캐시의 정의
캐시( Cache)는 데이터 교환을 위한 버퍼로 일반적으로 알려진 캐시는 버퍼에 있는 데이터 로 , 일반적으로 데이터베이스에서 얻어 로컬 코드에 저장된다. 과도한 데이터 액세스가 시스템에 돌입하여 운영 스레드가 적시에 정보를 처리하지 못하고 마비되는 것을 방지합니다. 이는 기업, 실제 개발 시 제품 평판 및 사용자 평가에 치명적이므로 기업은 캐싱 기술, Redis를 매우 중요하게 생각합니다 . 가장 많이 사용되는 캐싱 미들웨어는 면접을 위한 고주파 테스트 사이트이기도 합니다.
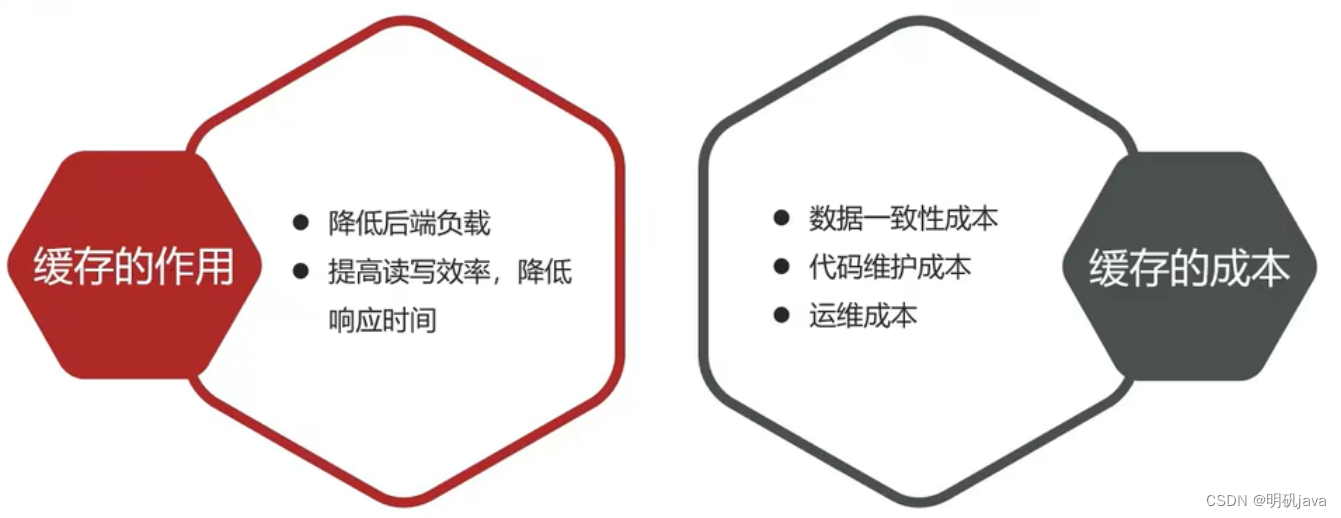
캐시 사용 목적
캐시 데이터는 코드에 저장되고 코드는 메모리에서 실행됩니다.메모리의 읽기 및 쓰기 성능은 디스크의 성능보다 훨씬 높습니다.캐시는 서버에 대한 읽기 및 쓰기 압력을 크게 줄일 수 있습니다 . 동시 사용자 액세스 . 실제 개발 과정에서 기업의 데이터 양은 수십만에서 수천만에 이르는데, 이렇게 많은 양의 데이터에 대한 캐시가 없으면 시스템에서 지원하기 어렵습니다. 캐시 기술의 수.
캐시를 사용하는 방법
실제 개발에서는 시스템 속도를 더욱 높이기 위해 다중 레벨 캐시가 구축됩니다. 예를 들어 로컬 캐시와 Redis의 캐시가 동시에 사용됩니다.
브라우저 캐시 : 주로 브라우저 측에 존재하는 캐시
애플리케이션 레이어 캐시: 앞서 언급한 맵과 같은 Tomcat 로컬 캐시로 분할하거나 Redis를 캐시로 사용할 수 있습니다.
데이터베이스 캐시: 데이터베이스에 버퍼 풀로 사용되는 공간이 있으며, 추가, 수정, 확인된 데이터는 mysql 캐시에 먼저 로드됩니다.
CPU 캐시: 현대 컴퓨터의 가장 큰 문제점은 CPU 성능은 향상되었으나 메모리 읽기 및 쓰기 속도가 따라오지 못하고 있다는 점입니다. 따라서 현재 상황에 적응하기 위해 CPU의 L1, L2, L3 캐시는 추가되었습니다.
캐시스토어 정보
매장 정보 인터페이스는 동시성이 높으며 쿼리 데이터는 데이터베이스에서 매번 쿼리할 수 없으며 매장 데이터는 높은 동시성에 대처하기 위해 redis에 캐시되어야 합니다.
@GetMapping("/{id}")
public Result queryShopById(@PathVariable("id") Long id) {
//这里是直接查询数据库
return shopService.queryById(id);
}
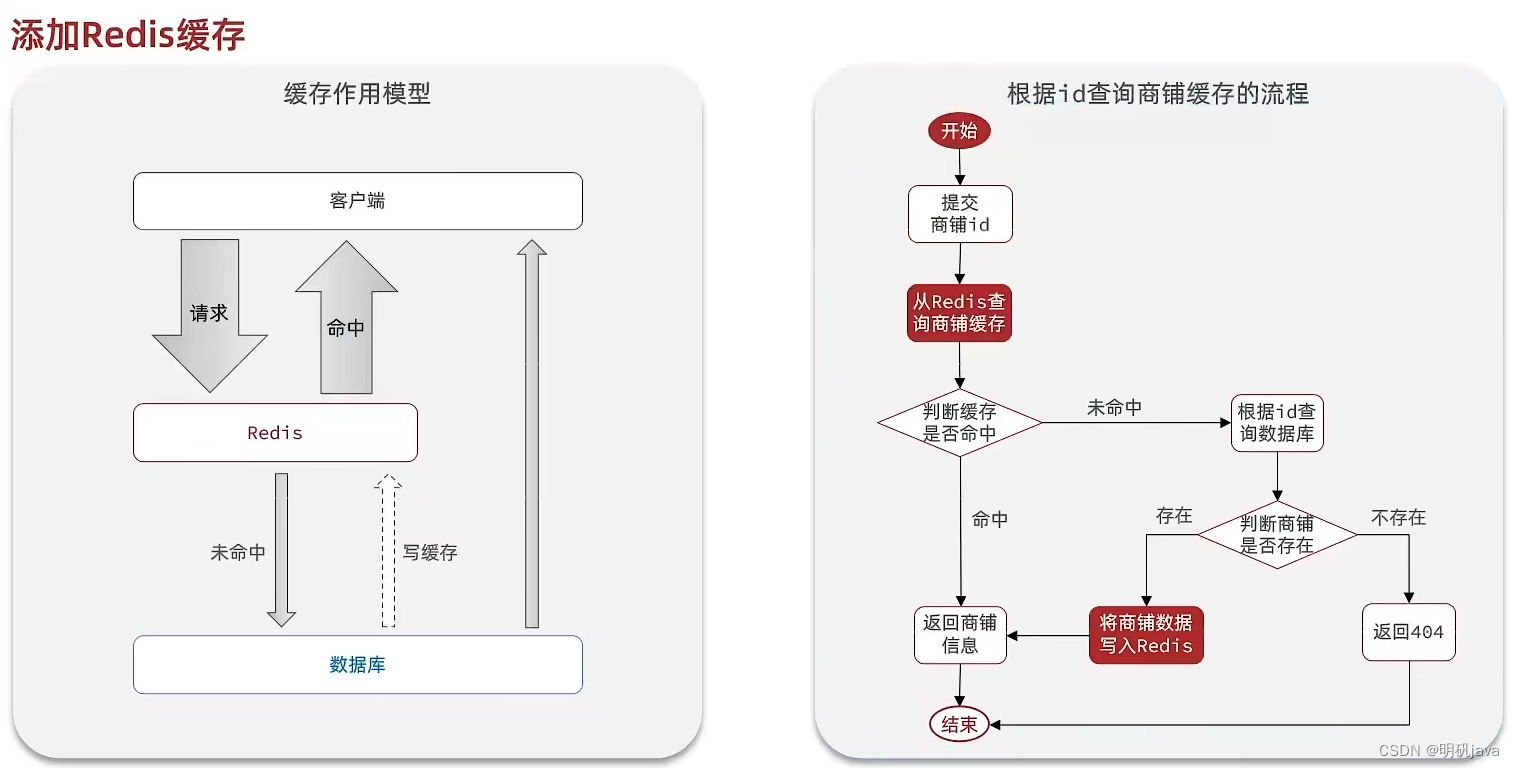
캐싱 모델 및 아이디어
표준적인 동작 방법은 데이터베이스를 질의하기 전에 캐시를 질의하는 것이며, 캐시된 데이터가 존재하면 캐시에서 직접 반환하고, 캐시된 데이터가 존재하지 않으면 데이터베이스를 질의하여 Redis에 저장한다.
암호
이 때 캐시 데이터는 만료 시간을 설정하지 않는다는 점에 유의하십시오.데이터베이스에 대한 부담을 줄이기 위해서는 캐시가 메모리에 상주해야 하지만 캐시 데이터와 캐시 데이터가 일치하지 않는 문제도 발생합니다. 이는 버퍼 업데이트 전략 의 문제로 이어지는 데이터베이스 데이터입니다 .
@Override
public Result queryById(Long id) {
//根据业务代码组装key
String key = CACHE_SHOP_KEY + id;
//从redis中获取商铺信息
String shopJson = stringRedisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(shopJson)) {
//将json转化为shop对象直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
Shop shop = getById(id);
if (shop == null) {
return Result.fail("店铺不存在");
}
//将数据库查询的数据写入缓存
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop));
//返回
return Result.ok(shop);캐시 업데이트 전략
업데이트 전략은 주로 비즈니스에 따라 선택됩니다. 이 프로젝트에서는 활성 업데이트 + 시간 초과 제거의 업데이트 전략을 채택합니다. 시간 초과 제거는 주로 캐시가 가끔씩 업데이트되도록 보장된 업데이트 전략으로 사용됩니다. 활성 업데이트를 트리거하지 않고 캐시를 지웁니다.
캐시 업데이트는 주로 메모리 데이터가 소중하기 때문에 메모리를 절약하기 위해 Redis가 설계한 것입니다. Redis에 너무 많은 데이터를 삽입하면 캐시에 너무 많은 데이터가 발생할 수 있으므로 Redis는 일부 데이터 업데이트를 처리하거나 그를 제거했다고 부르는 것이 더 적절합니다.
메모리 제거: redis가 자동으로 수행됩니다 .redis 메모리가 우리가 설정한 최대 메모리에 도달하면 자동으로 제거 메커니즘을 트리거하여 중요하지 않은 일부 데이터를 제거합니다(전략을 직접 설정할 수 있음).
시간 초과 제거: Redis에 대해 만료 시간 ttl을 설정하면 Redis는 캐시를 계속 사용할 수 있도록 시간 초과된 데이터를 삭제합니다.
활성 업데이트: 캐시를 삭제하는 메소드를 수동으로 호출 할 수 있습니다 . 이는 일반적으로 캐시와 데이터베이스 간의 불일치 문제를 해결하는 데 사용됩니다.

데이터베이스 캐시 데이터 불일치 솔루션
캐시 의 데이터 소스는 데이터베이스에서 가져오고 데이터베이스 의 데이터가 변경되므로 데이터베이스의 데이터가 변경 되지만 캐시가 동기화되지 않으면 현재 일관성 문제가 발생하며 결과는 다음과 같습니다. :
사용자가 캐시에 있는 오래된 데이터를 사용할 경우 유사한 멀티스레드 데이터 보안 문제가 발생하여 비즈니스, 제품 평판 등에 영향을 미칠 수 있습니다. 이를 해결하는 방법은 무엇입니까? 여러 가지 옵션이 있습니다
Cache Aside Pattern 수동 코딩 방법 : 캐시 호출자가 데이터베이스를 업데이트한 후 캐시를 업데이트하는 방식(이중 쓰기 방식이라고도 함)
Read/Write Through 패턴: 시스템 자체에서 완료되며 데이터베이스 및 캐시 문제는 시스템 자체에서 처리됩니다.
캐싱 뒤에 쓰기 패턴: 호출자는 캐시만 작동 하고 다른 스레드는 데이터베이스를 비동기식으로 처리하여 최종 일관성을 달성합니다.
옵션 2를 사용하면 시스템의 복잡성이 증가하여 호출자가 관련 문제를 해결하는 데 도움이 되지 않습니다.옵션 3은 일련의 스레드 안전을 가지므로 데이터베이스 캐시가 일치하지 않습니다.종합적으로 고려한 후 수동을 선택하는 것이 더 안전합니다. 코딩 .
수동 코딩 단계
- 캐시 삭제: 데이터베이스 업데이트 시 캐시 무효화 후 질의 시 캐시 업데이트 (데이터베이스 업데이트와 동시에 캐시 업데이트 시 업데이트 동작이 너무 많아 성능을 보장할 수 없음)
- 모놀리식 시스템에서는 캐시와 데이터베이스 작업을 하나의 트랜잭션에 넣어 데이터베이스가 성공적으로 업데이트되면 캐시도 성공적으로 추가되어야 합니다. 즉, 두 작업이 동시에 성공하거나 실패하도록 보장합니다.
-
데이터베이스를 먼저 운영한 후 캐시를 삭제 멀티스레딩의 경우 데이터베이스를 운영하는 시간이 레디스 캐시를 운영하는 시간보다 훨씬 길기 때문에 데이터베이스를 쓸 때 캐시 실패 가능성이 적다 .
저장소와 캐시, 데이터베이스 간의 이중 쓰기 일관성 실현
- ID를 기준으로 스토어 조회 시 캐시가 누락되면 데이터베이스를 쿼리하고 데이터베이스 결과를 캐시에 쓰고 타임아웃을 설정합니다.
- ID를 기준으로 스토어를 수정하는 경우 데이터베이스를 먼저 수정한 후 캐시를 삭제하세요.
캐시 추가 시 Redis 캐시 설정 시 만료 시간 추가
@Override
public Result queryById(Long id) {
//根据业务代码组装key
String key = CACHE_SHOP_KEY + id;
//从redis中获取商铺信息
String shopJson = stringRedisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(shopJson)) {
//将json转化为shop对象直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
Shop shop = getById(id);
if (shop == null) {
return Result.fail("店铺不存在");
}
//将数据库查询的数据写入缓存,并设置过期时间
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), 30L,TimeUnit.MINUTES);
//返回
return Result.ok(shop);
}이중 쓰기 문제를 해결하기 위해 삭제 전략을 사용하기로 결정했습니다 . 데이터를 수정하면 캐시에 있는 데이터가 삭제됩니다. 쿼리 시 캐시에 데이터가 없는 것으로 확인되면 최신 데이터가 로드됩니다. mysql에서 캐시와의 데이터베이스 불일치를 방지하려면 이 메소드에 @Transactional 주석을 달아 트랜잭션을 선언해야 합니다.
@Transactional
@Override
public Result update(Shop shop) {
Long id = shop.getId();
//判断id是否为空,因为可以绕过前端直接发送请求,此步必须判断
if (id == null) {
return Result.fail("店铺id不能为空");
}
//更新数据库
updateById(shop);
//删除缓存
stringRedisTemplate.delete(CACHE_SHOP_KEY + id);
return Result.ok();
}