공공 수가 원래 기사 : 원숭이 저우 Xiansen 프로그램입니다. 이 플랫폼은 나의 기사처럼, 나는 마이크로 채널 대중 번호로 주목을 환영합니다, 정기적으로 업데이트되지 않습니다.

언급 한 기사는, 레디 스 다섯 개 데이터 유형이 가장 자주 사용되는이 있습니다 : 문자열,리스트, 해시, 설정 , SortSet. 이 기사는 단순히 각각 분석 명령 지침과 일반적인 시나리오에 5 개 개의 데이터 타입의 사용이 문서는 기본 공통 작업에 대한 5 개의 데이터 타입의 종류와 각각의 데이터 구조를 이야기합니다 설명합니다. 레디 스이 키 - 값 - 메모리 데이터베이스의 가장 인기있는 유형으로, 데이터베이스 작업뿐만 아니라 메모리에 정기적으로 디스크에 영구 데이터 일 수있다, 많은 고성능 데이터베이스에 상대적으로 일반적이고, 레디 스에서, 각각의 실제 값 redisObject 의해 나타내어지는 구조에 기초 :
타입 정의 구조체 {redisObject
부호 형 :. 4]
부호 부호화 :. 4]
보이드 * PTR;
INT refcount가,
부호 LRU :
}
우리는 이러한 파라미터의 의미로 볼 수있다 :
유형 : 개체의 데이터 형식은 일반적으로 5 개 개의 데이터 유형입니다.
인코딩 : 주로 단순한 동적 문자열리스트, 사전, 점프 테이블 정수 압축 목록을 입력 부호화 객체 기반 코드를 달성 redisObject.
*의 PTR : 기본 데이터 구조를 구현 포인터 포인트.
참조 카운트 : 기준 객체가 해제 될 때, 카운터의 카운트 값은 0이다.
LRU는 : 마지막으로이 객체를 방문했다.
String 데이터 유형
String 데이터 구조는 키 - 값의 간단한 유형, 레디 스 데이터의 가장 일반적으로 사용되는 유형이며, 값은 문자열이나 숫자 일 수도있다. String 데이터 유형이 실제로 문자열, 부동 소수점 값의 세 가지 유형의 정수 저장, 식별 자동으로 수행하는 방법 레디 스 문자열, 정수, 세 가지 유형의 부동 소수점 값. 레디 스는 C로 구현하지만, C에서 문자열을 사용하지 않고, 자신이 실제로 SDS 대체하는 String 형의 구조를 구현 레디 스됩니다 :
구조체 sdshdr {
// 기록 배열 사용 버피 바이트 길이
INT는 len;
// BUF 배열의 나머지 공간의 기록 길이
INT으로없는
문자열 기억 // 바이트 배열
[] BUF 숯불;
};
우리는 무료 매개 변수는 남아있는 사용 가능한 공간의 길이를 결정하는 데 사용되는 것을 볼 수 있습니다, 렌은 '\ 0'에 저장되어있는 문자열, 각 문자 버피와 문자열의 끝의 길이를 나타냅니다. 왜 레디 스 자신의 SDS 구조에게 그것을 달성하기 위해? 이후 SDS 구조는 몇 가지 장점이 있습니다 :
由于len保存了当前字符串的实际长度,所以获取长度时间复杂度为O(1)。SDS在拼接之前会对当前字符串的空间进行自动调整和扩展,防止当前字符串数据溢出。减少内存分配次数,SDS拼接字符串发生时,如果此时的字符串长度len小于1M,则SDS会分配和len大小相同的未使用空间给free,如果此时的字符串长度len大于1M,则SDS会分配和1M的未使用空间给free,当字符串缩短时,缩短的空间会叠加到free中,用于后续的拼接使用。
문자열 데이터는 일반적으로 사용되는 명령을 입력 :
- 일반적으로 사용되는 명령 : 등등 세트, 얻을, DECR, 증분, MGET합니다.
String 데이터 유형의 응용 프로그램 시나리오 :
분산 잠금
분산 세션 : 세션이 레디 스에서 분산 응용 프로그램에 저장됩니다
상품 스파이크
일반 개수 : 블로그 번호, 독서의 수
목록 데이터 유형
에서 데이터 구조는 캐릭터의 순서화 된 복수 저장하는 데 사용되는 각 문자열,리스트 요소가되는 레디 스에서, 노드 목록 재배치 순차 액세스 노드에 대한 능력을 제공 할 수있는리스트를 종료 푸시와 팝 요소, 당신은 또한, 범위를 지정된 요소의 목록을 두 가지 방법으로 구현 인수 및 기타 요소 지정된 인덱스, 주요 zipList의 목록 데이터 구조 (압축 목록) 및 LinkedList의 (이중 연결리스트)를 타겟팅 할 수 있습니다. 첫째, 우리는 LinkedList의 구조를 볼 수 :
유형 목록 구조체 {
// 헤더 노드
listnode의 머리;
// 테이블 꼬리 노드
listnode의 꼬리,
노드의 총 수는 // 포함
부호없는 긴 렌을;
};
각 헤더 포함 LinkedList의 노드에서 알 수있는 (A)의 헤드 노드와 꼬리 LinkedList의 각 노드가 갖고 꼬리 이전 포인트를 전방 요소뿐만 아니라 점 후 다음의 요소, 각 노드 값이 노드의 값이다. 이중 연결리스트를 달성하기 위해 사실을 이해하고 C 이중 연결리스트는 유사성의 큰 학위를 가지고 있습니다. 그리고 다른 하나는 다소 방법의 배열과 유사하지만 약간의 일관성 및 배열 연속 구현 zipList 메모리 구현을 기반으로 zipList가 일치하지 않을 수 있습니다 각 항목의 크기, 솔루션을 제어하기 위해 특별한 방법을 필요가 있지만, 푸시의 구현에, 팝 동작 데이터 이전이 될 때, 시간 복잡도는 O (n)에, 일반적으로는 이하 zipList 요소는 우리가 zipList의 구조를 볼 수 때만 사용된다 :
구조체 {ziplist 유형
// 압축 전체 목록의 바이트 수
uint32_t의 zlbytes,
헤드 노드 // 압축 꼬리를 기록하는 노드 목록의 바이트 수는 직접 노드의 주소를 찾을 수 있습니다
uint32_t의 zltail_offset을;
// 기록 노드의 수의 다양한 유형, 기본값은 다음과
uint16_t의 zllength을;
// 노드
목록 entryX을;
}
각 노드에서 zipList는 다음 매개 변수 정보를 가지고 :
previous_entry_length : 촬영 전에 노드 바이트 길이
함량 노드에 저장된 콘텐츠는 바이트 배열이나 정수 할
인코딩 : 콘텐츠 속성 유형 및 길이에 저장된 기록 데이터
*** 장면에 대한 목록 데이터 유형 **
데이터 유형의 문서 목록의 목록을 렌더링 할 때, 각 사용자는 문서의 목록을 표시해야하는 경우 일반적으로이 목록의 데이터 유형을 사용할 수 있습니다, 기사의 자신의 목록을 게시해야합니다 및 문서 인덱스 범위에 따라 문의를 할뿐만 아니라 주문할 수 있습니다 사용할 수 있습니다 목록.
데이터 유형을 설정합니다
목록 데이터 유형과 데이터 유형이 다소 유사하다 설정, 여러 요소를 저장하는 데 사용하지만, 가장 큰 차이점은, 설정 소수점 데이터 유형이 중복 된 요소는 표시를 허용하지 않으며, 요소의 설정이 무질서하다는 것이다 우리는 목록에 가지게 될 수있다 여러 유형을 지원하기 위해 인덱스 인덱스로 요소를 받고 있지만, 마찬가지로 교차로, 노동 조합, 차이를 취할 수있는 설정을 설정, 그래서 합리적인 사용 세트 데이터 유형은 실제 프로젝트 개발에 많은 문제를 해결할 수 있습니다. IntSet 및 해시 : 설정 데이터는 데이터 구조의 두 가지 유형이 있습니다. 먼저 우리는 IntSet의 구조를 보면 :
구조체 {IntSet 타입 정의
// 부호화
enconding uint32_t,
세트의 요소의 개수가 포함 //
uint32_t 길이;
// 배열 요소 저장
내용 [] int8_t;
} IntSet 단계;
정수 컬렉션의 모든 요소 인 설정하면, 레디 스 IntSet는 데이터 구조를 사용한다. IntSet 데이터 구조가 정렬 :이다에 특히주의하는 것이 중요하다. 요소의 순서를 제어하면서 레디 스 세트의 동적 배열 구조의 사용에 기초하여 정수 요소의 집합이다 때문에 가압 부재가 될 때 바이너리 서치 알고리즘을 사용할 수 있도록 소비 성능을 줄이기 위해서 푸시 및 팝 동작 요소가되도록 시간 복잡도는 O (logN)이다. 데이터 요소가 컬렉션 집합이 아닌 정수가있을 때, 레디 스가 자동으로 해시에, 키가 항상 null이 될 수 있도록, 데이터, 해시 테이블에있는 유일한 키 값, 저장된 값없이 값을 저장하기 위해 해시 데이터 구조를 사용합니다 . 우리는 해시 테이블의 구조를 볼 수 있습니다 :
구조체 {딕셔너리의 typedef
// 유형별 기능
dictType의 * 입력]
// 두 해시 테이블, 실시간 저장 한 상기 개작의 하나
[2] dictht의 HT;
//이 개작 데이터 이전 인덱스 이용한
부호 rehashidx 단계;
}
설정 데이터 유형 사용 시나리오 :
고유 값을 기록 : 예를 들어, IP를 기록, ID 번호
태그 및 사용자 환경 설정 데이터 컴퓨팅 학위를-설정 교차 할 수 태그를 추가합니다.
해시 데이터 유형
레디 스 해시 유형은 키 자체가 구조의 핵심이며, 우리가 객체를 부르는, 객체를 저장하는 데 사용 때문에 해시 데이터 유형이 가장 적합한 데이터 형식입니다. 해시 데이터 타입 코딩 zipList 또는 해시 일 수있다. 미만인 경우 64 바이트에 대한 해시 키에 저장된 모든 객체 미만 512 zipList 때 사용되는 요소의 수, 그렇지 해시 테이블. 목록 zipList 데이터 유형 그냥 기본적으로 동일한 zipList 사실을 언급, 유일한 차이점은 저장 해시 항목의 쌍의 수를 증가하기 때문에 특정 길이 2의 정수 배수 인 것입니다. O (N)의 물론 zipList를 사용하여 상기 한 빼낼 시간 복잡도가되도록 만하는 경우 소량의 데이터 만이 허용되는 곳. DICT, dictht, 항목 : 그리고 사실, 해시 자바 해시 다소 유사, HashTTable 세 가지 주요 구조에 의존한다. 세 구조로 표현 될 수있다 관계는이 도면을 따른다 :
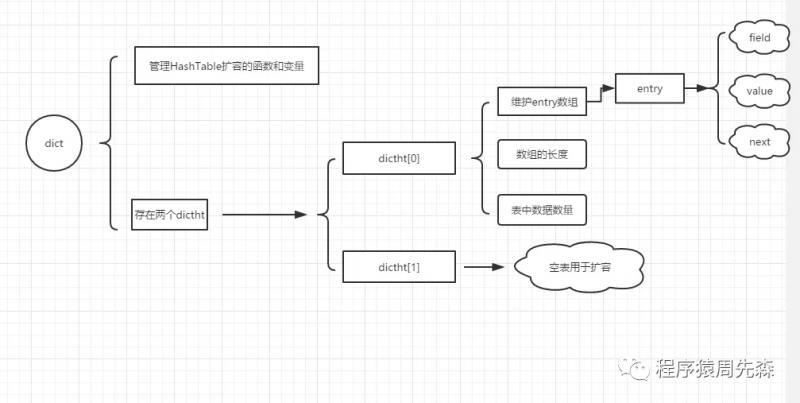
해시 데이터 형식 해당 장면 :
스토리지 오브젝트 데이터입니다.
JSON 객체들의 집합에서 설명한.
SortSet 데이터 유형
설정 명령 세트가 컬렉션을 기반으로, 컬렉션의 SortSet 요소가 SortSet 목록 정렬 및 인덱스를 정렬하는 지표로 사용될 수 정렬 정렬 할 수 있습니다, 유지 특성은 컬렉션에 설정 요소를 복제 할 수 없습니다,하지만 차이는 기초 SortSet는이 컬렉션의 질서와 키 데이터를 얻을 수 있도록 SortSet 데이터 구조 : zipList 및 skipList + 해시, zipList는 기본 정렬을 많이하지 않아도 때 적은 데이터를 사용 소규모에서 대규모까지의 요소. 데이터 구조 skipList + 해시의 사용은 skiplist 최적 범위 정렬 됨 복잡한 경우에 설정된 시간은, 해시 테이블이 이미 푸시 및 팝 요소의 시간 복잡도를 최적화 할 수있는 한 것을 확인한다. skipList 주문 목록을 기반으로, 당신은 다층 지수, 연습 시간의 복잡성에 대한 대가로 공간적 복잡도의 실현, 그리고 궁극적으로 시간 복잡도 인 쿼리 프로세스의 O (logN) 요소, 당신은 팝업 요소를 밀거나 할 필요가 사용을 만들 수 있습니다 해시 시간 복잡도를 달성는 O (1).
장면에 SortSet 데이터 유형
스코어 보드 :에 따라 포인트가 정렬 오름차순
데이터 수집의 범위 : 시험 80-100 데이터 포인트
공공 우려 번호에 오신 것을 환영합니다 : 프로그래머 저우 Xiansen