"서문" 기사의 내용은 응용 계층 프로토콜의 HTTP 프로토콜에 대한 대략적인 설명입니다.
"소속 컬럼" 네트워크 프로그래밍
"홈페이지 링크" 개인 홈페이지
"작가" Mr. Maple Leaf (fy)
"단풍잎씨는 문학이 조금" "문장 나눔"
속담처럼 활을 펴면 되돌릴 수 없고, 화살이 부러지고, 화살이 떨어지고, 화살이 과녁을 맞추는 세 가지 결과만 있습니다.
——Jiang Xiaoying "소동포: 세상에서 가장 진정한 사랑"

목차
1. HTTP 프로토콜 소개
HTTP(Hyper Text Transfer Protocol)하이퍼텍스트 전송 프로토콜이라고도 하는 이 프로토콜은 응용 프로그램 계층에서 작동하는 요청-응답 프로토콜입니다.
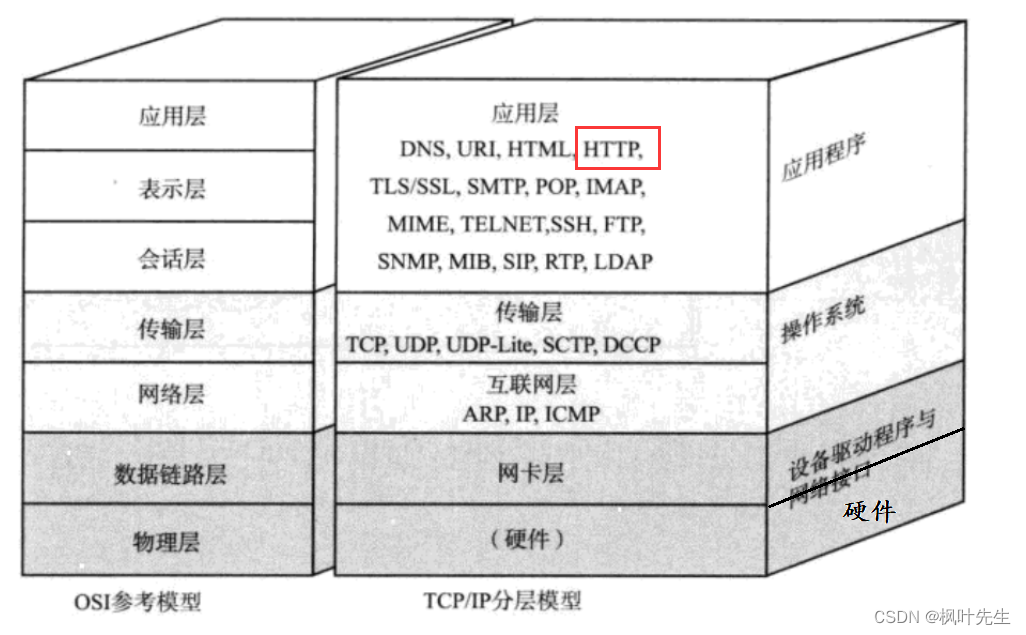
응용 계층 프로토콜은 자체적으로 사용자 정의할 수 있다고 말했지만 실제로 일부 우수한 엔지니어는 이미 일부 기성 프로토콜을 정의했으며 응용 계층 프로토콜 HTTP(Hypertext Transfer Protocol)는 우리가 직접 참조할 수 있는 프로토콜 중 하나입니다. .
둘째, URL을 알고
일반적으로 "URL"이라고 부르는 것은 실제로 다음을 의미합니다.URL
URL(Uniform Resource Lacator)URL은 URL이라고 하는 균일한 리소스 로케이터라고 합니다.
URL은 대략 다음과 같은 부분으로 구성됩니다.

(1) 프로토콜 방식 이름
http://프로토콜의 이름을 나타내며http, 요청 시 사용해야 하는 프로토콜을 나타냅니다. 우리가 일상생활에서 인터넷에서 흔히 볼 수 있는 프로토콜은 다음 과http같습니다 . 다음 장에서 논의할 데이터 전송 프로토콜.httpshttp协议https
(2) 로그인 정보
usr:pass로그인 사용자의 사용자 이름과 암호를 포함한 로그인 인증 정보를 나타냅니다. 이제 이 필드는 대부분의 URL에서 생략됩니다.
(3) 서버 주소
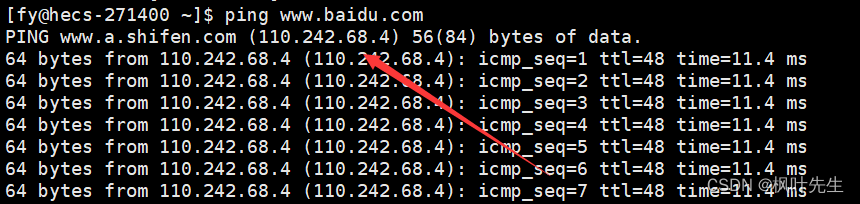
www.example.jp도메인 이름이라고도 하는 서버 주소를 나타냅니다. 이 도메인 이름은 고유한 호스트를 식별하는 데 사용되는 주소이며 이 도메인 이름을 주소IP로 변환 하고 도메인 이름 확인 서버에서 도메인 이름 확인을 완료합니다.IP
Linux에서는 ping명령을 통해 도메인 이름을 확인할 수 있습니다.
(4) 서버 포트 번호
80서버 포트 번호를 나타내며http프로토콜의 기본 포트 번호는 이고80프로토콜https의 기본 포트 번호는 입니다443.- URL에서 서버의 포트 번호는 일반적으로 생략됩니다. 서비스와 포트 번호 간의 대응이 명확하기 때문입니다(코드가 작성됨). 따라서 사용할 때 프로토콜에 해당하는 포트 번호를 지정할 필요가 없습니다. 프로토콜
http_
(5) 계층적 파일 경로
/dir/index.htm액세스할 리소스가 있는 경로를 나타냅니다.- 첫 번째
/는 Linux의 루트 디렉터리가 아닌 웹의 루트 디렉터리입니다.웹의 루트 디렉터리는 Linux 아래의 모든 디렉터리가 될 수 있습니다. - 서버에 접근하는 목적은 서버에서 특정 리소스를 획득하기 위함이며, 해당 서버 프로세스는 이전 도메인 네임과 포트를 통해 이미 찾을 수 있으며 이때 해야 할 일은 리소스가 위치한 경로를 알려주는 것입니다. .
http프로토콜은 원격 서버에서 로컬 서버로 리소스를 가져오기 위한 프로토콜로,
인터넷에서 우리가 보는 모든 것은 텍스트, 오디오, 사진, 웹 페이지 등과 같은 리소스입니다. 이러한 리소스(파일)는 특정 서버에 저장되어야 합니다. HTTP이 프로토콜은 다양한 종류의 파일 자원을 전송할 수 있으므로 텍스트 전송 프로토콜 대신 하이퍼텍스트 전송 프로토콜이라고 합니다. 전송할 수 있는 파일 리소스의 유형은 超단어에 반영됩니다.
(6) 쿼리 문자열
uid=1요청 시 제공된 매개변수를 &기호로 구분하여 나타냅니다.
(7) 조각 식별자
ch1리소스에 대한 부분 보완인 조각 식별자를 나타냅니다.
3, urlencode 및 urldecode
URL에서 등의 문자는 /URL ? 에 의해 특별한 의미로 해석되었습니다. 따라서 이러한 문자는 임의로 나타날 수 없습니다.
예를 들어 매개변수에 이러한 특수 문자가 필요한 경우 특수 문자를 먼저 이스케이프 처리해야 합니다.
탈출 규칙은 다음과 같습니다.
트랜스코딩이 필요한 문자를 로 변환한 16进制후 오른쪽에서 왼쪽으로 4자리를 취하여(4자리 미만은 직접 처리) 2자리마다 1자리를 만들어 앞에 추가하여 다음과 같이 인코딩한다 %.%XY
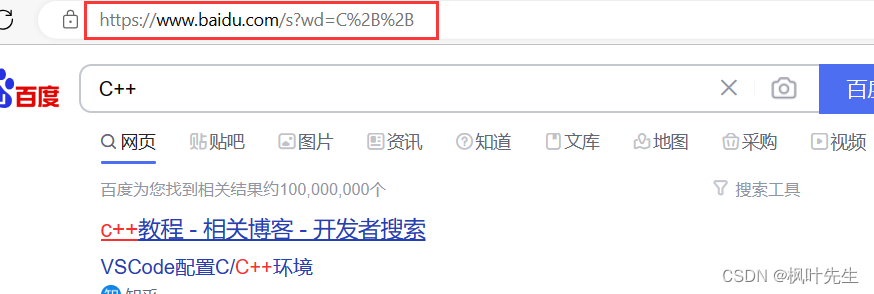
예를 들어 브라우저에서 무언가를 검색할 때:
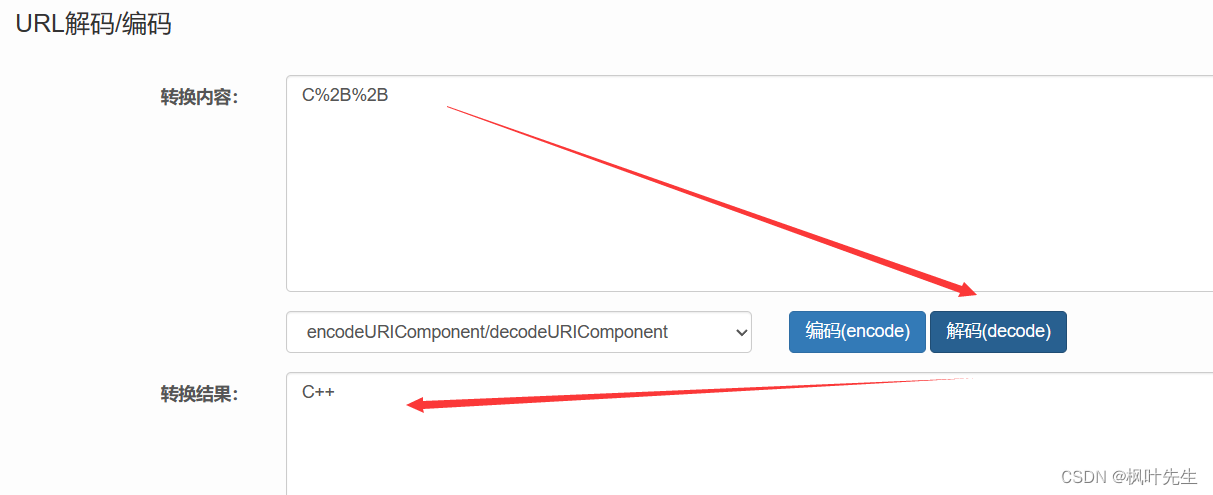
예를 들어 를 검색할 때 C++다음 wd은 모두 검색 매개변수( wd매개변수 이름) 이고 +더하기 기호는 URL의 특수 기호이며 +문자를 16진수로 변환한 후의 값은 이므로 0x2B하나가 +됩니다 . 메모로 인코딩 %2B
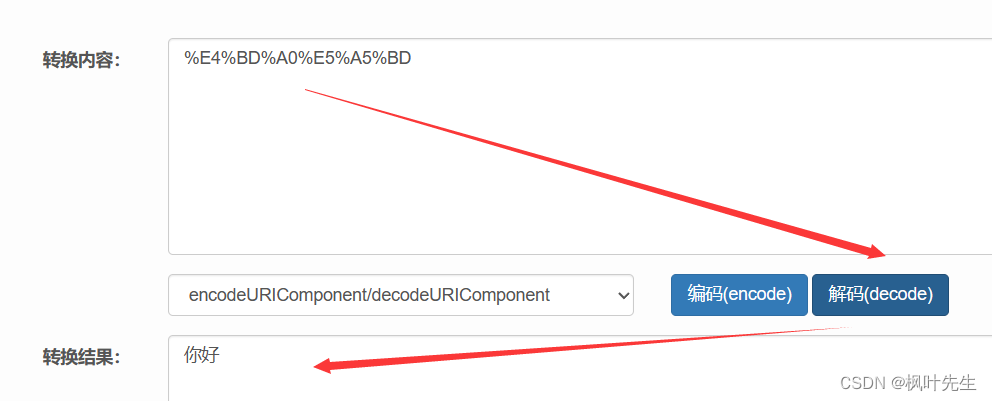
: 한자와 특수문자를 변환해야 하는데 이 과정이 URL이 되는데 encode
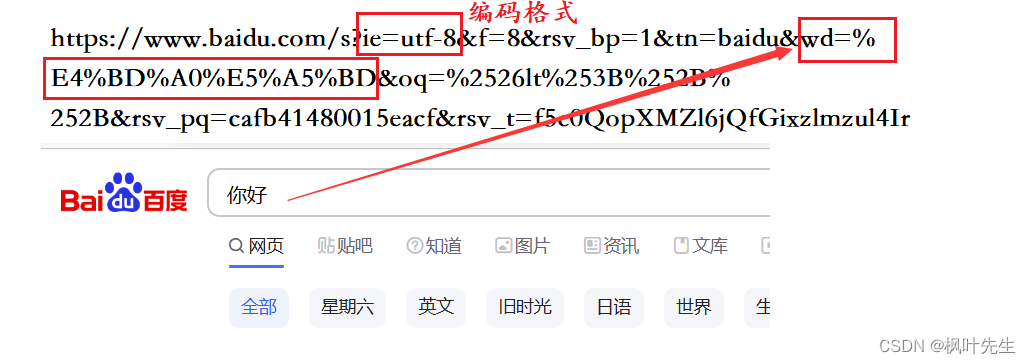
서버가 우리의 요청을 받으면 %xx특수기호를 해독하게 되는데 이 과정을 URL이라고 합니다 decode. 서버를 작성하기 위해 사용할 때 C++이 작업을 수행해야 합니다. (소스 코드는 인터넷에서 구할 수 있으므로 직접 사용하십시오.)
디코딩 프로세스를 확인하고 인터넷에서 온라인 URL 디코딩 도구를 검색하여 사용하십시오.
넷째, HTTP 프로토콜 요청 및 응답 형식
HTTP는 요청과 응답을 기반으로 하는 응용 계층 서비스입니다.클라이언트는 서버에 대한 요청을 시작할 수 있습니다 . request서버는 이것을 수신한 request후 request이를 분석하여 액세스하려는 리소스를 찾은 다음 서버가 이를 완료하기 위한 응답을 작성합니다 response. HTTP 요청입니다. 이 작업 방법을 기반으로 request&response호출하거나 cs모드 bs, c는 client, s는 , b는 브라우저가 프로토콜의 클라이언트 임을 server의미 하므로 프로토콜을 사용하기 위해 클라이언트를 작성할 필요가 없습니다.browserhttphttp
4.1 HTTP 요청 프로토콜 형식
HTTP 요청 프로토콜 형식은 대략 다음과 같습니다.

HTTP 요청은 네 부분으로 구성됩니다.
- 요청 라인: [요청 방법]+[url]+[http 버전]+[\r\n]
- 요청 헤더: 요청의 속성, 이러한 속성은
name:value[\r\n]으로 끝나는 + 형식으로 나열 됩니다. - 빈 줄: 빈 줄(\r\n)이 나타나면 요청 헤더의 끝을 나타냅니다.
- 요청 본문: 요청 본문은 빈 문자열일 수 있으며 요청 본문은 비어 있을 수 있습니다.
Content-Length요청 본문이 있는 경우 요청 본문의 길이를 식별하기 위해 요청 헤더에 하나가 있습니다.
알아채다: http는 특수 기호(\r\n)를 사용하여 내용을 나눕니다.
처음 세 부분은 일반적으로 HTTP 프로토콜에 포함되며 요청 본문의 마지막 부분은 생략할 수 있습니다.(빈 문자열) 요청이 패키징된 후 바로 다음 계층인 전송 계층으로 전달됩니다. 그것을 처리
4.2 HTTP 응답 프로토콜 형식
HTTP 응답 프로토콜의 형식은 대략 다음과 같습니다.

HTTP 응답은 네 부분으로 구성됩니다.
- 상태 표시줄: [http 버전]+[상태 코드]+[상태 코드 설명]]+[\r\n]
- 응답 헤더: 응답의 속성, 이러한 속성은
name:value[\r\n]으로 끝나는 + 형식으로 나열 됩니다. - 빈 줄: 빈 줄(\r\n)을 만나면 응답 헤더의 끝을 나타냅니다.
- 응답 본문: 응답 본문은 빈 문자열이 될 수 있으며 응답 본문은 비어 있을 수 있습니다.
Content-Length응답 본문이 있는 경우 응답 헤더에 응답 본문의 길이를 식별하는 속성이 있습니다.
알아채다: http는 특수기호(\r\n)로 나누어진다.
내용의 처음 세 부분은 일반적으로 HTTP 프로토콜에서 제공한다. 응답 본문의 마지막 부분은 생략될 수 있다(빈 문자열). 요청이 패키징된 후, 다음 계층인 전송 계층으로 직접 전달되며 전송 계층에서 처리됩니다.
4.3 질문
http 요청 및 응답이 애플리케이션 계층에서 완전히 읽히도록 하는 방법은 무엇입니까? ?
- 첫째, 요청 및 응답의 경우 한 줄씩 읽을 수 있습니다(각 줄에는
\r\n) - 루프를 사용하여 모든 요청 헤더 또는 응답 헤더를
while읽을 때까지 전체 줄(\r\n분할용)을 읽고 빈 줄을 읽어 읽기가 완료되었음을 나타냅니다. - 다음 단계는 텍스트를 읽는 것입니다. 텍스트를 읽는 방법은 무엇입니까? ? 텍스트에 특수 기호가 없습니다.
- 우리는 이미 요청 또는 응답 헤더를 읽었으며 헤더에
Content-Length응답 본문 또는 요청 본문의 길이를 식별하는 데 사용되는 필드가 있어야 합니다. - 구문 분석을 위해
Content-Length텍스트 길이를 가져와서 읽은 텍스트가 완전한지 확인하고 구문 분석된 길이에 따라 직접 읽을 수 있습니다.
이렇게 하면 http 요청 및 응답을 애플리케이션 계층에서 완전히 읽을 수 있습니다.
http 요청 및 응답은 어떻게 직렬화 및 역직렬화됩니까? ?
- 직렬화와 역직렬화는
http특수문자를 이용하여 스스로 구현하며\r\n,第一行 + 请求/响应报头특수문자를 한 줄씩 읽어주기만 하면 전체 문자열을 얻을 수 있다. - 본문은 직렬화 및 역직렬화할 필요가 없으며, 필요한 경우 직접 사용자 지정합니다.
위는 http프로토콜에 대한 매크로 이해이고 다음은 http프로토콜을 이해하기 위한 코드입니다.
다섯, HTTP 테스트 코드
5.1 HTTP 요청
간단한 TCP 서버를 작성해 보겠습니다. 이 서버에서 해야 할 일은 브라우저에서 보낸 HTTP 요청을 인쇄하는 것입니다.
http서버.hpp
#pragma once
#include <iostream>
#include <string>
#include <functional>
#include <strings.h>
#include <unistd.h>
#include <pthread.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include "protocol.hpp"
static const int gbacklog = 5;
using func_t = std::function<bool(const httpRequest &req, httpResponse &resp)>;
// 错误类型枚举
enum
{
UAGE_ERR = 1,
SOCKET_ERR,
BIND_ERR,
LISTEN_ERR
};
// 业务处理
void handlerHttp(int sockfd, func_t func)
{
char buffer[4096];
httpRequest req;
httpResponse resp;
size_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (n > 0)
{
buffer[n] = 0;
req.inbuffer = buffer;
func(req, resp);
send(sockfd, resp.outbuffer.c_str(), resp.outbuffer.size(), 0);
}
}
class ThreadDate
{
public:
ThreadDate(int sockfd, func_t func) : _sockfd(sockfd), _func(func)
{
}
public:
int _sockfd;
func_t _func;
};
class httpServer
{
public:
httpServer(const uint16_t &port) : _listensock(-1), _port(port)
{
}
// 初始化服务器
void initServer()
{
// 1.创建套接字
_listensock = socket(AF_INET, SOCK_STREAM, 0);
if (_listensock == -1)
{
std::cout << "create socket error" << std::endl;
exit(SOCKET_ERR);
}
std::cout << "create socket success: " << _listensock << std::endl;
// 2.绑定端口
// 2.1 填充 sockaddr_in 结构体
struct sockaddr_in local;
bzero(&local, sizeof(local)); // 把 sockaddr_in结构体全部初始化为0
local.sin_family = AF_INET; // 未来通信采用的是网络通信
local.sin_port = htons(_port); // htons(_port)主机字节序转网络字节序
local.sin_addr.s_addr = INADDR_ANY; // INADDR_ANY 就是 0x00000000
// 2.2 绑定
int n = bind(_listensock, (struct sockaddr *)&local, sizeof(local)); // 需要强转,(struct sockaddr*)&local
if (n == -1)
{
std::cout << "bind socket error" << std::endl;
exit(BIND_ERR);
}
std::cout << "bind socket success" << std::endl;
// 3. 把_listensock套接字设置为监听状态
if (listen(_listensock, gbacklog) == -1)
{
std::cout << "listen socket error" << std::endl;
exit(LISTEN_ERR);
}
std::cout << "listen socket success" << std::endl;
}
// 启动服务器
void start(func_t func)
{
for (;;)
{
// 4. 获取新链接,accept从_listensock套接字里面获取新链接
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
// 这里的sockfd才是真正为客户端请求服务
int sockfd = accept(_listensock, (struct sockaddr *)&peer, &len);
if (sockfd < 0) // 获取新链接失败,但不会影响服务端运行
{
std::cout << "accept error, next!" << std::endl;
continue;
}
std::cout << "accept a new line success, sockfd: " << sockfd << std::endl;
// 5. 为sockfd提供服务,即为客户端提供服务
// 多线程版
pthread_t tid;
ThreadDate *td = new ThreadDate(sockfd, func);
pthread_create(&tid, nullptr, threadRoutine, td);
}
}
static void *threadRoutine(void *args)
{
pthread_detach(pthread_self()); // 线程分离
ThreadDate *td = static_cast<ThreadDate *>(args);
handlerHttp(td->_sockfd, td->_func); // 业务处理
close(td->_sockfd); // 必须关闭,由新线程关闭
delete td;
return nullptr;
}
~httpServer()
{
}
private:
int _listensock; // listen套接字,不是用来数据通信的,是用来监听链接到来
uint16_t _port; // 端口号
};
http서버.cc
#include "httpServer.hpp"
#include <memory>
// 使用手册
// ./httpServer port
static void Uage(std::string proc)
{
std::cout << "\nUage:\n\t" << proc << " local_port\n\n";
}
bool get(const httpRequest &req, httpResponse &resp)
{
std::cout << "----------------------http start----------------------" << std::endl;
std::cout << req.inbuffer;
std::cout << "----------------------http end ----------------------" << std::endl;
}
int main(int argc, char *argv[])
{
if (argc != 2)
{
Uage(argv[0]);
exit(UAGE_ERR);
}
uint16_t port = atoi(argv[1]); // string to int
std::unique_ptr<httpServer> tsvr(new httpServer(port));
tsvr->initServer(); // 初始化服务器
tsvr->start(get); // 启动服务器
return 0;
}
프로토콜.hpp
#pragma once
#include <iostream>
#include <string>
#include <vector>
class httpRequest
{
public:
std::string inbuffer;
};
class httpResponse
{
public:
std::string outbuffer;
};
서버 프로그램을 실행한 후 브라우저로 접속하면 우리 서버 가 브라우저로부터 HTTP 요청을 받아 출력하게 됩니다
.
브라우저의 요청 들어오는 HTTP 요청 및 인쇄(한 번만 방문했지만 여러 HTTP 요청, 브라우저의 동작)

GET / HTTP/1.1
Host: 119.3.185.15:8080
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.67
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
설명하다:
- 브라우저는 요청을 시작할 때 기본적으로 HTTP 프로토콜을 사용하므로 브라우저의 url 상자에 URL을 입력할 때 HTTP 프로토콜을 지정하지 않고 서버의 공용 네트워크 주소와 포트 번호를 직접 입력할 수 있습니다.
- 첫 번째 줄은 상태 줄입니다:
GET / HTTP/1.1,GET브라우저의 기본값인 요청 방법이고 URL은 입니다. 특정\요청이 없기 때문에 브라우저는\기본적으로 (웹 루트 디렉터리)를 방문합니다.HTTP/1.1HTTP의 버전 번호
나머지는 모두 요청 헤더이며 모두 name: value라인 형태로 표시되는 다양한 요청 속성입니다.
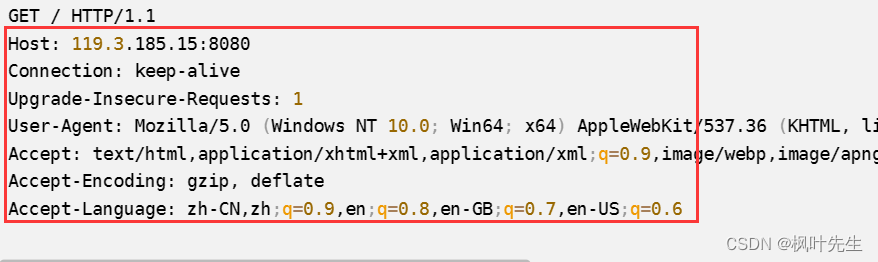
빈 라인도 인쇄됩니다.요청 본문이 없으므로 기본값은 빈 문자열이며 인쇄되는 정보는 없습니다.
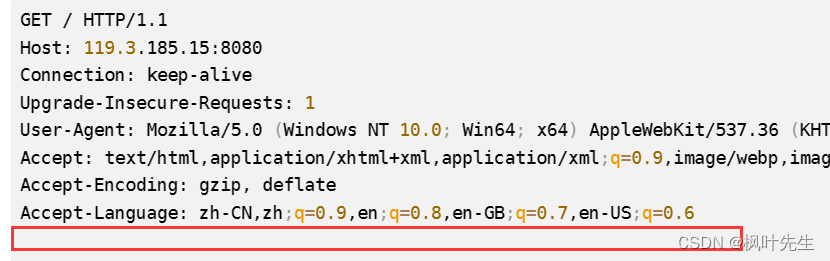
클라이언트 에 의해 표시됩니다 . 호스트 버전 정보:
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.67
User-Agent요청을 시작한 클라이언트 호스트의 버전 정보를 표시하는 것입니다.
예를 들어 다운로드할 항목을 검색하면 기본적으로 자신의 운영 체제와 일치하는 다운로드를 표시합니다. 컴퓨터 버전을 다운로드하시겠습니까? ?
그 이유는 우리가 요청을 시작할 때 요청이 이미 우리 운영 체제의 버전 정보를 가지고 있기 때문입니다 . 나머지
는 인코딩 형식, 텍스트 종류 등과 같이 내 클라이언트가 현재 지원하는 것을 서버에 알리는 것입니다.
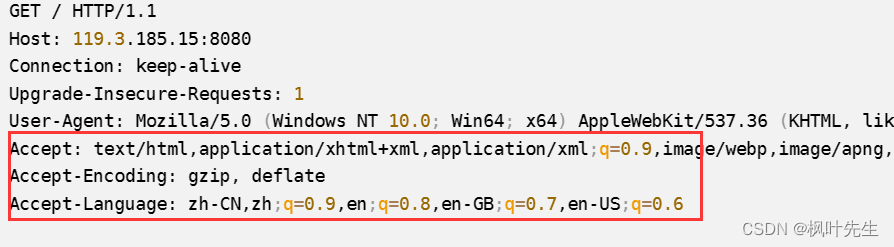
페이로드에서 HTTP 헤더를 분리하는 방법은 무엇입니까?
- HTTP의 경우 상태 표시줄과 응답/요청 헤더는 HTTP 헤더 정보이며 여기서 응답/요청 본문은 실제로 HTTP 페이로드입니다.
- 빈 줄을 읽었다면 헤더를 읽었다는 의미로 빈 줄은 HTTP 헤더와 페이로드를 구분하는 핵심이다.
- 즉, http는 특수 기호를 사용하여 헤더와 페이로드를 구분합니다.
HTTP에 대화식 버전이 필요한 이유는 무엇입니까?
- HTTP 요청의 요청 줄과 HTTP 응답의 상태 줄 모두 http 버전 정보를 포함합니다. . HTTP 요청은 클라이언트에서 보내므로 HTTP 요청은 클라이언트의 http 버전을 나타내고 HTTP 응답은 서버에서 보내므로 HTTP 응답은 서버의 http 버전을 나타냅니다.
- 클라이언트와 서버가 통신할 때 주로 호환성 문제 때문에 양 당사자의 http 버전을 교환합니다. 서버와 클라이언트는 서로 다른 http 버전을 사용할 수 있으므로 서로 다른 버전의 클라이언트가 해당 서비스를 이용할 수 있도록 통신 당사자는 버전 협상을 수행해야 합니다.
- 예를 들어 버전이 1.0인 애플리케이션이 오늘 2.0으로 업그레이드(새로운 기능이 제공되지만 이전 버전은 제공되지 않음)하는 경우 일부 사용자는 업그레이드하고 일부 사용자는 업그레이드하지 않습니다. 이때 다음과 같은 문제가 발생합니다. 버전 차이. 이전 버전은 서버에 접근하지만, 새로운 버전의 서버에는 접근할 수 없습니다. 이전 버전은 이전 서버에 접근할 수 있어야 합니다. 이때 양 당사자의 버전 정보를 교환해야 서로 다른 버전의 클라이언트가 가능합니다. 해당 서비스를 즐길 수 있습니다.
- 따라서 좋은 호환성을 보장하기 위해 양 당사자는 버전 정보를 교환해야 합니다.
5.2 HTTP 응답
간단한 코드를 추가하고 HTTP 응답을 관찰해 봅시다.
bool get(const httpRequest &req, httpResponse &resp)
{
std::cout << "----------------------http request start----------------------" << std::endl;
std::cout << req.inbuffer;
std::cout << "+++++++++++++++++++++++++++++" << std::endl;
std::cout << "request method: " << req.method << std::endl;
std::cout << "request url: " << req.url << std::endl;
std::cout << "request httpversion: " << req.httpversion << std::endl;
std::cout << "request path: " << req.path << std::endl;
std::cout << "request file suffix: " << req.suffix << std::endl;
std::cout << "request body size: " << req.size << "字节" << std::endl;
std::cout << "----------------------http request end ----------------------" << std::endl;
std::cout << "----------------------http response start ----------------------" << std::endl;
std::string respline = "HTTP/1.1 200 OK\r\n"; // 响应状态行
std::string respheader = Util::suffixToDesc(req.suffix);
std::string respblank = "\r\n"; // 响应空行
std::string respbody; // 响应正文
respbody.resize(req.size);
if (!Util::readFile(req.path, (char *)respbody.c_str(), req.size)) // 访问资源不存在,打开404html
{
struct stat st;
stat(html_404.c_str(), &st);
respbody.resize(st.st_size);
Util::readFile(html_404, (char *)respbody.c_str(), st.st_size); // 一定成功
}
resp.outbuffer = respline;
respheader += "Content-Length: ";
respheader += std::to_string(respbody.size());
respheader += respblank;
resp.outbuffer += respheader;
resp.outbuffer += respblank;
std::cout << resp.outbuffer;
resp.outbuffer += respbody;
std::cout << "----------------------http response end ----------------------" << std::endl;
return true;
}
코드가 너무 많으면 게시되지 않습니다. gitee 링크: 링크
작업 결과, 서버가 다시 응답하고(브라우저가 당사 서버에 액세스하면 서버는 index.html브라우저에 이 파일에 응답하며 기본 index.html파일은 방문한 웹 사이트의 홈 페이지임)
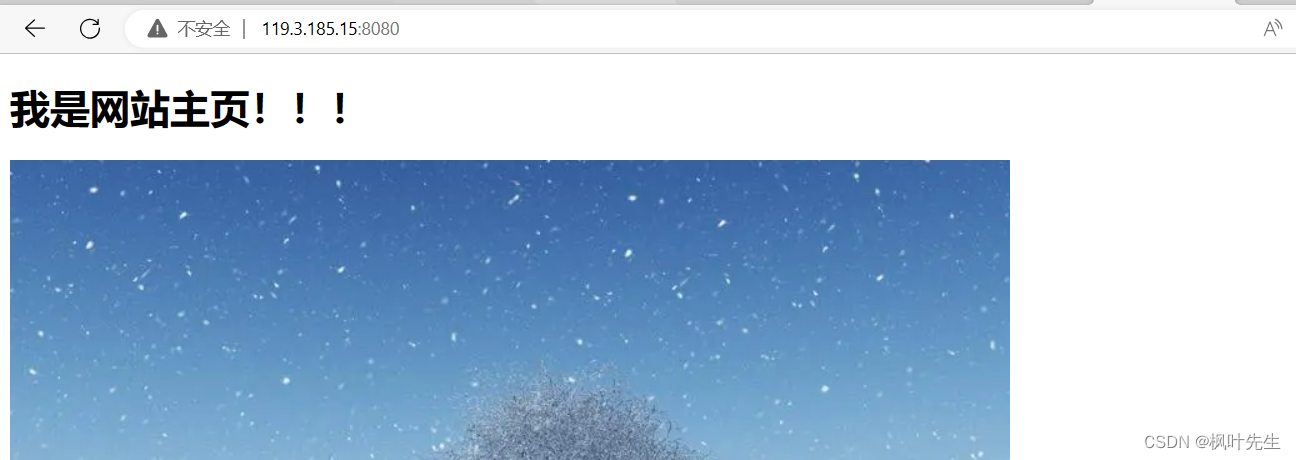
응답 정보의 일부를 인쇄합니다.

메모: 예를 들어 HTTP 응답을 구성할 때 2개의 속성 정보만 응답 헤더에 추가되고 실제 HTTP 응답 헤더에는 많은 속성 정보가 포함됩니다.
여섯, HTTP 방식

HTTP의 일반적인 메서드는 다음과 같습니다. (요청에서)
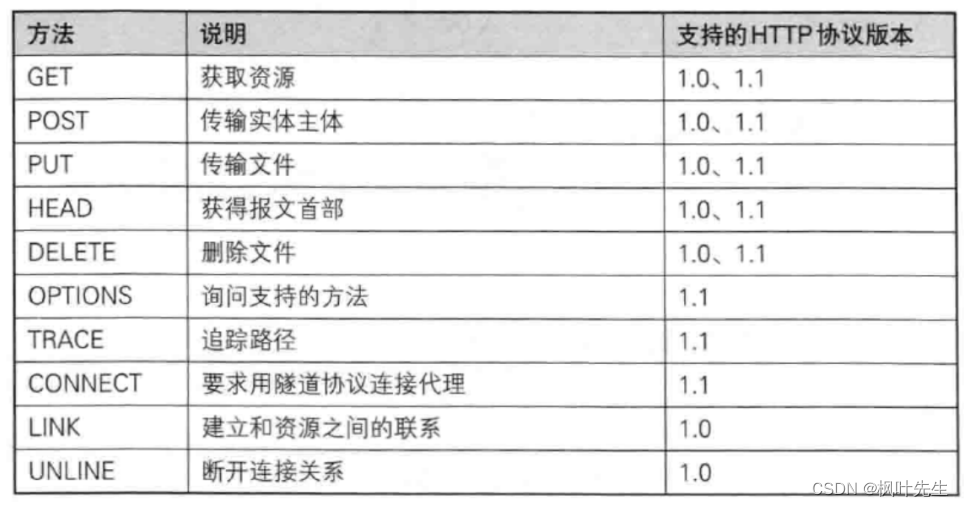
가장 일반적으로 사용되는 방법은 GET 방식과 POST 방식입니다.
프런트 엔드 및 백엔드 데이터와 상호 작용할 때 본질은 프런트 엔드가 form양식을 통해 제출하고 브라우저가 자동으로 양식의 내용을 GET/POST요청 으로 변환한다는 것입니다
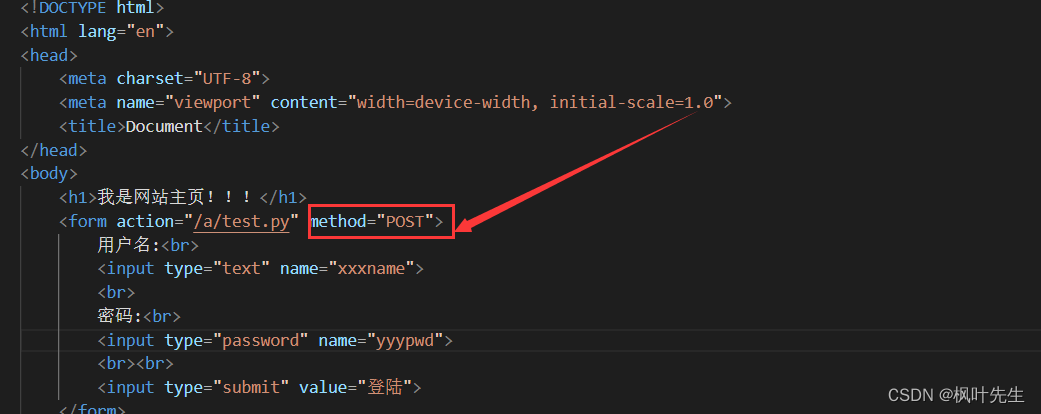
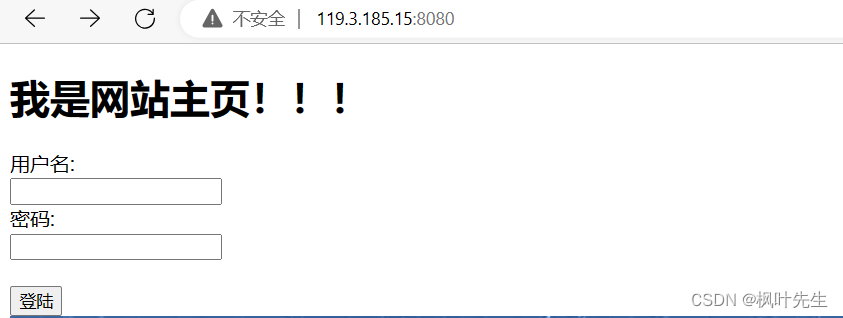
예를 들어 프론트 엔드 양식 제출 페이지

action="/a/test.py"양식이 지정된 경로 파일에 제출됨을 의미하며 method="GET"이는 http 액세스를 의미합니다. 방법은 GET
서버를 시작하고 브라우저를 방문하여

장산, 123123과 같은 콘텐츠를 제출하는 것입니다.
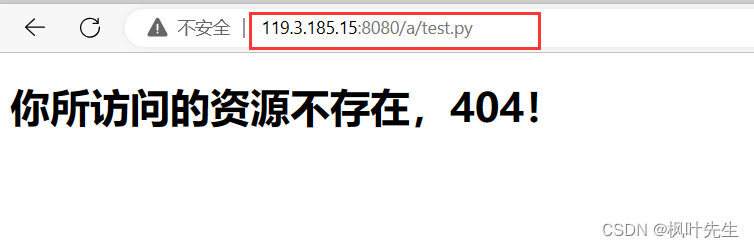
액세스 한 페이지가 존재 /a/test.py하지 않기 때문에 서버에서 인쇄한 요청 정보를 볼 수 있는 404페이지(직접 설정)

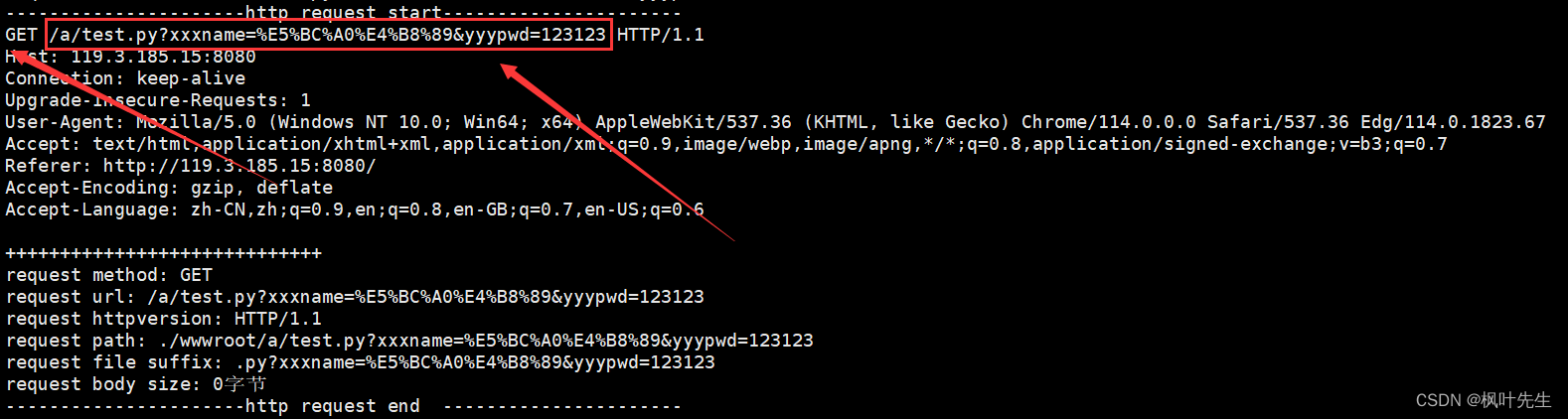
GET메서드가 매개변수를 제출하면 매개변수 제출이 URL 뒤에 연결됩니다.
/a/test.py?앞은 우리가 요청하고자 하는 자원, 뒤는 xxxname=%E5%BC%A0%E4%B8%89&yyypwd=123123양식에 의해 제출된 정보입니다.또한 브라우저 URL 표시줄에 제출된 내용이 표시됩니다. 아래 방법을
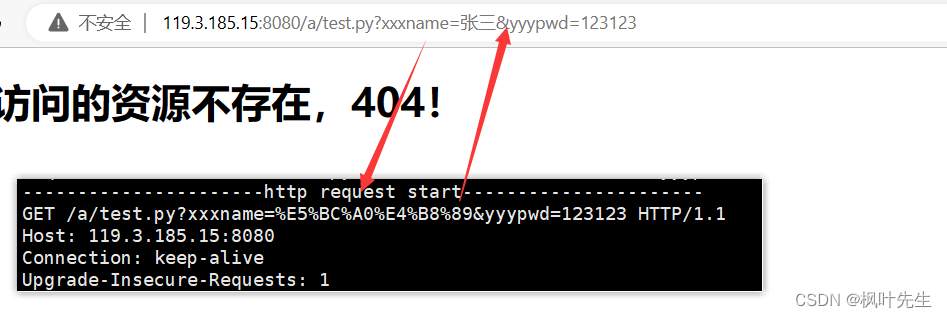
시도 하고 HTML 브라우저를 수정하여 제출 양식 에 액세스하고 , 브라우저 URL 표시줄에는 표시되지 않습니다. 제출한 콘텐츠는 있지만 액세스하는 리소스는 볼 수 있습니다. 서버에서 인쇄한 요청 정보 보기POST
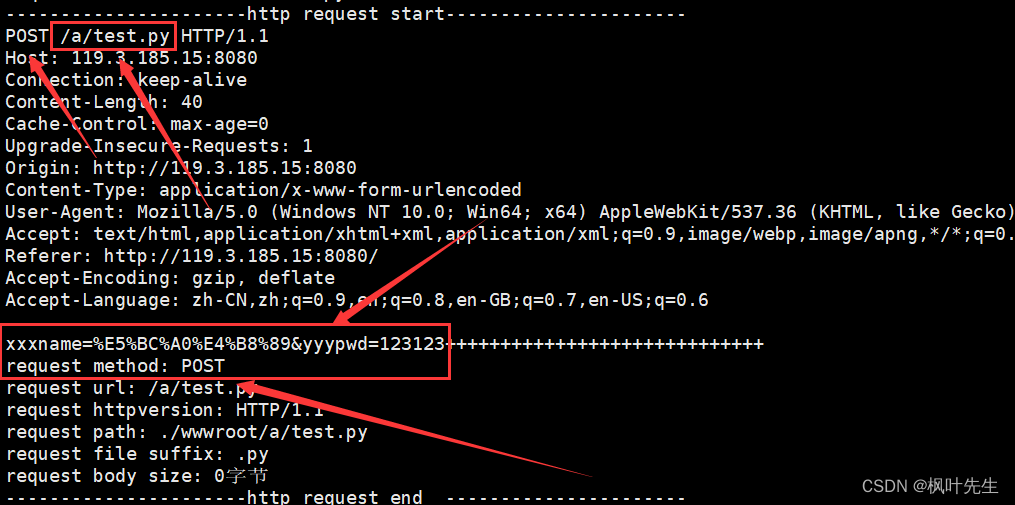
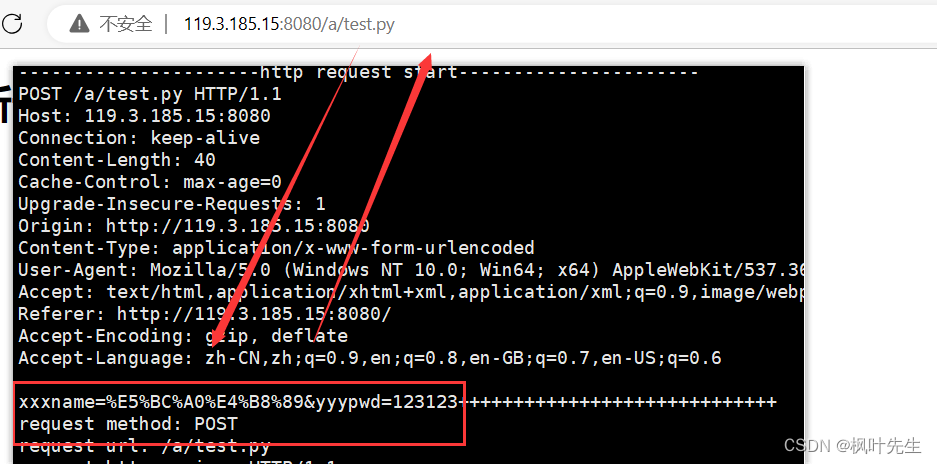
POST메소드는 양식 정보를 제출하고 제출된 매개변수는 http 요청의 본문에 배치됩니다.
브라우저의 URL 표시줄에는 제출한 콘텐츠가 표시되지 않지만 방문하는 리소스는 볼 수 있습니다.
요약:
GET/POSThttp 요청 방법 간의 차이점
GET메소드 제출 매개변수는 URL을 통해 매개변수를 전달하는 것입니다. 예를 들면 다음과 같습니다.http://ip:port/xxx/yyy?name=value&name2=value2...POST메소드 제출 매개변수는 http 요청 본문을 통해 매개변수를 제출하는 것입니다.POST이 메서드는 요청 본문을 통해 매개 변수를 제출하며, 이는 일반적으로 사용자에게 보이지 않고 개인 정보 보호에 더 좋습니다.GET메소드 제출 매개변수는 누구나 볼 수 있는 URL을 통해 전달되는 매개변수입니다.GET메서드는 URL을 통해 매개 변수를 전달하고 매개 변수는 너무 크지 않도록 지정되는 반면POST메서드는 본문을 통해 매개 변수를 전달하며 본문은 매우 클 수 있습니다.
알아채다: 사생활! = 보안, HTTP 보안이 좋지 않아 타인에게 직접 적발될 수 있음
일곱, HTTP 상태 코드
HTTP 상태 코드는 다음과 같습니다.
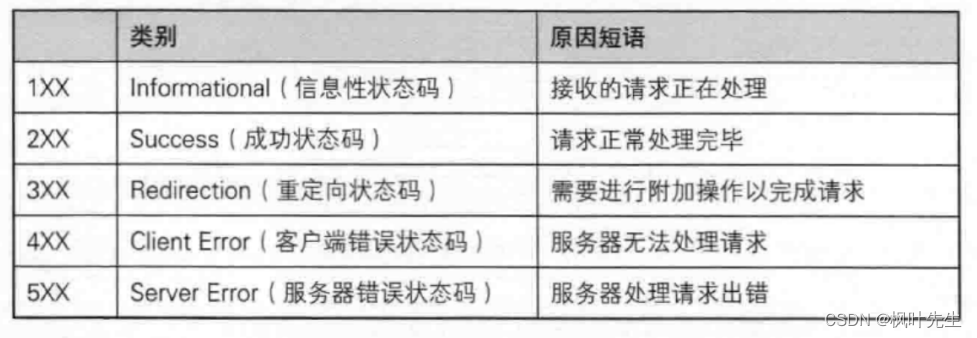
메모: 1xx는 1로 시작하는 상태 코드를 나타내며, 상태 코드는 3자리입니다. 예를 들어 404는
다음과 같은 가장 일반적인 상태 코드입니다.200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
리디렉션(리디렉션 상태 코드)에 대해 알아보겠습니다.
리다이렉션은 다양한 네트워크 요청을 다양한 방법을 통해 다른 위치로 리디렉션하는 것으로 이때 서버는 가이드 서비스를 제공하는 것과 같다 리다이렉션은
클라이언트가 수행하고 서버는 클라이언트에게

리디렉션을 지시하는 임시 리디렉션으로 나눌 수 있다 상태 코드 301은 영구 리디렉션을 나타내고 상태 코드 302 및 307은 임시 리디렉션을 나타냅니다.
영구적으로 이동됨, 영구적으로 리디렉션됨
- 영구적이란 원래 액세스한 리소스가 영구적으로 삭제되었으며 클라이언트가 새 URI 액세스에 따라 리디렉션되어야 함을 의미합니다.
임시 리디렉션
- 임시는 먼저 위치 URI를 사용하여 액세스된 리소스에 일시적으로 액세스할 수 있지만 이전 리소스는 여전히 존재하므로 다음에 방문할 때 리디렉션할 필요가 없을 수 있음을 의미합니다.
- 302 리디렉션에는 URL 하이재킹(URL 하이재킹)이 있을 수 있습니다. 예를 들어 검색 결과에는 여전히 URL A가 표시되지만 사용된 웹 페이지의 콘텐츠는 URL B의 콘텐츠입니다. 이러한 상황을 URL 하이재킹이라고 합니다.
리디렉션에 대한 자세한 설명은 리디렉션 문서 링크를 참조하세요.
다음은 임시 리디렉션 데모입니다.
- Location 필드는 리디렉션하려는 대상 웹 사이트를 나타내는 HTTP 헤더의 속성 정보입니다.
HTTP 응답의 상태 코드를 307로 변경한 다음 해당 상태 코드 설명을 유지합니다. 또한 HTTP 응답 헤더에 위치 필드를 추가해야 합니다. 이 위치 뒤에 리디렉션해야 하는 웹 페이지가 옵니다. , 예를 들어 내 CSDN의 홈 페이지로 설정

이때 브라우저가 우리 서버에 액세스하면 즉시 CSDN의 홈 페이지로 이동합니다.

서버는 인쇄 정보로 응답합니다.

여덟, HTTP 공통 헤더
일반적인 HTTP 헤더는 다음과 같습니다.
Content-Type: 데이터 유형(텍스트/html 등)Content-Length: 몸의 길이Host: 클라이언트는 요청한 리소스가 호스트의 어느 포트에 있는지 서버에 알립니다.User-Agent: 사용자의 운영 체제 및 브라우저 버전 정보를 선언합니다.Referer: 현재 페이지가 리디렉션되는 페이지Location: 3xx 상태 코드와 함께 사용하여 클라이언트에게 다음에 방문할 위치를 알려줍니다.Cookie: 클라이언트 측에 소량의 정보를 저장하기 위해 사용하며, 주로 세션 기능을 구현하기 위해 사용
주인
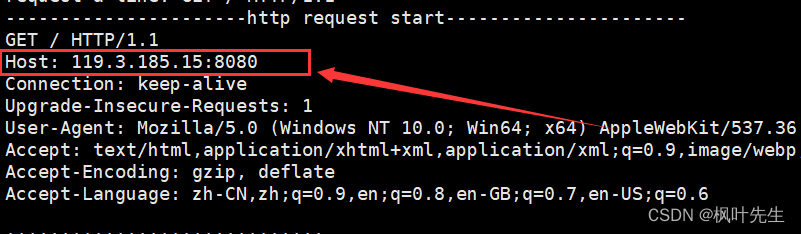
Host필드는 클라이언트가 접속하고자 하는 서비스의 IP와 포트를 나타내며, 예를 들어 브라우저가 우리 서버에 접속할 때 브라우저가 보낸 HTTP 요청의 호스트 필드는 우리의 IP와 포트로 채워집니다.
사용자 에이전트
앞서 언급한 바와 같이 User-Agent클라이언트에 해당하는 운영체제와 브라우저의 버전 정보를 나타냅니다.

나타내다
Referer현재 점프하고 있는 페이지를 나타냅니다. Referer이전 페이지 기록의 장점은 롤백이 편리하다는 점과 한편으로는 현재 페이지와 이전 페이지의 상관 관계를 알 수 있다는 것입니다.
연결 유지(긴 연결)
Keep-Alive긴 연결이라고도 하는 은 각 요청의 지연과 리소스 소비를 줄이기 위해 클라이언트와 서버 간의 지속적인 연결을 유지하기 위해 HTTP 프로토콜에서 사용되는 기술입니다.
전통적인 HTTP 프로토콜에서는 클라이언트가 요청을 보낼 때마다 서버가 즉시 응답을 반환하고 연결을 닫습니다. 이러한 연결을 짧은 연결이라고 합니다. 긴 연결은 클라이언트와 서버 사이에 연결이 설정된 후 연결을 통해 여러 요청을 보내고 여러 응답을 받을 수 있다는 것입니다.
긴 연결의 장점은 다음과 같습니다.
- 연결 설정 및 연결 해제의 오버헤드 감소: 짧은 연결에서는 각 요청이 연결을 설정 및 연결 해제해야 하는 반면, 긴 연결은 설정된 연결을 재사용할 수 있으므로 이러한 오버헤드가 줄어듭니다.
- 지연 감소: 짧은 연결에서는 각 요청이 연결을 다시 설정해야 하지만 긴 연결은 이러한 지연을 방지하고 응답 속도를 향상시킬 수 있습니다.
- 리소스 소비 감소: 짧은 연결에서는 각 요청이 연결을 다시 설정해야 하며 긴 연결은 서버 리소스의 소비를 줄일 수 있습니다.
알아두세요: 긴 연결은 영구적이지 않으며 서버와 클라이언트 모두 적극적으로 연결을 닫을 수 있음
HTTP 요청 또는 응답 헤더의 Connect필드에 해당하는 값은 Keep-Alive긴 연결이 지원됨을 의미합니다.

그것에 대해 자세히 이야기합시다Cookie和Session
나인, 쿠키 및 세션
HTTP는 실제로 상태 비저장 프로토콜 이며 HTTP의 각 요청/응답 사이에는 관계가 없지만 브라우저를 사용할 때는 그렇지 않다는 것을 알게 됩니다.
예를 들어, 우리가 빌리빌리와 같은 웹사이트에 로그인할 때 한 번 로그인하면 로그인 상태가 오랫동안 유지될 수 있으며, 빌리빌리 웹사이트를 닫았다가 다시 열어도 계정이 여전히 로그인되어 있는 것을 발견하고, 다시 로그인할 필요가 없습니다. 브라우저도 닫으세요.
이것은
cookie및 를 통해session달성되며 이를 세션 지속성이라고 합니다.
알아채다: 엄밀히 말하면 세션 유지는 http의 자연스러운 기능이 아니며 추후 사용 후 세션 유지가 필요한 것으로 파악됩니다.
http 프로토콜은 상태 비저장이지만 사용자에게 필요합니다. 사용자가 웹 페이지 작업을 수행할 때 새로운 웹 페이지를 볼 필요가 있으며 페이지 점프가 발생하면 새 페이지는 어떤 사용자인지 식별할 수 없게 되며 다시 로그인해야 합니다. 따라서
로그인한 사용자는 자신의 신원에 따라 전체 웹 사이트를 방문할 수 있으며 세션 지속성이 필요합니다.
세션 지속성(이전 방식)
- 사용자가 웹사이트를 방문하면 웹사이트는 사용자에게 로그인을 유도합니다. 사용자가 로그인한 후 클라이언트 브라우저는 사용자의 계정 번호와 비밀번호를 저장합니다. 향후 사용자가 동일한 웹사이트를 방문하는 한 브라우저는 저장된 기록을 자동으로 푸시합니다. 정보, 인증
- 브라우저는 계정 번호와 비밀번호를 저장합니다. 이 기술을
cookie
쿠키
Cookie사용자의 브라우저에 저장되는 작은 텍스트 파일로, 사용자의 본인 인증 정보, 개인화 설정 등을 저장하기 위해 사용됩니다. 사용자가 웹 사이트를 방문하면 서버는 일부 정보를 저장 하고Cookie향후 요청 시Cookie서버로 전송합니다.cookie저장 방법은 두 가지가 있습니다:cookie文件저장 및cookie内存저장- 브라우저를 닫았다가 다시 열고 이전에 로그인한 웹 사이트를 방문하십시오. 계정 번호와 비밀번호를 다시 입력해야 하는 경우 이전에 로그인할 때 브라우저에 저장된 쿠키 정보가 메모리 수준임을 의미합니다.
- 브라우저를 닫거나 컴퓨터를 다시 시작하고 다시 열어 이전에 로그인했던 웹 사이트를 방문하십시오. 계정과 비밀번호를 다시 입력할 필요가 없다면 이전에 로그인할 때 브라우저에 저장된 쿠키 정보를 의미합니다. 파일 수준에 있음
이것은 cookie브라우저에서 관리할 수 있고, cookie이 모든 것을 삭제하고, 모든 웹사이트는 다시 로그인 해야
합니다 . 다시 로그인해야 합니다.cookie
cookie

사용상
cookie의 문제
정상적인 상황에서는 문제가 없으며

사용자의 안전하지 않은 작업이 바이러스, 웜, 트로이 목마 등에 감염되면 사용자 자신이 cookie유출됩니다.
- 웜 : 사용자 호스트를 직접 공격(주로 CPU, 메모리 등 공격)하여 시스템 리소스를 고갈시키는 것을 목표로 함
- 트로이 목마 바이러스: 트로이 목마는 고대 전설에 나오는 트로이 목마와 유사하며 적군을 숨기고 밤에 나타나 그들을 파괴합니다. 트로이 목마는 컴퓨터 파괴를 목적으로 하는 것이 아니라 겉보기에 정상 프로그램에 숨어 있으며 해커와 협력하여 내외부와 협력하고 있습니다. 악의적으로 사용자 호스트를 공격
cookie악의적인 의도를 가진 누군가에 의해 획득된 후 해커는 자신의 브라우저에서 직접 서버에 액세스할 수 있으며 서버는 사용자가 서버에 액세스하는 것으로 잘못 인식합니다(사회에 큰 피해)
솔루션session
세션
session사용자 세션 정보를 저장하기 위한 서버 측 저장 기술입니다.- 사용자가 처음으로 웹 사이트를 방문하면 서버는 사용자의 고유 ID를 생성하고
Session ID브라우저에 ID를 저장한 다음Cookie브라우저로 보냅니다. 브라우저는 후속 요청에서 이를 자동으로 서버로 보냅니다Session ID. 서버는Session ID다음과 같은 정보에 따라 해당 세션 정보를 찾습니다. session서버 측에 저장되며 각 사용자는 서버에서 고유한 하나의 를 가집니다session文件(session ID문자열).- 클라이언트 브라우저는 사용자의 계정 암호를 저장할 필요가 없으며
sessionID그냥 저장sessionID합니다cookie.
SessionID우리가 웹사이트에 처음 로그인하여 계정 번호와 비밀번호를 입력 하면 서버 인증에 SessionID성공한 후 서버에서 해당 계정을 생성하고
응답할 때 생성된 SessionID 값을 브라우저에 응답합니다. 브라우저가 응답을 받은 후 자동으로 Session ID값을 추출하여 브라우저 cookie파일에 저장합니다. 나중에 서버에 액세스할 때 해당 HTTP 요청에 자동으로 전달됩니다 Session ID.
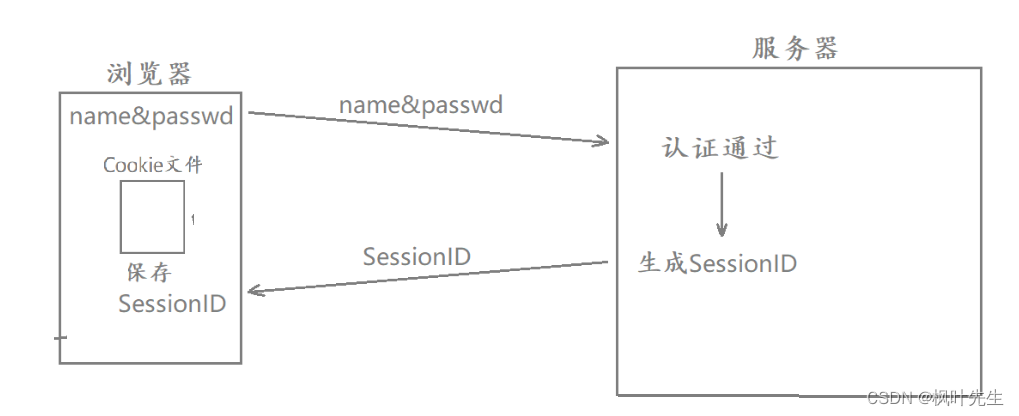
- 현재 사용자 정보 유출은 크게 개선되었지만 여전히 문제가 있습니다.
- 해커는 사용자의 세션 파일을 훔쳤는데, 해커는 사용자로 서버에 접근할 수 있고, 서버는 불법 사용자를 정상 사용자로 오인하여 해결할 수 없습니다.
- 이때 IP 등의 일정한 전략을 이용하여
session ID무효화 시키는 방식으로 비밀번호를 아는 사람만 로그인이 가능하며, 다시 로그인에 성공하여 도용의 문제를 어느 정도session ID완화 (암호를 알 수 없음)session ID경화)
보안은 상대적이다
- 실제로 보안 문제를 해결하지는 않지만 이 접근 방식은 비교적 안전합니다. 인터넷에는 절대적인 보안의 개념이 없습니다.모든 보안은 상대적입니다.네트워크로 전송되는 정보를 암호화하더라도 다른 사람이 크랙할 수 있습니다.
- 보안 분야에는 규칙이 있습니다. 정보를 크래킹하는 비용이 크래킹 후 얻은 이점보다 훨씬 크면(이를 수행하는 것이 금전적 손실임을 나타냄) 정보가 안전하다고 말할 수 있습니다 .
아래를 확인하면 클라이언트가 쿠키 정보를 전달합니다.
- 브라우저가 당사 서버에 액세스할 때 서버에서 브라우저로 보내는 HTTP 응답에 필드가 포함되어 있으면
Set-Cookie브라우저가 서버에 다시 액세스할 때 이cookie정보가 전달됩니다.
j 위의 코드를 수정하세요 . 코드 가 너무 많으면 붙여넣지
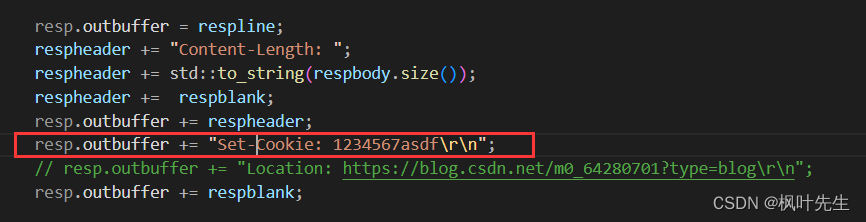
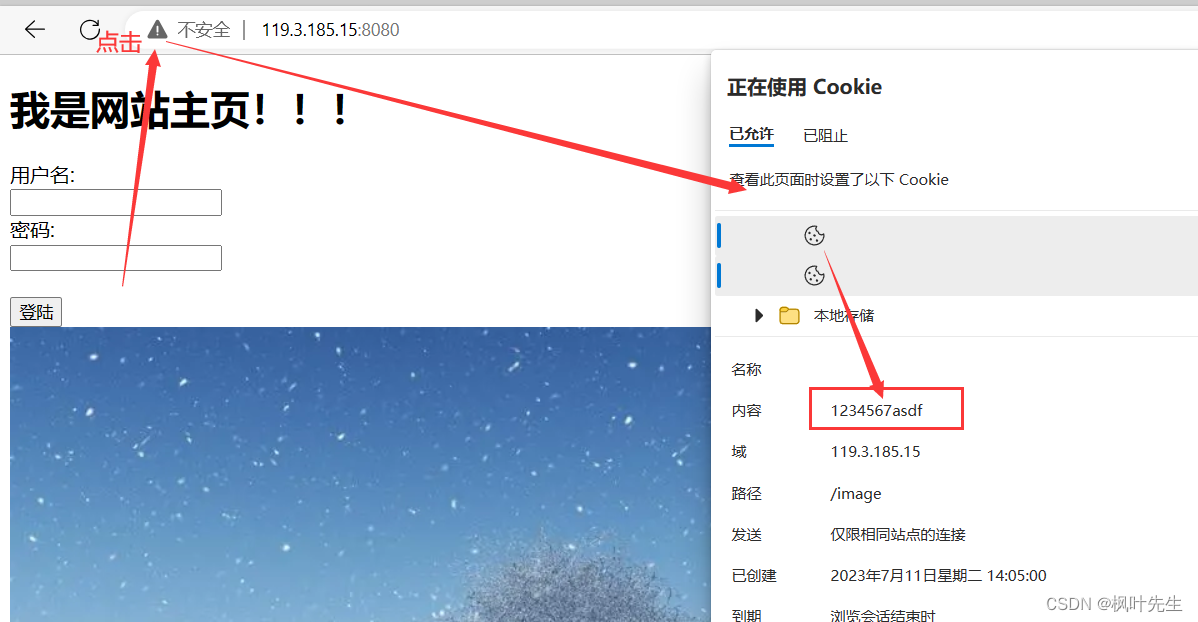
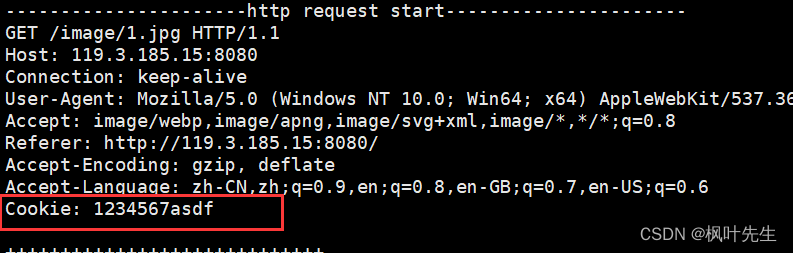
마세요 Set-Cookie. . 서버를 실행한 후 브라우저를 사용하여 당사 서버에 액세스하고 값은 당사에서 설정하며 이때 이러한 쿠키는 브라우저에 작성되며 클라이언트의 두 번째 요청에는 이미 쿠키 정보가 포함되어 있습니다 . 모든 http 요청은 서버가 인증 동작을 수행하는 데 도움이 되도록 설정된 모든 쿠키를 자동으로 전달합니다. 이것이 http 세션 유지 기능입니다.Set-Cookiecookie1234567asdf
도구 추천:
우편 배달부: HTTP 디버깅 도구, 브라우저 동작 시뮬레이트
피들러: 패킷 캡처 도구, HTTP 도구
--------------------- END --------- -- -----------
「 作者 」 枫叶先生
「 更新 」 2023.7.11
「 声明 」 余之才疏学浅,故所撰文疏漏难免,
或有谬误或不准确之处,敬请读者批评指正。