
Spark 는 빠르고 다재다능하며 확장 가능한 빅 데이터 컴퓨팅 엔진 입니다 . 고성능, 사용 용이성, 내결함성, Hadoop 생태계와의 원활한 통합 및 높은 커뮤니티 활동이라는 장점이 있습니다. 실제 사용에서는 광범위한 응용 시나리오가 있습니다.
· 데이터 정리 및 전처리: 빅 데이터 분석 시나리오에서 데이터는 일반적으로 데이터 품질과 일관성을 보장하기 위해 정리 및 전처리 작업이 필요합니다. Spark는 데이터에 대한 정리, 필터링, 변환 및 기타 작업을 수행할 수 있는 풍부한 API를 제공합니다.
· 일괄 처리 분석: Spark는 통계 분석, 데이터 마이닝, 특징 추출 등 다양한 응용 시나리오의 일괄 처리 작업에 적합합니다. 사용자는 Spark의 강력한 API 및 내장 라이브러리를 사용하여 복잡한 데이터 처리 및 데이터 마이닝 분석을 수행할 수 있습니다. .
· 대화형 쿼리: Spark는 SQL 쿼리를 지원하는 Spark SQL 모듈을 제공합니다. 사용자는 대화형 쿼리 및 대규모 데이터 분석을 위해 표준 SQL 문을 사용할 수 있습니다 .
Kangaroo Cloud에서 Spark 사용
Kangaroo Cloud Stack 오프라인 개발 플랫폼 에서는 Spark를 사용하는 세 가지 방법을 제공합니다.
● Spark SQL 작업 만들기
사용자는 SQL을 작성하여 자신의 비즈니스 로직을 직접 구현할 수 있습니다. 이 방법은 현재 데이터 스택 오프라인 플랫폼에서 Spark를 사용하는 데 가장 널리 사용되는 방법이며 가장 권장되는 방법이기도 합니다.
● Spark Jar 작업 만들기
사용자는 Scala 또는 Java 언어를 사용하여 IDEA에서 비즈니스 로직을 구현한 다음 프로젝트를 컴파일 및 패키징하고 결과 Jar 패키지를 오프라인 플랫폼에 업로드한 다음 Spark Jar 작업을 생성할 때 이 Jar 패키지를 참조하고 마지막으로 작업을 제출해야 합니다. 예약된 실행으로 이동합니다.
SQL을 사용하여 달성하거나 표현하기 어려운 요구 사항이 있거나 사용자에게 다른 더 깊은 요구 사항이 있는 경우 Spark Jar 작업은 의심할 여지 없이 사용자에게 Spark를 사용하는 보다 유연한 방법을 제공합니다.
● PySpark 작업 만들기
사용자는 해당 Python 코드를 직접 작성할 수 있습니다 . 우리 고객 중에는 SQL 외에 Python을 주요 언어로 사용하는 고객도 꽤 있습니다. 특히 특정 데이터 분석 및 알고리즘 기반을 갖춘 사용자의 경우 처리된 데이터에 대한 심층 분석을 수행하는 경우가 많으며 이때 PySpark 작업이 당연히 최선의 선택입니다.
Spark는 Kangaroo Cloud Data Stack 오프라인 개발 플랫폼 에서 중요한 역할을 합니다 . 따라서 고객이 Spark를 사용하여 작업을 보다 편리하게 제출할 수 있도록 Spark에 대한 많은 내부 최적화를 수행했습니다. 또한 전체 데이터 스택 오프라인 개발 플랫폼의 기능을 향상시키기 위해 Spark 기반의 몇 가지 도구를 만들었습니다.
또한 Spark는 데이터 레이크 시나리오에서도 매우 중요한 역할을 합니다. Kangaroo Cloud의 통합 레이크 및 웨어하우스 모듈은 이미 두 가지 주요 데이터 레이크인 Iceberg와 Hudi를 지원합니다. 사용자는 Spark를 사용하여 레이크 테이블을 읽고 쓸 수 있으며 Spark를 사용하여 다양한 저장 프로시저를 호출함으로써 구현됩니다.
다음은 엔진 측면과 Spark 자체 측면에서 Kangaroo Cloud 내부에서 이루어진 최적화에 대해 설명합니다.
엔진측 최적화
Kangaroo Cloud 내부 엔진 의 기능 은 주로 작업 제출, 작업 상태 획득, 작업 로그 획득, 작업 중지, 구문 확인 등에 사용됩니다. 각 기능 포인트를 다양한 수준으로 최적화했습니다. 다음은 두 가지 예를 통해 간략하게 소개합니다.
Spark on Yarn 제출 속도가 향상되었습니다.
엔진 측 Spark 플러그인의 새로운 기능이 지속적으로 개발 및 개선됨에 따라 엔진 측에서 Spark 작업을 제출하는 데 필요한 시간도 그에 따라 증가하므로 Spark 작업 제출과 관련된 코드를 최적화해야 합니다. Spark 작업 제출 시간을 단축합니다. 사용자 경험을 개선합니다.
이를 위해 우리는 core-site.xml, Yarn-site.xml, keytab 파일, Spark-sql-application.jar 등과 같은 일부 공통 구성 파일에 대해 다음 작업을 수행했습니다. 작업을 제출할 때 서버에서 해당 구성 파일을 다운로드하고 제출해야 합니다. 이제 최적화 후에는 클라이언트 SparkYarnClient 가 초기화될 때 위 파일을 한 번만 다운로드한 다음 지정된 HDFS 경로에 업로드하면 됩니다. 이후 Spark 작업 제출은 매개변수를 통해 해당 HDFS 경로에 지정하기만 하면 됩니다. 이러한 방식으로 각 Spark 작업의 제출 시간이 크게 단축됩니다.
새로운 버전의 데이터 스택에서는 임시 쿼리 의 경우 사용자 정의 규칙을 기반으로 실행할 SQL의 복잡성을 판단하고 덜 복잡한 SQL을 엔진 측에서 시작된 SparkSQLEngine 으로 보내 작업 속도를 높일 것입니다. 이 내부 SparkSQLEngine은 과거에는 구문 검증용으로만 사용되었지만 이제는 SQL 실행 기능의 일부도 가정하며, SparkSQLEngine도 전체 실행 상황에 따라 자원을 동적으로 확장 및 축소하여 자원의 효과적인 활용을 달성할 수 있습니다.
문법 점검
이전 데이터 스택 버전에서는 SQL 구문 확인을 위해 엔진이 먼저 SQL을 Spark Thrift Server로 보냅니다. 이 Spark Thrift 서버는 로컬 모드로 배포되며 구문 확인에만 사용되는 것이 아닙니다. 다른 플랫폼의 모든 메타데이터는 실행을 위해 이 Spark Thrift 서버에 SQL을 전송하여 얻습니다. 이 방법에는 큰 단점이 있으므로 몇 가지 최적화를 수행했습니다. Spark 작업은 엔진 측에서 로컬 모드 로 시작됩니다. 구문 확인을 수행할 때 SQL은 더 이상 Spark Thrift Server로 전송되지 않으며 대신 SQL에서 직접 구문 확인을 수행하기 위해 SparkSession이 내부적으로 유지됩니다.
이 방법은 외부 Spark Thrift 서버와의 강력한 연결이 필요하지 않지만 일정 구성 요소에 어느 정도 부담을 주며 구현 과정에서 엔진 플러그인의 전반적인 복잡성도 많이 증가합니다.
위의 문제를 최적화하기 위해 스케줄링 구성 요소가 시작되면 Spark 작업 SparkSQLEngine을 Yarn에 제출합니다. Yarn에서 실행되는 원격 Spark Thrift Server로 이해될 수 있습니다. 엔진 측은 SparkSQLEngine 의 상태를 항상 모니터링합니다 . 이런 방식으로 구문 검증을 수행할 때마다 엔진은 구문 검증을 위해 JDBC를 통해 SparkSQLEngine에 SQL을 보냅니다.
위의 최적화를 통해 오프라인 개발 플랫폼은 Spark Thrift Server에서 분리되어 EasyManager는 추가 Spark Thrift Server를 배포할 필요가 없으므로 배포가 더 간단해집니다. 예약 측면에서 로컬 모드 Spark 상주 프로세스를 유지할 필요가 없습니다. 또한 오프라인 개발 플랫폼에서 Spark SQL 작업의 대화형 쿼리 향상을 위한 길을 열어줍니다.
EasyManager가 배포한 Spark Thrift Server에서 오프라인 개발 플랫폼을 분리하면 다음과 같은 이점이 있습니다.
· 여러 Spark 클러스터와 여러 버전의 진정한 공존을 실현할 수 있습니다.
· EasyManager 표준 배포로 Spark Thrift Server를 제거하고 일선 운영 및 유지 관리에 대한 부담을 줄일 수 있습니다.
· Spark SQL 구문 검증이 더욱 가벼워지고 SparkContext를 캐시할 필요가 없어 엔진 리소스 사용량이 줄어듭니다.
스파크 기능 최적화
비즈니스가 발전함에 따라 일부 시나리오에서는 오픈 소스 Spark에 해당 기능 구현이 없다는 것을 알게 되었습니다. 따라서 우리는 데이터 스택의 더 많은 기능적 애플리케이션을 지원하기 위해 오픈 소스 Spark를 기반으로 더 많은 새로운 플러그인을 개발했습니다.
임무 진단
첫째, Spark의 메트릭 싱크를 향상했습니다. Spark는 내부적으로 ConsoleSink 외에도 CSVSink, JmxSink, MetricsServlet, GraphiteSink, Slf4jSink, StatsdSink 등 다양한 싱크를 제공합니다. PrometheusServlet도 Spark3.0 이후에 추가되었지만 이는 우리의 요구 사항을 충족할 수 없습니다.
작업 진단 기능을 개발할 때 Spark의 내부 지표를 PushGateway에 통일적으로 푸시해야 하며, Prometheus 서버는 주기적으로 PushGateway에서 지표를 가져옵니다. 마지막으로 Prometheus에서 제공하는 쿼리 인터페이스를 호출하여 내부를 쿼리할 수 있습니다. 거의 실시간으로 Spark 지표를 표시합니다.

그러나 Spark는 PushGateway에 대한 싱킹 내부 표시기를 구현하지 않습니다. 따라서 우리는 Spark-prometheus-sink 플러그인을 추가 하고 PrometheusPushGatewaySink를 사용자 정의하여 Spark 내부 표시기를 PushGateway에 푸시했습니다.
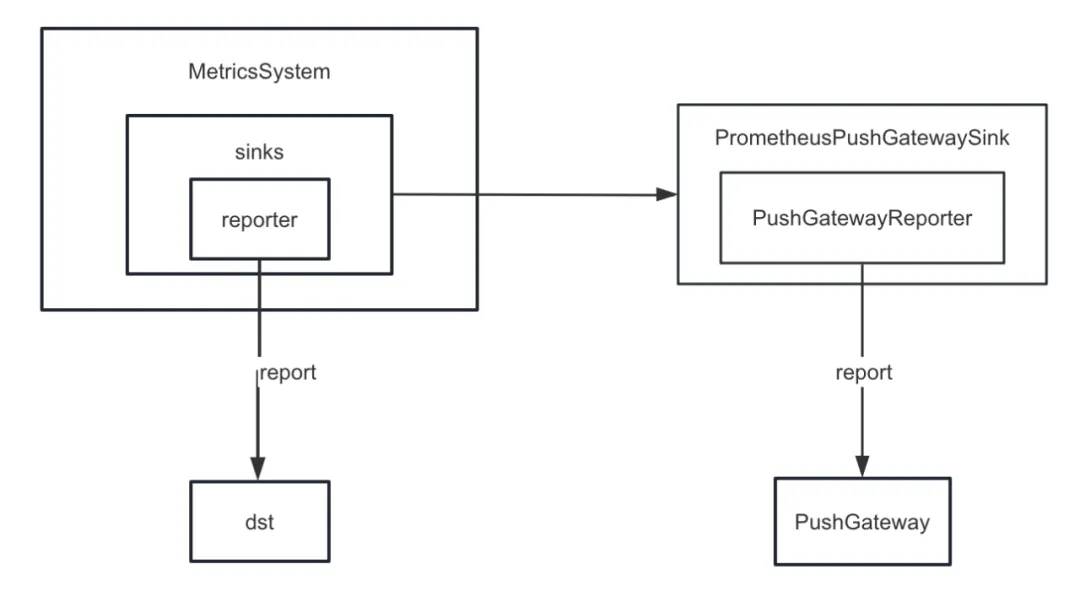
또한 Spark SQL 임시 쿼리 표시 작업 실행 진행 상황을 설명하는 새로운 표시기를 사용자 지정했습니다. 구체적인 단계는 다음과 같습니다:
· JobProgressSource를 커스터마이징하여 오프라인 작업의 진행 상황을 설명하는 지표를 추가하고 , Spark 내부 관리 시스템의 지표 관리 시스템에 지표를 등록합니다.
· JobProgressListener를 사용자 정의하고 JobProgressListener를 Spark 내부 관리 시스템의 ListenerBus에 등록합니다. 그중 JobProgressListener의 onJobStart 메소드 논리는 현재 Job에 속한 모든 Task의 수를 계산하는 것이고, onTaskEnd 메소드의 논리는 각 Task가 완료된 후 현재 오프라인 작업 진행 상황을 계산하고 업데이트하는 것입니다 . onJobEnd 메서드는 각 작업이 완료된 후 현재 오프라인 작업 진행 상황을 계산하고 업데이트합니다.
Hadoop 클러스터의 상용 버전에 연결
Kangaroo Cloud 고객 수가 증가함에 따라 환경도 다양해졌습니다. 일부 고객은 오픈 소스 버전의 Hadoop 클러스터를 사용하고 있으며 상당수의 고객이 HDP, CDH, CDP, TDH 등을 사용하고 있습니다. 이러한 고객의 클러스터에 연결할 때 개발 측면에서는 새로운 적응이 필요한 경우가 많으며, 운영 및 유지 관리 측면에서도 배포 및 업그레이드될 때마다 추가 매개변수를 구성하거나 기타 추가 작업을 수행해야 합니다.
HDP를 예로 들면, HDP에 연결할 때 우리가 사용하는 Spark는 HDP와 함께 제공되는 Spark2.3이며, 또한 운영 및 유지 관리 측면에서 일부 매개변수를 추가하고 HDP와 함께 제공되는 Spark의 모든 Jar 패키지를 이동해야 합니다. 디렉토리를 지정합니다. 이러한 작업은 실제로 운영 및 유지 관리에 약간의 혼란과 문제를 가져옵니다. 다양한 유형의 클러스터는 다양한 운영 및 유지 관리 문서를 유지해야 하며 배포 프로세스도 오류가 발생하기 쉽습니다. 그리고 실제로 Spark 소스 코드의 기능을 향상하고 버그를 수정했습니다. HDP와 함께 제공되는 Spark를 사용하는 경우 내부적으로 유지 관리되는 Spark의 모든 이점을 누릴 수 없습니다.
위의 문제를 해결하기 위해 우리 내부 Spark는 기존 시장의 기존 퍼블리셔와 일반 퍼블리셔에 맞게 조정되었습니다. 즉, 내부 Spark는 모든 다른 Hadoop 클러스터에서 실행될 수 있습니다. 이런 방식으로 어떤 유형의 Hadoop 클러스터가 연결되어 있든 운영 및 유지 관리는 동일한 Spark만 배포하면 되므로 운영 및 유지 관리 배포에 대한 부담이 크게 줄어듭니다. 더 중요한 것은 고객이 내부 Spark 안정 버전을 직접 사용하여 더 많은 새로운 기능과 더 큰 성능 향상을 누릴 수 있다는 것입니다.
Spark3.2의 새로운 기능 - AQE
이전 Data Stack 버전에서는 기본 Spark 버전이 2.1.3이지만 나중에 Spark 버전을 2.4.8로 업그레이드하여 Spark 3.2도 사용할 수 있습니다. 여기서는 Spark3.x의 가장 중요한 새 기능이기도 한 AQE 에 중점을 둡니다 .
AQE 개요
Spark3.2 이전에는 AQE가 기본적으로 꺼져 있었습니다. AQE를 활성화하려면 Spark.sql.adaptive.enabled를 true로 설정해야 합니다. Spark3.2 이후에는 작업이 AQE의 트리거 조건을 충족하는 한 AQE가 기본적으로 활성화됩니다. AQE가 제공하는 최적화를 누릴 수 있습니다.
AQE의 최적화는 셔플 단계에서만 발생한다는 점에 유의해야 합니다. 셔플 작업이 SQL 실행 프로세스에 포함되지 않으면 AQE는 Spark.sql.adaptive.enabled의 값이 다음과 같더라도 역할을 수행하지 않습니다. 진실. 더 정확하게 말하면 AQE는 물리적 실행 계획에 교환 노드가 포함되거나 하위 쿼리가 포함된 경우에만 적용됩니다.
AQE는 운영 중 Shuffle Map 단계에서 생성된 중간 파일의 정보를 수집하고, 이 정보에 대한 통계를 수집하며, 기존 규칙을 기반으로 아직 실행되지 않은 Optimized Logical Plan과 Spark Plan을 동적으로 조정하여 원본을 수정합니다. SQL 문. 런타임 최적화.
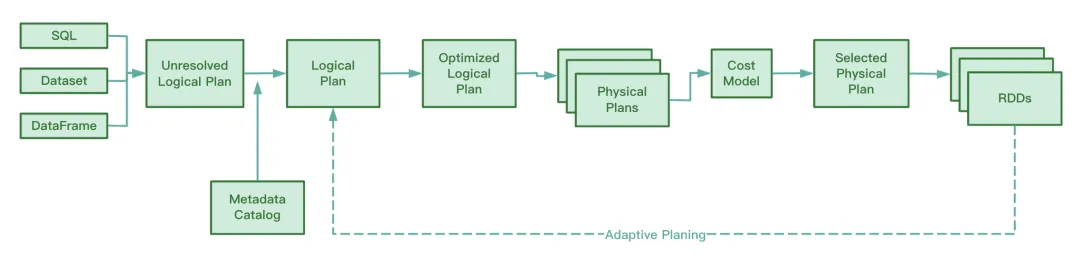
Spark 소스 코드를 보면 AQE에는 다음 네 가지 최적화 규칙이 포함됩니다.

우리는 RBO가 조건자 푸시다운, 열 정리, 상수 교체 등을 포함한 일련의 규칙을 기반으로 SQL을 최적화한다는 것을 알고 있습니다. 이러한 정적 규칙 자체는 Spark에 내장되어 있으며 Spark가 SQL을 실행할 때 이러한 규칙은 하나씩 SQL에 적용됩니다.
AQE 장점
CBO의 이 기능은 Spark2.2 이후에만 사용할 수 있습니다. RBO와 비교하여 CBO는 테이블의 통계 정보를 결합하고 이러한 통계 정보와 비용 모델을 기반으로 보다 최적화된 실행 계획을 선택합니다.
그러나 CBO는 Hive Metastore에 등록된 테이블만 지원합니다. CBO는 분산 파일 시스템에 저장된 parquet 및 orc와 같은 파일을 지원하지 않습니다. 또한 Hive 테이블에 메타데이터 정보가 부족할 경우 CBO가 통계 수집 시 통계를 수집하지 못하여 CBO가 실패할 수 있습니다.
CBO의 또 다른 단점은 CBO가 최적화 전에 통계 정보를 수집하기 위해 ANALYZE TABLE COMPUTE STATISTICS를 실행해야 한다는 것입니다. 이 문이 실행 중에 큰 테이블을 발견하면 시간이 더 많이 걸리고 수집 효율성이 낮아집니다.
CBO이든 RBO이든 정적 최적화입니다. 물리적 실행 계획을 제출한 후 작업이 실행되는 동안 데이터 볼륨 및 데이터 분포가 변경되면 CBO는 기존 물리적 실행 계획을 최적화하지 않습니다.
CBO 및 RBO와 달리 AQE는 실행 프로세스 중에 셔플 맵 프로세스 중에 생성된 중간 파일을 분석하고 아직 실행이 시작되지 않은 논리적 실행 계획 및 물리적 실행 계획을 정적으로 최적화된 CBO와 비교하여 동적으로 조정하고 최적화합니다. , RBO와 비교하여 AQE 처리는 보다 최적화된 물리적 실행 계획을 얻을 수 있습니다 .
AQE 세 가지 주요 기능
● 자동 파티션 병합
Shuffle 프로세스는 Map 단계와 Reduce 단계의 두 단계로 나누어지며, Reduce 단계는 Map 단계에서 생성된 중간 임시 파일을 해당 Executor로 가져옵니다. 실제로 데이터 조각은 몇 개뿐이므로 처리 후 데이터가 많은 수의 작은 파일을 형성할 수 있습니다.
위의 상황을 방지하려면 AQE의 자동 파티션 병합 기능을 활성화하여 Map 단계에서 생성된 작은 파일을 가져오기 위해 너무 많은 축소 작업을 시작하는 것을 방지할 수 있습니다.
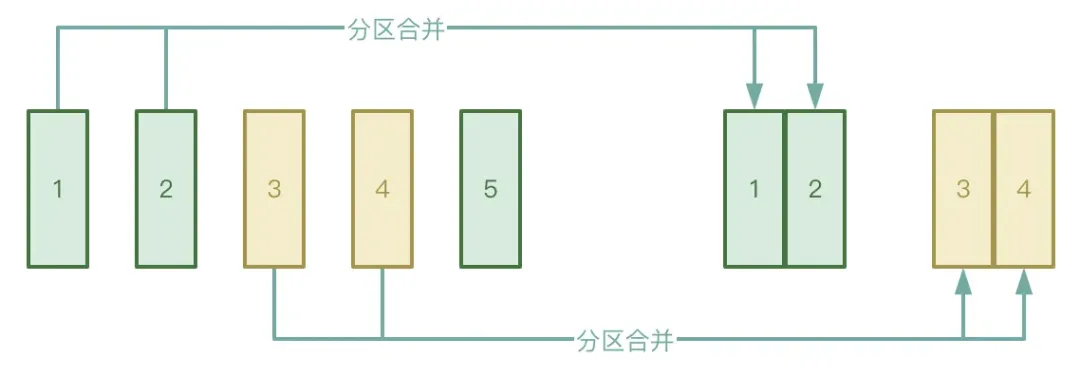
● 자동 데이터 편향 처리
애플리케이션 시나리오는 주로 데이터 조인에 있습니다. 데이터 편향이 발생하면 AQE는 편향된 파티션을 자동으로 감지 하고 특정 규칙에 따라 편향된 파티션을 분할할 수 있습니다. 현재 Spark3.2에서는 SortMergeJoin 및 ShuffleHashJoin 모두에 대해 자동 데이터 편향 처리가 지원됩니다.
● 가입 전략 조정
AQE는 Hash Join 및 Sort Merge Join을 Broadcast Join으로 동적으로 다운그레이드합니다.
Spark 작업이 실행되기 시작하면 병렬 처리 수준이 결정된다는 것을 알고 있습니다. 예를 들어 셔플 맵 단계에서 병렬 처리는 파티션 수이고, 셔플 감소 단계에서 병렬 처리는 Spark.sql.shuffle.partitions의 값이며 기본값은 200입니다. Spark 작업을 실행하는 동안 데이터 양이 작아지면 대부분의 파티션 크기가 작아지고, 작은 데이터 세트를 처리하기 위해 너무 많은 스레드가 계속 시작되면 리소스 낭비가 발생합니다.
실행 프로세스 중에 AQE는 CoalesceShufflePartitions 규칙을 적용하고 사용자가 제공한 매개변수를 결합하여 셔플 후 특정 조건에서 생성된 중간 임시 결과를 기반으로 파티션을 자동으로 병합합니다. 이는 실제로 리듀서 수를 조정합니다. 원래 감소 스레드는 처리된 하나의 파티션의 데이터만 가져오지만 이제 감소 스레드는 실제 상황에 따라 더 많은 파티션의 데이터를 가져오므로 리소스 낭비를 줄이고 작업 실행 효율성을 높일 수 있습니다. "산업 지표 시스템 백서" 다운로드 주소: https://www.dtstack.com/resources/1057?src=szsm
"Dutstack 제품 백서" 다운로드 주소: https://www.dtstack.com/resources/1004?src=szsm
"데이터 거버넌스 산업 실무 백서" 다운로드 주소: https://www.dtstack.com/resources/1001?src=szsm
빅데이터 제품, 산업 솔루션, 고객 사례에 대해 더 알고 싶거나 상담하고 싶은 분들은 Kangaroo Cloud 공식 홈페이지( https://www.dtstack.com/?src=szkyzg )를 방문해 주세요.
오픈 소스 Hongmeng을 포기하기로 결정했습니다 . 오픈 소스 Hongmeng의 아버지 Wang Chenglu: 오픈 소스 Hongmeng은 중국에서 유일하게 기초 소프트웨어 분야의 건축 혁신 산업 소프트웨어 행사입니다. OGG 1.0이 출시되고 Huawei는 모든 소스 코드를 제공합니다. 구글 리더가 '코드 똥산'에 죽는다 페도라 리눅스 40 정식 출시 전 마이크로소프트 개발자: 윈도우 11 성능이 ' 어처구니없을 정도로 나쁨' 마화텡과 저우홍이가 악수하며 '원한 해소' 유명 게임사들이 새로운 규정 발표 : 직원 결혼 선물은 100,000위안을 초과할 수 없습니다. Ubuntu 24.04 LTS 공식 출시 Pinduoduo는 부정 경쟁 혐의로 판결을 받았습니다. 보상금 500만 위안