Em primeiro lugar, instalar o pré-requisito
antecedência Cluster instalado Hadoop, colmeia.
SCP pacotes de instalação colmeia precisa ser instalado em todos os nós impala, porque a necessidade de impala referência dependências colmeia.
Hadoop necessidades estruturais para interface de acesso a apoio ao programa C, ver a figura a seguir, há assim arquivo se o caminho para provar que suporte a interface C.

Em segundo lugar, fazer o download do pacote de instalação, dependências
Desde o impala não fornece pacote tar está instalado, apenas o pacote rpm. Assim, quando o impala montagem, pacotes rpm precisa ser instalado. pacote rpm apenas empresa oferece Cloudera, então vá site da empresa Cloudera para baixar o pacote rpm.
Mas uma outra questão, impala outro pacote pacote rpm rpm muito dependente, pode-se descobrir dependerá, mas também todo o pacote rpm pode ser baixado, feita em nossa fonte yum local para instalar. Aqui podemos escolher para criar fonte yum local para instalar.
Então, primeiro de tudo você precisa baixar o pacote rpm, baixe o seguinte endereço
http://archive.cloudera.com/cdh5/repo-as-tarball/5.14.0/cdh5.14.0-centos6.tar.gz
## Por causa de pacote de download cdh5.14.0-centos6.tar.gz é muito grande, cerca de 5 G, após a descompressão também requer um mínimo de espaço para cinco G da. E o nosso disco de máquina virtual é limitada, pode não ser suficiente, é possível montar um novo disco para a máquina virtual dedicada ao pacote cdh5.14.0-centos6.tar.gz armazenamento.
Em terceiro lugar, configurar o yum locais fonte
1. Descompacte o pacote Carregar
tar -zxvf cdh5.14.0-centos6.tar.gz
rz só pode carregar dados dentro de um máximo de 4G, é necessário colocá-lo de forma diferente carregar por exemplo sslclient.
2, para configurar o yum local de informação da fonte
Instalar o servidor Apache Servidor
yum -y install httpd
service httpd start
chkconfig httpd on
3, configurar o arquivo de origem yum locais
cd /etc/yum.repos.d
vim cdh.repo

Criar um link para ler o apache httpd
ln -s /export/servers/cdh/5.14.0 / var / www / html / CDH
Verifique se o linux SELinux fechada
临时关闭:
[root@localhost ~]# getenforce
Enforcing
[root@localhost ~]# setenforce 0
[root@localhost ~]# getenforce
Permissive
永久关闭:
[root@localhost ~]# vim /etc/sysconfig/selinux
SELINUX=enforcing 改为 SELINUX=disabled
重启服务rebootacesso do browser através de uma fonte yum local, se houver sucesso a seguinte página.
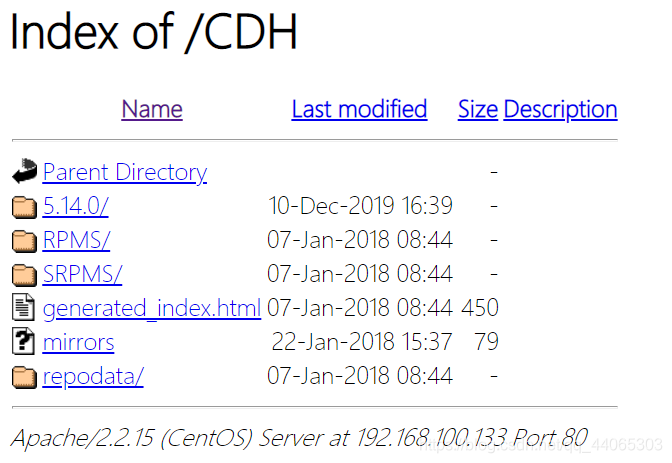
O perfil de origem yum locais localimp.repo distribuído a todos nós na necessidade de instalar impala.
cd /etc/yum.repos.d/
SCP cdh.repo nó 0 2: $ PWD
SCP cdh.repo node0 3: $ PWD
Em quarto lugar, instalar Impala
1, o plano de conjunto
| Name service |
a partir do nó |
a partir do nó |
O nó mestre |
| impala-catálogo |
|
|
Nó-3 |
| impala-state-store |
|
|
Nó-3 |
| impala-servidor (impalad) |
Nó-1 |
Nó-2 |
Nó-3 |
No planejamento do nó mestre nó-3 instalado execute os seguintes comandos:
yum install -y impala impala-server impala-state-store impala-catalog impala-shellNo planejamento das node-1 nodos , Node-2 instale a seguinte ordem:
yum install -y impala-serverEm quinto lugar, modificar Hadoop, configuração Hive
3 máquinas precisam de operar em todo o agrupamento , precisa de ser modificada. hadoop, se o serviço normal colmeia e configurado, é decidido se impala lançamento bem sucedido ea utilização da premissa
1, a configuração de modificação colmeia
vim /export/servers/hive/conf/hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node01:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!-- 绑定运行hiveServer2的主机host,默认localhost -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node01</value>
</property>
<!-- 指定hive metastore服务请求的uri地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://node01:9083</value>
<!-- 启动impala使用hive的时候要在这里指定的节点开启hive服务 -->
</property>
<property>
<name>hive.metastore.client.socket.timeout</name>
<value>3600</value>
</property>
</configuration>Cp configurar a colmeia para as outras duas máquinas.
cd $ HIVE_HOME / conf
node02 scp hive-site.xml: $ PWD
node03 scp hive-site.xml: $ PWD
2, hadoop Modificar configuração
Todos os nós criar a seguinte pasta
mkdir -p / var / run / HDFS-sockets
Modificar hdfs-site.xml todos os nós adicionar a seguinte configuração alterações entrem em vigor, reinicie o cluster depois de completar hdfs
vim etc / hadoop / hdfs-site.xml
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<property>
<name>dfs.domain.socket.path</name>
<value>/var/run/hdfs-sockets/dn</value>
</property>
<property>
<name>dfs.client.file-block-storage-locations.timeout.millis</name>
<value>10000</value>
</property>
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
</property>dfs.domain.socket.path é um caminho de comunicação entre DFSClient local e DataNode em Socket. dados de controle de leitura aberta locais dfs.client.read.shortcircuit DFSClient,
O arquivo de configuração de atualização Hadoop, scp para outras máquinas.
cd $ HADOOP_HOME / etc / hadoop
node02 scp -r hdfs-site.xml: $ PWD
node03 scp -r hdfs-site.xml: $ PWD
Nota: o usuário root não precisam operar abaixo, os usuários comuns precisam este passo.
permissão dar a esta pasta, se estiver usando um hadoop usuário normal, dá diretamente privilégios de usuário comuns, tais como:
chown -R Hadoop: hadoop / var / run / HDFS-sockets /
3, restart Hadoop, Hive
Execute o seguinte comando em node01 foram iniciados serviços metastore colmeia e Hadoop.
cd / $ HIVE
nohup bin / colmeia --service metastore &
nohup bin / colmeia - serviço hiveserver2 &
cd / $ HADOOP_HOME
sbin / stop-dfs.sh | sbin / start-dfs.sh
4. Copie o Hadoop, perfil Hive
directório configuração impala / etc / impala / conf, esta necessidade caminho para o núcleo-site.xml, hdfs-site.xml e colmeia-site.xml abaixo.
Todos os nós execute o seguinte comando
cp -r /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/core-site.xml /etc/impala/conf/core-site.xml
cp -r /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/hdfs-site.xml /etc/impala/conf/hdfs-site.xml
cp -r /export/servers/hive-1.1.0-cdh5.14.0/conf/hive-site.xml /etc/impala/conf/hive-site.xml
Em sexto lugar, modificar a configuração do impala
1, modificar o impala configuração padrão
Todos os nós mudar o impala perfil padrão
vim / etc / default / impala
IMPALA_CATALOG_SERVICE_HOST = nó 0 3
IMPALA_STATE_STORE_HOST = nó 03
scp / etc / default / impala node02: $ PWD
scp / etc / default / impala node03: $ PWD
2, motorista add mysql
Ao configurar o / etc / default / impala pode ser encontrado no local foi nome especificado mysql conduzido.
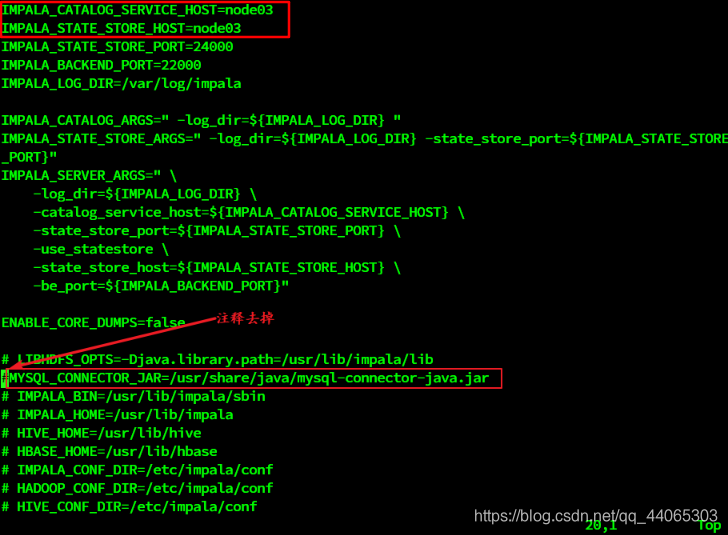
Use um soft link para a rota para (3 máquinas precisam ser executadas)
Ln -s /export/servers/hive/lib/mysql-connector-java-5.1.32.jar /usr/share/java/mysql-connector-java.jar
3, modificar a configuração bigtop
Java_home bigtop caminho modificado (3 máquinas)
vim / etc / default / bigtop-utils
export JAVA_HOME = / export / servidores / jdk1.8.0_65
Sete, arranque, serviço de desligamento impala
O nó-3 nó mestre iniciar o seguinte processo de três serviço
serviço de início impala-state-store
serviço impala-catálogo início
início impala-servidor do serviço
Iniciar node-1 e node-2 promotora impala-servidor a partir do nó
início impala-servidor do serviço
existe processo Ver impala
ps -ef | impala aderência

Depois de começar tudo sobre impala do padrão log em / var / log / impala
Se você precisa desligar o comando impala serviço para iniciar a paragem pode ser. Note-se que após o processo de desligamento se ainda residem, você pode ter a seguinte maneira de remover. Em circunstâncias normais, com o desaparecimento de perto.
solução:

impala Web UI
gerenciamento de acesso Impalad interface de http: // nó-3: 25000 /
gerenciamento de acesso Statestored interface de http: // nó-3: 25010 /
