
편집자 주: 저자가 어머니에게 LLM을 사용하여 작업을 완료하는 방법을 가르치려고 할 때 프롬프트 단어 최적화가 상상만큼 간단하지 않다는 것을 깨달았습니다. 프롬프트 단어의 자동 최적화는 모델에 제공된 프롬프트 단어를 조정하고 개선할 충분한 경험이 없는 경험이 부족한 프롬프트 단어 작성자에게 유용하며 , 이로 인해 자동화된 프롬프트 단어 최적화 도구에 대한 추가 탐색이 촉발되었습니다.
이 글의 저자는 프롬프트 워드 엔지니어링의 본질을 두 가지 관점에서 분석합니다. 하이퍼파라미터 최적화의 일부로 볼 수도 있고, 끊임없는 시도와 조정이 필요한 탐색, 시행착오, 수정의 과정으로 볼 수도 있습니다. .
저자는 수학적 문제 해결, 감정 분류, SQL 문 생성 등과 같이 비교적 명확한 모델 입력 및 출력이 있는 작업의 경우 저자는 이 경우 프롬프트 단어 엔지니어링이 기계 학습의 하이퍼 매개변수를 조정하는 것처럼 "매개변수"를 최적화하는 것과 비슷하다고 믿습니다. 우리는 자동화된 방법을 사용하여 다양한 프롬프트 단어를 지속적으로 시도하여 어떤 단어가 가장 효과적인지 확인할 수 있습니다. 이메일 쓰기, 시 쓰기, 기사 요약 쓰기 등과 같이 상대적으로 주관적이고 모호한 작업에 사용됩니다. 출력이 "올바른"지 판단하는 흑백 표준이 없기 때문에 프롬프트 단어의 최적화는 간단하고 기계적으로 수행될 수 없습니다.
원본 기사 링크: https://towardsdatascience.com/automated-prompt-engineering-78678c6371b9
LinkedIn 프로필 링크: https://linkedin.com/in/ianhojy
구독을 위한 미디엄 프로필 링크: https://ianhojy.medium.com/
저자 |
편집됨 | 양유에
지난 몇 달 동안 저는 다양한 LLM 기반 앱을 구축하려고 노력해 왔습니다. 솔직히 말해서 저는 LLM에서 원하는 결과를 얻으려면 프롬프트를 개선하는 데 많은 시간을 소비합니다.
나는 과연 영광스러운 프롬프트 엔지니어였는가 하는 의문이 들 정도로 공허함과 혼란 속에 갇혀 있을 때가 많았다. LLM(대형 언어 모델)과의 인간 상호 작용의 현재 상태를 고려할 때 나는 여전히 "아직"이라는 결론을 내리는 경향이 있으며 대부분의 밤에 가면 증후군을 극복할 수 있습니다. (번역자 주: 자신의 성취와 능력에 대해 회의적인 개인을 가리키는 심리적 현상입니다. 그들은 종종 자신이 거짓말쟁이라고 느끼고, 자신이 성취한 성취를 가질 자격이 없거나 성취할 가치가 없다고 믿으며, 노출될까봐 걱정됩니다.) 현재로서는 이 문제에 대해 심도있게 논의하지 않겠습니다.
하지만 언젠가는 Prompt 작성 과정이 기본적으로 자동화될 수 있을지 여전히 궁금합니다. 이 질문에 답하는 방법은 프롬프트 엔지니어링의 본질을 파악할 수 있는지 여부에 달려 있습니다.
광대한 인터넷에는 셀 수 없이 많은 프롬프트 엔지니어링 플레이북이 있지만 프롬프트 엔지니어링이 예술인지 과학인지는 여전히 판단할 수 없습니다.
한편으로는 모델 출력에서 관찰한 내용을 바탕으로 작성한 프롬프트를 반복적으로 배우고 다듬어야 하는 것이 예술처럼 느껴집니다 . 시간이 지나면서 저는 "should" 대신 "must"를 사용하거나 지침 권장 사항이나 사양을 프롬프트 단어 중간이 아닌 끝에 추가하는 등 작은 세부 사항이 중요하다는 사실을 깨달았습니다. 작업에 따라 일련의 지시와 지침을 표현할 수 있는 방법이 너무 많아 때로는 끊임없는 시행착오처럼 느껴지고 실수도 하게 됩니다.
반면에 프롬프트 단어는 단지 하이퍼 매개 변수라고 생각할 수도 있습니다. 궁극적으로 LLM(Large Language Model)은 실제로 모든 하이퍼파라미터와 마찬가지로 우리가 작성한 프롬프트 단어만 임베딩으로 처리합니다. 기계 학습 모델을 훈련하고 테스트하기 위해 준비되고 승인된 데이터 세트가 있으면 프롬프트 단어를 조정하고 그 성능을 객관적으로 평가할 수 있습니다. 최근 HuggingFace[1]의 ML 엔지니어인 Moritz Laurer의 게시물을 보았습니다.
데이터에 대해 다른 프롬프트를 테스트할 때마다 LLM이 실제로 보이지 않는 데이터로 일반화되는지 여부에 대한 확신이 약해집니다. 별도의 검증 분할을 사용하여 LLM의 주요 하이퍼 매개변수(프롬프트)를 조정하는 것은 훈련-평가-테스트만큼 중요합니다. 미세 조정을 위해 분할합니다. 유일한 차이점은 더 이상 교육 데이터 세트가 없으며 교육/매개변수 업데이트가 없기 때문에 왠지 다르게 느껴진다는 것입니다. 실제로는 데이터에 대한 프롬프트를 과대적합했지만 LLM이 작업을 잘 수행한다고 믿도록 속이기 쉽습니다. 모든 좋은 "제로샷" 논문은 최종 테스트 전에 프롬프트를 찾기 위해 검증 분할을 사용했음을 명확히 해야 합니다.
이러한 데이터 세트에 대해 점점 더 다양한 프롬프트 단어(프롬프트)를 테스트함에 따라 LLM이 실제로 보이지 않는 데이터를 일반화할 수 있는지 여부가 점점 더 불확실해집니다... 데이터 세트의 일부를 격리하여 주요 하이퍼 매개변수를 조정하는 검증 세트로 설정합니다. (프롬프트) 학습-평가-테스트 분할(번역자 참고 사항: 사용 가능한 데이터 세트를 훈련 세트, 검증 세트 및 테스트 세트의 세 부분으로 나눕니다.) 방법을 사용하여 진행하는 것도 마찬가지로 중요합니다. 유일한 차이점은 이 프로세스에는 모델 훈련(훈련 없음) 또는 모델 매개변수 업데이트(매개변수 업데이트 없음)가 포함되지 않고 검증 세트에서 다양한 프롬프트 단어의 성능만 평가한다는 점입니다. 실제로 조정된 큐 단어가 이 현재 데이터 세트에서 매우 잘 수행될 수 있지만 적용할 수 없는 더 광범위하거나 보이지 않는 데이터 세트에서는 잘 수행되지 않을 수 있는 경우 LLM이 대상 작업에서 잘 작동한다고 믿기 쉽습니다. 모든 좋은 "제로샷" 문서에는 최종 테스트 전에 최상의 프롬프트를 찾는 데 도움이 되는 검증 세트를 사용한다는 점을 명확하게 명시해야 합니다.
잠시 생각해보면 답은 그 사이 어딘가에 있을 것 같습니다. 프롬프트 엔지니어링이 과학인지 예술인지는 우리가 LLM이 무엇을 하길 원하는지에 달려 있습니다. 우리는 지난 한 해 동안 LLM이 놀라운 일을 많이 하는 것을 보았습니다. 그러나 저는 대형 모델을 사용하려는 사람들의 의도를 문제 해결과 창의적인 작업 완료(창작)라는 두 가지 광범위한 범주로 분류하는 경향이 있습니다.
문제 해결 측면에서는 LLM이 수학 문제 해결, 감정 분류, SQL 문 생성, 텍스트 번역 등을 수행합니다. 일반적으로 이러한 작업은 상대적으로 명확한 입력-출력 쌍을 가질 수 있기 때문에 모두 함께 그룹화될 수 있다고 생각합니다(역자 주: 입력 데이터와 해당 모델 출력 데이터 간의 연관성)(따라서 우리는 다음을 사용하는 경우를 많이 볼 수 있습니다). 소수의 프롬프트만이 목표 작업을 매우 잘 수행할 수 있습니다. 잘 정의된 학습 데이터를 사용하는 이러한 종류의 작업(역자 주: 학습 데이터 세트의 입력과 출력 간의 관계는 명확하고 명확함)의 경우 프롬프트 엔지니어링이 나에게는 과학처럼 보입니다. 따라서 이 글의 전반부는 프롬프트를 하이퍼파라미터로 논의하고 , 특히 자동화된 프롬프트 엔지니어링의 연구 진행 상황을 탐구합니다(역자 주: 자동화된 방법이나 기술을 사용하여 프롬프트 단어를 설계, 최적화 및 조정).
창의적인 업무 측면에서 LLM에 필요한 업무는 더 주관적이고 모호합니다. 이메일, 보고서, 시, 초록을 작성하세요. 여기서 우리는 더 모호한 상황에 직면하게 됩니다. ChatGPT의 글 내용이 비개인적인 것입니까? (내가 작성한 수천 개의 기사를 바탕으로 현재 내 의견은 '그렇다'입니다.) 그리고 LLM이 어떻게 대응하기를 원하는지에 대한 보다 객관적인 기준이 부족한 경우가 많기 때문에 창의적인 작업의 성격과 요구 사항이 적절하지 않은 경우가 많습니다. 큐 단어를 하이퍼파라미터처럼 조정하고 최적화할 수 있는 매개변수로 생각하는 것입니다.
이 시점에서 어떤 사람들은 창의적인 작업을 하려면 상식만 사용하면 된다고 말할 수도 있습니다. 솔직히 말해서, 어머니에게 ChatGPT를 사용하여 업무용 이메일을 생성하는 방법을 가르치기 전까지 나도 그렇게 생각했습니다. 이러한 경우 프롬프트 엔지니어링은 여전히 일회성 완료가 아닌 지속적인 실험과 조정을 통한 개선에 중점을 두고 있으므로 어떻게 자신의 아이디어를 활용하여 Prompt를 개선하면서도 Prompt의 보편성을 유지할 수 있습니까? ), 항상 명확한 것은 아닙니다.
어쨌든, 대규모 모델 생성 사례에 대한 사용자 피드백을 기반으로 프롬프트를 자동으로 개선할 수 있는 도구를 찾았지만 아무 것도 발견하지 못했습니다. 따라서 저는 실현 가능한 솔루션이 존재하는지 알아보기 위해 그러한 도구의 프로토타입을 만들었습니다. 이 기사 후반부에서는 실시간 사용자 피드백을 기반으로 프롬프트 단어를 자동으로 개선하는 실험적인 도구를 공유하겠습니다.
01 1부 - 해결자로서의 LLM: 프롬프트 엔지니어링을 하이퍼파라미터 최적화의 일부로 처리
업계의 많은 사람들은 "Large Language Models are Zero-Shot Reasoners"[2] 기사에서 유명한 "Zero-Shot-COT" 용어에 익숙합니다. (역자 주: 모델은 특정 작업에 대한 명시적 훈련 데이터를 학습하지 않았습니다. 다음으로 기존 지식을 결합하여 새로운 문제를 해결합니다. Zhou et al.(2022)은 "대형 언어 모델은 인간 수준의 프롬프트 엔지니어입니다"라는 기사에서 더 자세히 살펴보기로 결정했습니다. [3] 개선된 버전은 무엇입니까? —— "올바른 답을 얻을 수 있도록 단계별로 이 문제를 해결해 봅시다." 다음은 그들이 제안한 자동 프롬프트 엔지니어 방법의 개요입니다.
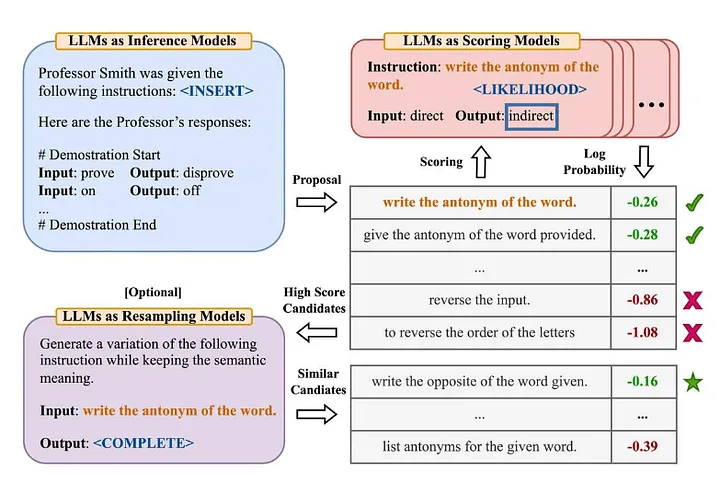
출처: 대규모 언어 모델은 인간 수준의 프롬프트 엔지니어입니다[3]
이 문서를 요약하면 다음과 같습니다.
- LLM을 사용하여 주어진 입력-출력 쌍을 기반으로 후보 지침 프롬프트를 생성합니다(번역자 참고 사항: 입력 데이터와 해당 모델 출력 데이터 간의 연관성).
- LLM을 사용하여 지침을 사용하여 생성된 답변이 예상 답변과 얼마나 잘 일치하는지 또는 지침으로 얻은 모델 응답을 기반으로 로그 확률을 평가하여 각 지침 프롬프트에 점수를 매깁니다.
- 높은 점수를 받은 후보자 지도 프롬프트어(지침)를 기반으로 새로운 후보자 지도 프롬프트어를 반복적으로 생성한다.
몇 가지 흥미로운 결론이 발견되었습니다.
- (인간 프롬프트 엔지니어) 및 이전에 제안된 알고리즘의 우수한 성능을 입증하는 것 외에도 저자는 다음과 같이 언급합니다 . 작은 샘플(몇 장의 샷)의 경우 "
- 반복적인 몬테카를로 탐색 알고리즘(Monte Carlo Search)의 효과는 대부분의 경우 점차 약화되지만, 원래의 제안 공간(번역자 주: 초기에 후보 생성에 사용된 몬테카를로 탐색 알고리즘을 참조할 수 있음)이 실행될 때 잘 수행됩니다. 문제의 초기 범위나 해결책이 적합하지 않거나 충분히 효과적이지 않습니다.
그러다가 2023년에 Google DeepMind의 일부 연구원은 "OPRO(Optimisation by Prompting)"라는 방법을 출시했습니다. 이전 예와 유사하게 메타 프롬프트에는 일련의 입력/출력 쌍이 포함되어 있습니다(번역자 참고 사항: 특정 작업 또는 문제 출력 조합을 설명하는 입력 및 기대치). 여기서 주요 차이점은 메타 프롬프트에는 이전에 훈련된 프롬프트 단어 샘플과 정답 또는 솔루션, 모델이 이러한 프롬프트 단어에 얼마나 정확하게 응답했는지, 그리고 메타 프롬프트 안내 단어의 여러 부분 간의 차이점이 자세히 설명되어 있다는 것입니다. 관계를 위해.
저자가 설명했듯이 연구 작업의 각 단서 최적화 단계는 모델이 현재 작업을 더 잘 이해하고 보다 정확한 출력 결과를 생성할 수 있도록 이전 학습 궤적을 참조하는 것을 목표로 새로운 단서를 생성합니다.
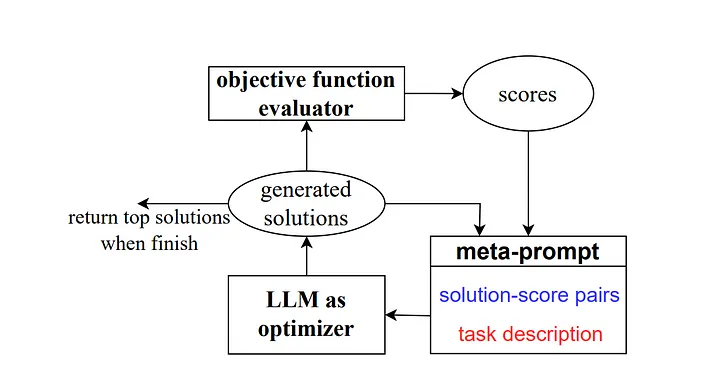
출처: 최적화 도구로서의 대규모 언어 모델[4]
Zero-Shot-COT 시나리오에서는 "심호흡을 하고 이 문제를 단계별로 해결해 보세요"라는 프롬프트 단어 최적화 방법을 제안하여 좋은 결과를 얻었습니다.
나는 이것에 대해 몇 가지 생각을 가지고 있습니다:
- “다양한 유형의 언어 모델에서 생성된 교육 프롬프트의 스타일은 매우 다양합니다. PaLM 2-L-IT 및 text-bison과 같은 일부 모델은 매우 간결하고 명확한 교육 프롬프트를 생성하는 반면, GPT와 같은 다른 모델은 길고 길고 매우 상세합니다. "이것은 우리의 관심을 끌 만한 가치가 있습니다. 현재 시중에 나와 있는 많은 프롬프트 엔지니어링 방법은 OpenAI의 언어 모델을 참조 개체로 사용하여 작성되었습니다. 그러나 다양한 소스의 모델이 점점 더 많이 사용되기 시작하면 이러한 일반적인 프롬프트 단어에 주의해야 합니다. 글쎄요. 지침의 작은 변화에 대한 모델 성능의 높은 민감도를 보여주는 예가 논문의 섹션 5.2.3에 나와 있습니다. 우리는 이것에 더 많은 관심을 기울일 필요가 있습니다.
예를 들어 GSM8K 테스트 세트에서 모델을 평가하기 위해 PaLM 2-L을 사용했을 때 '단계적으로 생각해 보자'의 정확도는 71.8%, '함께 문제를 해결하자'의 정확도는 60.5%에 이르렀다. 처음 두 명령 단어의 의미 조합인 "이 문제를 단계별로 해결하기 위해 함께 노력하자"는 정확도가 49.4%에 불과합니다.
이 동작은 단일 단계 지침과 최적화 프로세스 중에 발생하는 변동을 모두 증가시켜 최적화 프로세스의 안정성을 향상시키기 위해 각 단계에서 여러 단일 단계 지침을 생성하도록 유도합니다.
또 다른 중요한 점은 논문의 결론에 언급되어 있습니다. "실제 문제에 대한 현재 알고리즘 적용의 한 가지 한계는 큐 단어를 최적화하는 데 사용되는 대규모 언어 모델이 추론을 위해 훈련 세트의 잘못된 사례를 효과적으로 활용하지 못한다는 것입니다. 유망한 실험에서는 각 최적화 단계에서 훈련 세트에서 무작위로 샘플링하는 대신 모델을 훈련하거나 메타 프롬프트에서 테스트할 때 발생하는 오류 사례를 추가하려고 시도했지만 결과는 유사하여 이러한 오류 사례에 대한 정보의 양은 옵티마이저 LLM(프롬프트 단어를 최적화하는 데 사용되는 대규모 언어 모델)이 잘못된 예측의 이유를 이해하는 데 충분하지 않습니다. 프롬프트 단어의 최적화 프로세스 기존 ML/AI의 하이퍼파라미터 최적화 프로세스와 유사하지만 LLM에 제공할 콘텐츠 입력의 종류 또는 LLM을 안내하는 방법에 관계없이 긍정적이고 긍정적인 예를 사용하는 것을 선호하는 경향이 있습니다. 프롬프트 단어를 향상시킵니다. 그러나 기존 ML/AI에서는 일반적으로 이러한 선호도가 그다지 명확하지 않으며 오류 자체의 방향이나 유형에 너무 많은 주의를 기울이기보다는 오류 정보를 사용하여 모델을 최적화하는 방법에 더 중점을 둡니다(예: 우리는 -5에 초점을 맞추고 +5 오류는 대부분 동일하게 처리됩니다.
APE(Automated Prompt Engineering)에 관심이 있으신 분은 https://github.com/keirp/automatic_prompt_engineer 에 접속하셔서 다운로드 받아 사용하실 수 있습니다.
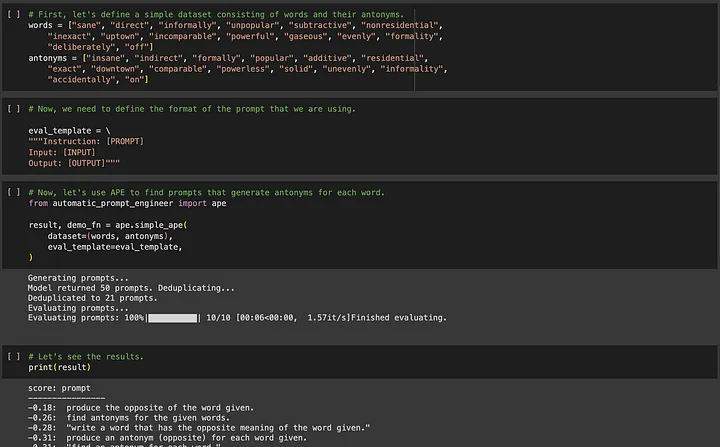
출처: APE용 예제 노트북의 스크린샷[5]
APE와 OPRO 두 가지 방법의 핵심 요구 사항은 최적화에 도움이 되는 훈련 데이터가 있어야 하며 데이터 세트는 최적화된 단서의 보편성을 보장할 만큼 충분히 커야 한다는 것입니다.
이제 저는 쉽게 사용할 수 있는 데이터가 없는 또 다른 유형의 LLM 작업에 대해 이야기하고 싶습니다.
02 2부 - 창조자로서의 LLM: Prompt Engineering을 끊임없이 노력하고 조정하여 점진적인 개선을 이루는 과정으로 생각하십시오.
이제 우리가 몇 가지 단편소설을 생각해낸다고 가정해 보세요.
모델을 훈련할 새로운 텍스트 예제가 없으며, 자격을 갖춘 소설 텍스트 예제를 작성하는 데 너무 오랜 시간이 걸립니다. 게다가, 수용 가능한 모델 출력 유형이 다양할 수 있기 때문에 대규모 모델 출력이 "소위 정답"을 출력하는 것이 타당한지 여부가 명확하지 않습니다. 따라서 이러한 유형의 작업에서는 프롬프트 단어 엔지니어링을 자동화하기 위해 APE와 같은 방법을 사용하는 것이 거의 비실용적입니다.
그러나 일부 독자들은 왜 프롬프트 단어 작성 과정을 자동화해야 하는지 궁금해할 수 있습니다. " {{issue}} in " 에 관한 3개의 짧은 이야기 아이디어 제공"과 같은 간단한 프롬프트 단어로 시작하고, {{country}}{{issue}}를 "inequality"로 채우고, {{country}}를 "Singapore"로 바꾸고, 모델을 관찰할 수 있습니다. 결과에 따라 문제를 발견하고 프롬프트 단어를 조정한 다음 조정이 효과적인지 관찰하는 과정을 반복합니다.
하지만 이 경우 큐 워드 엔지니어링으로 가장 많은 혜택을 받는 사람은 누구일까요? 프롬프트 단어 작성 경험이 없는 초보자 는 모델에 제공되는 프롬프트 단어를 조정하고 개선할 만큼 충분한 경험이 없습니다 . 나는 어머니에게 ChatGPT를 사용하여 작업을 완료하도록 가르쳤을 때 이것을 직접 경험했습니다.
우리 엄마는 ChatGPT의 결과에 대한 불만을 프롬프트 단어의 추가 개선으로 전달하는 데 능숙하지 않을 수도 있지만 프롬프트 단어 엔지니어링 기술이 아무리 훌륭하더라도 우리가 정말 잘하는 것은 문제를 명확하게 표현하는 것임을 깨달았습니다. (즉, 불평하는 능력)을 참조하십시오. 그래서 나는 사용자가 불만을 표현하는 데 도움이 되는 도구를 만들고 LLM이 우리를 위해 프롬프트 단어를 개선할 수 있도록 노력했습니다. 나에게는 이것이 상호 작용하는 더 자연스러운 방법인 것 같고 창의적인 작업에 LLM을 사용하려는 사람들이 더 쉽게 사용할 수 있는 것 같습니다.
이것은 단지 개념 증명일 뿐이라는 점을 미리 밝힙니다. 독자들에게 좋은 아이디어가 있으면 저자에게 자유롭게 공유해 주세요!
먼저 {{}} 변수를 사용하여 프롬프트 단어를 작성합니다. 이 도구는 위의 예를 다시 사용하여 나중에 채울 수 있도록 이러한 자리 표시자를 감지하여 대형 모델에 싱가포르의 불평등에 대한 창의적인 이야기를 출력하도록 요청합니다.
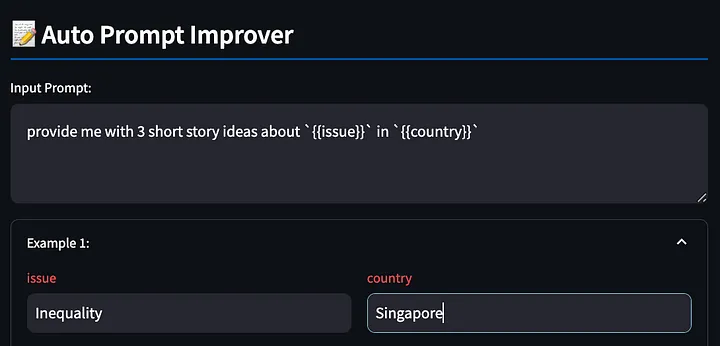
다음으로, 도구는 채워진 프롬프트 단어를 기반으로 모델 응답을 생성합니다.

그런 다음 피드백을 제공하십시오(모델 출력에 대한 불만 사항).
그런 다음 모델은 스토리 아이디어의 추가 예 생성을 중단하고 첫 번째 반복에서 개선된 단서 단어를 출력하도록 요청 받았습니다. 아래 제시된 프롬프트는 "이러한 과제를 극복하거나 참여하기 위한...전략 설명"을 요구하도록 개선되고 일반화되었습니다. 그리고 첫 번째 모델 출력에 대한 나의 피드백은 "이야기의 주인공이 불평등을 어떻게 해결하는지 이야기해달라"는 것이었습니다.

그런 다음 대형 모델에게 수정된 프롬프트 단어를 사용하여 단편 소설을 다시 생각해 보라고 요청했습니다.
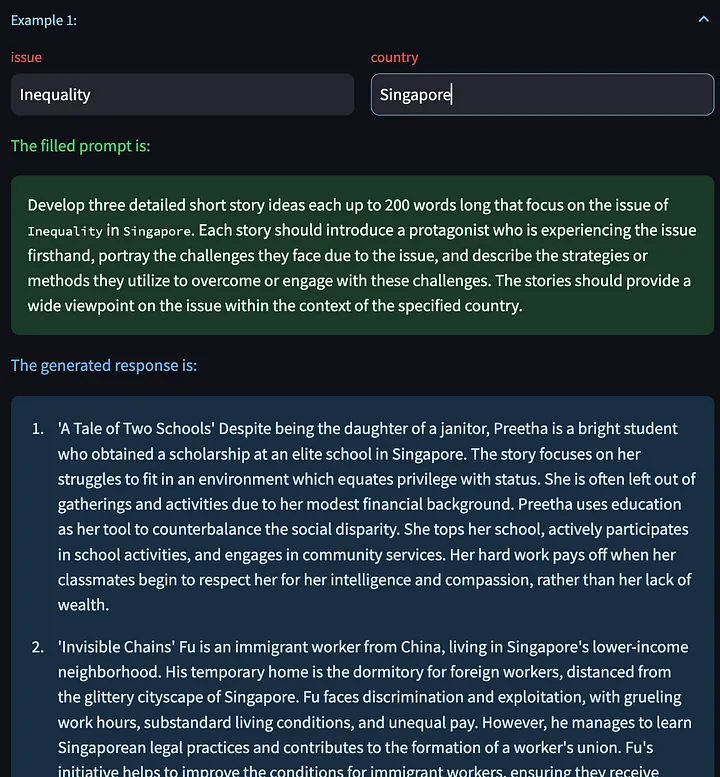
또한 다른 입력 변수를 기반으로 새로운 모델 응답을 생성할 수 있는 "다음 예제 생성"을 클릭할 수 있는 옵션도 있습니다. 다음은 중국의 해고 문제에 대해 생성된 몇 가지 창의적인 이야기입니다.
그런 다음 위 모델 출력에 대한 피드백을 제공합니다.
그런 다음 프롬프트 단어가 더욱 최적화되었습니다.

이번 최적화 결과는 꽤 좋아 보입니다. 결국 처음에는 단순한 프롬프트 단어였지만 2분도 채 안 되는 피드백 끝에 세 번의 반복 후에 최적화된 프롬프트 단어를 얻었습니다. 이제 우리는 단순히 앉아서 LLM 결과에 대한 불만을 표현함으로써 프롬프트 단어를 계속해서 최적화할 수 있습니다.
이 기능의 내부 구현은 메타 프롬프트에서 시작하여 사용자의 동적 피드백을 기반으로 새로운 프롬프트 단어를 지속적으로 최적화하고 생성하는 것입니다. 화려하지는 않으며 확실히 추가 개선의 여지가 있지만 좋은 시작입니다.
prompt_improvement_prompt = """
# Context #
You are given an original prompt.
The original prompt was used to generate some example responses. For each response, feedback was provided on how to improve the desired response.
Your task is to review all the feedback and then return an improved prompt that addresses the feedback, making it better at generating responses when prompted against the GPT language model.
# Guidelines #
- The original prompt will contain placeholders within double curly brackets. These are values for input that you will see in the examples.
- The improved prompt should not exceed 200 words
- Just return the improved prompt and nothing else before and after. Remember to include the same placeholders with double curly brackets.
- When generating the improved prompt, refrain from writing the entire prompt as one paragraph. Instead, you should use a combination of task descriptions, guidelines (in point form), and other sections to the prompt as appropriate.
- The guidelines should be in point form, and should not be a repetition of the task. The guidelines should also be distinct from one another.
- The improved prompt should be written in normal English that is best understood by the language model.
- Based on the feedback provided, you must rephrase the desired behavior of the response into `must`, imperative statements, instead of `should` suggestive statements.
- Improvements made to the prompt should not be overly specific to one single example.
# Details #
The original prompt is:
```
{original_prompt}
```
These are the examples that were provided and the feedback for each:
```
{examples}
```
The improved prompt is:
```
"""
이 도구를 사용하는 동안 관찰한 사항은 다음과 같습니다.
- GPT4는 텍스트를 생성할 때 많은 수의 단어를 사용하는 경향이 있습니다("다언어" 기능). 이러한 이유로 두 가지 효과가 있을 수 있습니다. 첫째, 이 "장황한" 속성은 특정 예에 대한 과적합을 조장할 수 있습니다 . ** LLM에 너무 많은 단어가 제공되면 사용자가 제공한 특정 피드백을 수정하는 데 해당 단어를 사용합니다. 둘째, 이러한 "언어적" 특성은 프롬프트 단어의 효율성을 손상시킬 수 있으며, 특히 긴 프롬프트 단어에서는 일부 중요한 안내 정보가 모호해질 수 있습니다. 첫 번째 문제는 사용자 피드백을 기반으로 모델이 일반화되도록 좋은 메타 프롬프트를 작성하면 해결될 수 있다고 생각합니다. 그러나 두 번째 문제는 더 어렵습니다. 다른 사용 사례에서는 프롬프트 단어가 너무 길면 지시 프롬프트가 무시되는 경우가 많습니다. 메타 프롬프트에 몇 가지 제한 사항을 추가 할 수 있습니다(예: 위에 제공된 프롬프트 예의 단어 수 제한) . 그러나 이는 실제로 임의적이며 프롬프트 단어의 일부 제한 사항이나 규칙은 기본 대형 모델의 영향을 받을 수 있습니다. 특정 속성이나 행동의 영향.
- 개선된 프롬프트 단어는 프롬프트 단어에 대한 이전 최적화를 잊어버리는 경우가 있습니다. 이 문제를 해결하는 한 가지 방법은 시스템에 더 긴 개선 내역을 제공하는 것이지만, 그렇게 하면 개선 프롬프트 단어가 너무 길어지게 됩니다.
- 첫 번째 반복에서 이 접근 방식의 한 가지 장점은 LLM이 사용자 피드백의 일부가 아닌 개선 사항에 대한 지침을 제공할 수 있다는 것입니다. 예를 들어, 위의 첫 번째 단어 최적화에서 제가 제공한 피드백은 단순히 신뢰할 수 있는 소스의 관련 통계에 대한 요청임에도 불구하고 도구는 "논의된 문제에 대한 더 넓은 관점을 제공합니다..."를 추가했습니다.
아직 이 도구를 배포하지 않은 이유는 메타 프롬프트에서 무엇이 가장 효과적인지 확인하고 일부 간소화된 프레임워크 문제를 해결한 다음 프로그램에서 발생할 수 있는 다른 오류나 예외를 처리하는 중이기 때문입니다. 하지만 도구가 곧 출시될 예정입니다!
03 결론
프롬프트 엔지니어링 전체 분야는 작업 해결을 위한 최상의 프롬프트 단어를 제공하는 데 중점을 둡니다. APE와 OPRO는 이 분야에서 가장 중요하고 뛰어난 사례이지만 모든 것을 대표하지는 않습니다. 우리는 앞으로 이 분야에서 얼마나 많은 진전을 이룰 수 있을지 기대하고 기대합니다. 다양한 모델에 대한 이러한 기술의 효과를 평가하면 해당 모델의 작업 경향이나 작업 특성을 밝힐 수 있으며 어떤 메타 프롬프트 기술이 효과적인지 이해하는 데도 도움이 될 수 있으므로 LLM을 사용하는 데 도움이 되는 매우 중요한 작업이라고 생각합니다. 우리의 일상적인 생산 관행에서.
그러나 이러한 방법은 창의적인 작업에 LLM을 사용하려는 다른 사람들에게는 적합하지 않을 수 있습니다. 현재로서는 시작하는 데 도움이 되는 기존 학습 매뉴얼이 많이 있지만 시행착오를 능가하는 것은 없습니다. 따라서 단기적으로 가장 가치 있는 것은 인간의 강점에 부합하는 이 실험 과정을 어떻게 효율적으로 완료하고(피드백 제공) 나머지는 LLM에 맡기는 것(즉각적인 단어 개선)이라고 생각합니다.
또한 POC(개념 증명)에 대해 더 많은 작업을 수행할 예정입니다. 이에 관심이 있으시면 저에게 연락해주세요( https://www.linkedin.com/in/ianhojy/) !
읽어 주셔서 감사합니다!
끝
참고자료
[1] https://www.linkedin.com/in/moritz-laurer/?originalSubdomain=de
[2] https://arxiv.org/pdf/2205.11916.pdf
[3] https://arxiv.org/pdf/2211.01910.pdf
[4] https://arxiv.org/pdf/2309.03409.pdf
[5] https://github.com/keirp/automatic_prompt_engineer
[6] https://arxiv.org/abs/2104.08691
[7] https://medium.com/mantisnlp/automatic-prompt-engineering-part-i-main-concepts-73f94846cacb
[8] https://www.promptingguide.ai/techniques/ape
이 기사는 Baihai IDP가 원저자의 승인을 받아 편집한 것입니다. 번역물을 재인쇄해야 하는 경우 당사에 연락하여 승인을 받으시기 바랍니다.
원본 링크:
https://towardsdatascience.com/automated-prompt-engineering-78678c6371b9
오픈 소스 Hongmeng을 포기하기로 결정했습니다 . 오픈 소스 Hongmeng의 아버지 Wang Chenglu: 오픈 소스 Hongmeng은 중국에서 유일하게 기초 소프트웨어 분야의 건축 혁신 산업 소프트웨어 행사입니다. OGG 1.0이 출시되고 Huawei는 모든 소스 코드를 제공합니다. 구글 리더가 '코드 똥산'에 죽는다 페도라 리눅스 40 정식 출시 전 마이크로소프트 개발자: 윈도우 11 성능이 ' 어처구니없을 정도로 나쁨' 마화텡과 저우홍이가 악수하며 '원한 해소' 유명 게임사들이 새로운 규정 발표 : 직원 결혼 선물은 100,000위안을 초과할 수 없습니다. Ubuntu 24.04 LTS 공식 출시 Pinduoduo는 부정 경쟁 혐의로 판결을 받았습니다. 보상금 500만 위안