otimização de banco de dados de alto desempenho
Primeiro, Análise de Desempenho
1, processo DQL consulta:
- O cliente envia uma consulta para o servidor;
- Depois que o servidor verificando as permissões, primeiro verifica o cache de consultas, se o cache bateu, em seguida, retornar imediatamente os resultados armazenados no cache. Caso contrário, prosseguir para a fase seguinte;
- do lado do servidor de análise SQL, o pré-tratamento, e, em seguida, calculada pelo optimizador de acordo com a informação estatística relaciona-se com as tabelas de dados SQL, gerando o plano de execução correspondente;
- De acordo com MySQL otimizador de consulta gera o plano de execução, as chamadas de API mecanismo de armazenamento para executar a consulta;
- Os resultados são retornados para o cliente.
query Optimizer
1, escrever qualquer SQL, no final é como a execução real, de acordo com o que consulta critérios, a ordem da última execução, mais do que provavelmente haverá a execução do programa.
2, o otimizador de consulta estatísticas básicas (tais como índices, o número de dados) da tabela de dados, antes da implementação real de um sql, com base em seus próprios dados interno, investigação abrangente.
3. As estatísticas próprias mysql de uma variedade de implementação do programa entre a selecioná-lo considerado uma execução adequada do programa, venha e executar.
O que fazer otimização
- Do otimização, é permitir que o otimizador de consulta de acordo com as nossas ideias, ajuda-nos a escolher a melhor implementação do programa
- Vamos escolhe otimizador de desempenho em linha com a declaração de programadores plano para reduzir consulta IO gerado no processo
mysql problema comum
- saturação de CPU
- Disk I / O ler dados grandes
- Servidor baixo configuração de hardware

2, Explicar
Consulta plano de execução:
Use explicar palavra-chave, ele pode simular um otimizador de instrução SQL executada, para que saibam como lidar com instrução MySQL sql pode analisar gargalos de desempenho de consulta ou estrutura de tabela por Explicar.
papel:
- Verifique a ordem de leitura da tabela
- Leitura de dados tipo de operação de operação
- Veja qual índice você pode usar
- Veja qual índice é realmente usado
- Confira as referências entre tabelas
- Verifique quantas linhas por tabela é executada otimizador
uso
explain sql
##############################################################
explain select * from stuinfo join score using(sid)\G
Eu iria
- Não selecionar consulta
- Se o ID do mesmo na vertical, de cima para baixo a fim de execução
- Se o ID de diferentes tamanhos, geralmente um sub-consulta, maior será o valor de prioridade id será executado
explain select * from stuinfo where age in (select max(age) from stuinfo);
- id ambos têm o mesmo diferente
explain select * from stuinfo join score using(sid) where age in (select max(age) from stuinfo);
explain select * from stuinfo where sid in (select sid from score where sid in (select max(ch) from score));
- Resumo: ir na mesma ordem, o diferente grande ir primeiro.
selecione o tipo
- simples: basta selecionar a consulta, a consulta não contém subconsultas ou da União
- primária: Se a consulta contém quaisquer sub-queries complexas, a consulta externa foram marcadas primário
- subconsulta: contém sub-consultas na seleção ou onde em
- união se a segunda escolha aparecer após a união, foram rotulados: união
explain select * from stuinfo union select * from stuinfo;
- derivada: Se a união incluída na cláusula de subconsulta, a camada exterior irá ser marcado como seleccione derivador
explain select * from ((select * from stuinfo where sid =1 ) union (select * from stuinfo where sid=2)) as a;
- resultado da união: união resultado a obtenção de escolha a partir da tabela, os resultados combinados de dois conjuntos de união final
tipo
- ALL: A varredura completa da tabela, ler os dados do disco rígido que, All reduzir a quantidade de dados se há uma muito grande, tem que fazer otimização
explain select * from stuinfo;
- ÍNDICE:
- Todos índice e índice de diferença é o tipo de percorrer a árvore de índice somente, geralmente mais rápido do que a todos, porque o arquivo de índice é geralmente menor do que o arquivo de dados
- todos são lidos e todo o índice da tabela, mas o índice é lido a partir do índice, os quais são lidos a partir do disco
explain select sid from stuinfo;
- sistema: há uma linha na tabela (sistema de tabela) const Este é um caso especial do tipo normalmente não ocorre
- const: representada pelo índice de uma vez encontrado, o índice de const primária ou única para comparar diretamente consulta a chave primária ou índice exclusivo, porque apenas uma linha de correspondência de dados, tão rápido.
explain select * from stuinfo where sid=1;
- intervalo: A seleção das estatísticas da tabela de índice e caso, uma estimativa aproximada do número de linhas necessárias para encontrar a leitura registro desejado
explain select * from stuinfo where sid>2;
- Eq_ref um tipo de índice, foi usado
Resumo: Enquanto ALL (tabela completa verifica o disco rígido) não aparecer, então a velocidade de consulta da instrução SQL atual deve ser relativamente rápido
possible_keys
Pode-se ter criado quatro índices, quando executado, pode determinar automaticamente de acordo com o uso interno somente três
Ele pode ser usado para determinar o índice
chave
A utilização efectiva do índice
- Índice realmente utilizados, se NULL, então não use o índice
- Se a consulta usa o índice de cobertura, o índice só aparece na lista de chaves
- possible_keys com que a teoria relação de dice de chave deve ser utilizados para usos práticos que indexa
- Campos cobertos consultas índice de campo e construir um acordo justo, que chamamos de um índice de cobertura
key_len
- Indica o número de bytes usados no índice, o índice pode ser utilizado no comprimento de consulta é calculado pela coluna.
- Não necessariamente muito precisas
ref
Se o índice é introduzido para, no final, que várias referências ao Índice
explain select * from stuinfo a,score b where a.sid=b.sid and a.age=22;
linha 和 filtrada
linha é digitalizado, o melhor
filtrada é índice de linha aplicada é a proporção de 100% é utilizado no seu conjunto, é o melhor
#优化的比较好
explain select * from stuinfo a,score b where a.sid=b.sid and a.age=22;
#不好
explain select * from stuinfo a,score b where a.sid=b.sid and a.age=22;
Extra
Gerar valores:
- Usando filesort: Descrição mysql irá utilizar um índice de classificação de dados externo
explain select * from stuinfo a,score b order by age;
- Usando temporária: o uso de uma tabela temporária para armazenar resultados intermediários, Mysql ao classificar os resultados da consulta, use uma tabela temporária, comum na ordenação e agrupamento grupo consultas por orderby
- usando o índice: um campo de consulta chave
explain select sname from stuinfo ;
- usando onde: onde uma consulta é determinada (no caso não é satisfeita)
explain select * from stuinfo where sname;
Em segundo lugar, o índice
Qual é o índice: Mysql ajudar a obter de forma eficiente a estrutura de dados dos dados, semelhante ao catálogo Xinhua Dictionary Index, pode ser encontrado rapidamente através da palavra que você quer para o diretório índice, encontrar rapidamente a seqüência boa linha de dados.
1. Por que a indexação:
- Depois de melhorar a consulta de desempenho, um por um, antes de olhar para trás não classificadas, classificar através do índice pode ser definida diretamente para o local desejado
- Classificadas encontrar rapidamente estrutura de dados -> índice é
2. Vantagens e Desvantagens
vantagens:
- Classificando os itens de dados de índice, os dados de triagem reduzir custos, reduzir o consumo de CPU
- Semelhante bibliográfica biblioteca índice de indexação universidade, melhorar os dados de eficiência de recuperação, reduzir o custo do banco de dados IO
desvantagens:
- Em geral, o índice em si também é grande, o índice frequentemente armazenados no disco como arquivos
- Embora o índice para melhorar a consulta velocidade, mas irá reduzir a velocidade de atualização da tabela
- Será ajustado porque as principais mudanças trazidas pela informações de atualização de índice

3. Por que os dados do índice de busca vai ser ainda mais rápido
Quando armazenar dados, se o sistema de banco de dados indexado mantém uma estrutura de dados para algoritmo de busca encontram específico, essas estruturas de dados dados referenciados, de alguma forma, estar no topo destas estruturas de dados, implementar avançado algoritmo de busca, esta estrutura é índice
Em geral, o índice em si também é grande, não podem ser armazenados na memória, de modo que o índice é muitas vezes na forma de arquivos de índice são armazenadas no disco
Para acelerar os dados de pesquisa, pode manter uma árvore de busca binária, cada nó inclui uma chave de índice, respectivamente, e um ponteiro para o endereço físico correspondente aos dados registados, de modo que você pode usar uma pesquisa binária para obter os dados correspondentes para uma certa complexidade gravar para recuperar rapidamente a qualificação
Além disso, há BTtree índice árvore binária, o referido índice I geralmente, se não especificado, referem-se à estrutura de dice de árvore B do tecido, em que o índice de foco, índice secundário, um índice composto, índice de prefixo, o padrão é a única B + índice de árvore .
Além B + índice de árvore, e um índice de hash (índice de Hash) e semelhantes.
4. árvore de busca binária
Use uma pesquisa binária para procurar rapidamente
5.B-Tree (saldo múltipla árvore de busca)
m ordem satisfaz B-tree as seguintes propriedades:
- (1) cada nó tem a maior sub m
- (2) o sub raiz menos dois
- (3) nó ramo mínima tem m / 2 sub
- (4) todos os nós de folha na mesma camada, cada nodo tem no máximo m-1 th chave, e dispostas em ordem ascendente

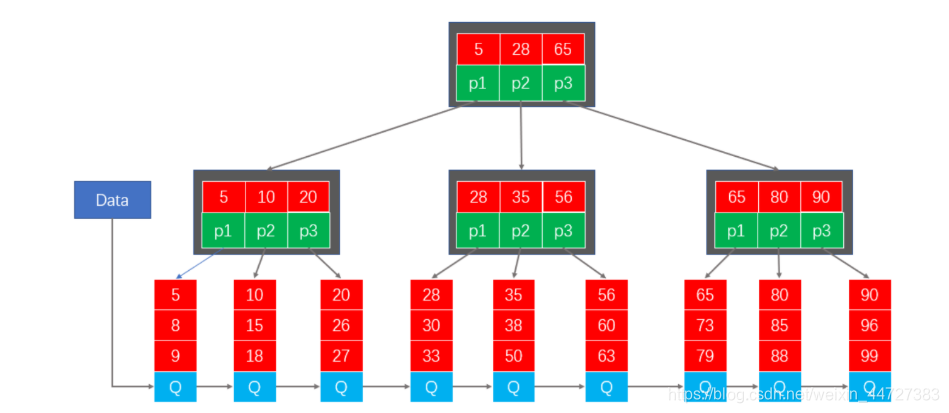
6.B + Tree
B + Tree em relação ao B-Tree têm pontos diferentes:
- 1. O nó estabelecimentos não folha única de informação chave.
- 2 tem uma cadeia de apontadores entre todos os nós de folha.
- 3. Os registros de dados são armazenados nos nós folha
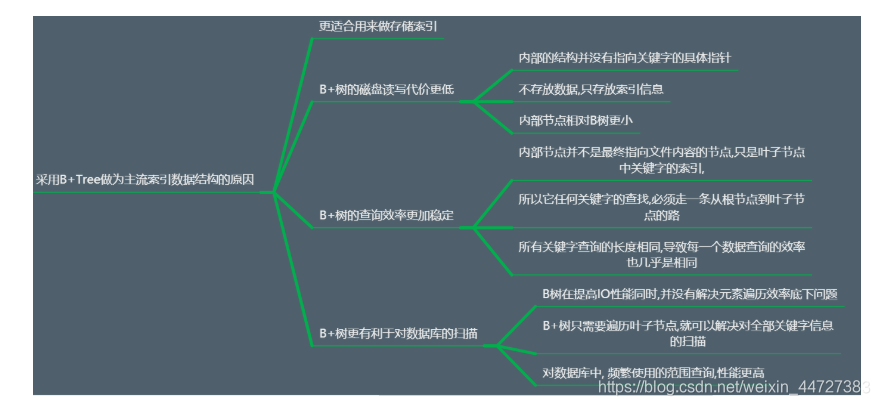
Por que, quando B + índice de árvore como padrão
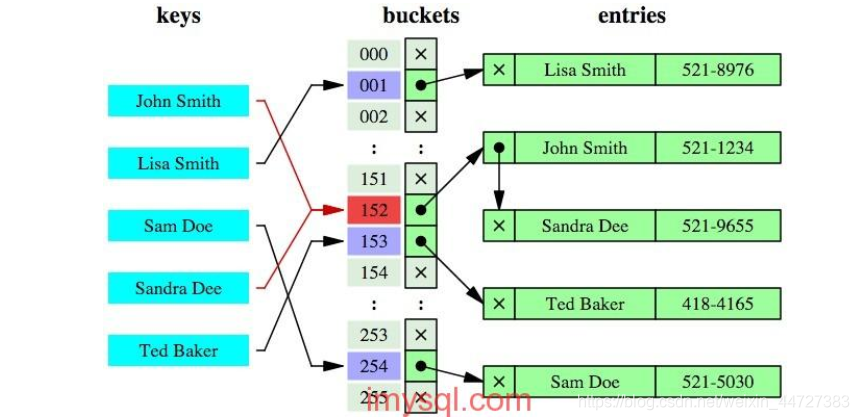
Índice 7.hash
índice hash especial, a complexidade de tempo é O (1), mas apenas para a forma de realização comparativa equivalência consulta, o âmbito de aplicação não é adequado para comparação do tamanho ou consulta
8. Criar um índice princípio
- Adequado para coluna de pesquisa frequente
- Colunas adequadas são muitas vezes usadas para determinar as condições
- Adequado muitas vezes devido à coluna de tipo
- Não é adequado para colunas de dados pequenos
- Não é adequado para pequena coluna de consultas
Em terceiro lugar, backup e recuperação de dados
-
backup
mysqldump -h localhost -u root -p123456 dbname > dbname.sql -
recuperação
mysql -h localhost -u root -p123456 dbname < ./dbname.sql
Em quarto lugar, as perguntas índice de face
De acordo com a regra do prefixo esquerda para corresponder
- índice combinado pode ser usado por uma única tecla
- Três índices principais para formar uma coalizão, se houver dois de uso, não usar o índice para o lado esquerdo ou o índice mais à esquerda posição no ranking é incorreta falhar
- Encontrar o intervalo do índice vai levar ao fracasso
- uso índice geral ou operação pode falhar

