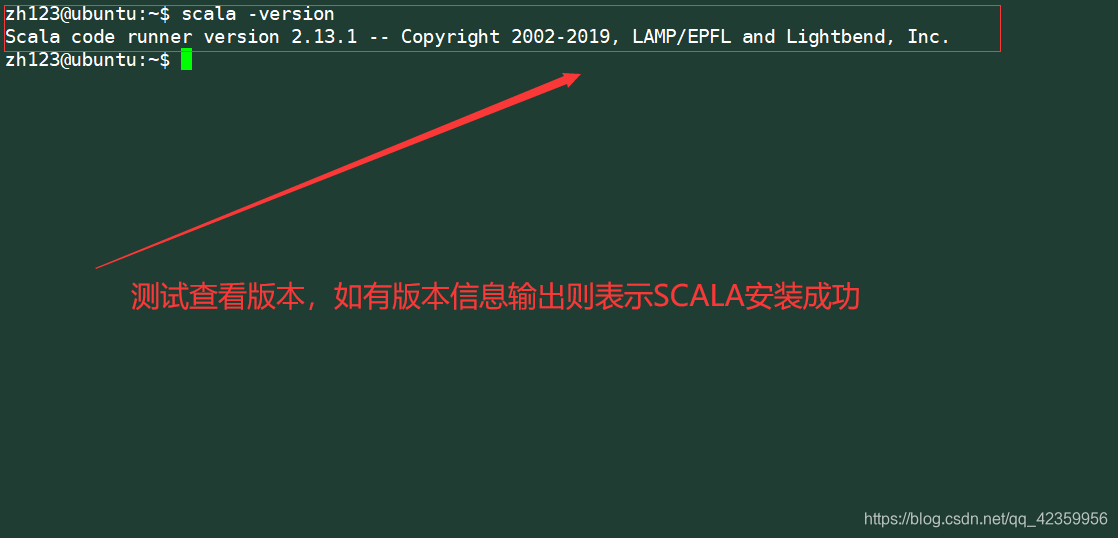
然后使用命令
scala scala -version teste para ver se a versão de vista o sucesso
- download do arquivo faísca
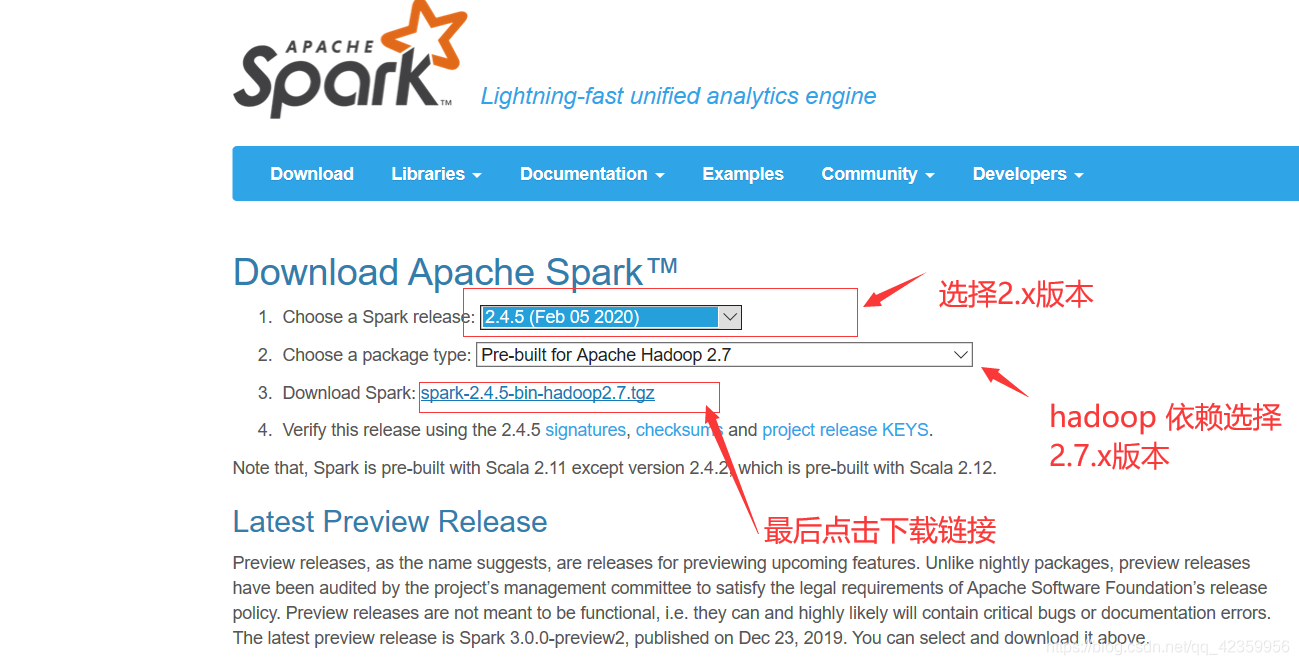
(1) Entre no site oficial
endereço do site oficial: http://spark.apache.org/downloads.html
selecionar a versão necessária para baixar
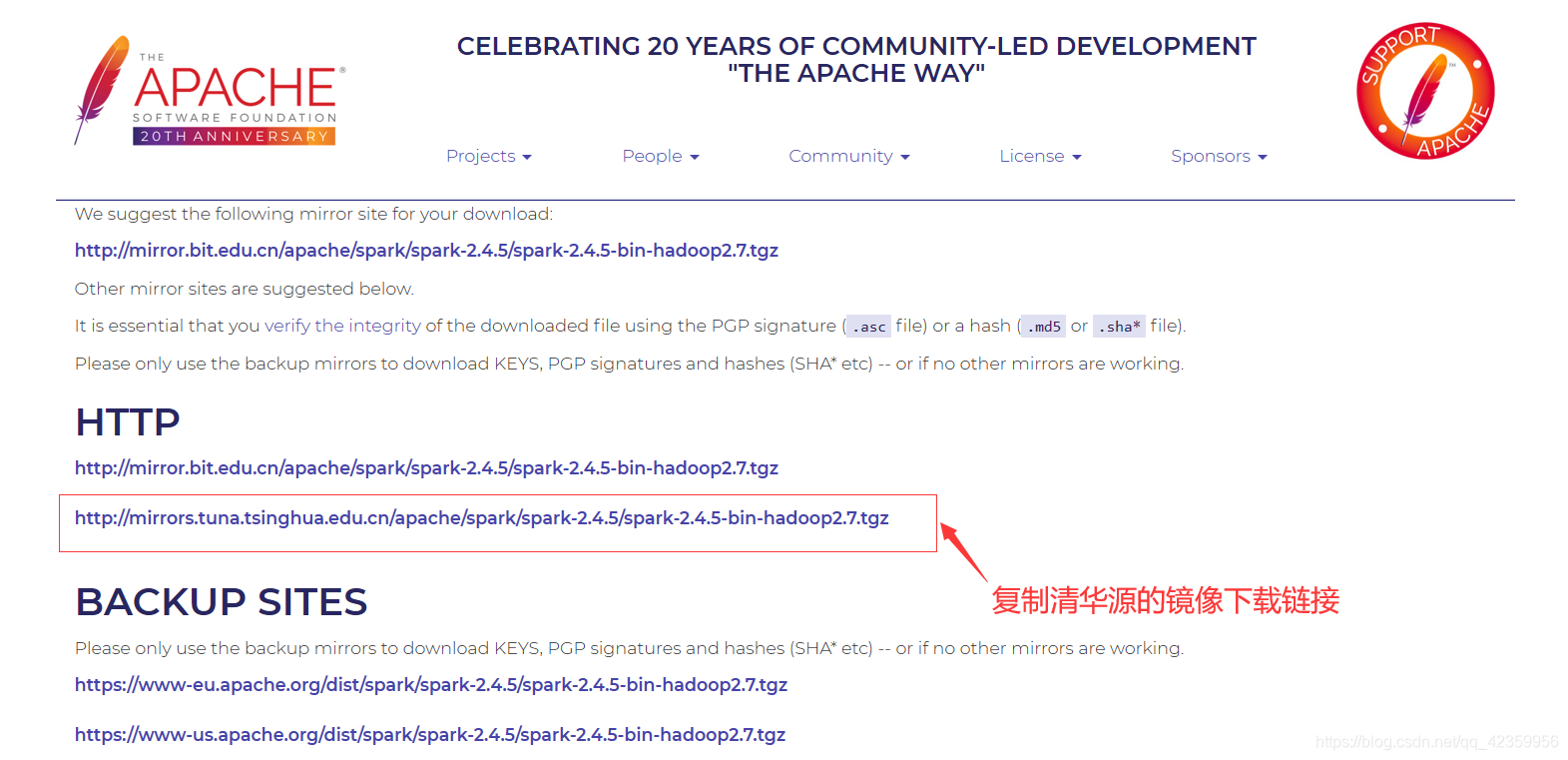
copiar a imagem de download link da fonte Tsinghua
(2) Baixe e descompacte o arquivo
Comando wget http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz
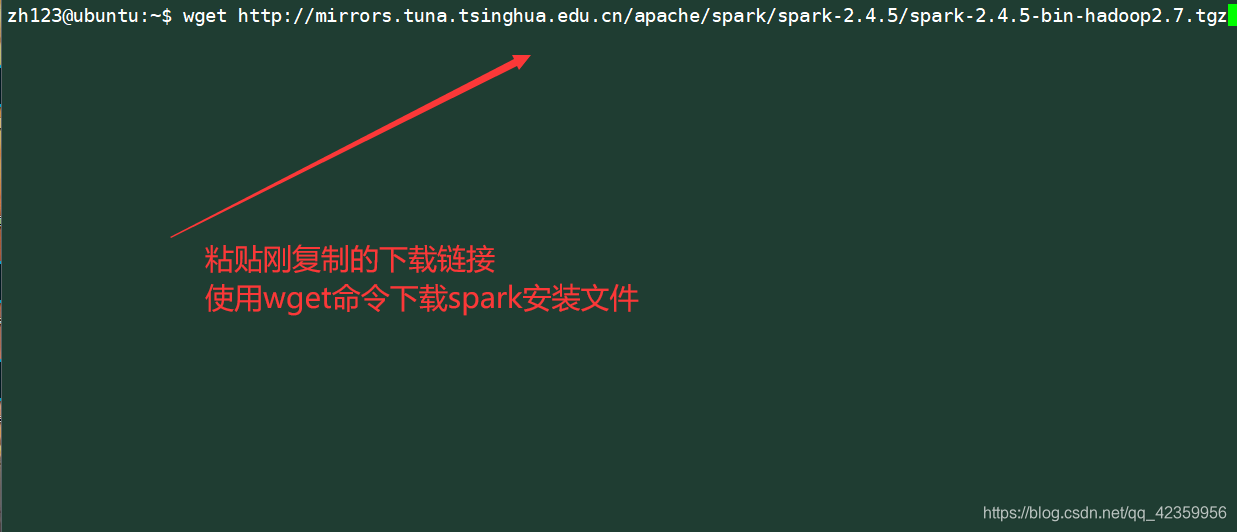
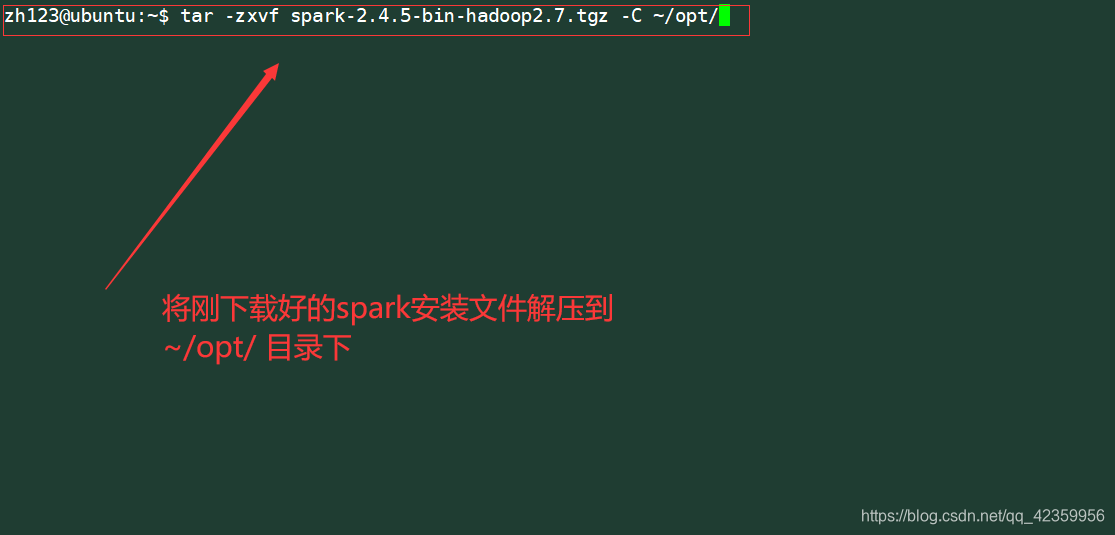
Extraia o arquivo baixado para a próxima bom ~ / opt / diretório
命令: alcatrão -zxvf faísca-2.4.5-bin-hadoop2.7.tgz -C ~ / opt /
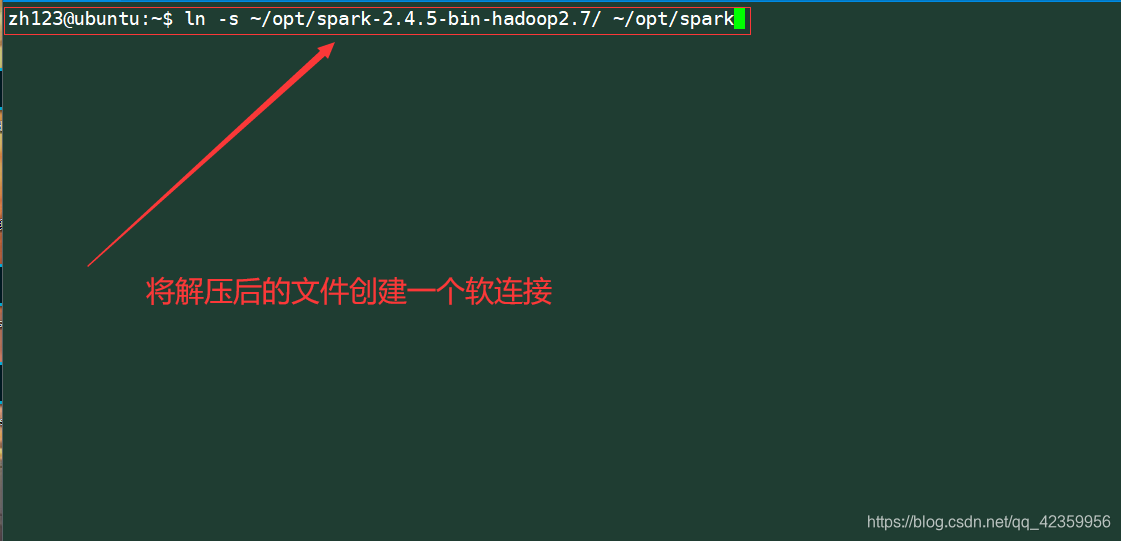
Criar um soft link para o arquivo após a descompressão
命令: ln -s ~ / opt / faísca-2.4.5-bing-hadoop2.7 / ~ / opt / faísca
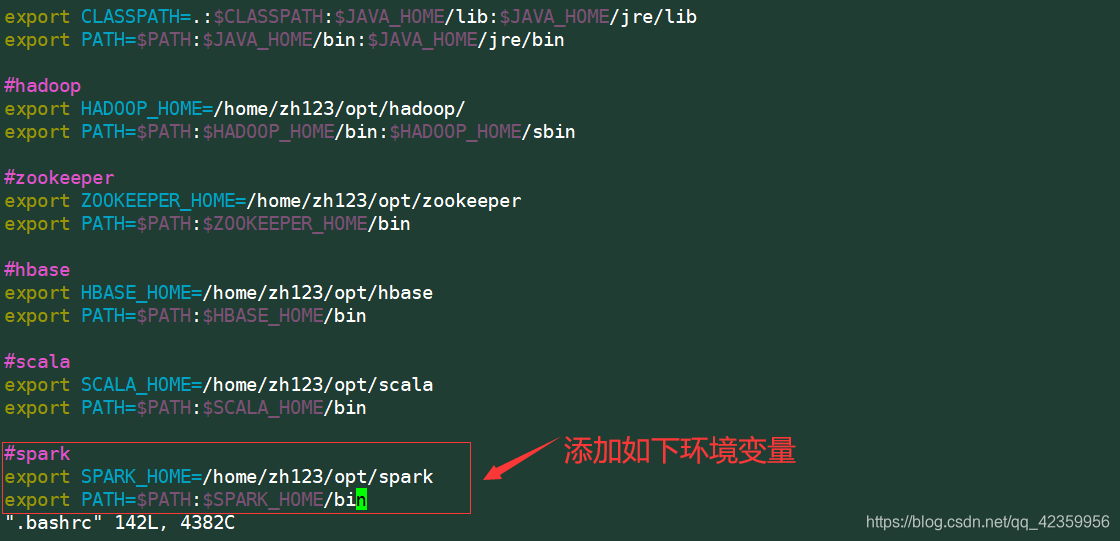
Editar .bashrc informações caminho do arquivo adicionado
Comando: vim .bashrc
conteúdo add:
Export SPARK_HOME = / Home / zh123 / opt / Spark
Export PATH = $ PATH: $ SPARK_HOME / bin
Dois, configuração do ambiente de faísca
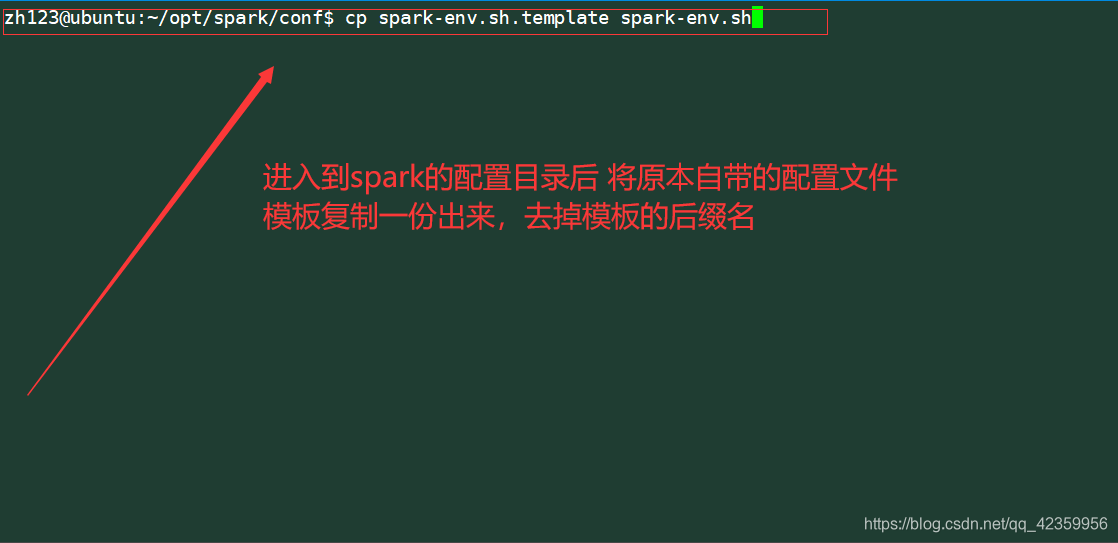
- 1, um exemplo de configuração da faísca cópia
Comando: cp faísca-env.sh.template spark-env.sh
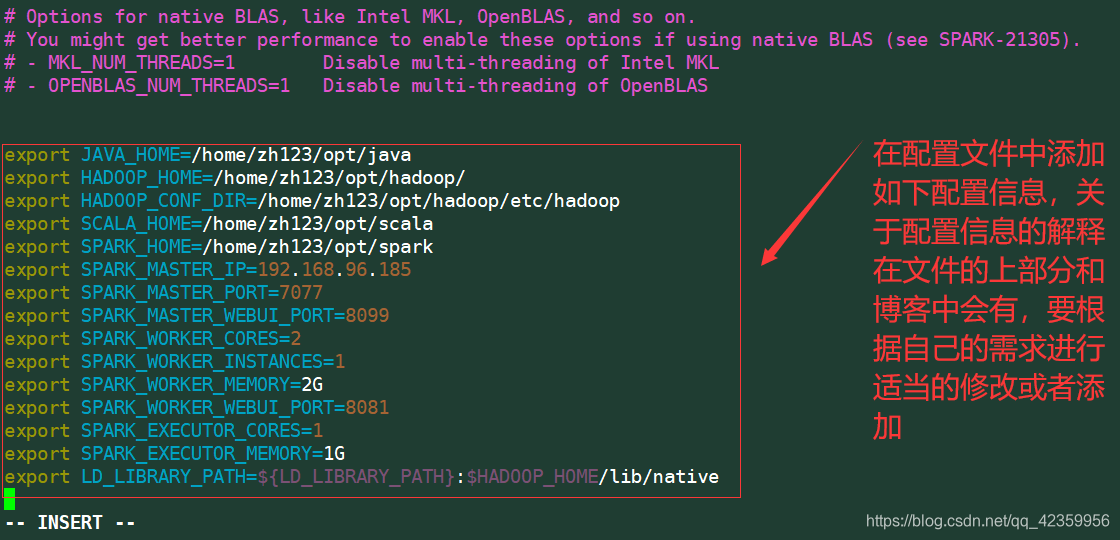
- 2, modificar o arquivo de configuração spark-env.sh
Comando: vim spark-env.sh
Adicionar conteúdo:
export JAVA_HOME = / home / zh123 / opt / java exportação
HADOOP_HOME = / home / zh123 / hadoop exportação
HADOOP_CONF_DIR = / home / zh123 / hadoop / etc / hadoop exportação
SCALA_HOME = / home / zh123 / scala exportação SPARK_HOME = / home / zh123 / faísca
exportação SPARK_MASTER_IP = 192.168.96.185 exportação SPARK_MASTER_PORT = 7077
exportação SPARK_MASTER_WEBUI_PORT = 8099 SPARK_WORKER_CORES exportação = 2 exportação
SPARK_WORKER_INSTANCES = 1 exportação exportação 2G SPARK_WORKER_MEMORY =
SPARK_EXECUTOR_CORES SPARK_WORKER_WEBUI_PORT = 8081 exportação = 1 exportação
1G exportação SPARK_EXECUTOR_MEMORY =
LD_LIBRARY_PATH = $ {LD_LIBRARY_PATH}: $ HADOOP_HOME / lib / nativa
explicação conteúdo:
| Os nomes das variáveis | explicação |
|---|---|
| JAVA_HOME | diretório de instalação do JDK |
| HADOOP_HOME | diretório de instalação do Hadoop |
| HADOOP_CONF_DIR | diretório de armazenamento do arquivo de configuração do Hadoop |
| SCALA_HOME | diretório de instalação scala |
| SPARK_HOME | diretório de instalação faísca |
| SPARK_MASTER_IP | mestre faísca nó endereço ligado |
| SPARK_MASTER_PORT | O nó mestre número da porta de ignição ligado |
| SPARK_MASTER_WEBUI_PORT | nó mestre faísca porta web |
| SPARK_WORKER_CORES | trabalhador núcleos de CPU usado |
| SPARK_WORKER_INSTANCES | Exemplos do número de simultaneamente o arranque de EXECUTOR |
| SPARK_WORKER_MEMORY | A quantidade de trabalhador memória alocada |
| SPARK_WORKER_WEBUI_PORT | número da porta da página para visualizar o trabalhador obrigado |
| SPARK_EXECUTOR_CORES | núcleos de CPU alocada para cada executor |
| SPARK_EXECUTOR_MEMORY | Cada montante executor de memória alocada |
| LD_LIBRARY_PATH | Especificar onde encontrar a biblioteca compartilhada |
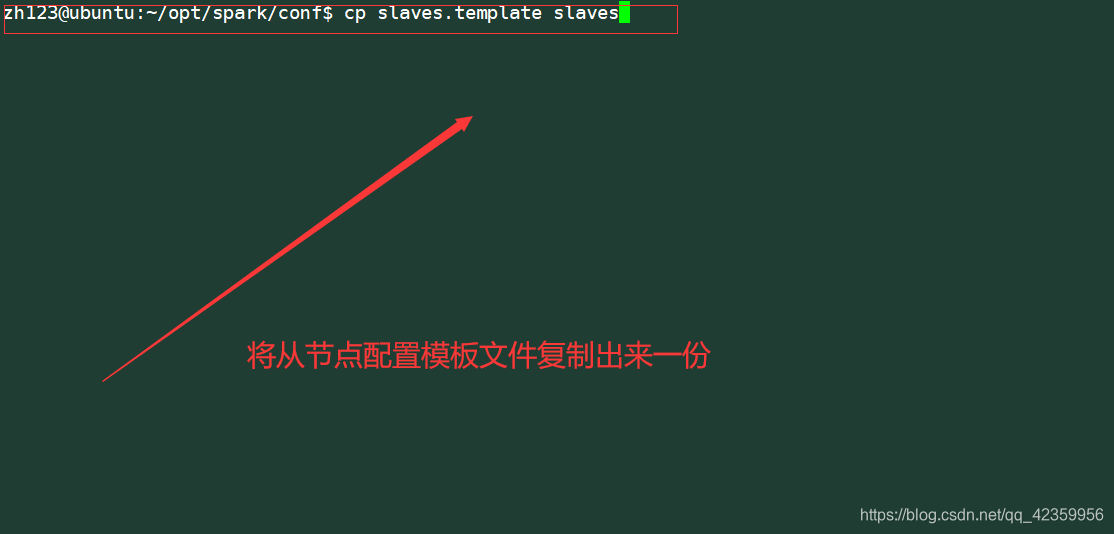
- 3, a pomada configuração de nó de
cópias do exemplo de configuração original de um documento
命令: escravos cp slaves.template
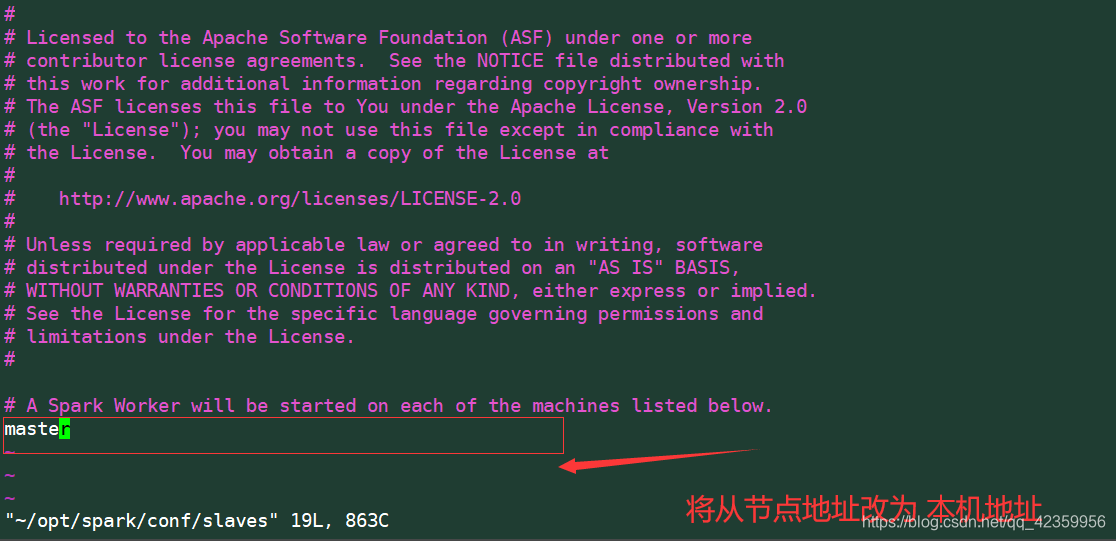
Editar escravos arquivo
modificação endereço do nó escravo
! ! ! Note que eu escrevo aqui é o mestre dele implica um endereço IP é o endereço IP da máquina (192.168.96.185)
se não tiver configurado aqui vai abordar erros de mapeamento resolução
leitores precisam de ver / configuração etc aqui quando arquivo / hosts a configuração do mapa vista
Em terceiro lugar, começar a faísca teste
- Em primeiro lugar, temos de começar a hadoop
Comando: start-all.sh
- Comece faísca
porque não há nenhuma faísca de configuração variável de ambiente / sbin diretórios você precisa cd para o próximo faísca sbin novamente ser iniciado (variável de ambiente não estiver configurado para este diretório é porque o nome do arquivo de inicialização e inicialização arquivos start-all.sh a centelha do Hadoop o mesmo nome, com o conflito, a solução pode estar em um dos dois arquivos podem ser renomeados, onde o leitor há operações relacionadas, e é um caminho direto para a plena implementação do início especificada)
para essa centelha distribuídos-pseudo da configuração de instalação é longo
