
DolphinDB는 분산 컴퓨팅, 트랜잭션 지원, 다중 모드 저장 및 스트리밍 배치 통합 기능을 갖춘 고성능 분산 시계열 데이터베이스로 원스톱 고성능 빅데이터를 쉽게 구축할 수 있는 이상적인 경량 빅데이터 플랫폼으로 매우 적합합니다. 성능 실시간 데이터베이스.
이 튜토리얼에서는 사례와 스크립트를 사용하여 DolphinDB를 통해 실시간 데이터 웨어하우스를 빠르게 구축하여 다양한 산업(예: 에너지 및 전력, 항공우주, 차량 인터넷, 석유화학, 광업, 지능형 제조, 무역 및 정부 업무, 금융 등) 비즈니스 시나리오의 대용량 데이터에 대한 저지연 복합 지표 계산 및 분석을 신속하게 구현합니다.
이 튜토리얼에는 원칙 및 실제 작업에 대한 소개와 지원 샘플 코드가 포함되어 있습니다. 사용자는 튜토리얼을 따라 자신의 비즈니스 특성을 결합하여 경량의 고성능 실시간 데이터 웨어하우스를 구축할 수 있습니다 .
1. 소개
1.1 사건 배경과 필요성
빅데이터 시대가 도래하면서 각계각층에서는 데이터 처리의 실시간성과 정확성에 대한 요구 사항이 점점 더 높아지고 있습니다. 기존의 오프라인 데이터 웨어하우스는 기업의 데이터 저장 및 오프라인 분석 요구 사항을 어느 정도 충족할 수 있지만 대규모 실시간 데이터를 처리할 수 없는 경우가 많습니다. 특히 실시간 데이터에 대한 요구 사항이 매우 높은 선도적인 사물 인터넷 및 금융 회사에서는 오프라인 데이터 웨어하우스의 한계가 더욱 분명해집니다.
전력 산업의 발전소를 예로 들면, 각 발전소에는 발전소의 운영 데이터를 실시간으로 수집하는 수많은 측정 지점이 있습니다. 방대한 발전소 운영 데이터를 어떻게 결합하고, 실시간 데이터에 대한 정확하고 복잡한 계산과 분석을 어떻게 수행하는가는 발전소의 주요 과제가 되었습니다. 기존 실시간 데이터베이스에는 대용량 데이터에 대한 집계 분석 및 컴퓨팅 기능이 부족한 반면, 기존 빅데이터 시스템으로 구축된 오프라인 데이터 웨어하우스는 느린 처리 속도, 높은 대기 시간, 복잡한 아키텍처로 인해 심층적인 비즈니스 요구 사항을 충족하기 어렵습니다.
경량 원스톱 실시간 데이터 웨어하우스 솔루션인 DolphinDB는 고성능 분산 컴퓨팅 프레임워크, 실시간 스트리밍 데이터 처리 기능, 분산 다중 모드 스토리지 엔진 및 메모리 컴퓨팅 기술을 통해 이 문제에 대한 솔루션이 되었습니다. .
이 기사에서는 DolphinDB를 사용하여 일반적인 발전 측면 수요 시나리오를 구현합니다. 발전측에서 1초마다 샘플링되는 40,000개의 측정점으로 다양한 측정점 표시기(최대값, 최소값, 평균값, 중앙값, 95% 분위수, 5% 분위수, 변화량, 변화율, 시작값, 종료값 등) .), 밀리초 수준의 쿼리 응답을 달성합니다. 이러한 지표는 발전소 운영 모니터링, 오류 경고, 에너지 효율 분석, 빅데이터 표시 등에 매우 중요합니다. (더 많은 IoT 산업 시나리오 솔루션을 원하시면 DolphinDB 보조 돌고래db1을 추가하세요)
1.2 데이터 웨어하우스의 기본 개념
데이터 웨어하우스(줄여서 DW 또는 DWH)는 특정 비즈니스 시나리오에서 의사 결정 프로세스를 지원하도록 설계된 대량의 데이터를 저장, 처리 및 분석하는 데 사용되는 시스템입니다. 데이터 웨어하우스는 여러 데이터 소스(예: MySQL, Oracle, MongoDB, HBase 등)로부터 이종 데이터(예: 데이터 테이블, Json, CSV, Protobuf 등)를 데이터를 통해 수집하고 통합할 수 있는 기술 아키텍처이기도 합니다. 다차원 비즈니스 분석, 데이터 마이닝 및 정확한 의사 결정을 지원하기 위해 데이터를 정리, 통합 및 변환하고 통합 스토리지 시스템(예: DolphinDB, Hadoop)에 통합합니다.
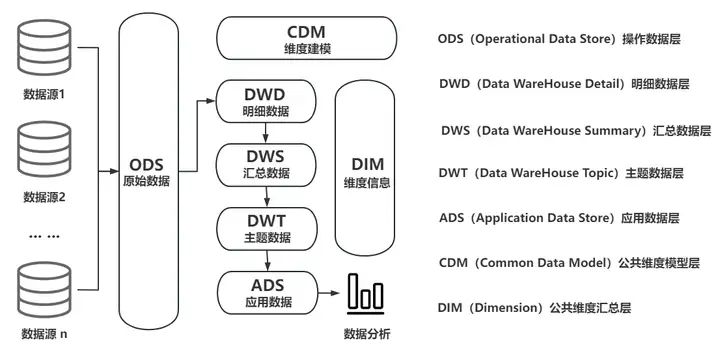
1.1 기존 데이터 웨어하우스의 일반적인 아키텍처 다이어그램
데이터 웨어하우스의 중요성은 기업이 데이터를 중앙 집중식으로 관리하고 효율적으로 활용하도록 돕는 능력에 있습니다. 목적과 실시간 특성에 따라 오프라인 데이터 웨어하우스와 실시간 데이터 웨어하우스의 두 가지 유형으로 나눌 수 있습니다.
오프라인 데이터 웨어하우스는 일반적으로 T-1 방식으로 구현되는데, 즉 매일 일정한 시간(예: 이른 아침)에 작업을 통해 전날의 이력 데이터를 데이터 웨어하우스로 가져온 후 대규모 이력 데이터( 배치 데이터)은 OLAP(Online Analytical Process)을 통해 분석됩니다.
대부분의 기업에서는 실시간 위험 제어, 실시간 효과 분석, 실시간 프로세스 제어 및 기타 비즈니스 기능을 실현하기 위해 T+0이 시급히 필요합니다. 기존의 오프라인 데이터 웨어하우스는 실시간 요구 사항을 충족할 수 없으므로 실시간 및 분석 기능을 고려한 새로운 데이터 웨어하우스 아키텍처, 즉 실시간 데이터 웨어하우스가 등장했습니다.
실시간 데이터 웨어하우스의 기술 요구 사항과 구현 난이도는 기존 데이터 웨어하우스의 기술 요구 사항을 훨씬 능가합니다. 기존 데이터 웨어하우스와 비교하여 실시간 데이터 웨어하우스는 보다 효율적인 데이터 처리 기능과 실시간(준실시간) 데이터 업데이트 빈도를 가질 수 있습니다. 저지연 성능 요구 사항에 따라 데이터 소스 이질성, 데이터 품질 관리, 트랜잭션 및 강력한 일관성, 다중 모드 스토리지, 고성능 집계 분석 등의 기술적 문제를 해결해야 합니다. 또한, 일반 개발자가 어떻게 실시간 데이터 웨어하우스의 개발 및 운영, 유지 관리 능력을 갖추고, 지속적이고 안정적으로 제품 반복을 수행할 수 있는지도 매우 큰 테스트입니다.
1.3 기존 실시간 데이터 웨어하우스의 일반적인 아키텍처
기존의 실시간 데이터 웨어하우스는 일반적으로 Hadoop 빅 데이터 프레임워크를 기반으로 하며 Lambda 아키텍처 또는 Kappa 아키텍처를 사용합니다. 기술이 복잡하고 개발 주기가 길어 개발자 비용, 시간 비용, 하드웨어 투자 비용 측면에서 기업에 큰 부담이 됩니다.
기존 실시간 데이터 웨어하우스의 일반적인 기술 스택은 다음과 같습니다.
- 컬렉션(Sqoop, Flume, Flink CDC, DataX, Kafka)
- 스토리지(HBase, HDFS, Hive, MySQL, MongoDB)
- 데이터 처리 및 컴퓨팅(Hive, Spark, Flink, Storm, Presto)
- OLAP 분석 및 쿼리(TSDB/HTAP, ES, Kylin, DorisDB)
기업이 기존 실시간 데이터 웨어하우스를 구현하려는 경우 높은 학습 비용, 대규모 리소스 소비, 부족한 확장성 및 실시간 성능 등 많은 문제에 직면하게 됩니다.
1.4 DolphinDB 실시간 데이터 웨어하우스 아키텍처 및 성능
복잡한 기존 실시간 데이터 웨어하우스와 달리 DolphinDB는 자체 제품 기능을 통해 경량 실시간 데이터 웨어하우스를 빠르게 구현할 수 있습니다. 수집, 저장, 흐름 컴퓨팅, ETL, 의사 결정 분석 및 계산, 시각적 표시를 독립적으로 수행할 수 있습니다. 또한 기업이 배포한 다양한 타사 애플리케이션(예: 빅 데이터 플랫폼, AI 중간 플랫폼, 조종석)에 대한 효과적인 보완책으로 사용하여 기업 수준 애플리케이션 시스템 및 그룹에 대한 실시간 데이터 웨어하우스 기술 지원을 제공할 수 있습니다. 보다 복잡한 애플리케이션 시나리오를 달성하기 위한 레벨 데이터 중간 플랫폼입니다.
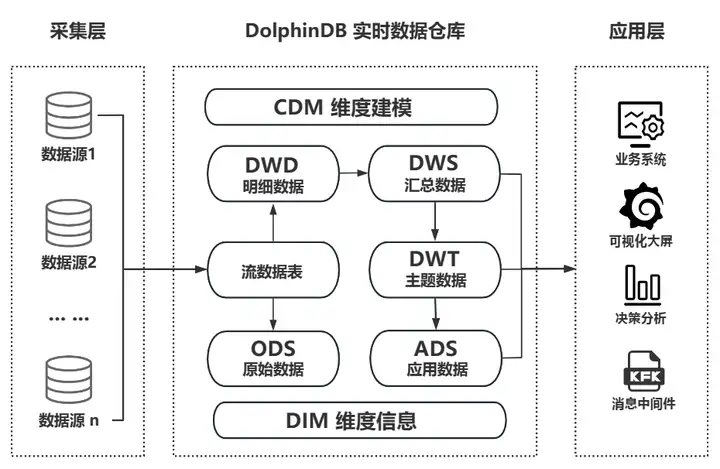
DolphinDB 실시간 데이터 웨어하우스 비즈니스 아키텍처 다이어그램
DolphinDB는 사물인터넷, 금융 등 다양한 산업 분야에서 풍부하고 성숙한 데이터 웨어하우스 실무 사례를 보유하고 있어 광범위한 애플리케이션 가치를 충분히 입증하고 있습니다.
지방 관세전자항만업체의 실시간 데이터 웨어하우스 프로젝트를 예로 들면, 돌핀DB가 구축한 실시간 데이터 웨어하우스는 올인원의 경량 원스톱 제품의 장점을 십분 활용한다. 다중 소스 이기종 데이터에 대한 액세스를 지원하고 표준 SQL과 호환되며 복잡한 다중 테이블 연결을 지원하고 강력한 ETL 데이터 정리 기능을 갖추고 있어 데이터 처리 체인을 크게 단축하고 운영, 유지 관리 및 개발 비용을 절감합니다. 사업 구조와 기술적 특성은 아래 그림과 같습니다.
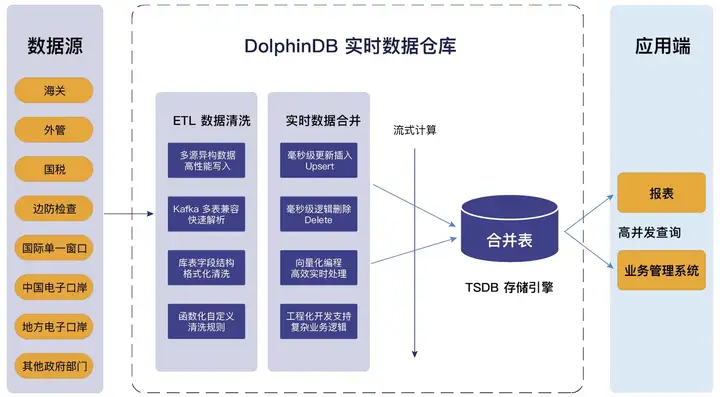
성 전자항만 실시간 데이터웨어 하우스 프로젝트 사업 구조도
다음은 3개 머신 고가용성 클러스터를 배포할 때 DolphinDB가 지원할 수 있는 실시간 데이터 웨어하우스 성능 지표에 대한 참조입니다.
- 지원되는 측정 지점 수: >1억 측정 지점
- 쓰기 처리량: >1억 측정 포인트/초
- ODS에서 지원하는 레코드 수: > 1조
- 최대 클라이언트 연결 수: >5000
- 동시 쿼리(QPS): >5000
- 다차원 집계 쿼리: 밀리초 수준
- 실시간 스트림 컴퓨팅 특징값 추출: >500,000/초
- 단일 레코드 및 단일 프로세스의 삭제 및 수정(소프트 삭제, upsert)을 위한 동기화 시간: ≒ 10ms
- 고가용성 클러스터: 다중 복사본(데이터 고가용성), 다중 제어 노드(메타데이터 고가용성), 클라이언트 연결 끊김 재연결 및 장애 조치(클라이언트 고가용성)
- 탄력적 확장: 다운타임 없는 수평 확장(노드 추가), 다운타임 없는 수직 확장(디스크 볼륨 추가), 그레이스케일 업그레이드 지원
2. DolphinDB 실시간 데이터 웨어하우스 실습
다음으로, 수력 발전소 발전기 장비의 실시간 모니터링에 대한 실제 요구 사항을 예로 들어 DolphinDB를 사용하여 경량 실시간 데이터 웨어하우스를 구축하겠습니다. 이 사례는 에너지 및 전력, 산업용 사물 인터넷, 차량 인터넷 및 기타 산업에 적용될 수 있습니다.
모두가 함께 시도하고 검증해 보시기 바랍니다!
2.1 DolphinDB 설치 및 배포
1. 공식 홈페이지 커뮤니티의 최신 버전을 다운로드하세요. 버전 2.00.11 이상을 권장합니다.
포털: https://cdn.dolphindb.cn/downloads/DolphinDB_Win64_V2.00.11.3.zip
2. 프로그램 파일 경로에 설치하지 않으려면 Windows 압축 해제 경로에 공백이 없어야 합니다.
공식 웹사이트 튜토리얼: https://docs.dolphindb.cn/zh/tutorials/deploy_dolphindb_on_new_server.htm l
3. 본 테스트는 기업 버전을 사용하며, 무료 평가판 라이선스를 신청할 수 있습니다. 무료 커뮤니티 버전을 사용하는 경우 테스트의 데이터 수준을 줄이는 것이 좋습니다.
획득 방법 : https://dolphindb.cn/product# 다운로드
4. 설치 및 테스트 과정에서 질문이 있는 경우 백그라운드에서 비공개 메시지를 보내 상담을 받을 수 있습니다.
2.2 실시간 데이터 웨어하우스 지표 요구 사항
- 기본 데이터 상황
측정점 수: 40000
샘플링 빈도: 초
- 계산된 지표(집계된 값)

2.3 실무계획 수립
DolphinDB 스트림 컴퓨팅 프레임워크를 기반으로 엣지에 경량 실시간 데이터 웨어하우스가 구축됩니다. 모든 계산 결과는 데이터가 기록되는 동안 효율적으로 완료되며 지연은 밀리초 수준으로 제어됩니다.
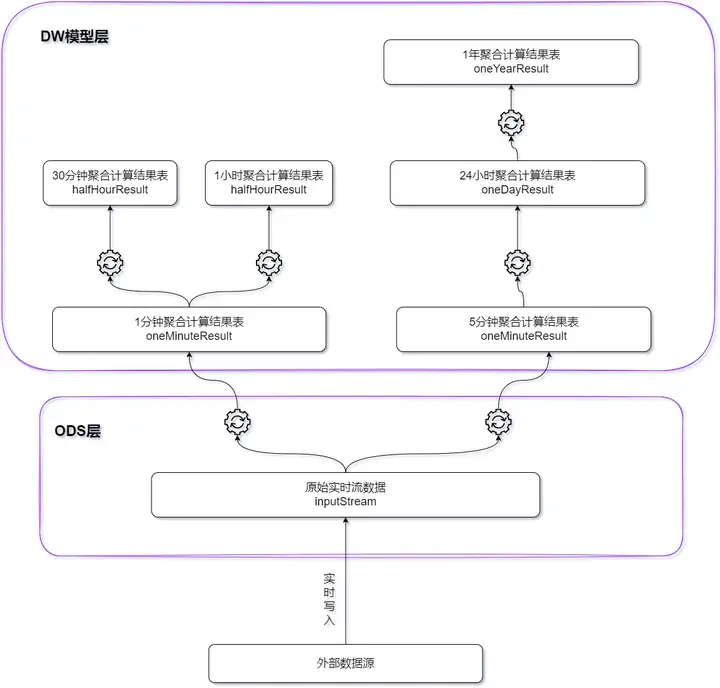
- 계산주기가 1분, 계산주기가 5분인 지표의 경우 원본 실시간 데이터가 기본 테이블로 사용됩니다.
- 계산 기간이 30분이고 계산 기간이 1시간인 지표의 경우 1분 계산 결과가 기본 테이블로 사용됩니다.
- 24시간 계산 주기 지표의 경우 5분 계산 결과가 기본 테이블로 사용됩니다.
- 계산 기간이 1년인 지표의 경우 24시간 계산 결과가 기본 테이블로 사용됩니다.
각 지표 유형의 계산 창과 슬라이딩 단계 크기는 다음 표와 같습니다.
| 계산주기 | 창 길이 | 슬라이딩 단계 크기 | 주목 |
|---|---|---|---|
| 1 분 | 1 분 | 1 분 | 1분마다 지난 1분 범위의 값을 계산합니다. |
| 5 분 | 5 분 | 5 분 | 5분마다 지난 5분 범위 내의 값을 계산합니다. |
| 30 분 | 30 분 | 30 분 | 30분마다 지난 30분 범위 내의 값이 계산됩니다. |
| 1 시간 | 1 시간 | 1 시간 | 1시간마다 지난 1시간 범위 내의 값이 계산됩니다. |
| 24 시간 | 24 시간 | 24 시간 | 24시간마다 지난 24시간 범위 내의 값이 계산됩니다. |
| 일년 | 일년 | 24 시간 | 1일마다 지난 1년 범위 내의 값이 계산됩니다. |
3. 성능 테스트 및 결과
3.1 테스트 환경
테스트 및 검증을 용이하게 하기 위해 단일 머신 및 단일 노드 배포 방법을 사용하여 경량 실시간 데이터 웨어하우스를 구현합니다. 서버 구성은 다음과 같습니다.
- CPU: 코어 12개
- 메모리: 32GB
- 디스크: 1.1T HDD 150MB/s
스크립트를 이용하여 24시간(2023.01.01T00:00:00~2023.01.02T00:00:01.000) 내 모든 측정지점(40000)의 실시간 데이터를 시뮬레이션하고 1분, 5분, 30분, 1회 수행 시간, 24시간 창 집계 계산이 수행되고 계산 결과가 분산 데이터베이스에 기록됩니다. (특정 윈도우에서는 데이터 항목의 개수가 윈도우 길이보다 작을 수 있습니다)
1년 기간 계산을 위해 24시간 기간 계산 결과의 실시간 데이터도 시뮬레이션하고, 시뮬레이션 결과를 실시간으로 집계, 계산한다.
자세한 테스트 스크립트는 기사 끝 부분의 첨부 파일에 포함되어 있습니다.
3.2 테스트 결과
성능 테스트 결과는 아래 표와 같습니다.
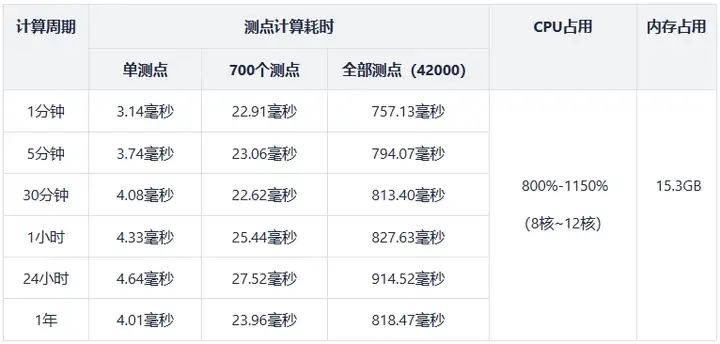
참고: 위 표에서 모든 측정 지점에 대한 계산 시간은 시간 창에서 모든 측정 지점의 지표를 계산하는 시간입니다. 단일/다중 측정 지점에 대한 계산 시간은 선택한 측정 지점의 지표를 계산하는 시간입니다. 시간 창의 포인트.
4. 요약
이 튜토리얼의 연구와 실습을 통해 우리는 경량 실시간 데이터 웨어하우스를 구축하는 DolphinDB의 강력한 기능을 심층적으로 이해하게 되었습니다. 고성능, 분산 및 실시간 컴퓨팅 특성을 갖춘 DolphinDB는 다양한 산업에 대규모 데이터에 대한 복잡한 지표의 저지연 계산 및 분석을 신속하게 실현할 수 있는 강력한 도구를 제공합니다.
실제적인 운영을 통해 DolphinDB의 사용 용이성과 효율성을 경험할 수 있습니다. 데이터 가져오기, 데이터 쿼리 또는 복잡한 스트리밍 계산 등 DolphinDB는 간결하고 명확한 구문과 강력한 기능을 제공합니다. 첨부파일에 제공된 스크립트에는 DolphinDB의 기본적인 사용법과 운영 방법이 포함되어 있을 뿐만 아니라 실시간 데이터 웨어하우스의 구축 원리와 응용 시나리오에 대한 심층적인 이해를 제공합니다. 이를 통해 비즈니스 요구를 충족하고 다양하고 복잡한 분석 요구에 실시간으로 대응하는 실시간 데이터 웨어하우스를 신속하게 구축할 수 있습니다.
마지막으로 독자들이 이 튜토리얼의 샘플 코드를 자신의 비즈니스 특성과 결합하여 가볍고 고성능의 실시간 데이터 웨어하우스를 구축할 수 있기를 바랍니다. 실제 애플리케이션에서 DolphinDB의 잠재력은 에너지 및 전력, 석유화학 산업, 지능형 제조, 항공우주, 차량 인터넷, 금융 및 기타 산업 등 다양한 산업 분야에서 지속적으로 탐구되고 있습니다. 시간 데이터 창고.
5. 액세서리
테스트 결과는 다음 스크립트를 통해 DolphinDB 서버에서 재현할 수 있습니다.
def clearEnv(){
//取消订阅
unsubscribeTable(tableName=`inputStream, actionName="dispatch1")
unsubscribeTable(tableName=`inputStream, actionName="dispatch2")
unsubscribeTable(tableName=`oneMinuteResult, actionName="calcHalfHour")
unsubscribeTable(tableName=`oneMinuteResult, actionName="calcOneHour")
unsubscribeTable(tableName=`fiveMinuteResult, actionName="calcOneDay")
unsubscribeTable(tableName = `oneDayResultSimulate,actionName=`calcOneYear)
unsubscribeTable(tableName = `oneMinuteResult,actionName=`appendInToDFS)
unsubscribeTable(tableName = `fiveMinuteResult,actionName=`appendInToDFS)
unsubscribeTable(tableName = `halfHourResult,actionName=`appendInToDFS)
unsubscribeTable(tableName = `oneHourResult,actionName=`appendInToDFS)
unsubscribeTable(tableName = `oneDayResult,actionName=`appendInToDFS)
unsubscribeTable(tableName = `oneYearResult,actionName=`appendInToDFS)
//删除流计算引擎
for(i in 1..2){
try{dropStreamEngine(`dispatchDemo+string(i))}catch(ex){print(ex)}
}
for(i in 1..5){
try{dropStreamEngine(`oneMinuteCalc+string(i))}catch(ex){print(ex)}
try{dropStreamEngine(`fiveMinuteCalc+string(i))}catch(ex){print(ex)}
}
try{dropStreamEngine(`halfHourCalc)}catch(ex){print(ex)}
try{dropStreamEngine(`oneHourCalc)}catch(ex){print(ex)}
try{dropStreamEngine(`oneDayCalc)}catch(ex){print(ex)}
try{dropStreamEngine(`oneYearCalc)}catch(ex){print(ex)}
//删除流数据表
try{dropStreamTable(`inputStream)}catch(ex){print(ex)}
try{dropStreamTable(`oneMinuteResult)}catch(ex){print(ex)}
try{dropStreamTable(`fiveMinuteResult)}catch(ex){print(ex)}
try{dropStreamTable(`halfHourResult)}catch(ex){print(ex)}
try{dropStreamTable(`oneHourResult)}catch(ex){print(ex)}
try{dropStreamTable(`oneDayResult)}catch(ex){print(ex)}
try{dropStreamTable(`oneDayResultSimulate)}catch(ex){print(ex)}
try{dropStreamTable(`oneYearResult)}catch(ex){print(ex)}
}
def createStreamTable(){
//定义输入流表
enableTableShareAndPersistence(table = streamTable(1000:0,`Time`deviceId`value,`TIMESTAMP`SYMBOL`DOUBLE),
tableName = `inputStream,cacheSize = 1000000,precache=1000000)
colName = `Time`deviceId`filterTime`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last`endTime
colType = `TIMESTAMP`SYMBOL`NANOTIMESTAMP join take(`DOUBLE,10) join `NANOTIMESTAMP
//定义1分钟窗口计算结果流表
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `oneMinuteResult,cacheSize = 1000000,precache=1000000)
//定义5分钟窗口计算结果流表
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `fiveMinuteResult,cacheSize = 1000000,precache=1000000)
//定义30分钟窗口计算结果流表
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `halfHourResult,cacheSize = 1000000,precache=1000000)
//定义1小时窗口计算结果流表
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `oneHourResult,cacheSize = 1000000,precache=1000000)
//定义24小时窗口计算结果流表
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `oneDayResult,cacheSize = 1000000,precache=1000000)
//定义模拟24小时窗口计算结果流表
colName = `TIME`deviceId`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last
colType = `DATE`SYMBOL join take(`DOUBLE,10)
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `oneDayResultSimulate,cacheSize = 1000000,precache=1000000)
//定义1年窗口计算结果流表
colName = `Time`deviceId`filterTime`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last`endTime
colType = `DATE`SYMBOL`NANOTIMESTAMP join take(`DOUBLE,10) join `NANOTIMESTAMP
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `oneYearResult,cacheSize = 1000000,precache=1000000)
}
def createDFS(){
//创建存储计算1分钟窗口计算结果表
if(existsDatabase("dfs://oneMinuteCalc")){dropDatabase("dfs://oneMinuteCalc")}
db1 = database(, VALUE,2023.01.01..2023.01.03)
db2 = database(, HASH,[SYMBOL,20])
db = database(directory="dfs://oneMinuteCalc", partitionType=COMPO, partitionScheme=[db1,db2],engine="TSDB")
colName = `Time`deviceId`filterTime`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last`endTime
colType = `TIMESTAMP`SYMBOL`NANOTIMESTAMP join take(`DOUBLE,10) join `NANOTIMESTAMP
t = table(1:0,colName,colType)
pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time","deviceId"],
sortColumns =["deviceId","Time"],compressMethods={Time:"delta"})
//创建存储计算5分钟窗口计算结果表
if(existsDatabase("dfs://fiveMinuteCalc")){dropDatabase("dfs://fiveMinuteCalc")}
db = database(directory="dfs://fiveMinuteCalc", partitionType=VALUE,
partitionScheme=2023.01.01..2023.01.03,engine="TSDB")
t = table(1:0,colName,colType)
pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time"],
sortColumns =["deviceId","Time"],compressMethods={Time:"delta"},
sortKeyMappingFunction=[hashBucket{,100}])
//创建存储计算30分钟窗口计算结果表
if(existsDatabase("dfs://halfHourCalc")){dropDatabase("dfs://halfHourCalc")}
db = database(directory="dfs://halfHourCalc", partitionType=VALUE,
partitionScheme=2023.01.01..2023.01.03,engine="TSDB")
t = table(1:0,colName,colType)
pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time"],
sortColumns =["deviceId","Time"],compressMethods={Time:"delta"})
//创建存储计算1小时窗口计算结果表
if(existsDatabase("dfs://oneHourCalc")){dropDatabase("dfs://oneHourCalc")}
db = database(directory="dfs://oneHourCalc", partitionType=VALUE,
partitionScheme=2023.01.01..2023.01.03,engine="TSDB")
t = table(1:0,colName,colType)
pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time"],
sortColumns =["deviceId","Time"],compressMethods={Time:"delta"})
//创建存储计算24小时窗口计算结果表
if(existsDatabase("dfs://oneDayCalc")){dropDatabase("dfs://oneDayCalc")}
db = database(directory="dfs://oneDayCalc", partitionType=VALUE,
partitionScheme=2023.01.01..2023.01.03,engine="TSDB")
t = table(1:0,colName,colType)
pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time"],
sortColumns =["deviceId","Time"],compressMethods={Time:"delta"})
//创建存储计算1年窗口计算结果表
if(existsDatabase("dfs://oneYearCalc")){dropDatabase("dfs://oneYearCalc")}
db = database(directory="dfs://oneYearCalc", partitionType=VALUE,
partitionScheme=2023.01.01..2023.01.03,engine="TSDB")
t = table(1:0,colName,colType)
pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time"],
sortColumns =["deviceId","Time"],compressMethods={Time:"delta"})
}
//1分钟窗口计算过滤函数
def filter1(msg){
t = select *,now(true) as filterTime from msg
getStreamEngine(`dispatchDemo1).append!(t)
}
//5分钟窗口计算过滤函数
def filter2(msg){
t = select *,now(true) as filterTime from msg
getStreamEngine(`dispatchDemo2).append!(t)
}
//30分钟窗口计算过滤函数
def filter3(msg){
t = select *,now(true) as filterTime2 from msg
getStreamEngine(`halfHourCalc).append!(t)
}
//1小时窗口计算
def filter4(msg){
t = select *,now(true) as filterTime2 from msg
getStreamEngine(`oneHourCalc).append!(t)
}
//24小时窗口计算
def filter5(msg){
t = select *,now(true) as filterTime2 from msg
getStreamEngine(`oneDayCalc).append!(t)
}
clearEnv();
createStreamTable();
createDFS();
schemas1 = table(1:0,`Time`deviceId`value`filterTime,`TIMESTAMP`SYMBOL`DOUBLE`NANOTIMESTAMP)
metrics1 = <[first(filterTime),max(value),min(value),mean(value),med(value),percentile(value,95),
percentile(value,5),last(value)-first(value),
(last(value)-first(value))/first(value),first(value),last(value),now(true)]>
//创建1分钟窗口聚合计算引擎
for(i in 1..5){
engine1 = createTimeSeriesEngine(name="oneMinuteCalc"+string(i), windowSize=60000, step=60000,
metrics=metrics1 , dummyTable=schemas1 , outputTable=objByName(`oneMinuteResult),
timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)
}
//创建5分钟窗口聚合计算引擎
for(i in 1..5){
engine2 = createTimeSeriesEngine(name="fiveMinuteCalc"+string(i), windowSize=300000, step=300000,
metrics=metrics1 , dummyTable=schemas1 , outputTable=objByName(`fiveMinuteResult),
timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)
}
//1分钟、5分钟窗口聚合计算分发引擎
dispatchEngine1=createStreamDispatchEngine(name="dispatchDemo1", dummyTable=schemas1, keyColumn=`deviceId,
outputTable=[getStreamEngine("oneMinuteCalc1"),getStreamEngine("oneMinuteCalc2"),
getStreamEngine("oneMinuteCalc3"),getStreamEngine("oneMinuteCalc4"),
getStreamEngine("oneMinuteCalc5")])
dispatchEngine2=createStreamDispatchEngine(name="dispatchDemo2", dummyTable=schemas1, keyColumn=`deviceId,
outputTable=[getStreamEngine("fiveMinuteCalc1"),getStreamEngine("fiveMinuteCalc2"),
getStreamEngine("fiveMinuteCalc3"),getStreamEngine("fiveMinuteCalc4"),
getStreamEngine("fiveMinuteCalc5")])
colName = `Time`deviceId`filterTime`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last`endTime`filterTime2
colType = `TIMESTAMP`SYMBOL`NANOTIMESTAMP join take(`DOUBLE,10) join `NANOTIMESTAMP`NANOTIMESTAMP
schemas2 = table(1:0,colName,colType)
metrics2 = <[first(filterTime2),max(MAX),min(MIN),mean(MEAN),med(MED),avg(P95),avg(P5),last(last)-first(first),
(last(last)-first(first))/first(first),first(first),last(last),now(true)]>
//创建30分钟窗口聚合计算引擎
engine3 = createTimeSeriesEngine(name="halfHourCalc", windowSize=1800000, step=1800000, metrics=metrics2 ,
dummyTable=schemas2 , outputTable=objByName(`halfHourResult),
timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)
//创建1小时窗口聚合计算引擎
engine4 = createTimeSeriesEngine(name="oneHourCalc", windowSize=3600000, step=3600000, metrics=metrics2 ,
dummyTable=schemas2 , outputTable=objByName(`oneHourResult),
timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)
//创建24小时窗口聚合计算引擎
engine5 = createTimeSeriesEngine(name="oneDayCalc", windowSize=86400000, step=86400000,
metrics=metrics2 , dummyTable=schemas2 , outputTable=objByName(`oneDayResult),
timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)
//订阅
subscribeTable(tableName=`inputStream, actionName="dispatch1", handler=filter1, msgAsTable = true,
batchSize = 10240)
subscribeTable(tableName=`inputStream, actionName="dispatch2", handler=filter2, msgAsTable = true,
batchSize = 10240)
subscribeTable(tableName=`oneMinuteResult, actionName="calcHalfHour", handler=filter3,
msgAsTable = true,batchSize = 10240)
subscribeTable(tableName=`oneMinuteResult, actionName="calcOneHour", handler=filter4,
msgAsTable = true,batchSize = 10240)
subscribeTable(tableName=`fiveMinuteResult, actionName="calcOneDay", handler=filter5,
msgAsTable = true,batchSize = 10240)
subscribeTable(tableName = `oneMinuteResult,actionName=`appendInToDFS,offset=0,
handler=loadTable("dfs://oneMinuteCalc","test"),
msgAsTable=true,batchSize=10240)
subscribeTable(tableName = `fiveMinuteResult,actionName=`appendInToDFS,offset=0,
handler=loadTable("dfs://fiveMinuteCalc","test"),
msgAsTable=true,batchSize=10240)
subscribeTable(tableName = `halfHourResult,actionName=`appendInToDFS,offset=0,
handler=loadTable("dfs://halfHourCalc","test"),
msgAsTable=true,batchSize=10240)
subscribeTable(tableName = `oneHourResult,actionName=`appendInToDFS,offset=0,
handler=loadTable("dfs://oneHourCalc","test"),
msgAsTable=true,batchSize=10240)
subscribeTable(tableName = `oneDayResult,actionName=`appendInToDFS,offset=0,
handler=loadTable("dfs://oneDayCalc","test"),
msgAsTable=true,batchSize=10240)
def filter6(msg){
tmp = select * ,now(true) as filterTime from msg
getStreamEngine(`oneYearCalc).append!(tmp)
}
colName = `Time`deviceId`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last`filterTime
colType = `DATE`SYMBOL join take(`DOUBLE,10) join `NANOTIMESTAMP
schemas3 = table(1:0,colName,colType)
metrics3 = <[last(filterTime),max(MAX),min(MIN),mean(MEAN),med(MED),avg(P95),avg(P5),last(last)-first(first),
(last(last)-first(first))/first(first),first(first),last(last),now(true)]>
engine6 = createTimeSeriesEngine(name="oneYearCalc", windowSize=365, step=1, metrics=metrics3 ,
dummyTable=schemas3 , outputTable=objByName(`oneYearResult),
timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)
subscribeTable(tableName = `oneDayResultSimulate,actionName=`calcOneYear, handler=filter6,
msgAsTable = true,batchSize = 10240)
subscribeTable(tableName = `oneYearResult,actionName=`appendInToDFS,offset=0,
handler=loadTable("dfs://oneYearCalc","test"),
msgAsTable=true)
deviceIdList = lapd(string(rand(10000,700)),6,"0") //测点id
//模拟数据的函数,一共模拟1小时的数据
def simulateData(deviceIdList){
num = deviceIdList.size()
startTime = timestamp(2023.01.01)
do{
Time = take(startTime,num)
deviceId = deviceIdList
value = rand(100.0,num)
objByName(`inputStream).append!(table(Time,deviceId,value))
startTime = startTime+1000
sleep(100)
}while(startTime<=2023.01.02T00:00:10.000)
}
def simulateOneDay(deviceIdList){
num = deviceIdList.size()
startTime =2022.01.01
do{
Time = take(startTime,num)
deviceId = deviceIdList
MAX = rand(100.0,num)
MIN = rand(100.0,num)
MEAN = rand(100.0,num)
MED = rand(100.0,num)
P95 = rand(100.0,num)
P5 = rand(100.0,num)
CHANGE = rand(100.0,num)
CHANGE_RATE = rand(100.0,num)
first = rand(100.0,num)
last = rand(100.0,num)
tmp = table(Time,deviceId,MAX,MIN,MEAN,MED,P95,P5,CHANGE,CHANGE_RATE,first,last)
objByName(`oneDayResultSimulate).append!(tmp)
startTime = startTime+1
sleep(500)
}while(startTime<=2023.12.31)
}
submitJob("simulateData","write",simulateData,deviceIdList)
submitJob("simulateOneDay","write",simulateOneDay,deviceIdList)
//耗时统计
tmp1 = select Time,deviceId,filterTime,endTime from loadTable("dfs://oneYearCalc","test") order by Time,deviceId
tmp2 = select Time,deviceId,next(filterTime) as startTime,endTime from tmp1 context by deviceId
select avg(endTime-startTime)\1000\1000 as timeUsed from tmp2 group by deviceId //统计单个测点的计算耗时
tmp3 = select min(startTime) as st,max(endTime) as dt from tmp2 group by Time
select (dt-st)\1000\1000 as used from tmp3 //统计整个时间窗口的计算耗时