Uma tabela de dados do algoritmo de segmentação vertical ou horizontal física ou alguma da ferramenta é alcançado por HASH
cena aplicável
1, o número de registros da tabela simples ou chegar a um milhão milhões de nível
2, de resolução de problemas da tabela de bloqueio
de sub-tabela maneira
O nível de sub-tabela: uma grande mesa, após a separação pode reduzir o número de páginas na consulta necessidades para ler os dados e os índices, ao mesmo tempo, reduzindo o número de camadas do índice, aumentar o número de consultas

cena aplicável
1, os dados da tabela em si independência, tais como registos de dados da tabela em várias regiões ou tabela de dados entalhadas em diferentes períodos, em particular, alguns dos dados utilizada, alguns não utilizada.
2, os dados necessitam de ser armazenado na pluralidade de meios de comunicação.
Exemplos: login qq, particularmente uma vez que o número qq, agora por módulo algoritmo para optimizar SQL, sub-tabela 99, por módulo 100, a parte restante dos dados é determinado tabela !!!
horizontal cisalhamento desvantagens mínimo
1, para aumentar a complexidade da aplicação, requerem vários nomes de tabela durante consulta normal, todos os dados necessários para operar UNIÃO
2, em muitas aplicações de base de dados, esta complexidade superam as vantagens que ela traz, irá aumentar o número de disco lê uma camada de índice de consulta
Tabela Vertical
E um número de colunas da chave primária em uma tabela, e a chave primária e colunas adicionais em diferentes tabelas de
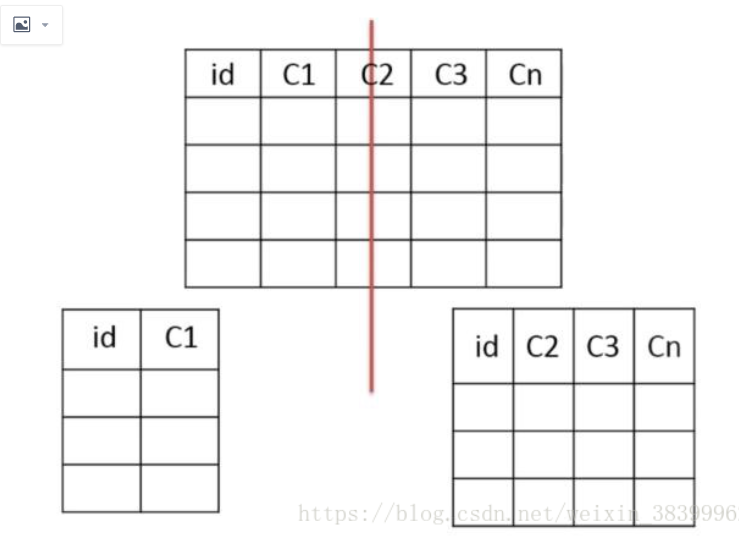
cena aplicável
1, se uma determinada coluna da tabela utilizada, algumas outras colunas não são usadas
2, a linha de dados pode ser feita pequena, uma página de dados podem armazenar mais dados, reduzindo a frequência de I / O e a consulta
Exemplo: A figura é dividida verticalmente, com uma transcrição, há a identificação do aluno, nome do aluno, as perguntas dos alunos, a resposta alunos, mas você vai encontrar instrução SQL é
Selecione * de tt, onde id = "8", desta vez a lista de recall, haverá tópicos e respostas, esta tabela é relativamente grande, desta vez para o assunto, e as respostas quebrar, deixando uma tabela de informações sobre ele, a consulta informações em tempo consultar diretamente a mesa, em vez de consulta tópicos e respostas, mas projectos empresariais de grande escala vai colocar algumas grandes arquivos são armazenados em uma imagem especial ou um servidor de arquivos, de modo que aqueles de nós que não precisa considerar o
deficiência
mesa pontos deficiência
Alguns pontos do algoritmo de lógica mesa política com base na camada de aplicação, uma vez que os algoritmos de lógica, e toda a lógica sub-tabela vai mudar, má escalabilidade
Para a camada de aplicação, algoritmos de lógica, aumentando o custo de desenvolvimento
MySQL replicação e equilíbrio de carga princípio
obras de replicação master-slave MySQL
No repositório de dados primários gravação maior log binário
Cópia da biblioteca principais registros da biblioteca para o seu relay log
Leia evento log relé da biblioteca, da biblioteca para os dados de peso
MySQL problema replicação mestre-escravo
A distribuição dos dados: livre para iniciar ou replicação de parada, e os dados geograficamente distribuídas de backup
de balanceamento de carga: único servidor reduz a pressão de
alta disponibilidade e failover: aplicativo ajuda único ponto evitar de falha
teste de upgrade: Você pode usar uma versão posterior do MySQL a partir de armazém
Resolução de problemas abordagem
compreender completamente a tabela de pontos das principais partição e aplicação cenários, na entrevista, tais questões são geralmente mais flexível, as empresas vão encontrar problemas de algum do cenário existente, podemos particionar pontos mesa, replicação do MySQL, cenários de aplicação balanceamento de carga para responder sob as circunstâncias
exames
Defina o número de usuários do site em dez milhões, mas apenas 1% do número de usuários ativos, como os usuários ativos para otimizar o acesso de banco de dados aumentar a velocidade?
R:
pode ser utilizado, os utilizadores activos em uma sub-área, não há utilizadores activos em si uma outra subzona é menos activa do que a área de dados do utilizador, é possível melhorar a velocidade de acesso dos utilizadores activos.
Além disso, o nível de sub-mesa, os pontos de usuários ativos em uma mesa, os usuários não ativos divididos em outra tabela, você pode melhorar usuários ativos velocidade de acesso.