
통신 토폴로지를 재구성하기 위해 피어 주소를 TCP 스트림으로 직접 전파하는 eBPF 코드의 마법
译自방해되지 않는 방식으로 Kubernetes 애플리케이션의 네트워크 토폴로지 구축,작자 Ilya Shakhat。
소개하다
Kubernetes 애플리케이션은 논리적으로 두 부분으로 나뉩니다. 한 부분은 컴퓨팅 리소스(포드로 표시)이고 다른 부분은 애플리케이션에 대한 액세스를 제공합니다(서비스로 표시). 애플리케이션 클라이언트는 어떤 Pod가 실제로 요청을 처리하는지 신경 쓰지 않고 추상 이름을 사용하여 액세스할 수 있습니다. 또한 단일 서비스에는 백엔드로 여러 포드가 있을 수 있으므로 로드 밸런서 역할도 합니다. 기본 Kubernetes 배포에서 이 로드 밸런싱 기능은 매우 간단한 iptables 또는 Linux IPVS를 사용하여 구현됩니다. 둘 다 L4(예: TCP) 계층에서 작동하고 순진한 무작위 기반 라운드 로빈 메커니즘을 구현합니다. 물론 클라우드 제공업체는 애플리케이션 노출을 위해 보다 전통적인 로드 밸런싱 솔루션을 제공할 수도 있지만 간단하게 시작하겠습니다.
Kubernetes에 배포된 애플리케이션에서 발생할 수 있는 다양한 문제에 대해 생각해 보면 클라이언트 요청을 처리하는 특정 인스턴스를 이해해야 하는 문제 클래스가 있습니다. 예를 들면 다음과 같습니다. (1) 애플리케이션 포드가 네트워크 연결 상태가 좋지 않은 호스트에 배포되어 다른 포드보다 새 연결을 설정하는 데 시간이 더 오래 걸립니다. 또는 (2) 시간이 지남에 따라 포드 성능이 저하되는 반면 다른 포드의 성능은 안정적으로 유지됩니다. 또는 (3) 특정 클라이언트의 요청이 애플리케이션 성능에 영향을 미칩니다. 분산 추적은 이와 같은 문제에 대한 통찰력을 얻는 방법 중 하나인 경우가 많으며 백엔드 애플리케이션에 대한 클라이언트 요청 경로를 추적하는 데 사용됩니다. 전통적으로 분산 추적에는 수동으로 코드를 추가하는 것에서 런타임에 완전히 자동화된 주입으로 이동할 수 있는 일종의 계측이 필요합니다. 하지만 클라이언트 코드를 전혀 수정하지 않고도 동일한 효과를 얻을 수 있습니까?
위 문제를 디버깅하려면 기본적으로 분산 추적의 두 가지 기능이 필요합니다. (1) 요청 대기 시간과 관련된 측정항목을 수집하고 (2) 각 요청이 어디로 가는지 정확히 아는 것입니다. 첫 번째 기능은 eBPF(커널 기능에 동적으로 프로브를 연결할 수 있는 기술)에서 지원하는 다양한 도구 중 하나를 사용하여 비침해적인 방식으로 쉽게 구현할 수 있습니다. 예를 들어 어떤 프로세스가 새 연결을 설정했는지 기록하고 소켓/연결 관련 메트릭을 가져옵니다. 재전송이나 악의적인 연결 재설정도 확인합니다. openEuler 생태계에서 이러한 도구는 소켓, TCP 및 L7/HTTP(s) 프로브를 포함하여 다양한 프로브를 제공하는 gala-gopher입니다. 그러나 두 번째 기능(개별 요청이 어디로 가는지 아는 것)은 달성하기가 훨씬 더 어렵습니다. 분산 추적 프레임워크에서는 범위/추적 ID를 애플리케이션 페이로드에 삽입한 다음 동일한 범위 ID를 사용하여 클라이언트와 백엔드 모두의 관찰 결과를 연관시켜 이를 수행합니다. 애플리케이션 코드에 방해가 되지 않는다는 것은 동일한 정보를 일반적인 방식으로 주입해야 함을 의미하지만, 애플리케이션 프로토콜에 이 작업을 수행하려면 아웃바운드 트래픽을 가로채서 구문 분석하고 ID를 주입해야 하므로 실행 가능하지 않습니다. 직렬화되어 전달됩니다. 서비스 메시를 재창조한 것 같습니다!
계속하기 전에 네트워크 모니터링에서 사용할 수 있는 데이터를 살펴보겠습니다. 여기서는 모니터가 애플리케이션 포드를 호스팅하는 모든 노드로부터 정보를 얻은 다음 이 데이터가 예를 들어 Prometheus에 의해 처리된다고 가정합니다. 수집하세요. 이를 달성하려면 몇 가지 실험 환경이 필요합니다.
테스트 환경
먼저 배포된 다중 노드 Kubernetes 클러스터가 필요합니다. Huawei Cloud에서는 해당 서비스를 CCE(Cloud Container Engine)라고 합니다.
그런 다음 테스트 애플리케이션이 필요하며 이를 위해 HTTP 요청을 수락하고 원래 요청에 지정된 주소로 나가는 HTTP 요청을 만들 수 있는 매우 간단한 Python 프로그램을 사용합니다. 이렇게 하면 응용 프로그램을 쉽게 연결할 수 있습니다.
이러한 응용 프로그램의 이름은 라틴 문자 A, B 등으로 지정됩니다. 애플리케이션 A는 배포 A와 서비스 A 등으로 배포됩니다. 첫 번째 애플리케이션도 외부에서 호출할 수 있도록 외부 세계에 노출됩니다.
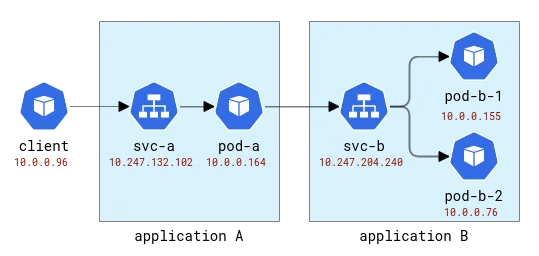
A 및 B 애플리케이션 토폴로지
Kubernetes에서 Gala-gopher는 데몬 세트로 배포되고 모든 Kubernetes 노드에서 실행됩니다. Prometheus에서 사용하고 궁극적으로 Grafana에서 시각화하는 측정항목을 제공합니다. 서비스 토폴로지는 메트릭을 기반으로 구축되고 NodeGraph 플러그인으로 시각화됩니다.
관찰 가능성
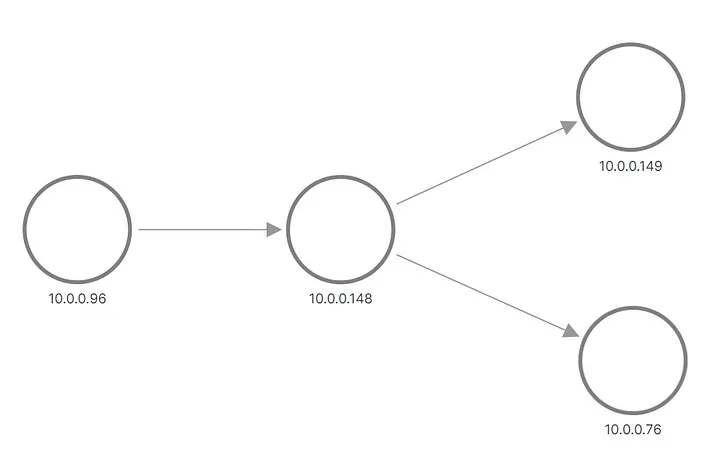
다음과 같이 일부 요청을 애플리케이션 A에 보내고 애플리케이션 B에 전달해 보겠습니다.
[root@debug-7d8bdd568c-5jrmf /]# curl http://a.app:8000/b.app:8000
..Hello from pod b-67b75c8557-698tr ip 10.0.0.76 at node 192.168.3.218
Hello from pod a-7954c595f7-tmnx8 ip 10.0.0.148 at node 192.168.3.14
[root@debug-7d8bdd568c-5jrmf /]# curl http://a.app:8000/b.app:8000
..Hello from pod b-67b75c8557-mzn6p ip 10.0.0.149 at node 192.168.3.14
Hello from pod a-7954c595f7-tmnx8 ip 10.0.0.148 at node 192.168.3.14
출력에서 애플리케이션 B에 대한 요청 중 하나가 하나의 Pod로 전송되고 다른 요청이 다른 Pod로 전송된 것을 볼 수 있습니다. Grafana에 토폴로지가 나타나는 방식은 다음과 같습니다.
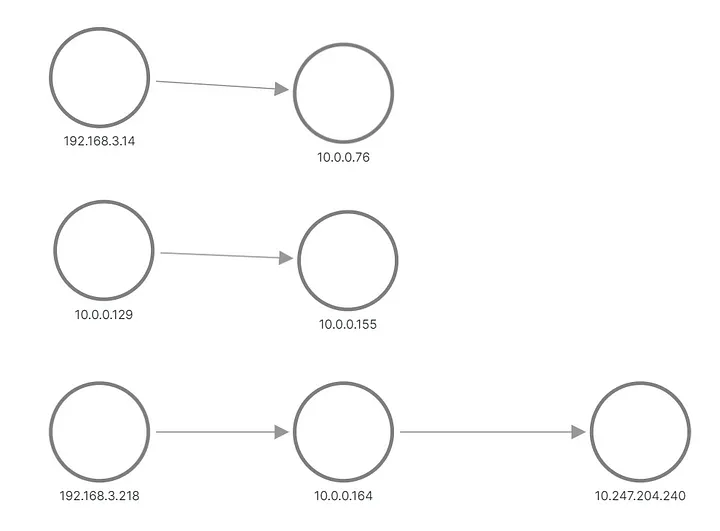
A와 B는 메트릭에서 재구성된 토폴로지를 적용합니다.
상단과 중간 행에는 애플리케이션 B의 포드에 요청을 보내는 항목이 표시되고, 하단에는 서비스 B의 가상 IP에 요청을 보내는 A의 포드 중 하나가 표시됩니다. 하지만 이건 우리가 기대했던 것과 전혀 같지 않죠? 우리는 그들 사이에 링크가 없는 세 개의 노드 세트만 볼 수 있습니다. 192.168.3.0/24 서브넷의 IP 주소는 클러스터 프라이빗 네트워크(VPC)의 노드 주소이고, 10.0.0.1/24는 포드 주소입니다. 단, 내부 트래픽에 사용되는 노드 주소인 10.0.0.129는 제외됩니다. 노드 통신 .
이제 이러한 측정항목은 소켓 수준에서 수집됩니다. 즉, 애플리케이션 프로세스에서 볼 수 있는 것과 정확히 일치합니다. 수집은 eBPF 프로브를 통해 수행되므로 첫 번째 아이디어는 운영 체제 커널이 소켓에서 사용 가능한 정보보다 애플리케이션 연결에 대해 더 많이 알고 있는지 확인하는 것입니다. 클러스터는 기본 CNI로 구성되고 Kubernetes 서비스는 iptables 규칙으로 구현됩니다. iptables-save의 출력에는 구성이 표시됩니다. 가장 흥미로운 것은 실제로 로드 밸런싱을 구성하는 다음 규칙입니다.
-A KUBE-SERVICES -d 10.247.204.240/32 -p tcp -m comment
--comment "app/b:http-port cluster IP" -m tcp --dport 8000 -j KUBE-SVC-CELO6J2CXNI7KVVA
-A KUBE-SVC-CELO6J2CXNI7KVVA -d 10.247.204.240/32 -p tcp -m comment
--comment "app/b:http-port cluster IP" -m tcp --dport 8000 -j KUBE-MARK-MASQ
-A KUBE-SVC-CELO6J2CXNI7KVVA -m comment --comment "app/b:http-port -> 10.0.0.155:8000"
-m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-VFBYZLZKPEFJ3QIZ
-A KUBE-SVC-CELO6J2CXNI7KVVA -m comment --comment "app/b:http-port -> 10.0.0.76:8000"
-j KUBE-SEP-SXF6FD423VYX6VFB
로드 밸런싱은 클라이언트와 동일한 노드에서 수행됩니다. 따라서 Pod를 노드에 매핑하면 다음과 같습니다.
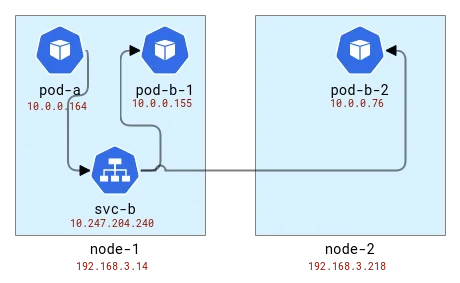
A 및 B 애플리케이션 토폴로지를 Kubernetes 노드에 매핑
내부적으로 iptables(실제로는 nftables )는 conntrack 모듈을 사용하여 패킷이 동일한 연결에 속하며 유사한 방식으로 처리되어야 함을 이해합니다. Conntrack은 주소 변환도 담당하므로 클라이언트 애플리케이션이 있는 노드는 패킷을 보낼 위치를 알아야 합니다. conntrack CLI 도구를 사용하여 확인해 보겠습니다.
# node-1
# conntrack -L | grep 8000
tcp 6 82 TIME_WAIT src=10.0.0.164 dst=10.247.204.240 sport=51030 dport=8000 src=10.0.0.76 dst=192.168.3.14 sport=8000 dport=19554 [ASSURED] use=1
tcp 6 79 TIME_WAIT src=10.0.0.164 dst=10.247.204.240 sport=51014 dport=8000 src=10.0.0.155 dst=10.0.0.129 sport=8000 dport=56734 [ASSURED] use=1
# node-2
# conntrack -L | grep 8000
tcp 6 249 CLOSE_WAIT src=10.0.0.76 dst=192.168.3.14 sport=8000 dport=19554 [UNREPLIED] src=192.168.3.14 dst=10.0.0.76 sport=19554 dport=8000 use=1
좋아요, 첫 번째 노드에서 주소는 애플리케이션 A의 포드에서 변환되었으며 임의의 포트가 있는 노드 주소를 얻었습니다. 두 번째 노드에서는 자체 패킷이 실제로 응답이므로 연결 정보가 반전되지만 이를 염두에 두고 요청이 첫 번째 노드와 동일한 임의 포트에서 오는 것을 볼 수 있습니다. 2개의 요청을 보냈고 서로 다른 Pod(동일한 노드의 pod-b-1 및 다른 노드의 Pod-b-2)에서 처리되었기 때문에 Node-1에는 두 개의 요청이 있습니다.
여기서 좋은 소식은 클라이언트 노드에서 실제 요청 수신자를 알 수 있지만 서버 측에서는 이를 클라이언트 노드에서 수집된 정보와 연관시켜야 한다는 것입니다 . 이와 같이:
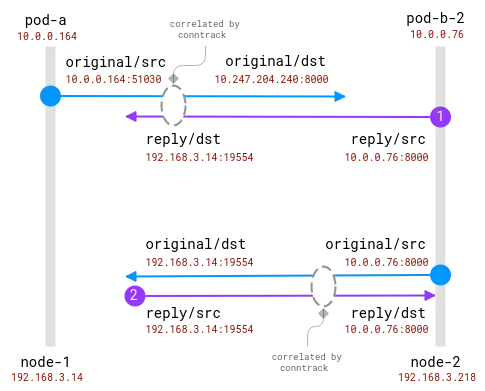
연결은 conntrack 모듈에 의해 추적됩니다. 파란색 원은 소켓에서 관찰되는 로컬 주소이고 보라색 원은 원격 주소입니다. 문제는 보라색과 파란색을 연관시키는 것입니다.
클라이언트와 서버 포드가 모두 동일한 노드에 있으면 상관관계가 더 단순해집니다. 하지만 어떤 주소가 실제 주소이고 어떤 주소를 무시해야 하는지에 대한 몇 가지 가정이 여전히 있습니다.
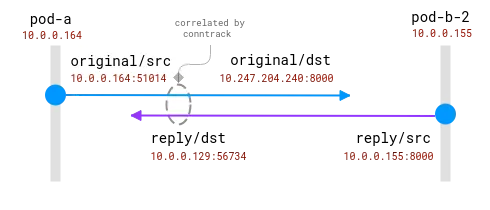
동일한 노드에 있는 두 포드 간의 연결입니다. 소스 주소는 실제이지만 대상 주소는 매핑되어야 합니다.
여기서 운영 체제는 NAT에 대한 완전한 가시성을 가지며 실제 소스와 실제 대상 간의 매핑을 제공할 수 있습니다. 10.0.0.164에서 10.0.0.155로 전체 스트림을 재구축하는 것이 _가능_합니다.
이 섹션을 마무리하려면 conntrack 모듈의 주소 변환에 대한 정보를 포함하도록 기존 eBPF 프로브를 확장하는 것이 가능해야 합니다. 클라이언트는 요청이 어디로 가는지 알 수 있습니다. 그러나 서버는 클라이언트가 누구인지 항상 알 수 없으며 중앙 집중식 상관 알고리즘이 직접 없습니다. 반면, 분산 추적 방법은 통신 데이터를 통해 클라이언트와 서버에 동료에 대한 정보를 직접적으로 즉시 제공합니다. 그래서 FlowTracer가 왔습니다!
플로우트레이서
아이디어는 간단합니다. 연결 내에서 피어 간에 직접 데이터를 전송하는 것입니다. 이러한 기능이 필요한 것은 이번이 처음이 아닙니다. 예를 들어 HTTP 로드 밸런서는 백엔드 서버에 클라이언트에 대해 알리기 위해 X-Forwarded-For HTTP 헤더를 삽입합니다. 여기서 제한 사항은 L4에 머물면서 모든 애플리케이션 수준 프로토콜을 지원한다는 것입니다. 이러한 기능도 존재하며 일부 L4 로드 밸런서(예: 이 기능 )는 원본 주소를 TCP 헤더 옵션으로 주입하여 서버에서 사용할 수 있도록 할 수 있습니다.
요구사항 요약:
- L4 계층 전송 피어 주소입니다.
- 주소 주입을 동적으로 활성화하는 기능(K8s에 애플리케이션을 쉽게 배포하는 등)
- 비침습적이고 빠릅니다.
가장 간단한 접근 방식은 TCP 헤더 옵션(TOA라고도 함)을 사용하는 것 같습니다. 페이로드는 IP 주소와 포트 번호입니다(주소 변환 중에 변경되기 때문). Huawei Kubernetes 배포는 IPv4만 지원하므로 지원을 IPv4로만 제한할 수 있습니다. IPv4 주소는 32비트인 반면 포트 번호에는 16비트가 필요합니다. 즉, 옵션 유형에 1바이트, 옵션 길이에 1바이트를 더해 총 6바이트가 필요합니다. TCP 헤더 사양은 다음과 같습니다.
헤더에는 최대 40바이트의 여러 옵션이 포함될 수 있습니다. 각 옵션은 길이와 유형/종류가 가변적일 수 있습니다.
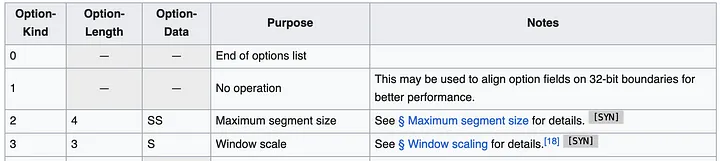
일반적으로 Linux TCP 패킷에는 이미 MSS 또는 타임스탬프와 같은 몇 가지 옵션이 있습니다. 하지만 아직 우리가 사용할 수 있는 공간은 약 20바이트 정도입니다.
이제 데이터를 어디에 넣을지 알았으면 다음 질문은 어디에 코드를 추가해야 하는가입니다. 우리는 솔루션이 가능한 한 일반적이고 모든 TCP 연결에 사용될 수 있기를 원합니다. 이상적인 위치는 네트워크 스택의 커널 어딘가, 즉 최상위 레벨부터 네트워크를 통해 전송될 준비가 된 패킷까지 소켓 버퍼(네트워크 연결 정보를 나타내는 구조)라고 불리는 곳입니다. 구현 관점에서 볼 때 코드는 eBPF 코드(물론!)여야 하며 그런 다음 주소 주입 기능을 동적으로 활성화할 수 있습니다.
이런 종류의 코드가 가장 눈에 띄는 곳은 흐름 제어 모듈인 TC입니다. TC에서 eBPF 프로그램은 생성된 패킷에 액세스할 수 있으며 패킷에서 데이터를 읽고 쓸 수 있습니다. 한 가지 단점은 패킷을 처음부터 구문 분석해야 한다는 것입니다. 즉, bpf_skb_load_bytes_relative 함수가 L3 헤더의 시작 부분에 대한 포인터를 제공하더라도 L4 위치는 여전히 수동으로 계산해야 합니다. 가장 문제가 되는 것은 삽입 작업이다. bpf_skb_adjust_room 및 bpf_skb_change_tail 이라는 유망한 이름을 가진 두 가지 함수가 있지만 L4가 아닌 L3 패킷 크기 조정을 허용합니다. 다른 해결책은 기존 TCP 헤더에 특정 옵션이 포함되어 있는지 확인하고 이를 재정의하는 것입니다. 하지만 먼저 일반적인 패킷에 포함된 내용을 확인하겠습니다.
1514772378.301862 IP (tos 0x0, ttl 64, id 20960, offset 0, flags [DF], proto TCP (6), length 60)
192.168.3.14.28301 > 10.0.0.76.8000: Flags [S], cksum 0xbc03 (correct), seq 1849406961, win 64240, options [mss 1460,sackOK,TS val 142477455 ecr 0,nop,wscale 9], length 0
0x0000: 0000 0001 0006 fa16 3e22 3096 0000 0800 ........>"0.....
0x0010: 4500 003c 51e0 4000 4006 1ada c0a8 030e E..<Q.@.@.......
0x0020: 0a00 004c 6e8d 1f40 6e3b b5f1 0000 0000 ...Ln..@n;......
0x0030: a002 faf0 bc03 0000 0204 05b4 0402 080a ................
0x0040: 087e 088f 0000 0000 0103 0309 .~..........
이는 클라이언트가 백엔드 애플리케이션과 연결을 설정할 때 전송되는 TCP SYN 패킷입니다. 헤더에는 여러 가지 옵션이 포함됩니다. 최대 세그먼트 크기를 지정하는 MSS, 선택적 승인, 패킷 순서를 보장하는 특정 타임스탬프, 단어 정렬을 위한 opcode NOP, 마지막으로 창 크기에 대한 창 크기 조정. 해당 목록에서 타임스탬프 옵션은 다루기에 가장 좋은 후보인 반면(Wikipedia에 따르면 채택률은 여전히 약 40%), 비침해적 eBPF 추적 분야의 선두주자 중 하나인 DeepFlow는 이 작업을 에서 수행했습니다.
이 접근 방식은 실현 가능해 보이지만 구현하기는 쉽지 않습니다. TC 프로그램은 번역된 주소에 액세스할 수 있습니다. 이는 번역 맵을 어떻게든 conntrack 모듈에서 검색하여 저장해야 함을 의미합니다. TC 프로그램은 네트워크 카드에 연결되므로 노드에 여러 네트워크 카드가 있는 경우 배포 시 연결 위치를 올바르게 식별해야 합니다. 리더 모듈은 모든 패킷을 구문 분석하여 TCP를 찾은 다음 헤더를 반복하여 헤더가 어디에 있는지 찾아야 합니다. 다른 방법이 있나요?
2023년 8월에 Google을 통해 이 질문을 검색하면 검색 결과 페이지 하단에 더 이상 결과가 표시되지 않는 것이 일반적입니다(이 블로그 게시물이 이를 변경하길 바랍니다!). 가장 유용한 참고 자료는 2020년 Facebook 엔지니어가 제작한 Linux 커널 패치에 대한 링크입니다. 이 패치는 우리가 원하는 것을 보여줍니다:
BPF-TCP-CC에 대한 초기 작업을 통해 TCP 혼잡 제어 알고리즘을 BPF로 작성할 수 있었습니다. 새로운 혼잡 제어 아이디어를 테스트/출시할 때 프로덕션 환경에서 처리 시간을 개선할 수 있는 기회를 제공합니다. 동일한 유연성을 TCP 헤더 옵션 작성에도 확장할 수 있습니다.
사람들이 TCP 성능을 향상시키기 위해 새로운 TCP 헤더 옵션을 테스트하고 싶어하는 것은 드문 일이 아닙니다. 또 다른 사용 사례는 보다 통제된 환경을 갖추고 내부 전용 트래픽에 헤더 옵션을 배치하여 더 많은 유연성을 제공할 수 있는 데이터 센터에 대한 것입니다.
성배는 bpf_store_hdr_opt 및 bpf_load_hdr_opt 함수입니다 ! 둘 다 5.10 커널부터 사용할 수 있는 특별한 유형의 양말 작전 프로그램 에 속합니다 . 즉, 2022년 이후 거의 모든 버전에서 사용할 수 있습니다. Sock ops 프로그램은 특정 소켓(예: 특정 컨테이너에 속함)에 대해서만 활성화할 수 있도록 cgroup v2에 연결된 단일 기능입니다. 프로그램은 소켓의 현재 상태를 나타내는 단일 작업을 받습니다. 새 헤더 옵션을 작성하려면 먼저 활성 또는 수동 연결에 대한 쓰기를 활성화한 다음 헤더 페이로드를 작성하기 전에 새 헤더 길이를 알려야 합니다. 읽기 작업은 더 간단하지만 헤더 옵션을 읽기 전에 먼저 읽기를 활성화해야 합니다. TCP 패킷이 생성되면 TCP 헤더 콜백이 호출됩니다. 이는 주소 변환 전에 발생하므로 소켓 소스 주소를 헤더 옵션에 복사할 수 있습니다. 판독기는 헤더 옵션에서 값을 쉽게 추출하여 BPF 맵에 저장할 수 있으므로 나중에 소비자가 관찰된 원격 주소를 읽고 실제 주소로 매핑할 수 있습니다. 첫 번째 실행 코드의 BPF 부분은 100줄보다 훨씬 적습니다. 꽤 좋아!
코드 생산 준비 완료
그러나 악마는 디테일에 있습니다. 먼저 BPF 맵에서 오래된 레코드를 삭제하는 방법이 필요합니다. 이를 수행하기에 가장 좋은 시기는 conntrack 모듈이 테이블에서 연결을 삭제할 때입니다. Arthur Chiao의 이 기사 는 conntrack 모듈과 연결 수명주기의 내부 구조에 대한 좋은 설명을 제공하므로 커널 소스( nf_conntrack_destroy )에서 올바른 함수를 쉽게 찾을 수 있습니다 . 이 함수는 내부 테이블에서 삭제하기 전에 conntrack 항목을 수신합니다. 이때 연결이 공식적으로 종료되므로 매핑 테이블에서 연결을 제거하는 프로브를 추가할 수도 있습니다.
sock ops 프로그램에서는 새 헤더 옵션이 모든 패킷에 적용된다는 가정 하에 어떤 패킷에 삽입되는지 지정하지 않습니다. 실제로 이는 사실이지만 읽기는 연결이 설정/확인된 상태일 때만 유효합니다. 즉, 서버 측에서는 들어오는 SYN 패킷에서 헤더 옵션을 읽을 수 없습니다. SYN-ACK도 일반 TCP 스택보다 먼저 처리되므로 헤더 옵션을 삽입하거나 읽을 수 없습니다. 실제로 이 기능은 연결이 첫 번째 PSH(패킷)로 완전히 실행되는 경우 양쪽 끝에서만 작동합니다. 연결이 작동하는 경우에는 문제가 없지만 연결 시도가 실패하면 클라이언트는 연결을 시도한 위치를 알 수 없습니다. 이는 중대한 실수입니다. 이 정보는 네트워크 문제를 디버깅하는 데 유용합니다. 아시다시피 Kubernetes 로드 밸런싱은 클라이언트 노드에 구현되므로 conntrack에서 정보를 추출하여 스트림을 통해 수신된 데이터와 동일한 형식으로 저장할 수 있습니다. Conntrack 함수 ___nf_conntrack_confirm_이 여기에 도움이 됩니다. 새 연결이 확인되려고 할 때 호출됩니다. 이는 활성 클라이언트(나가는) TCP 연결의 경우 첫 번째 SYN 패킷이 전송될 때 발생합니다.
이러한 모든 추가로 인해 코드가 약간 부풀어오르지만 여전히 총 1000줄보다 훨씬 적습니다. 전체 패치는 이 MR 에서 사용할 수 있습니다 . 실험 설정에서 이를 활성화하고 측정항목과 토폴로지를 다시 확인할 시간입니다!
바라보다:
올바른 A/B 애플리케이션 토폴로지
1990년대에 태어난 프로그래머가 비디오 포팅 소프트웨어를 개발하여 1년도 안 되어 700만 개 이상의 수익을 올렸습니다. 결말은 매우 처참했습니다! 고등학생들이 성인식으로 자신만의 오픈소스 프로그래밍 언어 만든다 - 네티즌 날카로운 지적: 만연한 사기로 러스트데스크 의존, 가사 서비스 타오바오(taobao.com)가 가사 서비스를 중단하고 웹 버전 최적화 작업 재개 자바 17은 가장 일반적으로 사용되는 Java LTS 버전입니다. Windows 10 시장 점유율 70%에 도달, Windows 11은 계속해서 Open Source Daily를 지원합니다. Google은 Docker가 지원하는 오픈 소스 Rabbit R1을 지원합니다. Electric, 개방형 플랫폼 종료 Apple, M4 칩 출시 Google, Android 범용 커널(ACK) 삭제 RISC-V 아키텍처 지원 Yunfeng은 Alibaba에서 사임하고 향후 Windows 플랫폼용 독립 게임을 제작할 계획이 기사는 Yunyunzhongsheng ( https://yylives.cc/ ) 에 처음 게재되었습니다 . 누구나 방문하실 수 있습니다.