interpretação Day04- da rede neural clássico convolução
Diretório do artigo
Descrição Job
artigos reais de hoje baseia-se na categoria "máscara" rede neural clássico convolução de VGG.
reconhecimento máscaras, é aquele que pode efetivamente detectar e levar o proprietário não usar uma máscara carregando uma densa multidão na área do rosto, enquanto o juiz se deve usar uma máscara. Geralmente consiste de duas unidades funcionais, a classificação pode ser feito para detectar máscaras faciais e máscaras, respectivamente.
A prática de produção em relação ao meio ambiente máscaras problemas identificados, reduzir a dificuldade para conseguir apenas o rosto máscaras modelo julgamento, permitindo a determinação de se usar máscaras faciais . Esta prática é projetado para identificar a coluna de texto através de uma máscara, para que possamos compreender e saber como usar diagrama dinâmica para construir uma rede neural clássico convolução hélice voar.
Nota especial: Esta prática conjuntos de dados a partir da Internet, e não para fins comerciais com.
Exigências de trabalho:
- 1, de acordo com os conteúdos aprendidos na classe, e se deslocam sobre uma rede construída VGGNet. Nesta base, tente outra configuração de rede.
- 2, pensar e hands-parâmetro de ajuste, otimização, melhorar a precisão do conjunto de teste.
Courseware e conjunto de dados link está disponível para prefácio à procura de introdução antes da aprendizagem formal
Todos necessidade que são os dados contidos na pasta day04. characterData.zip é um conjunto de dados que precisamos de uso, CarID.png é usado para testar o efeito da imagem final.
Código de exemplo
Em primeiro lugar, a configuração do ambiente
# 导入需要的包
import os
import zipfile
import random
import json
import paddle
import sys
import numpy as np
from PIL import Image
from PIL import ImageEnhance
import paddle.fluid as fluid
from multiprocessing import cpu_count
import matplotlib.pyplot as plt
# 参数配置
train_parameters = {
"input_size": [3, 224, 224], #输入图片的shape
"class_dim": -1, #分类数
"src_path":"/home/aistudio/work/maskDetect.zip",#原始数据集路径
"target_path":"/home/aistudio/data/", #要解压的路径
"train_list_path": "/home/aistudio/data/train.txt", #train.txt路径
"eval_list_path": "/home/aistudio/data/eval.txt", #eval.txt路径
"readme_path": "/home/aistudio/data/readme.json", #readme.json路径
"label_dict":{}, #标签字典
"num_epochs": 1, #训练轮数
"train_batch_size": 8, #训练时每个批次的大小
"learning_strategy": { #优化函数相关的配置
"lr": 0.001 #超参数学习率
}
}
Em segundo lugar, a preparação de dados
- Descompressão do conjunto de dados original
- Dividido em proporção ao conjunto de treinamento e conjunto de validação
- Mexidos, gerando uma lista de dados
- Configurado para fornecer conjunto de dados de treinamento e um provedor de validação conjunto de dados
def unzip_data(src_path,target_path):
'''
解压原始数据集,将src_path路径下的zip包解压至data目录下
'''
if(not os.path.isdir(target_path + "maskDetect")):
z = zipfile.ZipFile(src_path, 'r')
z.extractall(path=target_path)
z.close()
def get_data_list(target_path,train_list_path,eval_list_path):
'''
生成数据列表
'''
#存放所有类别的信息
class_detail = []
#获取所有类别保存的文件夹名称
data_list_path=target_path+"maskDetect/"
class_dirs = os.listdir(data_list_path)
#总的图像数量
all_class_images = 0
#存放类别标签
class_label=0
#存放类别数目
class_dim = 0
#存储要写进eval.txt和train.txt中的内容
trainer_list=[]
eval_list=[]
#读取每个类别,['maskimages', 'nomaskimages']
for class_dir in class_dirs:
if class_dir != ".DS_Store":
class_dim += 1
#每个类别的信息
class_detail_list = {}
eval_sum = 0
trainer_sum = 0
#统计每个类别有多少张图片
class_sum = 0
#获取类别路径
path = data_list_path + class_dir
# 获取所有图片
img_paths = os.listdir(path)
for img_path in img_paths: # 遍历文件夹下的每个图片
name_path = path + '/' + img_path # 每张图片的路径
if class_sum % 10 == 0: # 每10张图片取一个做验证数据
eval_sum += 1 # test_sum为测试数据的数目
eval_list.append(name_path + "\t%d" % class_label + "\n")
else:
trainer_sum += 1
trainer_list.append(name_path + "\t%d" % class_label + "\n")#trainer_sum测试数据的数目
class_sum += 1 #每类图片的数目
all_class_images += 1 #所有类图片的数目
# 说明的json文件的class_detail数据
class_detail_list['class_name'] = class_dir #类别名称,如jiangwen
class_detail_list['class_label'] = class_label #类别标签
class_detail_list['class_eval_images'] = eval_sum #该类数据的测试集数目
class_detail_list['class_trainer_images'] = trainer_sum #该类数据的训练集数目
class_detail.append(class_detail_list)
#初始化标签列表
train_parameters['label_dict'][str(class_label)] = class_dir
class_label += 1
#初始化分类数
train_parameters['class_dim'] = class_dim
#乱序
random.shuffle(eval_list)
with open(eval_list_path, 'a') as f:
for eval_image in eval_list:
f.write(eval_image)
random.shuffle(trainer_list)
with open(train_list_path, 'a') as f2:
for train_image in trainer_list:
f2.write(train_image)
# 说明的json文件信息
readjson = {}
readjson['all_class_name'] = data_list_path #文件父目录
readjson['all_class_images'] = all_class_images
readjson['class_detail'] = class_detail
jsons = json.dumps(readjson, sort_keys=True, indent=4, separators=(',', ': '))
with open(train_parameters['readme_path'],'w') as f:
f.write(jsons)
print ('生成数据列表完成!')
def custom_reader(file_list):
'''
自定义reader
'''
def reader():
with open(file_list, 'r') as f:
lines = [line.strip() for line in f]
for line in lines:
img_path, lab = line.strip().split('\t')
img = Image.open(img_path)
if img.mode != 'RGB':
img = img.convert('RGB')
img = img.resize((224, 224), Image.BILINEAR)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1)) # HWC to CHW
img = img/255 # 像素值归一化
yield img, int(lab)
return reader
# 参数初始化
src_path=train_parameters['src_path']
target_path=train_parameters['target_path']
train_list_path=train_parameters['train_list_path']
eval_list_path=train_parameters['eval_list_path']
batch_size=train_parameters['train_batch_size']
'''
解压原始数据到指定路径
'''
unzip_data(src_path,target_path)
'''
划分训练集与验证集,乱序,生成数据列表
'''#每次生成数据列表前,首先清空train.txt和eval.txtwith open(train_list_path, 'w') as f:
f.seek(0)
f.truncate()
with open(eval_list_path, 'w') as f:
f.seek(0)
f.truncate()
#生成数据列表
get_data_list(target_path,train_list_path,eval_list_path)
'''
构造数据提供器
'''
train_reader = paddle.batch(custom_reader(train_list_path),
batch_size=batch_size,
drop_last=True)
eval_reader = paddle.batch(custom_reader(eval_list_path),
batch_size=batch_size,
drop_last=True)
Em terceiro lugar, a configuração do modelo
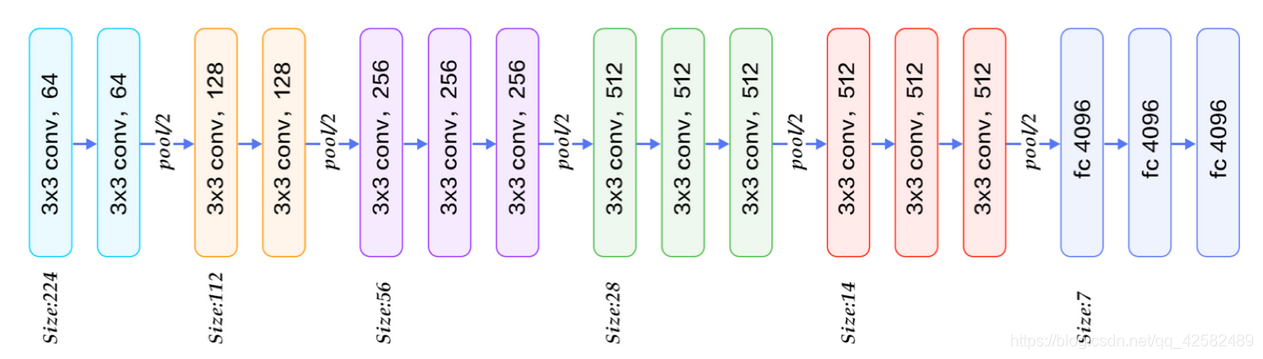
VGG núcleo de cinco operação de convolução entre cada um dos dois grupos fazer redução dimensão espaço Max-pooling. O número de vezes utilizando o mesmo grupo de sucessivas convolução 3x3, a convolução Kernel aumentar de 64-512 grupo raso, o número de grãos de convolução no mesmo grupo é o mesmo que o grupo mais profunda. Depois de duas camadas de ligação de contacto convolução completa, seguida por uma camada de classificação. Uma vez que as diferentes camadas dentro de cada convolução com estes tipos de camadas 11,13,16,19 modelo, na Fig. 16 mostra uma camada de estrutura de rede.
class ConvPool(fluid.dygraph.Layer):
'''卷积+池化'''
def __init__(self,
num_channels,
num_filters,
filter_size,
pool_size,
pool_stride,
groups,
pool_padding=1,
pool_type='max',
conv_stride=1,
conv_padding=0,
act=None):
super(ConvPool, self).__init__()
self._conv2d_list = []
for i in range(groups):
conv2d = self.add_sublayer( #返回一个由所有子层组成的列表。
'bb_%d' % i,
fluid.dygraph.Conv2D(
num_channels=num_channels, #通道数
num_filters=num_filters, #卷积核个数
filter_size=filter_size, #卷积核大小
stride=conv_stride, #步长
padding=conv_padding, #padding大小,默认为0
act=act)
)
self._conv2d_list.append(conv2d)
self._pool2d = fluid.dygraph.Pool2D(
pool_size=pool_size, #池化核大小
pool_type=pool_type, #池化类型,默认是最大池化
pool_stride=pool_stride, #池化步长
pool_padding=pool_padding #填充大小
)
def forward(self, inputs):
x = inputs
for conv in self._conv2d_list:
x = conv(x)
x = self._pool2d(x)
return x
Por favor, preencha a definição de rede VGG :
class VGGNet(fluid.dygraph.Layer):
'''
VGG网络
'''
def __init__(self):
super(VGGNet, self).__init__()
def forward(self, inputs, label=None):
"""前向计算"""
Em quarto lugar, o treinamento do modelo
all_train_iter=0
all_train_iters=[]
all_train_costs=[]
all_train_accs=[]
def draw_train_process(title,iters,costs,accs,label_cost,lable_acc):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel("cost/acc", fontsize=20)
plt.plot(iters, costs,color='red',label=label_cost)
plt.plot(iters, accs,color='green',label=lable_acc)
plt.legend()
plt.grid()
plt.show()
def draw_process(title,color,iters,data,label):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel(label, fontsize=20)
plt.plot(iters, data,color=color,label=label)
plt.legend()
plt.grid()
plt.show()
'''
模型训练
'''
# with fluid.dygraph.guard(place = fluid.CUDAPlace(0)):
with fluid.dygraph.guard():
print(train_parameters['class_dim'])
print(train_parameters['label_dict'])
vgg = VGGNet()
optimizer=fluid.optimizer.AdamOptimizer(learning_rate=train_parameters['learning_strategy']['lr'],parameter_list=vgg.parameters())
for epoch_num in range(train_parameters['num_epochs']):
for batch_id, data in enumerate(train_reader()):
dy_x_data = np.array([x[0] for x in data]).astype('float32')
y_data = np.array([x[1] for x in data]).astype('int64')
y_data = y_data[:, np.newaxis]
#将Numpy转换为DyGraph接收的输入
img = fluid.dygraph.to_variable(dy_x_data)
label = fluid.dygraph.to_variable(y_data)
out,acc = vgg(img,label)
loss = fluid.layers.cross_entropy(out, label)
avg_loss = fluid.layers.mean(loss)
#使用backward()方法可以执行反向网络
avg_loss.backward()
optimizer.minimize(avg_loss)
#将参数梯度清零以保证下一轮训练的正确性
vgg.clear_gradients()
all_train_iter=all_train_iter+train_parameters['train_batch_size']
all_train_iters.append(all_train_iter)
all_train_costs.append(loss.numpy()[0])
all_train_accs.append(acc.numpy()[0])
if batch_id % 1 == 0:
print("Loss at epoch {} step {}: {}, acc: {}".format(epoch_num, batch_id, avg_loss.numpy(), acc.numpy()))
draw_train_process("training",all_train_iters,all_train_costs,all_train_accs,"trainning cost","trainning acc")
draw_process("trainning loss","red",all_train_iters,all_train_costs,"trainning loss")
draw_process("trainning acc","green",all_train_iters,all_train_accs,"trainning acc")
#保存模型参数
fluid.save_dygraph(vgg.state_dict(), "vgg")
print("Final loss: {}".format(avg_loss.numpy()))
Quinto, validação do modelo
'''
模型校验
'''
with fluid.dygraph.guard():
model, _ = fluid.load_dygraph("vgg")
vgg = VGGNet()
vgg.load_dict(model)
vgg.eval()
accs = []
for batch_id, data in enumerate(eval_reader()):
dy_x_data = np.array([x[0] for x in data]).astype('float32')
y_data = np.array([x[1] for x in data]).astype('int')
y_data = y_data[:, np.newaxis]
img = fluid.dygraph.to_variable(dy_x_data)
label = fluid.dygraph.to_variable(y_data)
out, acc = vgg(img, label)
lab = np.argsort(out.numpy())
accs.append(acc.numpy()[0])
print(np.mean(accs))
Sexto, previsões do modelo
def load_image(img_path):
'''
预测图片预处理
'''
img = Image.open(img_path)
if img.mode != 'RGB':
img = img.convert('RGB')
img = img.resize((224, 224), Image.BILINEAR)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1)) # HWC to CHW
img = img/255 # 像素值归一化
return img
label_dic = train_parameters['label_dict']
'''
模型预测
'''with fluid.dygraph.guard():
model, _ = fluid.dygraph.load_dygraph("vgg")
vgg = VGGNet()
vgg.load_dict(model)
vgg.eval()
#展示预测图片
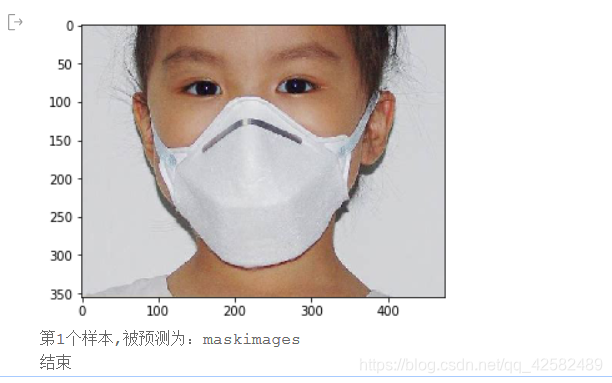
infer_path='/home/aistudio/data/data23615/infer_mask01.jpg'
img = Image.open(infer_path)
plt.imshow(img) #根据数组绘制图像
plt.show() #显示图像
#对预测图片进行预处理
infer_imgs = []
infer_imgs.append(load_image(infer_path))
infer_imgs = np.array(infer_imgs)
for i in range(len(infer_imgs)):
data = infer_imgs[i]
dy_x_data = np.array(data).astype('float32')
dy_x_data=dy_x_data[np.newaxis,:, : ,:]
img = fluid.dygraph.to_variable(dy_x_data)
out = vgg(img)
lab = np.argmax(out.numpy()) #argmax():返回最大数的索引
print("第{}个样本,被预测为:{}".format(i+1,label_dic[str(lab)]))
print("结束")
Terminar o trabalho
VGG rede definida:
Há poucos dias, eo código é semelhante, mas hoje muitos do código de exemplo ao longo dos parâmetros do modelo foram unificados pacote, e acrescentou uma classe ConvPool, os compostos de convolução e piscina juntos, que seria mais conveniente, nós também é que o uso.
class VGGNet(fluid.dygraph.Layer):
'''
VGG网络
'''
def __init__(self):
super(VGGNet, self).__init__()
# 通道数、卷积核个数、卷积核大小、池化核大小、池化步长、连续卷积个数
self.convpool01 = ConvPool(3, 64, 3, 2, 2, 2, act='relu')
self.convpool02 = ConvPool(64, 128, 3, 2, 2, 2, act='relu')
self.convpool03 = ConvPool(128, 256, 3, 2, 2, 3, act='relu')
self.convpool04 = ConvPool(256, 512, 3, 2, 2, 3, act='relu')
self.convpool05 = ConvPool(512, 512, 3, 2, 2, 3, act='relu')
self.pool_5_shape = 512*7*7
self.fc01 = fluid.dygraph.Linear(self.pool_5_shape, 4096, act='relu')
self.fc02 = fluid.dygraph.Linear(4096, 4096, act='relu')
self.fc03 = fluid.dygraph.Linear(4096, 2, act='softmax')
def forward(self, inputs, label=None):
"""前向计算"""
out = self.convpool01(inputs)
out = self.convpool02(out)
out = self.convpool03(out)
out = self.convpool04(out)
out = self.convpool05(out)
out = fluid.layers.reshape(out, shape=[-1, 512*7*7])
out = self.fc01(out)
out = self.fc02(out)
out = self.fc03(out)
if label is not None:
acc = fluid.layers.accuracy(input=out, label=label)
return out, acc
else:
return out
Número de rodinhas de nossa tomada inicial é 10, você pode ver a precisão do modelo do trem é os altos e baixos.
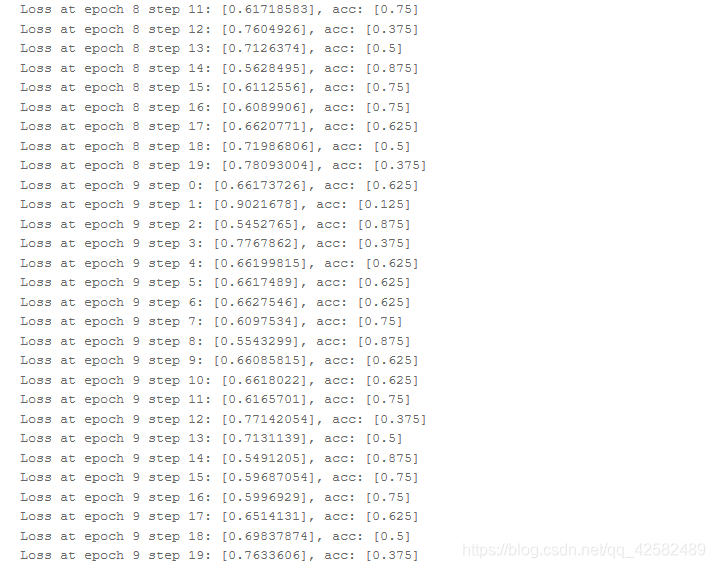
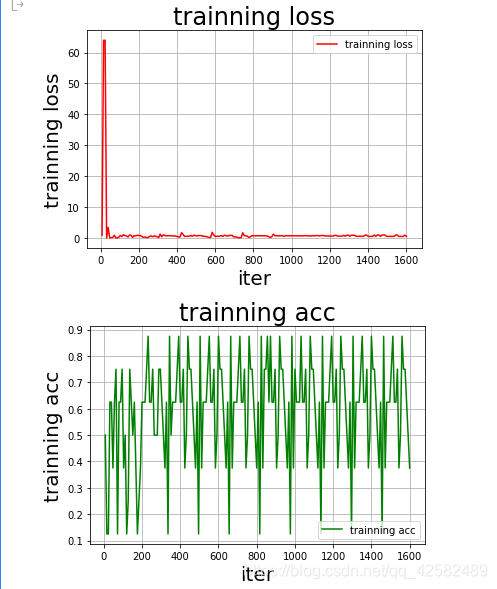
Tirada fora do quadro, também, a precisão do modelo foi treinado em estado de choque.
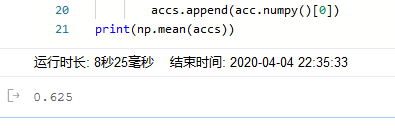
A precisão do conjunto de teste em cerca de 0,6.
reconhecimento de máscaras é uma classificação binária, os resultados só usam máscaras e não usando máscaras dois tipos. Prevemos máscaras Shihai imaginar mal capaz de prever o sucesso.
taxa de precisão é de apenas cerca de 0,6 acho que certamente ainda tem que ir parâmetros otimizados foram transferidos a partir dos três aspectos seguintes.
- Várias rodadas de formação, isto é, o número de iterações (num_epochs)
- taxa de aprendizagem (learningrate)
- Cada tamanho de lote de formação (batch_size)
Aumentamos o número de ciclos de formação, o aumento de 20 vezes, reduzir a taxa de aprendizagem, caiu para 0,0001, aumentando o tamanho de cada lote de formação, aumentada para 16. Estes parâmetros podem ser modificados de configuração do ambiente do primeiro passo.
Enfatizar aqui que um ligeiro aumento no tamanho do lote pode ser treinado para melhorar a precisão, mas batch_size não apenas o tamanho da transferência, normalmente um múltiplo de 8, a mais alta eficiência de tal operação paralela dentro da GPU .
Após o treinamento você pode ver, a precisão do conjunto de treinamento convergem gradualmente para 1,0.
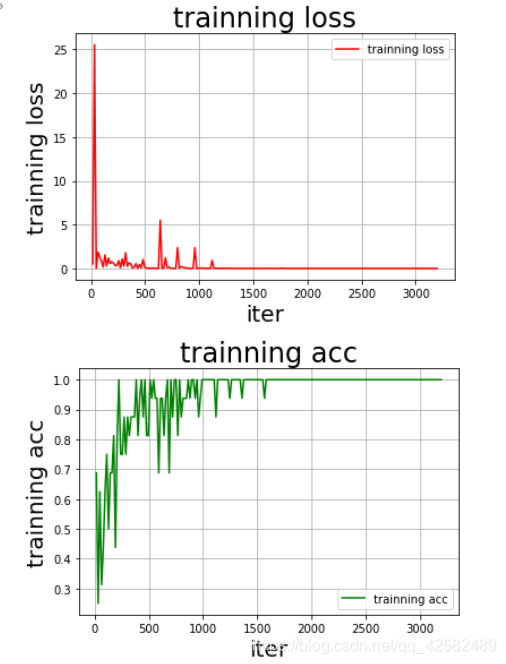
A precisão do conjunto de teste também alcançou 1,0, muito agradável.

Porque os dados é relativamente pequeno estudo, a capacidade de generalização não é forte, o grupo de realimentação bigwigs que pode ser adequadamente utilizado realce de dados (dados de aumento) métodos para melhorar a previsão de uma taxa de sucesso cena real.
